course
Data Manipulation in SQL
4 timmar
324.1K
Har du lagt märke till att MySQL efterfrågas i nästan varje jobbannons som rör databaser? Det finns en bra anledning till det — MySQL driver i princip allt från dina favoritplattformar för sociala medier till apparna du använder dagligen.
Jag har satt ihop den här guiden för att hjälpa dig hantera MySQL-intervjufrågor. Jag går igenom allt från grunderna som juniora utvecklare bör kunna till mer avancerade områden som krävs för seniora roller. Jag delar också några tips för att hjälpa dig uppträda tryggt i dina nästa datarelaterade intervjuer.
MySQL är ett öppen källkods-baserat RDBMS (relational database management system) byggt på SQL som organiserar data i strukturerade tabeller. Det utvecklades av Oracle Corporation.
Det rankades som den mest populära DBMS:en 2024. En Stack Overflow Developer Survey 2025 visade dock att PostgreSQL rankades som den mest använda databasen bland professionella utvecklare och gick om MySQL för första gången.
Missförstå mig inte: MySQL är fortfarande enormt populärt — med 40,5 % användning bland utvecklare 2025 — och driver fortfarande otaliga webbapplikationer, innehållshanteringssystem och företagsverktyg. Och särskilt om du arbetar med webbapplikationer eller LAMP-stacken är MySQL en förstklassig kompetens att ha.
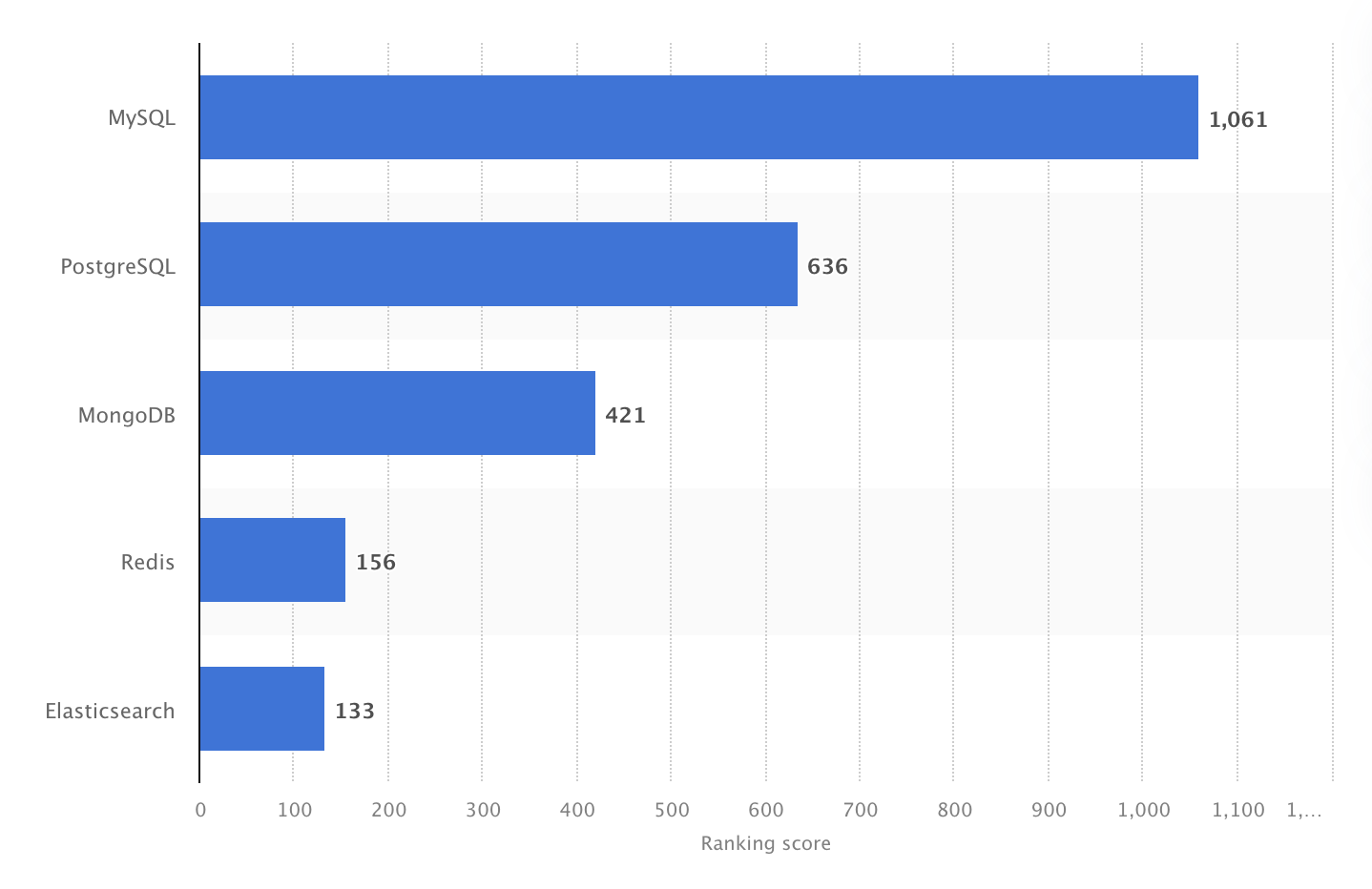
År 2024 var MySQL världens mest populära öppna DBMS, med ett rankingresultat på 1061. Källa: Statista.
I det inledande intervjuskedet kan intervjuaren ställa grundläggande frågor för att bedöma din förståelse av databaser och MySQL-koncept.
En databas är en lagringsbehållare som håller data som vi kan komma åt, ändra och analysera. Till exempel lagrar sociala medieplattformar data om vem som gillat våra inlägg i databaser.
Ett DBMS (Database Management System) är programvaran som låter oss interagera med och hantera den datan genom att skapa användare och styra deras åtkomst. MySQL är ett av de mest populära DBMS-alternativen. Andra exempel include PostgreSQL, MongoDB, och Microsoft SQL Server.
MySQL är ett relationsdatabashanteringssystem (RDBMS) med öppen källkod som använder SQL för att hantera data. Det är känt för sin enkelhet, hastighet och kompatibilitet med webbapplikationer.
Så här skiljer sig MySQL från andra RDBMS:
MySQL är idealiskt i scenarier som kräver hastighet och skalbarhet, men för mer komplexa eller företagsinriktade funktioner kan PostgreSQL vara ett bättre val.
MySQL stöder en mängd datatyper i följande kategorier:
Numeriska: INT, DECIMAL, FLOAT, DOUBLE, etc.
Strängar: CHAR, VARCHAR, TEXT, BLOB.
Datum/tid: DATE, DATETIME, TIMESTAMP, TIME.
JSON: För att lagra JSON-objekt.
INT lagrar heltal utan decimaler. Vi kan använda den när det inte finns behov av fraktioner. Däremot kan DECIMAL lagra finansiella värden och lämpar sig för precisa beräkningar med decimaler.
Funktionen DATE i MySQL lagrar datum i formatet år, månad och dag:
YYYY-MM-DD
Däremot lagrar DATETIME datum med tid, och ser ut så här:
YYYY-MM-DD HH:MM:SS
En främmande nyckel är ett fält i en tabell som länkar till primärnyckeln i en annan tabell.
Till exempel, i en tabell customers som lagrar kundinformation har varje kund ett unikt customer_id — i en annan tabell som heter transactions (som lagrar köp), använder vi customer_id som främmande nyckel. customer_id i tabellen transactions länkar varje köp till en specifik kund i tabellen customers .
Så här ser det ut i SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Joins kombinerar rader från två eller flera tabeller baserat på relaterade kolumner. Här är skillnaderna:
INNER JOIN: Returnerar rader där det finns en matchning i båda tabellerna.
LEFT JOIN: Returnerar alla rader från vänstra tabellen och matchande rader från högra tabellen. Om det inte finns någon matchning returneras NULL för högra tabellens kolumner.
RIGHT JOIN: Liknar LEFT JOIN, men returnerar alla rader från högra tabellen och matchande rader från vänstra.
FULL JOIN: Kombinerar resultaten från LEFT JOIN och RIGHT JOIN, inklusive icke-matchande rader från båda tabellerna. Obs: MySQL stöder inte inbyggd FULL JOIN-syntax. För att uppnå samma resultat, använd en UNION av en LEFT JOIN och en RIGHT JOIN
Kommandon som DELETE, TRUNCATE och DROP kan låta lika, men de beter sig olika:
DELETE: Tar bort rader från en tabell baserat på ett villkor. Det kan ångras om det körs inom en transaktion. Exempel:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: Tar bort alla rader från en tabell, men tabellstrukturen finns kvar. Det är snabbare än DELETE och kan inte ångras. Exempel:
TRUNCATE TABLE employees;DROP: Tar helt bort tabellstrukturen och datan, tillsammans med beroenden som index. Exempel:
DROP TABLE employees;För att skapa tabeller använder du CREATE TABLE, och för att ändra dem använder du vanligtvis ALTER TABLE. Här är några exempel:
Skapa tabell:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Ändra för att lägga till en kolumn:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);En temporär tabell finns bara under den aktuella databassessionen. När vi stänger sessionen raderas tabellen. Den här typen av tabell kan tillfälligt lagra mellanresultat. Vi kan använda den för testning, filtrering eller förberedelse av data innan den förs in i en beständig tabell.
Här är ett exempel:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;En subquery (även kallad nästlad fråga) är inbäddad i en annan fråga. Den bryter ner komplexa databasoperationer i mer hanterbara steg. Till exempel kan du skapa en subquery för att hitta anställda som tjänar över genomsnittet:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Låt oss bryta ner detta:
Den inre frågan SELECT AVG(salary) FROM employees beräknar först medellönen.
Den yttre frågan använder sedan detta medel för att hitta anställda som tjänar över det.
Vi kan använda kommandot INSERT för att lägga till data i en tabell. Den grundläggande syntaxen är:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Här är några bästa praxis att följa när du använder INSERT-kommandot
Lista uttryckligen dina kolumner. Det gör koden tydligare och förhindrar fel om tabellstrukturen ändras senare.
För AUTO_INCREMENT-kolumner som ID hoppar du över dem i INSERT-kommandot. MySQL hanterar dessa automatiskt för att förhindra dubbletter av ID.
Var konsekvent med enkla eller dubbla citattecken för strängar. Jag föredrar personligen enkla citattecken, men båda fungerar.
Om du lägger in flera rader kan du göra det i ett enda kommando för bättre prestanda.
Attributet AUTO_INCREMENT i MySQL genererar unika, sekventiella nummer för en kolumn, vanligtvis tabellens primärnyckel.
Här är ett exempel på hur du skapar en tabell med en AUTO_INCREMENT-kolumn:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);Och så här lägger du in rader i den:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');En vy är en sparad fråga som fungerar som en virtuell tabell. Med den kan vi ta en komplex fråga, ge den ett namn och använda den som en tabell i framtida frågor. På så sätt behöver du inte skriva om hela frågan varje gång.
Till exempel, för att förenkla hämtning av anställdas detaljer tillsammans med deras avdelningsnamn kan du skapa en vy:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Du kan nu fråga vyn employee_details precis som en tabell:
SELECT * FROM employee_details;Vi kan dock inte använda vyer för att infoga och uppdatera data. De flesta stöder endast läsning och hindrar användare från direkt åtkomst till databasen, vilket stärker dataskyddet. Vyer kan ibland sakta ner frågor, eftersom de kör den underliggande frågan varje gång de nås.
Lär dig mer om SQL med dessa kurser!
course
course
course