Course
Data Manipulation in SQL
4 ч
324.1K
Вы замечали, что MySQL требуется почти в каждом описании вакансии, связанной с базами данных? На то есть веская причина — MySQL в буквальном смысле обеспечивает работу всего: от ваших любимых соцсетей до приложений, которыми вы пользуетесь каждый день.
Я подготовил это руководство, чтобы помочь вам справиться с вопросами на собеседовании по MySQL. Мы пройдемся по всем темам — от основ, которые должен знать джуниор, до более сложных аспектов для Senior-ролей. Также я поделюсь советами, которые помогут вам уверенно чувствовать себя на следующих собеседованиях, связанных с данными.
MySQL — это открытая СУБД (реляционная система управления базами данных), построенная на SQL и организующая данные в структурированные таблицы. Разрабатывается компанией Oracle Corporation.
Она заняла место самой популярной СУБД в 2024 году. Однако опрос разработчиков Stack Overflow в 2025 году показал, что PostgreSQL впервые обогнал MySQL и стал самой широко используемой базой данных среди профессиональных разработчиков.
Не поймите неправильно: MySQL по‑прежнему чрезвычайно популярен — в 2025 году им пользовались 40,5% разработчиков — и он по‑прежнему питает бесчисленные веб‑приложения, системы управления контентом и корпоративные инструменты. И особенно если вы работаете с веб‑приложениями или стеком LAMP, MySQL — это навык высшей категории.
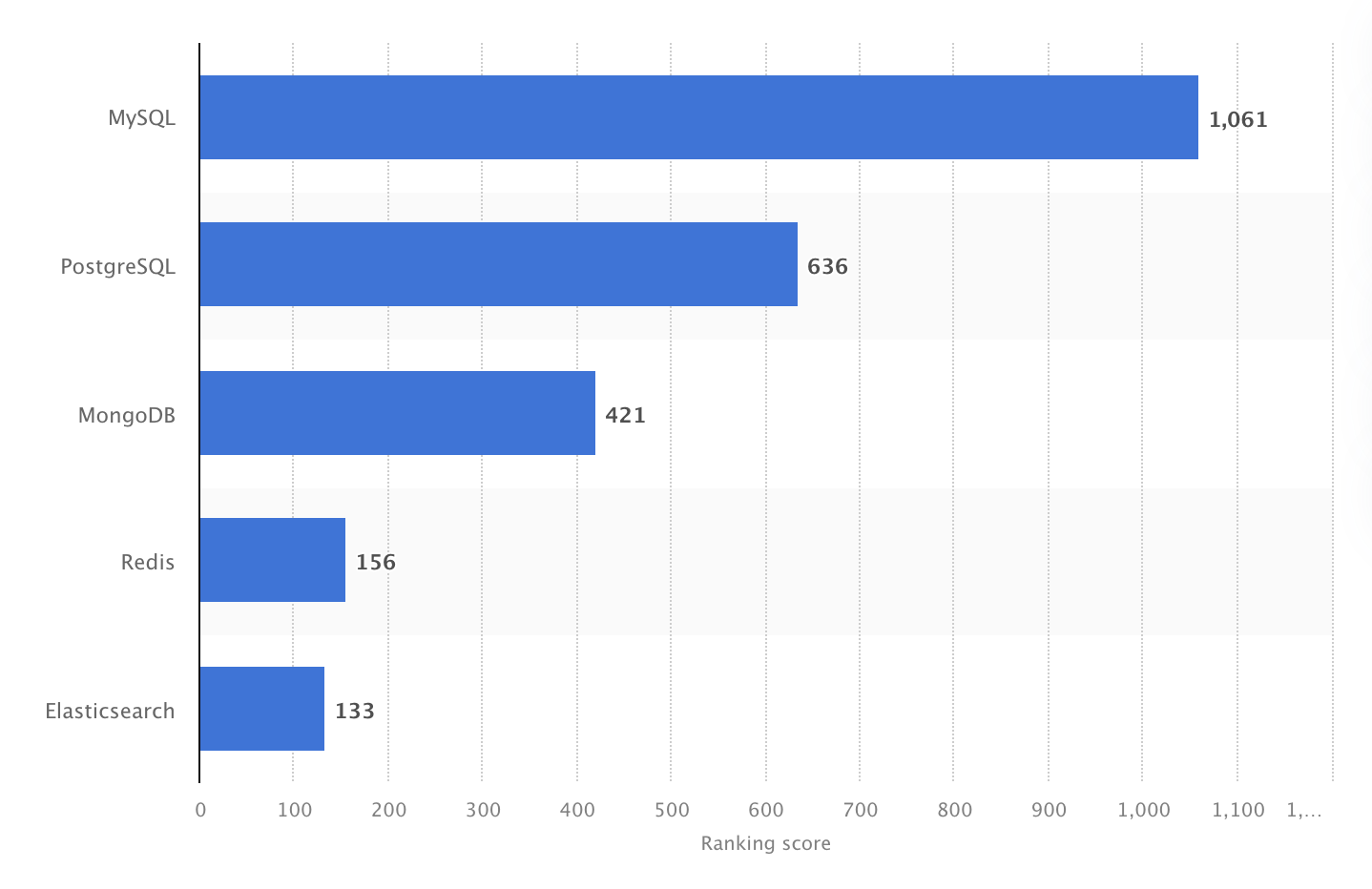
В 2024 году MySQL была самой популярной в мире открытой СУБД с рейтингом 1061. Источник: Statista.
На начальном этапе собеседования интервьюер может задавать фундаментальные вопросы, чтобы оценить ваше понимание баз данных и концепций MySQL.
База данных — это контейнер для хранения данных, к которым мы можем получать доступ, изменять и анализировать. Например, социальные сети хранят в базах данных информацию о том, кто поставил лайк нашим публикациям.
СУБД (система управления базами данных) — это программное обеспечение, которое позволяет нам взаимодействовать с данными и управлять ими, создавать пользователей и настраивать их доступ. MySQL — одна из самых популярных СУБД. К другим примерам относятся PostgreSQL, MongoDB и Microsoft SQL Server.
MySQL — это открытая реляционная система управления базами данных (RDBMS), которая использует SQL для управления данными. Она известна простотой использования, скоростью и совместимостью с веб‑приложениями.
Вот чем MySQL отличается от других RDBMS:
MySQL идеален там, где требуются скорость и масштабируемость, но для более сложных или корпоративных возможностей лучше может подойти PostgreSQL.
MySQL поддерживает множество типов данных, сгруппированных так:
Числовые: INT, DECIMAL, FLOAT, DOUBLE и др.
Строковые: CHAR, VARCHAR, TEXT, BLOB.
Дата/время: DATE, DATETIME, TIMESTAMP, TIME.
JSON: для хранения объектов JSON.
INT хранит целые числа без десятичных знаков. Его можно использовать, когда доли не нужны. Напротив, DECIMAL подходит для хранения финансовых значений и точных вычислений с десятичными дробями.
Функция DATE в MySQL хранит дату в формате год, месяц, день:
YYYY-MM-DD
А вот DATETIME хранит дату вместе со временем и выглядит так:
YYYY-MM-DD HH:MM:SS
Внешний ключ — это поле в одной таблице, которое ссылается на первичный ключ другой таблицы.
Например, в таблице customers, которая хранит информацию о клиентах, у каждого клиента есть уникальный customer_id — в другой таблице под названием transactions (в которой хранятся записи о покупках) мы используем customer_id в качестве внешнего ключа. Поле customer_id в таблице транзакций будет связывать каждую покупку с конкретным клиентом из таблицы customers .
Вот как это выглядит в SQL:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Операции JOIN объединяют строки из двух и более таблиц на основе связанных столбцов. Вот различия:
INNER JOIN: Возвращает строки, для которых есть совпадение в обеих таблицах.
LEFT JOIN: Возвращает все строки из левой таблицы и совпадающие строки из правой. Если совпадения нет, для столбцов правой таблицы возвращается NULL.
RIGHT JOIN: Похоже на LEFT JOIN, но возвращает все строки из правой таблицы и совпадающие из левой.
FULL JOIN: Объединяет результаты LEFT JOIN и RIGHT JOIN, включая несовпадающие строки из обеих таблиц. Примечание: MySQL не поддерживает синтаксис FULL JOIN нативно. Чтобы получить такой же результат, используйте UNION из LEFT JOIN и RIGHT JOIN
Команды DELETE, TRUNCATE и DROP могут звучать похоже, но ведут себя по‑разному:
DELETE: Удаляет строки из таблицы по условию. Может быть отменен, если выполняется внутри транзакции. Пример:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: Удаляет все строки из таблицы, но структура таблицы остается. Быстрее, чем DELETE, и не может быть отменен. Пример:
TRUNCATE TABLE employees;DROP: Полностью удаляет структуру таблицы и данные, а также зависимости, такие как индексы. Пример:
DROP TABLE employees;Для создания таблиц используйте оператор CREATE TABLE, а для изменения — обычно ALTER TABLE. Вот примеры:
Создать таблицу:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));Изменить — добавить столбец:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);Временная таблица существует только в текущей сессии базы данных. Как только мы закрываем сессию, таблица удаляется. Такой тип таблиц может временно хранить промежуточные результаты. Мы можем использовать их для тестирования, фильтрации или подготовки данных перед вставкой в постоянную таблицу.
Пример:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;Подзапрос (он же вложенный запрос) размещается внутри другого запроса. Он разбивает сложные операции с базой данных на более управляемые шаги. Например, можно создать подзапрос, чтобы найти сотрудников, зарабатывающих выше среднего:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Разберем по шагам:
Внутренний запрос SELECT AVG(salary) FROM employees сначала вычисляет среднюю зарплату.
Внешний запрос затем использует это значение, чтобы найти сотрудников, которые зарабатывают выше среднего.
Мы можем использовать оператор INSERT для добавления данных в таблицу. Базовый синтаксис:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Вот несколько рекомендаций при использовании оператора INSERT
Явно перечисляйте столбцы. Это делает код понятнее и предотвращает ошибки, если структура таблицы изменится позже.
Для столбцов с AUTO_INCREMENT, например ID, пропускайте их в INSERT. MySQL заполнит их автоматически, чтобы избежать дублирования ID.
Будьте последовательны с кавычками для строк. Я лично предпочитаю одинарные, но подойдут любые.
Если вставляете несколько строк, делайте это одним оператором ради производительности.
Атрибут AUTO_INCREMENT в MySQL генерирует уникальные последовательные числа для столбца, обычно для первичного ключа таблицы.
Вот пример создания таблицы со столбцом AUTO_INCREMENT:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);И вставка строк в неё:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');Представление — это сохраненный запрос, который работает как виртуальная таблица. С его помощью можно оформить сложный запрос, дать ему имя и использовать как таблицу в будущих запросах. Так вам не придется каждый раз заново печатать весь запрос.
Например, чтобы упростить получение сведений о сотрудниках вместе с названиями отделов, можно создать представление:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;Теперь можно запрашивать представление employee_details как обычную таблицу:
SELECT * FROM employee_details;Однако при помощи представлений нельзя вставлять и обновлять данные. Большинство из них поддерживает режим только для чтения и ограничивает доступ пользователей к базе, повышая безопасность. Представления могут иногда замедлять запросы, так как при каждом обращении выполняется исходный запрос.
Узнайте больше о SQL с этими курсами!
Course
Course
Course