Courses
SQL 中的数据处理
4小时
324.1K
您是否注意到,几乎所有与数据库相关的岗位都要求会 MySQL?这是有充分理由的——从您常用的社交媒体平台到日常使用的应用程序,MySQL 几乎无处不在。
我整理了这份指南,帮助您攻克 MySQL 面试题。从初级开发者应掌握的基础,到高级岗位需要的复杂知识,我都会覆盖。此外,我还会分享一些技巧,帮助您在下一次与数据相关的面试中更自信地应对。
MySQL 是一种基于 SQL 的开源关系型数据库管理系统(RDBMS),将数据组织为结构化的表。它由 Oracle Corporation 开发。
它在 2024 年被评为最受欢迎的 DBMS。不过,2025 年的 Stack Overflow 开发者调查显示,PostgreSQL 在专业开发者中首次超越 MySQL,成为使用最广泛的数据库。
别误会:MySQL 依然非常流行——2025 年开发者使用率达 40.5%——并且仍在支撑无数网络应用、内容管理系统与企业工具。尤其是当您从事 Web 应用或 LAMP 技术栈相关工作时,MySQL 仍是一项顶级技能。
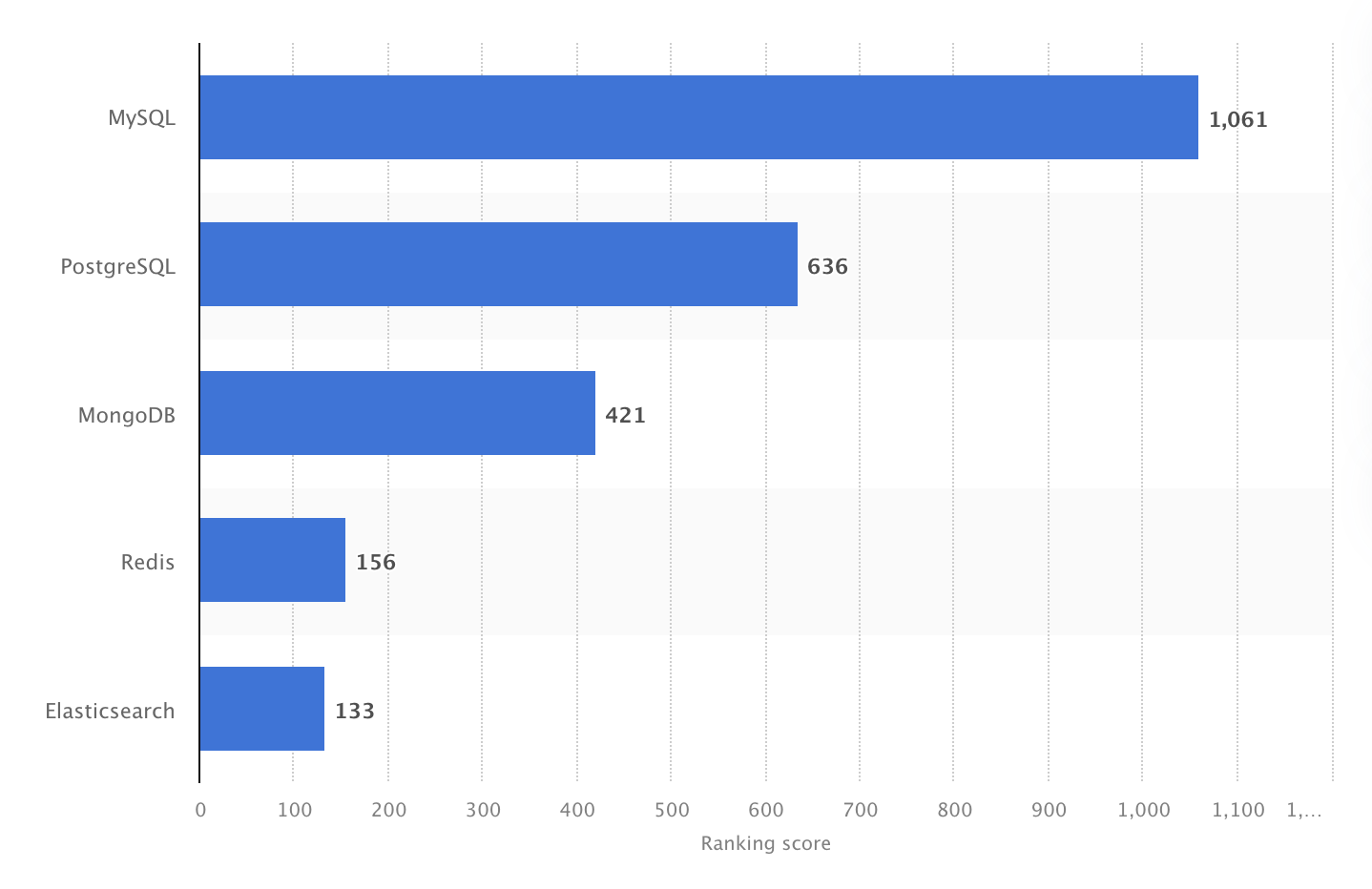
2024 年,MySQL 是全球最受欢迎的开源 DBMS,排名分数为 1061。来源:Statista。
在初轮面试中,面试官可能会通过一些基础问题来评估您对数据库与 MySQL 核心概念的理解。
数据库是一个用于存储数据的容器,我们可以对其进行访问、修改和分析。比如,社交媒体平台会在数据库中存储哪些用户点赞了我们的帖子等数据。
DBMS(数据库管理系统)是一种软件,使我们能够与这些数据交互与管理它们,例如创建用户并管理其访问权限。MySQL 是最受欢迎的 DBMS 之一。其他示例包括 PostgreSQL、MongoDB 和 Microsoft SQL Server。
MySQL 是一种开源的关系型数据库管理系统(RDBMS),使用 SQL 管理数据。它以易用性、速度快以及与 Web 应用的良好兼容性而闻名。
以下是 MySQL 与其他 RDBMS 的差异:
MySQL 适用于需要速度与可扩展性的场景;而若追求更复杂或企业级特性,PostgreSQL 可能更合适。
MySQL 支持多种数据类型,主要分为:
数值型: INT、DECIMAL、FLOAT、DOUBLE 等。
字符串型: CHAR、VARCHAR、TEXT、BLOB。
日期/时间: DATE、DATETIME、TIMESTAMP、TIME。
JSON: 用于存储 JSON 对象。
INT 存储不含小数点的整数,适用于不需要小数的场景。相反,DECIMAL 可存储金融金额,适合需要小数精度的计算。
MySQL 中的 DATE 以年、月、日的格式存储日期:
YYYY-MM-DD
而 DATETIME 会存储日期与时间,如下所示:
YYYY-MM-DD HH:MM:SS
外键是某个表中的字段,用于关联另一个表的主键。
例如,在存储客户信息的 customers 表中,每位客户都有唯一的 customer_id——在另一个名为 transactions 的表(用于存储购买记录)中,我们将 customer_id 作为外键。transactions 表中的 customer_id 会将每笔购买关联到 customers 表中的特定客户。
以下是 SQL 示例:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);连接用于基于相关列将两个或多个表的行组合。区别如下:
INNER JOIN: 返回两表中匹配的行。
LEFT JOIN: 返回左表的所有行以及右表中匹配的行;若无匹配,右表列返回 NULL。
RIGHT JOIN: 类似 LEFT JOIN,但返回右表所有行以及与之匹配的左表行。
FULL JOIN:合并 LEFT JOIN 和 RIGHT JOIN 的结果,包含两表中未匹配的行。注意:MySQL 原生不支持 FULL JOIN 语法。要实现相同效果,可将 LEFT JOIN 与 RIGHT JOIN 的结果使用 UNION 进行合并。
DELETE、TRUNCATE 和 DROP 看起来相似,但行为不同:
DELETE: 根据条件删除表中的行。若在事务中,可回滚。示例:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: 删除表中所有行,但保留表结构。它比 DELETE 更快,且不可回滚。示例:
TRUNCATE TABLE employees;DROP: 完全删除表结构及数据,并移除索引等依赖。示例:
DROP TABLE employees;创建表使用 CREATE TABLE 语句,修改通常用 ALTER TABLE。示例如下:
创建表:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));新增列:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);临时表仅在当前数据库会话中存在。会话关闭后,表即被删除。它可用于临时存储中间结果,适合测试、筛选或在插入永久表前准备数据。
示例如下:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;子查询(也称嵌套查询)是嵌套在另一条查询中的查询。它能将复杂操作拆分为更易管理的步骤。例如,您可以用子查询找出薪资高于平均值的员工:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);解析如下:
内部查询 SELECT AVG(salary) FROM employees 先计算平均薪资。
外部查询再据此找出薪资高于平均值的员工。
我们使用 INSERT 语句向表中添加数据。基本语法如下:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); 使用 INSERT 时的几条最佳实践:
显式列出列名。这样更清晰,也能在表结构变更时避免出错。
对于 AUTO_INCREMENT 列(如 ID),在 INSERT 语句中跳过它们。MySQL 会自动处理,避免重复 ID。
字符串引号风格保持一致。我个人偏好单引号,但两者皆可。
插入多行时,尽量在一条语句中完成以获得更好性能。
AUTO_INCREMENT 属性用于为列(通常是主键)自动生成唯一的、递增的数值。
下面是创建带 AUTO_INCREMENT 列的表:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);插入数据如下:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');视图是一个已保存的查询,像虚拟表一样工作。借助视图,我们可以将复杂查询命名保存,后续像表一样直接使用,避免每次都重复书写完整查询。
例如,为简化查询员工详情及其部门名称,可以创建如下视图:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;之后就可以像查询表一样使用 employee_details:
SELECT * FROM employee_details;不过,视图一般不用于插入或更新数据。大多数视图是只读的,并可限制用户直接访问底层数据,从而提升数据安全。需要注意的是,视图每次访问都会运行底层查询,可能会导致查询变慢。