course
Data Manipulation in SQL
4 घंटा
324.1K
क्या आपने गौर किया है कि डेटाबेस से जुड़ी लगभग हर जॉब डिस्क्रिप्शन में MySQL की मांग होती है? इसकी एक अच्छी वजह है — MySQL आपकी पसंदीदा सोशल मीडिया प्लेटफॉर्म से लेकर रोज़ाना इस्तेमाल होने वाले ऐप्स तक, लगभग हर चीज़ को पावर देता है।
मैंने यह गाइड MySQL इंटरव्यू प्रश्नों से निपटने में आपकी मदद के लिए तैयार किया है। इसमें मैं उन मूल बातों से लेकर उन्नत कॉन्सेप्ट तक कवर करूंगा, जो जूनियर डेवलपर्स से लेकर सीनियर रोल्स तक के लिए ज़रूरी हैं। साथ ही, मैं कुछ टिप्स भी साझा करूंगा ताकि आप अपने अगले डेटा-सम्बंधित इंटरव्यू में आत्मविश्वासी नज़र आएं।
MySQL एक ओपन-सोर्स RDBMS (रिलेशनल डेटाबेस मैनेजमेंट सिस्टम) है जो SQL पर आधारित है और डेटा को संरचित टेबलों में व्यवस्थित करता है। इसे Oracle Corporation ने विकसित किया है।
यह 2024 में सबसे लोकप्रिय DBMS के रूप में रैंक किया गया था। हालांकि, 2025 के Stack Overflow Developer सर्वे में पेशेवर डेवलपर्स के बीच PostgreSQL को सबसे अधिक उपयोग होने वाला डेटाबेस बताया गया, जिसने पहली बार MySQL को पीछे छोड़ा।
गलत मत समझिए: MySQL अब भी बेहद लोकप्रिय है — 2025 में डेवलपर्स के बीच 40.5% उपयोग तक पहुंचा — और अब भी असंख्य वेब एप्लीकेशंस, कंटेंट मैनेजमेंट सिस्टम, और एंटरप्राइज टूल्स को पावर देता है। और खासकर अगर आप वेब एप्लीकेशंस या LAMP स्टैक के साथ काम कर रहे हैं, तो MySQL एक शीर्ष-स्तरीय स्किल है।
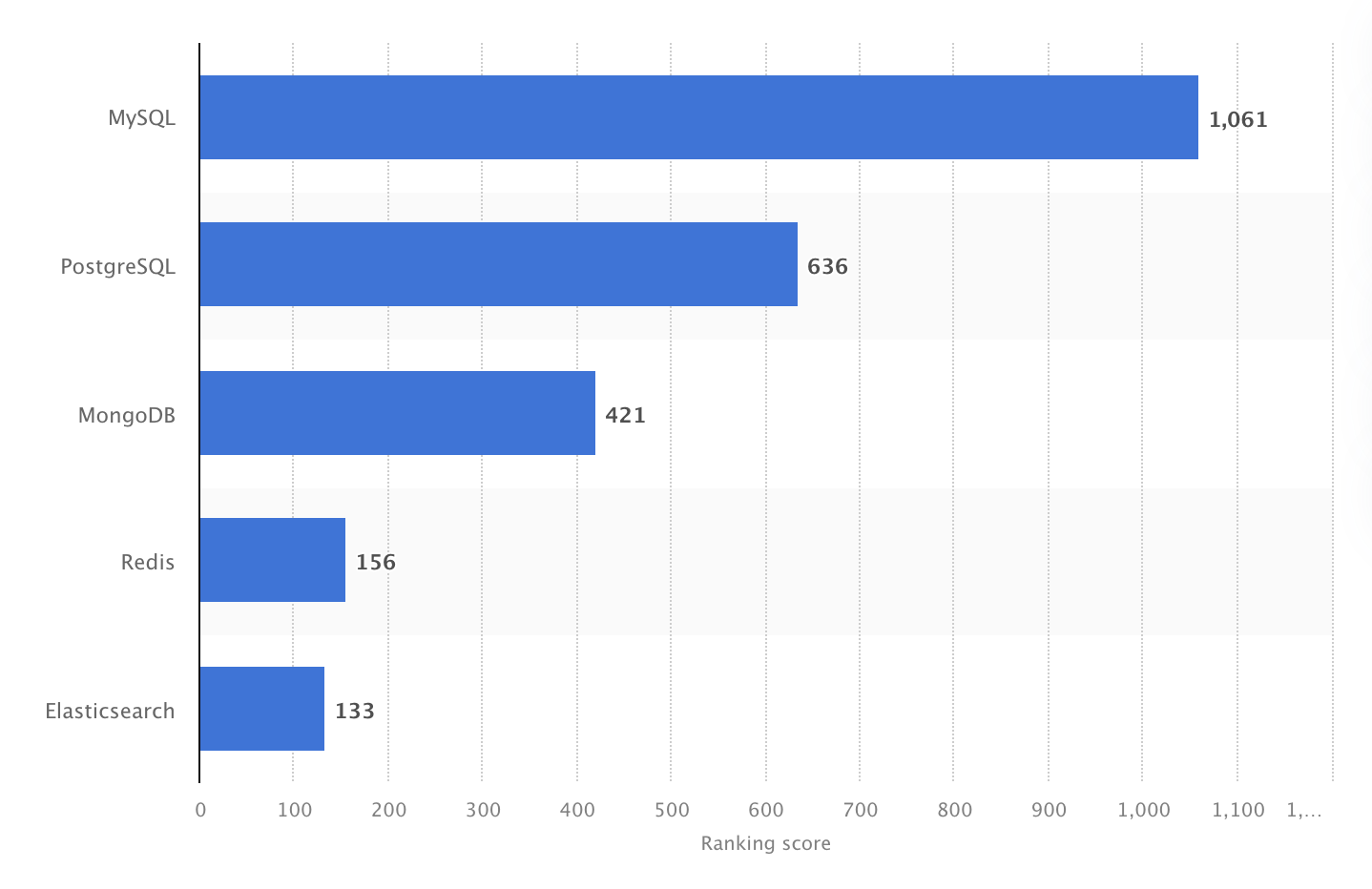
2024 में, MySQL दुनिया का सबसे लोकप्रिय ओपन-सोर्स DBMS था, जिसका रैंकिंग स्कोर 1061 था। स्रोत: Statista.
प्रारंभिक इंटरव्यू चरण में, इंटरव्यूअर आपके बुनियादी डेटाबेस और MySQL कॉन्सेप्ट्स की समझ का आकलन करने के लिए मूलभूत प्रश्न पूछ सकता है।
डेटाबेस एक स्टोरेज कंटेनर है जिसमें डेटा रखा जाता है, जिसे हम एक्सेस, संशोधित और विश्लेषित कर सकते हैं। उदाहरण के लिए, सोशल मीडिया प्लेटफॉर्म हमारे पोस्ट को किसने पसंद किया, इसका डेटा डेटाबेस में स्टोर करते हैं।
DBMS (Database Management System) एक सॉफ्टवेयर है जो हमें उस डेटा के साथ इंटरैक्ट करने और उसे मैनेज करने देता है—जैसे उपयोगकर्ता बनाना और उनकी एक्सेस प्रबंधित करना। MySQL सबसे लोकप्रिय DBMS विकल्पों में से एक है। अन्य उदाहरणों में PostgreSQL, MongoDB, और Microsoft SQL Server शामिल हैं।
MySQL एक ओपन-सोर्स रिलेशनल डेटाबेस मैनेजमेंट सिस्टम (RDBMS) है जो डेटा को प्रबंधित करने के लिए SQL का उपयोग करता है। यह उपयोग में सरलता, स्पीड, और वेब-आधारित एप्लीकेशंस के साथ अनुकूलता के लिए जाना जाता है।
यहां बताया गया है कि MySQL अन्य RDBMSs से कैसे अलग है:
MySQL उन स्थितियों के लिए आदर्श है जहां स्पीड और स्केलेबिलिटी की ज़रूरत होती है, लेकिन अधिक जटिल या एंटरप्राइज-ग्रेड सुविधाओं के लिए PostgreSQL बेहतर विकल्प हो सकता है।
MySQL विभिन्न डेटा टाइप्स को सपोर्ट करता है, जो इस प्रकार वर्गीकृत हैं:
Numeric: INT, DECIMAL, FLOAT, DOUBLE, आदि
String: CHAR, VARCHAR, TEXT, BLOB.
Date/time: DATE, DATETIME, TIMESTAMP, TIME.
JSON: JSON ऑब्जेक्ट्स स्टोर करने के लिए।
INT पूर्णांक (डेसिमल पॉइंट के बिना) स्टोर करता है। जब भिन्नांश की ज़रूरत नहीं हो, तब इसका उपयोग किया जा सकता है। इसके विपरीत, DECIMAL वित्तीय मानों को स्टोर कर सकता है और डेसिमल्स के साथ सटीक गणनाओं के लिए उपयुक्त है।
DATE MySQL में वर्ष, माह और दिन के फॉर्मेट में तारीख स्टोर करता है:
YYYY-MM-DD
जबकि DATETIME तारीख के साथ समय भी स्टोर करता है, और यह इस प्रकार दिखता है:
YYYY-MM-DD HH:MM:SS
फॉरेन की एक टेबल में वह फील्ड है जो किसी दूसरी टेबल की प्राइमरी की से जुड़ती है।
उदाहरण के लिए, एक customers टेबल में जो ग्राहक की जानकारी स्टोर करती है, प्रत्येक ग्राहक का एक यूनिक customer_id होता है—एक अन्य टेबल transactions (जो खरीद रिकॉर्ड स्टोर करती है) में, हम customer_id को फॉरेन की के रूप में उपयोग करते हैं। ट्रांज़ैक्शंस टेबल में customer_id प्रत्येक खरीद को customers टेबल के एक विशिष्ट ग्राहक से जोड़ता है।
SQL में यह इस तरह दिखता है:
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Joins सम्बंधित कॉलम के आधार पर दो या अधिक टेबल्स की पंक्तियों को जोड़ते हैं। इनके अंतर इस प्रकार हैं:
INNER JOIN: वहीं पंक्तियाँ लौटाता है जहां दोनों टेबल्स में मैच हो।
LEFT JOIN: बाएँ टेबल की सभी पंक्तियाँ और दाएँ टेबल से मैचिंग पंक्तियाँ लौटाता है। अगर मैच नहीं है, तो दाएँ टेबल के कॉलम्स के लिए NULL लौटता है।
RIGHT JOIN: LEFT JOIN जैसा ही, लेकिन दाएँ टेबल की सभी पंक्तियाँ और बाएँ से मैचिंग पंक्तियाँ लौटाता है।
FULL JOIN: LEFT JOIN और RIGHT JOIN के परिणामों को मिलाकर दोनों टेबल्स की अनमैच्ड पंक्तियाँ भी शामिल करता है। नोट: MySQL मूल रूप से FULL JOIN सिंटैक्स को सपोर्ट नहीं करता। समान परिणाम पाने के लिए LEFT JOIN और RIGHT JOIN के UNION का उपयोग करें।
DELETE, TRUNCATE, और DROP जैसे कमांड सुनने में एक जैसे लगते हैं, लेकिन इनका व्यवहार अलग होता है:
DELETE: शर्त के आधार पर टेबल से पंक्तियाँ हटाता है। यदि ट्रांज़ैक्शन के अंदर हो, तो रोल बैक किया जा सकता है। उदाहरण:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: टेबल की सभी पंक्तियाँ हटाता है, लेकिन टेबल स्ट्रक्चर बना रहता है। यह DELETE से तेज है और रोल बैक नहीं किया जा सकता। उदाहरण:
TRUNCATE TABLE employees;DROP: टेबल के स्ट्रक्चर और डेटा को पूरी तरह हटाता है, साथ ही इंडेक्स जैसी निर्भरताएँ भी हट जाती हैं। उदाहरण:
DROP TABLE employees;टेबल बनाने के लिए आप CREATE TABLE स्टेटमेंट का उपयोग कर सकते हैं, और संशोधन के लिए आमतौर पर ALTER TABLE का। यहां कुछ उदाहरण हैं:
टेबल बनाएं:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));कॉलम जोड़ने के लिए संशोधित करें:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);टेम्परेरी टेबल केवल वर्तमान डेटाबेस सेशन के दौरान मौजूद रहती है। सेशन बंद होते ही टेबल डिलीट हो जाती है। इस प्रकार की टेबल अस्थायी रूप से मध्यवर्ती परिणामों को स्टोर कर सकती है। इसे टेस्टिंग, फ़िल्टरिंग, या स्थायी टेबल में डालने से पहले डेटा तैयार करने के लिए उपयोग किया जा सकता है।
यहां एक उदाहरण है:
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;सबक्वेरी (जिसे नेस्टेड क्वेरी भी कहते हैं) किसी दूसरी क्वेरी के अंदर लिखी जाती है। यह जटिल डेटाबेस ऑपरेशंस को अधिक प्रबंधनीय चरणों में तोड़ देती है। उदाहरण के लिए, आप औसत वेतन से अधिक कमाने वाले कर्मचारियों को ढूंढने के लिए सबक्वेरी बना सकते हैं:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);आइए इसे समझते हैं:
भीतरी क्वेरी SELECT AVG(salary) FROM employees पहले औसत वेतन निकालती है।
बाहरी क्वेरी फिर इस औसत का उपयोग करके ऐसे कर्मचारियों को ढूंढती है जो इससे अधिक कमाते हैं।
हम INSERT स्टेटमेंट का उपयोग टेबल में डेटा जोड़ने के लिए कर सकते हैं। बेसिक सिंटैक्स है:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); INSERT स्टेटमेंट इस्तेमाल करते समय इन सर्वोत्तम अभ्यासों का पालन करें
कॉलम्स को स्पष्ट रूप से लिस्ट करें। इससे कोड स्पष्ट रहता है और बाद में टेबल स्ट्रक्चर बदलने पर त्रुटियाँ कम होती हैं।
AUTO_INCREMENT कॉलम्स जैसे IDs को INSERT में स्किप करें। MySQL इन्हें ऑटोमैटिक संभालता है ताकि डुप्लिकेट IDs न बनें।
स्ट्रिंग कोट्स का उपयोग सुसंगत रखें। मैं व्यक्तिगत रूप से सिंगल कोट्स पसंद करता/करती हूँ, लेकिन दोनों काम करते हैं।
यदि आप कई पंक्तियाँ जोड़ रहे हैं, तो बेहतर परफॉर्मेंस के लिए एक ही स्टेटमेंट में करें।
MySQL में AUTO_INCREMENT ऐट्रिब्यूट किसी कॉलम के लिए यूनिक, क्रमिक नंबर जनरेट करता है, आमतौर पर टेबल की प्राइमरी की के रूप में।
यहाँ AUTO_INCREMENT कॉलम के साथ टेबल बनाने का उदाहरण है:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);और इसमें पंक्तियाँ डालने का तरीका:
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');व्यू एक सेव्ड क्वेरी होती है जो वर्चुअल टेबल की तरह काम करती है। इसके जरिए हम किसी जटिल क्वेरी को नाम देकर सेव कर सकते हैं और भविष्य की क्वेरियों में टेबल की तरह उपयोग कर सकते हैं। इस तरह आपको हर बार पूरी क्वेरी फिर से टाइप नहीं करनी पड़ती।
उदाहरण के लिए, कर्मचारियों के विवरण को उनके विभाग नामों के साथ सरलता से क्वेरी करने के लिए आप एक व्यू बना सकते हैं:
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;अब आप employee_details व्यू को टेबल की तरह क्वेरी कर सकते हैं:
SELECT * FROM employee_details;हालांकि, हम व्यूज़ का उपयोग डेटा को इन्सर्ट और अपडेट करने के लिए नहीं कर सकते। अधिकांश व्यूज़ रीड-ओनली होते हैं और यूज़र्स की सीधे डेटाबेस तक पहुँच को सीमित करते हैं, जिससे डेटा सुरक्षा बढ़ती है। कभी-कभी व्यूज़ क्वेरियों को धीमा भी कर सकते हैं, क्योंकि हर बार एक्सेस होने पर वे अंतर्निहित क्वेरी चलाते हैं।
इन कोर्सेज़ के साथ SQL के बारे में और जानें!
course
course
course