courses
SQL에서의 데이터 조작
4
324.2K
거의 모든 데이터베이스 관련 채용 공고에 MySQL이 포함되어 있다는 점, 눈치채셨나요? 그럴 만한 이유가 있습니다 — MySQL은 우리가 매일 사용하는 앱부터 즐겨 쓰는 소셜 미디어 플랫폼까지 사실상 대부분을 구동합니다.
이 가이드는 MySQL 면접 질문을 효과적으로 준비할 수 있도록 구성했습니다. 주니어 개발자가 알아야 할 기초부터 시니어 직무에 필요한 심화 주제까지 모두 다룹니다. 또한 다음 데이터 관련 면접에서 자신감 있게 임할 수 있도록 몇 가지 팁도 함께 공유합니다.
MySQL은 SQL 위에 구축된 오픈 소스 RDBMS(관계형 데이터베이스 관리 시스템)로, 데이터를 구조화된 테이블에 저장하고 관리합니다. Oracle Corporation에서 개발했습니다.
2024년에 가장 인기 있는 DBMS로 선정되었습니다. 다만, 2025년 Stack Overflow 개발자 설문에서는 PostgreSQL이 전문 개발자 사이에서 가장 널리 사용되는 데이터베이스로 처음으로 MySQL을 앞질렀습니다.
그렇다고 해서 오해하진 마세요. MySQL은 여전히 엄청나게 널리 쓰이며 — 2025년 개발자 사용률 40.5%에 달했고 — 수많은 웹 애플리케이션, 콘텐츠 관리 시스템, 엔터프라이즈 도구의 핵심입니다. 특히 웹 애플리케이션이나 LAMP 스택을 다룬다면 MySQL은 최고의 핵심 역량입니다.
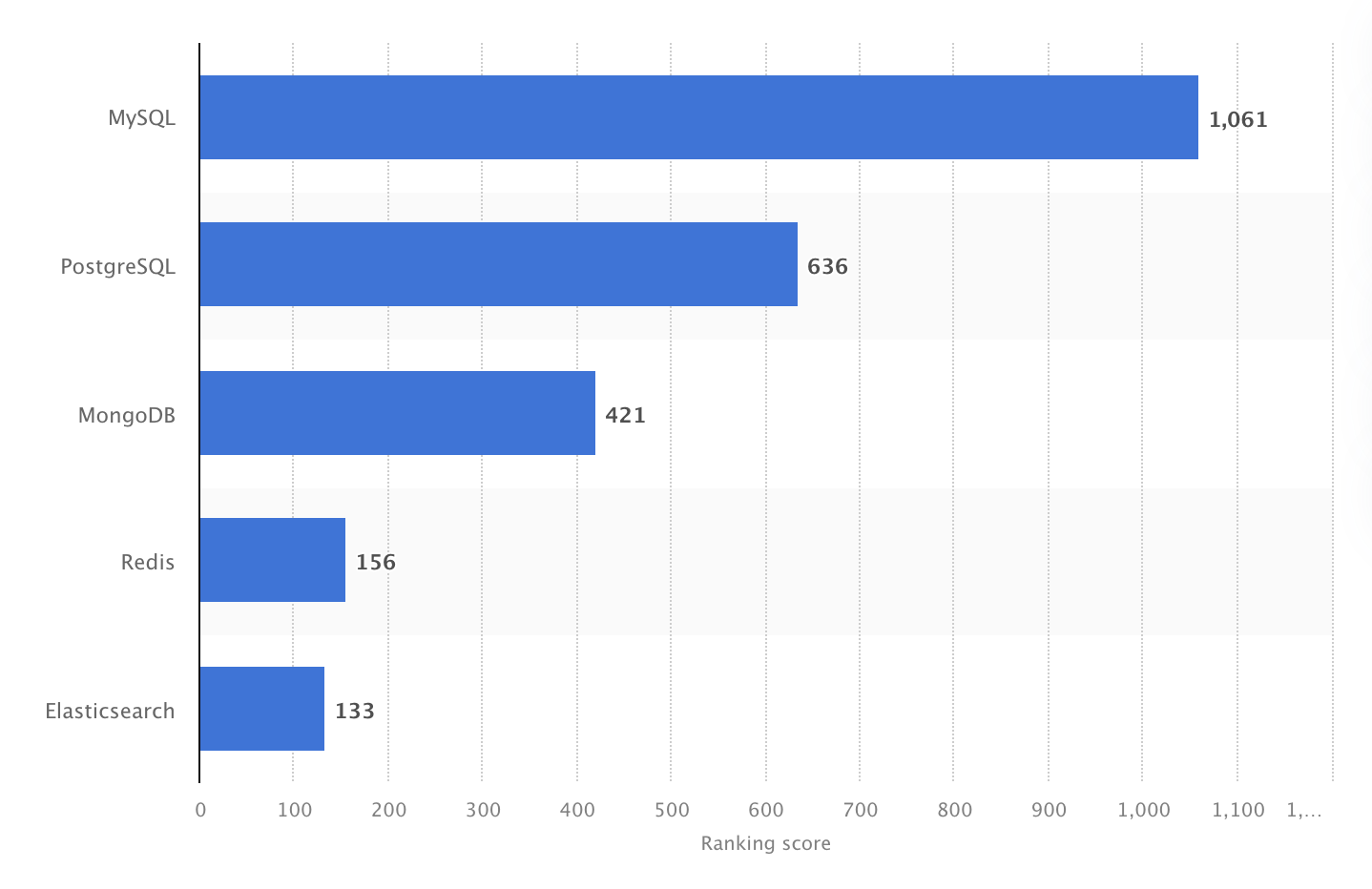
2024년, MySQL은 전 세계에서 가장 인기 있는 오픈 소스 DBMS로, 순위 점수 1061을 기록했습니다. 출처: Statista.
초기 면접 단계에서는 기본적인 데이터베이스 및 MySQL 개념에 대한 이해를 평가하기 위한 질문이 나올 수 있습니다.
데이터베이스는 데이터를 저장해 두고 접근, 수정, 분석할 수 있는 저장소입니다. 예를 들어 소셜 미디어 플랫폼은 누가 우리 게시글에 좋아요를 눌렀는지에 대한 데이터를 데이터베이스에 저장합니다.
DBMS(Database Management System)는 사용자 생성과 접근 제어 등으로 해당 데이터를 관리하고 상호작용하게 해 주는 소프트웨어입니다. MySQL은 가장 인기 있는 DBMS 중 하나입니다. 다른 예로는 PostgreSQL, MongoDB, Microsoft SQL Server가 있습니다.
MySQL은 SQL을 사용해 데이터를 관리하는 오픈 소스 관계형 데이터베이스 관리 시스템(RDBMS)입니다. 사용이 쉽고 빠르며 웹 기반 애플리케이션과의 호환성이 뛰어난 것으로 알려져 있습니다.
MySQL이 다른 RDBMS와 다른 점은 다음과 같습니다.
MySQL은 속도와 확장성이 중요한 시나리오에 적합하며, 보다 복잡하거나 엔터프라이즈급 기능이 필요하다면 PostgreSQL이 더 나은 선택일 수 있습니다.
MySQL은 다음과 같이 분류되는 다양한 데이터 타입을 지원합니다.
숫자형: INT, DECIMAL, FLOAT, DOUBLE 등
문자열: CHAR, VARCHAR, TEXT, BLOB
날짜/시간: DATE, DATETIME, TIMESTAMP, TIME
JSON: JSON 객체 저장용
INT는 소수점이 없는 정수를 저장합니다. 분수가 필요 없을 때 사용합니다. 반대로 DECIMAL은 금액처럼 소수점 이하가 필요한 값을 정밀하게 저장하는 데 적합합니다.
DATE는 연, 월, 일 형식으로 날짜를 저장합니다:
YYYY-MM-DD
반면 DATETIME은 날짜와 시간을 함께 저장하며, 형식은 다음과 같습니다:
YYYY-MM-DD HH:MM:SS
외래 키는 한 테이블의 필드로서, 다른 테이블의 기본 키와 연결됩니다.
예를 들어 고객 정보를 저장하는 customers 테이블에서 각 고객은 고유한 customer_id를 가집니다. 구매 내역을 저장하는 transactions 테이블에서는 customer_id를 외래 키로 사용합니다. 즉, transactions 테이블의 customer_id는 각 구매를 customers 테이블의 특정 고객과 연결합니다.
SQL 예시는 다음과 같습니다.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);조인은 관련 있는 컬럼을 기준으로 두 개 이상의 테이블에서 행을 결합합니다. 차이는 다음과 같습니다.
INNER JOIN: 두 테이블 모두에서 일치하는 행만 반환합니다.
LEFT JOIN: 왼쪽 테이블의 모든 행과 오른쪽 테이블에서 일치하는 행을 반환합니다. 일치하지 않으면 오른쪽 테이블 컬럼은 NULL이 됩니다.
RIGHT JOIN: LEFT JOIN과 유사하게, 오른쪽 테이블의 모든 행과 왼쪽 테이블에서 일치하는 행을 반환합니다.
FULL JOIN: LEFT JOIN과 RIGHT JOIN의 결과를 합쳐 두 테이블의 불일치 행까지 포함합니다. 참고: MySQL은 FULL JOIN 문법을 기본 지원하지 않습니다. 동일한 결과가 필요하면 LEFT JOIN과 RIGHT JOIN을 UNION으로 결합하세요.
DELETE, TRUNCATE, DROP은 비슷하게 들리지만 동작은 다릅니다.
DELETE: 조건에 따라 테이블의 행을 삭제합니다. 트랜잭션 내에서는 롤백할 수 있습니다. 예:
DELETE FROM employees WHERE department_id = 5;TRUNCATE: 테이블의 모든 행을 삭제하지만 테이블 구조는 남깁니다. DELETE보다 빠르며 롤백할 수 없습니다. 예:
TRUNCATE TABLE employees;DROP: 테이블 구조와 데이터를 완전히 제거하며, 인덱스 같은 의존 객체도 함께 삭제합니다. 예:
DROP TABLE employees;테이블 생성에는 CREATE TABLE 문을, 수정에는 주로 ALTER TABLE을 사용합니다. 예시는 다음과 같습니다.
테이블 생성:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50));컬럼 추가 수정:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);임시 테이블은 현재 데이터베이스 세션 동안만 존재합니다. 세션이 종료되면 테이블이 삭제됩니다. 중간 결과를 임시로 저장하는 데 유용하며, 테스트, 필터링, 영구 테이블로 삽입하기 전 데이터 준비에 사용할 수 있습니다.
예시는 다음과 같습니다.
CREATE TEMPORARY TABLE temp_employees (
id INT,
name VARCHAR(50)
);
INSERT INTO temp_employees VALUES (1, 'John Doe');
SELECT * FROM temp_employees;서브쿼리(중첩 쿼리)는 다른 쿼리 내부에 포함된 쿼리입니다. 복잡한 작업을 더 작은 단계로 나누는 데 도움이 됩니다. 예를 들어 평균 급여보다 더 받는 직원을 찾는 서브쿼리는 다음과 같습니다.
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);설명을 덧붙이면:
내부 쿼리 SELECT AVG(salary) FROM employees가 먼저 평균 급여를 계산합니다.
외부 쿼리는 이 평균을 이용해 그보다 더 받는 직원을 찾습니다.
INSERT 문으로 테이블에 데이터를 추가할 수 있습니다. 기본 문법은 다음과 같습니다.
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); 다음은 INSERT 문 사용 시 권장 사항입니다.
컬럼을 명시적으로 나열하세요. 코드 가독성이 좋아지고, 테이블 구조가 바뀌어도 오류를 줄일 수 있습니다.
AUTO_INCREMENT 컬럼(예: ID)은 INSERT에서 생략하세요. MySQL이 자동으로 처리해 중복 ID를 방지합니다.
문자열 따옴표는 일관되게 사용하세요. 필자는 홑따옴표를 선호하지만 어느 쪽도 가능합니다.
여러 행을 삽입할 때는 단일 문으로 묶는 것이 성능에 유리합니다.
AUTO_INCREMENT는 보통 테이블의 기본 키 컬럼에 대해 고유하고 연속적인 숫자를 자동 생성합니다.
다음은 AUTO_INCREMENT 컬럼이 있는 테이블 생성 예시입니다.
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50)
);행 삽입은 다음과 같습니다.
INSERT INTO employees (name, department) VALUES ('John Doe', 'Sales');
INSERT INTO employees (name, department) VALUES ('Jane Smith', 'Marketing');뷰는 저장된 쿼리로, 가상 테이블처럼 동작합니다. 복잡한 쿼리에 이름을 부여해 이후 테이블처럼 재사용할 수 있어, 매번 전체 쿼리를 다시 작성할 필요가 없습니다.
예를 들어 직원 정보와 부서명을 함께 조회하는 작업을 단순화하려면 다음과 같이 뷰를 생성할 수 있습니다.
CREATE VIEW employee_details AS
SELECT
e.id,
e.name,
d.department_name,
e.salary
FROM
employees e
JOIN
departments d ON e.department_id = d.department_id;이제 employee_details 뷰를 테이블처럼 조회할 수 있습니다.
SELECT * FROM employee_details;다만, 뷰를 통해 삽입이나 업데이트를 수행할 수 없는 경우가 많습니다. 대부분 읽기 전용을 지원하여 사용자의 직접적인 데이터베이스 접근을 제한하고 보안을 강화합니다. 또한 뷰는 접근할 때마다 기반 쿼리를 실행하므로, 경우에 따라 쿼리가 느려질 수 있습니다.
이 강의로 SQL을 더 깊이 배워 보세요!
courses
courses
courses