
Program
Yardımcı Veri Mühendisi SQL içinde
30 sa
Veri mühendisliği son derece tekniktir; bu yüzden mülakat sürecinizin büyük kısmının teknik sorular ve alıştırmalar içermesi şaşırtıcı değildir. Bu bölümde, başlangıç seviyesinden Python, SQL, proje tabanlı ve yönetim sorularına odaklanarak farklı teknik soru türlerini ve cevaplarını ele alacağız.
Junior mühendis mülakatları araçlar, Python ve SQL sorgularına odaklanır. Ayrıca veritabanı yönetimi ve ETL süreçleri hakkında sorular, kodlama sınavları ve ev ödevi testleri içerebilir.
Şirketler yeni mezunları işe alırken, verilerini ve sistemlerini etkili şekilde yönetebileceğinizden emin olmak ister.
Üç temel veri modelleme tasarım şeması vardır: yıldız, kar tanesi ve galaksi.
Yıldız şeması örneği. Görsel: guru99
Kar tanesi şeması örneği. Görsel: guru99
Galaksi şeması örneği. Görsel: guru99
Bu soruyu yanıtlarken, hâkim olduğunuz ETL araçlarını belirtin ve belirli projeler için neden bu araçları seçtiğinizi açıklayın. Her aracın artılarını ve eksilerini ve iş akışınıza nasıl uyduğunu tartışın. Popüler açık kaynaklı araçlar şunlardır:
ETL bilginizi tazelemeniz gerekiyorsa, Introduction to Data Engineering kursunu düşünün.
Veri orkestrasyonu; birden çok kaynaktan ham veriye erişme, veri temizleme, dönüşüm ve modelleme tekniklerini uygulama ve analitik görevler için sunma süreçlerini otomatikleştiren bir işlemdir. Verinin farklı sistemler ve işleme aşamaları arasında sorunsuz akmasını sağlar.
Veri orkestrasyonu için popüler araçlar şunlardır:
Analitik mühendisliği, işlenmiş verileri dönüştürmeyi, istatistiksel modeller uygulamayı ve raporlar ile panolar üzerinden görselleştirmeyi içerir.
Analitik mühendisliği için popüler araçlar şunlardır:
Bu araçlar, anlamlı içgörüler çıkarmak ve karar alma süreçlerini desteklemek için veriye erişmeye, dönüştürmeye ve görselleştirmeye yardımcı olur.
OLAP (Online Analytical Processing) geçmiş verileri analiz eder ve karmaşık sorguları destekler. Okuma ağırlıklı iş yükleri için optimize edilmiştir ve sıklıkla iş zekâsı görevleri için veri ambarlarında kullanılır. OLTP (Online Transaction Processing) gerçek zamanlı işlemsel veriyi yönetmek için tasarlanmıştır. Yazma ağırlıklı iş yükleri için optimize edilmiştir ve günlük operasyonlar için operasyonel veritabanlarında kullanılır.
Ana fark amaçlarındadır: OLAP karar almayı desteklerken, OLTP günlük operasyonları destekler.
Hâlâ tereddütünüz varsa, OLTP vs OLAP blog yazısını okumanızı öneririm.
Python, çok yönlülüğü ve veri işleme, analiz ve otomasyona yönelik zengin kütüphane ekosistemi nedeniyle veri mühendisliğinde en popüler dildir. İşte veri mühendisliği mülakatında karşılaşabileceğiniz bazı Python odaklı sorular.
Python’daki en popüler veri işleme kütüphaneleri şunlardır:
Bu kütüphanelerin her birinin artıları ve eksileri vardır; seçim, belirli veri gereksinimlerine ve işleme ölçeğine bağlıdır.
Python’da web scraping genellikle şu adımları içerir:
1. requests kütüphanesini kullanarak web sayfasına erişin:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. BeautifulSoup kullanarak tabloları ve bilgileri çıkarın:
tables = soup.find_all('table')3. Bunu pandas kullanarak yapılandırılmış bir formata dönüştürün:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Verileri pandas ve NumPy ile temizleyin:
df.dropna(inplace=True) # Drop missing values5. Verileri CSV dosyası olarak kaydedin:
df.to_csv('scraped_data.csv', index=False)Bazı durumlarda pandas.read_html süreci basitleştirebilir:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneBelleğe sığmayan büyük veri kümelerini yönetmek, bellek dışı hesaplama için tasarlanmış araç ve teknikleri kullanmayı gerektirir:
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionPython kodunun verimli ve performans için optimize edilmiş olmasını sağlamak için şu uygulamaları dikkate alın:
cProfile, line_profiler veya memory_profiler gibi araçları kullanın.import cProfile
cProfile.run('your_function()')numpy veya pandas ile vektörleştirilmiş işlemler kullanın.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultGüvenilir veri mühendisliği için veri bütünlüğü ve kalitesi önemlidir. En iyi uygulamalar şunları içerir:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas gibi kütüphaneleri kullanarak verileri temizleyin ve ön işleme tabi tutun. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest gibi çerçevelerle veri işleme fonksiyonları için birim testleri geliştirin.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Eksik verileri ele almak veri mühendisliğinde yaygın bir görevdir. Yaklaşımlar şunlardır:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)API hız sınırlarını yönetmek için şu stratejiler kullanılabilir:
Python’un time kütüphanesi ve requests modülünü kullanarak örnek:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python, veri mühendisliğinde tartışmasız en önemli dillerden biridir. Modern veri mühendisliği kavramları, programlama dilleri, araçlar ve çerçeveleri kapsayan kapsamlı bir müfredat sunan Data Engineer in Python yolumuz ile becerilerinizi geliştirebilirsiniz.
SQL kodlama aşaması, veri mühendisliği işe alım sürecinin önemli bir parçasıdır. Çeşitli basit ve karmaşık betikleri pratik etmek hazırlık açısından yardımcı olur. Görüşmeciler veri analitiği, ortak tablo ifadeleri, sıralama, ara toplam ekleme ve geçici fonksiyonlar için sorgular yazmanızı isteyebilir.
CTE’ler, karmaşık join’leri basitleştirmek ve alt sorguları çalıştırmak için kullanılır. SQL sorgularını daha okunabilir ve sürdürülebilir hale getirirler. İşte Fen (Science) bölümlü ve A notuna sahip tüm öğrencileri gösteren bir CTE örneği:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);CTE kullanıldığında sorgu şu hale gelir:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);CTE’ler daha karmaşık problemler için kullanılabilir ve birden fazla CTE birbirine zincirlenebilir.
Veri mühendisleri genellikle satış ve kâr gibi parametrelere göre değerleri sıralar. Belirli bir sütuna göre sıralamak için RANK() fonksiyonu kullanılır:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Alternatif olarak, aynı değerlere sahip sıralarda atlama yapmayan DENSE_RANK() kullanabilirsiniz.
Python’da olduğu gibi, SQL’de de sorgularınızı daha zarif kılmak ve tekrarlı case ifadelerinden kaçınmak için fonksiyonlar oluşturabilirsiniz. İşte get_gender adlı geçici bir fonksiyon örneği:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Bu yaklaşım SQL kodunuzu daha temiz ve sürdürülebilir hale getirir.
GROUP BY ve ROLLUP() fonksiyonlarını kullanarak ara toplamlar eklenebilir. İşte bir örnek:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Bu sorgu, her departman için bir ara toplam ve sonunda genel toplam verecektir.
Veri bütünlüğünü korumak için eksik verileri ele almak esastır. Yaygın yaklaşımlar şunlardır:
COALESCE() kullanımı: Bu fonksiyon listedeki ilk null olmayan değeri döndürür.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE ifadeleri kullanımı: Eksik değerleri koşullu olarak ele almak için. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;Veri toplulaştırma, SUM(), AVG(), COUNT(), MIN() ve MAX() gibi toplama fonksiyonlarını kullanmayı içerir. İşte bir örnek:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Daha iyi performans için SQL sorgularını şu şekilde optimize edebilirsiniz:
SELECT * yerine yalnızca gerekli sütunları belirtin.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;SQL kodlama alıştırmalarını çözmek, pratik yapmak ve unutulan kavramları gözden geçirmek için en iyi yoldur. DataCamp’in SQL ile Veri Analizi testini yaparak SQL becerilerinizi ölçebilirsiniz (bu değerlendirmeye erişmek için bir hesaba ihtiyacınız olacak).
Genel mülakat turlarından sonra genellikle kodlama zorlukları, problem çözme, beyaz tahtada veritabanı sistemi tasarımı, ev ödevi sınavı ve analitik sorulardan oluşan teknik bir aşamaya ilerlersiniz.
Bu aşama oldukça yoğun olabilir; bu nedenle yaygın veri mühendisliği mülakat soruları ve cevaplarını bilmek mülakatta başarılı olmanıza yardımcı olabilir.
Öğrenci ya da profesyonel olarak daha önce bir veri mühendisliği projesinde çalıştıysanız bu yanıt doğal gelecektir. Yine de önceden hazırlık yapmak her zaman faydalıdır. Yanıtınızı şu şekilde yapılandırın:
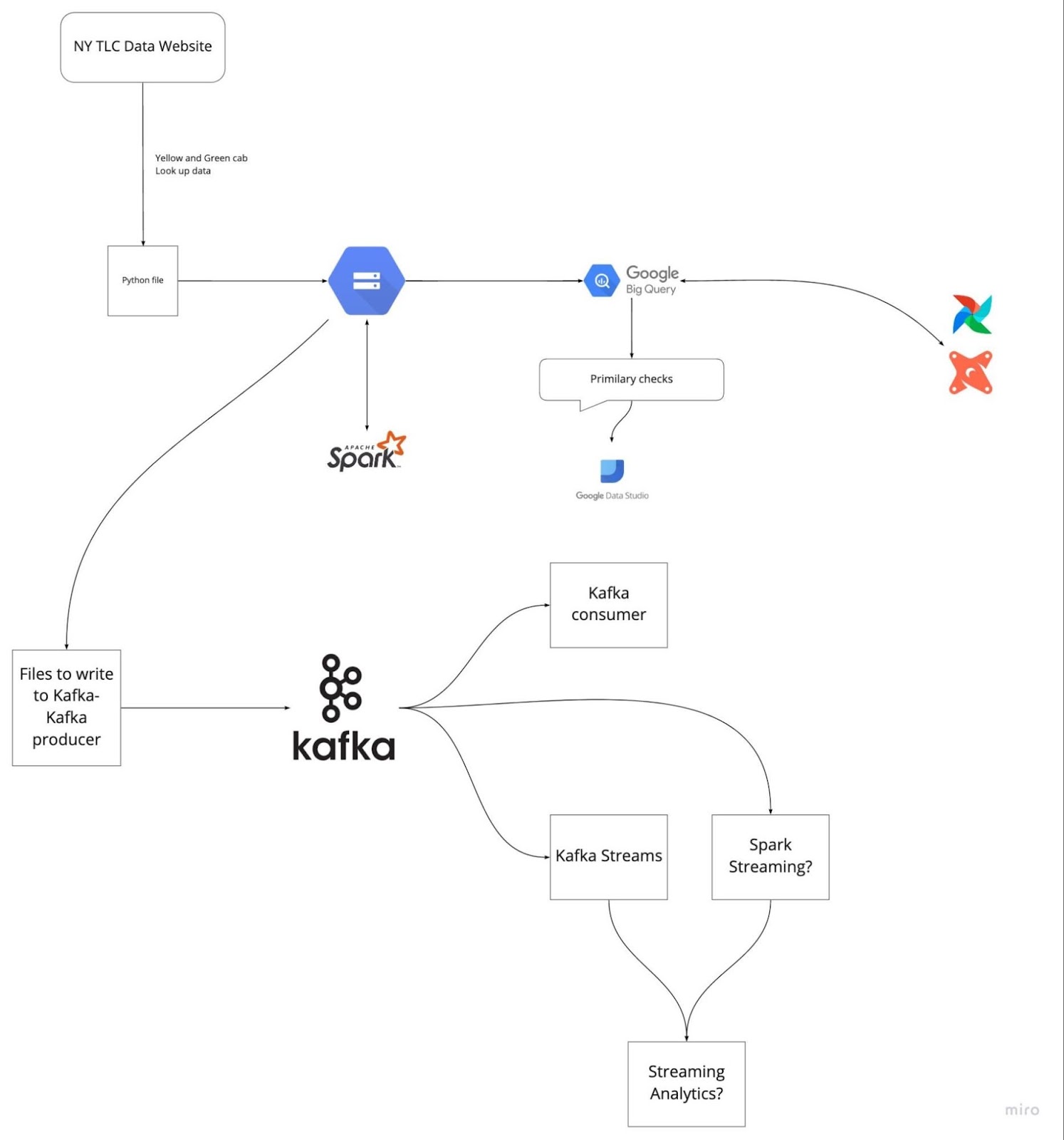
Görsel: DataTalksClub/data-engineering-zoomcamp
Son beş projenizi gözden geçirerek önceden hazırlık yapmak, mülakatta kilitlenmenizi önlemeye yardımcı olabilir. Problem ifadesini ve uyguladığınız çözümleri netleştirin. Her adımı açık ve öz bir şekilde anlatmayı pratiğe dökün.
Mühendislik yönetici pozisyonlarında sorular genellikle karar alma, iş anlayışı, veri kümelerinin kürasyonu ve bakımı, uyumluluk ve güvenlik politikalarıyla ilgilidir.
Bir veri ambarı, veri analitiği görevleri ve karar alma için geçmiş verileri sunar. Online Analytical Processing (OLAP) gibi yüksek hacimli analitik işlemleri destekler. Veri ambarları, birden fazla satıra erişen karmaşık sorguları işlemek üzere tasarlanmıştır ve okuma ağırlıklı işlemler için optimize edilmiştir. Az sayıda eşzamanlı kullanıcıyı destekler ve veriyi hızlı ve yüksek hacimde verimli şekilde getirmek üzere tasarlanmıştır.
Operasyonel Veritabanı Yönetim Sistemleri (OLTP) dinamik veri kümelerini gerçek zamanlı yönetir. Binlerce eşzamanlı istemci için yüksek hacimli işlem işlemesini destekleyerek günlük operasyonlar için uygundur. Veriler genellikle iş işlemleri ve operasyonlarla ilgili güncel, anlık bilgiden oluşur. OLTP sistemleri yazma ağırlıklı işlemler ve hızlı sorgu işleme için optimize edilmiştir.
Felaket yönetimi, bir veri mühendisliği yöneticisinin sorumluluğudur. Bir felaket kurtarma planı; siber saldırı, donanım arızası, doğal afet veya diğer yıkıcı olaylar durumunda veri sistemlerinin geri yüklenmesini ve çalışmaya devam etmesini sağlar. İlgili unsurlar şunlardır:
Bir veri mühendisliği yöneticisi olarak karar alma, teknik hususları iş hedefleriyle dengelemeyi içerir. Bazı yaklaşımlar şunlardır:
Veri koruma düzenlemelerine uyum, örneğin şu uygulamaları içerir:
Zorlu bir projeyi tartışırken aşağıdaki unsurlara odaklanabilirsiniz:
Yeni veri teknolojilerini değerlendirmek ve uygulamak şunları içerir:
Görevleri önceliklendirmek için etkilerini iş hedeflerine ve aciliyetlerine göre değerlendirmek etkilidir. Görevleri dört bölüme ayırmak için Eisenhower Matrisi gibi çerçeveler kullanabilirsiniz: acil ve önemli, önemli ama acil değil, acil ama önemli değil ve ikisi de değil. Ayrıca, paydaşlarla iletişim kurarak öncelikleri hizalayın ve ekibin yüksek değerli faaliyetlere odaklanmasını sağlayın.
Bu bölümde, Facebook, Amazon ve Google yöneticilerinin veri mühendisliği pozisyonları için en sık sorduğu veri mühendisliği mülakat sorularını inceliyoruz.
Bir Kafka kümesi, veriyi birden fazla örneğe dağıtan birden çok broker’dan oluşur. Bu mimari, kesinti olmaksızın ölçeklenebilirlik ve hata toleransı sağlar. Birincil küme devre dışı kalırsa diğer Kafka kümeleri aynı hizmetleri sunabilir ve yüksek erişilebilirlik sağlanır.
Kafka küme mimarisi Topics, Brokers, ZooKeeper, Producers ve Consumers bileşenlerinden oluşur. Büyük veri uygulamaları için veri akışlarını verimli şekilde yönetir ve sağlam, veriye dayalı uygulamalar oluşturmaya olanak tanır.
Apache Airflow, analitik iş akışları, veri ambarı yönetimi ile veri dönüşüm ve modelleme için hatları yönetmenizi ve zamanlamanızı sağlar. Şunları sunar:
Bir IP adresinin geçerliliğini belirlemek için diziyi “.” üzerinden bölüp her parçayı doğrulamak için çeşitli kontroller oluşturabilirsiniz. Bunu gerçekleştiren bir Python fonksiyonu şöyledir:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop temel olarak üç modda çalışır:
SQL’de yinelenenleri ele almak için DISTINCT anahtar sözcüğünü kullanabilir veya ROWID ile MAX ya da MIN fonksiyonlarını kullanarak yinelenen satırları silebilirsiniz. İşte örnekler:
DISTINCT kullanımı:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;ROWID kullanarak yinelenenleri silme:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Bu yaygın kodlama sorunu matematiksel bir yaklaşımla çözülebilir:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Bir mülakata girmeden önce, veri mühendisliğinde kullanılan tüm kavramları ve standart terimleri gözden geçirmelisiniz. Odaklanmanız gereken en önemli alanlardan bazıları şunlardır:
Bir veri mühendisliği mülakatına hazırlanmak zorlayıcı olabilir; ancak doğru kaynaklar ve pratikle başarılı olabilir ve hayalinizdeki işe ulaşabilirsiniz. Becerilerinizi ve bilginizi daha da geliştirmek için şu değerli kaynaklara göz atın:
Bu kurslardan yararlanarak temelinizi sağlamlaştırın ve veri mühendisliği kariyerinizde öne geçin. Mülakatlarınızda bol şans!
Bu kurslarla veri mühendisliği hakkında daha fazlasını öğrenin!
Program
Program
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
