Introduction
Data is everywhere. In recent years, with the growing number of connected devices and the expansion of their use, the world has been producing a vast amount of data that cannot be handled with traditional methods anymore.
According to Statista, as of 2021 there are 23.8 billion devices connected to the internet and 58% of those are IoT devices (smart home devices, connected self-driving cars, industrial devices, etc.) and the remaining 42% are non-IoT devices (laptops, smartphones, etc.). This means that nowadays data can come from various sources. Some of these are:
- User activities: Any user action produces data and even the data that reflects where and how often we tap on the mobile applications we use is valuable. Every piece of data that contains this kind of information needs to be kept and distributed to the applications’ data centers.
- “Internet of Things” devices: These devices produce a huge amount of information, such as sensor data generated in many different locations. All this data needs to be retrieved and sent to a data pool for further analysis.
- Program logs: Today’s computer applications consist of many components and all those components produce program logs. These logs are sent to a data engineering pipeline for further analysis.
All the different structured data that the world produces needs to be delivered to other components in the software structure, or visualized and interpreted by business analysts and data scientists. However, this delivery is not a simple task. There are some crucial requirements on how to deliver the data:
- Data needs to be delivered in a standardized structure
- The data should not present any conflicts
- Data duplication may need to be removed
- The data needs to be reliable
- The data delivery must be done with minimum delay
Therefore, the delivery of this information is a complex process and, if it is not carried out properly, it can be very problematic, especially for medium and large-scale companies. This is where data engineers come into play.
In this article you will learn the basics of data engineering, which are:
- What data engineering is and why to ensure a robust data pipeline
- The difference between data science and data engineering
- The reason behind the increasing popularity of data engineering
- The skills of a good data engineer
- How DataCamp can help you become a data engineer
What are the responsibilities of a data engineer?
To put it simply, data engineers:
- Aim to make data easily accessible and available for data scientists and business intelligence engineers (or anyone working with data)
- Optimize the big data system architecture of companies
- Design and configure databases
- Collaborate with teams of business intelligence engineers, data scientists, and data analysts
- Explore and transform data In order to perform all these tasks, data engineers first need to set up the ETL pipelines.
You can find out more about what a data engineer does in our full article.
ETL pipelines
ETL pipelines receive complex data at regular time intervals and process it with the aim of storing the data in a usable form. It is the responsibility of the data engineers to establish and maintain these pipelines.
There are 3 types of ETL pipelines:
- Extract A vast number of data created by data sources is collected in different formats.
- Transform Since the data comes in different formats and due to its inconsistent sources, the data is processed to become as standardized as possible. This increases the discoverability and usability of the data for the next steps.
- Load Once the data is in a discoverable and usable format, it is usually stored in data warehouses. This makes the data available at all times for further analysis.
Data warehouses
Data warehouses are where standardized data is stored. They are optimized for filtering and reading large volumes of data. In modern data warehouses, both structured and unstructured data can be stored, because it is also important to store the data that cannot be categorized, such as photos and videos.
Data engineering vs data science
The differences between the roles of a data engineer and a data scientist are important. On the one hand, data scientists have an important role in companies because they contribute to data-driven decision making. Nevertheless, the success of data scientists is only as good as the data that they have available.
On the other hand, data engineers are the ones who design the systems that provide data to data scientists in an organized and consistent manner. Once the data engineers make the information available for them, data scientists then try to find patterns in the data to reach conclusions, using the format provided by the data engineers.
Data engineers and data scientists clearly work closely together. We can think of it as a football match. In football, it is the coach who develops the strategies that will create goal opportunities, and it is the coach who sets the players in certain positions. In this context the coach is the data engineer, so we can consider that the ball is the data and the player who scores is the data scientist. The rest of the team is the infrastructure.
Why has data engineering increased in popularity?
According to research conducted on the Burning Glass Nova platform, job postings for "data engineer" increased by 88.3% in 2019. According to this research, demand for data engineers has been on the rise since 2016. Another interesting piece of information is that the number of job openings for data engineers is almost 5 times higher than the job openings for data scientists. The salary of a data engineer is also 20-30% higher than the salary of a data scientist.
As stated above, data scientists are the final link in the data processing chain. They need the data to be processed by a data engineer in order to perform their job. As the number of data sources and data types multiply, the need for a data engineer grows. For this reason, companies have recently started to invest more in the extraction and distribution of data.
In Figure 4.1, a pyramid chart displays the hierarchy of needs of data science. In this hierarchy, the tasks assigned to data engineers are at the base of the pyramid, which explains how crucial data engineers are for companies.
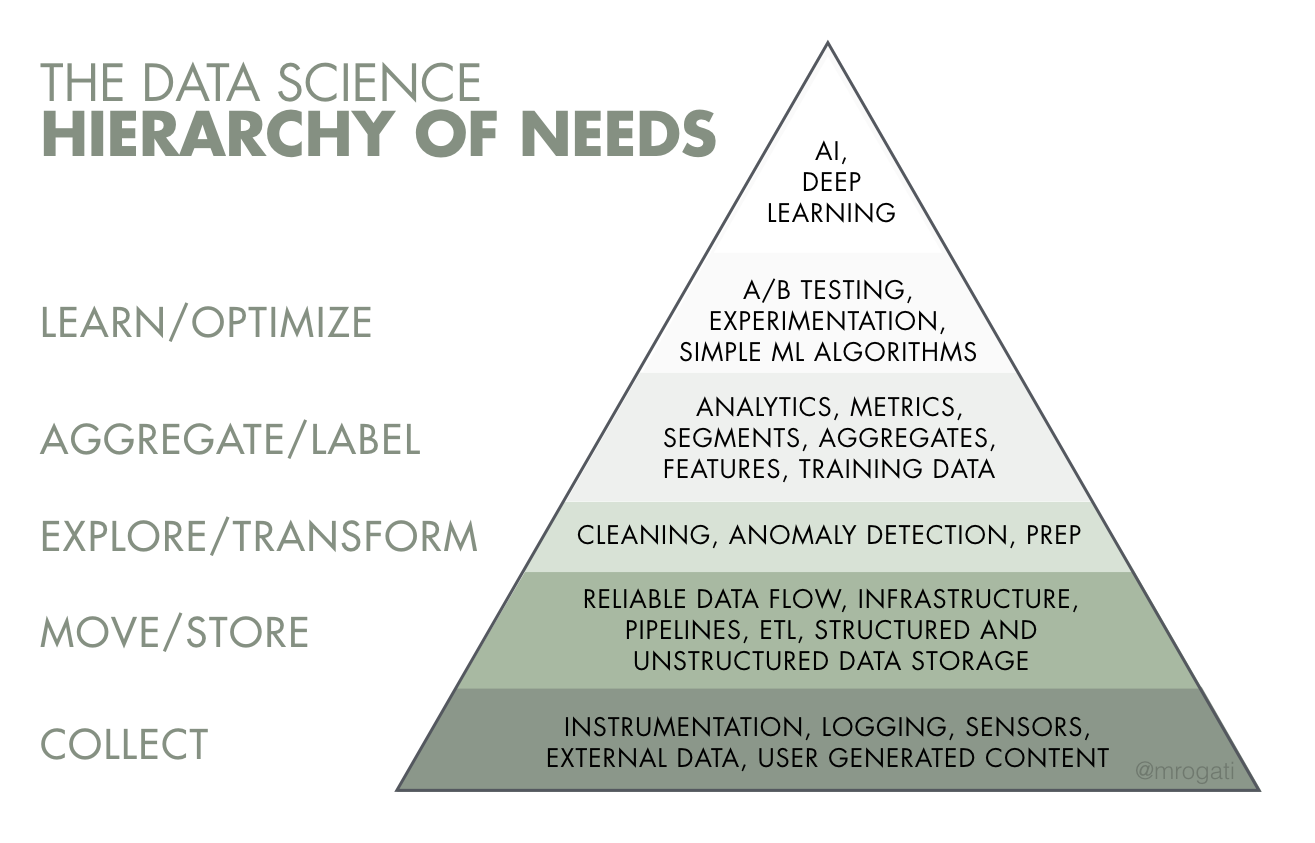 Figure 4.1: The data science hierarchy of needs.
Figure 4.1: The data science hierarchy of needs.What are the skills of a data engineer?
The skills of data engineers are generally intertwined with the skills of software engineers and data scientists, as shown in Figure 5.1.
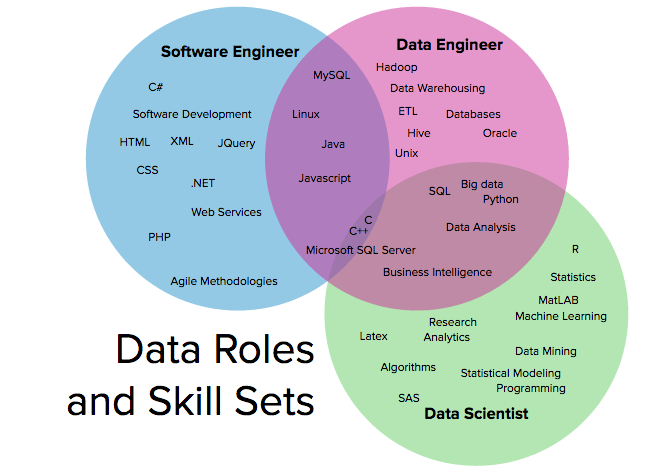 Figure 5.1: Data roles and skill sets
Figure 5.1: Data roles and skill setsIs the role of a data engineer closer to the one of a software engineer or to the one of a data scientist?
The previous occupations of a group of data engineers are displayed in Figure 5.2. According to this figure, over 40% of them have a software engineering background. Not only does this mean that data engineering and software engineering are significantly closer than we may have first thought, but also that software engineers nowadays are much more likely to switch to data engineering than any other field.
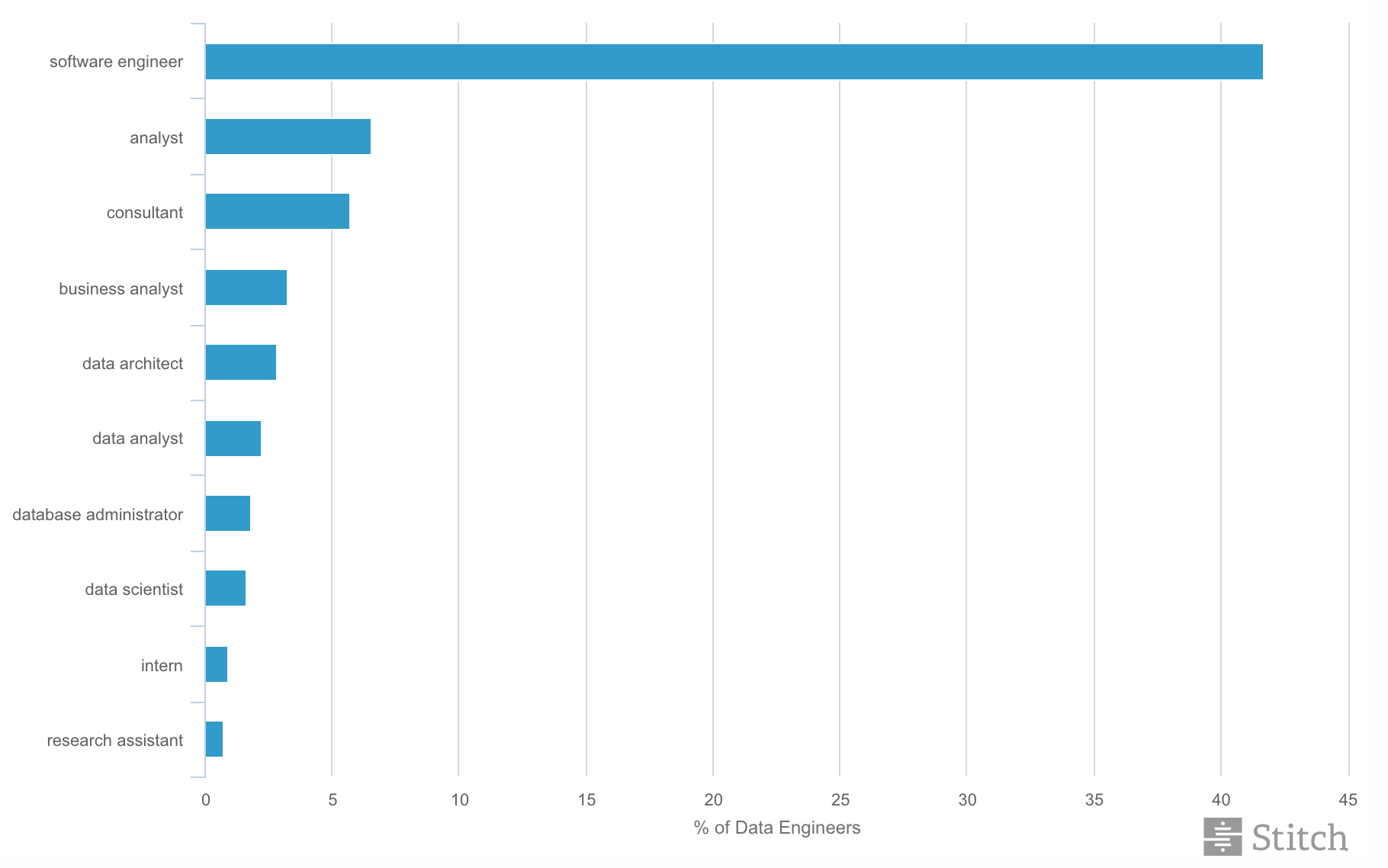 Figure 5.2: Data engineers by prior role (top 10).
Figure 5.2: Data engineers by prior role (top 10).At DataCamp we believe the following to be the skills of a good data engineer:
- Software engineering background Data engineers need to have a software engineering background, since they need to approach data engineering challenges with their knowledge of object-oriented programming, data structures and algorithms. Data engineers must be experienced in Python, Scala or Java.
- Tools Data engineers need to be comfortable with data engineering tools like Airflow, Apache or Kafka.
- Database Technologies A data engineer should have knowledge of multiple kinds of databases.
- Cloud Technologies Data engineers should be comfortable using multiple cloud platforms like Amazon Web Services, Google Cloud Platform and Microsoft Azure. They need to have experience in cloud architecture and DevOps tools as well, since they are responsible for the automation of the data flow part of the system.
How to learn data engineering
If you want to improve in the data engineering field, you can start by completing the following recommended DataCamp courses. By completing these courses and projects, you will likely become a more suitable candidate for internships or job positions in the field of data engineering.
- Introduction to Python
- Intermediate Python
- Introduction to Relational Databases in SQL
- Introduction to Scala
- Introduction to Data Engineering
- Introduction to Airflow in Python
- AWS Cloud Concepts
- Exploring London's Travel Network (Snowflake, Redshift, BigQuery) Projects
- Building Data Engineering Pipelines in Python
- NoSQL Concepts
- ETL in Python
- Streaming Concepts
- Streaming Data with AWS Kinesis and Lambda
In addition, our Data Engineer Certification is industry recognized and enables you to prove your skills to employers.
If you're interested in this career path, you can learn how to become a data engineer in our separate article.
