
Lernpfad
Associate Data Engineer in SQL
30 Std.
Datenverarbeitung ist echt technisch, also ist es klar, dass die meisten Fragen und Aufgaben in deinem Vorstellungsgespräch technisch sein werden. In diesem Abschnitt schauen wir uns verschiedene technische Fragen und Antworten an, vor allem für Anfänger, Python, SQL, projektbezogene und Management-Fragen.
Die Vorstellungsgespräche für Nachwuchsingenieure drehen sich um Tools, Python und SQL-Abfragen. Es kann auch um Fragen zur Datenbankverwaltung und zu ETL-Prozessen gehen, einschließlich Programmieraufgaben und Tests, die man zu Hause machen kann.
Wenn Firmen Absolventen einstellen, wollen sie sicher sein, dass du mit ihren Daten und Systemen gut umgehen kannst.
Es gibt drei Hauptschemata für die Datenmodellierung: Stern, Snowflake und Galaxie.
Beispiel für ein Sternschema. Bild von guru99
Beispiel für ein Snowflake-Schema. Bild von guru99
Beispiel für ein Galaxy-Schema. Bild von guru99
Erwähne bei der Beantwortung dieser Frage die ETL-Tools, die du beherrschst, und erkläre, warum du bestimmte Tools für bestimmte Projekte ausgewählt hast. Sag mal, was die einzelnen Tools für Vor- und Nachteile haben und wie sie in deinen Arbeitsablauf passen. Beliebte Open-Source-Tools sind zum Beispiel:
Wenn du deine ETL-Kenntnisse auffrischen willst, solltest du den Kurs „Einführung in das Data Engineering“ machen.
Datenorchestrierung ist ein automatisierter Prozess, bei dem man auf Rohdaten aus verschiedenen Quellen zugreift, sie bereinigt, umwandelt und modelliert und dann für Analysen bereitstellt. Es sorgt dafür, dass die Daten zwischen verschiedenen Systemen und Verarbeitungsschritten reibungslos fließen.
Beliebte Tools für die Datenorchestrierung sind:
Analytics Engineering bedeutet, verarbeitete Daten umzuwandeln, statistische Modelle anzuwenden und sie durch Berichte und Dashboards zu visualisieren.
Beliebte Tools für Analytics Engineering sind:
Diese Tools helfen dabei, auf Daten zuzugreifen, sie umzuwandeln und zu visualisieren, um wichtige Erkenntnisse zu gewinnen und Entscheidungsprozesse zu unterstützen.
OLAP (Online Analytical Processing) checkt alte Daten und hilft bei komplizierten Abfragen. Es ist für leseintensive Aufgaben optimiert und wird oft in Data Warehouses für Business-Intelligence-Aufgaben genutzt. OLTP ( Online Transaction Processing) ist für die Verwaltung von Echtzeit-Transaktionsdaten gedacht. Es ist für schreibintensive Aufgaben optimiert und wird in operativen Datenbanken für den täglichen Geschäftsbetrieb genutzt.
Der Hauptunterschied liegt in ihrem Zweck: OLAP hilft bei der Entscheidungsfindung, während OLTP den täglichen Betrieb unterstützt.
Wenn du immer noch Zweifel hast, schau dir mal den Blogbeitrag „OLTP vs. OLAP” an.
Python ist die beliebteste Sprache im Bereich Data Engineering, weil sie so vielseitig ist und es so viele Bibliotheken für Datenverarbeitung, Analyse und Automatisierung gibt. Hier sind ein paar Fragen zu Python, die dir in einem Vorstellungsgespräch im Bereich Data Engineering gestellt werden könnten.
Zu den beliebtesten Bibliotheken für die Datenverarbeitung in Python gehören:
Jede dieser Bibliotheken hat ihre Vor- und Nachteile, und die Wahl hängt von den spezifischen Datenanforderungen und dem Umfang der Datenverarbeitungsaufgaben ab.
Web Scraping in Python läuft meistens so ab:
1. Ruf die Webseite mit der Bibliothek „ requests “ auf:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Extrahier Tabellen und Infos mit BeautifulSoup:
tables = soup.find_all('table')3. Mach daraus mit pandas ein strukturiertes Format:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Reinige die Daten mit pandas und NumPy:
df.dropna(inplace=True) # Drop missing values5. Speichere die Daten als CSV-Datei:
df.to_csv('scraped_data.csv', index=False)Manchmal kann „ pandas.read_html “ den Prozess vereinfachen:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneUm mit großen Datensätzen umzugehen, die nicht in den Arbeitsspeicher passen, braucht man Tools und Techniken, die für die Out-of-Core-Berechnung entwickelt wurden:
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionUm sicherzustellen, dass Python-Code effizient und leistungsoptimiert ist, solltest du die folgenden Vorgehensweisen beachten:
cProfile, line_profiler oder memory_profiler, um Engpässe in deinem Code zu finden.import cProfile
cProfile.run('your_function()')numpy “ oder „ pandas “ für vektorisierte Operationen anstelle von Schleifen.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultDatenintegrität und -qualität sind wichtig für zuverlässiges Data Engineering. Zu den bewährten Methoden gehören:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas, um Daten zu bereinigen und vorzubereiten, indem du fehlende Werte bearbeitest, Duplikate entfernst und Fehler korrigierst. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Der Umgang mit fehlenden Daten ist eine häufige Aufgabe im Bereich Data Engineering. Zu den Ansätzen gehören:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Um API-Ratenbeschränkungen zu umgehen, gibt's Strategien wie:
Beispiel mit der Python-Bibliothek „ time ” und dem Modul „ requests ”:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python ist echt eine der wichtigsten Sprachen im Bereich Data Engineering. Du kannst deine Fähigkeiten verbessern, indem du unseren Lernpfad „Data Engineer in Python“ machst. Der Lernpfad deckt ein umfassendes Lehrprogramm ab, das dir moderne Datenverarbeitungskonzepte, Programmiersprachen, Tools und Frameworks beibringt.
Die SQL-Codierungsphase ist ein wichtiger Teil des Einstellungsprozesses für Dateningenieure. Das Üben von verschiedenen einfachen und komplizierten Skripten kann dir bei der Vorbereitung helfen. Die Interviewer könnten dich bitten, Abfragen für Datenanalysen, gemeinsame Ausdrücke in Tabellen, Ranglisten, Zwischensummen und temporäre Funktionen zu schreiben.
CTEs werden benutzt, um komplizierte Verknüpfungen zu vereinfachen und Unterabfragen auszuführen. Sie machen SQL-Abfragen übersichtlicher und einfacher zu pflegen. Hier ist ein Beispiel für eine CTE, die alle Studenten mit dem Hauptfach Naturwissenschaften und der Note A anzeigt:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);Mit CTE sieht die Abfrage so aus:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);CTEs kann man für kompliziertere Probleme nutzen und mehrere CTEs kann man miteinander verbinden.
Dateningenieure ordnen Werte oft nach Parametern wie Umsatz und Gewinn. Die Funktion „ RANK() “ sortiert Daten nach einer bestimmten Spalte:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Du kannst auch „ DENSE_RANK() “ verwenden, das nachfolgende Ränge nicht überspringt, wenn die Werte gleich sind.
Genau wie in Python kannst du in SQL Funktionen erstellen, um deine Abfragen eleganter zu gestalten und wiederholte case-Anweisungen zu vermeiden. Hier ist ein Beispiel für eine temporäre Funktion „ get_gender “:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Dieser Ansatz macht deinen SQL-Code übersichtlicher und einfacher zu pflegen.
Zwischensummen kannst du mit den Funktionen „ GROUP BY “ und „ ROLLUP() “ hinzufügen. Hier ein Beispiel:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Diese Abfrage gibt dir eine Zwischensumme für jede Abteilung und am Ende eine Gesamtsumme.
Der Umgang mit fehlenden Daten ist super wichtig, um die Datenintegrität zu sichern. Zu den gängigen Ansätzen gehören:
COALESCE(): Diese Funktion gibt den ersten Wert in der Liste zurück, der nicht null ist.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE -Anweisungen verwenden: Um fehlende Werte bedingt zu behandeln. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;Bei der Datenaggregation werden Aggregatfunktionen wie „ SUM() “, „ AVG() “, „ COUNT() “, „ MIN() “ und „ MAX() “ benutzt. Hier ein Beispiel:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Um SQL-Abfragen zu optimieren, kannst du Folgendes tun:
SELECT * “, indem du nur die benötigten Spalten angibst.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;SQL-Codierungsübungen zu lösen ist der beste Weg, um zu üben und vergessene Konzepte wieder aufzufrischen. Du kannst deine SQL-Kenntnisse mit dem Test „Datenanalyse in SQL“ von DataCamp checken (du brauchst ein Konto, um auf diesen Test zugreifen zu können).
Nach den allgemeinen Vorstellungsgesprächen geht's normalerweise weiter zur technischen Phase, wo du dich mit Programmieraufgaben, Problemlösungen, dem Entwurf von Datenbanksystemen auf einem Whiteboard, einer Hausarbeit und analytischen Fragen beschäftigen musst.
Diese Phase kann ziemlich intensiv sein, daher kann es dir helfen, einige der üblichen Fragen und Antworten aus Vorstellungsgesprächen im Bereich Data Engineering zu kennen, um das Vorstellungsgespräch mit Bravour zu meistern.
Diese Antwort sollte dir leicht fallen, wenn du schon mal als Student oder Profi an einem Datenengineering-Projekt gearbeitet hast. Trotzdem ist es immer gut, sich im Voraus vorzubereiten. So kannst du deine Antwort aufbauen:
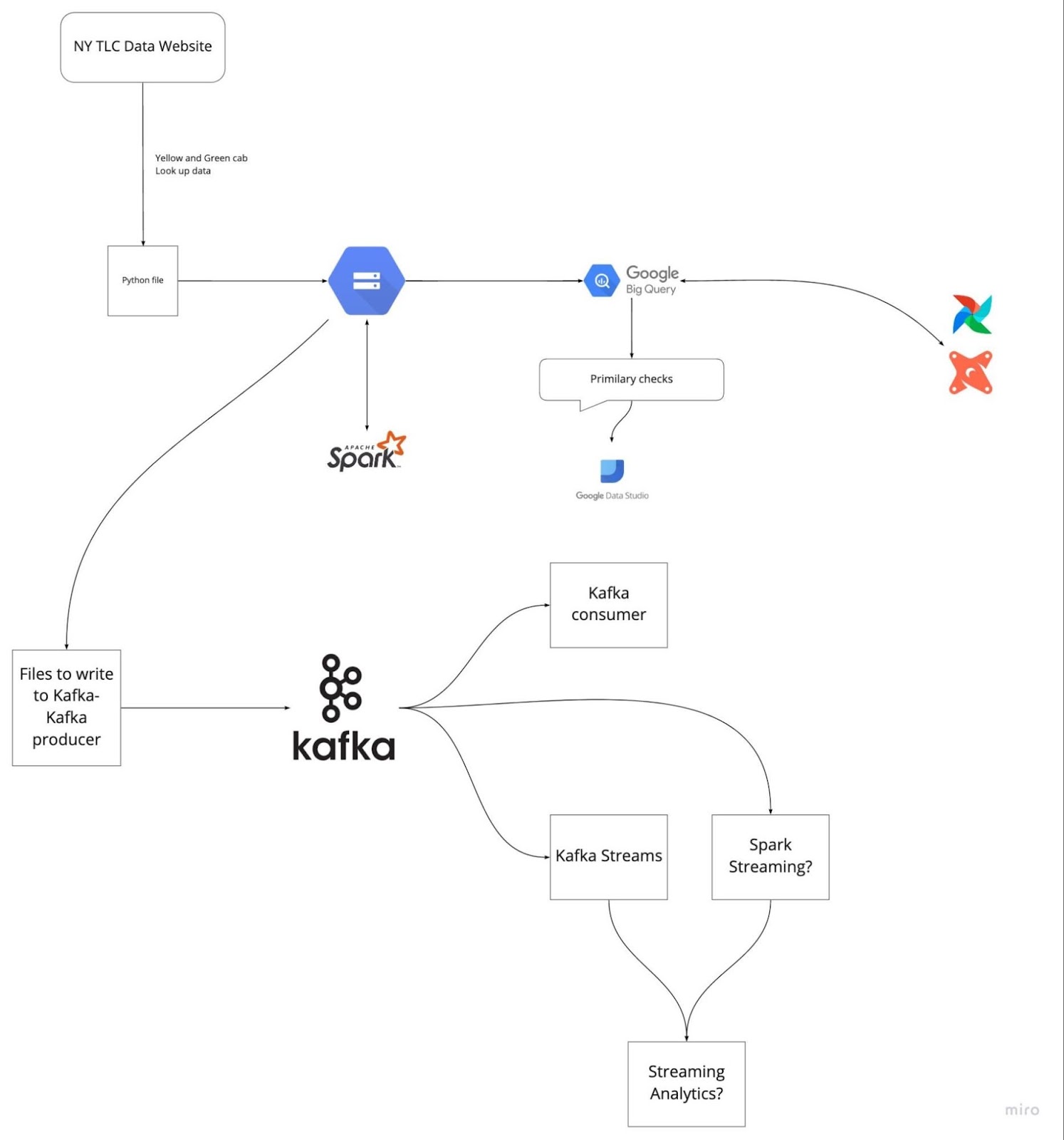
Bild von DataTalksClub/data-engineering-zoomcamp
Wenn du dich im Voraus auf die letzten fünf Projekte vorbereitest, an denen du gearbeitet hast, kannst du vermeiden, dass du während des Vorstellungsgesprächs nervös wirst. Verstehe die Problemstellung und die Lösungen, die du umgesetzt hast. Übe, jeden Schritt klar und knapp zu erklären.
Bei Stellen als Engineering Manager drehen sich die Fragen normalerweise um Themen wie Entscheidungsfindung, Geschäftsverständnis, Kuratieren und Pflegen von Datensätzen, Compliance und Sicherheitsrichtlinien.
Ein Data Warehouse liefert alte Daten für Datenanalysen und Entscheidungen. Es unterstützt die Verarbeitung großer Datenmengen, wie zum Beispiel Online Analytical Processing (OLAP). Datenlager sind so gemacht, dass sie komplizierte Abfragen mit vielen Zeilen hinkriegen und sind für leseintensive Vorgänge optimiert. Sie unterstützen mehrere Benutzer gleichzeitig und sind so gemacht, dass sie schnell und effizient große Datenmengen abrufen können.
Operative Datenbankmanagementsysteme (OLTP) verwalten dynamische Datensätze in Echtzeit. Sie können viele Transaktionen für viele Kunden gleichzeitig abwickeln und sind deshalb super für den täglichen Betrieb. Die Daten sind meistens aktuelle Infos über Geschäftstransaktionen und -abläufe. OLTP-Systeme sind für schreibintensive Vorgänge und schnelle Abfrageverarbeitung optimiert.
Katastrophenmanagement ist die Aufgabe eines Daten-Engineering-Managers. Ein Notfallwiederherstellungsplan sorgt dafür, dass Datensysteme wiederhergestellt werden können und weiterlaufen, wenn es zu einem Cyberangriff, einem Hardwareausfall, einer Naturkatastrophe oder anderen katastrophalen Ereignissen kommt. Wichtige Punkte sind:
Als Daten-Engineering-Manager muss man bei Entscheidungen technische Aspekte und Geschäftsziele gegeneinander abwägen. Einige Ansätze sind:
Um die Datenschutzregeln einzuhalten, muss man ein paar Sachen beachten, zum Beispiel:
Wenn du über ein anspruchsvolles Projekt redest, kannst du dich auf die folgenden Punkte konzentrieren:
Neue Datentechnologien zu checken und einzusetzen bedeutet:
Eine gute Methode, um Aufgaben zu priorisieren, ist, sie nach ihrer Bedeutung für die Geschäftsziele und ihrer Dringlichkeit zu sortieren. Du kannst Frameworks wie die Eisenhower-Matrix nutzen, um Aufgaben in vier Quadranten einzuteilen: dringend und wichtig, wichtig, aber nicht dringend, dringend, aber nicht wichtig und weder noch. Außerdem solltest du mit den Beteiligten reden, um Prioritäten abzustimmen und sicherzustellen, dass sich das Team auf wichtige Sachen konzentriert.
In diesem Abschnitt schauen wir uns die häufigsten Fragen an, die Manager von Facebook, Amazon und Google bei Vorstellungsgesprächen für Stellen im Bereich Data Engineering stellen.
Ein Kafka-Cluster besteht aus mehreren Brokern, die Daten auf mehrere Instanzen verteilen. Diese Architektur bietet Skalierbarkeit und Ausfallsicherheit ohne Ausfallzeiten. Wenn der primäre Cluster ausfällt, können andere Kafka-Cluster die gleichen Dienste übernehmen und so für hohe Verfügbarkeit sorgen.
Die Kafka-Clusterarchitektur besteht aus Themen, Brokern, ZooKeeper, Produzenten und Konsumenten. Es macht einen super Job beim Umgang mit Datenströmen für Big-Data-Anwendungen und hilft dabei, starke datengesteuerte Anwendungen zu entwickeln.
Mit Apache Airflow kannst du Pipelines für Analyse-Workflows, Data-Warehouse-Management sowie Datentransformation und -modellierung verwalten und planen. Es bietet:
Um zu checken, ob eine IP-Adresse echt ist, kannst du die Zeichenfolge an den Punkten „.“ trennen und mehrere Prüfungen machen, um jedes Segment zu checken. Hier ist eine Python-Funktion, um das zu machen:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop läuft hauptsächlich in drei Modi:
Um Duplikate in SQL zu bearbeiten, kannst du das Schlüsselwort „ DISTINCT “ verwenden oder doppelte Zeilen mit „ ROWID “ und den Funktionen „ MAX “ oder „ MIN “ löschen. Hier sind ein paar Beispiele:
DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Duplikate löschen mit „ ROWID “:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Dieses häufige Problem beim Codieren kann mit einem mathematischen Ansatz gelöst werden:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Bevor du zum Vorstellungsgespräch gehst, solltest du dir alle Begriffe und Standardausdrücke im Bereich Data Engineering nochmal anschauen. Hier sind ein paar der wichtigsten Bereiche, auf die du dich konzentrieren solltest:
Die Vorbereitung auf ein Vorstellungsgespräch im Bereich Data Engineering kann echt schwierig sein, aber mit den richtigen Ressourcen und etwas Übung kannst du dich von der Masse abheben und deinen Traumjob ergattern. Um deine Fähigkeiten und dein Wissen noch weiter zu verbessern, schau dir diese coolen Ressourcen an:
Nutze diese Kurse, um deine Grundlagen zu festigen und in deiner Karriere im Bereich Data Engineering immer einen Schritt voraus zu sein. Viel Glück bei deinen Vorstellungsgesprächen!
Lerne mit diesen Kursen mehr über Data Engineering!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
Tutorial
Matt Crabtree