
Program
Associate Data Engineer dalam SQL
30 Hr
Rekayasa data sangat teknis, jadi tidak mengherankan jika sebagian besar proses wawancara Anda akan melibatkan pertanyaan dan latihan teknis. Pada bagian ini, kami membahas berbagai jenis pertanyaan dan jawaban teknis, dengan fokus pada tingkat pemula, Python, SQL, berbasis proyek, dan manajerial.
Wawancara level junior berfokus pada alat, Python, dan kueri SQL. Mereka juga dapat mencakup pertanyaan tentang manajemen basis data dan proses ETL, termasuk tantangan coding dan tes take-home.
Saat perusahaan merekrut lulusan baru, mereka ingin memastikan Anda dapat menangani data dan sistem mereka secara efektif.
Ada tiga skema desain pemodelan data utama: star, snowflake, dan galaxy.
Contoh star schema. Gambar dari guru99
Contoh snowflake schema. Gambar dari guru99
Contoh galaxy schema. Gambar dari guru99
Saat menjawab, sebutkan alat ETL yang Anda kuasai dan jelaskan mengapa Anda memilih alat tertentu untuk proyek tertentu. Bahas kelebihan dan kekurangan tiap alat serta bagaimana alat tersebut masuk ke alur kerja Anda. Alat open-source populer meliputi:
Jika Anda perlu menyegarkan pengetahuan ETL, pertimbangkan mengikuti kursus Introduction to Data Engineering.
Orkestrasi data adalah proses otomatis untuk mengakses data mentah dari berbagai sumber, melakukan teknik pembersihan, transformasi, dan pemodelan data, serta menyajikannya untuk tugas analitik. Ini memastikan data mengalir mulus antara berbagai sistem dan tahap pemrosesan.
Alat populer untuk orkestrasi data mencakup:
Analytics engineering melibatkan transformasi data yang telah diproses, menerapkan model statistik, dan memvisualisasikannya melalui laporan serta dashboard.
Alat populer untuk analytics engineering meliputi:
Alat-alat ini membantu mengakses, mentransformasi, dan memvisualisasikan data untuk memperoleh wawasan bermakna dan mendukung proses pengambilan keputusan.
OLAP (Online Analytical Processing) menganalisis data historis dan mendukung kueri kompleks. Dioptimalkan untuk beban kerja yang dominan baca dan sering digunakan di data warehouse untuk tugas business intelligence. OLTP (Online Transaction Processing) dirancang untuk mengelola data transaksional real-time. Dioptimalkan untuk beban kerja yang dominan tulis dan digunakan di basis data operasional untuk operasi bisnis sehari-hari.
Perbedaan utama terletak pada tujuannya: OLAP mendukung pengambilan keputusan, sedangkan OLTP mendukung operasi harian.
Jika Anda masih ragu, saya sarankan membaca posting blog OLTP vs OLAP.
Python adalah bahasa paling populer dalam rekayasa data karena fleksibilitasnya dan ekosistem pustaka yang kaya untuk pemrosesan data, analisis, dan otomatisasi. Berikut beberapa pertanyaan terkait Python yang mungkin Anda temui dalam wawancara rekayasa data.
Pustaka pemrosesan data paling populer di Python meliputi:
Masing-masing pustaka ini memiliki kelebihan dan kekurangan, dan pilihan bergantung pada kebutuhan data spesifik serta skala tugas pemrosesan.
Web scraping di Python umumnya melibatkan langkah-langkah berikut:
1. Mengakses halaman web menggunakan pustaka requests:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Mengekstrak tabel dan informasi menggunakan BeautifulSoup:
tables = soup.find_all('table')3. Mengonversinya ke format terstruktur menggunakan pandas:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Membersihkan data menggunakan pandas dan NumPy:
df.dropna(inplace=True) # Drop missing values5. Menyimpan data dalam bentuk file CSV:
df.to_csv('scraped_data.csv', index=False)Dalam beberapa kasus, pandas.read_html dapat menyederhanakan proses:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneMenangani dataset besar yang tidak muat di memori memerlukan penggunaan alat dan teknik yang dirancang untuk komputasi out-of-core:
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionUntuk memastikan kode Python efisien dan teroptimasi, pertimbangkan praktik berikut:
cProfile, line_profiler, atau memory_profiler untuk mengidentifikasi bottleneck pada kode Anda.import cProfile
cProfile.run('your_function()')numpy atau pandas untuk operasi tervektor alih-alih loop.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultIntegritas dan kualitas data penting untuk rekayasa data yang andal. Praktik terbaik meliputi:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas untuk membersihkan dan melakukan praproses data dengan menangani nilai hilang, menghapus duplikat, dan memperbaiki kesalahan. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Menangani data hilang adalah tugas umum dalam rekayasa data. Pendekatan meliputi:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Untuk menangani rate limit API, ada strategi seperti:
Contoh menggunakan pustaka time Python dan modul requests:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python tak diragukan lagi adalah salah satu bahasa terpenting dalam rekayasa data. Anda dapat mengasah keterampilan dengan mengikuti track Data Engineer in Python kami, yang mencakup kurikulum komprehensif untuk membekali Anda dengan konsep, bahasa pemrograman, alat, dan kerangka kerja rekayasa data modern.
Tahap pengkodean SQL merupakan bagian penting dari proses perekrutan data engineer. Berlatih berbagai skrip sederhana dan kompleks dapat membantu Anda bersiap. Pewawancara mungkin meminta Anda menulis kueri untuk analitik data, common table expressions, ranking, menambahkan subtotal, dan fungsi sementara.
CTE digunakan untuk menyederhanakan join kompleks dan menjalankan subquery. CTE membantu membuat kueri SQL lebih mudah dibaca dan dipelihara. Berikut contoh CTE yang menampilkan semua mahasiswa dengan jurusan Sains dan nilai A:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);Dengan menggunakan CTE, kuerinya menjadi:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);CTE dapat digunakan untuk masalah yang lebih kompleks dan beberapa CTE dapat dirangkai bersama.
Data engineer umum melakukan peringkat nilai berdasarkan parameter seperti penjualan dan laba. Fungsi RANK() digunakan untuk memberi peringkat data berdasarkan kolom tertentu:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Sebagai alternatif, Anda dapat menggunakan DENSE_RANK() yang tidak melewatkan peringkat berikutnya jika nilainya sama.
Seperti di Python, Anda dapat membuat fungsi di SQL untuk membuat kueri lebih rapi dan menghindari pernyataan case yang berulang. Berikut contoh fungsi sementara get_gender:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Pendekatan ini membuat kode SQL Anda lebih bersih dan mudah dirawat.
Menambahkan subtotal dapat dicapai menggunakan fungsi GROUP BY dan ROLLUP(). Berikut contohnya:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Kueri ini akan memberikan subtotal untuk setiap departemen dan total keseluruhan di akhir.
Menangani data hilang penting untuk menjaga integritas data. Pendekatan umum meliputi:
COALESCE(): Fungsi ini mengembalikan nilai pertama yang bukan null dalam daftar.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE: Untuk menangani nilai hilang secara kondisional. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;Agregasi data melibatkan penggunaan fungsi agregat seperti SUM(), AVG(), COUNT(), MIN(), dan MAX(). Berikut contohnya:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Untuk mengoptimalkan kueri SQL, Anda dapat:
SELECT * dengan hanya menyebutkan kolom yang diperlukan.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;Menyelesaikan latihan pengkodean SQL adalah cara terbaik untuk berlatih dan meninjau konsep yang terlupa. Anda dapat menilai keterampilan SQL Anda dengan mengikuti tes Data Analysis in SQL dari DataCamp (Anda memerlukan akun untuk mengakses penilaian ini).
Setelah putaran wawancara umum, Anda biasanya akan melanjutkan ke tahap teknis yang terdiri dari tantangan coding, pemecahan masalah, desain sistem basis data di papan tulis, ujian take-home, dan pertanyaan analitis.
Tahap ini bisa cukup intens, jadi mengetahui beberapa pertanyaan dan jawaban wawancara rekayasa data yang biasa dapat membantu Anda unggul dalam wawancara.
Jawaban ini seharusnya mengalir alami jika Anda pernah mengerjakan proyek rekayasa data sebagai mahasiswa atau profesional. Meski begitu, tetap berguna untuk mempersiapkan sebelumnya. Berikut cara menyusun jawaban Anda:
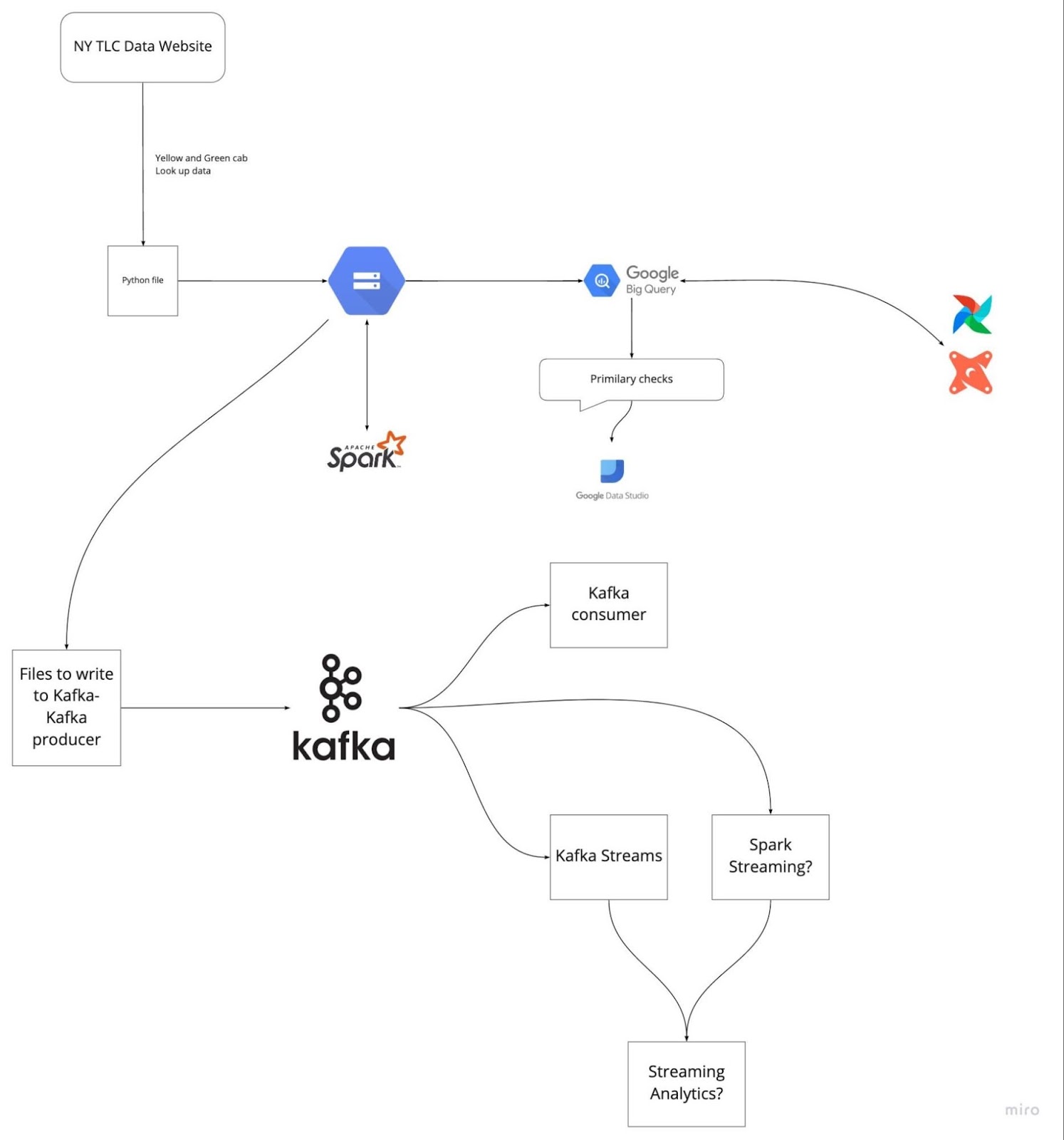
Gambar dari DataTalksClub/data-engineering-zoomcamp
Mempersiapkan diri sebelumnya dengan meninjau lima proyek terakhir yang telah Anda kerjakan dapat membantu Anda menghindari kebekuan saat wawancara. Pahami pernyataan masalah dan solusi yang Anda terapkan. Latih menjelaskan setiap langkah dengan jelas dan ringkas.
Untuk posisi manajer engineering, pertanyaan biasanya terkait pengambilan keputusan, pemahaman bisnis, kurasi dan pemeliharaan dataset, kepatuhan, dan kebijakan keamanan.
Data warehouse menyajikan data historis untuk tugas analitik data dan pengambilan keputusan. Ia mendukung pemrosesan analitik volume tinggi, seperti Online Analytical Processing (OLAP). Data warehouse dirancang untuk menangani kueri kompleks yang mengakses banyak baris dan dioptimalkan untuk operasi yang dominan baca. Mereka mendukung sedikit pengguna bersamaan dan dirancang untuk mengambil data dengan cepat dan dalam volume tinggi secara efisien.
Operational Database Management Systems (OLTP) mengelola dataset dinamis secara real time. Mereka mendukung pemrosesan transaksi volume tinggi untuk ribuan klien bersamaan, sehingga cocok untuk operasi sehari-hari. Datanya biasanya terdiri dari informasi terkini tentang transaksi dan operasi bisnis. Sistem OLTP dioptimalkan untuk operasi yang dominan tulis dan pemrosesan kueri cepat.
Manajemen bencana adalah tanggung jawab manajer rekayasa data. Rencana pemulihan bencana memastikan sistem data dapat dipulihkan dan terus beroperasi jika terjadi serangan siber, kegagalan perangkat keras, bencana alam, atau peristiwa katastrofik lainnya. Aspek terkait mencakup:
Sebagai manajer rekayasa data, pengambilan keputusan melibatkan penyeimbangan pertimbangan teknis dengan tujuan bisnis. Beberapa pendekatan meliputi:
Kepatuhan terhadap regulasi perlindungan data melibatkan beberapa praktik, misalnya:
Saat membahas proyek menantang, Anda dapat fokus pada aspek berikut:
Mengevaluasi dan menerapkan teknologi data baru melibatkan:
Cara efektif untuk memprioritaskan tugas adalah berdasarkan dampaknya pada tujuan bisnis dan urgensinya. Anda dapat menggunakan kerangka seperti Matriks Eisenhower untuk mengkategorikan tugas ke dalam empat kuadran: mendesak dan penting, penting tetapi tidak mendesak, mendesak tetapi tidak penting, dan tidak keduanya. Selain itu, berkomunikasilah dengan pemangku kepentingan untuk menyelaraskan prioritas dan memastikan tim fokus pada aktivitas bernilai tinggi.
Pada bagian ini, kami membahas pertanyaan wawancara rekayasa data yang paling sering ditanyakan oleh manajer Facebook, Amazon, dan Google untuk posisi data engineer.
Cluster Kafka terdiri dari beberapa broker yang mendistribusikan data ke berbagai instance. Arsitektur ini memberikan skalabilitas dan toleransi kesalahan tanpa waktu henti. Jika cluster utama down, cluster Kafka lain dapat memberikan layanan yang sama, memastikan ketersediaan tinggi.
Arsitektur cluster Kafka terdiri dari Topic, Broker, ZooKeeper, Producer, dan Consumer. Ia menangani aliran data untuk aplikasi big data secara efisien, memungkinkan pembuatan aplikasi berbasis data yang tangguh.
Apache Airflow memungkinkan Anda mengelola dan menjadwalkan pipeline untuk workflow analitik, manajemen data warehouse, serta transformasi dan pemodelan data. Airflow menyediakan:
Untuk menentukan validitas alamat IP, Anda dapat membagi string pada tanda titik dan membuat beberapa pemeriksaan untuk memvalidasi setiap bagiannya. Berikut fungsi Python untuk melakukannya:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop terutama bekerja dalam tiga mode:
Untuk menangani duplikat di SQL, Anda dapat menggunakan kata kunci DISTINCT atau menghapus baris duplikat menggunakan ROWID dengan fungsi MAX atau MIN. Berikut contohnya:
Menggunakan DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Menghapus duplikat menggunakan ROWID:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Tantangan coding umum ini dapat diselesaikan menggunakan pendekatan matematis:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Sebelum mengikuti wawancara, Anda harus meninjau semua konsep dan istilah standar yang digunakan dalam rekayasa data. Berikut beberapa area terpenting yang perlu difokuskan:
Mempersiapkan wawancara rekayasa data bisa menantang, tetapi dengan sumber daya yang tepat dan latihan, Anda dapat unggul dan meraih pekerjaan impian. Untuk lebih meningkatkan keterampilan dan pengetahuan Anda, lihat sumber berharga berikut:
Manfaatkan kursus-kursus ini untuk memperkuat fondasi Anda dan tetap selangkah lebih maju dalam karier rekayasa data. Semoga sukses dengan wawancara Anda!
Pelajari lebih lanjut tentang rekayasa data dengan kursus-kursus ini!
Program
Program
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
