
Track
Associate Data Engineer in SQL
30 hr
Data engineering is highly technical, so it’s no surprise that most of your interview process will involve technical questions and exercises. In this section, we will cover different types of technical questions and answers, focusing on beginner, Python, SQL, project-based, and management questions.
The junior engineering interviews focus on tools, Python, and SQL queries. They may also involve questions about database management and ETL processes, including coding challenges and take-home tests.
When companies hire fresh graduates, they want to ensure you can handle their data and systems effectively.
There are three primary data modeling design schemas: star, snowflake, and galaxy.
Star schema example. Image from guru99
Snowflake schema example. Image from guru99
Galaxy schema example. Image from guru99
When answering this question, mention the ETL tools you have mastered and explain why you chose specific tools for certain projects. Discuss the pros and cons of each tool and how they fit into your workflow. Popular open-source tools include:
If you need to refresh your ETL knowledge, consider taking the Introduction to Data Engineering course.
Data orchestration is an automated process for accessing raw data from multiple sources, performing data cleaning, transformation, and modeling techniques, and serving it for analytical tasks. It ensures that data flows smoothly between different systems and stages of processing.
Popular tools for data orchestration include:
Analytics engineering involves transforming processed data, applying statistical models, and visualizing it through reports and dashboards.
Popular tools for analytics engineering include:
These tools help access, transform, and visualize data to derive meaningful insights and support decision-making processes.
OLAP (Online Analytical Processing) analyzes historical data and supports complex queries. It’s optimized for read-heavy workloads and is often used in data warehouses for business intelligence tasks. OLTP (Online Transaction Processing) is designed for managing real-time transactional data. It’s optimized for write-heavy workloads and is used in operational databases for day-to-day business operations.
The main difference lies in their purpose: OLAP supports decision-making, while OLTP supports daily operations.
If you still have doubts, I recommend reading the OLTP vs OLAP blog post.
Python is the most popular language in data engineering due to its versatility and the rich ecosystem of libraries available for data processing, analysis, and automation. Here are some questions related to Python that you might encounter in a data engineering interview.
The most popular data processing libraries in Python include:
Each of these libraries has pros and cons, and the choice depends on the specific data requirements and the scale of the data processing tasks.
Web scraping in Python typically involves the following steps:
1. Access the webpage using the requests library:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Extract tables and information using BeautifulSoup:
tables = soup.find_all('table')3. Convert it into a structured format using pandas:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Clean the data using pandas and NumPy:
df.dropna(inplace=True) # Drop missing values5. Save the data in the form of a CSV file:
df.to_csv('scraped_data.csv', index=False)In some cases, pandas.read_html can simplify the process:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneHandling large datasets that do not fit into memory requires using tools and techniques designed for out-of-core computation:
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionTo ensure Python code is efficient and optimized for performance, consider the following practices:
cProfile, line_profiler, or memory_profiler to identify bottlenecks in your code.import cProfile
cProfile.run('your_function()')numpy or pandas for vectorized operations instead of loops.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultData integrity and quality are important for reliable data engineering. Best practices include:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas to clean and preprocess data by handling missing values, removing duplicates, and correcting errors. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Handling missing data is a common task in data engineering. Approaches include:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)To handle API rate limits, there are strategies such as:
Example using Python's time library and the requests module:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python is undoubtedly one of the most important languages in data engineering. You can hone your skills by taking our Data Engineer in Python track, which covers a comprehensive curriculum to equip you with modern data engineering concepts, programming languages, tools, and frameworks.
The SQL coding stage is a significant part of the data engineering hiring process. Practicing various simple and complex scripts can help you prepare. Interviewers may ask you to write queries for data analytics, common table expressions, ranking, adding subtotals, and temporary functions.
CTEs are used to simplify complex joins and run subqueries. They help make SQL queries more readable and maintainable. Here’s an example of a CTE that displays all students with Science majors and grade A:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);Using a CTE, the query becomes:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);CTEs can be used for more complex problems and multiple CTEs can be chained together.
Data engineers commonly rank values based on parameters such as sales and profit. The RANK() function is used to rank data based on a specific column:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Alternatively, you can use DENSE_RANK() which does not skip subsequent ranks if the values are the same.
Like in Python, you can create functions in SQL to make your queries more elegant and avoid repetitive case statements. Here’s an example of a temporary function get_gender:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;This approach makes your SQL code cleaner and more maintainable.
Adding subtotals can be achieved using the GROUP BY and ROLLUP() functions. Here’s an example:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);This query will give you a subtotal for each department and a grand total at the end.
Handling missing data is essential for maintaining data integrity. Common approaches include:
COALESCE(): This function returns the first non-null value in the list.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE statements: To handle missing values conditionally. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;Data aggregation involves using aggregate functions like SUM(), AVG(), COUNT(), MIN(), and MAX(). Here’s an example:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;To optimize SQL queries, you can:
SELECT * by specifying only the required columns.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;Solving SQL coding exercises is the best way to practice and revise forgotten concepts. You can assess your SQL skills by taking DataCamp’s Data Analysis in SQL test (you will need an account to access this assessment).
After general rounds of interviews, you will usually progress into a technical stage which consists of coding challenges, problem-solving, database system design on a whiteboard, a take-home exam, and analytical questions.
This stage can be quite intense, so knowing some of the usual data engineering interview questions and answers can help you ace the interview.
This answer should come naturally if you have previously worked on a data engineering project as a student or a professional. That being said, preparing ahead of time is always helpful. Here's how to structure your response:
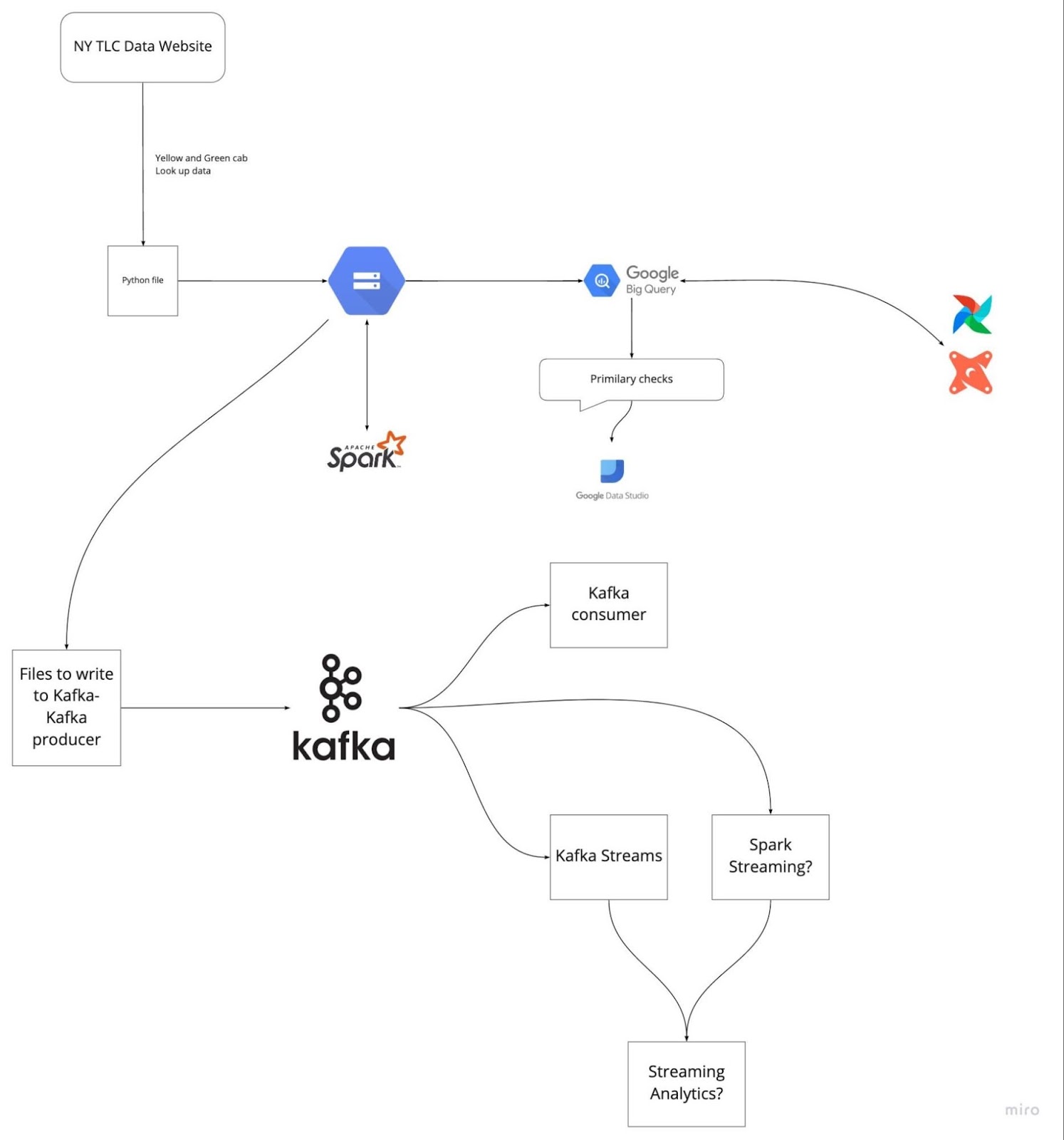
Image from DataTalksClub/data-engineering-zoomcamp
Preparing ahead by reviewing the last five projects you have worked on can help you avoid freezing during the interview. Understand the problem statement and the solutions you implemented. Practice explaining each step clearly and concisely.
For engineering manager positions, the questions normally relate to decision-making, business understanding, curating and maintaining datasets, compliance, and security policies.
A data warehouse serves historical data for data analytics tasks and decision-making. It supports high-volume analytical processing, such as Online Analytical Processing (OLAP). Data warehouses are designed to handle complex queries that access multiple rows and are optimized for read-heavy operations. They support a few concurrent users and are designed to retrieve fast and high volumes of data efficiently.
Operational Database Management Systems (OLTP) manage dynamic datasets in real time. They support high-volume transaction processing for thousands of concurrent clients, making them suitable for day-to-day operations. The data usually consists of current, up-to-date information about business transactions and operations. OLTP systems are optimized for write-heavy operations and fast query processing.
Disaster management is the responsibility of a data engineering manager. A disaster recovery plan ensures that data systems can be restored and continue to operate in the event of a cyber-attack, hardware failure, natural disaster, or other catastrophic events. Relevant aspects include:
As a data engineering manager, decision-making involves balancing technical considerations with business objectives. Some approaches include:
Compliance with data protection regulations involves several practices, for example:
When discussing a challenging project, you can focus on the following aspects:
Evaluating and implementing new data technologies involves:
An effective way to prioritize tasks is based on their impact on business objectives and urgency. You can use frameworks like the Eisenhower Matrix to categorize tasks into four quadrants: urgent and important, important but not urgent, urgent but not important, and neither. Additionally, communicate with stakeholders to align priorities and ensure the team focuses on high-value activities.
In this section, we explore the most frequently asked data engineering interview questions by Facebook, Amazon, and Google managers for data engineering positions.
A Kafka cluster consists of multiple brokers that distribute data across multiple instances. This architecture provides scalability and fault tolerance without downtime. If the primary cluster goes down, other Kafka clusters can deliver the same services, ensuring high availability.
The Kafka cluster architecture comprises Topics, Brokers, ZooKeeper, Producers, and Consumers. It efficiently handles data streams for big data applications, enabling the creation of robust data-driven applications.
Apache Airflow allows you to manage and schedule pipelines for analytical workflows, data warehouse management, and data transformation and modeling. It provides:
To determine the validity of an IP address, you can split the string on “.” and create multiple checks to validate each segment. Here is a Python function to accomplish this:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop mainly works in three modes:
To handle duplicates in SQL, you can use the DISTINCT keyword or delete duplicate rows using ROWID with the MAX or MIN function. Here are examples:
Using DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Deleting duplicates using ROWID:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);This common coding challenge can be solved using a mathematical approach:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Before appearing for an interview, you should review all the concepts and standard terms used in data engineering. Here are some of the most important areas to focus on:
Preparing for a data engineering interview can be challenging, but with the right resources and practice, you can excel and land your dream job. To further enhance your skills and knowledge, check out these valuable resources:
Take advantage of these courses to solidify your foundation and stay ahead in your data engineering career. Good luck with your interviews!
Learn more about data engineering with these courses!
Track
Track
Course
blog
Thalia Barrera
15 min
blog
Dario Radečić
15 min
blog
Dhiraj Kumar
15 min
blog
Flavio Matos
15 min
blog
Fatos Morina
15 min
blog
Kurtis Pykes
15 min