
Tracks
Kỹ sư Dữ liệu Hỗ trợ trong SQL
30 giờ
Kỹ sư dữ liệu mang tính kỹ thuật cao, nên không ngạc nhiên khi phần lớn quy trình phỏng vấn sẽ là câu hỏi và bài tập kỹ thuật. Phần này sẽ bao quát các loại câu hỏi và đáp án kỹ thuật khác nhau, tập trung vào cấp độ sơ cấp, Python, SQL, dự án và quản lý.
Phỏng vấn kỹ sư junior tập trung vào công cụ, Python và truy vấn SQL. Chúng cũng có thể bao gồm câu hỏi về quản trị cơ sở dữ liệu và quy trình ETL, bao gồm thử thách code và bài kiểm tra làm tại nhà.
Khi tuyển dụng sinh viên mới tốt nghiệp, các công ty muốn đảm bảo bạn có thể xử lý dữ liệu và hệ thống của họ hiệu quả.
Có ba schema thiết kế mô hình hóa dữ liệu chính: sao (star), bông tuyết (snowflake) và dải ngân hà (galaxy).
Ví dụ star schema. Ảnh từ guru99
Ví dụ snowflake schema. Ảnh từ guru99
Ví dụ galaxy schema. Ảnh từ guru99
Khi trả lời, hãy nêu các công cụ ETL bạn đã thành thạo và giải thích vì sao bạn chọn công cụ cụ thể cho từng dự án. Thảo luận ưu nhược điểm của mỗi công cụ và cách chúng phù hợp với quy trình làm việc của bạn. Các công cụ mã nguồn mở phổ biến gồm:
Nếu cần ôn lại kiến thức ETL, hãy cân nhắc khóa Introduction to Data Engineering.
Điều phối dữ liệu là quy trình tự động để truy cập dữ liệu thô từ nhiều nguồn, thực hiện làm sạch, chuyển đổi và mô hình hóa, rồi phục vụ cho các tác vụ phân tích. Nó đảm bảo dữ liệu chảy trơn tru giữa các hệ thống và giai đoạn xử lý.
Các công cụ điều phối dữ liệu phổ biến gồm:
Analytics engineering liên quan đến chuyển đổi dữ liệu đã xử lý, áp dụng mô hình thống kê và trực quan hóa qua báo cáo, dashboard.
Các công cụ phổ biến gồm:
Những công cụ này giúp truy cập, chuyển đổi và trực quan hóa dữ liệu để rút ra insight hữu ích và hỗ trợ ra quyết định.
OLAP (Online Analytical Processing) phân tích dữ liệu lịch sử và hỗ trợ truy vấn phức tạp. Tối ưu cho tải công việc đọc nặng và thường dùng trong kho dữ liệu cho tác vụ business intelligence. OLTP (Online Transaction Processing) được thiết kế để quản lý dữ liệu giao dịch thời gian thực. Tối ưu cho tải công việc ghi nặng và dùng trong cơ sở dữ liệu vận hành cho hoạt động hằng ngày.
Khác biệt chính nằm ở mục đích: OLAP hỗ trợ ra quyết định, còn OLTP hỗ trợ vận hành hằng ngày.
Nếu bạn vẫn còn băn khoăn, hãy đọc bài viết OLTP vs OLAP.
Python là ngôn ngữ phổ biến nhất trong kỹ sư dữ liệu nhờ tính linh hoạt và hệ sinh thái thư viện phong phú cho xử lý dữ liệu, phân tích và tự động hóa. Dưới đây là một số câu hỏi liên quan đến Python bạn có thể gặp.
Các thư viện xử lý dữ liệu phổ biến trong Python gồm:
Mỗi thư viện có ưu nhược điểm riêng; lựa chọn phụ thuộc vào yêu cầu và quy mô bài toán xử lý dữ liệu.
Web scraping trong Python thường gồm các bước sau:
1. Truy cập trang web bằng thư viện requests:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Trích xuất bảng và thông tin bằng BeautifulSoup:
tables = soup.find_all('table')3. Chuyển thành định dạng có cấu trúc bằng pandas:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Làm sạch dữ liệu bằng pandas và NumPy:
df.dropna(inplace=True) # Drop missing values5. Lưu dữ liệu dạng tệp CSV:
df.to_csv('scraped_data.csv', index=False)Trong một số trường hợp, pandas.read_html có thể đơn giản hóa quy trình:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneXử lý tập dữ liệu không vừa bộ nhớ cần dùng công cụ và kỹ thuật tính toán ngoài lõi (out-of-core):
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionĐể đảm bảo mã Python hiệu quả và tối ưu, hãy cân nhắc:
cProfile, line_profiler hoặc memory_profiler để xác định nút thắt.import cProfile
cProfile.run('your_function()')numpy hoặc pandas cho thao tác vector thay vì vòng lặp.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultToàn vẹn và chất lượng dữ liệu rất quan trọng cho kỹ sư dữ liệu. Thực tiễn tốt gồm:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas để tiền xử lý bằng cách xử lý giá trị khuyết, loại trùng lặp và sửa lỗi. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Xử lý dữ liệu khuyết là tác vụ phổ biến. Các cách tiếp cận gồm:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Để xử lý rate limit API, có thể áp dụng các chiến lược như:
Ví dụ dùng thư viện time của Python và module requests:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Không nghi ngờ gì, Python là một trong những ngôn ngữ quan trọng nhất trong kỹ sư dữ liệu. Bạn có thể rèn luyện kỹ năng qua lộ trình Data Engineer in Python của chúng tôi, bao quát chương trình học toàn diện về khái niệm, ngôn ngữ lập trình, công cụ và framework hiện đại.
Giai đoạn viết mã SQL là phần quan trọng trong quy trình tuyển kỹ sư dữ liệu. Luyện tập nhiều script đơn giản và phức tạp sẽ giúp bạn chuẩn bị. Nhà phỏng vấn có thể yêu cầu bạn viết truy vấn cho phân tích dữ liệu, CTE, xếp hạng, thêm tổng phụ và hàm tạm.
CTE được dùng để đơn giản hóa join phức tạp và chạy truy vấn con. Chúng giúp truy vấn SQL dễ đọc và dễ bảo trì hơn. Đây là ví dụ CTE hiển thị tất cả sinh viên học ngành Khoa học và điểm A:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);Dùng CTE, truy vấn trở thành:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);CTE có thể dùng cho bài toán phức tạp hơn và có thể xâu chuỗi nhiều CTE.
Kỹ sư dữ liệu thường xếp hạng theo các tham số như doanh số, lợi nhuận. Hàm RANK() dùng để xếp hạng dựa trên một cột cụ thể:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Ngoài ra, bạn có thể dùng DENSE_RANK() vốn không bỏ qua hạng tiếp theo nếu giá trị bằng nhau.
Tương tự Python, bạn có thể tạo hàm trong SQL để truy vấn gọn gàng và tránh lặp lại các câu lệnh case. Đây là ví dụ hàm tạm get_gender:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Cách tiếp cận này giúp mã SQL sạch và dễ bảo trì hơn.
Thêm tổng phụ có thể thực hiện bằng GROUP BY và ROLLUP(). Ví dụ:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Truy vấn này sẽ cho tổng phụ theo phòng ban và tổng cộng cuối cùng.
Xử lý dữ liệu khuyết rất quan trọng để duy trì toàn vẹn dữ liệu. Các cách phổ biến gồm:
COALESCE(): Hàm này trả về giá trị không null đầu tiên trong danh sách.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE: Để xử lý giá trị khuyết có điều kiện. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;Tổng hợp dữ liệu sử dụng các hàm như SUM(), AVG(), COUNT(), MIN() và MAX(). Ví dụ:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Để tối ưu truy vấn SQL, bạn có thể:
SELECT * bằng cách chỉ định cột cần thiết.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;Giải bài tập code SQL là cách tốt nhất để luyện tập và ôn các khái niệm đã quên. Bạn có thể đánh giá kỹ năng SQL bằng bài kiểm tra Data Analysis in SQL của DataCamp (bạn cần tài khoản để truy cập).
Sau các vòng phỏng vấn tổng quát, bạn thường bước vào giai đoạn kỹ thuật gồm thử thách code, giải quyết vấn đề, thiết kế hệ thống cơ sở dữ liệu trên bảng trắng, bài thi tại nhà và câu hỏi phân tích.
Giai đoạn này có thể khá căng, nên biết trước các câu hỏi và đáp án thường gặp sẽ giúp bạn vượt qua tốt.
Câu trả lời sẽ tự nhiên nếu bạn từng làm dự án kỹ sư dữ liệu khi là sinh viên hoặc chuyên gia. Dù vậy, chuẩn bị trước luôn hữu ích. Đây là cách cấu trúc câu trả lời:
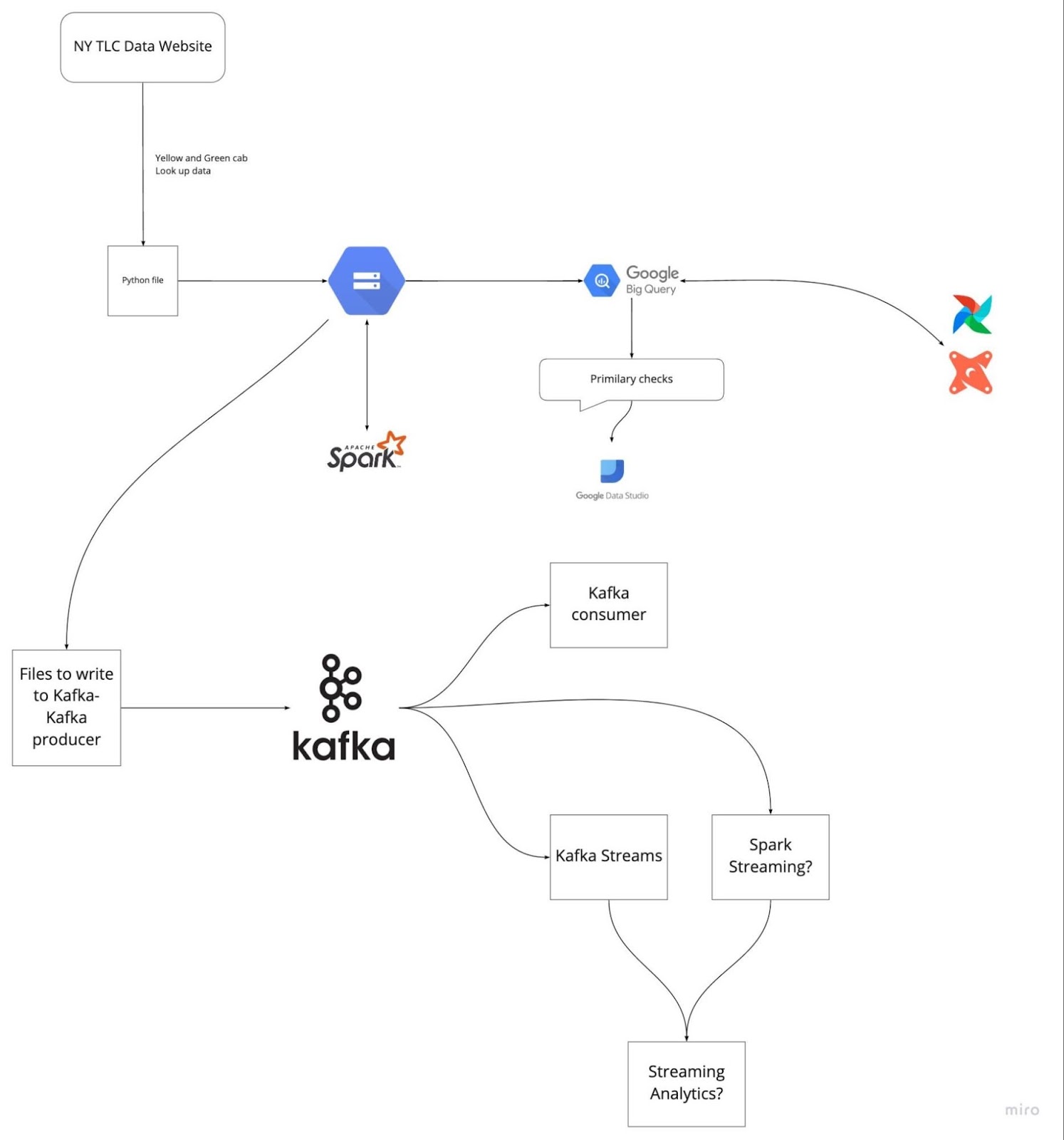
Ảnh từ DataTalksClub/data-engineering-zoomcamp
Chuẩn bị trước bằng cách rà soát năm dự án gần nhất bạn đã làm sẽ giúp bạn tránh bị khựng lại khi phỏng vấn. Hiểu rõ bài toán và giải pháp bạn đã triển khai. Luyện tập giải thích từng bước rõ ràng, súc tích.
Với vị trí quản lý kỹ thuật, câu hỏi thường liên quan đến ra quyết định, hiểu biết kinh doanh, biên soạn và duy trì tập dữ liệu, tuân thủ và chính sách bảo mật.
Kho dữ liệu phục vụ dữ liệu lịch sử cho tác vụ phân tích và ra quyết định. Nó hỗ trợ xử lý phân tích khối lượng lớn như OLAP. Kho dữ liệu được thiết kế để xử lý truy vấn phức tạp truy cập nhiều hàng và tối ưu cho tác vụ đọc nặng. Chúng hỗ trợ một vài người dùng đồng thời và được thiết kế để truy hồi lượng dữ liệu lớn nhanh chóng, hiệu quả.
Hệ quản trị cơ sở dữ liệu vận hành (OLTP) quản lý tập dữ liệu động theo thời gian thực. Chúng hỗ trợ xử lý giao dịch khối lượng lớn cho hàng nghìn khách hàng đồng thời, phù hợp cho hoạt động hằng ngày. Dữ liệu thường là thông tin hiện thời, cập nhật về giao dịch và vận hành. Hệ thống OLTP tối ưu cho tác vụ ghi nặng và xử lý truy vấn nhanh.
Quản lý thảm họa là trách nhiệm của quản lý kỹ sư dữ liệu. Kế hoạch khôi phục thảm họa đảm bảo hệ thống dữ liệu có thể được khôi phục và tiếp tục vận hành khi xảy ra tấn công mạng, hỏng phần cứng, thiên tai hay sự kiện thảm khốc khác. Các khía cạnh liên quan gồm:
Với vai trò quản lý kỹ sư dữ liệu, ra quyết định liên quan đến cân bằng giữa cân nhắc kỹ thuật và mục tiêu kinh doanh. Một số cách tiếp cận gồm:
Tuân thủ quy định bảo vệ dữ liệu bao gồm một số thực hành, ví dụ:
Khi thảo luận về dự án thách thức, bạn có thể tập trung vào:
Đánh giá và triển khai công nghệ dữ liệu mới bao gồm:
Một cách hiệu quả để ưu tiên là dựa trên tác động đến mục tiêu kinh doanh và mức độ khẩn cấp. Bạn có thể dùng khung Ma trận Eisenhower để phân loại nhiệm vụ vào bốn nhóm: khẩn cấp và quan trọng, quan trọng nhưng không khẩn, khẩn nhưng không quan trọng, và không thuộc cả hai. Ngoài ra, hãy trao đổi với bên liên quan để căn chỉnh ưu tiên và đảm bảo đội tập trung vào hoạt động giá trị cao.
Phần này khám phá các câu hỏi phỏng vấn kỹ sư dữ liệu thường gặp nhất từ các quản lý tại Facebook, Amazon và Google cho vị trí kỹ sư dữ liệu.
Một cluster Kafka gồm nhiều broker phân phối dữ liệu qua nhiều phiên bản. Kiến trúc này cung cấp khả năng mở rộng và chịu lỗi mà không downtime. Nếu cluster chính gặp sự cố, các cluster Kafka khác có thể cung cấp cùng dịch vụ, đảm bảo tính sẵn sàng cao.
Kiến trúc cluster Kafka gồm Topic, Broker, ZooKeeper, Producer và Consumer. Nó xử lý luồng dữ liệu hiệu quả cho ứng dụng big data, cho phép xây dựng ứng dụng dựa trên dữ liệu vững chắc.
Apache Airflow cho phép bạn quản lý và lập lịch pipeline cho workflow phân tích, quản trị kho dữ liệu, chuyển đổi và mô hình hóa dữ liệu. Nó cung cấp:
Để xác định IP hợp lệ, bạn có thể tách chuỗi theo dấu “.” và tạo nhiều kiểm tra để xác thực từng phần. Đây là hàm Python để thực hiện:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop chủ yếu hoạt động ở ba chế độ:
Để xử lý trùng lặp trong SQL, bạn có thể dùng từ khóa DISTINCT hoặc xóa hàng trùng bằng ROWID với MAX hoặc MIN. Ví dụ:
Dùng DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Xóa trùng bằng ROWID:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Bài toán coding phổ biến này có thể giải bằng cách tiếp cận toán học:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Trước khi phỏng vấn, bạn nên rà soát các khái niệm và thuật ngữ chuẩn trong kỹ sư dữ liệu. Dưới đây là những mảng quan trọng cần tập trung:
Chuẩn bị cho phỏng vấn kỹ sư dữ liệu có thể thách thức, nhưng với tài nguyên phù hợp và luyện tập, bạn có thể xuất sắc và giành được công việc mơ ước. Để nâng cao kỹ năng và kiến thức, hãy xem các tài nguyên hữu ích sau:
Tận dụng các khóa học này để củng cố nền tảng và dẫn trước trong sự nghiệp kỹ sư dữ liệu của bạn. Chúc bạn phỏng vấn thành công!
Tìm hiểu thêm về kỹ sư dữ liệu với các khóa học này!
Tracks
Tracks
Courses