
Programma
Ingegnere dei dati associato in SQL
30 h
Il data engineering è altamente tecnico, quindi non sorprende che gran parte del tuo processo di colloquio includa domande ed esercizi tecnici. In questa sezione trattiamo diversi tipi di domande e risposte tecniche, con focus su junior, Python, SQL, progetti e domande gestionali.
I colloqui per profili junior si concentrano su strumenti, Python e query SQL. Possono includere anche domande sulla gestione dei database e sui processi ETL, compresi coding challenge e test a casa.
Quando le aziende assumono neolaureati, vogliono assicurarsi che tu possa gestire efficacemente i loro dati e sistemi.
Esistono tre principali schemi di data modeling: stella (star), fiocco di neve (snowflake) e galassia.
Esempio di schema a stella. Immagine da guru99
Esempio di schema a fiocco di neve. Immagine da guru99
Esempio di schema a galassia. Immagine da guru99
Quando rispondi, cita gli strumenti ETL che conosci al meglio e spiega perché hai scelto determinati strumenti per specifici progetti. Discuti pro e contro di ciascuno e come si inseriscono nel tuo flusso di lavoro. Strumenti open-source popolari includono:
Se vuoi rinfrescare le tue conoscenze ETL, considera il corso Introduction to Data Engineering.
L'orchestrazione dei dati è un processo automatico per accedere a dati grezzi da più fonti, eseguire pulizia, trasformazione e modeling, e servirli per attività analitiche. Garantisce che i dati fluiscano senza intoppi tra sistemi e fasi diverse di elaborazione.
Strumenti popolari per l'orchestrazione includono:
L'analytics engineering prevede la trasformazione dei dati processati, l'applicazione di modelli statistici e la loro visualizzazione tramite report e dashboard.
Strumenti popolari per l'analytics engineering includono:
Questi strumenti aiutano ad accedere, trasformare e visualizzare i dati per ottenere insight utili e supportare i processi decisionali.
OLAP (Online Analytical Processing) analizza dati storici e supporta query complesse. È ottimizzato per carichi di lavoro orientati alla lettura ed è spesso usato nei data warehouse per attività di business intelligence. OLTP (Online Transaction Processing) è progettato per gestire dati transazionali in tempo reale. È ottimizzato per carichi di lavoro orientati alla scrittura ed è usato nei database operativi per le attività quotidiane.
La differenza principale è nello scopo: l'OLAP supporta il decision making, l'OLTP le operazioni giornaliere.
Se hai ancora dubbi, ti consiglio di leggere il post OLTP vs OLAP.
Python è il linguaggio più popolare nel data engineering grazie alla sua versatilità e al ricco ecosistema di librerie per elaborazione, analisi e automazione dei dati. Ecco alcune domande su Python che potresti incontrare in un colloquio.
Le librerie più popolari per l'elaborazione dei dati in Python includono:
Ognuna ha pro e contro; la scelta dipende dai requisiti e dalla scala dei task.
Il web scraping in Python tipicamente segue questi passaggi:
1. Accedi alla pagina web con la libreria requests:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Estrai tabelle e informazioni con BeautifulSoup:
tables = soup.find_all('table')3. Converti in un formato strutturato usando pandas:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Pulisci i dati con pandas e NumPy:
df.dropna(inplace=True) # Drop missing values5. Salva i dati in un file CSV:
df.to_csv('scraped_data.csv', index=False)In alcuni casi, pandas.read_html può semplificare il processo:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneGestire dataset che non entrano in memoria richiede strumenti e tecniche per l'elaborazione out-of-core:
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionPer garantire efficienza e performance del codice Python, considera queste pratiche:
cProfile, line_profiler o memory_profiler per individuare colli di bottiglia.import cProfile
cProfile.run('your_function()')numpy o pandas per operazioni vettoriali invece dei loop.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultIntegrità e qualità dei dati sono fondamentali per un data engineering affidabile. Best practice includono:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas per pulire e preprocessare gestendo valori mancanti, rimuovendo duplicati e correggendo errori. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Gestire i dati mancanti è un compito comune. Approcci includono:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Per gestire i limiti di rate di un'API, strategie utili includono:
Esempio con le librerie Python time e requests:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python è senza dubbio uno dei linguaggi più importanti nel data engineering. Puoi affinare le tue competenze con il nostro percorso Data Engineer in Python, che copre un curriculum completo per dotarti di concetti, linguaggi, strumenti e framework moderni.
La fase di coding in SQL è una parte significativa del processo di selezione. Esercitarti con script semplici e complessi può aiutarti a prepararti. Potrebbero chiederti di scrivere query per analytics, common table expression, ranking, aggiunta di subtotali e funzioni temporanee.
Le CTE sono usate per semplificare join complessi ed eseguire sottoquery. Rendono le query più leggibili e manutenibili. Ecco un esempio di CTE che mostra tutti gli studenti con major in Science e voto A:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);Usando una CTE, la query diventa:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);Le CTE possono essere utilizzate per problemi più complessi e si possono concatenare più CTE.
I data engineer classificano spesso valori in base a parametri come vendite e profitto. La funzione RANK() viene usata per classificare i dati in base a una colonna:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;In alternativa, puoi usare DENSE_RANK(), che non salta i ranghi successivi in caso di parità.
Come in Python, puoi creare funzioni in SQL per rendere le query più eleganti ed evitare ripetitive case statement. Ecco un esempio di funzione temporanea get_gender:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Questo approccio rende il tuo SQL più pulito e manutenibile.
L'aggiunta di subtotali si può ottenere con le funzioni GROUP BY e ROLLUP(). Ecco un esempio:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Questa query fornirà un subtotale per ogni reparto e un totale generale finale.
Gestire i dati mancanti è essenziale per mantenere l'integrità. Approcci comuni includono:
COALESCE(): restituisce il primo valore non nullo nell'elenco.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE: per gestire condizionalmente i valori mancanti. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;L'aggregazione usa funzioni come SUM(), AVG(), COUNT(), MIN() e MAX(). Ecco un esempio:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Per ottimizzare le query SQL, puoi:
SELECT * specificando solo le colonne necessarie.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;Risolvere esercizi di SQL è il modo migliore per fare pratica e ripassare concetti dimenticati. Puoi valutare le tue skill SQL sostenendo il test Data Analysis in SQL di DataCamp (serve un account per accedere alla valutazione).
Dopo i colloqui generali, di solito si passa a una fase tecnica con challenge di coding, problem solving, progettazione di sistemi database alla lavagna, esame a casa e domande analitiche.
Questa fase può essere intensa, quindi conoscere alcune tipiche domande e risposte di data engineering può aiutarti a eccellere.
Questa risposta dovrebbe venire naturale se hai già lavorato a un progetto di data engineering come studente o professionista. Detto questo, prepararsi in anticipo aiuta sempre. Ecco come strutturare la tua risposta:
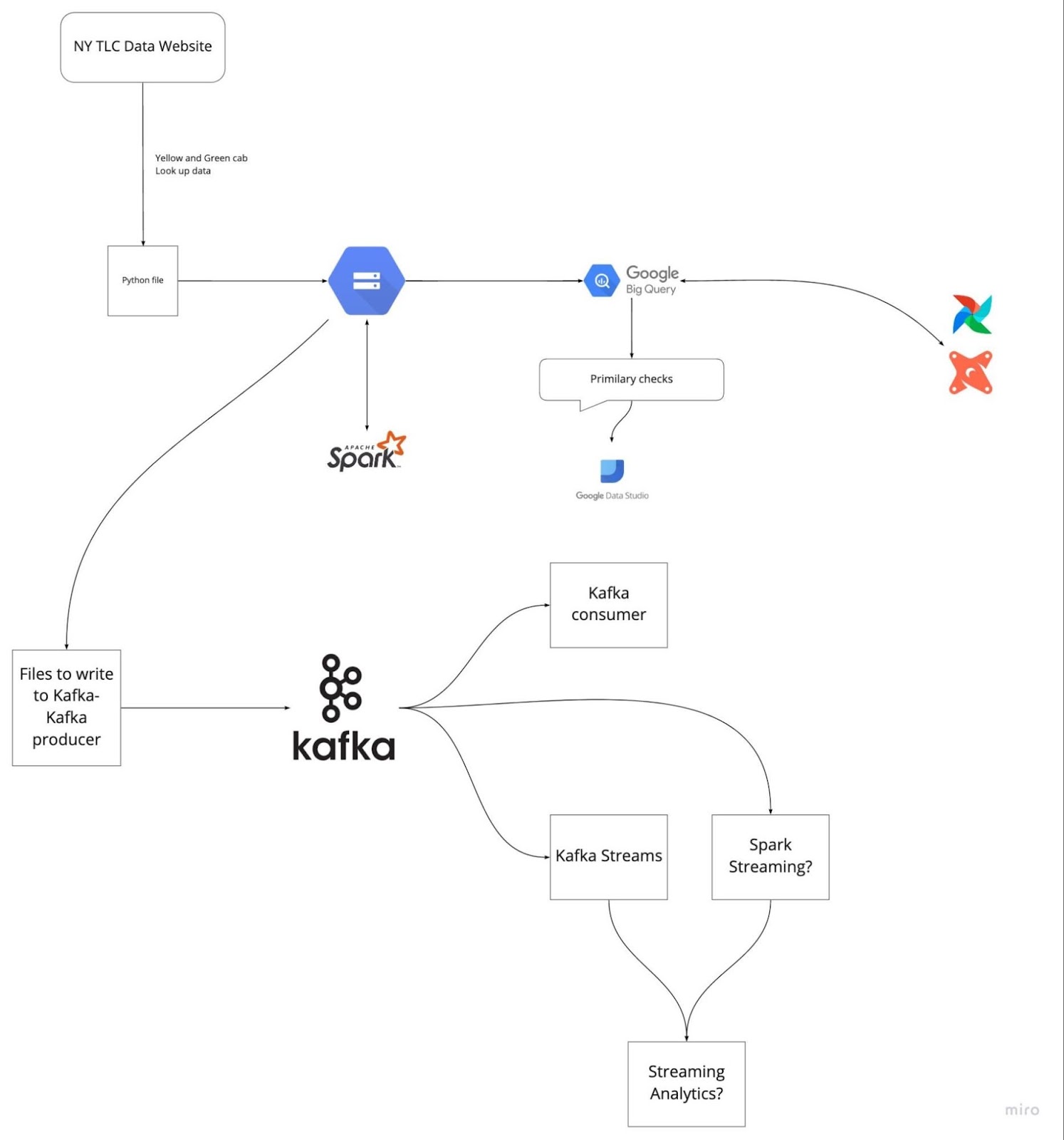
Immagine da DataTalksClub/data-engineering-zoomcamp
Prepararti in anticipo rivedendo gli ultimi cinque progetti a cui hai lavorato può aiutarti a evitare blocchi durante il colloquio. Comprendi il problema e le soluzioni implementate. Esercitati a spiegare ogni passaggio in modo chiaro e conciso.
Per i ruoli di engineering manager, le domande riguardano in genere decision making, comprensione del business, cura e mantenimento dei dataset, conformità e policy di sicurezza.
Un data warehouse serve dati storici per attività di data analytics e decision-making. Supporta elaborazioni analitiche ad alto volume, come l'Online Analytical Processing (OLAP). È progettato per gestire query complesse che accedono a molte righe ed è ottimizzato per operazioni di lettura. Supporta pochi utenti concorrenti ed è pensato per recuperare rapidamente grandi volumi di dati in modo efficiente.
I sistemi di database operativi (OLTP) gestiscono dataset dinamici in tempo reale. Supportano l'elaborazione di transazioni ad alto volume per migliaia di client concorrenti, risultando adatti alle operazioni quotidiane. I dati sono solitamente aggiornati e relativi a transazioni e operazioni. I sistemi OLTP sono ottimizzati per operazioni di scrittura e query veloci.
La gestione dei disastri è responsabilità di un data engineering manager. Un piano di disaster recovery garantisce che i sistemi dati possano essere ripristinati e continuare a operare in caso di attacchi informatici, guasti hardware, disastri naturali o altri eventi catastrofici. Aspetti rilevanti includono:
Come data engineering manager, il decision making implica bilanciare considerazioni tecniche e obiettivi di business. Alcuni approcci includono:
La conformità alle normative sulla protezione dei dati comporta diverse pratiche, ad esempio:
Quando parli di un progetto impegnativo, puoi focalizzarti su:
Valutare e implementare nuove tecnologie dati implica:
Un modo efficace è basarsi sull'impatto sugli obiettivi di business e sull'urgenza. Puoi usare framework come la Matrice di Eisenhower per categorizzare i task in quattro quadranti: urgente e importante, importante ma non urgente, urgente ma non importante, e nessuno dei due. Inoltre, comunica con gli stakeholder per allineare le priorità e assicurare che il team si concentri sulle attività a maggior valore.
In questa sezione esploriamo le domande più frequenti poste da manager di Facebook, Amazon e Google per posizioni di data engineering.
Un cluster Kafka è composto da più broker che distribuiscono i dati tra istanze multiple. Questa architettura offre scalabilità e tolleranza ai guasti senza downtime. Se il cluster primario cade, altri cluster Kafka possono fornire gli stessi servizi, garantendo alta disponibilità.
L'architettura del cluster Kafka comprende Topic, Broker, ZooKeeper, Producer e Consumer. Gestisce in modo efficiente stream di dati per applicazioni big data, abilitando la creazione di applicazioni data-driven robuste.
Apache Airflow consente di gestire e schedulare pipeline per workflow analitici, gestione di data warehouse e trasformazione e modeling dei dati. Fornisce:
Per determinarne la validità, puoi dividere la stringa su “.” ed effettuare vari controlli per validare ciascun segmento. Ecco una funzione Python per farlo:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop funziona principalmente in tre modalità:
Per gestire i duplicati in SQL, puoi usare la keyword DISTINCT oppure eliminare le righe duplicate usando ROWID con le funzioni MAX o MIN. Ecco alcuni esempi:
Uso di DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Eliminazione dei duplicati usando ROWID:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Questa challenge comune si può risolvere con un approccio matematico:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Prima di presentarti a un colloquio, dovresti rivedere tutti i concetti e i termini standard usati nel data engineering. Ecco le aree più importanti su cui concentrarti:
Prepararsi a un colloquio di data engineering può essere impegnativo, ma con le giuste risorse e pratica puoi eccellere e ottenere il lavoro dei tuoi sogni. Per migliorare ulteriormente competenze e conoscenze, dai un'occhiata a queste risorse utili:
Sfrutta questi corsi per consolidare le basi e restare un passo avanti nella tua carriera nel data engineering. In bocca al lupo per i colloqui!
Scopri di più sul data engineering con questi corsi!
Programma
Programma
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

