
Leerpad
Associate Data Engineer in SQL
30 Hr
Data engineering is sterk technisch, dus het is geen verrassing dat het grootste deel van je sollicitatieproces uit technische vragen en oefeningen bestaat. In deze sectie behandelen we verschillende soorten technische vragen en antwoorden, met focus op junior, Python, SQL, projectgerichte en managementvragen.
Junior-interviews richten zich op tools, Python en SQL-queries. Er kunnen ook vragen komen over databasemanagement en ETL-processen, inclusief codeeropdrachten en thuisopdrachten.
Wanneer bedrijven starters aannemen, willen ze zeker weten dat je effectief met hun data en systemen kunt werken.
Er zijn drie primaire datamodelleringsschema’s: ster, sneeuwvlok en galaxie.
Voorbeeld van een sterschema. Afbeelding van guru99
Voorbeeld van een sneeuwvlokschema. Afbeelding van guru99
Voorbeeld van een galaxieschema. Afbeelding van guru99
Noem de ETL-tools die je beheerst en leg uit waarom je voor bepaalde projecten specifieke tools hebt gekozen. Bespreek de voor- en nadelen van elke tool en hoe ze in je workflow passen. Populaire open-sourcetools zijn onder andere:
Moet je je ETL-kennis opfrissen? Volg dan de cursus Introduction to Data Engineering.
Data-orchestratie is een geautomatiseerd proces waarbij ruwe data uit meerdere bronnen wordt opgehaald, opgeschoond, getransformeerd en gemodelleerd en vervolgens beschikbaar wordt gemaakt voor analytische taken. Het zorgt voor een soepele datastroom tussen systemen en verwerkingsstadia.
Populaire tools voor data-orchestratie zijn:
Analytics engineering omvat het transformeren van verwerkte data, het toepassen van statistische modellen en het visualiseren via rapporten en dashboards.
Populaire tools voor analytics engineering zijn:
Met deze tools kun je data ontsluiten, transformeren en visualiseren om inzichten te verkrijgen en besluitvorming te ondersteunen.
OLAP (Online Analytical Processing) analyseert historische data en ondersteunt complexe queries. Het is geoptimaliseerd voor read-heavy workloads en wordt vaak gebruikt in datawarehouses voor business intelligence. OLTP (Online Transaction Processing) is ontworpen voor het beheren van realtime transactionele data. Het is geoptimaliseerd voor write-heavy workloads en wordt gebruikt in operationele databases voor dagelijkse bedrijfsvoering.
Het belangrijkste verschil zit in het doel: OLAP ondersteunt besluitvorming, OLTP ondersteunt dagelijkse operaties.
Heb je nog twijfels? Lees dan de blog OLTP vs OLAP.
Python is de populairste taal in data engineering vanwege de veelzijdigheid en de rijke ecosysteem aan libraries voor dataverwerking, analyse en automatisering. Hier zijn enkele Python-gerelateerde vragen die je kunt tegenkomen.
De populairste dataverwerkingslibraries in Python zijn:
Elke library heeft voor- en nadelen; de keuze hangt af van de eisen en schaal van je taak.
Webscraping in Python omvat doorgaans de volgende stappen:
1. Toegang krijgen tot de webpagina met de requests-library:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Tabellen en informatie extraheren met BeautifulSoup:
tables = soup.find_all('table')3. Omzetten naar een gestructureerd formaat met pandas:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Data opschonen met pandas en NumPy:
df.dropna(inplace=True) # Drop missing values5. Data opslaan als CSV-bestand:
df.to_csv('scraped_data.csv', index=False)In sommige gevallen kan pandas.read_html het proces vereenvoudigen:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneVoor grote datasets die niet in het geheugen passen, gebruik je tools en technieken voor out-of-core computing:
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionPas de volgende praktijken toe:
cProfile, line_profiler of memory_profiler om bottlenecks te vinden.import cProfile
cProfile.run('your_function()')numpy of pandas voor gevectoriseerde bewerkingen in plaats van lussen.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultDataintegriteit en -kwaliteit zijn cruciaal. Best practices zijn onder andere:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas om missende waarden te verwerken, duplicaten te verwijderen en fouten te corrigeren. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Missende data verwerken is een veelvoorkomende taak. Aanpakken zijn onder andere:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Strategieën zijn onder andere:
Voorbeeld met de Python-time-library en de module requests:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python is zonder twijfel een van de belangrijkste talen in data engineering. Je kunt je skills aanscherpen met onze Data Engineer in Python-track, met een complete leerlijn rond moderne concepten, programmeertalen, tools en frameworks.
De SQL-codeerfase is een belangrijk onderdeel van het wervingsproces. Oefen met uiteenlopende eenvoudige en complexe scripts. Interviewers kunnen je vragen queries te schrijven voor data-analyse, common table expressions, ranking, subtotals en tijdelijke functies.
CTE’s worden gebruikt om complexe joins te vereenvoudigen en subqueries uit te voeren. Ze maken SQL-queries leesbaarder en onderhoudsvriendelijker. Hier is een voorbeeld van een CTE die alle studenten met Science als major en cijfer A toont:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);Met een CTE wordt de query:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);CTE’s kun je ook voor complexere problemen gebruiken en je kunt meerdere CTE’s aaneenkoppelen.
Data engineers rangschikken vaak waarden op basis van parameters zoals omzet en winst. De functie RANK() wordt gebruikt om te rangschikken op een specifieke kolom:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Alternatief kun je DENSE_RANK() gebruiken, dat geen rangen overslaat bij gelijke waarden.
Net als in Python kun je in SQL functies maken om je queries eleganter te maken en repetitieve case-statements te vermijden. Hier is een voorbeeld van een tijdelijke functie get_gender:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Deze aanpak maakt je SQL-code overzichtelijker en beter onderhoudbaar.
Subtotals kun je maken met GROUP BY en ROLLUP(). Bijvoorbeeld:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Deze query geeft een subtotaal per afdeling en een totaaltelling aan het einde.
Het verwerken van missende data is essentieel voor dataintegriteit. Veelgebruikte methoden:
COALESCE() gebruiken: deze functie retourneert de eerste niet-null waarde in de lijst.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE-statements gebruiken: om missende waarden conditioneel af te handelen. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;Data-aggregatie omvat gebruik van aggregatiefuncties zoals SUM(), AVG(), COUNT(), MIN() en MAX(). Bijvoorbeeld:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Je kunt onder meer:
SELECT * vermijden en alleen benodigde kolommen selecteren.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;Het oplossen van SQL-oefeningen is de beste manier om te oefenen en vergeten concepten op te frissen. Je kunt je SQL-skills toetsen met DataCamp’s Data Analysis in SQL-test (je hebt een account nodig om de toets te maken).
Na de algemene rondes volgt meestal een technische fase met codeeropdrachten, probleemoplossing, systeem- en databasontwerp op een whiteboard, een thuisexamen en analytische vragen.
Deze fase kan intens zijn, dus kennis van veelvoorkomende vragen en antwoorden helpt je excelleren.
Als je eerder aan een data-engineeringproject hebt gewerkt als student of professional, komt dit antwoord vanzelf. Toch is voorbereiding nuttig. Zo structureer je je antwoord:
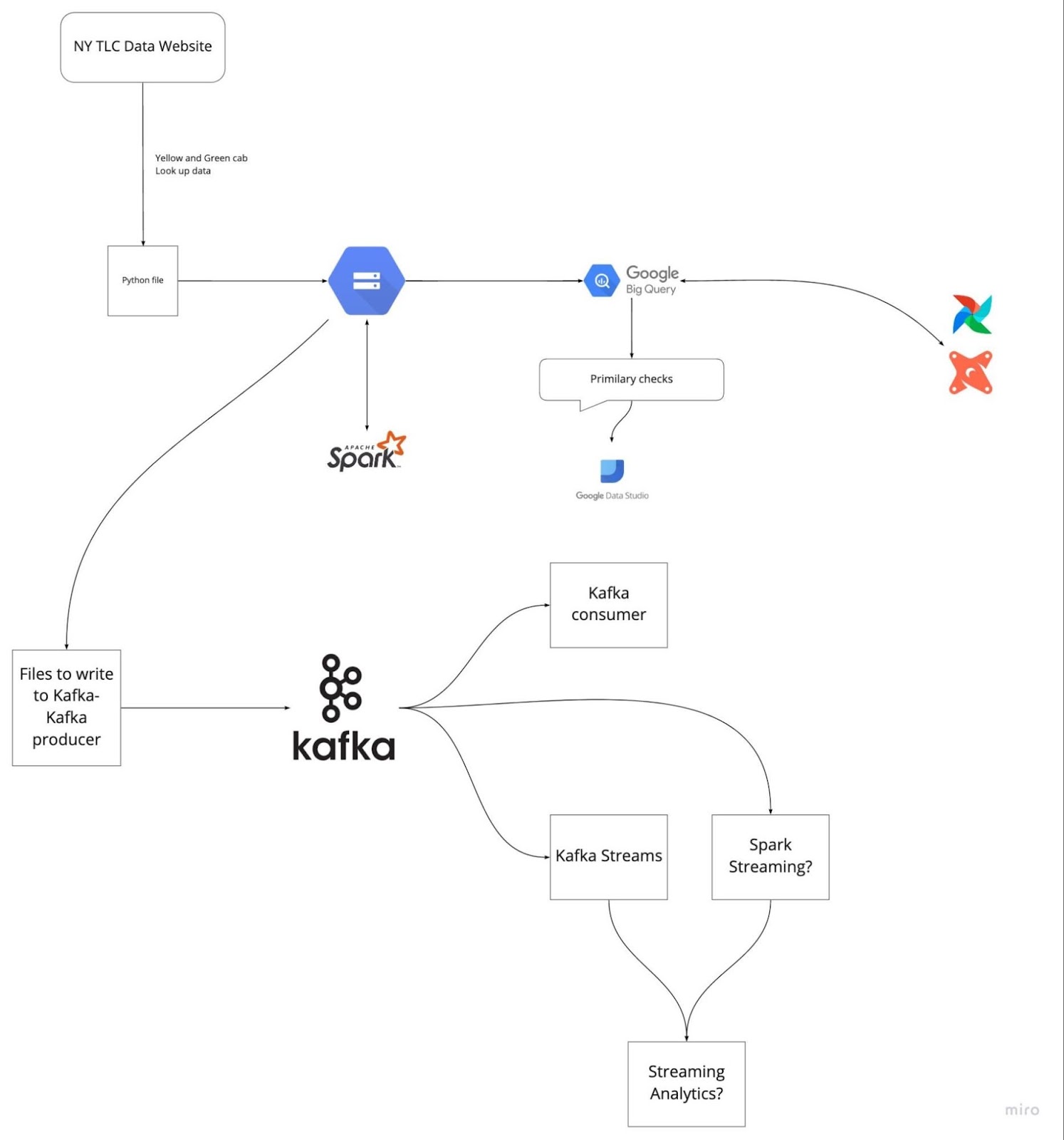
Afbeelding van DataTalksClub/data-engineering-zoomcamp
Voorbereiden door je laatste vijf projecten te herzien helpt om vastlopers in het gesprek te voorkomen. Begrijp de probleemstelling en je oplossingen. Oefen om elke stap helder en beknopt uit te leggen.
Voor engineeringmanagers gaan vragen doorgaans over besluitvorming, businessinzicht, het samenstellen en onderhouden van datasets, compliance en beveiligingsbeleid.
Een datawarehouse bevat historische data voor analytische taken en besluitvorming. Het ondersteunt high-volume analytische verwerking, zoals Online Analytical Processing (OLAP). Datawarehouses zijn ontworpen voor complexe queries die veel rijen aanspreken en zijn geoptimaliseerd voor leesintensieve operaties. Ze ondersteunen relatief weinig gelijktijdige gebruikers en zijn gebouwd om grote hoeveelheden data snel op te halen.
Operationele Database Management Systemen (OLTP) beheren dynamische datasets in realtime. Ze ondersteunen transactieverwerking op grote schaal voor duizenden gelijktijdige clients en zijn geschikt voor dagelijkse operaties. De data bestaat doorgaans uit actuele informatie over transacties en operaties. OLTP-systemen zijn geoptimaliseerd voor schrijfintensieve operaties en snelle queryverwerking.
Rampenbeheer is de verantwoordelijkheid van een data-engineeringmanager. Een disaster recovery-plan zorgt ervoor dat datasystemen kunnen worden hersteld en blijven draaien bij een cyberaanval, hardwarestoring, natuurramp of andere calamiteiten. Relevante aspecten zijn:
Als manager balanceer je technische overwegingen met bedrijfsdoelen. Aanpakken zijn onder andere:
Compliance met privacywetgeving omvat onder meer:
Focus bij een uitdagend project op:
Dit omvat:
Een effectieve manier is prioriteren op basis van impact op bedrijfsdoelen en urgentie. Je kunt frameworks als de Eisenhower-matrix gebruiken om taken in vier kwadranten te plaatsen: urgent en belangrijk, belangrijk maar niet urgent, urgent maar niet belangrijk, en geen van beide. Communiceer daarnaast met stakeholders om prioriteiten te alignen en focus te houden op activiteiten met hoge waarde.
In deze sectie bekijken we de meest gestelde data-engineeringvragen door managers van Facebook, Amazon en Google voor data-engineeringsfuncties.
Een Kafka-cluster bestaat uit meerdere brokers die data over meerdere instanties verdelen. Deze architectuur biedt schaalbaarheid en fouttolerantie zonder downtime. Als het primaire cluster uitvalt, kunnen andere Kafka-clusters dezelfde services leveren, waardoor hoge beschikbaarheid is gegarandeerd.
De Kafka-clusterarchitectuur bestaat uit Topics, Brokers, ZooKeeper, Producers en Consumers. Het verwerkt datastromen voor bigdata-toepassingen efficiënt en maakt robuuste datagedreven applicaties mogelijk.
Apache Airflow laat je pijplijnen beheren en plannen voor analytische workflows, datawarehousebeheer en datatransformatie en -modellering. Het biedt:
Split de string op "." en voer meerdere checks uit om elk segment te valideren. Hier is een Python-functie:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop werkt hoofdzakelijk in drie modi:
Je kunt het sleutelwoord DISTINCT gebruiken of dubbele rijen verwijderen met ROWID in combinatie met MAX of MIN. Bijvoorbeeld:
Met DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Duplicaten verwijderen met ROWID:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Deze veelvoorkomende codeeropgave kun je wiskundig oplossen:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Voordat je op gesprek gaat, moet je de concepten en standaardtermen in data engineering herhalen. Focus op de volgende gebieden:
Voorbereiden op een data-engineeringsgesprek kan uitdagend zijn, maar met de juiste resources en oefening kun je uitblinken en je droombaan bemachtigen. Vergroot je skills en kennis met deze waardevolle bronnen:
Maak gebruik van deze cursussen om je basis te versterken en voorop te blijven in je data-engineeringscarrière. Succes met je sollicitaties!
Leer meer over data engineering met deze cursussen!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
