
Cursus
Ingénieur de données associé en SQL
30 h
L'ingénierie des données est un domaine hautement technique, il n'est donc pas surprenant que la majeure partie de votre processus d'entretien comprenne des questions et des exercices techniques. Dans cette section, nous aborderons différents types de questions et réponses techniques, en mettant l'accent sur les questions relatives aux débutants, à Python, à SQL, aux projets et à la gestion.
Les entretiens pour les postes d'ingénieurs juniors se concentrent sur les outils, Python et les requêtes SQL. Ils peuvent également inclure des questions relatives à la gestion de bases de données et aux processus ETL, y compris des défis de codage et des tests à réaliser à domicile.
Lorsque les entreprises recrutent de jeunes diplômés, elles souhaitent s'assurer que vous êtes en mesure de gérer efficacement leurs données et leurs systèmes.
Il existe trois principaux schémas de conception de modélisation des données: étoile, flocon de neige et galaxie.
Exemple de schéma en étoile. Image provenant de guru99
Exemple de schéma Snowflake. Image provenant de guru99
Exemple de schéma Galaxy. Image provenant de guru99
En répondant à cette question, veuillez mentionner les outils ETL que vous maîtrisez et expliquer pourquoi vous avez choisi des outils spécifiques pour certains projets. Veuillez examiner les avantages et les inconvénients de chaque outil et leur intégration dans votre flux de travail. Les outils open source populaires comprennent :
Si vous avez besoin de rafraîchir vos connaissances en matière d'ETL, envisagez de suivre le cours Introduction à l'ingénierie des données.
L'orchestration des données est un processus automatisé qui consiste à accéder à des données brutes provenant de plusieurs sources, à effectuer des opérations de nettoyage, de transformation et de modélisation des données, puis à les mettre à disposition pour des tâches analytiques. Il garantit la fluidité des flux de données entre les différents systèmes et étapes du traitement.
Les outils populaires pour l'orchestration des données comprennent :
L'ingénierie analytique consiste à transformer les données traitées, à appliquer des modèles statistiques et à les visualiser à l'aide de rapports et de tableaux de bord.
Les outils populaires pour l'ingénierie analytique comprennent :
Ces outils facilitent l'accès, la transformation et la visualisation des données afin d'en tirer des informations pertinentes et d'appuyer les processus décisionnels.
OLAP (Online Analytical Processing) analyse les données historiques et prend en charge les requêtes complexes. Il est optimisé pour les charges de travail impliquant de nombreuses lectures et est fréquemment utilisé dans les entrepôts de données pour les tâches de veille économique. L'OLTP ( Online Transaction Processing) est conçu pour gérer les données transactionnelles en temps réel. Il est optimisé pour les charges de travail impliquant de nombreuses écritures et est utilisé dans les bases de données opérationnelles pour les opérations commerciales quotidiennes.
La principale différence réside dans leur objectif : OLAP facilite la prise de décision, tandis qu'OLTP soutient les opérations quotidiennes.
Si vous avez encore des doutes, je vous recommande de lire l'article de blog OLTP vs OLAP.
Python est le langage le plus populaire dans le domaine de l'ingénierie des données en raison de sa polyvalence et de la richesse de son écosystème de bibliothèques disponibles pour le traitement, l'analyse et l'automatisation des données. Voici quelques questions relatives à Python que vous pourriez rencontrer lors d'un entretien d'embauche dans le domaine de l'ingénierie des données.
Les bibliothèques de traitement de données les plus populaires en Python comprennent :
Chacune de ces bibliothèques présente des avantages et des inconvénients, et le choix dépend des exigences spécifiques en matière de données et de l'ampleur des tâches de traitement des données.
Le web scraping en Python implique généralement les étapes suivantes :
1. Veuillez accéder à la page Web en utilisant la bibliothèque requests:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Extraire des tableaux et des informations à l'aide de BeautifulSoup :
tables = soup.find_all('table')3. Veuillez le convertir en un format structuré à l'aide de pandas :
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Nettoyez les données à l'aide de pandas et NumPy :
df.dropna(inplace=True) # Drop missing values5. Veuillez enregistrer les données sous forme de fichier CSV :
df.to_csv('scraped_data.csv', index=False)Dans certains cas, pandas.read_html peut simplifier le processus :
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneLe traitement de grands ensembles de données qui ne tiennent pas en mémoire nécessite l'utilisation d'outils et de techniques conçus pour le calcul hors mémoire :
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionAfin de garantir l'efficacité et l'optimisation des performances du code Python, veuillez prendre en considération les pratiques suivantes :
cProfile, line_profiler ou memory_profiler pour identifier les goulots d'étranglement dans votre code.import cProfile
cProfile.run('your_function()')numpy ou pandas pour les opérations vectorisées au lieu des boucles.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultL'intégrité et la qualité des données sont essentielles pour garantir la fiabilité de l'ingénierie des données. Les meilleures pratiques comprennent :
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas pour nettoyer et prétraiter les données en traitant les valeurs manquantes, en supprimant les doublons et en corrigeant les erreurs. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Le traitement des données manquantes est une tâche courante dans l'ingénierie des données. Les approches comprennent :
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Pour gérer les limites de débit des API, il existe plusieurs stratégies, telles que :
Exemple utilisant la bibliothèque Python time et le module requests:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python est sans aucun doute l'un des langages les plus importants dans le domaine de l'ingénierie des données. Vous pouvez perfectionner vos compétences en suivant notre cursus Data Engineer in Python, qui propose un programme complet vous permettant d'acquérir les concepts, les langages de programmation, les outils et les frameworks modernes en matière d'ingénierie des données.
La phase de codage SQL constitue une partie importante du processus de recrutement en ingénierie des données. La pratique de divers scripts simples et complexes peut vous aider à vous préparer. Les examinateurs peuvent vous demander de rédiger des requêtes pour l'analyse de données, les expressions de table communes, le classement, l'ajout de sous-totaux et les fonctions temporaires.
Les CTE sont utilisées pour simplifier les jointures complexes et exécuter des sous-requêtes. Ils contribuent à rendre les requêtes SQL plus lisibles et plus faciles à maintenir. Voici un exemple de CTE qui affiche tous les étudiants ayant une spécialisation en sciences et une note A :
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);En utilisant une CTE, la requête devient :
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);Les CTE peuvent être utilisées pour des problèmes plus complexes et plusieurs CTE peuvent être enchaînées.
Les ingénieurs de données classent généralement les valeurs en fonction de paramètres tels que les ventes et les bénéfices. La fonction ` RANK() ` est utilisée pour classer les données en fonction d'une colonne spécifique :
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Vous pouvez également utiliser DENSE_RANK(), qui ne saute pas les rangs suivants si les valeurs sont identiques.
Tout comme en Python, vous pouvez créer des fonctions en SQL afin de rendre vos requêtes plus élégantes et d'éviter les instructions case répétitives. Voici un exemple de fonction temporaire get_gender:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Cette approche rend votre code SQL plus clair et plus facile à maintenir.
L'ajout de sous-totaux peut être réalisé à l'aide des fonctions GROUP BY et ROLLUP(). Voici un exemple :
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Cette requête vous fournira un sous-total pour chaque département et un total général à la fin.
La gestion des données manquantes est essentielle pour maintenir l'intégrité des données. Les approches courantes comprennent :
COALESCE(): Cette fonction renvoie la première valeur non nulle de la liste.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE » : Pour traiter les valeurs manquantes de manière conditionnelle. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;L'agrégation de données implique l'utilisation de fonctions d'agrégation telles que SUM(), AVG(), COUNT(), MIN() et MAX(). Voici un exemple :
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Pour optimiser les requêtes SQL, vous pouvez :
SELECT * e en spécifiant uniquement les colonnes requises.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;La résolution d'exercices de codage SQL constitue la méthode la plus efficace pour s'entraîner et réviser les concepts oubliés. Vous pouvez évaluer vos compétences en SQL en passant le test « Data Analysis in SQL » (Analyse de données en SQL ) de DataCamp (un compte est nécessaire pour accéder à cette évaluation).
Après les entretiens généraux, vous passerez généralement à une étape technique qui comprend des défis de codage, des exercices de résolution de problèmes, la conception d'un système de base de données sur un tableau blanc, un examen à domicile et des questions analytiques.
Cette étape peut être assez intense, donc connaître certaines des questions et réponses habituelles des entretiens d'embauche en ingénierie des données peut vous aider à réussir votre entretien.
Cette réponse devrait vous venir naturellement si vous avez déjà travaillé sur un projet d'ingénierie des données en tant qu'étudiant ou professionnel. Cela étant dit, il est toujours utile de se préparer à l'avance. Voici comment structurer votre réponse :
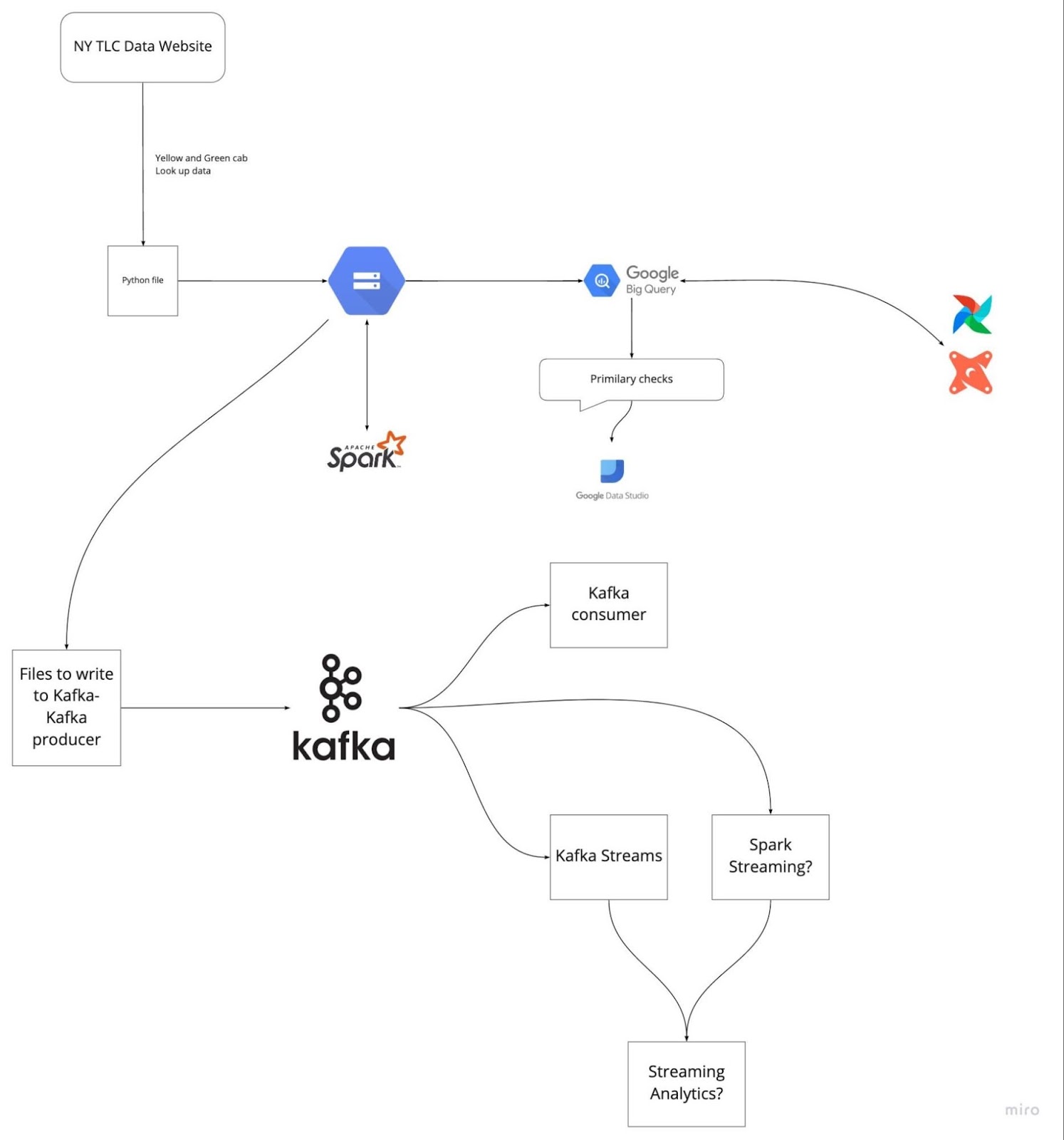
Image provenant de DataTalksClub/data-engineering-zoomcamp
En vous préparant à l'avance en passant en revue les cinq derniers projets sur lesquels vous avez travaillé, vous éviterez de vous bloquer pendant l'entretien. Veuillez comprendre l'énoncé du problème et les solutions que vous avez mises en œuvre. Entraînez-vous à expliquer chaque étape de manière claire et concise.
Pour les postes de responsable ingénierie, les questions portent généralement sur la prise de décision, la compréhension des activités commerciales, la gestion et la maintenance des ensembles de données, la conformité et les politiques de sécurité.
Un entrepôt de données fournit des données historiques pour les tâches d'analyse de données et la prise de décision. Il prend en charge le traitement analytique de volumes importants, tel que le traitement analytique en ligne (OLAP). Les entrepôts de données sont conçus pour traiter des requêtes complexes qui accèdent à plusieurs lignes et sont optimisés pour les opérations à forte intensité de lecture. Ils prennent en charge plusieurs utilisateurs simultanés et sont conçus pour récupérer rapidement et efficacement de grands volumes de données.
Les systèmes de gestion de bases de données opérationnelles (OLTP) gèrent des ensembles de données dynamiques en temps réel. Ils prennent en charge le traitement de transactions à haut volume pour des milliers de clients simultanés, ce qui les rend adaptés aux opérations quotidiennes. Les données comprennent généralement des informations actuelles et à jour sur les transactions et les opérations commerciales. Les systèmes OLTP sont optimisés pour les opérations impliquant de nombreuses écritures et le traitement rapide des requêtes.
La gestion des catastrophes relève de la responsabilité d'un responsable de l'ingénierie des données. Un plan de reprise après sinistre garantit que les systèmes de données peuvent être restaurés et continuer à fonctionner en cas de cyberattaque, de défaillance matérielle, de catastrophe naturelle ou d'autres événements catastrophiques. Les aspects pertinents comprennent :
En tant que responsable de l'ingénierie des données, la prise de décision implique de trouver un équilibre entre les considérations techniques et les objectifs commerciaux. Certaines approches comprennent :
La conformité aux réglementations en matière de protection des données implique plusieurs pratiques, par exemple :
Lorsque vous discutez d'un projet ambitieux, vous pouvez vous concentrer sur les aspects suivants :
L'évaluation et la mise en œuvre de nouvelles technologies de données impliquent :
Une méthode efficace pour hiérarchiser les tâches consiste à se baser sur leur impact sur les objectifs commerciaux et leur urgence. Vous pouvez utiliser des cadres tels que la matrice d'Eisenhower pour classer les tâches en quatre catégories : urgentes et importantes, importantes mais non urgentes, urgentes mais non importantes, et ni urgentes ni importantes. De plus, communiquez avec les parties prenantes afin d'harmoniser les priorités et de vous assurer que l'équipe se concentre sur les activités à forte valeur ajoutée.
Dans cette section, nous examinons les questions les plus fréquemment posées lors des entretiens d'embauche pour des postes d'ingénieur de données par les responsables de Facebook, Amazon et Google.
Un cluster Kafka est constitué de plusieurs brokers qui distribuent les données sur plusieurs instances. Cette architecture offre évolutivité et tolérance aux pannes sans interruption de service. Si le cluster principal tombe en panne, d'autres clusters Kafka peuvent fournir les mêmes services, garantissant ainsi une haute disponibilité.
L'architecture du cluster Kafka comprend des sujets, des courtiers, ZooKeeper, des producteurs et des consommateurs. Il gère efficacement les flux de données pour les applications Big Data, permettant ainsi la création d'applications robustes basées sur les données.
Apache Airflow vous permet de gérer et de planifier des pipelines pour les workflows analytiques, la gestion des entrepôts de données, ainsi que la transformation et la modélisation des données. Il prévoit :
Pour déterminer la validité d'une adresse IP, vous pouvez diviser la chaîne au niveau du « . » et créer plusieurs vérifications pour valider chaque segment. Voici une fonction Python permettant d'atteindre cet objectif :
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop fonctionne principalement selon trois modes :
Pour gérer les doublons dans SQL, vous pouvez utiliser le mot-clé « DISTINCT » ou supprimer les lignes en double à l'aide de « ROWID » avec la fonction « MAX » ou « MIN ». Voici quelques exemples :
Utilisation d'DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Suppression des doublons à l'aide d'ROWID:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Ce défi de codage courant peut être résolu à l'aide d'une approche mathématique :
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Avant de vous présenter à un entretien, il est recommandé de revoir tous les concepts et termes standard utilisés dans le domaine de l'ingénierie des données. Voici quelques-uns des domaines les plus importants sur lesquels il convient de se concentrer :
Se préparer à un entretien d'embauche dans le domaine de l'ingénierie des données peut s'avérer difficile, mais avec les bonnes ressources et de la pratique, vous pouvez exceller et décrocher l'emploi de vos rêves. Pour approfondir vos compétences et vos connaissances, veuillez consulter ces ressources utiles :
Profitez de ces cours pour consolider vos bases et rester à la pointe dans votre carrière d'ingénieur de données. Nous vous souhaitons bonne chance pour vos entretiens.
Veuillez approfondir vos connaissances en ingénierie des données grâce à ces cours.
Cursus
Cursus
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
Tutoriel
Sejal Jaiswal