
Program
Doğal Dil İşleme Python'da
20 sa
Görsel-Dil Modelleri (VLM) yapay zekâ sistemlerinin hem görüntüleri hem de metni anlamasını ve bu ikisi üzerine akıl yürütmesini sağlayarak sektörleri hızla dönüştürüyor. Geleneksel bilgisayarlı görü modellerinden farklı olarak, modern VLM’ler karmaşık görselleri yorumlayabilir, görsel içerikle ilgili ayrıntılı soruları yanıtlayabilir ve içinde gömülü metin bulunan videoları ve belgeleri dahi işleyebilir.
Bu özellik, hızdan çok hassasiyetin önemli olduğu tıbbi teşhis, otomatik kalite kontrol ve hassas uygulamalar için onları vazgeçilmez kılar.
Bu blogda, açık kaynak ve tescilli seçenekler dâhil olmak üzere 2026’nın en iyi görsel-dil modellerini inceleyeceğiz. Benzersiz yeteneklerini vurguladıktan sonra performanslarını ve kıyaslama sonuçlarını sunacağız. Geliştiriciler ve araştırmacılar için, modelleri hızlıca kendiniz deneyebilmeniz adına örnek kod parçacıkları da ekledik.
Bu modellerin temelleri hakkında daha fazlasını öğrenmek istiyorsanız mutlaka Python ile Görüntü İşleme beceri yoluna göz atın.
Gemini 2.5 Pro Google’ın en gelişmiş yapay zekâ modeli olup, görsel ve kodlama görevleri için LMArena ve WebDevArena lider tablolarında şu anda zirvede. Metin, görsel, ses ve video genelinde karmaşık akıl yürütme ve anlama için tasarlanmıştır.
Görsel-dil yetenekleri açısından Open LLM lider tablosunda en üst modellerden biri olarak yer alır. Gemini 2.5 Pro, görselleri ve videoları yorumlayabilir; bağlama duyarlı, ayrıntılı açıklamalar üreterek görsel içerikle ilgili soruları yanıtlayabilir.
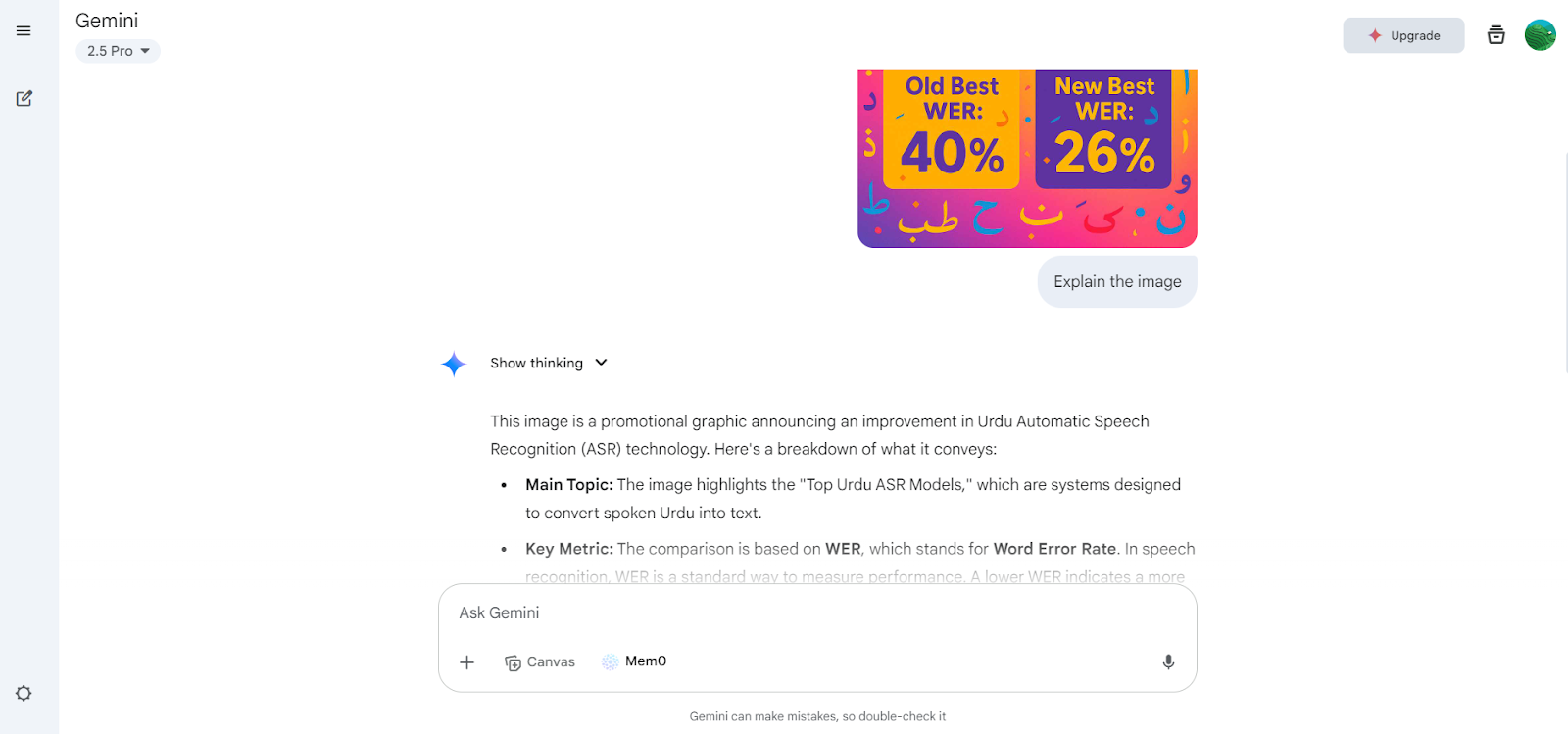
Kaynak: Google Gemini
Gemini 2.5 Pro’ya gemini.google.com/app adresindeki Gemini web uygulaması üzerinden veya Google AI Studio’yu kullanarak ücretsiz erişebilirsiniz.
Geliştiriciler için Gemini 2.5 Pro, Gemini API, Vertex AI ve resmi Python SDK aracılığıyla da sunulur; böylece görsel-dil özelliklerini kendi uygulamalarınıza veya iş akışlarınıza kolayca entegre edebilirsiniz.
Örnek kullanım:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)InternVL3, selefi InternVL 2.5’i geride bırakan gelişmiş bir çoklu modal büyük dil modeli (MLLM) serisidir. Çok modlu algı ve akıl yürütmede öne çıkar; araç kullanımı, GUI ajanları, endüstriyel görüntü analizi ve 3B görsel algı dâhil geliştirilmiş yeteneklere sahiptir.
Özel olarak InternVL3-78B modeli, görsel bileşeni için InternViT-6B-448px-V2_5’i, dil bileşeni için Qwen2.5-72B’yi kullanır. Toplam 78,41 milyar parametreyle InternVL3-78B, MMMU kıyaslamasında 72,2 puana ulaşarak açık kaynak MLLM’ler arasında yeni bir seviye belirlemiştir. Performansı, önde gelen tescilli modellerle rekabetçidir.
Kaynak: OpenGVLab/InternVL3-78B · Hugging Face
Örnek kullanım:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2, AIDC-AI tarafından geliştirilen çoklu modal büyük dil modeli (MLLM) serisidir. Bu modeller, görsel ve metinsel gömlemeleri etkili biçimde hizalamak üzere tasarlanmıştır. Özellikle Ovis2-34B modeli, görsel kodlayıcı olarak aimv2-1B-patch14-448’i, dil modeli olarak Qwen2.5-32B-Instruct’ı kullanır ve toplamda 34 milyar parametreye sahiptir. 32.768 belirtece kadar bağlam uzunluğunu destekler ve verimli işlem için bfloat16 hassasiyeti kullanır.
Ovis2-34B, çeşitli kıyaslamalarda güçlü performans göstermiş ve şu sonuçları elde etmiştir:
Kaynak: AIDC-AI/Ovis2-34B · Hugging Face
Örnek kullanım:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct Qwen ailesinden bir çoklu modal büyük dil modelidir (MLLM) ve hem görsel hem de metinsel bilgiyi anlamak ve işlemek üzere tasarlanmıştır. Birçok açık kaynak MLLM modelinin temeli olması, Qwen model serisinin yapay zekâ araştırmalarını ilerletmede önemli bir rol oynadığını gösterir.
Qwen2.5-VL-72B-Instruct, görüntü ve video anlama ile ajan işlevleri dâhil çeşitli kıyaslamalarda güçlü performans sergiler. MMMUval kıyaslamasında 70,2; MathVista_MINI’de 74,8 ve MMStar’da 70,8 puan alır.
Kaynak: Qwen/Qwen2.5-VL-72B-Instruct · Hugging Face
Örnek kullanım:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)OpenAI’nin o3 modeli; uygulamalarda daha yüksek zekâ, daha düşük maliyet ve daha verimli belirteç kullanımı sunmak üzere tasarlanmış yeni bir akıl yürütme modelidir. Gelişmiş akıl yürütme yeteneklerini öne çıkaran yeni bir model neslini temsil eder.
Bu model; matematik, bilim, kodlama ve görsel akıl yürütme görevleri için yeni bir standart belirler. Çeşitli görsel kıyaslamalarda hem o4-min hem de o1’i geride bırakır ve o3 Pro ile benzer düzeydedir.
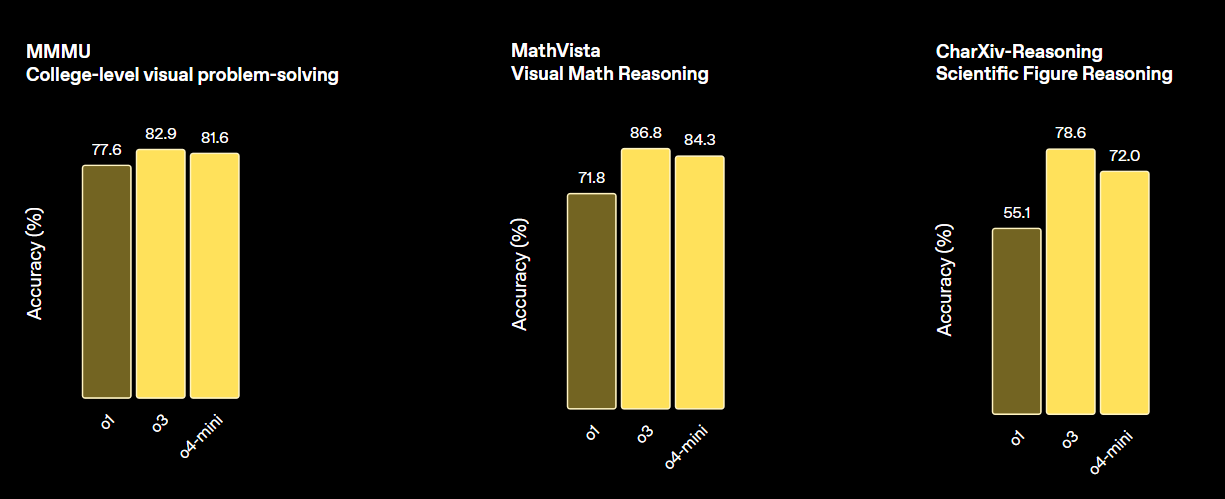
Kaynak: OpenAI o3 ve o4-mini Tanıtımı | OpenAI
Örnek kullanım:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1; GPT-4.1, GPT-4.1 Mini ve GPT-4.1 Nano’yu içeren yeni bir akıl yürütme dışı model ailesidir. Bu modeller, çeşitli kıyaslamalarda selefleri GPT-4o ve GPT-4o Mini’yi geride bırakmıştır.
GPT-4.1; çizelge, diyagram ve görsel matematik analizlerinde geliştirilmiş güçlü görsel yeteneklerini korur. Nesne sayımı, görsel soru yanıtlama ve çeşitli optik karakter tanıma (OCR) türleri gibi görevlerde öne çıkar.
Kaynak: API’de GPT-4.1 Tanıtımı | OpenAI
Örnek kullanım:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic, Claude modellerinin yeni neslini tanıttı: Claude 4 Opus ve Claude 4 Sonnet. Bu modeller; kodlama, gelişmiş akıl yürütme ve yapay zekâ yeteneklerinde yeni standartlar koymak üzere tasarlandı.
Görselleri anlayıp bu görsellerden yola çıkarak kod üretebilen veya bilgi sağlayabilen geliştirilmiş görsel yeteneklerle gelir. Temelde bir kodlama modeli olsa da farklı dosya biçimlerini anlayabilen çoklu modal yeteneklere sahiptir.
Aşağıdaki karşılaştırma tablosuna bakarsanız, özellikle görselleştirme akıl yürütmesi ve görsel soru yanıtlama alanlarında OpenAI’nin GPT-3 modeli hariç tüm üst seviye modelleri geride bıraktığını göreceksiniz.
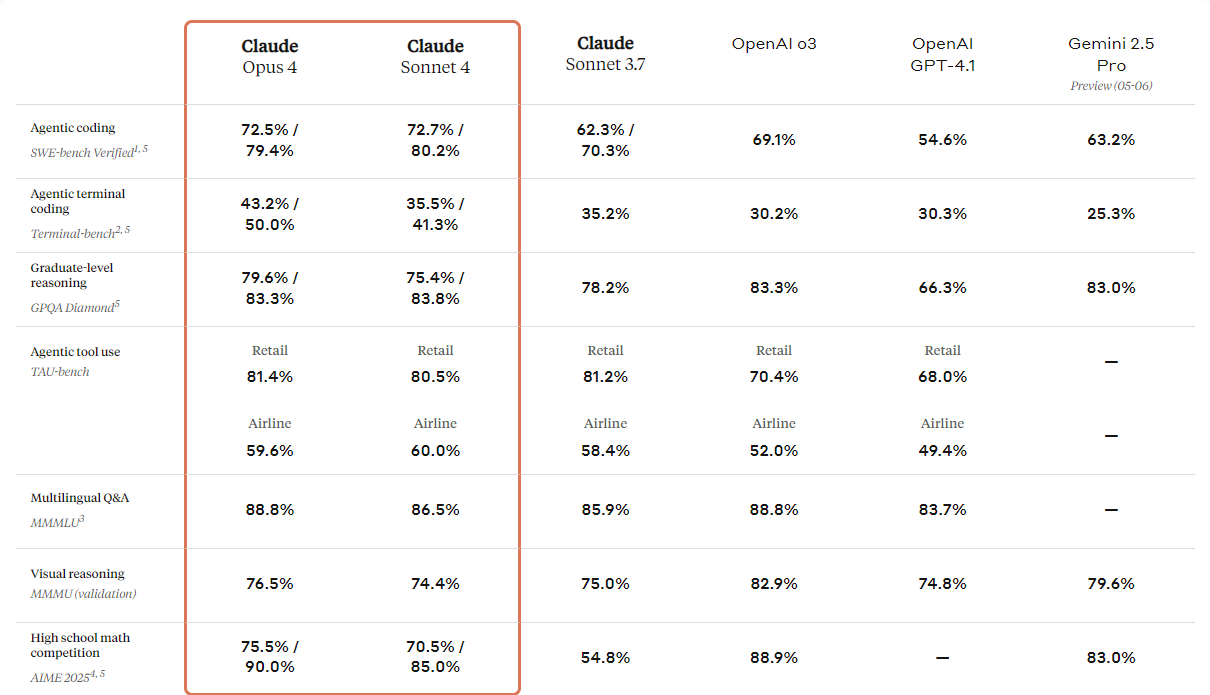
Kaynak: Claude 4 Tanıtımı \ Anthropic
Örnek kullanım:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)Kimi-VL-A3B-Thinking-2506, çok modlu yapay zekâda önemli bir ilerlemeyi temsil eden açık kaynaklı bir modeldir. Çok modlu akıl yürütme kıyaslamalarında üstün başarı gösterir; MathVision’da 56,9, MathVista’da 80,1, MMMU-Pro’da 46,3 ve MMMU’da 64,0 doğruluk elde ederken ortalama “düşünme uzunluğunu” %20 azaltır.
Akıl yürütme yeteneklerine ek olarak, 2506 sürümü genel görsel algı ve anlama konusunda da geliştirmeler sunar. MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0) ve MMVet (78,4) gibi kıyaslamalarda düşünme içermeyen modellerle aynı seviyeye ulaşır veya onları aşar.
Kaynak: MoonshotAI/Kimi-VL: Kimi-VL
Örnek kullanım:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 Google tarafından geliştirilen, hem metin hem de görsel girdileri işleyip metin çıktı üretebilen bir çoklu modal yapay zekâ model ailesidir. 1B, 4B, 12B ve 27B gibi farklı boyutlarda sunularak çeşitli donanım ve performans gereksinimlerine hitap eder.
En büyük varyant olan Gemma 3 27B, insan tercih değerlendirmelerinde etkileyici bir performans sergilemiş; Llama 3-405B ve DeepSeek-V3 gibi daha büyük modelleri dahi geride bırakmıştır.
Modeller, çeşitli kıyaslamalarda güçlü yetenekler gösterir. Özellikle çoklu modal görevlerde öne çıkarak COCOcap (116), DocVQA (85,6), MMMU (56,1) ve VQAv2 (72,9) gibi kıyaslamalarda dikkat çekici puanlara ulaşır.
Kaynak: Open VLM Leaderboard
Örnek kullanım:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)Llama 3.2 90B Vision Instruct modeli, Meta tarafından geliştirilen gelişmiş bir çoklu modal büyük dil modelidir. Görsel tanıma, görsel akıl yürütme ve açıklama üretimi gibi görevler için tasarlanmıştır.
Llama 3.2 90B Vision Instruct, yalnızca metin tabanlı Llama 3.1 sürümü üzerine inşa edilmiştir ve ayrı olarak eğitilmiş bir görsel bağdaştırıcı içerir; bu sayede hem görsel hem de metin girdilerini işleyip doğru metin çıktıları üretebilir.
Büyük ölçekte eğitilen Llama 3.2 90B Vision modeli 8,85 milyon GPU saati gerektirmiştir. VQAv2 (73,6), Text VQA (73,5) ve DocVQA (70,7) gibi kıyaslamalarda olağanüstü performans sergiler.
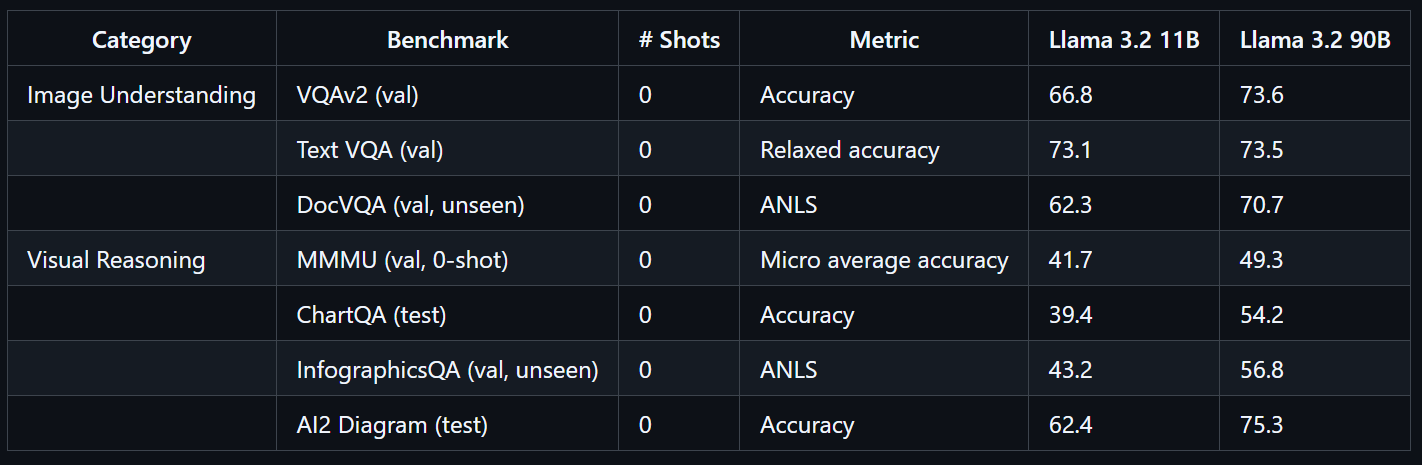
Kaynak: llama-models
Örnek kullanım:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Grafiklerle görsel akıl yürütme, Meta’nın en yeni modeli Muse Spark’ın da güçlü yönlerinden biridir.
Görsel-dil modelleri, görsel ve metinsel bilgilerle etkileşim kurma biçimimizi temelden dönüştürüyor; çok çeşitli sektörlerde dikkat çekici doğruluk ve esneklik sunuyor. Bu modeller, bilgisayarlı görü ile doğal dil işlemini sorunsuzca harmanlayarak gelişmiş nesne tespitinden sezgisel görsel asistanlara kadar yeni uygulamaları mümkün kılıyor.
Gizlilik ve güvenlik kullanım senaryonuzda en öncelikli konularsa, açık kaynak görsel-dil modellerini keşfetmenizi özellikle öneririm. Bu modelleri yerelde çalıştırmak verileriniz üzerinde tam kontrol sağlar ve onları hassas ortamlar için ideal hâle getirir. Açık kaynak VLM’ler ayrıca son derece uyarlanabilirdir; çoğu, yalnızca birkaç yüz örnekle ince ayar yapılarak belirli ihtiyaçlarınıza göre mükemmel sonuçlar verebilir.
Öte yandan tescilli modeller, en gelişmiş yeteneklere güvenilir ve maliyet etkin erişim sağlar. Genellikle çok yüksek doğruluk sunarlar ve yalnızca birkaç satır kodla iş akışınıza entegre edilebilirler; bu da derin yapay zekâ uzmanlığı olmayan ekipler için bile erişilebilir oldukları anlamına gelir.
Görsel-dil modelleri hakkında daha fazla öğrenmek isterseniz şu kaynaklara mutlaka göz atın:
Öne Çıkan DataCamp Kursları
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
