
Cursus
Traitement du langage naturel en Python
20 h
Modèles linguistiques visuels (VLM) transforment rapidement les industries en permettant aux systèmes d'IA de comprendre et d'analyser à la fois les images et le texte. Contrairement aux modèles traditionnels de vision par ordinateur, les VLM modernes sont capables d'interpréter des images complexes, de répondre à des questions détaillées sur le contenu visuel et même de traiter des vidéos et des documents contenant du texte intégré.
Cette caractéristique les rend indispensables pour les diagnostics médicaux, le contrôle qualité automatisé et les applications sensibles où la précision est plus importante que la vitesse.
Dans cet article, nous examinerons les principaux modèles de vision-langage de 2026, y compris les options open source et propriétaires. Nous mettrons en avant leurs capacités uniques, puis nous présenterons leurs performances et leurs résultats de référence. Pour les développeurs et les chercheurs, nous avons également inclus des exemples d'extraits de code afin que vous puissiez rapidement tester ces modèles par vous-même.
Si vous souhaitez en savoir plus sur les principes fondamentaux de ces modèles, veuillez consulter notre traitement d'images en Python cursus track.
Gemini 2.5 Pro est le modèle d'IA le plus avancé de Google, actuellement en tête des classements LMArena et WebDevArena pour les tâches de vision et de codage. Il est conçu pour permettre un raisonnement et une compréhension complexes à partir de textes, d'images, d'enregistrements audio et de vidéos.
En termes de capacités de vision-langage, il se classe parmi les meilleurs modèles du classement Open LLM. Gemini 2.5 Pro est capable d'interpréter des images et des vidéos, de générer des descriptions détaillées et contextuelles tout en répondant à des questions liées au contenu visuel.
Source : Google Gemini
Vous pouvez accéder gratuitement à Gemini 2.5 Pro via l'application web Gemini à l'adresse gemini.google.com/app ou en utilisant Google AI Studio.
Pour les développeurs, Gemini 2.5 Pro est également accessible via l'API Gemini, Vertex AI et le SDK Python officiel, ce qui facilite l'intégration de ses fonctionnalités de vision-langage dans vos propres applications ou flux de travail.
Exemple d'utilisation :
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)InternVL3 est une série avancée de modèles linguistiques multimodaux de grande taille (MLLM) qui surpasse son prédécesseur, InternVL 2.5. Il excelle dans la perception et le raisonnement multimodaux et dispose de capacités améliorées, notamment l'utilisation d'outils, les agents GUI, l'analyse d'images industrielles et la perception visuelle 3D.
Le modèle InternVL3-78B utilise spécifiquement InternViT-6B-448px-V2_5 pour sa composante visuelle et Qwen2.5-72B pour sa composante linguistique. Avec un total de 78,41 milliards de paramètres, InternVL3-78B a obtenu un score de 72,2 au benchmark MMMU, établissant ainsi un nouveau record parmi les MLLM open source. Ses performances sont comparables à celles des principaux modèles propriétaires.
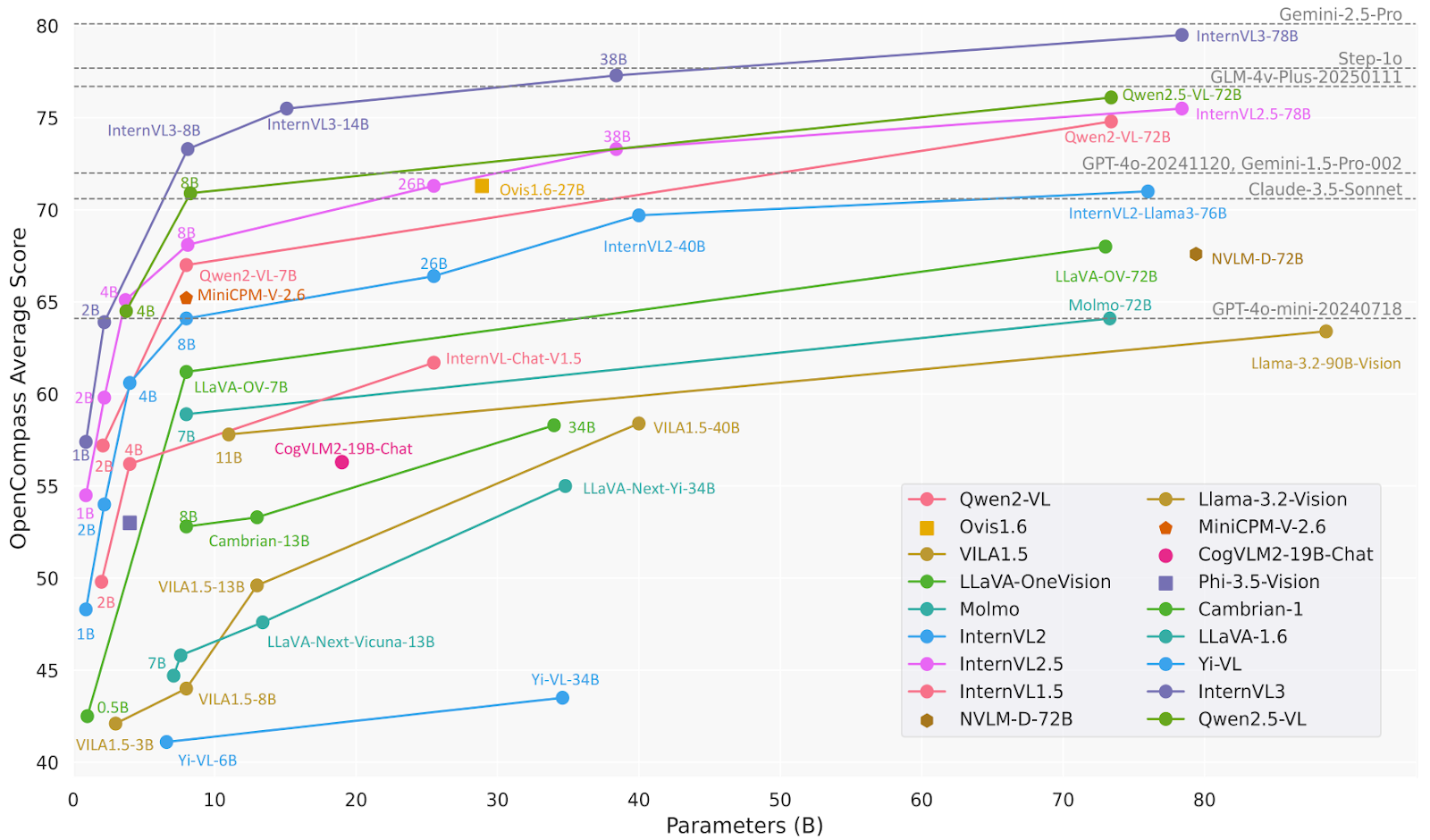
Source : OpenGVLab/InternVL3-78B · Hugging Face
Exemple d'utilisation :
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 est une série de modèles linguistiques multimodaux à grande échelle (MLLM) développés par AIDC-AI. Ces modèles sont conçus pour aligner efficacement les intégrations visuelles et textuelles. Le modèle Ovis2-34B, en particulier, utilise aimv2-1B-patch14-448 comme encodeur visuel et Qwen2.5-32B-Instruct comme modèle linguistique, pour un total de 34 milliards de paramètres. Il prend en charge une longueur de contexte maximale de 32 768 jetons et utilise une précision bfloat16 pour un traitement efficace.
Ovis2-34B a démontré d'excellentes performances lors de divers tests de référence, obtenant les résultats suivants :
Source : AIDC-AI/Ovis2-34B · Hugging Face
Exemple d'utilisation :
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct est un modèle linguistique multimodal de grande taille (MLLM) issu de la famille Qwen, conçu pour comprendre et traiter à la fois les informations visuelles et textuelles. est un modèle linguistique multimodal de grande taille (MLLM) de la famille Qwen, conçu pour comprendre et traiter à la fois les informations visuelles et textuelles. De nombreux modèles MLLM open source s'appuient sur cette technologie, ce qui démontre que la série de modèles Qwen joue un rôle significatif dans l'avancement de la recherche en intelligence artificielle.
Qwen2.5-VL-72B-Instruct affiche d'excellentes performances dans divers benchmarks, notamment en matière de compréhension des images et des vidéos, ainsi que dans ses fonctions d'agent. Il obtient un score de 70,2 au benchmark MMMUval, de 74,8 au MathVista_MINI et de 70,8 au MMStar.
Source : Qwen/Qwen2.5-VL-72B-Instruct · Hugging Face
Exemple d'utilisation :
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)O3 d'OpenAI est un nouveau modèle de raisonnement conçu pour offrir une intelligence supérieure, des coûts réduits et une utilisation plus efficace des jetons dans les applications. Il représente une nouvelle génération de modèles qui mettent l'accent sur des capacités de raisonnement avancées.
Ce modèle établit une nouvelle norme pour les tâches en mathématiques, en sciences, en codage et en raisonnement visuel. En termes de performances visuelles, il surpasse à la fois o4-min et o1, et est comparable à o3 Pro.
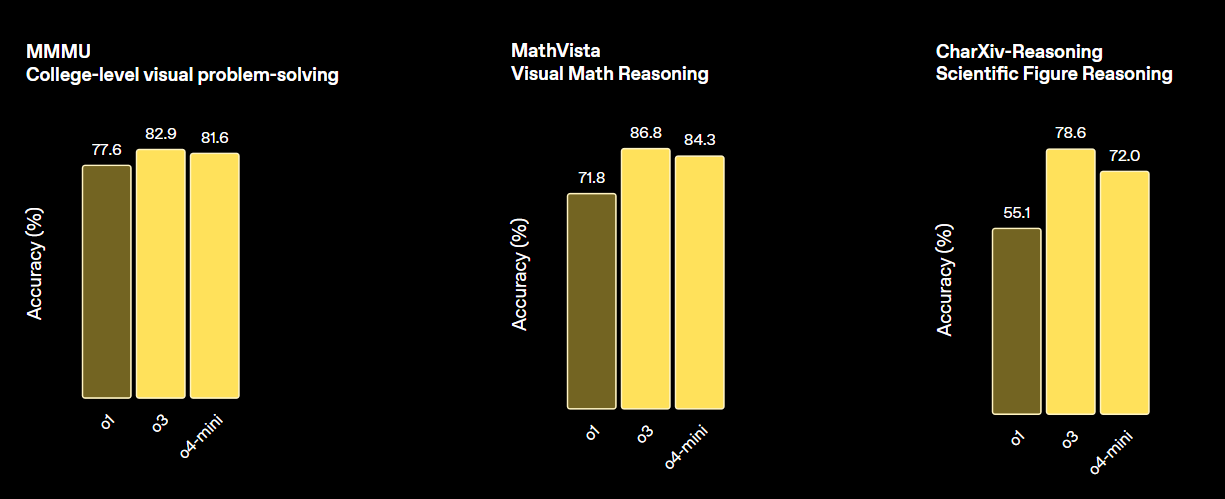
Source : Présentation d'OpenAI o3 et o4-mini | OpenAI
Exemple d'utilisation :
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 est une nouvelle famille de modèles non raisonnants, qui comprend GPT-4.1, GPT-4.1 Mini et GPT-4.1 Nano. Ces modèles ont surpassé leurs prédécesseurs, GPT-4o et GPT-4o Mini, dans divers tests de performance.
GPT-4.1 conserve de solides capacités de vision, avec des améliorations dans l'analyse des graphiques, des diagrammes et des mathématiques visuelles. Il excelle dans des tâches telles que le comptage d'objets, la réponse à des questions visuelles et diverses formes de reconnaissance optique de caractères (OCR).
Source : Présentation de GPT-4.1 dans l'API | OpenAI
Exemple d'utilisation :
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic a présenté la nouvelle génération de ses modèles Claude : Claude 4 Opus et Claude 4 Sonnet. Ces modèles sont conçus pour établir de nouvelles normes en matière de codage, de raisonnement avancé et de capacités d'IA.
Ils sont dotés de capacités de vision améliorées que les utilisateurs peuvent exploiter pour analyser des images, puis générer du code ou fournir des informations basées sur ces images. Bien qu'il s'agisse essentiellement d'un modèle de codage, il offre également des capacités multimodales, ce qui lui permet de comprendre différents types de formats de fichiers.
En consultant le tableau comparatif ci-dessous, vous constaterez que Claude 4 surpasse tous les modèles haut de gamme, à l'exception du modèle GPT-3 d'OpenAI, notamment en matière de raisonnement visuel et de réponse à des questions visuelles.
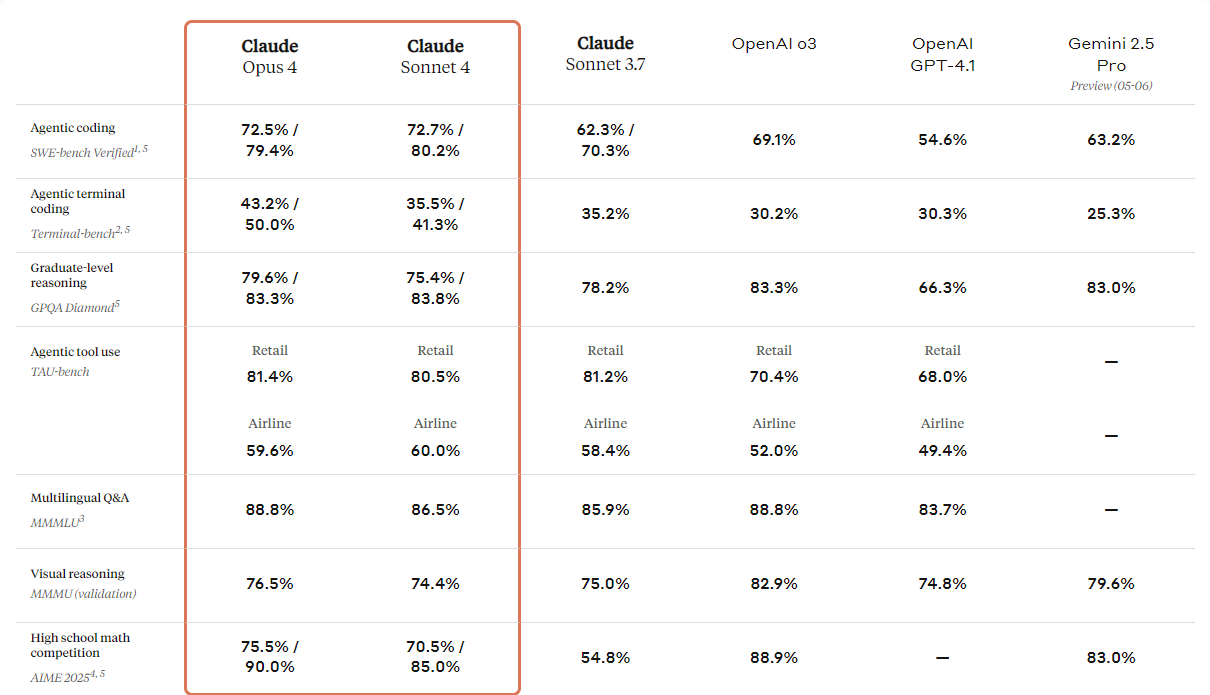
Source : Présentation de Claude 4 \ Anthropic
Exemple d'utilisation :
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)Le Kimi-VL-A3B-Thinking-2506 est un modèle open source qui représente une avancée significative dans le domaine de l'IA multimodale. Il se distingue dans les tests de raisonnement multimodal, obtenant des scores de précision remarquables : 56,9 sur MathVision, 80,1 sur MathVista, 46,3 sur MMMU-Pro et 64,0 sur MMMU, tout en réduisant sa « durée de réflexion » de 20 % en moyenne.
En plus de ses capacités de raisonnement, la version 2506 démontre une perception visuelle et une compréhension générales améliorées. Il égale, voire dépasse, les performances des modèles non intelligents sur des benchmarks tels que MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0) et MMVet (78,4).
Source : MoonshotAI/Kimi-VL : Kimi-VL
Exemple d'utilisation :
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 est une famille de modèles d'IA multimodaux développés par Google, capables de traiter à la fois des entrées textuelles et iconographiques afin de générer des sorties textuelles. Ces modèles sont disponibles en différentes tailles : 1B, 4B, 12B et 27B, répondant à différentes exigences en matière de matériel et de performances.
La variante la plus importante, Gemma 3 27B, a démontré des performances remarquables dans les évaluations de préférence humaine, surpassant même des modèles plus importants tels que Llama 3-405B et DeepSeek-V3.
Les modèles démontrent de solides capacités dans divers benchmarks. Plus précisément, ils excellent dans les tâches multimodales, obtenant des scores remarquables sur des benchmarks tels que COCOcap (116), DocVQA (85,6), MMMU (56,1) et VQAv2 (72,9).
Source : Ouvrir le classement VLM
Exemple d'utilisation :
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)Le modèle Llama 3.2 90B Vision Instruct est un modèle linguistique multimodal avancé développé par Meta. Il est conçu pour les tâches impliquant la reconnaissance visuelle, le raisonnement à partir d'images et la légende.
Llama 3.2 90B Vision Instruct est basé sur la version texte uniquement Llama 3.1 et intègre un adaptateur de vision formé séparément, ce qui lui permet de traiter à la fois des images et du texte en entrée, générant ainsi des sorties textuelles précises.
Entraîné à grande échelle, le modèle Llama 3.2 90B Vision a nécessité 8,85 millions d'heures de calcul GPU. Il affiche des performances exceptionnelles sur des benchmarks tels que VQAv2 (73,6), Text VQA (73,5) et DocVQA (70,7).
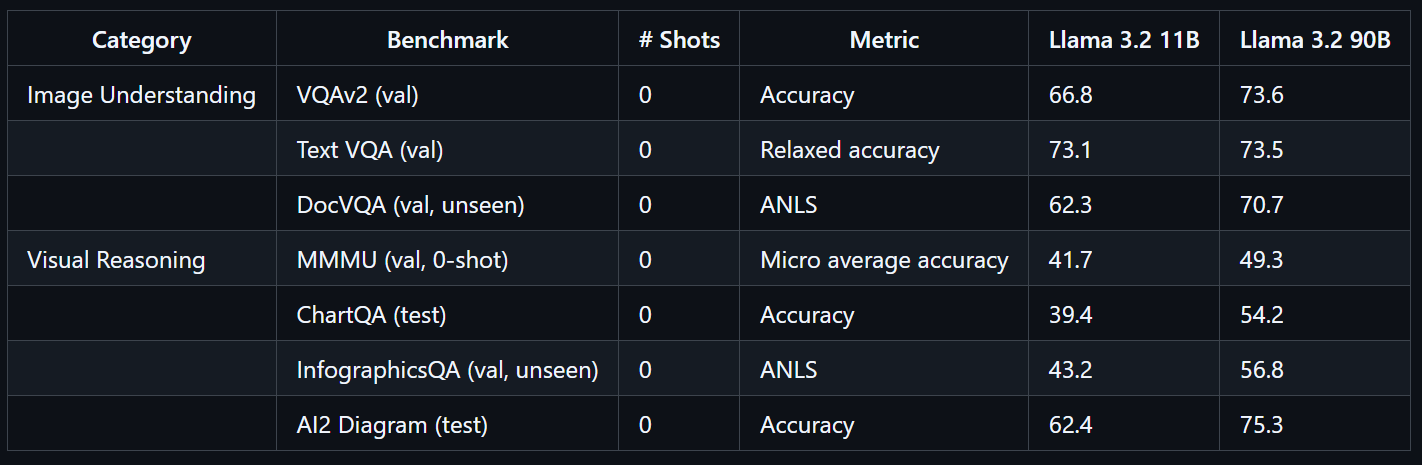
Source : llama-models
Exemple d'utilisation :
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Les modèles de langage visuel transforment fondamentalement notre manière d'interagir avec les informations visuelles et textuelles, offrant une précision et une flexibilité remarquables dans un large éventail de secteurs. Ces modèles combinent de manière transparente la vision par ordinateur et le traitement du langage naturel, permettant ainsi de nouvelles applications allant de la détection avancée d'objets aux assistants visuels intuitifs.
Si la confidentialité et la sécurité sont des priorités absolues pour votre cas d'utilisation, je vous recommande vivement d'explorer les modèles open source de vision-langage. L'exécution de ces modèles en local vous offre un contrôle total sur vos données, ce qui les rend particulièrement adaptés aux environnements sensibles. Les VLM open source sont également très adaptables ; la plupart peuvent être réglés avec précision à partir de quelques centaines d'échantillons seulement pour obtenir d'excellents résultats adaptés à vos besoins spécifiques.
Les modèles propriétaires, quant à eux, offrent un accès fiable et rentable à des fonctionnalités de pointe. Ils sont généralement très précis et peuvent être intégrés à votre flux de travail en quelques lignes de code seulement, ce qui les rend accessibles même aux équipes qui ne disposent pas d'une expertise approfondie en matière d'IA.
Si vous souhaitez en savoir plus sur les modèles linguistiques visuels, veuillez consulter les ressources suivantes :
Meilleurs cours DataCamp
Cursus
Cours
Cours
blog
Lynn Heidmann
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel

