
Lernpfad
Natürliche Sprachverarbeitung in Python
20 Std.
Vision Language Models (VLMs) verändern gerade die Industrie, weil sie KI-Systemen helfen, Bilder und Texte zu verstehen und zu analysieren. Im Gegensatz zu den alten Computervisionsmodellen können moderne VLMs komplizierte Bilder verstehen, detaillierte Fragen zu visuellen Inhalten beantworten und sogar Videos und Dokumente mit eingebettetem Text bearbeiten.
Diese Eigenschaft macht sie super nützlich für medizinische Diagnosen, automatisierte Qualitätskontrolle und sensible Anwendungen, bei denen es mehr auf Präzision als auf Geschwindigkeit ankommt.
In diesem Blog schauen wir uns die besten Vision-Language-Modelle von 2026 an, sowohl Open-Source- als auch proprietäre Optionen. Wir zeigen euch ihre einzigartigen Fähigkeiten und präsentieren dann ihre Leistung und Benchmark-Ergebnisse. Für Entwickler und Forscher haben wir auch Beispiel-Codeausschnitte beigefügt, damit ihr diese Modelle schnell selbst ausprobieren könnt.
Wenn du mehr über die Grundlagen dieser Modelle erfahren möchtest, schau dir unbedingt unseren Kurs Bildverarbeitung in Python an.
Gemini 2.5 Pro ist das fortschrittlichste KI-Modell von Google und führt gerade die Ranglisten von LMArena und WebDevArena sowohl für Bildverarbeitungs- als auch für Programmieraufgaben an. Es ist für komplexes Denken und Verstehen von Texten, Bildern, Audio- und Videodateien gemacht.
Was die Fähigkeiten im Bereich Vision-Sprache angeht, ist es eins der besten Modelle auf der Open-LLM-Rangliste. Gemini 2.5 Pro kann Bilder und Videos verstehen und detaillierte, kontextbezogene Beschreibungen erstellen, während es Fragen zu visuellen Inhalten beantwortet.
Quelle: Google Gemini
Du kannst Gemini 2.5 Pro kostenlos über die Gemini-Web-App unter gemini.google.com/app oder über Google AI Studio nutzen.
Für Entwickler ist Gemini 2.5 Pro auch über die Gemini-API, Vertex AI und das offizielle Python-SDK verfügbar, sodass ihr die Bildverarbeitungs- und Sprachfunktionen ganz einfach in eure eigenen Anwendungen oder Arbeitsabläufe einbauen könnt.
Beispiel für die Verwendung:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
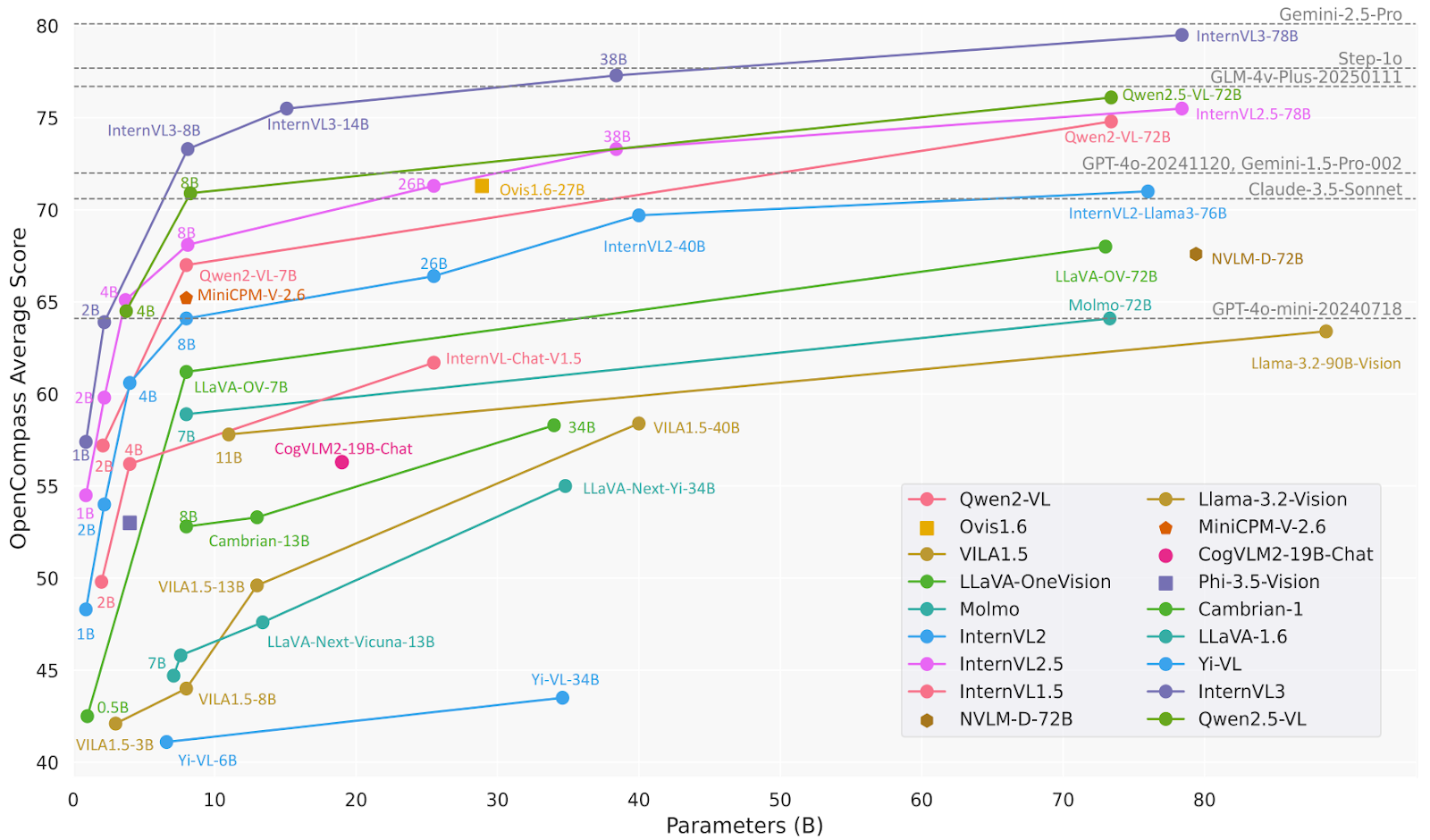
print(response.text)InternVL3 ist eine fortschrittliche Reihe multimodaler großer Sprachmodelle (MLLMs), die besser ist als ihr Vorgänger InternVL 2.5. Es ist super in multimodaler Wahrnehmung und Argumentation und hat verbesserte Fähigkeiten, wie zum Beispiel Werkzeuggebrauch, GUI-Agenten, industrielle Bildanalyse und 3D-Sichtwahrnehmung.
Das Modell InternVL3-78B nutzt InternViT-6B-448px-V2_5 für seine Bildverarbeitungskomponente und Qwen2.5-72B für seine Sprachkomponente. Mit insgesamt 78,41 Milliarden Parametern hat InternVL3-78B beim MMMU-Benchmark 72,2 Punkte erreicht und damit einen neuen Rekord unter den Open-Source-MLLMs aufgestellt. Seine Leistung kann mit der von führenden proprietären Modellen mithalten.
Quelle: OpenGVLab/InternVL3-78B · Hugging Face
Beispiel für die Verwendung:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 ist eine Reihe von multimodalen großen Sprachmodellen (MLLMs), die von AIDC-AI entwickelt wurden. Diese Modelle sind so gemacht, dass sie visuelle und textuelle Einbettungen gut aufeinander abstimmen. Das Modell Ovis2-34B nutzt zum Beispiel den aimv2-1B-patch14-448 als Bildverarbeitungs-Encoder und Qwen2.5-32B-Instruct als Sprachmodell, mit insgesamt 34 Milliarden Parametern. Es unterstützt eine maximale Kontextlänge von 32.768 Tokens und nutzt die bfloat16-Genauigkeit für eine effiziente Verarbeitung.
Ovis2-34B hat bei verschiedenen Benchmark-Tests echt gut abgeschnitten und dabei die folgenden Ergebnisse erzielt:
Quelle: AIDC-AI/Ovis2-34B · Hugging Face
Beispiel für die Verwendung:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct ist ein multimodales großes Sprachmodell (MLLM) aus der Qwen-Familie, das entwickelt wurde, um sowohl visuelle als auch textuelle Infos zu verstehen und zu verarbeiten. Viele Open-Source-MLLM-Modelle basieren darauf, was zeigt, dass die Qwen-Modellreihe eine wichtige Rolle bei der Weiterentwicklung der KI-Forschung spielt.
Qwen2.5-VL-72B-Instruct zeigt bei verschiedenen Benchmarks echt gute Leistungen, zum Beispiel beim Verstehen von Bildern und Videos sowie bei Agenten-Funktionen. Es hat 70,2 Punkte beim MMMUval-Benchmark, 74,8 bei MathVista_MINI und 70,8 bei MMStar.
Quelle: Qwen/Qwen2.5-VL-72B-Anleitung · Hugging Face
Beispiel für die Verwendung:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)OpenAI's o3 ist ein neues Modell, das für mehr Intelligenz, niedrigere Kosten und eine effizientere Token-Nutzung in Apps sorgt. Es ist eine neue Generation von Modellen, die auf fortschrittliche Denkfähigkeiten setzen.
Dieses Modell setzt neue Maßstäbe für Aufgaben in den Bereichen Mathematik, Naturwissenschaften, Programmierung und visuelles Denken. Bei verschiedenen Sehkraft-Benchmarks ist es besser als o4-min und o1 und genauso gut wie o3 Pro.
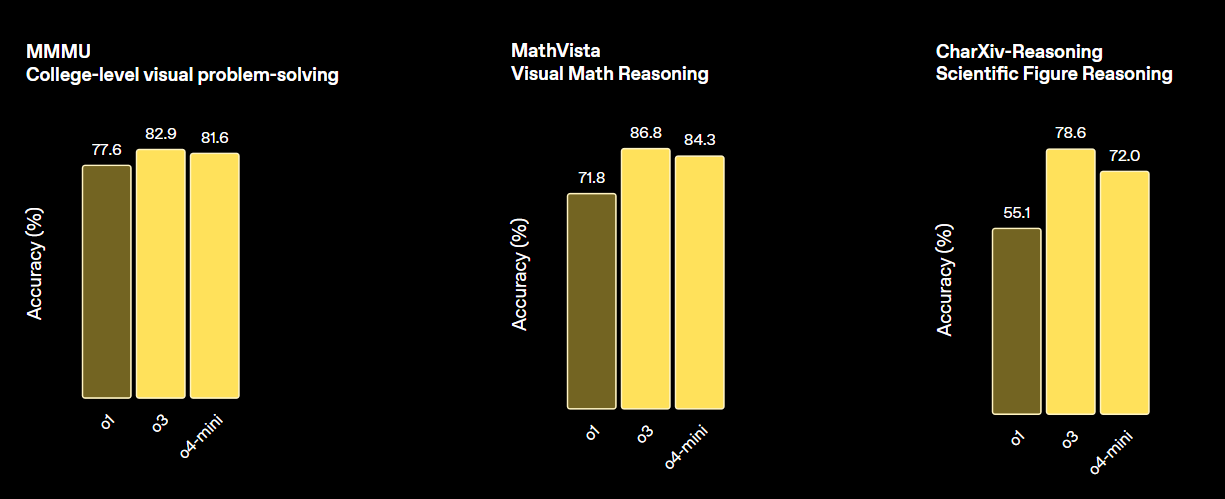
Quelle: Wir stellen vor: OpenAI o3 und o4-mini | OpenAI
Beispiel für die Verwendung:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 ist eine neue Familie von Modellen ohne Schlussfolgerungsfähigkeit, zu der GPT-4.1, GPT-4.1 Mini und GPT-4.1 Nano gehören. Diese Modelle haben ihre Vorgänger GPT-4o und GPT-4o Mini in verschiedenen Benchmarks übertroffen.
GPT-4.1 hat immer noch starke visuelle Fähigkeiten und kann jetzt noch besser Diagramme, Schaubilder und visuelle Mathematik analysieren. Es ist super bei Sachen wie dem Zählen von Objekten, dem Beantworten von visuellen Fragen und verschiedenen Arten der optischen Zeichenerkennung (OCR).
Quelle: Vorstellung von GPT-4.1 in der API | OpenAI
Beispiel für die Verwendung:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic hat die nächste Generation seiner Claude-Modelle vorgestellt: Claude 4 Opus und Claude 4 Sonett. Diese Modelle sollen neue Standards in Sachen Codierung, fortgeschrittenes Denken und KI-Fähigkeiten setzen.
Sie haben verbesserte Sehfähigkeiten, mit denen Nutzer Bilder verstehen und dann Codes erstellen oder Infos zu diesen Bildern geben können. Obwohl es im Grunde ein Codierungsmodell ist, hat es auch multimodale Fähigkeiten, sodass es verschiedene Dateiformate verstehen kann.
Wenn du dir die Tabelle unten ansiehst, wirst du feststellen, dass Claude 4 alle Top-Modelle außer dem GPT-3-Modell von OpenAI übertrifft, vor allem beim visuellen Schlussfolgern und bei der Beantwortung visueller Fragen.
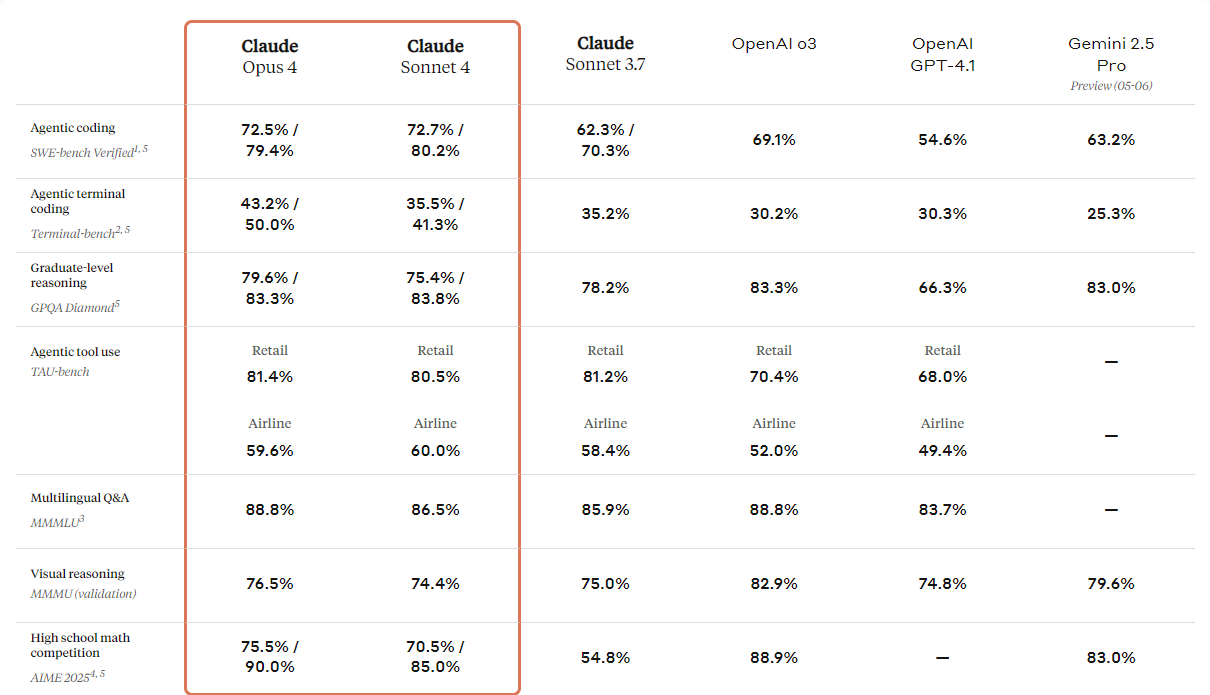
Quelle: Wir stellen vor: Claude 4 \ Anthropic
Beispiel für die Verwendung:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)Das Kimi-VL-A3B-Thinking-2506 ist ein Open-Source-Modell, das einen großen Fortschritt in der multimodalen KI bedeutet. Es ist super bei Benchmarks für multimodales Denken und erreicht echt beeindruckende Genauigkeitswerte: 56,9 bei MathVision, 80,1 bei MathVista, 46,3 bei MMMU-Pro und 64,0 bei MMMU, während die „Denkzeit” um durchschnittlich 20 % reduziert wurde.
Neben seinen Denkfähigkeiten zeigt die Version 2506 auch eine verbesserte allgemeine visuelle Wahrnehmung und ein besseres Verständnis. Es erreicht oder übertrifft sogar die Leistung von Modellen ohne Denkfunktion bei Benchmarks wie MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0) und MMVet (78,4).
Quelle: MoonshotAI/Kimi-VL: Kimi-VL
Beispiel für die Verwendung:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 ist eine Reihe von multimodalen KI-Modellen, die von Google entwickelt wurden und sowohl Text- als auch Bildeingaben verarbeiten können, um Textausgaben zu erzeugen. Diese Modelle gibt's in verschiedenen Größen: 1B, 4B, 12B und 27B, für verschiedene Hardware- und Leistungsanforderungen.
Die größte Variante, Gemma 3 27B, hat bei Tests zur menschlichen Präferenz echt gut abgeschnitten und sogar größere Modelle wie Llama 3-405B und DeepSeek-V3 übertroffen.
Die Modelle zeigen bei verschiedenen Benchmarks echt gute Leistungen. Insbesondere sind sie super bei multimodalen Aufgaben und haben echt gute Ergebnisse bei Benchmarks wie COCOcap (116), DocVQA (85,6), MMMU (56,1) und VQAv2 (72,9) erzielt.
Quelle: VLM-Rangliste öffnen
Beispiel für die Verwendung:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)Das Llama 3.2 90B Vision Instruct-Modell ist ein fortschrittliches multimodales großes Sprachmodell, das von Meta entwickelt wurde. Es ist für Aufgaben wie visuelle Erkennung, Bildinterpretation und Bildunterschriften gedacht.
Llama 3.2 90B Vision Instruct basiert auf der reinen Textversion Llama 3.1 und hat einen extra trainierten Bildadapter, der es ermöglicht, sowohl Bilder als auch Text zu verarbeiten und präzise Textausgaben zu generieren.
Das Modell Llama 3.2 90B Vision wurde in großem Maßstab trainiert und hat 8,85 Millionen GPU-Stunden gebraucht. Es zeigt echt gute Leistungen bei Benchmarks wie VQAv2 (73,6), Text VQA (73,5) und DocVQA (70,7).
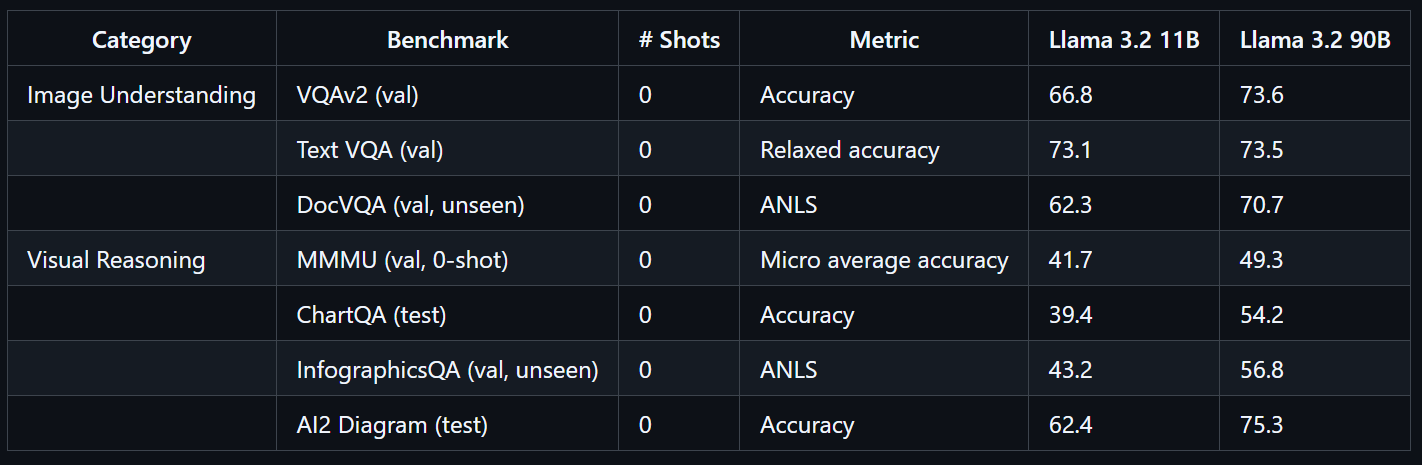
Quelle: llama-models
Beispiel für die Verwendung:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Vision-Sprachmodelle verändern total, wie wir mit visuellen und textuellen Infos umgehen, und bieten in vielen Branchen echt beeindruckende Genauigkeit und Flexibilität. Diese Modelle verbinden Computer Vision und natürliche Sprachverarbeitung nahtlos miteinander und ermöglichen so neue Anwendungen, von der erweiterten Objekterkennung bis hin zu intuitiven visuellen Assistenten.
Wenn Datenschutz und Sicherheit für deinen Anwendungsfall oberste Priorität haben, empfehle ich dir dringend, dich mit Open-Source-Vision-Sprachmodellen zu beschäftigen. Wenn du diese Modelle lokal laufen lässt, hast du die volle Kontrolle über deine Daten, was sie perfekt für sensible Umgebungen macht. Open-Source-VLMs sind auch super anpassungsfähig; die meisten kann man mit nur ein paar hundert Samples feinabstimmen, um echt gute Ergebnisse zu kriegen, die genau auf deine Bedürfnisse zugeschnitten sind.
Proprietäre Modelle bieten dagegen einen zuverlässigen und kostengünstigen Zugang zu modernsten Funktionen. Sie sind in der Regel sehr genau und lassen sich mit nur wenigen Zeilen Code in deinen Arbeitsablauf einbauen, sodass sie auch für Teams ohne große KI-Kenntnisse zugänglich sind.
Wenn du mehr über Vision-Sprachmodelle erfahren möchtest, schau dir unbedingt diese Ressourcen an:
Die besten DataCamp-Kurse
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
8 Min.