
Programma
Elaborazione del linguaggio naturale in Python
20 h
I Vision Language Models (VLM) stanno trasformando rapidamente i settori permettendo ai sistemi di IA di comprendere e ragionare sia su immagini che su testo. A differenza dei tradizionali modelli di computer vision, i VLM moderni possono interpretare immagini complesse, rispondere a domande dettagliate sui contenuti visivi e persino elaborare video e documenti con testo incorporato.
Questa caratteristica li rende preziosi per la diagnostica medica, il controllo qualità automatizzato e applicazioni sensibili in cui la precisione conta più della velocità.
In questo blog esamineremo i migliori modelli vision-language del 2026, includendo sia opzioni open-source che proprietarie. Metteremo in evidenza le loro capacità uniche e poi presenteremo prestazioni e risultati sui benchmark. Per sviluppatori e ricercatori, abbiamo incluso anche esempi di codice per provare rapidamente questi modelli in prima persona.
Se vuoi approfondire le basi di questi modelli, dai un'occhiata al nostro percorso su Image Processing in Python.
Gemini 2.5 Pro è il modello di IA più avanzato di Google, attualmente in cima alle classifiche LMArena e WebDevArena sia per compiti di visione che di coding. È progettato per il ragionamento complesso e la comprensione di testo, immagini, audio e video.
Per quanto riguarda le capacità vision-language, si classifica tra i migliori modelli nella Open LLM leaderboard. Gemini 2.5 Pro può interpretare immagini e video, generando descrizioni dettagliate e contestuali e rispondendo a domande relative ai contenuti visivi.
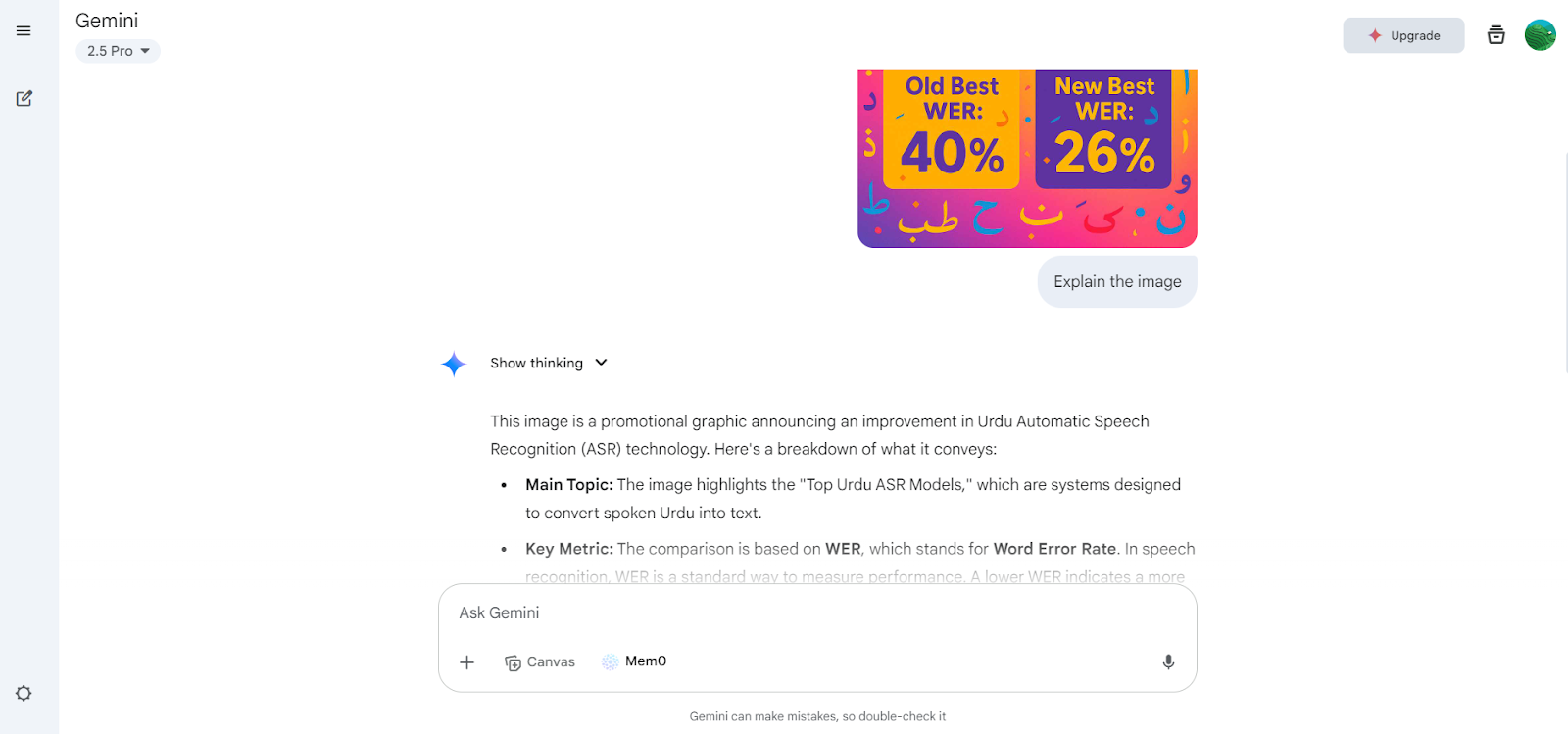
Fonte: Google Gemini
Puoi accedere a Gemini 2.5 Pro gratuitamente tramite l'app web Gemini su gemini.google.com/app o usando Google AI Studio.
Per gli sviluppatori, Gemini 2.5 Pro è disponibile anche tramite la Gemini API, Vertex AI e l'SDK ufficiale per Python, rendendo semplice integrare le sue funzionalità vision-language nelle tue applicazioni o nei tuoi workflow.
Esempio d'uso:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)InternVL3 è una serie avanzata di modelli linguistici multimodali di grandi dimensioni (MLLM) che supera il suo predecessore, InternVL 2.5. Eccelle nella percezione e nel ragionamento multimodale e offre capacità migliorate, tra cui uso di strumenti, agenti GUI, analisi di immagini industriali e percezione 3D.
Nello specifico, il modello InternVL3-78B utilizza InternViT-6B-448px-V2_5 per la componente visiva e Qwen2.5-72B per la componente linguistica. Con un totale di 78,41 miliardi di parametri, InternVL3-78B ha ottenuto un punteggio di 72,2 sul benchmark MMMU, stabilendo un nuovo stato dell'arte tra gli MLLM open-source. Le sue prestazioni sono competitive con quelle dei principali modelli proprietari.
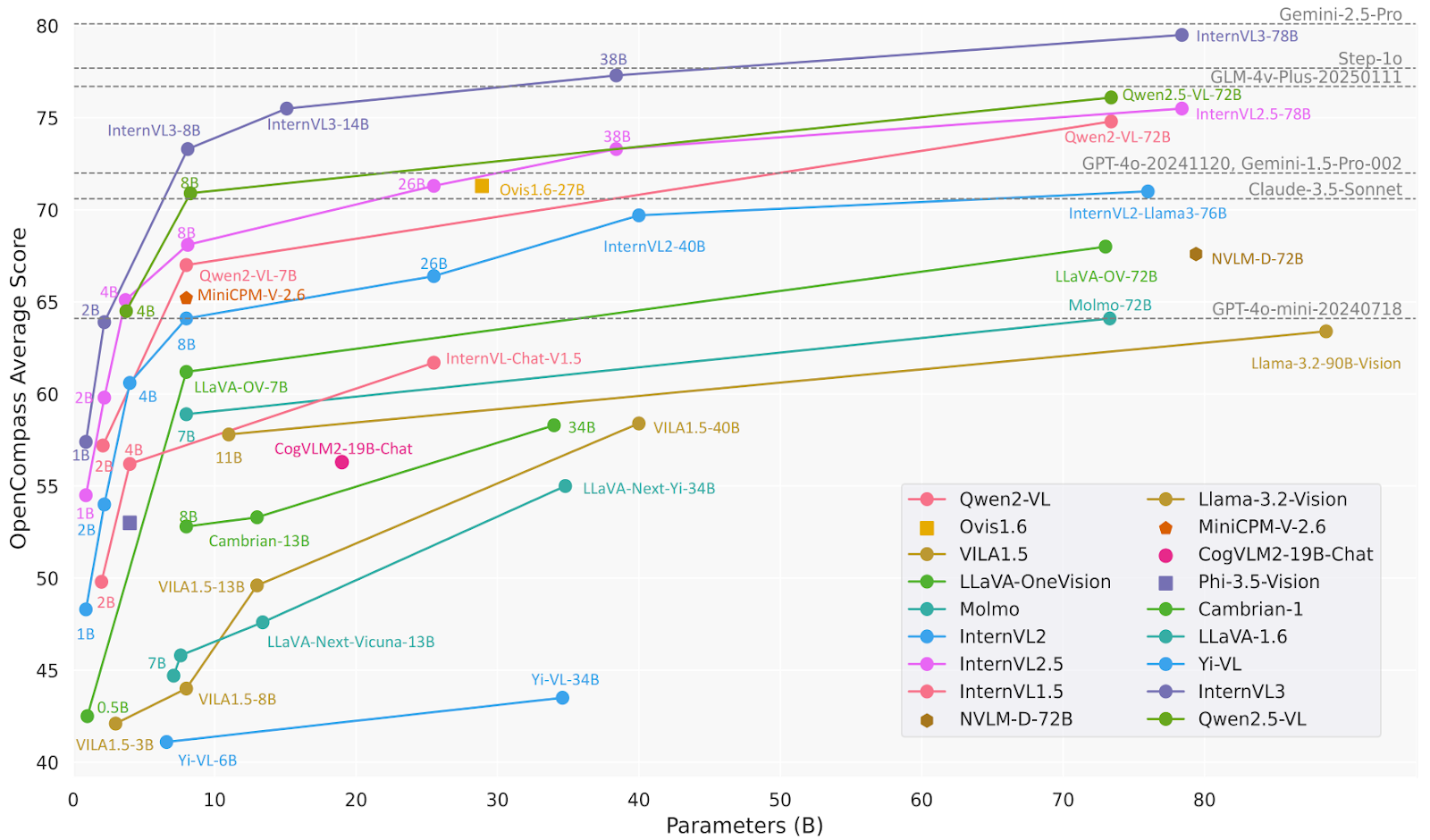
Fonte: OpenGVLab/InternVL3-78B · Hugging Face
Esempio d'uso:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 è una serie di modelli linguistici multimodali di grandi dimensioni (MLLM) sviluppati da AIDC-AI. Questi modelli sono progettati per allineare in modo efficace gli embedding visivi e testuali. In particolare, il modello Ovis2-34B utilizza aimv2-1B-patch14-448 come encoder di visione e Qwen2.5-32B-Instruct come modello linguistico, per un totale di 34 miliardi di parametri. Supporta una lunghezza massima del contesto di 32.768 token e utilizza la precisione bfloat16 per un'elaborazione efficiente.
Ovis2-34B ha mostrato prestazioni solide su vari test di benchmark, ottenendo i seguenti risultati:
Fonte: AIDC-AI/Ovis2-34B · Hugging Face
Esempio d'uso:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct è un modello linguistico multimodale (MLLM) della famiglia Qwen, progettato per comprendere ed elaborare informazioni sia visive che testuali. Molti modelli MLLM open-source si basano su di esso, a conferma del ruolo significativo della serie Qwen nell'avanzamento della ricerca sull'IA.
Qwen2.5-VL-72B-Instruct mostra ottime prestazioni su vari benchmark, incluse le capacità di comprensione di immagini e video e funzioni da agente. Ottiene 70,2 su MMMUval, 74,8 su MathVista_MINI e 70,8 su MMStar.
Fonte: Qwen/Qwen2.5-VL-72B-Instruct · Hugging Face
Esempio d'uso:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)o3 di OpenAI è un nuovo modello di ragionamento progettato per offrire maggiore intelligenza, costi inferiori e un uso più efficiente dei token nelle applicazioni. Rappresenta una nuova generazione di modelli che enfatizzano capacità avanzate di ragionamento.
Questo modello stabilisce un nuovo standard per compiti di matematica, scienza, coding e ragionamento visivo. In diversi benchmark di visione, supera sia o4-min che o1 ed è alla pari con o3 Pro.
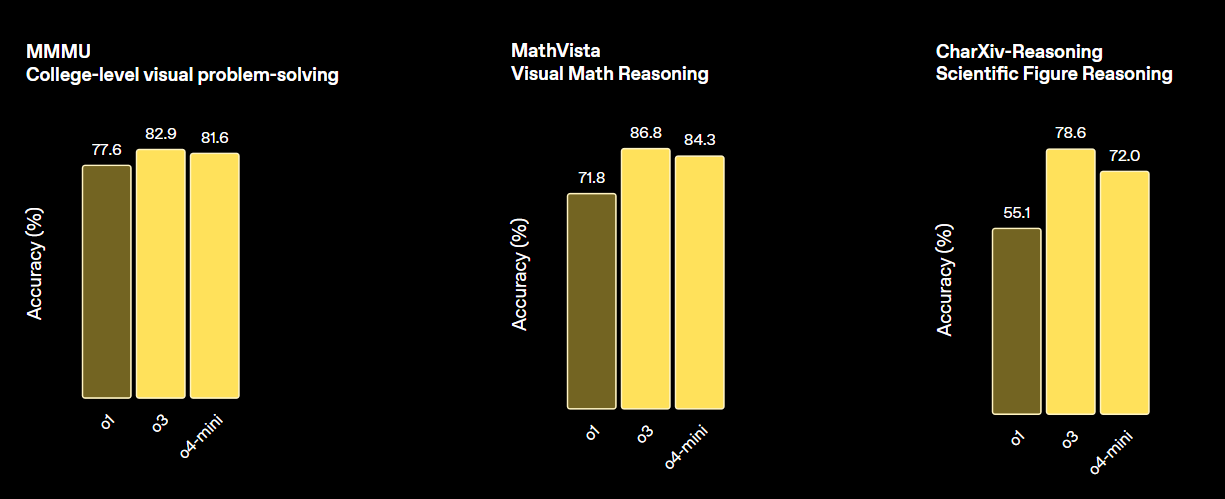
Fonte: Introducing OpenAI o3 and o4-mini | OpenAI
Esempio d'uso:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 è una nuova famiglia di modelli non orientati al ragionamento, che include GPT-4.1, GPT-4.1 Mini e GPT-4.1 Nano. Questi modelli hanno superato i loro predecessori, GPT-4o e GPT-4o Mini, su vari benchmark.
GPT-4.1 mantiene solide capacità di visione, con miglioramenti nell'analisi di grafici, diagrammi e matematica visiva. Eccelle in attività come il conteggio degli oggetti, il visual question answering e varie forme di riconoscimento ottico dei caratteri (OCR).
Fonte: Introducing GPT-4.1 in the API | OpenAI
Esempio d'uso:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic ha presentato la nuova generazione dei suoi modelli Claude: Claude 4 Opus e Claude 4 Sonnet. Questi modelli sono progettati per fissare nuovi standard nel coding, nel ragionamento avanzato e nelle capacità dell'IA.
Offrono capacità di visione migliorate che gli utenti possono impiegare per comprendere le immagini e poi generare codice o fornire informazioni basate su quelle immagini. Pur essendo fondamentalmente un modello per il coding, vanta anche capacità multimodali, che gli permettono di comprendere diversi formati di file.
Dalla tabella di confronto qui sotto, puoi vedere che Claude 4 supera tutti i modelli di punta, tranne il modello GPT-3 di OpenAI, in particolare nel ragionamento su visualizzazioni e nel visual question answering.
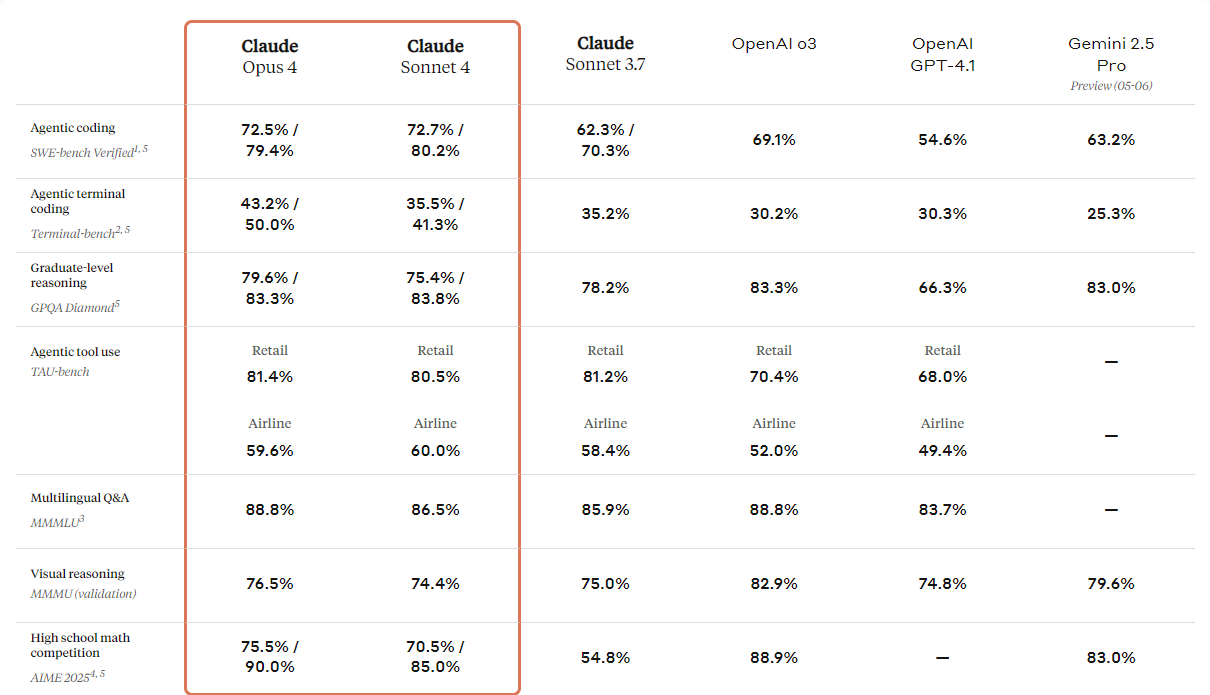
Fonte: Introducing Claude 4 \ Anthropic
Esempio d'uso:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)Kimi-VL-A3B-Thinking-2506 è un modello open-source che segna un notevole avanzamento nell'IA multimodale. Eccelle nei benchmark di ragionamento multimodale, raggiungendo risultati notevoli: 56,9 su MathVision, 80,1 su MathVista, 46,3 su MMMU-Pro e 64,0 su MMMU, riducendo al contempo la sua "thinking length" in media del 20%.
Oltre alle capacità di ragionamento, la versione 2506 mostra una migliore percezione e comprensione visiva generale. Eguaglia o addirittura supera le prestazioni dei modelli senza componente di "thinking" su benchmark come MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0) e MMVet (78,4).
Fonte: MoonshotAI/Kimi-VL: Kimi-VL
Esempio d'uso:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 è una famiglia di modelli di IA multimodali sviluppati da Google, in grado di elaborare input di testo e immagini per produrre output testuali. I modelli sono disponibili in varie dimensioni: 1B, 4B, 12B e 27B, per soddisfare diverse esigenze di hardware e prestazioni.
La variante più grande, Gemma 3 27B, ha mostrato prestazioni impressionanti nelle valutazioni di preferenza umana, superando persino modelli più grandi come Llama 3-405B e DeepSeek-V3.
I modelli mostrano solide capacità su vari benchmark. In particolare, eccellono nei compiti multimodali, raggiungendo punteggi notevoli su benchmark come COCOcap (116), DocVQA (85,6), MMMU (56,1) e VQAv2 (72,9).
Fonte: Open VLM Leaderboard
Esempio d'uso:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)Il modello Llama 3.2 90B Vision Instruct è un avanzato modello linguistico multimodale sviluppato da Meta. È progettato per compiti che coinvolgono riconoscimento visivo, ragionamento su immagini e didascalizzazione.
Llama 3.2 90B Vision Instruct si basa sulla versione solo testo Llama 3.1 e integra un adattatore di visione addestrato separatamente, che gli consente di elaborare sia immagini che testo come input, generando output testuali precisi.
Addestrato su larga scala, il modello Llama 3.2 90B Vision ha richiesto 8,85 milioni di ore GPU. Mostra prestazioni eccellenti su benchmark come VQAv2 (73,6), Text VQA (73,5) e DocVQA (70,7).
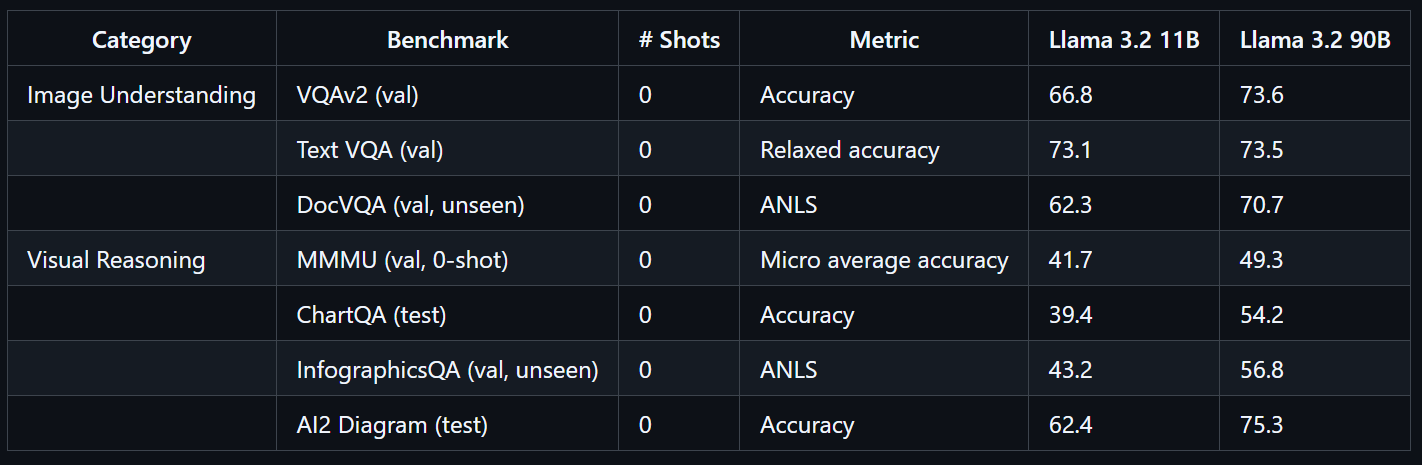
Fonte: llama-models
Esempio d'uso:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Il ragionamento visivo con grafici è anche un punto di forza del modello più recente di Meta, Muse Spark.
I modelli vision-language stanno trasformando alla radice il modo in cui interagiamo con informazioni visive e testuali, offrendo notevole accuratezza e flessibilità in un'ampia gamma di settori. Questi modelli fondono senza soluzione di continuità computer vision ed elaborazione del linguaggio naturale, abilitando nuove applicazioni che vanno dal rilevamento avanzato degli oggetti ad assistenti visivi intuitivi.
Se privacy e sicurezza sono le massime priorità per il tuo caso d'uso, ti consiglio vivamente di esplorare i modelli vision-language open-source. Eseguire questi modelli in locale ti dà il pieno controllo sui dati, rendendoli ideali per ambienti sensibili. I VLM open-source sono anche altamente adattabili; la maggior parte può essere messa a punto con poche centinaia di campioni per ottenere ottimi risultati su misura per le tue esigenze specifiche.
I modelli proprietari, d'altra parte, forniscono accesso affidabile ed economico a capacità all'avanguardia. Tendono a essere molto accurati e possono essere integrati nel tuo workflow con poche righe di codice, rendendoli accessibili anche a team senza profonda competenza in IA.
Se vuoi saperne di più sui vision language models, dai un'occhiata a queste risorse:
I migliori corsi DataCamp
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

