
programa
Procesamiento del lenguaje natural en Python
20 h
Modelos de lenguaje visual (VLMs) están transformando rápidamente las industrias al permitir que los sistemas de IA comprendan y razonen tanto sobre imágenes como sobre texto. A diferencia de los modelos tradicionales de visión artificial, los VLM modernos pueden interpretar imágenes complejas, responder preguntas detalladas sobre contenido visual e incluso procesar vídeos y documentos con texto incrustado.
Esta característica los hace muy valiosos para el diagnóstico médico, el control de calidad automatizado y aplicaciones sensibles en las que la precisión es más importante que la velocidad.
En este blog, revisaremos los mejores modelos de lenguaje visual de 2026, incluyendo tanto opciones de código abierto como propietarias. Destacaremos sus capacidades únicas y, a continuación, presentaremos su rendimiento y los resultados de las pruebas comparativas. Para programadores e investigadores, también hemos incluido fragmentos de código de ejemplo para que puedas probar rápidamente estos modelos por ti mismo.
Si deseas obtener más información sobre los fundamentos de estos modelos, no te pierdas nuestro artículo Procesamiento de imágenes en Python skill track.
Gemini 2.5 Pro es el modelo de IA más avanzado de Google, que actualmente lidera las clasificaciones de LMArena y WebDevArena tanto en tareas de visión como de codificación. Está diseñado para el razonamiento complejo y la comprensión de textos, imágenes, audio y vídeo.
En cuanto a tus capacidades de visión y lenguaje, te sitúas entre los mejores modelos de la clasificación Open LLM. Gemini 2.5 Pro puede interpretar imágenes y vídeos, generando descripciones detalladas y contextuales, al tiempo que responde a preguntas relacionadas con el contenido visual.
Fuente: Google Gemini
Puedes acceder a Gemini 2.5 Pro de forma gratuita a través de la aplicación web Gemini en gemini.google.com/app o utilizando Google AI Studio.
Para los programadores, Gemini 2.5 Pro también está disponible a través de la API de Gemini, Vertex AI y el SDK oficial de Python, lo que facilita la integración de sus funciones de visión y lenguaje en tus propias aplicaciones o flujos de trabajo.
Ejemplo de uso:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)InternVL3 es una serie avanzada de modelos lingüísticos multimodales de gran tamaño (MLLM) que supera a su predecesor, InternVL 2.5. Destaca en percepción y razonamiento multimodal y cuenta con capacidades mejoradas, como el uso de herramientas, agentes GUI, análisis de imágenes industriales y percepción de visión 3D.
El modelo InternVL3-78B utiliza específicamente InternViT-6B-448px-V2_5 para su componente de visión y Qwen2.5-72B para su componente de lenguaje. Con un total de 78 410 millones de parámetros, InternVL3-78B ha obtenido una puntuación de 72,2 en la prueba de rendimiento MMMU, lo que supone un nuevo récord entre los MLLM de código abierto. Su rendimiento es competitivo con el de los principales modelos patentados.
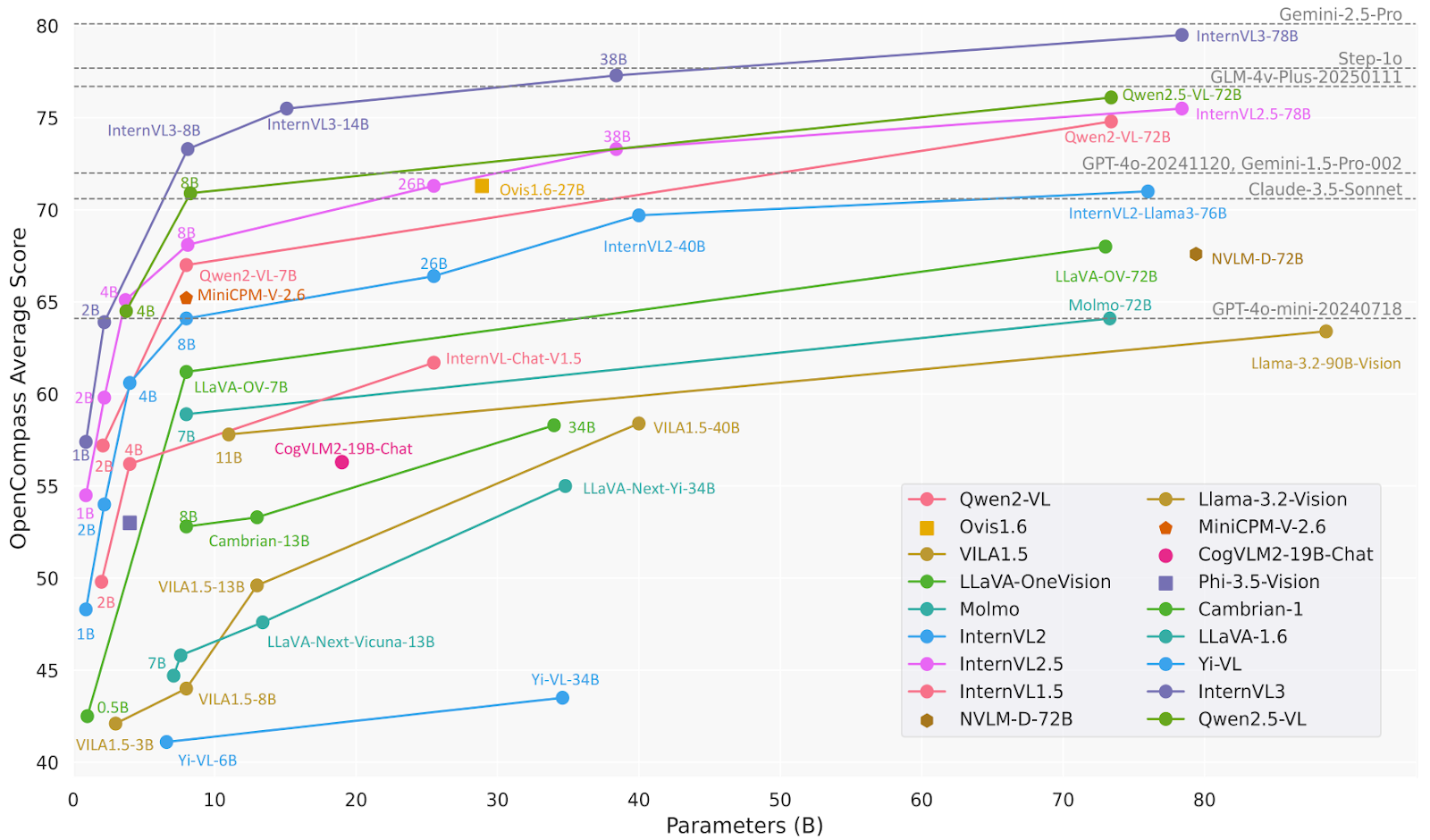
Fuente: OpenGVLab/InternVL3-78B · Hugging Face
Ejemplo de uso:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 es una serie de modelos lingüísticos multimodales de gran tamaño (MLLM) desarrollados por AIDC-AI. Estos modelos están diseñados para alinear eficazmente las incrustaciones visuales y textuales. El modelo Ovis2-34B, en particular, utiliza aimv2-1B-patch14-448 como codificador de visión y Qwen2.5-32B-Instruct como modelo de lenguaje, con un total de 34 000 millones de parámetros. Admite una longitud de contexto máxima de 32 768 tokens y utiliza una precisión bfloat16 para un procesamiento eficiente.
Ovis2-34B ha demostrado un gran rendimiento en diversas pruebas de referencia, logrando los siguientes resultados:
Fuente: AIDC-AI/Ovis2-34B · Hugging Face
Ejemplo de uso:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct es un modelo de lenguaje grande multimodal (MLLM) de la familia Qwen, diseñado para comprender y procesar tanto información visual como textual. Muchos modelos MLLM de código abierto se basan en él, lo que indica que la serie de modelos Qwen desempeña un papel importante en el avance de la investigación en IA.
Qwen2.5-VL-72B-Instruct demuestra un sólido rendimiento en diversas pruebas de referencia, incluidas sus capacidades en la comprensión de imágenes y vídeos, así como en funciones de agente. Obtiene una puntuación de 70,2 en el benchmark MMMUval, 74,8 en MathVista_MINI y 70,8 en MMStar.
Fuente: Qwen/Qwen2.5-VL-72B-Instruct · Hugging Face
Ejemplo de uso:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)El o3 de OpenAI es un nuevo modelo de razonamiento diseñado para proporcionar mayor inteligencia, menores costes y un uso más eficiente de los tokens en las aplicaciones. Representa una nueva generación de modelos que hacen hincapié en las capacidades de razonamiento avanzadas.
Este modelo establece un nuevo estándar para las tareas de matemáticas, ciencias, programación y razonamiento visual. En términos de diversos parámetros de referencia de visión, supera tanto a o4-min como a o1, y está a la par con o3 Pro.
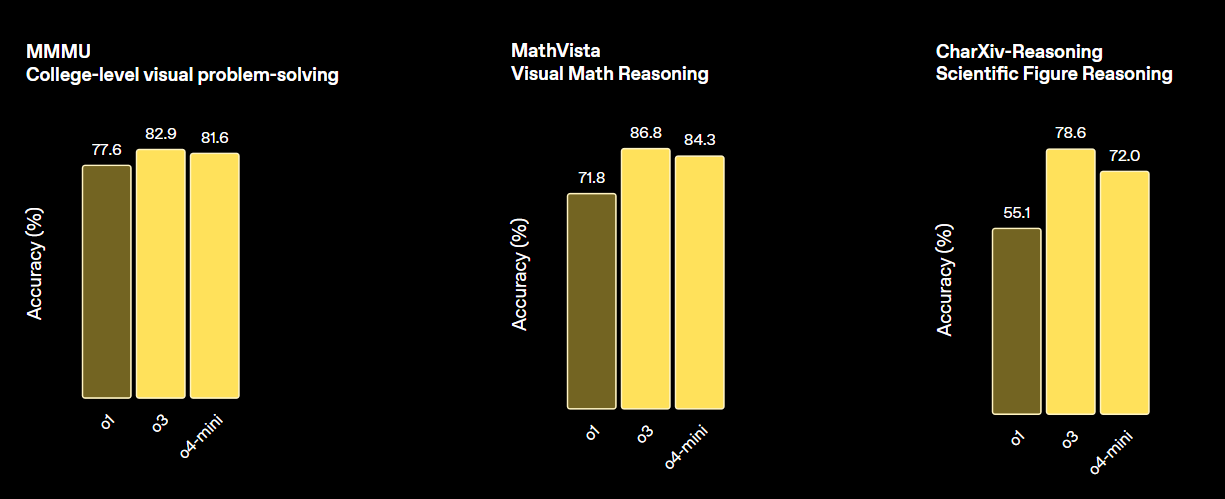
Fuente: Presentamos OpenAI o3 y o4-mini | OpenAI
Ejemplo de uso:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 es una nueva familia de modelos sin razonamiento, que incluye GPT-4.1, GPT-4.1 Mini y GPT-4.1 Nano. Estos modelos han superado a sus predecesores, GPT-4o y GPT-4o Mini, en diversas pruebas de rendimiento.
GPT-4.1 conserva sus potentes capacidades visuales, con mejoras en el análisis de gráficos, diagramas y matemáticas visuales. Destaca en tareas como el recuento de objetos, la respuesta a preguntas visuales y diversas formas de reconocimiento óptico de caracteres (OCR).
Fuente: Presentamos GPT-4.1 en la API | OpenAI
Ejemplo de uso:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic ha presentado la próxima generación de sus modelos Claude: Claude 4 Opus y Claude 4 Soneto. Estos modelos están diseñados para establecer nuevos estándares en codificación, razonamiento avanzado y capacidades de inteligencia artificial.
Vienen con capacidades de visión mejoradas que los usuarios pueden utilizar para comprender imágenes y, a continuación, generar código o proporcionar información basada en esas imágenes. Aunque se trata fundamentalmente de un modelo de codificación, también cuenta con capacidades multimodales, lo que te permite comprender diferentes tipos de formatos de archivo.
Si consultan la tabla comparativa que figura a continuación, verán que Claude 4 supera a todos los modelos punteros, excepto al modelo GPT-3 de OpenAI, especialmente en razonamiento visual y respuesta a preguntas visuales.
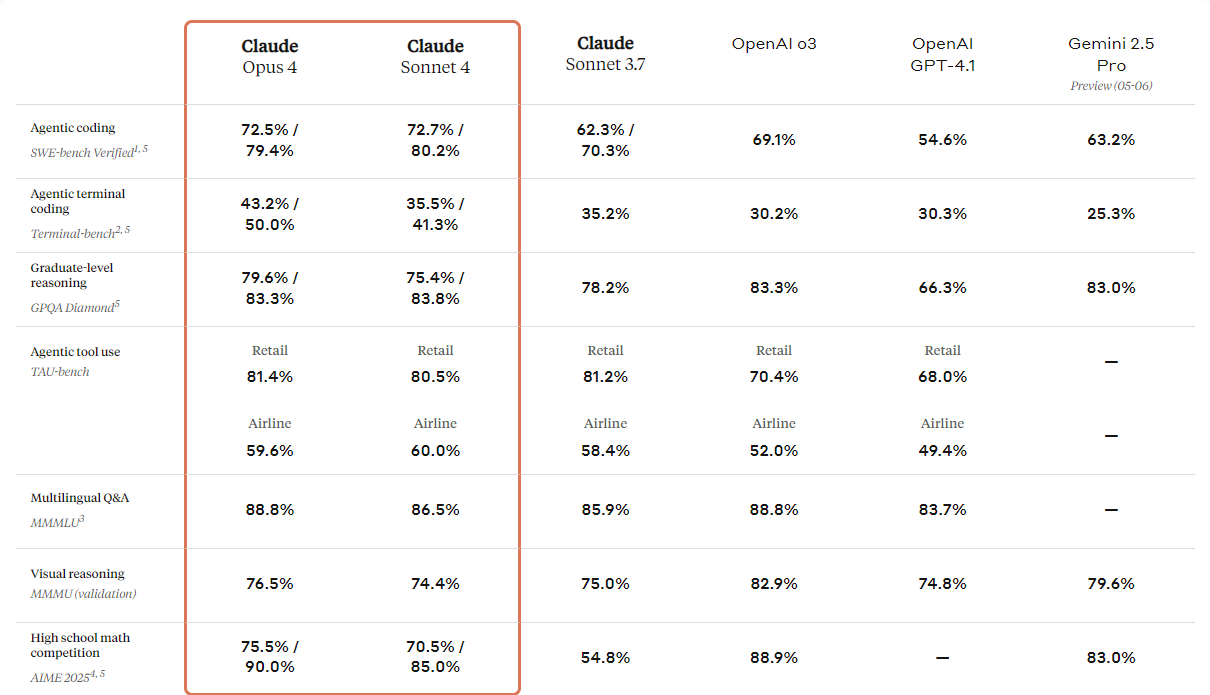
Fuente: Presentamos Claude 4 \ Anthropic
Ejemplo de uso:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)El Kimi-VL-A3B-Thinking-2506 es un modelo de código abierto que supone un avance significativo en la IA multimodal. Destaca en pruebas de razonamiento multimodal, logrando impresionantes puntuaciones de precisión: 56,9 en MathVision, 80,1 en MathVista, 46,3 en MMMU-Pro y 64,0 en MMMU, al tiempo que reducías tu «tiempo de reflexión» en un 20 % de media.
Además de sus capacidades de razonamiento, la versión 2506 demuestra una percepción visual y una comprensión generales mejoradas. Iguala o incluso supera el rendimiento de los modelos no inteligentes en pruebas de rendimiento como MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0) y MMVet (78,4).
Fuente: MoonshotAI/Kimi-VL: Kimi-VL
Ejemplo de uso:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 es una familia de modelos de IA multimodales desarrollados por Google, capaces de procesar entradas de texto e imágenes para producir salidas de texto. Estos modelos están disponibles en varios tamaños: 1B, 4B, 12B y 27B, que se adaptan a diferentes requisitos de hardware y rendimiento.
La variante más grande, Gemma 3 27B, ha mostrado un rendimiento impresionante en las evaluaciones de preferencia humana, superando incluso a modelos más grandes como Llama 3-405B y DeepSeek-V3.
Los modelos demuestran grandes capacidades en diversas pruebas comparativas. En concreto, destacan en tareas multimodales, obteniendo puntuaciones notables en pruebas de referencia como COCOcap (116), DocVQA (85,6), MMMU (56,1) y VQAv2 (72,9).
Fuente: Abrir la tabla de clasificación de VLM
Ejemplo de uso:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)El Llama 3.2 90B Vision Instruct es un modelo lingüístico multimodal avanzado desarrollado por Meta. Está diseñado para tareas relacionadas con el reconocimiento visual, el razonamiento por imágenes y la creación de subtítulos.
Llama 3.2 90B Vision Instruct se basa en la versión solo texto Llama 3.1 e incorpora un adaptador de visión entrenado por separado, que te permite procesar tanto imágenes como texto como entradas, generando salidas de texto precisas.
Entrenado a gran escala, el modelo Llama 3.2 90B Vision requirió 8,85 millones de horas de GPU. Demuestra un rendimiento excepcional en pruebas de referencia como VQAv2 (73,6), Text VQA (73,5) y DocVQA (70,7).
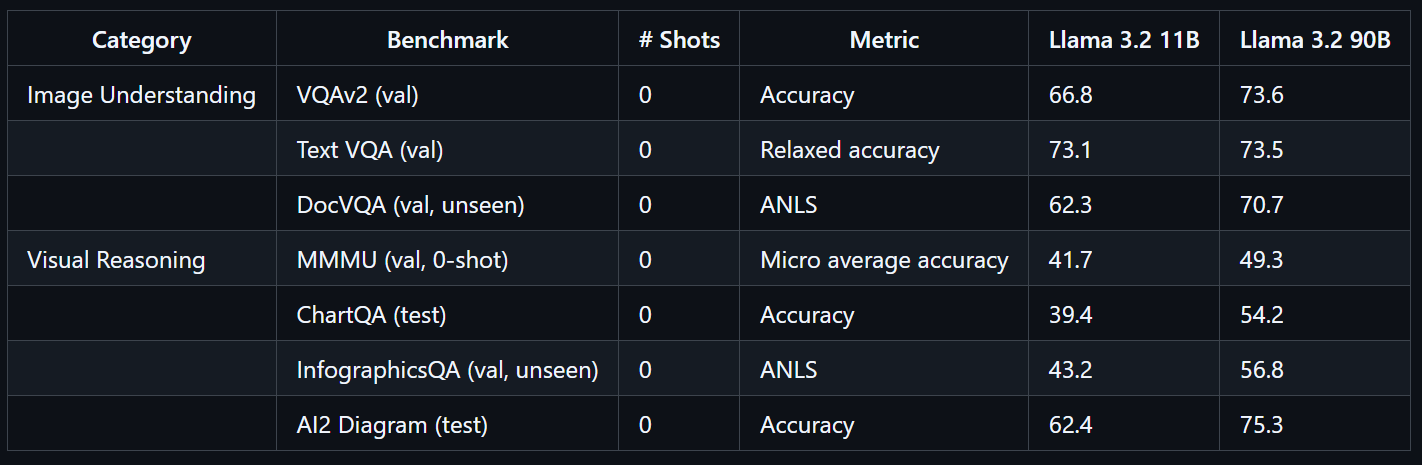
Fuente: llama-models
Ejemplo de uso:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Los modelos de lenguaje visual están transformando radicalmente la forma en que interactuamos con la información visual y textual, ofreciendo una precisión y flexibilidad extraordinarias en una amplia gama de sectores. Estos modelos combinan a la perfección la visión artificial y el procesamiento del lenguaje natural, lo que permite nuevas aplicaciones, desde la detección avanzada de objetos hasta asistentes visuales intuitivos.
Si la privacidad y la seguridad son prioridades fundamentales para tu caso de uso, te recomiendo encarecidamente que explores los modelos de visión-lenguaje de código abierto. La ejecución de estos modelos de forma local te proporciona un control total sobre tus datos, lo que los hace ideales para entornos sensibles. Los VLM de código abierto también son muy adaptables; la mayoría se pueden ajustar con solo unos cientos de muestras para obtener excelentes resultados adaptados a tus necesidades específicas.
Por otro lado, los modelos patentados proporcionan un acceso fiable y rentable a capacidades de última generación. Suelen ser muy precisos y se pueden integrar en tu flujo de trabajo con solo unas pocas líneas de código, lo que los hace accesibles incluso para equipos sin profundos conocimientos de IA.
Si deseas obtener más información sobre los modelos de lenguaje visual, no te pierdas estos recursos:
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Bhavishya Pandit
8 min
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Abid Ali Awan
13 min
blog
Javier Canales Luna
13 min
Tutorial
Arunn Thevapalan
Tutorial
Adel Nehme

