
Track
Natural Language Processing in Python
20 hr
Vision Language Models (VLMs) are rapidly transforming industries by enabling AI systems to understand and reason about both images and text. Unlike traditional computer vision models, modern VLMs can interpret complex images, answer detailed questions about visual content, and even process videos and documents with embedded text.
This feature makes them invaluable for medical diagnostics, automated quality control, and sensitive applications where precision matters more than speed.
In this blog, we will review the top vision-language models of 2026, including both open-source and proprietary options. We will highlight their unique capabilities and then present their performance and benchmark results. For developers and researchers, we have also included example code snippets so you can quickly try out these models yourself.
If you’re eager to learn more about the fundamentals of these models, be sure to check out our Image Processing in Python skill track.
Gemini 2.5 Pro is Google’s most advanced AI model, currently leading the LMArena and WebDevArena leaderboards for both vision and coding tasks. It is designed for complex reasoning and understanding across text, images, audio, and video.
In terms of its vision-language capabilities, it ranks as one of the top models on the Open LLM leaderboard. Gemini 2.5 Pro can interpret images and videos, generating detailed and context-aware descriptions while answering questions related to visual content.
Source: Google Gemini
You can access Gemini 2.5 Pro for free through the Gemini web app at gemini.google.com/app or by using Google AI Studio.
For developers, Gemini 2.5 Pro is also available via the Gemini API, Vertex AI, and the official Python SDK, making it easy to integrate its vision-language features into your own applications or workflows.
Example usage:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)InternVL3 is an advanced series of multimodal large language models (MLLMs) that outperforms its predecessor, InternVL 2.5. It excels in multimodal perception and reasoning and has enhanced capabilities, including tool usage, GUI agents, industrial image analysis, and 3D vision perception.
The InternVL3-78B model specifically uses InternViT-6B-448px-V2_5 for its vision component and Qwen2.5-72B for its language component. With a total of 78.41 billion parameters, InternVL3-78B has achieved a score of 72.2 on the MMMU benchmark, establishing a new state-of-the-art record among open-source MLLMs. Its performance is competitive with that of leading proprietary models.
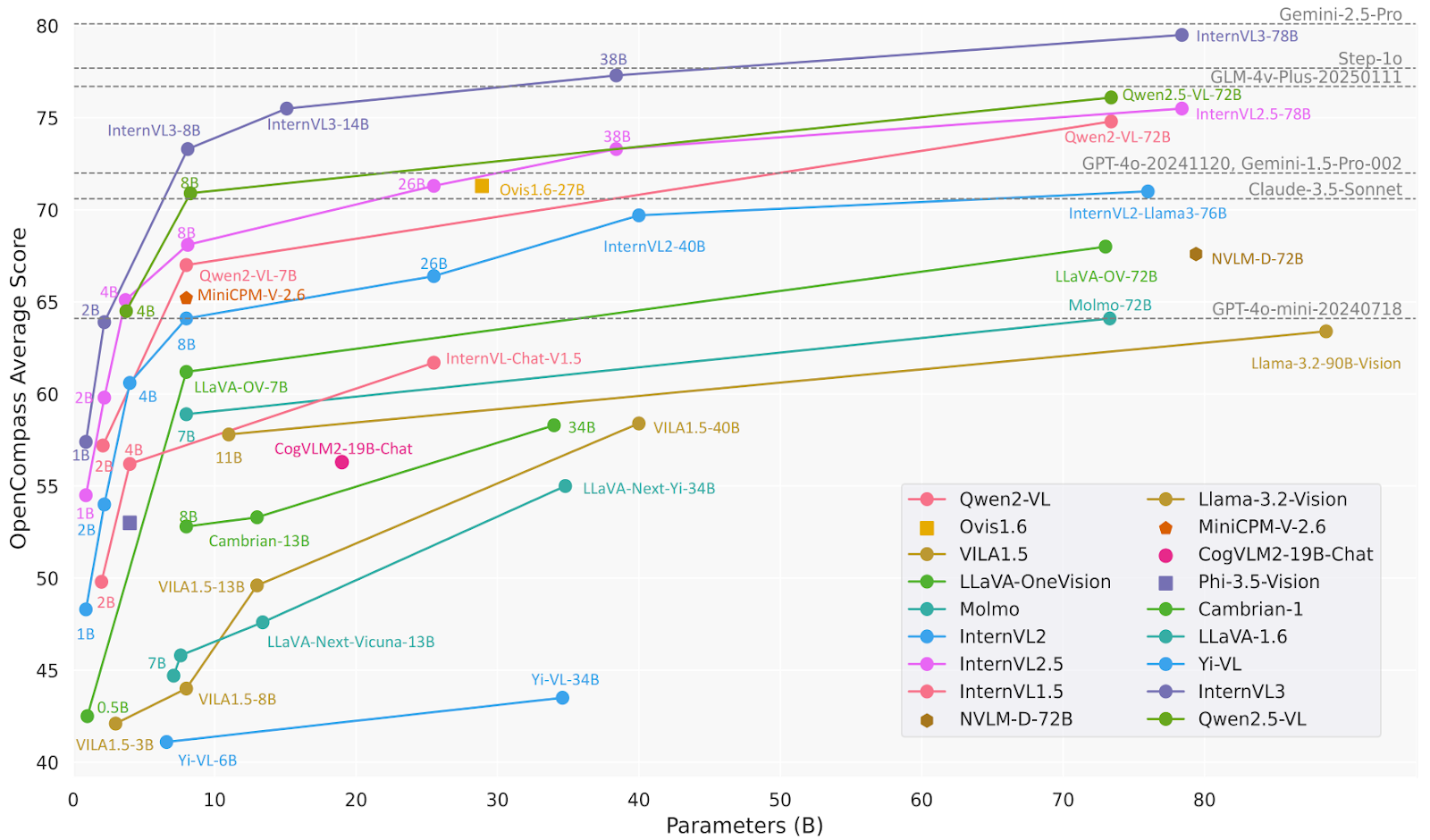
Source: OpenGVLab/InternVL3-78B · Hugging Face
Example usage:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 is a series of multimodal large language models (MLLMs) developed by AIDC-AI. These models are designed to align visual and textual embeddings effectively. The Ovis2-34B model, in particular, utilizes the aimv2-1B-patch14-448 as its vision encoder and Qwen2.5-32B-Instruct as its language model, totaling 34 billion parameters. It supports a maximum context length of 32,768 tokens and uses bfloat16 precision for efficient processing.
Ovis2-34B has shown strong performance on various benchmark tests, achieving the following results:
Source: AIDC-AI/Ovis2-34B · Hugging Face
Example usage:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct is a multimodal large language model (MLLM) from the Qwen family, designed to understand and process both visual and textual information. Many open-source MLLM models are based on it, indicating that the Qwen model series plays a significant role in advancing AI research.
Qwen2.5-VL-72B-Instruct demonstrates strong performance across various benchmarks, including its capabilities in image and video understanding as well as agent functions. It scores 70.2 on the MMMUval benchmark, 74.8 on MathVista_MINI, and 70.8 on MMStar.
Source: Qwen/Qwen2.5-VL-72B-Instruct · Hugging Face
Example usage:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)OpenAI's o3 is a new reasoning model designed to provide higher intelligence, lower costs, and more efficient token usage in applications. It represents a new generation of models that emphasize advanced reasoning capabilities.
This model sets a new standard for tasks in math, science, coding, and visual reasoning. In terms of various vision benchmarks, it outperforms both o4-min and o1, and is on par with o3 Pro.
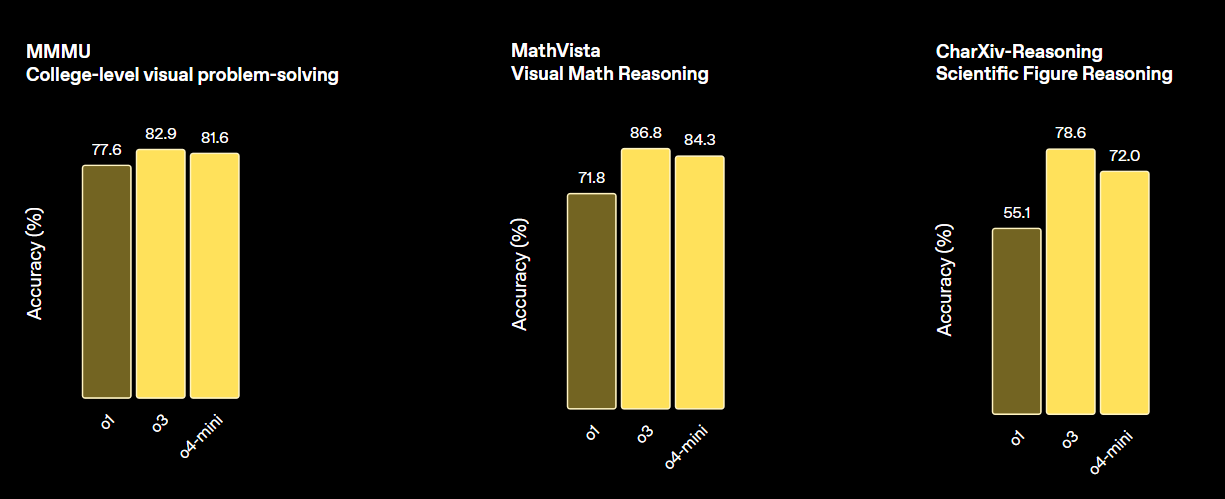
Source: Introducing OpenAI o3 and o4-mini | OpenAI
Example usage:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 is a new family of non-reasoning models, which includes GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. These models have outperformed their predecessors, GPT-4o and GPT-4o Mini, across various benchmarks.
GPT-4.1 retains strong vision capabilities, with improvements in analyzing charts, diagrams, and visual mathematics. It excels at tasks such as object counting, visual question answering, and various forms of optical character recognition (OCR).
Source: Introducing GPT-4.1 in the API | OpenAI
Example usage:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic has introduced the next generation of its Claude models: Claude 4 Opus and Claude 4 Sonnet. These models are designed to set new standards in coding, advanced reasoning, and AI capabilities.
They come with improved vision capabilities that users can use to understand images and then generate code or provide information based on those images. While it is fundamentally a coding model, it also boasts multimodal capabilities, allowing it to understand different types of file formats.
If you refer to the comparison table below, you will see that Claude 4 outperforms all top models, except for OpenAI's GPT-3 model, particularly in visualization reasoning and visual question answering.
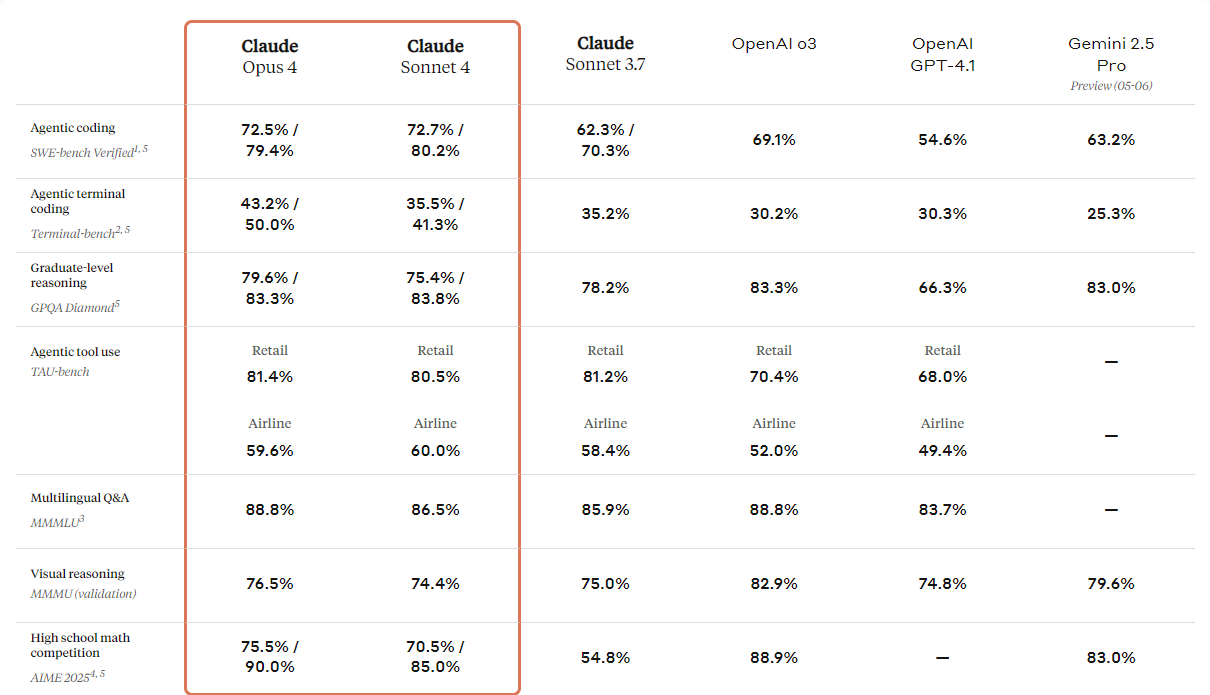
Source: Introducing Claude 4 \ Anthropic
Example usage:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)The Kimi-VL-A3B-Thinking-2506 is an open-source model that marks a significant advancement in multimodal AI. It excels in multimodal reasoning benchmarks, achieving impressive accuracy scores: 56.9 on MathVision, 80.1 on MathVista, 46.3 on MMMU-Pro, and 64.0 on MMMU, while reducing its "thinking length" by an average of 20%.
In addition to its reasoning capabilities, the 2506 version demonstrates enhanced general visual perception and understanding. It matches or even surpasses the performance of non-thinking models on benchmarks such as MMBench-EN-v1.1 (84.4), MMStar (70.4), RealWorldQA (70.0), and MMVet (78.4).
Source: MoonshotAI/Kimi-VL: Kimi-VL
Example usage:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 is a family of multimodal AI models developed by Google, capable of processing both text and image inputs to produce text outputs. These models are available in various sizes: 1B, 4B, 12B, and 27B, catering to different hardware and performance requirements.
The largest variant, Gemma 3 27B, has shown impressive performance in human preference evaluations, even surpassing larger models such as Llama 3-405B and DeepSeek-V3.
The models demonstrate strong capabilities across various benchmarks. Specifically, they excel in multimodal tasks, achieving notable scores on benchmarks like COCOcap (116), DocVQA (85.6), MMMU (56.1), and VQAv2 (72.9).
Source: Open VLM Leaderboard
Example usage:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)The Llama 3.2 90B Vision Instruct model is an advanced multimodal large language model developed by Meta. It is designed for tasks involving visual recognition, image reasoning, and captioning.
Llama 3.2 90B Vision Instruct is built upon the Llama 3.1 text-only version and incorporates a separately trained vision adapter, which enables it to process both images and text as inputs, generating precise text outputs.
Trained on a massive scale, the Llama 3.2 90B Vision model required 8.85 million GPU hours. It demonstrates exceptional performance on benchmarks such as VQAv2 (73.6), Text VQA (73.5), and DocVQA (70.7).
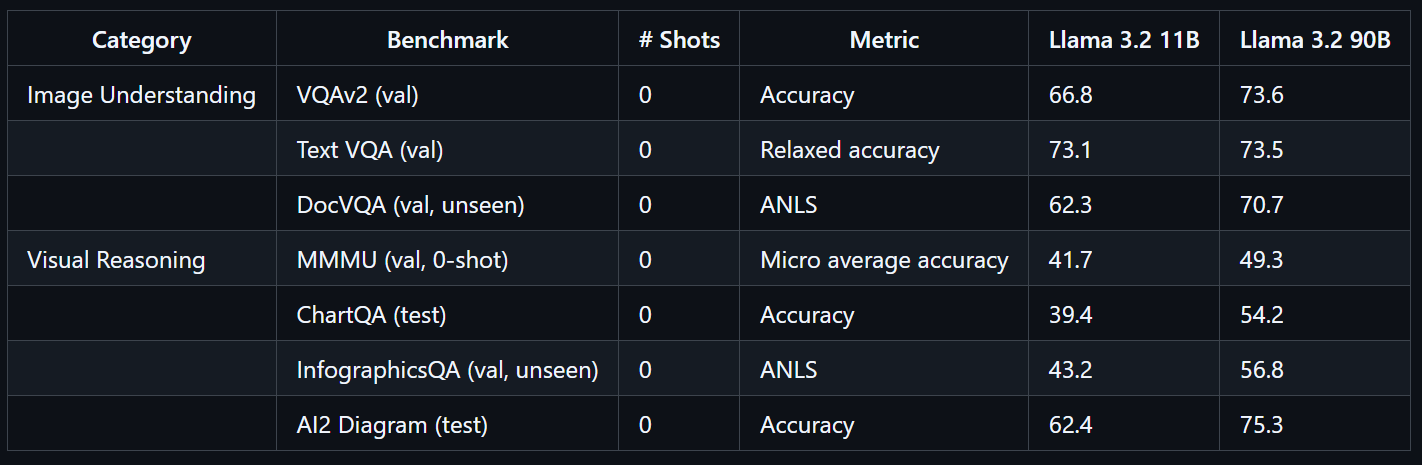
Source: llama-models
Example usage:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Visual reasoning with graphs is also the strength of Meta's newest model, Muse Spark.
Vision-language models are fundamentally transforming how we interact with both visual and textual information, delivering remarkable accuracy and flexibility across a wide range of industries. These models seamlessly blend computer vision and natural language processing, enabling new applications from advanced object detection to intuitive visual assistants.
If privacy and security are top priorities for your use case, I highly recommend exploring open-source vision-language models. Running these models locally gives you full control over your data, making them ideal for sensitive environments. Open-source VLMs are also highly adaptable; most can be fine-tuned on just a few hundred samples to achieve excellent results tailored to your specific needs.
Proprietary models, on the other hand, provide reliable and cost-effective access to state-of-the-art capabilities. They tend to be highly accurate and can be integrated into your workflow with just a few lines of code, making them accessible even for teams without deep AI expertise.
If you’re eager to learn more about vision language models, be sure to check out these resources:
Top DataCamp Courses
Track
Course
Course
blog
Abid Ali Awan
9 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Bhavishya Pandit
8 min
blog
Abid Ali Awan
13 min
blog
Bex Tuychiev
15 min
blog
Andrea Valenzuela
10 min
