
Leerpad
Natuurlijke taalverwerking in Python
20 Hr
Vision Language Models (VLM's) veranderen razendsnel hele sectoren doordat ze AI-systemen in staat stellen zowel afbeeldingen als tekst te begrijpen en daarover te redeneren. In tegenstelling tot traditionele computer vision-modellen kunnen moderne VLM's complexe beelden interpreteren, gedetailleerde vragen over visuele content beantwoorden en zelfs video's en documenten met ingesloten tekst verwerken.
Dankzij deze eigenschap zijn ze van onschatbare waarde voor medische diagnostiek, geautomatiseerde kwaliteitscontrole en gevoelige toepassingen waar precisie belangrijker is dan snelheid.
In deze blog bespreken we de beste vision-language modellen van 2026, zowel open-source als proprietair. We lichten hun unieke mogelijkheden uit en presenteren vervolgens hun prestaties en benchmarkresultaten. Voor developers en onderzoekers hebben we ook voorbeeldcode opgenomen, zodat je deze modellen snel zelf kunt uitproberen.
Wil je meer leren over de basis van deze modellen? Bekijk dan zeker onze Image Processing in Python skill track.
Gemini 2.5 Pro is Googles meest geavanceerde AI-model en voert momenteel de LMArena- en WebDevArena-ranglijsten aan voor zowel visie- als coderingstaken. Het is ontworpen voor complex redeneren en begrip over tekst, afbeeldingen, audio en video.
Qua vision-language mogelijkheden behoort het tot de topmodellen op het Open LLM-leaderboard. Gemini 2.5 Pro kan beelden en video's interpreteren, gedetailleerde en contextbewuste beschrijvingen genereren en vragen over visuele content beantwoorden.
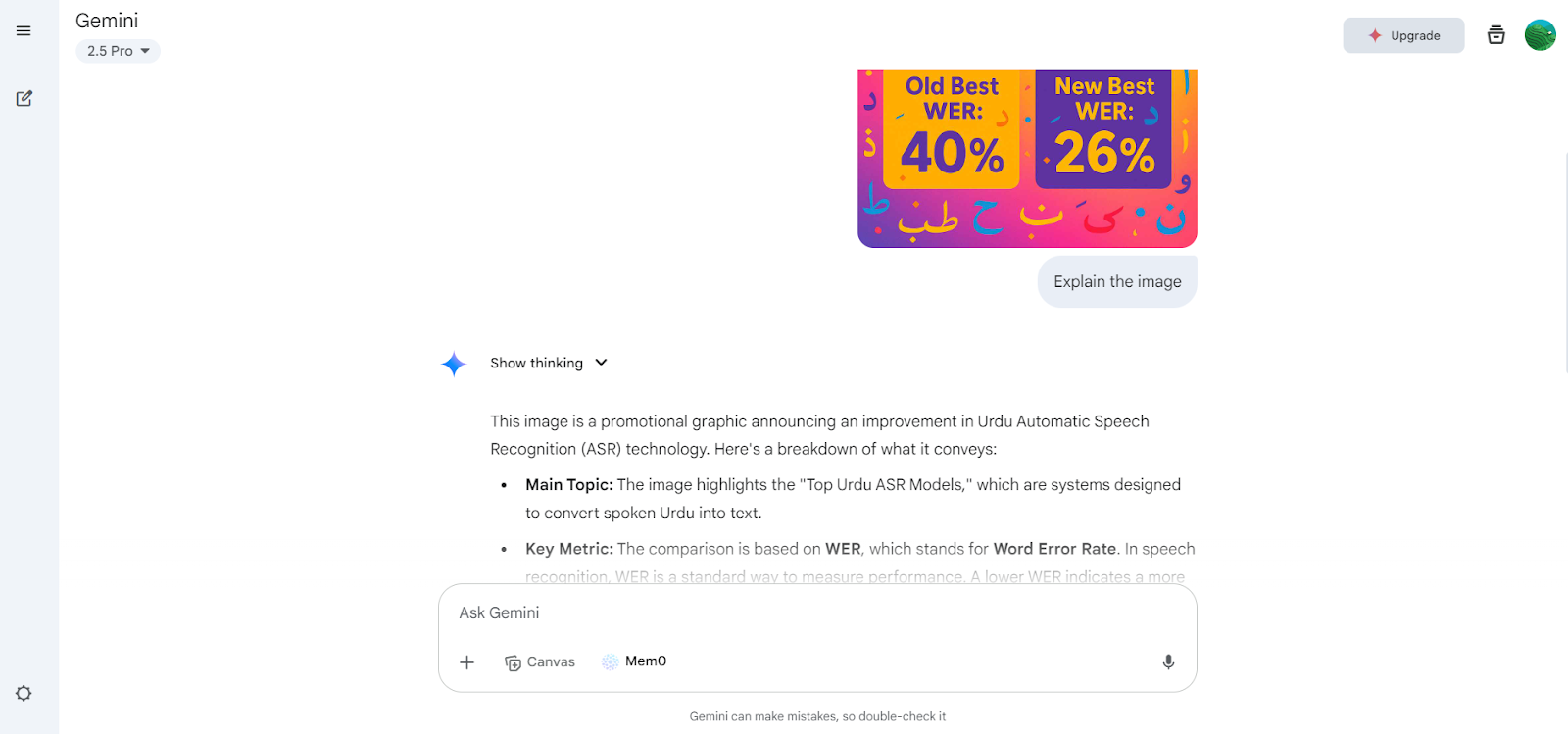
Bron: Google Gemini
Je kunt Gemini 2.5 Pro gratis gebruiken via de Gemini webapp op gemini.google.com/app of via Google AI Studio.
Voor developers is Gemini 2.5 Pro ook beschikbaar via de Gemini API, Vertex AI en de officiële Python SDK, zodat je de vision-language functies eenvoudig in je eigen apps of workflows kunt integreren.
Voorbeeldgebruik:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)InternVL3 is een geavanceerde serie multimodale large language modellen (MLLM's) die zijn voorganger InternVL 2.5 overtreft. Het blinkt uit in multimodale perceptie en redeneren en heeft verbeterde mogelijkheden, waaronder toolgebruik, GUI-agents, industriële beeldanalyse en 3D-visieperceptie.
Het InternVL3-78B-model gebruikt specifiek InternViT-6B-448px-V2_5 voor het visuele onderdeel en Qwen2.5-72B voor het taalonderdeel. Met in totaal 78,41 miljard parameters behaalde InternVL3-78B een score van 72,2 op de MMMU-benchmark, een nieuwe state-of-the-art onder open-source MLLM's. De prestaties zijn competitief met toonaangevende proprietaire modellen.
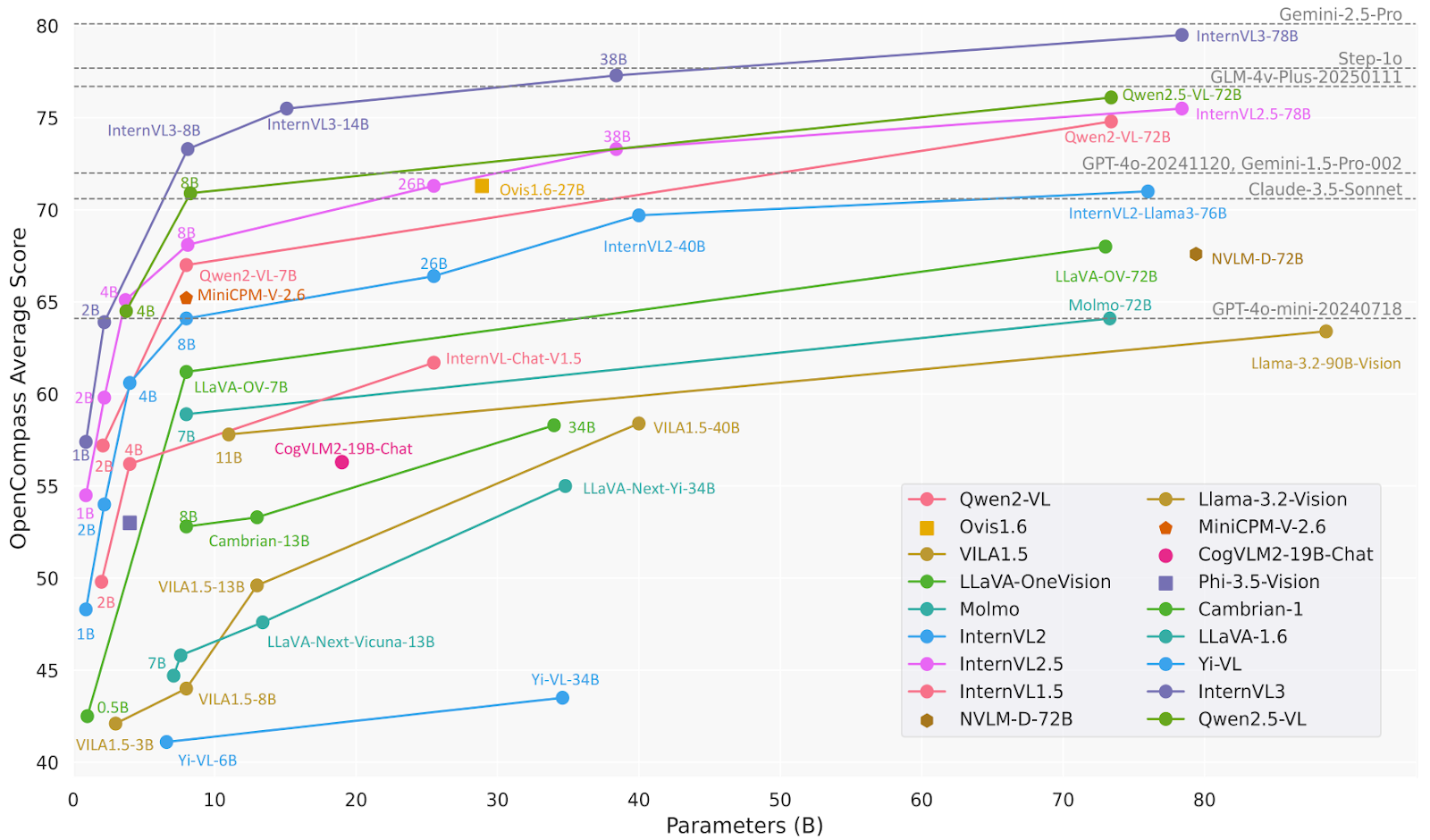
Bron: OpenGVLab/InternVL3-78B · Hugging Face
Voorbeeldgebruik:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 is een serie multimodale large language modellen (MLLM's) ontwikkeld door AIDC-AI. Deze modellen zijn ontworpen om visuele en tekstuele embeddings effectief op elkaar af te stemmen. Het Ovis2-34B-model gebruikt met name de aimv2-1B-patch14-448 als vision-encoder en Qwen2.5-32B-Instruct als taalmodel, goed voor in totaal 34 miljard parameters. Het ondersteunt een maximale contextlengte van 32.768 tokens en gebruikt bfloat16-precisie voor efficiënte verwerking.
Ovis2-34B heeft sterke prestaties laten zien op verschillende benchmarks en behaalde de volgende resultaten:
Bron: AIDC-AI/Ovis2-34B · Hugging Face
Voorbeeldgebruik:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct is een multimodaal large language model (MLLM) uit de Qwen-familie, ontworpen om zowel visuele als tekstuele informatie te begrijpen en te verwerken. Veel open-source MLLM-modellen zijn hierop gebaseerd, wat aangeeft dat de Qwen-modellenreeks een belangrijke rol speelt in de vooruitgang van AI-onderzoek.
Qwen2.5-VL-72B-Instruct laat sterke prestaties zien op diverse benchmarks, waaronder beeld- en videoverwerking en agentfuncties. Het scoort 70,2 op de MMMUval-benchmark, 74,8 op MathVista_MINI en 70,8 op MMStar.
Bron: Qwen/Qwen2.5-VL-72B-Instruct · Hugging Face
Voorbeeldgebruik:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)OpenAI's o3 is een nieuw redeneermodel dat is ontworpen voor hogere intelligentie, lagere kosten en efficiënter tokengebruik in toepassingen. Het vertegenwoordigt een nieuwe generatie modellen met de nadruk op geavanceerde redeneercapaciteiten.
Dit model zet een nieuwe standaard voor taken in wiskunde, wetenschap, coderen en visuele redenering. Op verschillende vision-benchmarks presteert het beter dan zowel o4-min als o1 en het is vergelijkbaar met o3 Pro.
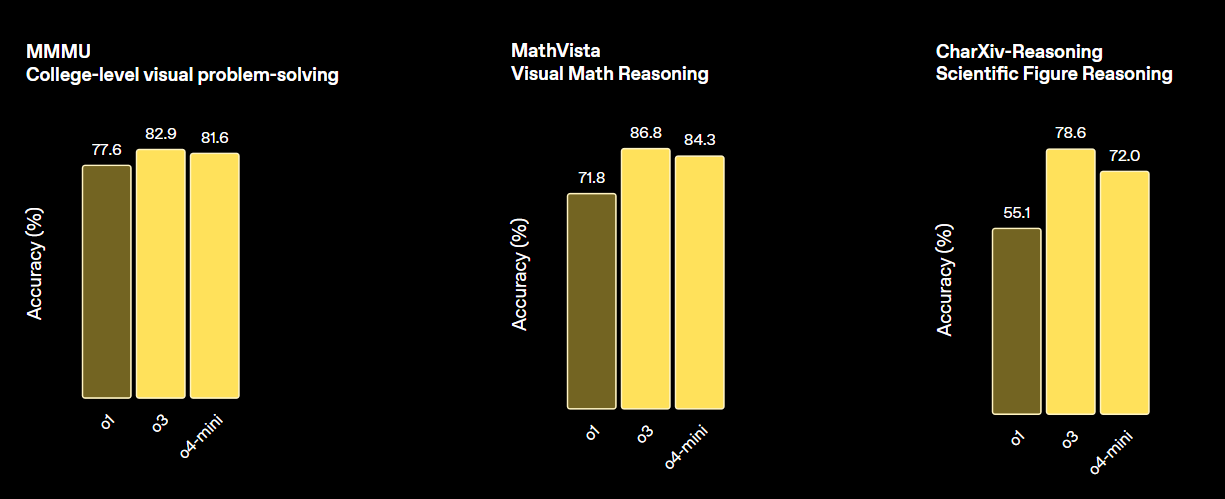
Bron: Introducing OpenAI o3 and o4-mini | OpenAI
Voorbeeldgebruik:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 is een nieuwe familie niet-redeneermodellen, waaronder GPT-4.1, GPT-4.1 Mini en GPT-4.1 Nano. Deze modellen presteren beter dan hun voorgangers, GPT-4o en GPT-4o Mini, op verschillende benchmarks.
GPT-4.1 behoudt sterke visuele capaciteiten, met verbeteringen in het analyseren van grafieken, diagrammen en visuele wiskunde. Het blinkt uit in taken zoals objectentelling, visuele vraagbeantwoording en diverse vormen van optical character recognition (OCR).
Bron: Introducing GPT-4.1 in the API | OpenAI
Voorbeeldgebruik:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic heeft de volgende generatie van zijn Claude-modellen geïntroduceerd: Claude 4 Opus en Claude 4 Sonnet. Deze modellen zijn ontworpen om nieuwe standaarden te zetten in coderen, geavanceerd redeneren en AI-capaciteiten.
Ze komen met verbeterde visuele mogelijkheden die gebruikers kunnen inzetten om afbeeldingen te begrijpen en vervolgens code te genereren of informatie te geven op basis van die afbeeldingen. Hoewel het in de kern een codemodel is, beschikt het ook over multimodale mogelijkheden, waardoor het verschillende bestandsformaten kan begrijpen.
In de vergelijkingstabel hieronder zie je dat Claude 4 alle topmodellen overtreft, behalve OpenAI's GPT-3-model, vooral in visuele redenering en visuele vraagbeantwoording.
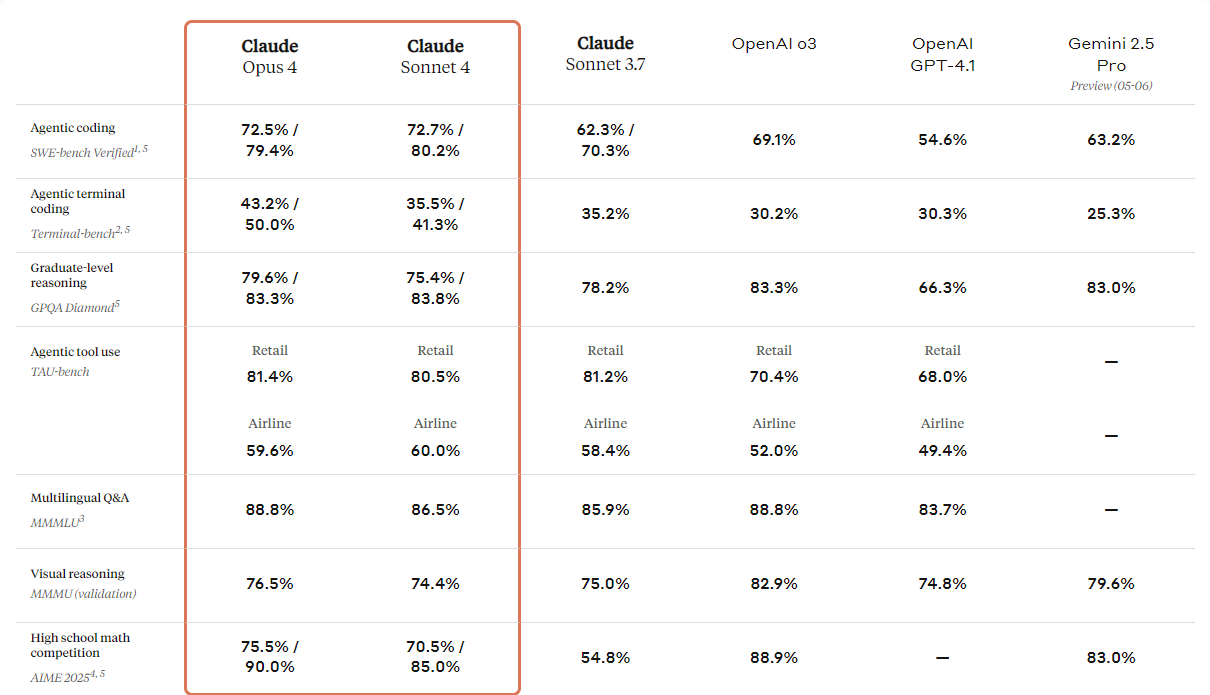
Bron: Introducing Claude 4 \ Anthropic
Voorbeeldgebruik:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)De Kimi-VL-A3B-Thinking-2506 is een open-source model dat een belangrijke stap vooruit markeert in multimodale AI. Het blinkt uit op multimodale redeneerbenchmarks en behaalt indrukwekkende nauwkeurigheidsscores: 56,9 op MathVision, 80,1 op MathVista, 46,3 op MMMU-Pro en 64,0 op MMMU, terwijl de "denk-lengte" gemiddeld met 20% wordt verkort.
Naast de redeneercapaciteiten toont de 2506-versie verbeterde algemene visuele perceptie en begrip. Het evenaart of overtreft zelfs de prestaties van niet-denkende modellen op benchmarks zoals MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0) en MMVet (78,4).
Bron: MoonshotAI/Kimi-VL: Kimi-VL
Voorbeeldgebruik:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 is een familie multimodale AI-modellen ontwikkeld door Google, die zowel tekst- als beeldinvoer kunnen verwerken en tekstuitvoer genereren. Deze modellen zijn beschikbaar in verschillende groottes: 1B, 4B, 12B en 27B, passend bij uiteenlopende hardware- en prestatie-eisen.
De grootste variant, Gemma 3 27B, heeft indrukwekkende prestaties laten zien in beoordelingen van menselijke voorkeuren, en overtreft zelfs grotere modellen zoals Llama 3-405B en DeepSeek-V3.
De modellen tonen sterke capaciteiten op diverse benchmarks. Ze excelleren met name in multimodale taken en behalen opvallende scores op benchmarks zoals COCOcap (116), DocVQA (85,6), MMMU (56,1) en VQAv2 (72,9).
Bron: Open VLM Leaderboard
Voorbeeldgebruik:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)Het Llama 3.2 90B Vision Instruct-model is een geavanceerd multimodaal large language model ontwikkeld door Meta. Het is ontworpen voor taken als visuele herkenning, beeldredenering en captioning.
Llama 3.2 90B Vision Instruct is gebaseerd op de tekst-only versie Llama 3.1 en bevat een apart getrainde visie-adapter, waardoor het zowel afbeeldingen als tekst als input kan verwerken en nauwkeurige tekstuitvoer kan genereren.
Het Llama 3.2 90B Vision-model is op enorme schaal getraind en vergde 8,85 miljoen GPU-uren. Het toont uitstekende prestaties op benchmarks zoals VQAv2 (73,6), Text VQA (73,5) en DocVQA (70,7).
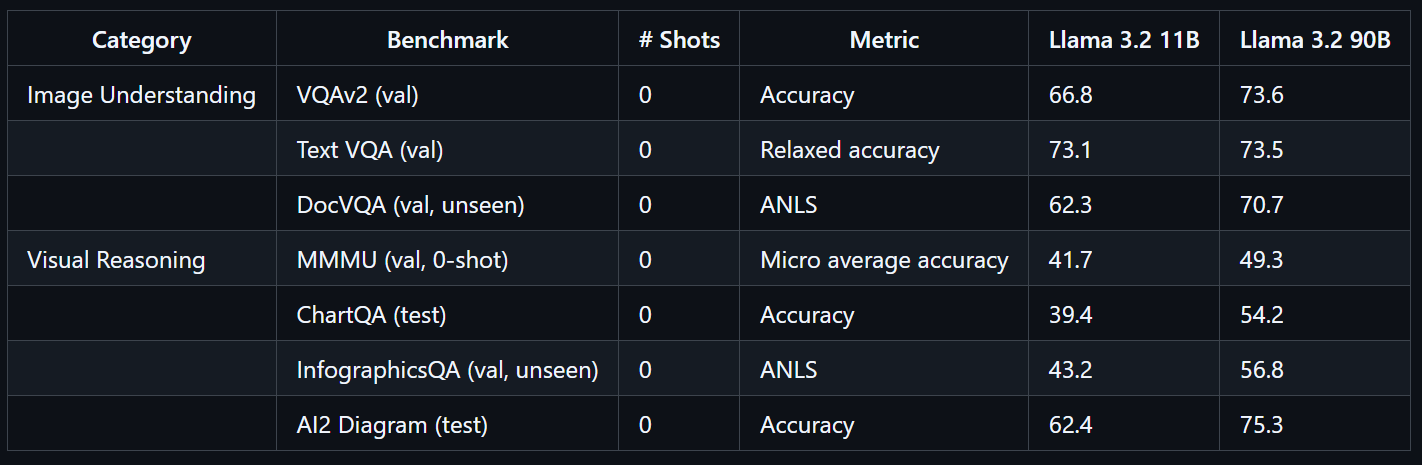
Bron: llama-models
Voorbeeldgebruik:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Visuele redenering met grafieken is ook de kracht van Meta's nieuwste model, Muse Spark.
Vision-language modellen veranderen fundamenteel hoe we met visuele en tekstuele informatie omgaan. Ze leveren opmerkelijke nauwkeurigheid en flexibiliteit in uiteenlopende sectoren. Deze modellen combineren moeiteloos computer vision en natural language processing en maken nieuwe toepassingen mogelijk, van geavanceerde objectdetectie tot intuïtieve visuele assistenten.
Als privacy en veiligheid topprioriteit hebben voor jouw usecase, raad ik aan om open-source vision-language modellen te verkennen. Door deze modellen lokaal te draaien, houd je volledige controle over je data, ideaal voor gevoelige omgevingen. Open-source VLM's zijn bovendien zeer aanpasbaar; de meeste kun je met een paar honderd voorbeelden fijn-afstemmen voor uitstekende, op jouw behoeften toegesneden resultaten.
Proprietaire modellen bieden daarentegen betrouwbare en kosteneffectieve toegang tot state-of-the-art capaciteiten. Ze zijn vaak zeer nauwkeurig en met een paar regels code in je workflow te integreren, waardoor ze ook toegankelijk zijn voor teams zonder diepe AI-expertise.
Wil je meer leren over vision-language modellen? Bekijk dan zeker deze bronnen:
Topcursussen op DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
