
Tracks
Xử lý ngôn ngữ tự nhiên trong Python
20 giờ
Các Mô hình Ngôn ngữ Thị giác (VLMs) đang nhanh chóng thay đổi các ngành bằng cách giúp hệ thống AI hiểu và suy luận về cả hình ảnh lẫn văn bản. Khác với các mô hình thị giác máy tính truyền thống, VLM hiện đại có thể diễn giải hình ảnh phức tạp, trả lời các câu hỏi chi tiết về nội dung trực quan, và thậm chí xử lý video lẫn tài liệu có văn bản nhúng.
Tính năng này khiến chúng trở nên vô giá cho chẩn đoán y khoa, kiểm soát chất lượng tự động, và các ứng dụng nhạy cảm nơi độ chính xác quan trọng hơn tốc độ.
Trong bài viết này, chúng tôi sẽ điểm qua các mô hình ngôn ngữ-thị giác hàng đầu năm 2026, bao gồm cả lựa chọn mã nguồn mở và độc quyền. Chúng tôi sẽ nêu bật các khả năng nổi trội của từng mô hình, sau đó trình bày hiệu năng và kết quả đánh giá chuẩn. Dành cho nhà phát triển và nhà nghiên cứu, chúng tôi cũng cung cấp các đoạn mã ví dụ để bạn có thể nhanh chóng tự thử các mô hình này.
Nếu bạn muốn tìm hiểu thêm về kiến thức nền tảng của các mô hình này, đừng quên xem Image Processing in Python skill track của chúng tôi.
Gemini 2.5 Pro là mô hình AI tiên tiến nhất của Google, hiện đang dẫn đầu bảng xếp hạng LMArena và WebDevArena cho cả tác vụ thị giác và lập trình. Mô hình được thiết kế cho suy luận phức tạp và hiểu biết đa phương thức trên văn bản, hình ảnh, âm thanh và video.
Xét về năng lực ngôn ngữ-thị giác, đây là một trong các mô hình dẫn đầu trên bảng xếp hạng Open LLM. Gemini 2.5 Pro có thể diễn giải hình ảnh và video, tạo mô tả chi tiết theo ngữ cảnh đồng thời trả lời câu hỏi liên quan đến nội dung trực quan.
Nguồn: Google Gemini
Bạn có thể truy cập Gemini 2.5 Pro miễn phí qua ứng dụng web Gemini tại gemini.google.com/app hoặc thông qua Google AI Studio.
Dành cho nhà phát triển, Gemini 2.5 Pro cũng có sẵn qua Gemini API, Vertex AI và SDK Python chính thức, giúp dễ dàng tích hợp các tính năng ngôn ngữ-thị giác vào ứng dụng hoặc quy trình làm việc của bạn.
Ví dụ sử dụng:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)InternVL3 là dòng mô hình ngôn ngữ lớn đa phương thức (MLLM) tiên tiến, vượt trội so với tiền nhiệm InternVL 2.5. Mô hình xuất sắc ở nhận thức đa phương thức và suy luận, đồng thời tăng cường các năng lực như sử dụng công cụ, tác tử GUI, phân tích ảnh công nghiệp và cảm nhận thị giác 3D.
Cụ thể, InternVL3-78B dùng InternViT-6B-448px-V2_5 cho thành phần thị giác và Qwen2.5-72B cho thành phần ngôn ngữ. Với tổng cộng 78,41 tỷ tham số, InternVL3-78B đạt 72,2 điểm trên bộ đánh giá MMMU, thiết lập kỷ lục mới cho MLLM mã nguồn mở. Hiệu năng của nó cạnh tranh với các mô hình độc quyền hàng đầu.
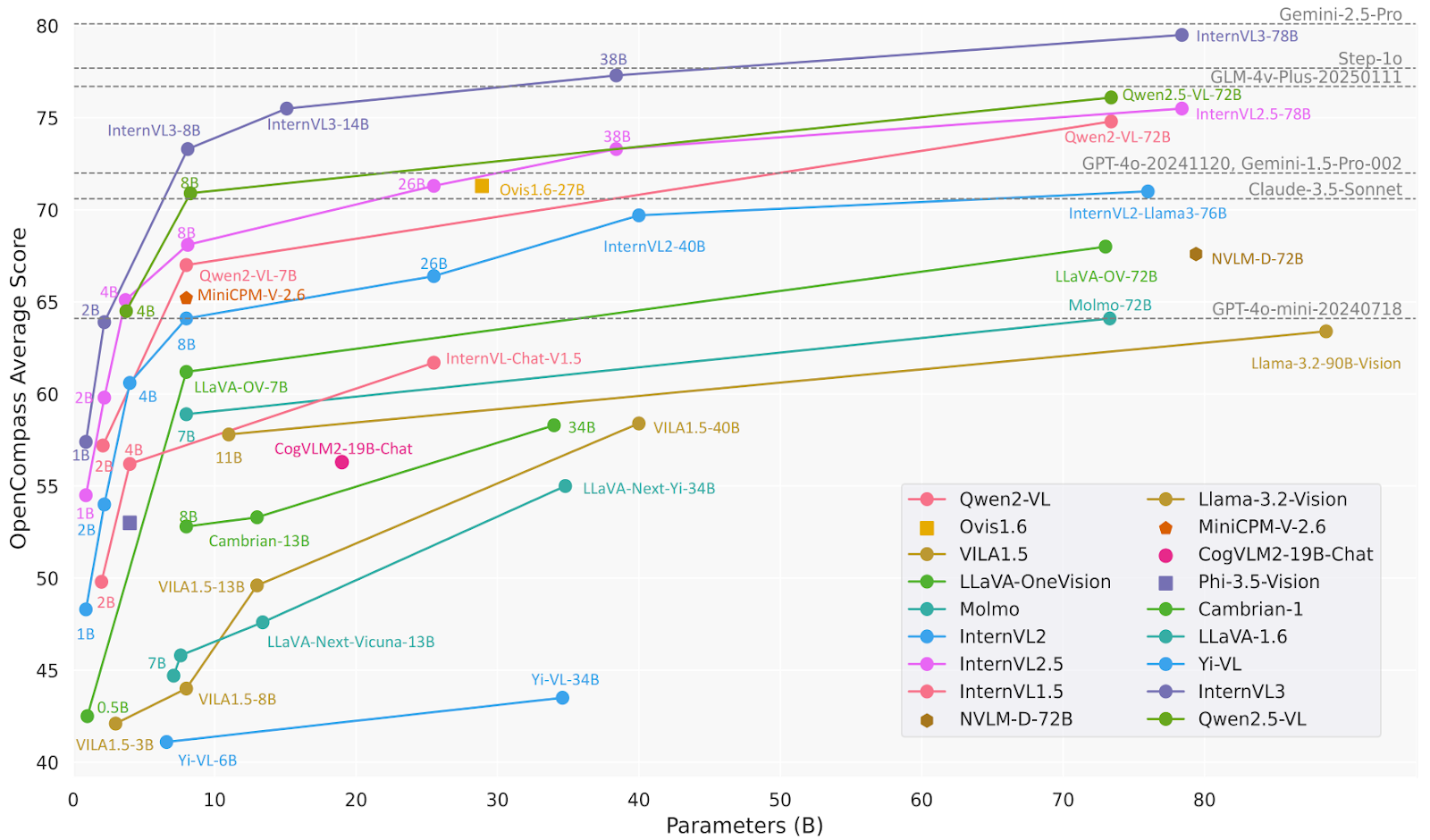
Nguồn: OpenGVLab/InternVL3-78B · Hugging Face
Ví dụ sử dụng:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 là dòng mô hình ngôn ngữ lớn đa phương thức (MLLM) do AIDC-AI phát triển. Các mô hình này được thiết kế để căn chỉnh hiệu quả các vector nhúng thị giác và văn bản. Đặc biệt, Ovis2-34B sử dụng aimv2-1B-patch14-448 làm bộ mã hóa thị giác và Qwen2.5-32B-Instruct làm mô hình ngôn ngữ, tổng cộng 34 tỷ tham số. Mô hình hỗ trợ độ dài ngữ cảnh tối đa 32.768 token và dùng độ chính xác bfloat16 để xử lý hiệu quả.
Ovis2-34B cho thấy hiệu năng mạnh trên nhiều bài kiểm tra chuẩn, đạt các kết quả sau:
Nguồn: AIDC-AI/Ovis2-34B · Hugging Face
Ví dụ sử dụng:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct là mô hình ngôn ngữ lớn đa phương thức (MLLM) thuộc họ Qwen, được thiết kế để hiểu và xử lý cả thông tin trực quan lẫn văn bản. Nhiều MLLM mã nguồn mở được xây dựng dựa trên nó, cho thấy dòng Qwen đóng vai trò quan trọng trong thúc đẩy nghiên cứu AI.
Qwen2.5-VL-72B-Instruct thể hiện hiệu năng mạnh trên nhiều bộ đánh giá, bao gồm khả năng hiểu hình ảnh và video cũng như các chức năng tác tử. Mô hình đạt 70,2 trên MMMUval, 74,8 trên MathVista_MINI và 70,8 trên MMStar.
Nguồn: Qwen/Qwen2.5-VL-72B-Instruct · Hugging Face
Ví dụ sử dụng:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)o3 của OpenAI là một mô hình suy luận mới được thiết kế để mang lại độ thông minh cao hơn, chi phí thấp hơn và sử dụng token hiệu quả hơn trong ứng dụng. Đây là thế hệ mô hình mới nhấn mạnh khả năng suy luận nâng cao.
Mô hình này đặt ra tiêu chuẩn mới cho các tác vụ toán học, khoa học, lập trình và suy luận thị giác. Trên nhiều thang đo thị giác, nó vượt trội cả o4-min và o1, và tương đương với o3 Pro.
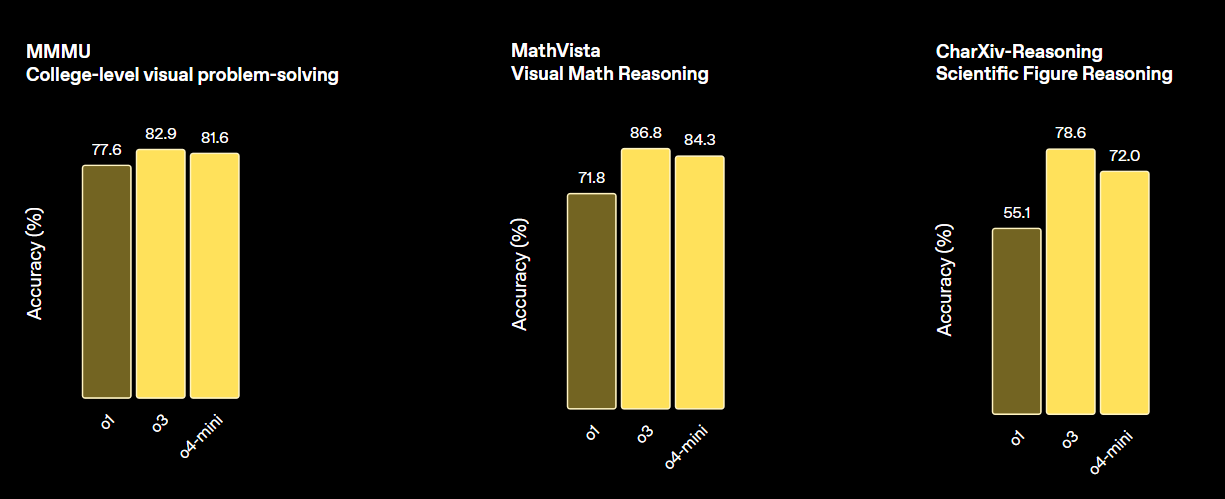
Nguồn: Introducing OpenAI o3 and o4-mini | OpenAI
Ví dụ sử dụng:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 là một họ mô hình không suy luận, gồm GPT-4.1, GPT-4.1 Mini và GPT-4.1 Nano. Các mô hình này vượt trội hơn so với tiền nhiệm GPT-4o và GPT-4o Mini trên nhiều thang đo.
GPT-4.1 giữ vững năng lực thị giác mạnh mẽ, với cải tiến trong phân tích biểu đồ, sơ đồ và toán học trực quan. Mô hình xuất sắc ở các tác vụ như đếm đối tượng, trả lời câu hỏi trực quan và nhiều dạng nhận dạng ký tự quang học (OCR).
Nguồn: Introducing GPT-4.1 in the API | OpenAI
Ví dụ sử dụng:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic đã giới thiệu thế hệ tiếp theo của dòng Claude: Claude 4 Opus và Claude 4 Sonnet. Các mô hình này được thiết kế để đặt ra tiêu chuẩn mới trong lập trình, suy luận nâng cao và năng lực AI.
Chúng đi kèm năng lực thị giác cải thiện, cho phép người dùng hiểu hình ảnh rồi tạo mã hoặc cung cấp thông tin dựa trên những hình ảnh đó. Dù về cơ bản là mô hình lập trình, nó cũng có năng lực đa phương thức, giúp hiểu nhiều định dạng tệp khác nhau.
Tham chiếu bảng so sánh bên dưới, bạn sẽ thấy Claude 4 vượt qua hầu hết các mô hình hàng đầu, ngoại trừ mô hình GPT-3 của OpenAI, đặc biệt ở suy luận trực quan và trả lời câu hỏi trực quan.
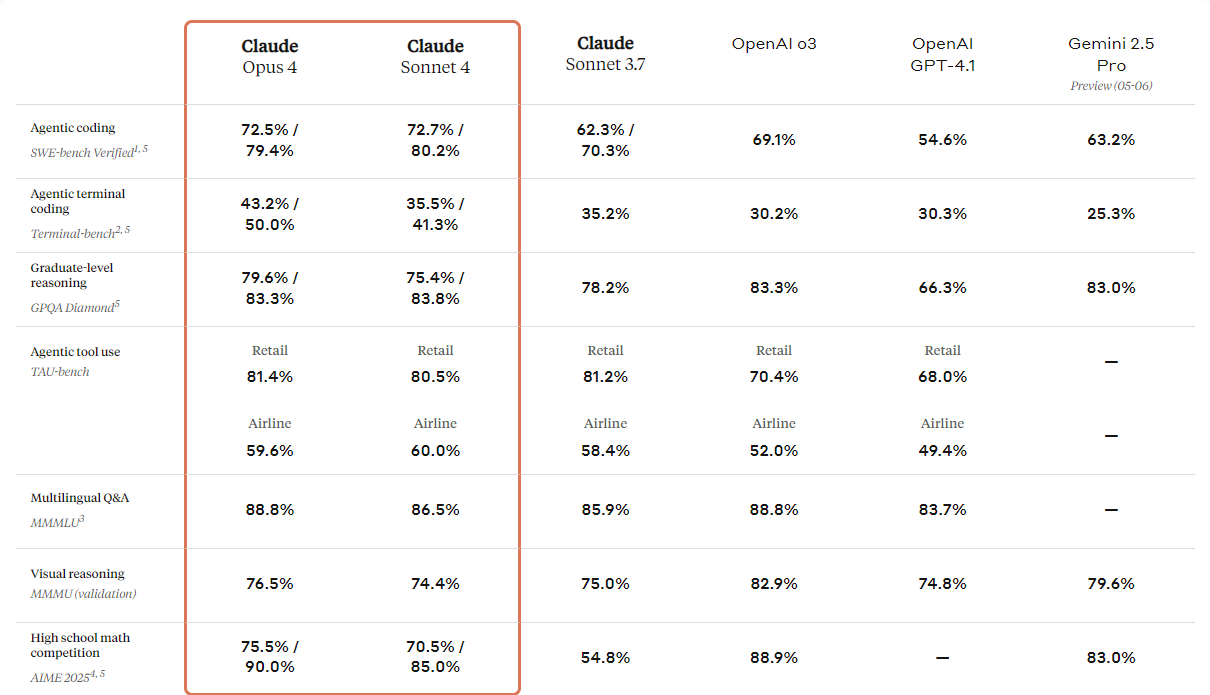
Nguồn: Introducing Claude 4 \ Anthropic
Ví dụ sử dụng:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)Kimi-VL-A3B-Thinking-2506 là một mô hình mã nguồn mở đánh dấu bước tiến quan trọng trong AI đa phương thức. Mô hình xuất sắc ở các chuẩn đánh giá suy luận đa phương thức, đạt độ chính xác ấn tượng: 56,9 trên MathVision, 80,1 trên MathVista, 46,3 trên MMMU-Pro và 64,0 trên MMMU, đồng thời giảm "độ dài suy nghĩ" trung bình 20%.
Ngoài khả năng suy luận, phiên bản 2506 còn thể hiện năng lực nhận thức và hiểu thị giác tổng quát được cải thiện. Mô hình sánh ngang hoặc thậm chí vượt các mô hình không suy luận trên các thang đo như MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0) và MMVet (78,4).
Nguồn: MoonshotAI/Kimi-VL: Kimi-VL
Ví dụ sử dụng:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 là họ mô hình AI đa phương thức do Google phát triển, có khả năng xử lý cả đầu vào văn bản và hình ảnh để tạo đầu ra văn bản. Các mô hình có nhiều kích cỡ: 1B, 4B, 12B và 27B, phù hợp nhiều yêu cầu phần cứng và hiệu năng.
Biến thể lớn nhất, Gemma 3 27B, thể hiện hiệu năng ấn tượng trong đánh giá theo sở thích của con người, thậm chí vượt các mô hình lớn hơn như Llama 3-405B và DeepSeek-V3.
Các mô hình cho thấy năng lực mạnh trên nhiều thang đo. Cụ thể, chúng xuất sắc ở các tác vụ đa phương thức, đạt điểm nổi bật trên các chuẩn như COCOcap (116), DocVQA (85,6), MMMU (56,1) và VQAv2 (72,9).
Nguồn: Open VLM Leaderboard
Ví dụ sử dụng:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)Mô hình Llama 3.2 90B Vision Instruct là một mô hình ngôn ngữ lớn đa phương thức tiên tiến do Meta phát triển. Nó được thiết kế cho các tác vụ nhận dạng trực quan, suy luận hình ảnh và tạo mô tả.
Llama 3.2 90B Vision Instruct được xây dựng trên phiên bản chỉ-văn-bản Llama 3.1 và tích hợp một bộ tiếp hợp thị giác được huấn luyện riêng, cho phép xử lý cả hình ảnh và văn bản đầu vào để tạo ra đầu ra văn bản chính xác.
Được huấn luyện ở quy mô lớn, mô hình Llama 3.2 90B Vision cần 8,85 triệu giờ GPU. Mô hình thể hiện hiệu năng xuất sắc trên các chuẩn như VQAv2 (73,6), Text VQA (73,5) và DocVQA (70,7).
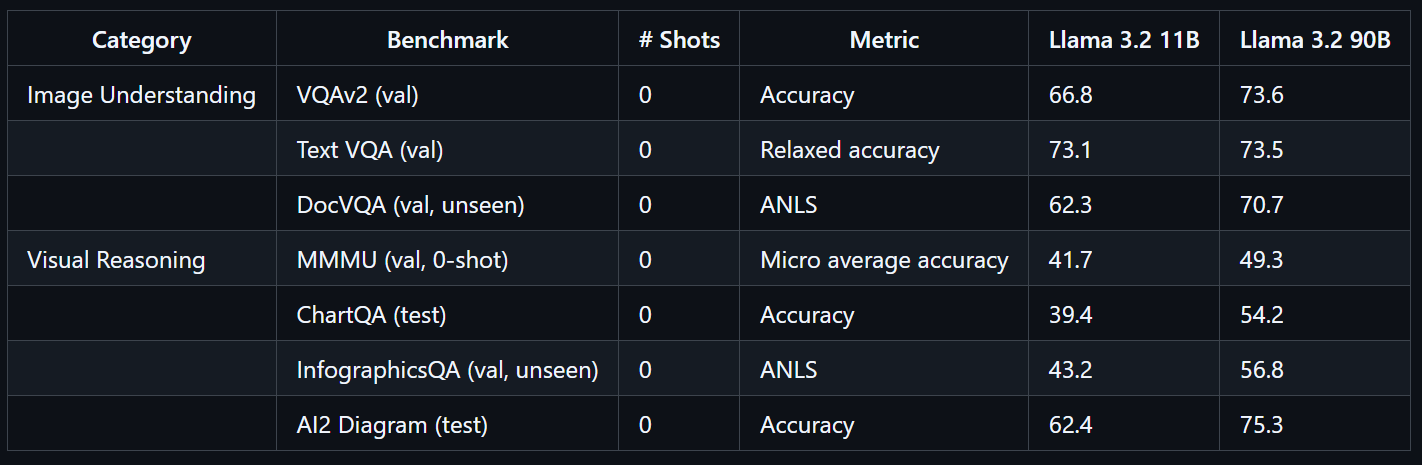
Nguồn: llama-models
Ví dụ sử dụng:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Suy luận trực quan với biểu đồ cũng là thế mạnh của mô hình mới nhất từ Meta, Muse Spark.
Các mô hình ngôn ngữ-thị giác đang làm thay đổi căn bản cách chúng ta tương tác với cả thông tin trực quan và văn bản, mang lại độ chính xác và tính linh hoạt đáng kể trên nhiều ngành. Những mô hình này kết hợp liền mạch thị giác máy tính và xử lý ngôn ngữ tự nhiên, mở ra các ứng dụng mới từ phát hiện đối tượng nâng cao đến trợ lý trực quan thân thiện.
Nếu quyền riêng tư và bảo mật là ưu tiên hàng đầu cho bài toán của bạn, tôi rất khuyến nghị khám phá các mô hình ngôn ngữ-thị giác mã nguồn mở. Chạy các mô hình này cục bộ giúp bạn kiểm soát hoàn toàn dữ liệu, lý tưởng cho môi trường nhạy cảm. VLM mã nguồn mở cũng rất dễ thích ứng; phần lớn có thể tinh chỉnh chỉ với vài trăm mẫu để đạt kết quả xuất sắc theo đúng nhu cầu của bạn.
Trong khi đó, các mô hình độc quyền mang đến khả năng tiếp cận đáng tin cậy và tiết kiệm chi phí đối với công nghệ tiên tiến. Chúng thường rất chính xác và có thể tích hợp vào quy trình làm việc của bạn chỉ với vài dòng mã, phù hợp cả với các đội ngũ chưa có chuyên môn AI sâu.
Nếu bạn muốn tìm hiểu thêm về các mô hình ngôn ngữ-thị giác, hãy xem các tài nguyên sau:
Các khóa học hàng đầu trên DataCamp
Tracks
Courses
Courses