
Programa
Processamento de Linguagem Natural em Python
20 h
Modelos de linguagem visual (VLMs) estão transformando rapidamente os setores, permitindo que os sistemas de IA entendam e raciocinem sobre imagens e textos. Diferente dos modelos tradicionais de visão computacional, os VLMs modernos conseguem entender imagens complexas, responder perguntas detalhadas sobre conteúdo visual e até mesmo processar vídeos e documentos com texto embutido.
Esse recurso os torna super importantes para diagnósticos médicos, controle de qualidade automatizado e aplicações sensíveis, onde a precisão é mais importante do que a velocidade.
Neste blog, vamos dar uma olhada nos principais modelos de linguagem visual de 2026, incluindo opções de código aberto e proprietárias. Vamos destacar suas capacidades únicas e, em seguida, apresentar seu desempenho e resultados de benchmark. Para desenvolvedores e pesquisadores, também colocamos trechos de código de exemplo para que você possa experimentar rapidamente esses modelos por conta própria.
Se você quiser saber mais sobre os fundamentos desses modelos, não deixe de conferir nosso Processamento de Imagens em Python skill track.
Gemini 2.5 Pro é o modelo de IA mais avançado do Google, atualmente liderando os rankings da LMArena e da WebDevArena tanto para tarefas de visão quanto de codificação. Ele foi feito pra lidar com raciocínios e entendimentos complexos em textos, imagens, áudio e vídeo.
Em termos de capacidades de linguagem visual, ele está entre os melhores modelos no ranking Open LLM. O Gemini 2.5 Pro consegue entender imagens e vídeos, criando descrições detalhadas e que entendem o contexto enquanto responde a perguntas relacionadas ao conteúdo visual.
Fonte: Google Gemini
Você pode acessar o Gemini 2.5 Pro de graça pelo aplicativo web Gemini em gemini.google.com/app ou usando o Google AI Studio.
Para desenvolvedores, o Gemini 2.5 Pro também está disponível por meio da API Gemini, Vertex AI e o SDK oficial do Python, facilitando a integração de seus recursos de linguagem visual em seus próprios aplicativos ou fluxos de trabalho.
Exemplo de uso:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)O InternVL3 é uma série avançada de modelos de linguagem multimodais de grande porte (MLLMs) que supera seu antecessor, o InternVL 2.5. Ele é ótimo em percepção e raciocínio multimodal e tem recursos avançados, como uso de ferramentas, agentes GUI, análise de imagens industriais e percepção de visão 3D.
O modelo InternVL3-78B usa especificamente o InternViT-6B-448px-V2_5 para o componente de visão e o Qwen2.5-72B para o componente de linguagem. Com um total de 78,41 bilhões de parâmetros, o InternVL3-78B conseguiu uma pontuação de 72,2 no benchmark MMMU, estabelecendo um novo recorde de ponta entre os MLLMs de código aberto. O desempenho dele é competitivo com o dos principais modelos proprietários.
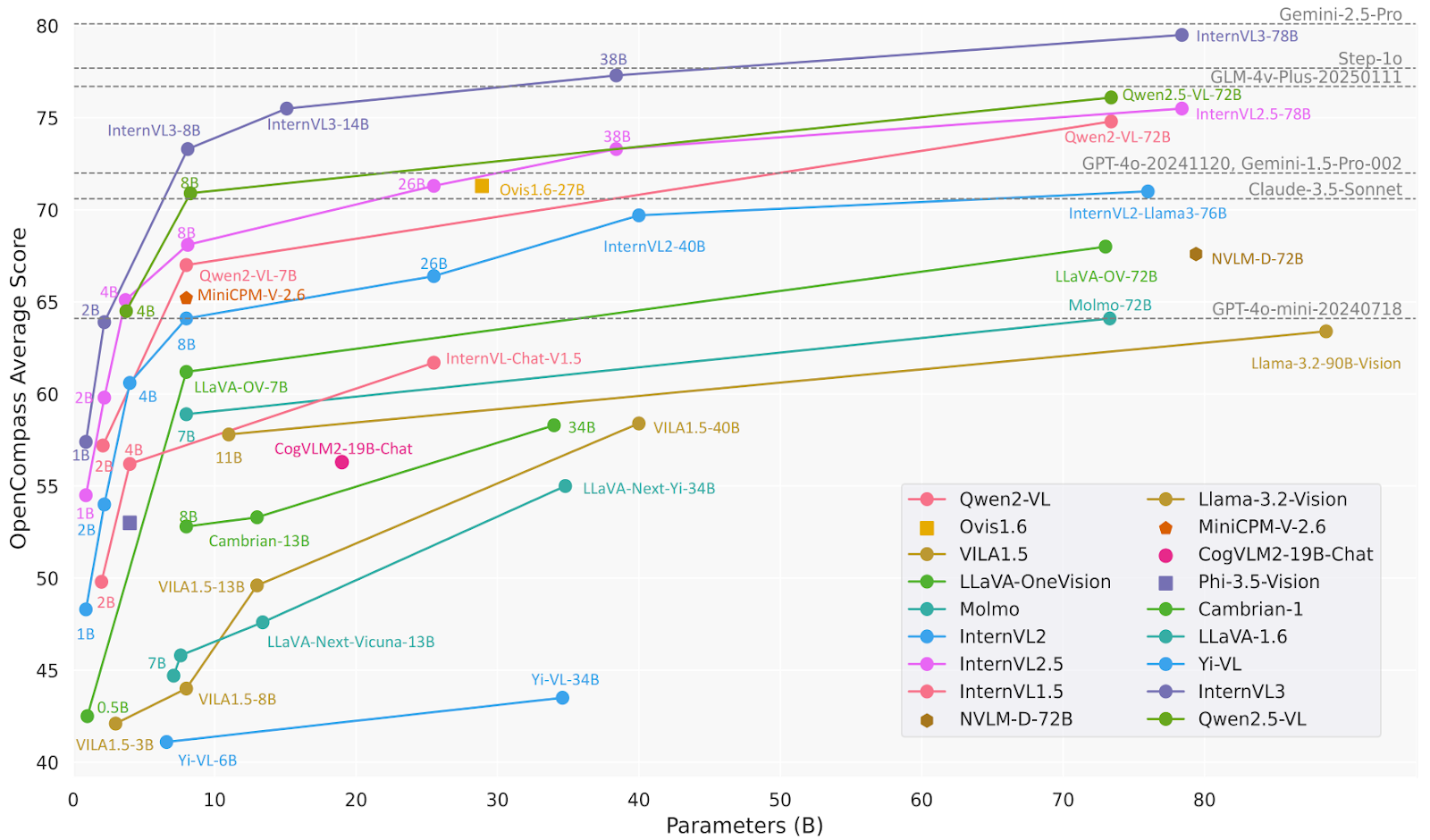
Fonte: OpenGVLab/InternVL3-78B · Hugging Face
Exemplo de uso:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 é uma série de modelos de linguagem multimodais de grande porte (MLLMs) desenvolvidos pela AIDC-AI. Esses modelos foram criados para alinhar incorporações visuais e textuais de forma eficaz. O modelo Ovis2-34B, em particular, usa o aimv2-1B-patch14-448 como seu codificador de visão e o Qwen2.5-32B-Instruct como seu modelo de linguagem, totalizando 34 bilhões de parâmetros. Ele suporta um comprimento máximo de contexto de 32.768 tokens e usa precisão bfloat16 para um processamento eficiente.
O Ovis2-34B mostrou um ótimo desempenho em vários testes de benchmark, conseguindo os seguintes resultados:
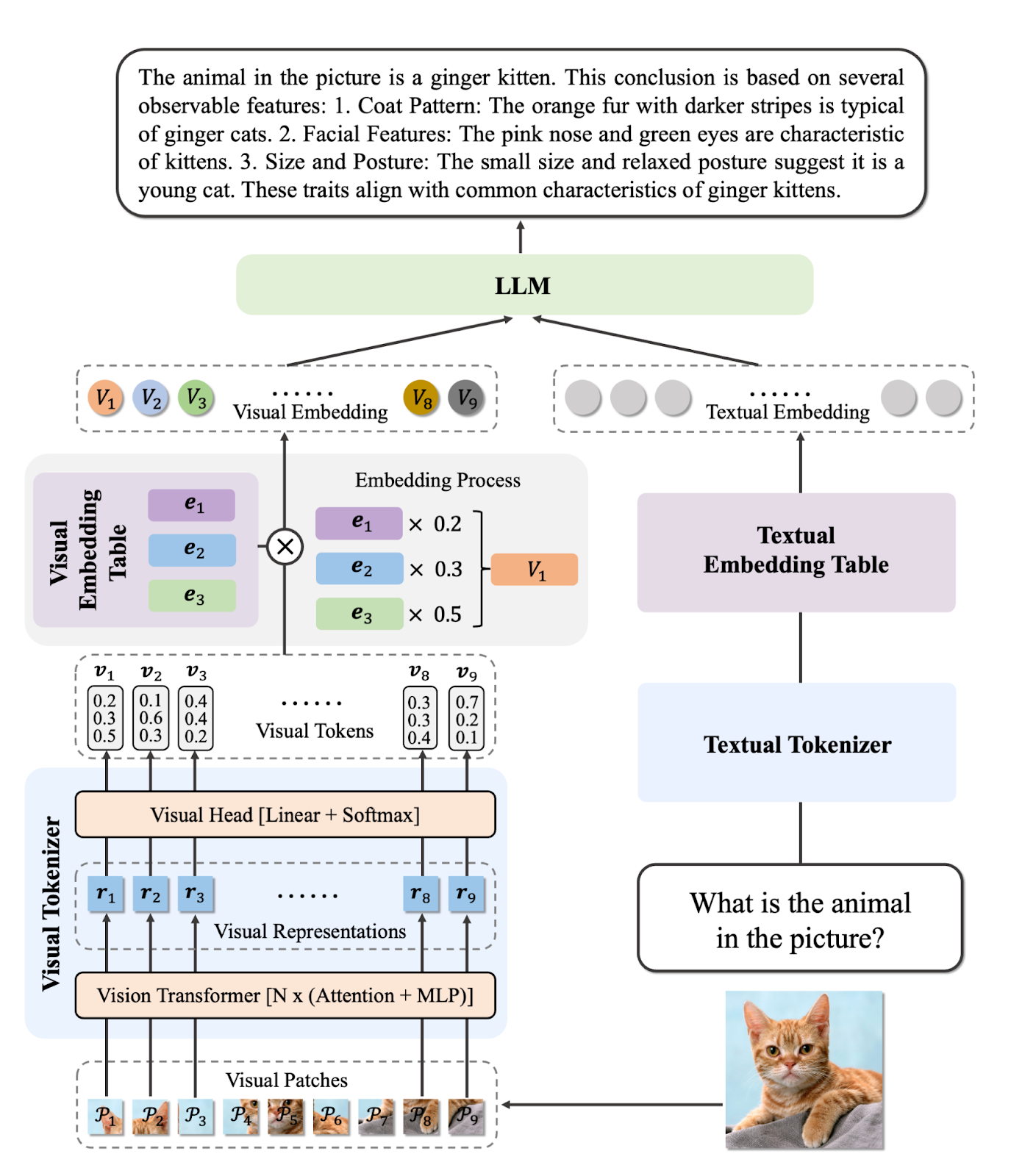
Fonte: AIDC-AI/Ovis2-34B · Hugging Face
Exemplo de uso:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct é um modelo de linguagem multimodal grande (MLLM) da família Qwen, feito pra entender e processar informações visuais e textuais. Muitos modelos MLLM de código aberto são baseados nele, o que mostra que a série de modelos Qwen é super importante para o avanço da pesquisa em IA.
O Qwen2.5-VL-72B-Instruct mostra um desempenho forte em vários benchmarks, incluindo suas capacidades em compreensão de imagens e vídeos, bem como funções de agente. Ele tem uma pontuação de 70,2 no benchmark MMMUval, 74,8 no MathVista_MINI e 70,8 no MMStar.
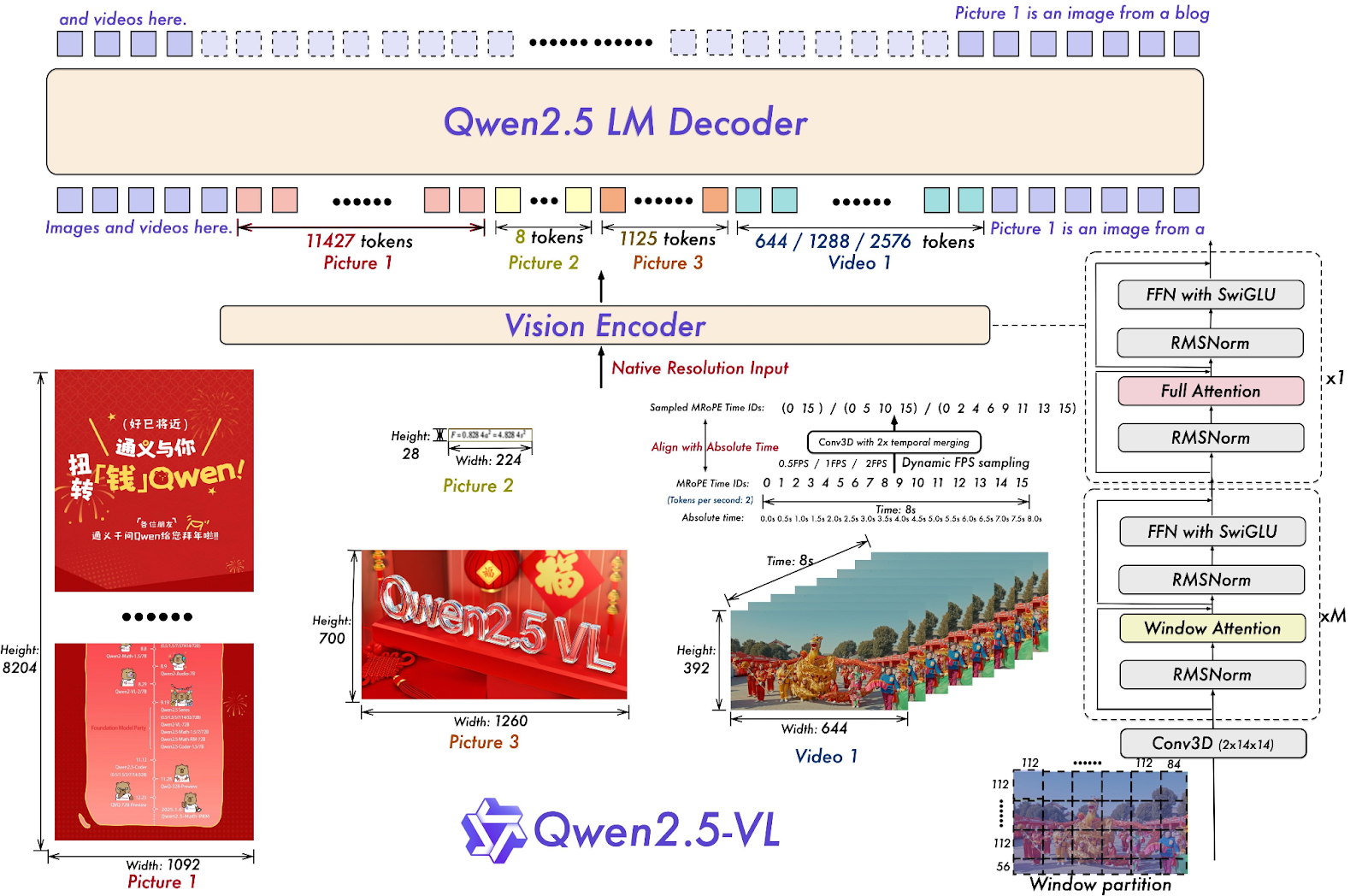
Fonte: Qwen/Qwen2.5-VL-72B-Instruções · Hugging Face
Exemplo de uso:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)O o3 da OpenAI é um novo modelo de raciocínio feito pra oferecer inteligência mais avançada, custos mais baixos e uso mais eficiente de tokens nas aplicações. Representa uma nova geração de modelos que enfatizam capacidades avançadas de raciocínio.
Esse modelo define um novo padrão para tarefas em matemática, ciências, programação e raciocínio visual. Em termos de vários benchmarks de visão, ele supera tanto o o4-min quanto o o1 e está no mesmo nível do o3 Pro.
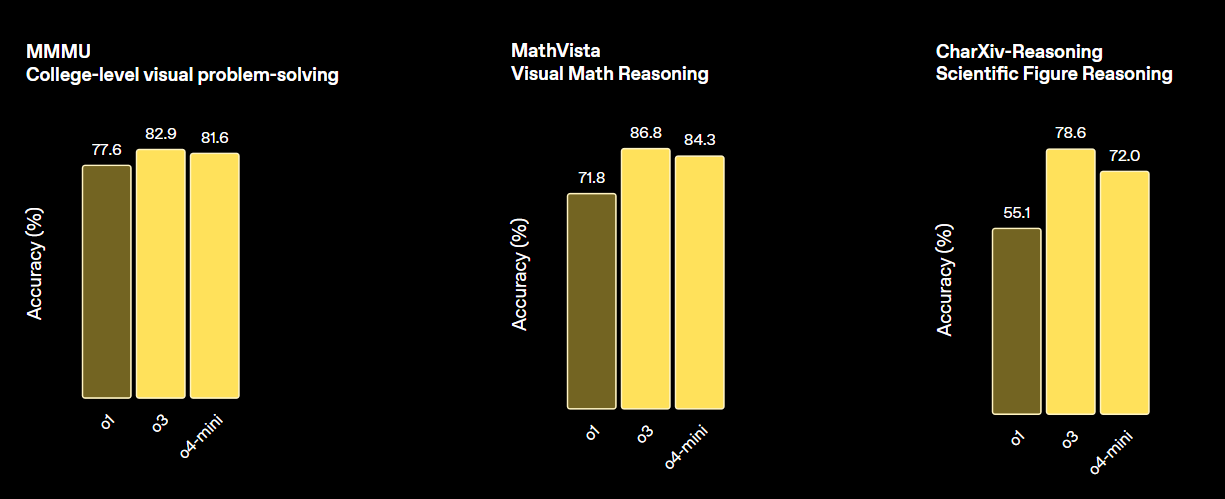
Fonte: Apresentando o OpenAI o3 e o4-mini | OpenAI
Exemplo de uso:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 é uma nova família de modelos sem raciocínio, que inclui o GPT-4.1, o GPT-4.1 Mini e o GPT-4.1 Nano. Esses modelos superaram seus antecessores, o GPT-4o e o GPT-4o Mini, em vários benchmarks.
O GPT-4.1 mantém fortes capacidades visuais, com melhorias na análise de gráficos, diagramas e matemática visual. É ótimo pra tarefas como contar objetos, responder perguntas visuais e vários tipos de reconhecimento óptico de caracteres (OCR).
Fonte: Apresentando o GPT-4.1 na API | OpenAI
Exemplo de uso:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)A Anthropic lançou a próxima geração dos seus modelos Claude: Claude 4 Opus e Claude 4 Soneto. Esses modelos foram criados pra definir novos padrões em codificação, raciocínio avançado e recursos de IA.
Eles vêm com recursos de visão aprimorados que os usuários podem usar para entender imagens e, em seguida, gerar código ou fornecer informações com base nessas imagens. Embora seja basicamente um modelo de codificação, ele também tem recursos multimodais, o que permite entender diferentes tipos de formatos de arquivo.
Se você der uma olhada na tabela comparativa abaixo, vai ver que o Claude 4 é melhor que todos os modelos top, exceto o modelo GPT-3 da OpenAI, principalmente em raciocínio de visualização e resposta a perguntas visuais.
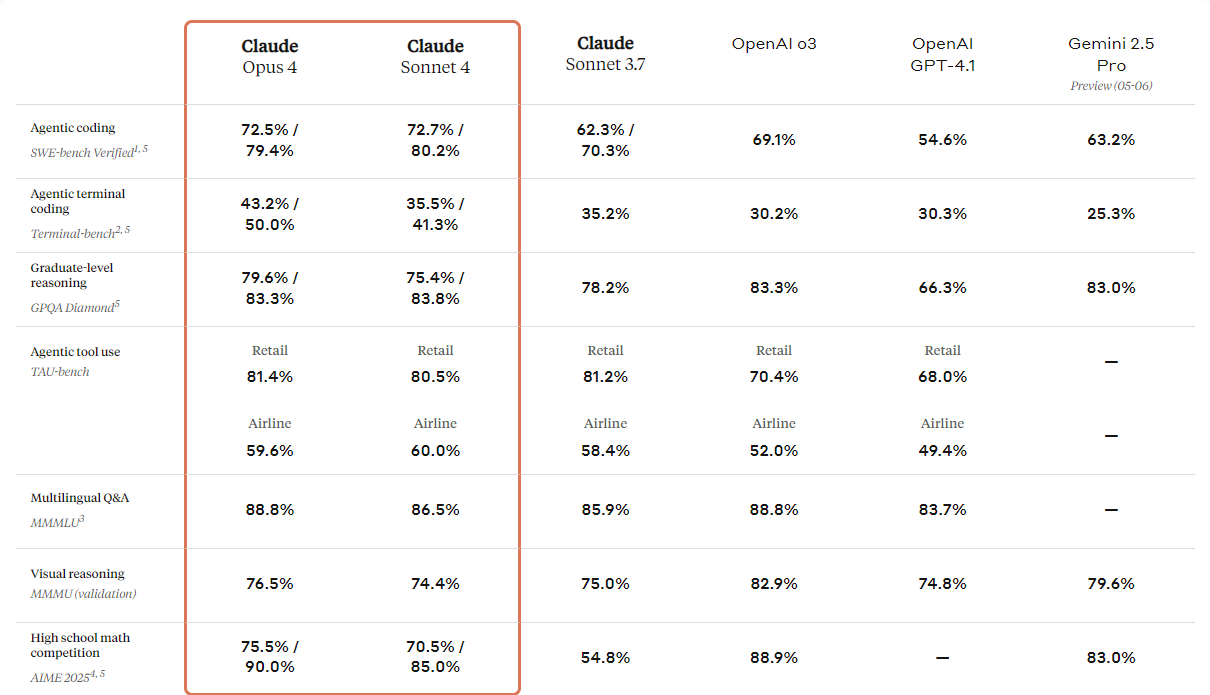
Fonte: Apresentando Claude 4 \ Anthropic
Exemplo de uso:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)O Kimi-VL-A3B-Thinking-2506 é um modelo de código aberto que representa um avanço significativo na IA multimodal. Ele se destaca em benchmarks de raciocínio multimodal, alcançando pontuações impressionantes de precisão: 56,9 no MathVision, 80,1 no MathVista, 46,3 no MMMU-Pro e 64,0 no MMMU, enquanto reduziu seu “tempo de reflexão” em uma média de 20%.
Além de suas capacidades de raciocínio, a versão 2506 mostra uma percepção visual geral e compreensão melhoradas. Ele iguala ou até supera o desempenho de modelos não inteligentes em benchmarks como MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0) e MMVet (78,4).
Fonte: MoonshotAI/Kimi-VL: Kimi-VL
Exemplo de uso:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 é uma família de modelos de IA multimodal desenvolvida pelo Google, capaz de processar entradas de texto e imagem para produzir saídas de texto. Esses modelos estão disponíveis em vários tamanhos: 1B, 4B, 12B e 27B, atendendo a diferentes requisitos de hardware e desempenho.
A maior variante, Gemma 3 27B, mostrou um desempenho incrível nas avaliações de preferência humana, até superando modelos maiores, como Llama 3-405B e DeepSeek-V3.
Os modelos mostram um desempenho incrível em vários testes de benchmark. Eles são ótimos em tarefas multimodais, tirando notas incríveis em benchmarks como COCOcap (116), DocVQA (85,6), MMMU (56,1) e VQAv2 (72,9).
Fonte: Abrir a tabela de classificação do VLM
Exemplo de uso:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)O Llama 3.2 90B Vision Instruct é um modelo de linguagem grande multimodal avançado desenvolvido pela Meta. Ele foi feito pra tarefas que envolvem reconhecimento visual, raciocínio de imagens e legendas.
O Llama 3.2 90B Vision Instruct foi feito com base na versão só de texto do Llama 3.1 e tem um adaptador de visão treinado separadamente, que permite processar imagens e texto como entradas, gerando saídas de texto precisas.
Treinado em grande escala, o modelo Llama 3.2 90B Vision precisou de 8,85 milhões de horas de GPU. Ele mostra um desempenho incrível em benchmarks como VQAv2 (73,6), Text VQA (73,5) e DocVQA (70,7).
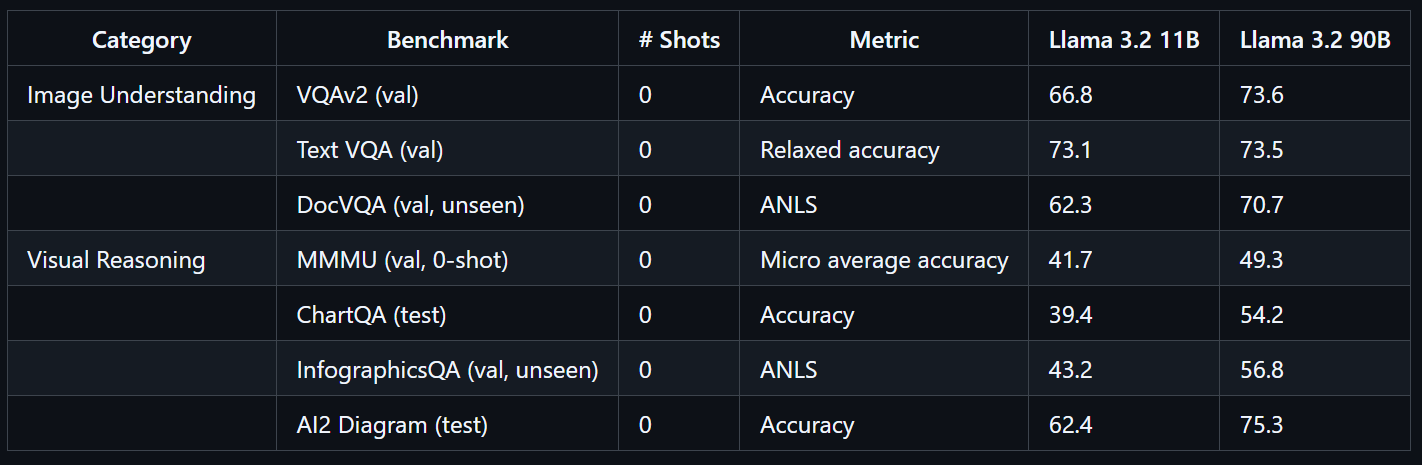
Fonte: llama-models
Exemplo de uso:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Os modelos de linguagem visual estão mudando de verdade a forma como a gente interage com informações visuais e textuais, oferecendo uma precisão e flexibilidade incríveis em vários setores. Esses modelos combinam perfeitamente visão computacional e processamento de linguagem natural, possibilitando novas aplicações, desde detecção avançada de objetos até assistentes visuais intuitivos.
Se privacidade e segurança são prioridades para o seu caso de uso, recomendo muito explorar modelos de linguagem de visão de código aberto. Executar esses modelos localmente te dá controle total sobre seus dados, o que os torna ideais para ambientes sensíveis. Os VLMs de código aberto também são super adaptáveis; a maioria pode ser ajustada com apenas algumas centenas de amostras para conseguir resultados excelentes, feitos sob medida para suas necessidades específicas.
Já os modelos proprietários oferecem acesso confiável e econômico a recursos de última geração. Eles costumam ser super precisos e podem ser integrados ao seu fluxo de trabalho com só algumas linhas de código, o que os torna acessíveis até mesmo para equipes sem muito conhecimento em IA.
Se você quer saber mais sobre modelos de linguagem visual, não deixe de conferir estes recursos:
Cursos mais populares do DataCamp
Programa
Curso
Curso
blog
Bhavishya Pandit
8 min
blog
Abid Ali Awan
8 min
blog
Abid Ali Awan
13 min
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
8 min


