
Program
Pemrosesan Bahasa Alami dalam Python
20 Hr
Vision Language Models (VLM) dengan cepat mentransformasi industri dengan memampukan sistem AI memahami dan menalar baik gambar maupun teks. Berbeda dari model visi komputer tradisional, VLM modern dapat menafsirkan gambar kompleks, menjawab pertanyaan terperinci tentang konten visual, dan bahkan memproses video serta dokumen dengan teks tersemat.
Fitur ini menjadikannya sangat berharga untuk diagnostik medis, kontrol kualitas otomatis, dan aplikasi sensitif di mana ketepatan lebih penting daripada kecepatan.
Dalam blog ini, kami akan mengulas model vision-language teratas tahun 2026, mencakup opsi open-source dan proprietari. Kami akan menyoroti kemampuan uniknya lalu menyajikan performa dan hasil benchmark. Bagi pengembang dan peneliti, kami juga menyertakan cuplikan kode contoh agar Anda bisa segera mencoba model-model ini sendiri.
Jika Anda ingin mempelajari lebih lanjut dasar-dasar model ini, pastikan untuk melihat Image Processing in Python skill track kami.
Gemini 2.5 Pro adalah model AI paling canggih dari Google, saat ini memimpin papan peringkat LMArena dan WebDevArena untuk tugas visi dan pengodean. Model ini dirancang untuk penalaran dan pemahaman kompleks lintas teks, gambar, audio, dan video.
Dalam hal kemampuan vision-language, model ini menempati peringkat teratas pada Open LLM leaderboard. Gemini 2.5 Pro dapat menafsirkan gambar dan video, menghasilkan deskripsi yang terperinci dan kontekstual sambil menjawab pertanyaan terkait konten visual.
Sumber: Google Gemini
Anda dapat mengakses Gemini 2.5 Pro secara gratis melalui aplikasi web Gemini di gemini.google.com/app atau dengan menggunakan Google AI Studio.
Bagi pengembang, Gemini 2.5 Pro juga tersedia melalui Gemini API, Vertex AI, dan SDK Python resmi, sehingga mudah untuk mengintegrasikan fitur vision-language ke dalam aplikasi atau alur kerja Anda sendiri.
Contoh penggunaan:
from google.genai import types
with open('path/to/image.jpg', 'rb') as f:
image_bytes = f.read()
response = client.models.generate_content(
model='gemini-2.5-pro',
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
'Explain the image.'
]
)
print(response.text)InternVL3 adalah rangkaian model bahasa besar multimodal (MLLM) canggih yang melampaui pendahulunya, InternVL 2.5. Model ini unggul dalam persepsi dan penalaran multimodal serta memiliki kemampuan yang ditingkatkan, termasuk penggunaan alat, agen GUI, analisis gambar industri, dan persepsi visi 3D.
Secara khusus, model InternVL3-78B menggunakan InternViT-6B-448px-V2_5 untuk komponen visi dan Qwen2.5-72B untuk komponen bahasa. Dengan total 78,41 miliar parameter, InternVL3-78B meraih skor 72,2 pada benchmark MMMU, menetapkan rekor state-of-the-art baru di antara MLLM open-source. Kinerjanya kompetitif dengan model proprietari terdepan.
Sumber: OpenGVLab/InternVL3-78B · Hugging Face
Contoh penggunaan:
# pip install lmdeploy>=0.7.3
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-78B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('Explain the image.', image))
print(response.text)Ovis2 adalah rangkaian model bahasa besar multimodal (MLLM) yang dikembangkan oleh AIDC-AI. Model-model ini dirancang untuk menyelaraskan embedding visual dan tekstual secara efektif. Khususnya, model Ovis2-34B memanfaatkan aimv2-1B-patch14-448 sebagai vision encoder dan Qwen2.5-32B-Instruct sebagai model bahasa, dengan total 34 miliar parameter. Model ini mendukung panjang konteks maksimum 32.768 token dan menggunakan presisi bfloat16 untuk pemrosesan yang efisien.
Ovis2-34B menunjukkan performa kuat pada berbagai uji benchmark, dengan pencapaian sebagai berikut:
Sumber: AIDC-AI/Ovis2-34B · Hugging Face
Contoh penggunaan:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-34B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')Qwen2.5-VL-72B-Instruct adalah model bahasa besar multimodal (MLLM) dari keluarga Qwen, dirancang untuk memahami dan memproses informasi visual dan tekstual. Banyak model MLLM open-source berbasis pada model ini, menunjukkan bahwa seri Qwen berperan penting dalam memajukan riset AI.
Qwen2.5-VL-72B-Instruct menunjukkan performa kuat di berbagai benchmark, termasuk kemampuan pemahaman gambar dan video serta fungsi agen. Model ini mencatat skor 70,2 pada benchmark MMMUval, 74,8 pada MathVista_MINI, dan 70,8 pada MMStar.
Sumber: Qwen/Qwen2.5-VL-72B-Instruct · Hugging Face
Contoh penggunaan:
# pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-72B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-72B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)o3 dari OpenAI adalah model penalaran baru yang dirancang untuk memberikan kecerdasan lebih tinggi, biaya lebih rendah, dan penggunaan token yang lebih efisien dalam aplikasi. Ini merepresentasikan generasi model baru yang menekankan kemampuan penalaran tingkat lanjut.
Model ini menetapkan standar baru untuk tugas di bidang matematika, sains, pengodean, dan penalaran visual. Dalam berbagai benchmark visi, model ini melampaui o4-min dan o1, serta setara dengan o3 Pro.
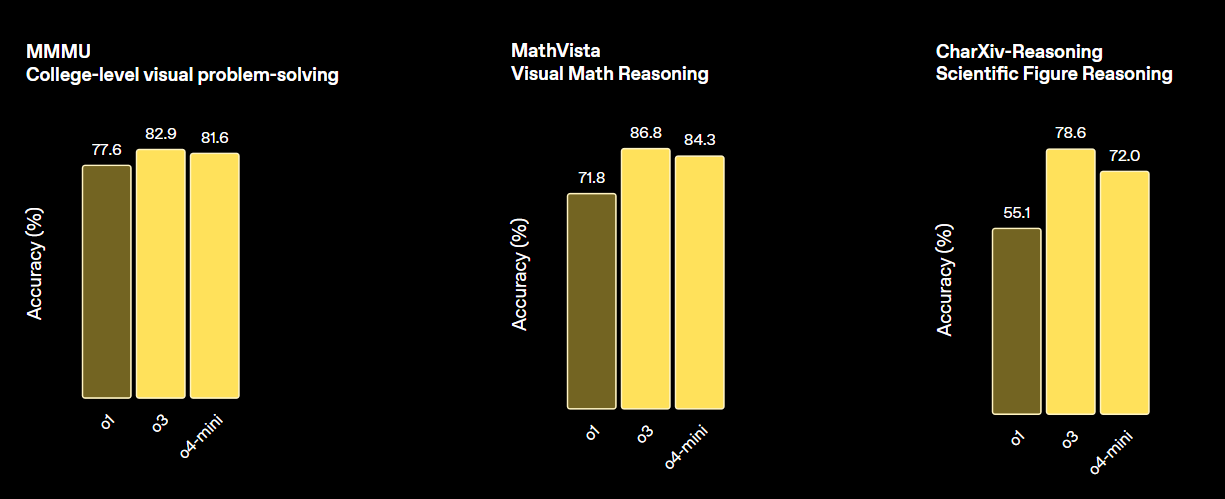
Sumber: Introducing OpenAI o3 and o4-mini | OpenAI
Contoh penggunaan:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3-2025-04-16",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)GPT-4.1 adalah keluarga baru model non-reasoning, yang mencakup GPT-4.1, GPT-4.1 Mini, dan GPT-4.1 Nano. Model-model ini melampaui pendahulunya, GPT-4o dan GPT-4o Mini, pada berbagai benchmark.
GPT-4.1 tetap memiliki kemampuan visi yang kuat, dengan peningkatan dalam menganalisis bagan, diagram, dan matematika visual. Model ini unggul dalam tugas seperti menghitung objek, visual question answering, dan berbagai bentuk optical character recognition (OCR).
Sumber: Introducing GPT-4.1 in the API | OpenAI
Contoh penggunaan:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-2025-04-14",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}],
)
print(response.output_text)Anthropic memperkenalkan generasi berikutnya dari model Claude: Claude 4 Opus dan Claude 4 Sonnet. Model-model ini dirancang untuk menetapkan standar baru dalam pengodean, penalaran lanjutan, dan kapabilitas AI.
Model ini hadir dengan kemampuan visi yang ditingkatkan yang dapat digunakan pengguna untuk memahami gambar lalu menghasilkan kode atau memberikan informasi berdasarkan gambar tersebut. Meskipun pada dasarnya merupakan model pengodean, model ini juga memiliki kemampuan multimodal, memungkinkannya memahami berbagai jenis format file.
Jika Anda merujuk ke tabel perbandingan di bawah, Anda akan melihat bahwa Claude 4 melampaui semua model teratas, kecuali model GPT-3 milik OpenAI, khususnya dalam penalaran visualisasi dan visual question answering.
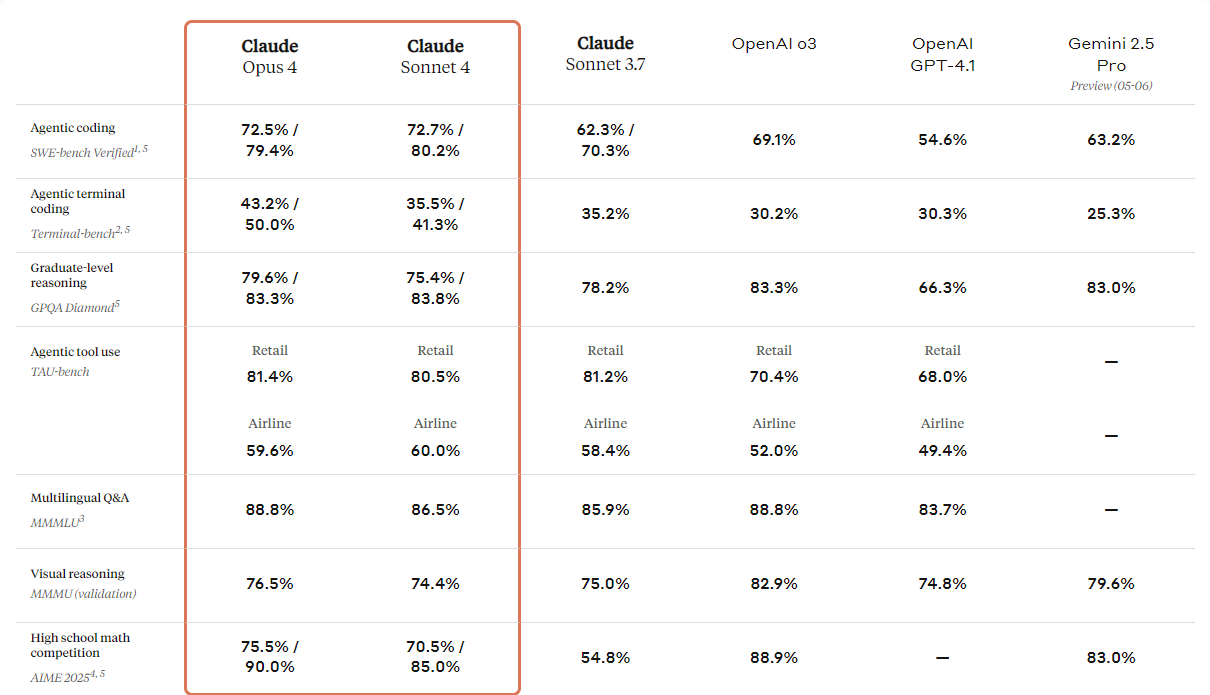
Sumber: Introducing Claude 4 \ Anthropic
Contoh penggunaan:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
},
},
{
"type": "text",
"text": "Describe this image."
}
],
}
],
)
print(message)Kimi-VL-A3B-Thinking-2506 adalah model open-source yang menandai kemajuan signifikan dalam AI multimodal. Model ini unggul pada benchmark penalaran multimodal, meraih akurasi mengesankan: 56,9 pada MathVision, 80,1 pada MathVista, 46,3 pada MMMU-Pro, dan 64,0 pada MMMU, sambil mengurangi "panjang pemikiran" rata-rata sebesar 20%.
Selain kemampuan penalarannya, versi 2506 menunjukkan peningkatan persepsi dan pemahaman visual umum. Model ini menyamai atau bahkan melampaui performa model non-thinking pada benchmark seperti MMBench-EN-v1.1 (84,4), MMStar (70,4), RealWorldQA (70,0), dan MMVet (78,4).
Sumber: MoonshotAI/Kimi-VL: Kimi-VL
Contoh penggunaan:
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
import requests
from PIL import Image
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))Gemma 3 adalah keluarga model AI multimodal yang dikembangkan oleh Google, mampu memproses masukan teks dan gambar untuk menghasilkan keluaran teks. Model ini tersedia dalam berbagai ukuran: 1B, 4B, 12B, dan 27B, untuk memenuhi kebutuhan perangkat keras dan performa yang berbeda.
Varian terbesar, Gemma 3 27B, menunjukkan performa mengesankan dalam evaluasi preferensi manusia, bahkan melampaui model yang lebih besar seperti Llama 3-405B dan DeepSeek-V3.
Model-model ini menunjukkan kemampuan kuat di berbagai benchmark. Secara khusus, model-model ini unggul dalam tugas multimodal, meraih skor menonjol pada benchmark seperti COCOcap (116), DocVQA (85,6), MMMU (56,1), dan VQAv2 (72,9).
Sumber: Open VLM Leaderboard
Contoh penggunaan:
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-27b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)Model Llama 3.2 90B Vision Instruct adalah model bahasa besar multimodal canggih yang dikembangkan oleh Meta. Model ini dirancang untuk tugas pengenalan visual, penalaran gambar, dan pembuatan caption.
Llama 3.2 90B Vision Instruct dibangun di atas Llama 3.1 versi teks saja dan menggabungkan adaptor visi yang dilatih secara terpisah, yang memungkinkannya memproses gambar dan teks sebagai masukan, lalu menghasilkan keluaran teks yang presisi.
Dilatih dalam skala masif, model Llama 3.2 90B Vision membutuhkan 8,85 juta jam GPU. Model ini menunjukkan performa luar biasa pada benchmark seperti VQAv2 (73,6), Text VQA (73,5), dan DocVQA (70,7).
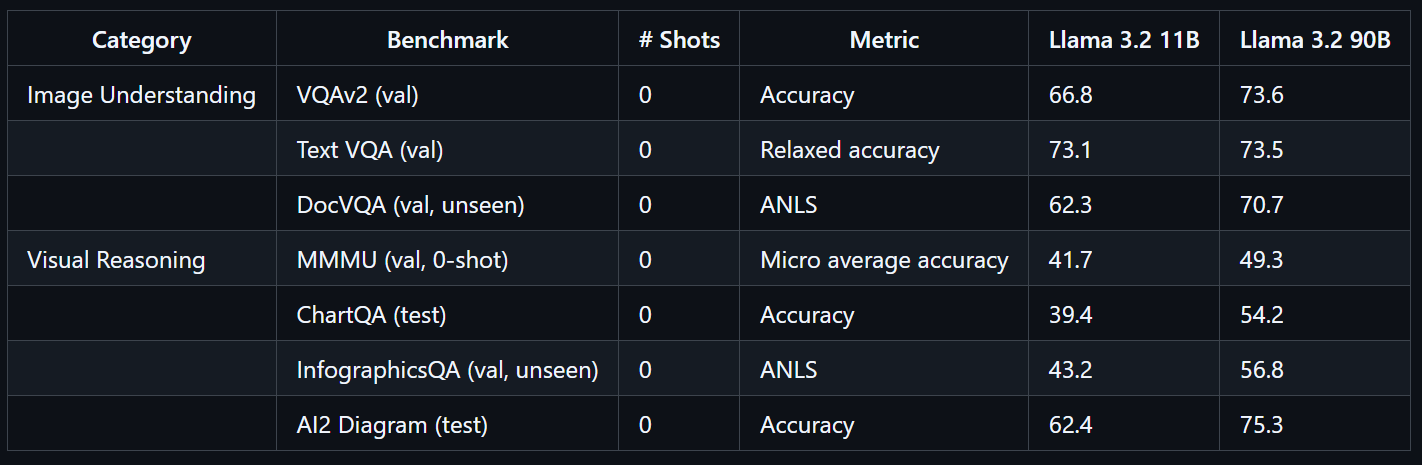
Sumber: llama-models
Contoh penggunaan:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to(model.device)
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))Penalaran visual dengan grafik juga menjadi keunggulan model terbaru Meta, Muse Spark.
Model vision-language secara fundamental mengubah cara kita berinteraksi dengan informasi visual dan tekstual, menghadirkan akurasi dan fleksibilitas luar biasa di berbagai industri. Model-model ini memadukan visi komputer dan pemrosesan bahasa alami secara mulus, memampukan aplikasi baru mulai dari deteksi objek tingkat lanjut hingga asisten visual yang intuitif.
Jika privasi dan keamanan menjadi prioritas utama dalam kasus penggunaan Anda, sangat disarankan untuk mengeksplorasi model vision-language open-source. Menjalankan model ini secara lokal memberi Anda kendali penuh atas data, sehingga ideal untuk lingkungan sensitif. VLM open-source juga sangat adaptif; sebagian besar dapat di-fine-tune hanya dengan beberapa ratus sampel untuk mencapai hasil sangat baik yang disesuaikan dengan kebutuhan spesifik Anda.
Di sisi lain, model proprietari menyediakan akses andal dan hemat biaya ke kapabilitas mutakhir. Model ini cenderung sangat akurat dan dapat diintegrasikan ke alur kerja Anda hanya dengan beberapa baris kode, sehingga dapat diakses bahkan oleh tim tanpa keahlian AI mendalam.
Jika Anda ingin mempelajari lebih lanjut tentang vision language models, pastikan untuk melihat sumber berikut:
Kursus Teratas di DataCamp
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
