
Kurs
MLOps Dağıtımı ve Yaşam Döngüsü
4 sa
12.3K
Doğal evrimden ilham alan GA’lar, çözüm uzayını verimli bir şekilde keşfederek, birçok hareketli parçaya sahip karmaşık problemler için bile optimal ya da optimale yakın çözümleri bulur. Doğal seçilim sürecini taklit ederek GA’lar, zaman içinde çözümleri evrimleştirir ve performanslarını yinelemeli olarak iyileştirir.
Genetik algoritmalar, doğal seçilim ve genetik süreçlerinden esinlenmiştir. Canlı organizmaların nesiller boyunca çevrelerine uyum sağlamak için nasıl evrimleştiğini taklit ederler. GA’ların arkasındaki temel biyolojik ilkeleri anlamak, bu algoritmaların nasıl çalıştığını kavramamıza ve onları daha stratejik kullanmamıza yardımcı olur.
Doğal seçilim, elverişli özelliklerin daha iyi kombinasyonlarına sahip bireylerin hayatta kalma ve üreme olasılığının daha yüksek olmasına neden olan süreçtir. Zamanla bu avantajlı özellikler popülasyonda daha yaygın hale gelir.
GA bağlamında bu kavram, üreme için daha yüksek uygunluk (fitness) puanına sahip bireylerin seçilmesiyle yansıtılır. Böylece elverişli özelliklerini, yani “genlerini”, bir sonraki nesle aktarırlar.
Bir biyolojik organizmanın özellikleri genleri tarafından kodlanır. Genler, kromozomlara düzenlenmiş DNA’nın bir parçasıdır.
GA’lar aynı kavram ve terminolojinin çoğunu ödünç alır. Bir probleme yönelik olası çözümler genellikle dizgiler veya diziler olarak kodlanan “kromozomlar” şeklinde gösterilir. Kromozomdaki her bir öğe, çözümün belirli bir özelliğini belirleyen bir gene karşılık gelir.
Çaprazlama ya da rekombinasyon, iki ebeveyn kromozomunun genetik materyalinin bölümlerini birleştirerek her bir ebeveynden parçalar içeren yeni bir kromozom oluşturan genetik bir işlemdir. Bu yeni kromozom karışımı çocuğa aktarılır. Bu yüzden annenizin göz rengini, babanızın saç rengini alabilirsiniz.
GA’larda çaprazlama, yeni bireyler oluşturmak için ebeveyn kromozomlarının segmentlerini değiştirmeyi içerir. Bu işlem, değişkenlik katar ve yavruların her iki ebeveynden de yararlı özellikler miras almasını sağlar.
Mutasyon, bir organizmanın genlerinde rastgele değişiklikler oluşturarak yeni özelliklere yol açabilir.
Genetik algoritmalarda mutasyon, bir kromozomdaki bir veya daha fazla genin rastgele değiştirilmesini içerir. Bu, popülasyon içinde genetik çeşitliliği korumaya yardımcı olur ve algoritmanın çözüm uzayının yeni bölgelerini keşfetmesini sağlar.
Doğada bir bireyin uygunluğu, hayatta kalma ve üreme yeteneğiyle belirlenir. Üremeden önce ölürseniz uygunluğunuz sıfırdır. 12 torununuz varsa uygunluğunuz 2 torunu olan birinden daha yüksektir.
GA’larda uygunluk benzer olsa da biraz farklıdır. Bir uygunluk fonksiyonu, bir çözümün eldeki problemi ne kadar iyi çözdüğünü değerlendirir. Daha yüksek uygunluk puanlarına sahip çözümlerin üreme için seçilme olasılığı daha yüksektir; bu da daha iyi çözümlerin nesiller boyunca yayılmasını sağlar.
Genetik algoritmalar evrimden ilham almıştır. Bu nedenle bir GA’nın bileşenleri, biyolojik karşılıklarıyla benzer ad ve işlevlere sahiptir. Bu bileşenlerin her biri genellikle kendi fonksiyonu olarak kodlanır.
Bir genetik algoritmadaki popülasyon, genellikle bireyler olarak adlandırılan aday çözümler kümesidir. Her birey bir kromozom olarak temsil edilir ve ikili dizgiler, diziler veya diğer veri yapıları olarak kodlanabilir.
Örneğin, her bir kromozom, optimize etmemiz gereken bir fonksiyona ait bir dizi girdi değerini temsil edebilir. Ya da her bir kromozom, dağıtım sürücüleri için bir kamyon rotasını temsil edebilir.
Uygunluk fonksiyonu, ilgilendiğimiz problemi çözme konusundaki her bireyin yeteneğini değerlendirir. Daha iyi çözümler için daha yüksek değerler atar. Uygunluk fonksiyonu, algoritmayı daha iyi çözümlere doğru yönlendirir.
Örneğin, matematiksel fonksiyon optimizasyonu örneğimizde uygunluk fonksiyonu, verilen girdiler için fonksiyonun değerini döndürebilir. Kamyon rotaları örneğimizde ise uygunluk fonksiyonu teslimatı tamamlama hızını döndürebilir.
Seçim fonksiyonu, uygunluklarına dayanarak popülasyondan üremek üzere bireyleri seçer. Uygunluğu daha yüksek bireylerin üreme için seçilme olasılığı daha fazladır. Bu, en iyi uyum sağlayan bireylerin hayatta kalma ve üreme olasılığının daha yüksek olduğu doğal seçilimi taklit eder.
Birkaç farklı seçim yöntemi vardır. Yaygın yöntemler arasında rulet tekeri seçimi, turnuva seçimi ve sıralama tabanlı seçim bulunur.
Rulet tekeri seçiminde bireyler, uygunluklarıyla orantılı bir olasılığa göre seçilir; rulet tekerinin çevrilmesine benzer.
Turnuva seçiminde, rastgele bir alt küme seçilir ve bu alt kümedeki en uygun birey seçilir.
Sıralama tabanlı seçimde, bireyler uygunluklarına göre sıralanır. Seçim olasılıkları, ham uygunluk değerleri yerine bu sıralamalara göre atanır.
Her yöntemin kendi avantajları vardır ve hangisinin seçileceği, eldeki problemin özel gereksinimlerine göre belirlenmelidir.
Çaprazlama, iki bireyden bilgi alarak yavrular oluşturur. Amaç, her iki ebeveynden de yararlı özellikleri miras almaktır. Yaygın çaprazlama teknikleri arasında tek noktalı çaprazlama, çok noktalı çaprazlama, uniform (düzgün) çaprazlama ve harman (blend) çaprazlama yer alır.
Tek noktalı çaprazlama, rastgele bir nokta seçilmesini ve bu noktada iki ebeveynden genetik materyalin değiştirilerek iki yavru oluşturulmasını içerir. Çok noktalı çaprazlama, ebeveynler arasında segmentlerin değişimi için birden fazla nokta kullanarak daha karmaşık genetik kombinasyonlara olanak tanır.
Uniform çaprazlama, her gen için hangi ebeveynin katkı sağlayacağına rastgele karar vererek yüksek düzeyde genetik çeşitlilik sağlar. Harman çaprazlama ise, rastgele bir harmanlama faktörü kullanarak ebeveynlerin genlerini harmanlayıp yavrular üretir. Hangi tekniğin kullanılacağına ilişkin karar, problemin karmaşıklığına ve yavrularda istenen çeşitlilik düzeyine bağlı olmalıdır.
Mutasyon, yavrunun genetik materyalinde rastgele değişiklikler yapar. Bu, popülasyondaki çeşitliliği korur ve çözüm uzayının yeni bölgelerinin keşfini sağlar. Mutasyonlar, ikili bir dizgide bir biti çevirmek kadar basit olabileceği gibi, kodlama şemasına bağlı olarak daha karmaşık değişiklikler de içerebilir.
Bir genetik algoritma, optimal çözümleri bulmak için doğal evrimsel süreçleri taklit eden bir dizi adımdan geçer. Bu adımlar, popülasyonun nesiller boyunca evrimleşmesini ve çözümlerin kalitesinin artmasını sağlar. Bir genetik algoritmanın genel işleyişi şöyledir:
Önce rasgele bireylerden oluşan bir başlangıç popülasyonu üretiriz. Bu adım, algoritmaya başlamak için çeşitli olası çözümler kümesi oluşturur.
Sonra popülasyondaki her bireyin uygunluğunu hesaplamamız gerekir. Burada her çözümün ne kadar iyi olduğunu değerlendirmek için uygunluk fonksiyonunu kullanırız.
Seçim ölçütlerini kullanarak bireyleri uygunluklarına göre üreme için seçeriz. Bu adım, hangi bireylerin ebeveyn olacağını belirler.
Sırada çaprazlama var. Seçilen ebeveynlerin genetik materyalini birleştirerek, çaprazlama tekniklerini uygulayıp yeni çözümler veya yavrular üretiriz.
Popülasyonumuzdaki çeşitliliği korumak için yavrularda rastgele mutasyonlar uygularız.
Ardından, hangi bireylerin bir sonraki nesle geçeceğine karar vererek eski popülasyonun bir kısmını veya tamamını yeni yavrularla değiştiririz.
Önceki 2-6 adımları, belirli sayıda nesil boyunca veya bir sonlandırma koşulu sağlanana kadar döngü halinde tekrarlanır. Bu döngü, popülasyonun zaman içinde evrimleşmesini sağlar ve umarız iyi bir çözüme ulaşır.
Artık genetik algoritmaların ne olduğunu ve genel olarak nasıl çalıştığını anladığımıza göre, basit bir optimizasyon problemini çözmek için kendi genetik algoritmamızı oluşturalım.
Grafiğe döküldüğünde y=ax2+bx+c denklemi bir parabol oluşturur. a, b ve c değerlerinin, en düz parabolü oluşturacak kombinasyonunu bulmak için bir genetik algoritma kullanacağız. İşte elde edeceğimiz sonucun bir ön izlemesi:
Fonksiyonumuzun başında gerekli kütüphaneleri içe aktaracağız. Başlangıç popülasyonumuz için rastgele değerler üretmek üzere ‘random’ kullanacağız. Numpy bence matematikle uğraşırken genel olarak faydalıdır.
Ayrıca, kodunuzun düşündüğünüz şeyi yaptığından emin olmak için her zaman grafikler çizmeniz gerektiğine inanırım. Bu yüzden grafik oluşturmak için ‘matplotlib.pyplot’ içe aktaracağız.
Ayrıca, simülasyon sırasında neler olduğunu daha iyi anlamak için (nispeten az sayıda nesil varsayarak) her nesilden önemli sonuçları yazdırmayı severim. Bunun için de ‘PrettyTable’ içe aktaracağız.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTableSırada, her bir çözümün uygunluğunu değerlendirecek uygunluk fonksiyonunu tanımlamamız gerekiyor. Bu durumda, grafikte en düz U-şeklini bulmak istiyoruz. Bu yüzden tepe noktasındaki y değerini ve x=-1 ile x=1 noktalarındaki değerleri hesapladım.
Ardından grafiğin eğriliğini, bu üç noktadaki y değerleri arasındaki fark olarak hesapladım. En düz eğriyi elde etmek istediğimiz için, uygunluk fonksiyonunu tamamlarken eğriliği negatifledim.
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curvinessRastgele çözümlerden oluşan bir popülasyon üretmek için ‘random’ kütüphanesini kullanacağız. Bu popülasyondaki her bir birey, a, b ve c için birer değer kümesidir.
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return populationSeçim fonksiyonu, bir sonraki popülasyonu oluşturmak için hangi bireylerin üreyeceğini belirleyecektir. Bu örnekte, popülasyondan rastgele bir alt kümenin alındığı ve bu alt küme içindeki en yüksek uygunluğa sahip bireylerin üreme için seçildiği bir turnuva seçimi süreci kullanacağız.
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selectedArdından, mevcut çözümlerden yararlanarak çaprazlama ile yeni çözümler oluşturmak için kısa bir fonksiyon yazacağız.
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2Sonraki nesillere rastgelelik katmak için bir mutasyon fonksiyonuna da ihtiyacımız var. Bu, her nesilde seçilecek yeterli çeşitlilik olmasını sağlamak açısından önemlidir.
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)Sırada, tüm bu parçaları bir araya getirip algoritmamızı çalıştıracak ana döngüyü oluşturmak var. Sonuçları da görselleştirmemiz gerektiğinden, bu bölüme çizim (plot) kodunu ve final tablosunu oluşturmak için gereken kodu da ekleyeceğim.
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)Son olarak, algoritmamız için parametreleri ayarlayıp çalıştırmamız gerekiyor.
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Bu örnekte, algoritmamızın çalışacağı belirli bir nesil sayısı belirledik. Ancak alternatif olarak, hedef bir uygunluk değerine ulaştığımızda programı durduran bir sonlandırma koşulu da kurabilirdik. Bu da şöyle görünebilir:
def termination_condition(fitnesses, target_fitness):
return max(fitnesses) >= target_fitnessİşte tüm kodun bir arada olduğu hal.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curviness
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return population
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selected
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Fonksiyonumuzun nasıl performans gösterdiğini anlamak için çıktılarımızı kullanalım.
Öncelikle, tablomuzdan 20 nesli tamamladığımızı ve uygunluğun her nesilde nispeten daha negatiften daha az negatife doğru arttığını görüyoruz. Harika!
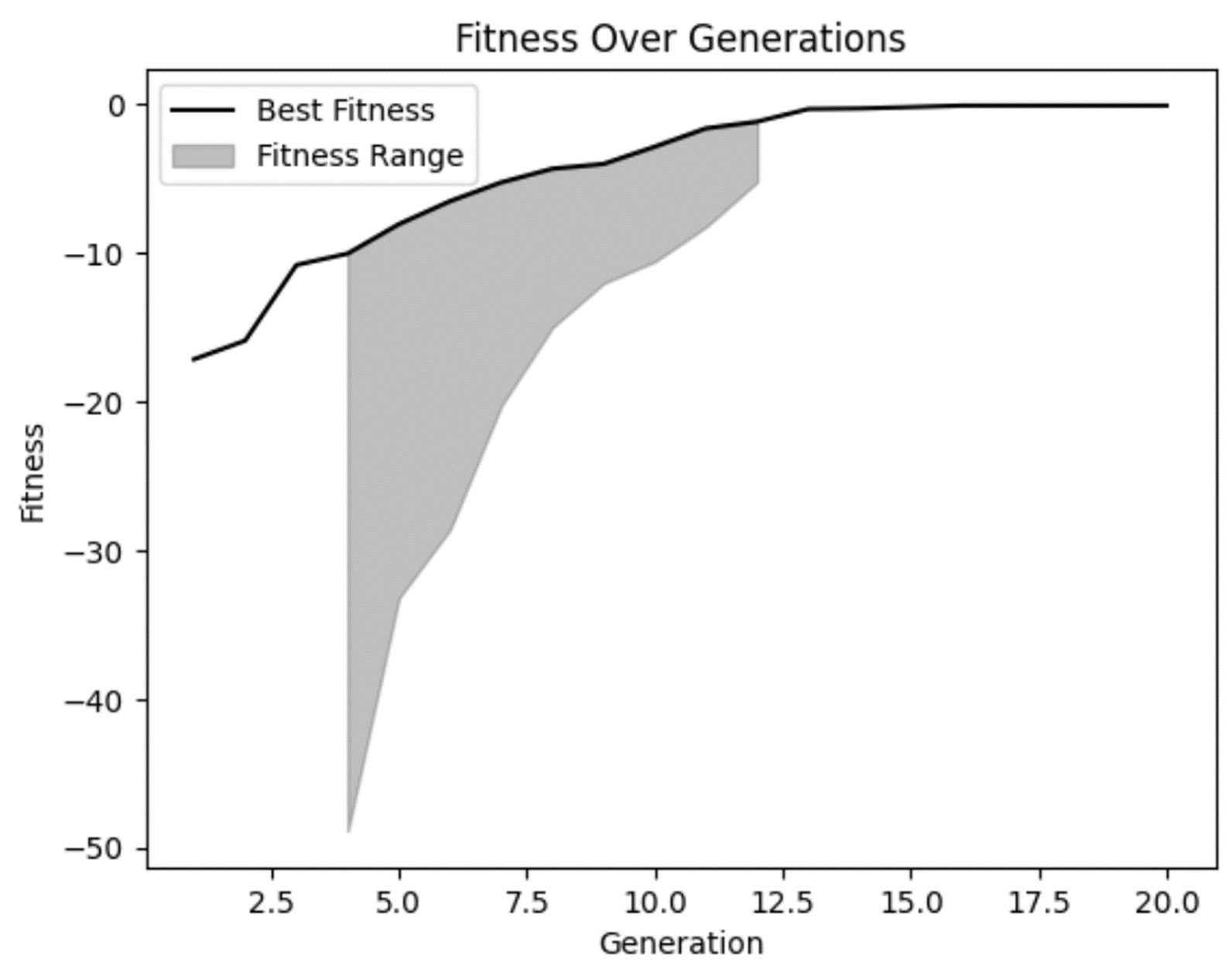
Uygunluk grafiğimizden, uygunluğun zaman içinde iyileştiğini ve sonraki nesillerde biraz yataylaştığını doğrulayabiliyoruz. Ancak erken nesillerin bazılarında modelimizin haklı olarak elediği gerçekten kötü çözümler de olduğunu görüyoruz.
Ayrıca birkaç nesilde uygunluk aralığında çok fazla çeşitlilik olmadığını görüyoruz. Bu her zaman kötü bir şey olmasa da dikkat edilmesi gereken bir durumdur. Bazı durumlarda bu, popülasyonda yeterli çeşitlilik olmadığında ortaya çıkan ve erken yakınsama (premature convergence) olarak adlandırılan bir problemin göstergesi olabilir.
Şimdi de gerçekten düzleşip düzleşmediğini görmek için her nesilden denklemlerimizi çizelim.
Erken nesil çözümlerimizin oldukça eğri olduğunu görüyoruz ki bu mantıklı. Bu denklem U-şeklinde bir grafik üretir. Ancak sonraki nesillerin giderek daha düz hale geldiğini de görüyoruz. Tam da aradığımız buydu!
Şunu da belirtmek gerekir ki açıkça -50 ile 50 arasındaki sınırlar içinde bakıyoruz. Bu grafiği uzaklaştırırsak, bu görünüşte düz çizgilerin bile aslında daha geniş tabanlı U-şekilleri olduğunu gösterirdi.
Bu örnek, varsayımlarımızın öngörülerimizi desteklediğinden emin olmak için analizlerde dikkatli olmanın önemini vurgular. Modelimiz tam olarak istediğimiz şeyi yaptı ancak yalnızca verdiğimiz sınırlar içinde. Daha uzakta düz bir şekil oluşturacak değişken kombinasyonunu bulmak isteseydik, modeli daha geniş sınırlarla yeniden çalıştırmamız gerekirdi.
Değişkenlerin her birini, nesiller boyunca ne kadar değiştiklerini görmek için ayrı ayrı çizebiliriz. Bu simülasyon çalıştırmasında c’nin başlarda çok dalgalandığını, a ve b’nin ise çok daha az dramatik biçimde değiştiğini görüyoruz. Başlangıç popülasyonu rastgele olduğundan, bu grafiğin görünümü parametreleri değiştirmesek bile her çalıştırmada farklı olacaktır.
Bakmak istediğim son grafik, tek bir nesildeki tüm popülasyonun anlık görüntüsü: son nesil. Popülasyondaki her bireyin üç parametresi olduğundan, 3 boyutlu grafiklerle uğraşmak yerine bunları üç alt grafiğe ayırmayı tercih ettim.
Bu grafiklerden gerçekten görmek istediğim şey, bu nesil içinde iyi bir çeşitlilik olup olmadığı. Yeterli çeşitlilik olmazsa, mevcut tek çözümler düşük uygunluk değerlerine sahip olanlar olabilir ve bu da erken yakınsamaya yol açar. Ancak bu grafik, iyi bir çeşitlilik düzeyi olduğunu gösteriyor gibi görünüyor; bu sonuca memnunum.
Genetik algoritmalar çok çeşitli durumlarda kullanılabilir. Ancak akılda tutulması gereken birkaç husus vardır.
Her modelde olduğu gibi, bir genetik algoritmanın performansı başta popülasyon büyüklüğü, çaprazlama oranı, mutasyon oranı ve sınırlandırma parametreleri olmak üzere çeşitli parametrelere bağlıdır. Bu parametreleri değiştirmek, modelinizin performansını da değiştirecektir.
Genel bir kural olarak, daha büyük popülasyonlar, seçilecek daha fazla seçenek olduğundan optimal çözüme daha hızlı ulaşmanıza yardımcı olur. Ancak daha büyük popülasyonlar, çalıştırmak için daha fazla zaman ve kaynak gerektirir.
Daha yüksek bir çaprazlama oranı, farklı bireylerden yararlı özellikleri daha sık birleştirerek daha hızlı yakınsamaya yol açabilir. Ancak çok yüksek bir çaprazlama oranı, popülasyon yapısını bozarak erken yakınsamaya neden olabilir.
Daha yüksek bir mutasyon oranı, genetik çeşitliliği koruyarak algoritmanın yerel optimumda takılıp kalmasını engeller. Ancak mutasyon oranı çok yüksek olursa, aşırı rastgelelik katarak yakınsama sürecini bozabilir ve algoritmanın çözümleri rafine etmesini zorlaştırabilir.
Sınırlandırma parametreleri, algoritmanın çözümleri aradığı aralığı tanımlar. Bunları, özel iş probleminize göre ayarlamak önemlidir. Çok dar bir sınırlandırma alanı, probleminizin optimal çözümlerini kaçırabilir. Çok geniş bir alan ise daha fazla zaman ve kaynak gerektirir. Ancak başka hususlar da vardır.
Örneğin, yukarıdaki kodlu örneğimizdeki denklemin teorik olarak sınırı yoktur. Ancak pratikte, bilgisayardan sonsuz büyük bir grafikte en düz yayı bulmasını isteyemeyiz. Bu yüzden sınırlar gereklidir. Fakat bu sınırları değiştirmek, optimal cevabı da değiştirecektir. Bana göre, herhangi bir modelde belirli kullanım durumunuza uygun sınırları belirlemek elzemdir.
Modelinizde ayarlamanız gereken başka önemli parametreler de olabilir. Probleminiz için en iyi ayarları bulmak amacıyla farklı değerlerle deneyler yapın. GA’ların özel olarak ayarlanması hakkında bilgi edinmek için Bilgilendirilmiş Yöntemler: Genetik Algoritmalar bölümüne göz atın.
Kodlama, bir genetik algoritmayı kurarken önemli bir adımdır. Olası çözümleri algoritmanın işleyebileceği bir formata dönüştürmeyi içerir. Örneğin, kamyonlarımız için teslimat rotalarını optimize edecek bir genetik algoritma tasarladığımızı varsayalım. Teslimat konumları listesini bir GA’ya girecek kromozoma nasıl dönüştürürsünüz? Kodlama, bu listeyi, olası bir teslimat rotasını temsil eden sıralı konumlar gibi, algoritmanın üzerinde işlem yapabileceği bir sıraya dönüştürür.
Doğru kodlama, genetik algoritmanın çözüm uzayını etkin şekilde keşfetmesini ve çözümleri anlamlı şekillerde birleştirmesini ya da mutasyona uğratmasını sağlar. Olmadan algoritma karmaşık verilerle baş edemezdi. Teslimat konumları, çizelgeleme problemleri veya müşteri hizmeti etkileşimleri gibi veriler, bilgisayarlar için yalnızca kodlama yoluyla erişilebilir hale gelir.
Seçebileceğiniz çeşitli kodlama şemaları vardır. Sizin durumunuz için hangisinin en uygun olabileceğini öğrenmek üzere Python’da Kategorik Verilerle Çalışma veya Python’da String’leri Byte’lara Dönüştürme içeriklerine göz atabilirsiniz.
Erken yakınsama, popülasyonun çok benzer hale gelmesi durumunda ortaya çıkan bir problemdir. Bu, algoritmanın küresel optimumu bulmak yerine yerel optimumda takılı kalmasına yol açabilir. Özünde, popülasyonda yeterli çeşitlilik yoksa çözümler “akraba evliliği” yapmış gibi olur ve en iyi çözüme ulaşamazsınız.
Erken yakınsamayı önlemek için deneyebileceğiniz birkaç teknik vardır. Daha yüksek bir mutasyon oranı, popülasyona daha fazla çeşitlilik katarak çözüm uzayının yeni bölgelerinin keşfine yardımcı olabilir. Ayrıca, çözüm uzayının başlangıçtan itibaren geniş kapsamda keşfini sağlamak için daha çeşitli bir başlangıç popülasyonuyla başlayabilirsiniz.
Hâlâ erken yakınsama ile karşılaşıyorsanız, algoritmanın ilerlemesine bağlı olarak mutasyon oranı ve çaprazlama oranı gibi parametreleri dinamik olarak ayarlamayı deneyebilirsiniz. Alternatif olarak, zaman zaman birey değişimi yapan birden fazla popülasyon (adanalar gibi düşünebilirsiniz) kullanarak çeşitliliği koruyabilirsiniz.
Erken yakınsama ve diğer makine öğrenimi hataları hakkında daha fazla bilgiyi Makine Öğrenimi Kavramlarını İzleme kursunda bulabilirsiniz.
Öte yandan, güçlü çaprazlama ve mutasyon ya da seçimdeki herhangi bir rastgelelik, harika çözümlerin üreyememesine yol açabilir. İşte bu noktada elitizm devreye girebilir. Elitizm, en iyi bireylerin iyi çözümleri korumak için doğrudan bir sonraki nesle aktarılması tekniğidir. Bu, evrimsel süreç sırasında en iyi çözümlerin kaybolmamasını sağlar.
Ancak elitizmi kullanırken dikkatli olun. Yeterince yüksek popülasyon çeşitliliği olmadan elitizm kullanılırsa yine erken yakınsamaya yol açabilirsiniz. İş probleminiz elitizm tekniklerini gerektiriyorsa, bunu yeterince güçlü çaprazlama ve mutasyon fonksiyonları ile büyük bir popülasyon büyüklüğüyle eşleştirdiğinizden emin olun. Bu yaklaşım, bilinen çözümlerden yararlanma ile yeni olasılıkları keşfetme arasında sağlıklı bir denge kurmaya yardımcı olur.
Genetik algoritmalar, veri biliminin doğal dünyadan ilham almasına harika bir örnektir. Doğal seçilim sürecini taklit ederek karmaşık optimizasyon problemlerini çözmek için güçlü bir yöntem sunarlar.
Biyolojiden ilham alan diğer modellere ilgi duyuyorsanız, sinir ağları ve diğer derin öğrenme tekniklerini Python’da Derin Öğrenmeye Giriş kursunda öğrenebilirsiniz. Ayrıca DataCamp’in Üretken Yapay Zekâ Kavramları kursu ve Yapay Zekâ Etiği içerikleri de ilginizi çekebilir.
Biyolojik verilerle bir proje yapma ilhamı aldıysanız, R ile Genomik Verileri Analiz Etme veya Python’da Biyomedikal Görüntü Analizi içeriklerine göz atın.
Bu kurslarla yapay zekâyı öğrenin!
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
