
Curso
Implantação e ciclo de vida em MLOps
4 h
12K
Inspirados na evolução natural, os AGs exploram com eficiência o espaço de solução para descobrir soluções ideais ou quase ideais, mesmo para problemas complexos com várias partes móveis. Ao imitar o processo de seleção natural, os AGs podem desenvolver soluções ao longo do tempo, melhorando seu desempenho iterativamente.
Os algoritmos genéticos foram inspirados no processo de seleção natural e genética. Eles imitam a maneira como os organismos vivos evoluem ao longo das gerações para se adaptar e sobreviver em seus ambientes. A compreensão dos princípios biológicos básicos por trás dos AGs pode nos ajudar a entender como esses algoritmos funcionam e a usá-los de forma mais estratégica.
A seleção natural é o processo que faz com que os indivíduos com melhores combinações de características favoráveis tenham maior probabilidade de sobreviver e se reproduzir. Com o tempo, essas características vantajosas se tornam mais comuns na população.
No contexto dos AGs, esse conceito é espelhado pela seleção de indivíduos com maior pontuação de aptidão para reprodução. Dessa forma, eles transmitem suas características favoráveis, ou "genes", para a próxima geração.
As características de um organismo biológico são codificadas por seus genes. Os genes fazem parte do DNA, que é organizado em cromossomos.
Os AGs usam muitos dos mesmos conceitos e terminologia. As possíveis soluções para um problema são representadas como "cromossomos", que normalmente são codificados como cadeias ou matrizes. Cada elemento do cromossomo corresponde a um gene que determina uma característica específica da solução.
O cruzamento, ou recombinação, é uma operação genética que combina partes do material genético de dois cromossomos pais em um novo cromossomo que contém partes de cada um deles. Essa nova mistura de cromossomos é passada para a criança. Essa é uma das razões pelas quais você pode obter a cor dos olhos de sua mãe e a cor do cabelo de seu pai.
Nos AGs, o crossover envolve a troca de segmentos dos cromossomos pais para criar novos indivíduos. Essa operação introduz variabilidade e permite que os descendentes herdem características benéficas de ambos os pais.
A mutação introduz mudanças aleatórias nos genes de um organismo, o que pode levar a novas características.
Nos algoritmos genéticos, a mutação envolve a alteração aleatória de um ou mais genes em um cromossomo. Isso ajuda a manter a diversidade genética dentro da população e permite que o algoritmo explore novas áreas do espaço de solução.
Na natureza, a aptidão de um indivíduo é determinada por sua capacidade de sobreviver e se reproduzir. Se você morrer antes de se reproduzir, sua aptidão será zero. Se você tiver 12 netos, sua aptidão física será maior do que a de alguém com 2 netos.
Nos GAs, a adequação é semelhante, mas um pouco diferente. Uma função de adequação avalia o grau em que uma solução resolve o problema em questão. As soluções com maior pontuação de adequação têm maior probabilidade de serem selecionadas para reprodução, garantindo que as melhores soluções se propaguem por gerações.
Os algoritmos genéticos foram inspirados pela evolução. Consequentemente, os componentes de um AG compartilham nomes e funções semelhantes aos de suas contrapartes biológicas. Cada um desses componentes geralmente é codificado como sua própria função.
A população em um algoritmo genético é um conjunto de soluções candidatas, geralmente chamadas de indivíduos. Cada indivíduo é representado como um cromossomo, que pode ser codificado como cadeias binárias, matrizesou outras estruturas de dados.
Por exemplo, cada cromossomo poderia representar um conjunto de valores de entrada para uma função que precisamos otimizar. Ou cada cromossomo poderia representar uma rota de caminhão para motoristas de entrega.
A função de adequação avalia a capacidade de cada indivíduo de resolver o problema no qual estamos interessados. Ele atribui um valor de adequação a cada indivíduo, com valores mais altos para soluções melhores. A função de adequação orienta o algoritmo em direção a soluções melhores.
Por exemplo, em nosso exemplo de otimização de função matemática, a função de adequação pode retornar o valor da função para as entradas fornecidas. No nosso exemplo de rotas de caminhões, a função de adequação pode retornar a velocidade de conclusão da entrega.
A função de seleção escolhe indivíduos da população para reproduzir com base em sua aptidão. Os indivíduos com maior aptidão têm maior probabilidade de serem escolhidos para reprodução. Isso imita a seleção natural, em que os indivíduos mais bem adaptados têm maior probabilidade de sobreviver e se reproduzir.
Existem alguns métodos de seleção diferentes. Os métodos de seleção comuns incluem a seleção da roleta, a seleção do torneio e a seleção baseada na classificação.
A seleção por roleta é aquela em que os indivíduos são selecionados com base em uma probabilidade proporcional à sua aptidão, semelhante a girar uma roleta.
Na seleção de torneios, um subconjunto de indivíduos é escolhido aleatoriamente e o indivíduo mais apto desse subconjunto é selecionado.
A seleção baseada em classificação classifica os indivíduos com base em sua aptidão. Em seguida, as probabilidades de seleção são atribuídas com base nessas classificações, em vez de nos valores brutos de adequação.
Cada método tem suas próprias vantagens e deve ser escolhido com base nos requisitos específicos do problema em questão.
O cruzamento combina informações de dois indivíduos para criar descendentes. O objetivo é herdar características benéficas de ambos os pais. As técnicas comuns de crossover incluem crossover de ponto único, crossover de vários pontos, crossover uniforme e crossover de combinação.
O crossover de ponto único envolve a escolha de um ponto aleatório e a troca do material genético de dois pais nesse ponto para criar dois descendentes. O crossover multiponto usa vários pontos para trocar segmentos entre os pais, permitindo combinações genéticas mais complexas.
O cruzamento uniforme decide aleatoriamente qual dos pais contribuirá com cada gene, proporcionando um alto nível de diversidade genética. O cruzamento de mistura gera descendentes misturando os genes dos pais usando um fator de mistura aleatório. A decisão de qual técnica usar deve se basear na complexidade do problema e no nível desejado de diversidade na prole.
A mutação introduz alterações aleatórias no material genético da prole. Isso ajuda a manter a diversidade na população e explora novas áreas do espaço de soluções. As mutações podem ser tão simples quanto inverter um bit em uma cadeia binária ou podem envolver alterações mais complexas, dependendo do esquema de codificação.
Um algoritmo genético passa por uma série de etapas que imitam os processos evolutivos naturais para encontrar soluções ideais. Essas etapas permitem que a população evolua ao longo das gerações, melhorando a qualidade das soluções. Aqui está uma diretriz geral de como um algoritmo genético procede:
Primeiro, geramos uma população inicial de indivíduos aleatórios. Essa etapa cria um conjunto diversificado de possíveis soluções para iniciar o algoritmo.
Em seguida, precisamos calcular a aptidão de cada indivíduo na população. Aqui, usamos a função de adequação para avaliar a qualidade de cada solução.
Usando os critérios de seleção, selecionamos indivíduos para reprodução com base em sua aptidão. Essa etapa determina quais indivíduos serão os pais.
O crossover vem em seguida. Ao combinar o material genético dos pais selecionados, aplicamos técnicas de cruzamento para gerar novas soluções ou descendentes.
Para manter a diversidade em nossa população, precisamos introduzir mutações aleatórias na prole.
Em seguida, substituímos parte ou toda a população antiga pela nova prole, determinando quais indivíduos passam para a próxima geração.
As etapas anteriores 2-6 são repetidas em loop por um número definido de gerações ou até que uma condição de término seja atendida. Esse loop permite que a população evolua ao longo do tempo e, com sorte, resulte em uma boa solução.
Agora que já sabemos o que são algoritmos genéticos e como eles funcionam, vamos criar nosso próprio algoritmo genético para resolver um problema simples de otimização.
A equação y=ax2+bx+c, quando representada graficamente, cria uma parábola. Usaremos um algoritmo genético para encontrar a combinação de valores para a, b e c que resulta na parábola mais plana. Aqui está uma prévia do que você conseguirá:
Na parte superior da nossa função, importaremos as bibliotecas necessárias. Usaremos "random" para gerar valores aleatórios para nossa população inicial. Numpy é geralmente útil quando você faz qualquer cálculo, na minha opinião.
E eu acredito firmemente que você deve sempre fazer cortes para ter certeza de que seu código está fazendo o que você acha que está fazendo. Portanto, importaremos 'matplotlib.pyplot' para criar alguns gráficos.
Também gosto de imprimir os resultados importantes de cada geração (supondo um número relativamente pequeno de gerações) para entender melhor o que aconteceu durante a simulação. Para isso, importaremos "PrettyTable".
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTableEm seguida, precisamos definir a função de adequação que avaliará a adequação de cada solução. Nesse caso, queremos encontrar o gráfico em forma de U mais plano. Então, calculei o valor y no vértice e em x=-1 e x=1.
Em seguida, calculei a curvatura do gráfico como a diferença no valor dey nesses três pontos. Como queremos obter a curva mais plana, neguei a curvatura para finalizar a função de adequação.
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curvinessUsaremos a biblioteca 'random' para gerar uma população de soluções aleatórias. Cada indivíduo dessa população é um conjunto de valores para a, b e c.
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return populationA função de seleção determinará quais indivíduos se reproduzirão para criar a próxima população. Neste exemplo, usaremos um processo de seleção de torneios, em que um subconjunto aleatório de indivíduos da população será selecionado, e os indivíduos com a maior aptidão dentro desse subconjunto serão selecionados para reprodução.
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selectedEm seguida, escreveremos uma função rápida para usar o crossover para criar novas soluções com base nas soluções existentes.
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2Também precisamos de uma função de mutação para introduzir aleatoriedade nas gerações subsequentes. Isso é importante para garantir que haja diversidade suficiente em cada geração para você selecionar.
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)Em seguida, precisamos criar o loop principal que reunirá todas essas peças para executar nosso algoritmo. Como também precisamos plotar nossos resultados, adicionarei o código de plotagem nesta seção, bem como o código necessário para criar nossa tabela final.
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)Por fim, precisamos configurar os parâmetros do nosso algoritmo e executá-lo.
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Neste exemplo, definimos um número específico de gerações para a execução do nosso algoritmo. No entanto, como alternativa, poderíamos ter configurado uma condição de encerramento que interrompesse o programa quando atingíssemos um valor de adequação desejado. Isso poderia ser parecido com o seguinte:
def termination_condition(fitnesses, target_fitness):
return max(fitnesses) >= target_fitnessAqui está o código completo.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curviness
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return population
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selected
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Vamos usar nossos resultados para ver o desempenho da nossa função.
Primeiro, podemos ver em nossa tabela que completamos 20 gerações e a aptidão pareceu aumentar de uma aptidão relativamente negativa para uma aptidão menos negativa em cada geração. Ótimo!
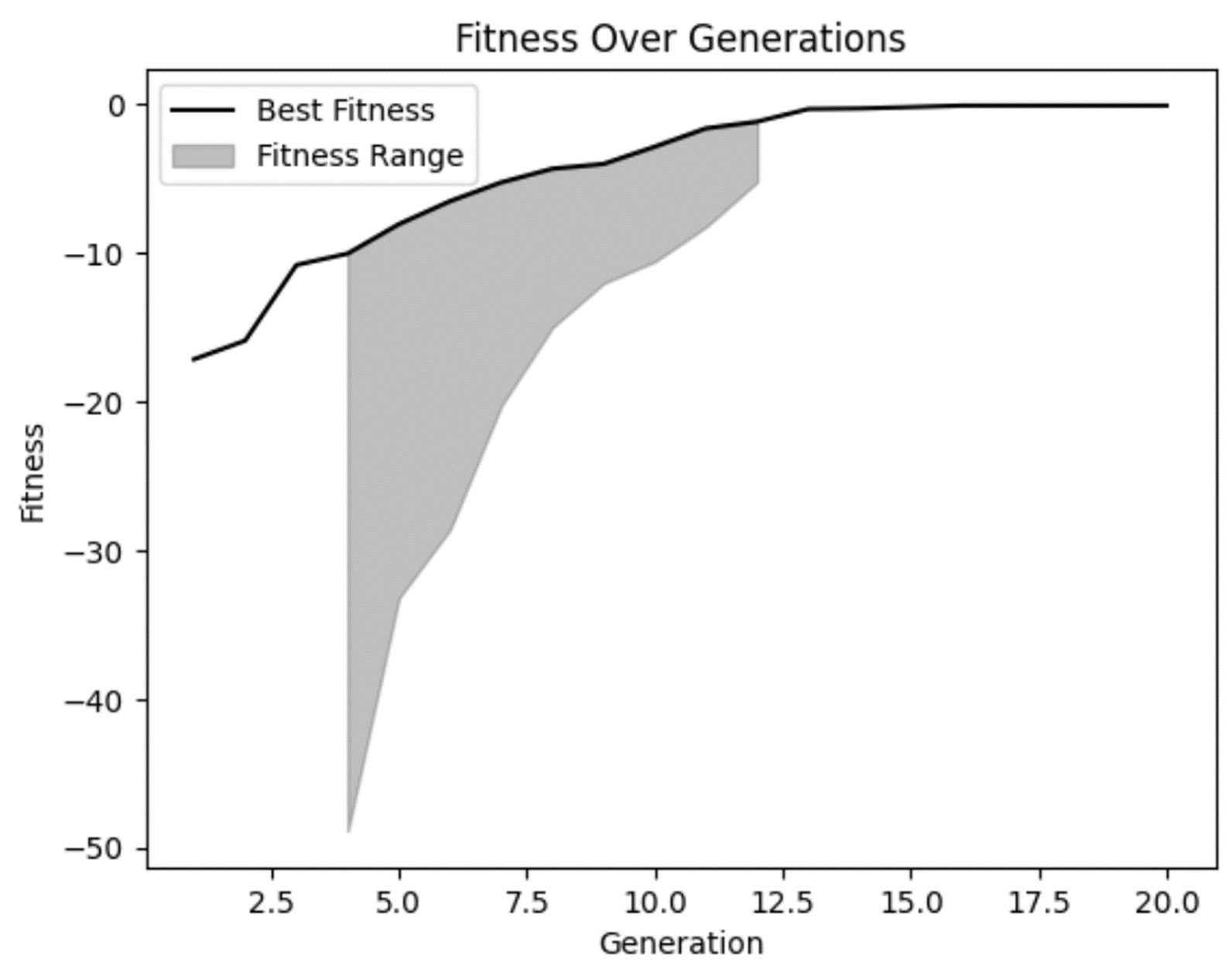
Com base em nosso gráfico de condicionamento físico, podemos confirmar nossas suspeitas de que o condicionamento físico melhorou ao longo do tempo e parece ter se achatado um pouco nas gerações posteriores. Mas também podemos ver que, em algumas das primeiras gerações, havia algumas soluções realmente ruins que nosso modelo rejeitou corretamente.
Também podemos ver que em várias gerações não houve muita diversidade na faixa de aptidão. Embora isso não seja necessariamente uma coisa ruim, você deve ficar atento. Em alguns casos, isso pode ser um indicador de convergência prematura, que é um problema que ocorre quando não há diversidade suficiente em sua população.
Em seguida, vamos plotar nossas equações de cada geração para ver se realmente as achatamos.
Podemos ver que nossas soluções de primeira geração são muito curvas, o que faz sentido. Essa equação produz um gráfico em forma de U. Mas também podemos ver que as gerações futuras se tornaram cada vez mais planas. Isso é exatamente o que estávamos procurando!
Agora, vale a pena observar que estamos explicitamente olhando apenas dentro dos limites declarados de -50 - 50. Se ampliássemos esse gráfico, ele mostraria que mesmo essas linhas aparentemente planas ainda são em forma de U, apenas com bases mais largas.
Esse exemplo destaca a importância de sermos cautelosos com nossas suposições nas análises para garantir que elas apoiem nossas previsões. Nosso modelo fez exatamente o que queríamos, mas somente dentro dos limites que estabelecemos. Se quisermos encontrar uma combinação de variáveis que crie uma forma plana mais distante, precisaremos executar novamente o modelo com limites mais amplos.
Podemos plotar cada uma das variáveis para ver o quanto elas mudaram ao longo das gerações. Podemos ver que, nessa execução da simulação, c variou muito no início, enquanto a e b mudaram de forma muito menos drástica. Esse gráfico terá uma aparência diferente toda vez que executarmos essa simulação, mesmo que não alteremos nenhum parâmetro, pois nossa população inicial é aleatória.
O último gráfico que quero analisar é apenas um instantâneo de toda a população em uma geração: a geração final. Como cada indivíduo da população tem três parâmetros, decidi separá-los em três subparcelas, em vez de me preocupar com parcelas tridimensionais.
O que eu realmente quero ver nesses gráficos é se há uma boa diversidade nessa geração. Sem uma boa quantidade de diversidade, podemos acabar em uma situação em que as únicas soluções disponíveis são aquelas com baixos valores de adequação, resultando em convergência prematura. Mas parece que esse gráfico mostra uma boa quantidade de diversidade, então estou feliz com esse resultado.
Os algoritmos genéticos podem ser usados em uma ampla variedade de situações. Mas há algumas considerações que você deve ter em mente.
Como em qualquer modelo, o desempenho de um algoritmo genético depende de vários parâmetros, principalmente do tamanho da população, da taxa de cruzamento, da taxa de mutação e dos parâmetros de limite. A alteração desses parâmetros mudará o desempenho do seu modelo.
Como regra geral, populações maiores ajudarão você a encontrar a solução ideal mais rapidamente, pois há mais opções para escolher. No entanto, populações maiores também exigem mais tempo e recursos para serem executadas.
Uma taxa de cruzamento mais alta pode levar a uma convergência mais rápida, combinando características benéficas de diferentes indivíduos com mais frequência. No entanto, uma taxa de cruzamento muito alta pode perturbar a estrutura da população, levando à convergência prematura.
Uma taxa de mutação mais alta ajuda a manter a diversidade genética, evitando que o algoritmo fique preso em um ótimo local. No entanto, se a taxa de mutação for muito alta, ela poderá interromper o processo de convergência ao introduzir muita aleatoriedade, dificultando o refinamento das soluções pelo algoritmo.
Os parâmetros de limite definem o intervalo dentro do qual o algoritmo busca soluções. É importante que você os ajuste ao seu problema comercial específico. Uma área delimitadora muito estreita pode deixar de oferecer soluções ideais para o seu problema. Uma área delimitadora muito ampla exigirá mais tempo e recursos para ser executada. Mas há outras considerações também.
Por exemplo, em nosso exemplo codificado acima, essa equação teoricamente não tem limites. Mas, na prática, não podemos pedir ao computador que encontre o arco mais plano em um gráfico infinitamente grande. Portanto, os limites são necessários. Mas a alteração desses limites também mudará a resposta ideal. Na minha opinião, estabelecer limites apropriados para o seu caso de uso específico é fundamental em qualquer modelo.
Pode haver outros parâmetros importantes a serem ajustados em seu modelo específico. Faça experiências com valores diferentes para encontrar as melhores configurações para o seu problema. Para saber mais sobre como ajustar os AGs especificamente, consulte Informed Methods: Algoritmos genéticos.
A codificação é uma etapa importante na configuração de um algoritmo genético. Isso envolve a conversão de soluções potenciais em um formato que o algoritmo possa processar. Por exemplo, digamos que estamos projetando um algoritmo genético para otimizar as rotas de entrega dos nossos caminhões. Como você transforma uma lista de locais de entrega em um cromossomo para colocar em um GA? A codificação transforma essa lista em uma sequência que o algoritmo pode manipular, como uma lista ordenada de locais que representam uma possível rota de entrega.
A codificação adequada garante que o algoritmo genético possa explorar efetivamente o espaço da solução e combinar ou transformar as soluções de maneira significativa. Sem ele, o algoritmo não seria capaz de lidar com dados complexos. Dados como locais de entrega, problemas de agendamento ou interações de atendimento ao cliente só se tornam acessíveis aos computadores por meio de codificação.
Você pode escolher entre vários esquemas de codificação. Você pode aprender mais para decidir qual é o melhor para sua situação em Trabalhando com dados categóricos em Python ou Como converter cadeias de caracteres em bytes em Python.
A convergência prematura é um problema que ocorre quando a população se torna muito semelhante. Isso pode fazer com que o algoritmo fique preso em um ótimo local em vez de encontrar o ótimo global. Essencialmente, se não houver diversidade suficiente na população, as soluções ficam "consanguíneas" e você não obtém a melhor solução.
Há algumas técnicas que você pode tentar para evitar a convergência prematura. Uma taxa de mutação mais alta pode introduzir mais diversidade na população, ajudando a explorar novas áreas do espaço de solução. Você também pode tentar começar com uma população inicial mais diversificada para garantir uma ampla exploração do espaço de solução desde o início.
Se ainda estiver lidando com convergência prematura, você pode tentar ajustar parâmetros como a taxa de mutação e a taxa de cruzamento dinamicamente com base no progresso do algoritmo. Como alternativa, você pode usar várias populações (pense nelas como ilhas) que ocasionalmente trocam indivíduos para manter a diversidade.
Você pode saber mais sobre convergência prematura e outros erros de aprendizado de máquina na seção Monitoramento dos conceitos de aprendizado de máquina que você pode fazer.
Por outro lado, o cruzamento e a mutação fortes ou qualquer aleatoriedade na seleção podem fazer com que as soluções excelentes acabem não se reproduzindo. É aí que entra o elitismo. O elitismo é uma técnica em que os melhores indivíduos são transferidos diretamente para a próxima geração para preservar boas soluções. Isso ajuda a garantir que as melhores soluções não sejam perdidas durante o processo evolutivo.
No entanto, seja cauteloso se você usar o elitismo. Se o elitismo for usado sem uma diversidade populacional alta o suficiente, você pode acabar tendo uma convergência prematura. Se o seu problema de negócios exigir técnicas de elitismo, certifique-se de combiná-las com funções de cruzamento e mutação suficientemente fortes e um grande tamanho de população. Essa abordagem ajuda a manter um equilíbrio saudável entre a exploração de soluções conhecidas e a exploração de novas possibilidades.
Os algoritmos genéticos são um exemplo fantástico de ciência de dados que se inspira no mundo natural. Eles oferecem um método eficiente para resolver problemas complexos de otimização, imitando o processo de seleção natural.
Se você estiver interessado em outros modelos inspirados na biologia, saiba mais sobre redes neurais e outras técnicas de aprendizagem profunda em Introdução à aprendizagem profunda em Python. Você também pode se interessar pelo curso do DataCamp Conceitos de IA generativa e Ética da IA.
Se você estiver inspirado a fazer um projeto com dados biológicos, confira Analisando dados genômicos em R ou Análise de imagens biomédicas em Python.
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
DataCamp Team
11 min
blog
Abid Ali Awan
11 min
Tutorial
Amberle McKee
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Kurtis Pykes
