
Kurs
MLOps-Bereitstellung und Lebenszyklus
4 Std.
12K
Nach dem Vorbild der natürlichen Evolution erforschen GAs effizient den Lösungsraum, um optimale oder nahezu optimale Lösungen zu finden, selbst für komplexe Probleme mit vielen beweglichen Teilen. Indem sie den Prozess der natürlichen Selektion nachahmen, können GAs Lösungen im Laufe der Zeit weiterentwickeln und ihre Leistung iterativ verbessern.
Genetische Algorithmen wurden durch den Prozess der natürlichen Selektion und der Genetik inspiriert. Sie ahmen die Art und Weise nach, wie sich lebende Organismen über Generationen hinweg entwickeln, um sich anzupassen und in ihrer Umgebung zu überleben. Wenn wir die grundlegenden biologischen Prinzipien hinter den GAs verstehen, können wir besser nachvollziehen, wie diese Algorithmen funktionieren und sie strategisch einsetzen.
Natürliche Auslese ist der Prozess, der dazu führt, dass Individuen mit besseren Kombinationen von günstigen Eigenschaften eher überleben und sich fortpflanzen. Mit der Zeit werden diese vorteilhaften Eigenschaften in der Bevölkerung immer häufiger.
Im Kontext von GAs wird dieses Konzept durch die Auswahl von Individuen mit höheren Fitnesswerten für die Reproduktion widergespiegelt. Auf diese Weise geben sie ihre vorteilhaften Eigenschaften, die "Gene", an die nächste Generation weiter.
Die Eigenschaften eines biologischen Organismus werden von seinen Genen kodiert. Gene sind Teil der DNA, die in Chromosomen angeordnet ist.
GAs leihen sich viele der gleichen Konzepte und Terminologie. Mögliche Lösungen für ein Problem werden als "Chromosomen" dargestellt, die in der Regel als Strings oder Arrays kodiert werden. Jedes Element im Chromosom entspricht einem Gen, das ein bestimmtes Merkmal der Lösung bestimmt.
Crossover oder Rekombination ist eine genetische Operation, bei der Teile des genetischen Materials zweier Elternchromosomen zu einem neuen Chromosom kombiniert werden, das Teile beider Elternteile enthält. Diese neue Chromosomenmischung wird an das Kind weitergegeben. Das ist ein Grund, warum du die Augenfarbe deiner Mutter und die Haarfarbe deines Vaters bekommen kannst.
Bei GAs werden beim Crossover Segmente der Elternchromosomen ausgetauscht, um neue Individuen zu schaffen. Dieser Vorgang führt zu Variabilität und ermöglicht es den Nachkommen, vorteilhafte Eigenschaften von beiden Elternteilen zu erben.
Mutation führt zufällige Veränderungen in den Genen eines Organismus ein, die zu neuen Merkmalen führen können.
Bei genetischen Algorithmen bedeutet Mutation, dass ein oder mehrere Gene in einem Chromosom zufällig verändert werden. Dies trägt dazu bei, die genetische Vielfalt innerhalb der Population zu erhalten und ermöglicht es dem Algorithmus, neue Bereiche des Lösungsraums zu erkunden.
In der Natur wird die Fitness eines Individuums durch seine Fähigkeit bestimmt, zu überleben und sich fortzupflanzen. Wenn du stirbst, bevor du dich fortpflanzt, hast du eine Fitness von Null. Wenn du 12 Enkelkinder hast, wird deine Fitness höher sein als bei jemandem mit 2 Enkelkindern.
Bei GAs ist die Fitness ähnlich, aber ein bisschen anders. Eine Fitnessfunktion bewertet, wie gut eine Lösung das jeweilige Problem löst. Lösungen mit höheren Fitnesswerten werden mit größerer Wahrscheinlichkeit für die Reproduktion ausgewählt, wodurch sichergestellt wird, dass sich bessere Lösungen über Generationen hinweg fortpflanzen.
Genetische Algorithmen wurden von der Evolution inspiriert. Daher haben die Komponenten eines GA ähnliche Namen und Funktionen wie ihre biologischen Gegenstücke. Jede dieser Komponenten wird normalerweise als eigene Funktion codiert.
Die Population in einem genetischen Algorithmus ist eine Gruppe von Lösungskandidaten, die oft Individuen genannt werden. Jedes Individuum wird als Chromosom dargestellt, das als binäre Zeichenkette kodiert werden kann, Arraysoder andere Datenstrukturen.
Jedes Chromosom könnte zum Beispiel eine Reihe von Eingabewerten für eine Funktion darstellen, die wir optimieren müssen. Oder jedes Chromosom könnte eine LKW-Route für Lieferfahrer darstellen.
Die Fitnessfunktion bewertet die Fähigkeit jedes Einzelnen, das Problem zu lösen, an dem wir interessiert sind. Es weist jedem Individuum einen Fitnesswert zu, wobei höhere Werte für bessere Lösungen stehen. Die Fitnessfunktion leitet den Algorithmus zu besseren Lösungen.
In unserem Beispiel zur Optimierung einer mathematischen Funktion könnte die Fitnessfunktion den Wert der Funktion für die gegebenen Eingaben zurückgeben. In unserem Beispiel mit den Lkw-Routen könnte die Fitnessfunktion die Geschwindigkeit der Liefererfüllung liefern.
Die Selektionsfunktion wählt Individuen aus der Population aus, die sich aufgrund ihrer Fitness vermehren. Individuen mit höherer Fitness werden mit größerer Wahrscheinlichkeit für die Fortpflanzung ausgewählt. Dies imitiert die natürliche Auslese, bei der die am besten angepassten Individuen mit größerer Wahrscheinlichkeit überleben und sich fortpflanzen.
Es gibt ein paar verschiedene Auswahlmethoden. Zu den gängigen Auswahlmethoden gehören die Roulettekesselauswahl, die Turnierauswahl und die rangbasierte Auswahl.
Bei der Roulette-Rad-Auswahl werden die Individuen auf der Grundlage einer Wahrscheinlichkeit ausgewählt, die proportional zu ihrer Fitness ist, ähnlich wie beim Drehen eines Roulette-Rades.
Bei der Turnierauswahl wird eine Teilmenge von Individuen nach dem Zufallsprinzip ausgewählt und das fitteste Individuum aus dieser Teilmenge wird ausgewählt.
Bei der rangbasierten Auswahl werden die Individuen auf der Grundlage ihrer Fitness eingestuft. Dann werden die Auswahlwahrscheinlichkeiten auf der Grundlage dieser Ränge und nicht auf der Grundlage der rohen Fitnesswerte zugewiesen.
Jede Methode hat ihre eigenen Vorteile und sollte je nach den spezifischen Anforderungen des jeweiligen Problems ausgewählt werden.
Bei der Kreuzung werden Informationen von zwei Individuen kombiniert, um Nachkommen zu erzeugen. Das Ziel ist es, vorteilhafte Eigenschaften von beiden Elternteilen zu erben. Zu den gängigen Crossover-Techniken gehören Single-Point-Crossover, Multi-Point-Crossover, Uniform-Crossover und Blend-Crossover.
Bei der Ein-Punkt-Kreuzung wird ein zufälliger Punkt ausgewählt und das genetische Material der beiden Eltern an diesem Punkt ausgetauscht, um zwei Nachkommen zu erzeugen. Bei der Mehrpunkt-Kreuzung werden mehrere Punkte für den Austausch von Segmenten zwischen den Eltern verwendet, wodurch komplexere genetische Kombinationen möglich sind.
Bei der gleichmäßigen Kreuzung wird nach dem Zufallsprinzip entschieden, welcher Elternteil welches Gen beisteuert, wodurch eine hohe genetische Vielfalt erreicht wird. Blend Crossover erzeugt Nachkommen, indem die Gene der Eltern mit einem zufälligen Mischungsfaktor gemischt werden. Die Entscheidung, welche Technik verwendet werden soll, sollte auf der Komplexität des Problems und dem gewünschten Grad an Vielfalt in der Nachkommenschaft basieren.
Mutation führt zu zufälligen Veränderungen im genetischen Material der Nachkommen. Dies trägt dazu bei, die Vielfalt in der Bevölkerung zu erhalten und neue Bereiche des Lösungsraums zu erkunden. Mutationen können so einfach sein wie das Umdrehen eines Bits in einer binären Zeichenkette oder sie können je nach Kodierungsschema komplexere Änderungen beinhalten.
Ein genetischer Algorithmus durchläuft eine Reihe von Schritten, die die natürlichen Evolutionsprozesse nachahmen, um optimale Lösungen zu finden. Diese Schritte ermöglichen es der Population, sich über Generationen hinweg weiterzuentwickeln und die Qualität der Lösungen zu verbessern. Hier ist ein allgemeiner Leitfaden, wie ein genetischer Algorithmus vorgeht:
Zuerst erzeugen wir eine Ausgangspopulation von zufälligen Individuen. Dieser Schritt erzeugt eine Vielzahl von möglichen Lösungen, mit denen der Algorithmus beginnt.
Als Nächstes müssen wir die Fitness jedes Individuums in der Population berechnen. Hier verwenden wir die Fitnessfunktion, um zu bewerten, wie gut jede Lösung ist.
Mithilfe der Selektionskriterien wählen wir die Individuen für die Fortpflanzung auf der Grundlage ihrer Fitness aus. In diesem Schritt wird festgelegt, welche Personen Eltern sein werden.
Crossover kommt als nächstes. Indem wir das genetische Material ausgewählter Eltern kombinieren, wenden wir Crossover-Techniken an, um neue Lösungen oder Nachkommen zu erzeugen.
Um die Vielfalt in unserer Population zu erhalten, müssen wir zufällige Mutationen in die Nachkommenschaft einführen.
Als Nächstes ersetzen wir einen Teil oder die gesamte alte Population durch die neuen Nachkommen, indem wir bestimmen, welche Individuen in die nächste Generation übergehen.
Die vorherigen Schritte 2-6 werden in einer Schleife für eine bestimmte Anzahl von Generationen oder bis zur Erfüllung einer Abbruchbedingung durchlaufen. Diese Schleife ermöglicht es der Population, sich im Laufe der Zeit weiterzuentwickeln, was hoffentlich zu einer guten Lösung führt.
Nachdem wir nun wissen, was genetische Algorithmen sind und wie sie im Allgemeinen funktionieren, wollen wir unseren eigenen genetischen Algorithmus bauen, um ein einfaches Optimierungsproblem zu lösen.
Die Gleichung y=ax2+bx+c ergibt, wenn man sie grafisch darstellt, eine Parabel. Wir werden einen genetischen Algorithmus verwenden, um die Kombination der Werte für a, b und c zu finden, die die flachste Parabel ergibt. Hier ist eine Vorschau auf das, was wir erreichen werden:
Am Anfang unserer Funktion importieren wir die notwendigen Bibliotheken. Wir verwenden "random", um Zufallswerte für unsere Startpopulation zu erzeugen. Numpy ist meiner Meinung nach bei allen mathematischen Aufgaben nützlich.
Und ich bin der festen Überzeugung, dass du immer Plots machen solltest, um sicherzustellen, dass dein Code das tut, was du denkst, dass er tut. Also importieren wir "matplotlib.pyplot", um einige Diagramme zu erstellen.
Ich drucke auch gerne wichtige Ergebnisse von jeder Generation aus (bei einer relativ kleinen Anzahl von Generationen), um besser zu verstehen, was während der Simulation passiert ist. Also importieren wir dafür "PrettyTable".
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTableAls nächstes müssen wir die Fitnessfunktion definieren, die die Fitness jeder Lösung bewertet. In diesem Fall wollen wir die flachste gezeichnete U-Form finden. Also habe ich den y-Wert am Scheitelpunkt und bei x=-1 und x=1 berechnet.
Dann habe ich die Krümmung des Graphen als Differenz der y Werte an diesen drei Punkten berechnet . Da wir die flachste Kurve erhalten wollen, habe ich die Krümmung negiert, um die Fitnessfunktion abzuschließen.
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curvinessWir verwenden die Bibliothek "random", um eine Population von Zufallslösungen zu erzeugen. Jedes Individuum in dieser Population ist ein Satz von Werten für a, b und c.
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return populationDie Selektionsfunktion bestimmt, welche Individuen sich fortpflanzen, um die nächste Population zu bilden. In diesem Beispiel verwenden wir ein Turnierauswahlverfahren, bei dem eine zufällige Teilmenge von Individuen in der Population ausgewählt wird und die Individuen mit der größten Fitness innerhalb dieser Teilmenge für die Reproduktion ausgewählt werden.
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selectedAls Nächstes werden wir eine schnelle Funktion schreiben, um mit Hilfe von Crossover neue Lösungen auf der Grundlage bestehender Lösungen zu erstellen.
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2Außerdem brauchen wir eine Mutationsfunktion, um Zufälligkeit in die nachfolgenden Generationen zu bringen. Das ist wichtig, um sicherzustellen, dass es in jeder Generation genug Vielfalt gibt, aus der du auswählen kannst.
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)Als Nächstes müssen wir die Hauptschleife erstellen, die all diese Teile zusammenfügt, um unseren Algorithmus auszuführen. Da wir unsere Ergebnisse auch grafisch darstellen müssen, füge ich in diesem Abschnitt den Code für die Darstellung sowie den Code für die Erstellung unserer endgültigen Tabelle ein.
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)Zum Schluss müssen wir noch die Parameter für unseren Algorithmus festlegen und ihn ausführen.
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")In diesem Beispiel haben wir eine bestimmte Anzahl von Generationen festgelegt, die unser Algorithmus durchlaufen soll. Wir hätten aber auch eine Abbruchbedingung einrichten können, die das Programm beendet, wenn wir einen bestimmten Fitnesswert erreicht haben. Das könnte etwa so aussehen:
def termination_condition(fitnesses, target_fitness):
return max(fitnesses) >= target_fitnessHier ist der komplette Code zusammen.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curviness
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return population
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selected
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Lass uns anhand unserer Ausgaben sehen, wie unsere Funktion funktioniert hat.
Erstens können wir aus unserer Tabelle ersehen, dass wir 20 Generationen abgeschlossen haben und die Fitness von einer relativ negativen Fitness zu einer weniger negativen Fitness über jede Generation zu steigen schien. Toll!
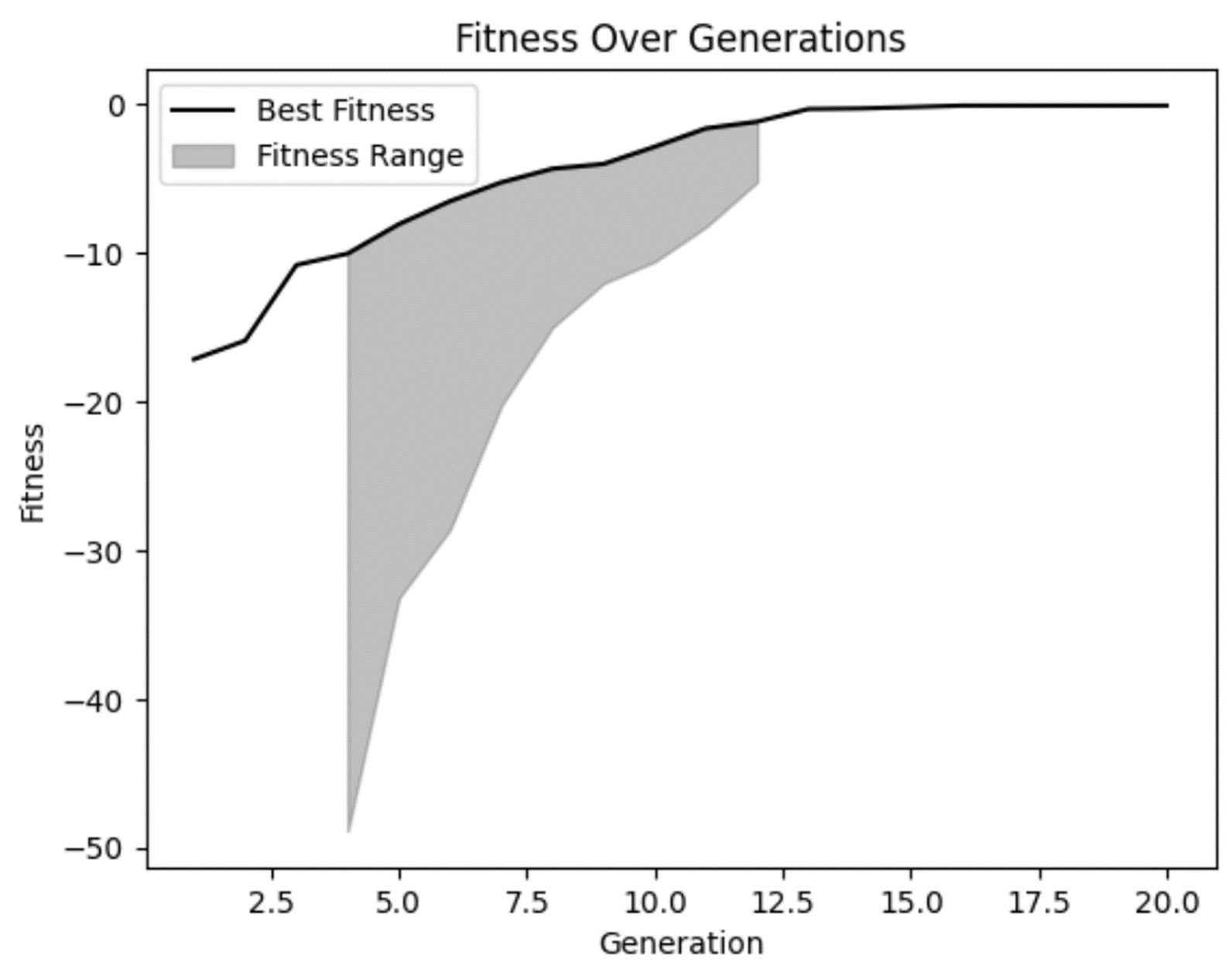
Unser Fitnessdiagramm bestätigt unsere Vermutung, dass sich die Fitness im Laufe der Zeit verbessert hat und in späteren Generationen etwas abgeflacht zu sein scheint. Aber wir können auch sehen, dass es in einigen der frühen Generationen einige wirklich schlechte Lösungen gab, die unser Modell zu Recht verworfen hat.
Wir können auch sehen, dass es in mehreren Generationen keine große Vielfalt im Fitnessbereich gab. Das ist zwar nicht unbedingt etwas Schlechtes, aber es ist etwas, worauf du achten solltest. In manchen Fällen kann dies ein Indikator für eine vorzeitige Konvergenz sein, die auftritt, wenn die Vielfalt in deiner Population nicht ausreicht.
Als Nächstes wollen wir unsere Gleichungen für jede Generation aufstellen, um zu sehen, ob wir sie wirklich abgeflacht haben.
Wir können sehen, dass unsere Lösungen der ersten Generation sehr gekrümmt sind, was auch Sinn macht. Diese Gleichung ergibt ein U-förmiges Diagramm. Aber wir können auch sehen, dass die nachfolgenden Generationen immer flacher wurden. Das ist genau das, wonach wir gesucht haben!
Es ist erwähnenswert, dass wir explizit nur innerhalb der von uns angegebenen Grenzen von -50 bis 50 suchen. Wenn wir das Diagramm herauszoomen, zeigt sich, dass selbst diese scheinbar flachen Linien immer noch u-förmig sind, nur mit einer breiteren Basis.
Dieses Beispiel zeigt, wie wichtig es ist, mit unseren Annahmen in den Analysen vorsichtig zu sein, um sicherzustellen, dass sie unsere Vorhersagen unterstützen. Unser Modell tat genau das, was wir wollten, aber nur innerhalb der Grenzen, die wir ihm setzten. Wenn wir eine Kombination von Variablen finden wollten, die eine flache Form weiter draußen erzeugt, müssten wir das Modell mit breiteren Grenzen erneut durchführen.
Wir können jede der Variablen aufzeichnen, um zu sehen, wie sehr sie sich über die Generationen hinweg verändert haben. Wir können sehen, dass in diesem Simulationslauf c schon früh stark schwankte, während a und b sich viel weniger stark veränderten. Dieses Diagramm wird jedes Mal anders aussehen, wenn wir die Simulation durchführen, auch wenn wir keine Parameter ändern, weil unsere Ausgangspopulation zufällig ist.
Die letzte Grafik, die ich mir ansehen möchte, ist nur eine Momentaufnahme der gesamten Bevölkerung in einer Generation: der letzten Generation. Da jedes Individuum in der Population drei Parameter hat, habe ich beschlossen, sie in drei Unterplots aufzuteilen, anstatt mit 3-dimensionalen Plots herumzuspielen.
Was mich an diesen Diagrammen wirklich interessiert, ist, ob es innerhalb dieser Generation eine gute Vielfalt gibt. Ohne eine große Vielfalt könnten wir in eine Situation geraten, in der nur noch Lösungen mit niedrigen Fitnesswerten verfügbar sind, was zu einer vorzeitigen Konvergenz führt. Aber es sieht so aus, als ob diese Grafik eine gute Menge an Vielfalt zeigt, also bin ich mit diesem Ergebnis zufrieden.
Genetische Algorithmen können in einer Vielzahl von Situationen eingesetzt werden. Aber es gibt ein paar Dinge, die du beachten solltest.
Wie bei jedem Modell hängt die Leistung eines genetischen Algorithmus von verschiedenen Parametern ab, insbesondere von der Populationsgröße, der Crossover-Rate, der Mutationsrate und den Begrenzungsparametern. Wenn du diese Parameter änderst, wird sich die Leistung deines Modells verändern.
Als Faustregel gilt: Je größer die Grundgesamtheit, desto schneller findest du die optimale Lösung, weil du mehr Optionen zur Auswahl hast. Größere Populationen erfordern jedoch auch mehr Zeit und Ressourcen für die Durchführung.
Eine höhere Crossover-Rate kann zu einer schnelleren Konvergenz führen, indem vorteilhafte Eigenschaften von verschiedenen Individuen häufiger kombiniert werden. Eine zu hohe Crossover-Rate könnte jedoch die Populationsstruktur stören und zu einer vorzeitigen Konvergenz führen.
Eine höhere Mutationsrate hilft, die genetische Vielfalt zu erhalten und verhindert, dass der Algorithmus in einem lokalen Optimum stecken bleibt. Wenn die Mutationsrate jedoch zu hoch ist, kann sie den Konvergenzprozess stören, indem sie zu viel Zufälligkeit einführt und es dem Algorithmus erschwert, Lösungen zu verfeinern.
Grenzparameter definieren den Bereich, in dem der Algorithmus nach Lösungen sucht. Diese sind wichtig, um sie auf dein spezielles Geschäftsproblem abzustimmen. Ein zu enger Begrenzungsbereich kann dazu führen, dass optimale Lösungen für dein Problem nicht gefunden werden. Ein zu weit gefasster Bereich benötigt mehr Zeit und Ressourcen für die Ausführung. Aber es gibt auch noch andere Überlegungen.
In unserem kodierten Beispiel oben hat diese Gleichung theoretisch keine Grenzen. Aber in der Praxis können wir den Computer nicht auffordern, den flachsten Bogen in einem unendlich großen Graphen zu finden. Grenzen sind also notwendig. Aber wenn du diese Grenzen änderst, wird sich auch die optimale Antwort ändern. Meiner Meinung nach ist es bei jedem Modell unerlässlich, angemessene Grenzen für deinen spezifischen Anwendungsfall festzulegen.
Möglicherweise gibt es noch andere wichtige Parameter, die du bei deinem Modell einstellen musst. Experimentiere mit verschiedenen Werten, um die besten Einstellungen für dein Problem zu finden. Wenn du mehr über das Tuning von GAs erfahren möchtest, schau auf Informierte Methoden: Genetische Algorithmen.
Die Kodierung ist ein wichtiger Schritt beim Aufbau eines genetischen Algorithmus. Es geht darum, potenzielle Lösungen in ein Format umzuwandeln, das der Algorithmus verarbeiten kann. Nehmen wir zum Beispiel an, wir entwickeln einen genetischen Algorithmus, um die Lieferrouten für unsere LKWs zu optimieren. Wie machst du aus einer Liste von Lieferorten ein Chromosom, das du in eine GA einbauen kannst? Die Kodierung wandelt diese Liste in eine Sequenz um, die der Algorithmus bearbeiten kann, z. B. eine geordnete Liste von Orten, die eine mögliche Lieferroute darstellen.
Die richtige Kodierung stellt sicher, dass der genetische Algorithmus den Lösungsraum effektiv erkunden und Lösungen auf sinnvolle Weise kombinieren oder mutieren kann. Ohne sie wäre der Algorithmus nicht in der Lage, komplexe Daten zu verarbeiten. Daten wie Lieferorte, Terminprobleme oder Interaktionen mit dem Kundenservice werden dem Computer nur durch Verschlüsselung zugänglich gemacht.
Es gibt mehrere Kodierungsschemata, aus denen du wählen kannst. Um zu entscheiden, was für deine Situation am besten geeignet ist, kannst du mehr erfahren in Arbeiten mit kategorialen Daten in Python oder Wie man in Python Strings in Bytes umwandelt.
Vorzeitige Konvergenz ist ein Problem, das auftritt, wenn die Population zu ähnlich wird. Das kann dazu führen, dass der Algorithmus in einem lokalen Optimum stecken bleibt, anstatt das globale Optimum zu finden. Wenn es nicht genug Vielfalt in der Population gibt, werden die Lösungen "inzüchtig" und du bekommst nicht die beste Lösung.
Es gibt ein paar Techniken, die du ausprobieren kannst, um eine vorzeitige Konvergenz zu vermeiden. Eine höhere Mutationsrate kann mehr Vielfalt in die Population bringen und dazu beitragen, neue Bereiche des Lösungsraums zu erkunden. Du kannst auch versuchen, mit einer vielfältigeren Ausgangspopulation zu beginnen, um von Anfang an eine breite Erkundung des Lösungsraums zu gewährleisten.
Wenn du immer noch mit einer vorzeitigen Konvergenz zu kämpfen hast, kannst du versuchen, Parameter wie die Mutationsrate und die Crossover-Rate dynamisch an den Fortschritt des Algorithmus anzupassen. Alternativ kannst du auch mehrere Populationen verwenden (stell dir diese als Inseln vor), die gelegentlich Individuen austauschen, um die Vielfalt zu erhalten.
Mehr über vorzeitige Konvergenz und andere Fehltritte beim maschinellen Lernen erfährst du in der Konzepte des maschinellen Lernens überwachen Kurs.
Andererseits kann eine starke Kreuzung und Mutation oder eine zufällige Auswahl dazu führen, dass sich großartige Lösungen am Ende nicht vermehren. Das ist der Punkt, an dem Elitedenken ins Spiel kommen kann. Elitismus ist eine Technik, bei der die besten Individuen direkt an die nächste Generation weitergegeben werden, um gute Lösungen zu erhalten. So wird sichergestellt, dass die besten Lösungen während des evolutionären Prozesses nicht verloren gehen.
Sei jedoch vorsichtig, wenn du Elitedenken einsetzt. Wenn Elitismus ohne eine ausreichend hohe Bevölkerungsvielfalt eingesetzt wird, kann es stattdessen zu einer vorzeitigen Konvergenz kommen. Wenn dein Geschäftsproblem Elitetechniken erfordert, musst du sicherstellen, dass du sie mit ausreichend starken Crossover- und Mutationsfunktionen und einer großen Populationsgröße kombinierst. Dieser Ansatz trägt dazu bei, ein gesundes Gleichgewicht zwischen der Nutzung bekannter Lösungen und der Erkundung neuer Möglichkeiten zu wahren.
Genetische Algorithmen sind ein fantastisches Beispiel dafür, wie sich die Datenwissenschaft von der Natur inspirieren lässt. Sie bieten eine leistungsstarke Methode, um komplexe Optimierungsprobleme zu lösen, indem sie den Prozess der natürlichen Selektion nachahmen.
Wenn du dich für andere von der Biologie inspirierte Modelle interessierst, erfährst du mehr über neuronale Netze und andere Deep Learning-Techniken in Einführung in Deep Learning in Python. Vielleicht interessiert dich auch der DataCamp Kurs Generative KI-Konzepte und KI-Ethik.
Wenn du dich für ein Projekt mit biologischen Daten inspirieren lassen willst, dann schau dir Genomische Daten in R analysieren oder Biomedizinische Bildanalyse in Python.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
Laiba Siddiqui
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
Adel Nehme
Tutorial
Allan Ouko
Tutorial
Mark Pedigo


