
Cours
Déploiement MLOps et cycle de vie
4 h
12K
Inspirés par l'évolution naturelle, les AG explorent efficacement l'espace des solutions pour découvrir des solutions optimales ou quasi optimales, même pour des problèmes complexes comportant de nombreux éléments mobiles. En imitant le processus de sélection naturelle, les AG peuvent faire évoluer les solutions au fil du temps, en améliorant leurs performances de manière itérative.
Les algorithmes génétiques s'inspirent du processus de sélection naturelle et de la génétique. Ils imitent la façon dont les organismes vivants évoluent au fil des générations pour s'adapter et survivre dans leur environnement. Comprendre les principes biologiques de base des AG peut nous aider à comprendre le fonctionnement de ces algorithmes et à les utiliser de manière plus stratégique.
La sélection naturelle est le processus qui fait que les individus présentant les meilleures combinaisons de caractéristiques favorables ont plus de chances de survivre et de se reproduire. Avec le temps, ces caractéristiques avantageuses deviennent plus courantes dans la population.
Dans le contexte des AG, ce concept est reflété par la sélection d'individus ayant des scores de fitness plus élevés pour la reproduction. Ils transmettent ainsi leurs caractéristiques favorables, ou "gènes", à la génération suivante.
Les caractéristiques d'un organisme biologique sont codées par ses gènes. Les gènes font partie de l'ADN, qui est organisé en chromosomes.
Les AG empruntent en grande partie les mêmes concepts et la même terminologie. Les solutions potentielles à un problème sont représentées sous forme de "chromosomes", qui sont généralement codés sous forme de chaînes ou de tableaux. Chaque élément du chromosome correspond à un gène qui détermine un caractère spécifique de la solution.
Le croisement, ou recombinaison, est une opération génétique qui combine des parties du matériel génétique de deux chromosomes parents en un nouveau chromosome qui contient des parties de chaque parent. Ce nouveau mélange de chromosomes est transmis à l'enfant. C'est l'une des raisons pour lesquelles vous pouvez obtenir la couleur des yeux de votre mère et la couleur des cheveux de votre père.
Dans les AG, le croisement consiste à échanger des segments des chromosomes parents pour créer de nouveaux individus. Cette opération introduit de la variabilité et permet à la progéniture d'hériter des traits bénéfiques des deux parents.
La mutation introduit des changements aléatoires dans les gènes d'un organisme, qui peuvent conduire à de nouvelles caractéristiques.
Dans les algorithmes génétiques, la mutation consiste à modifier aléatoirement un ou plusieurs gènes d'un chromosome. Cela permet de maintenir la diversité génétique au sein de la population et permet à l'algorithme d'explorer de nouvelles zones de l'espace de solution.
Dans la nature, l'aptitude d'un individu est déterminée par sa capacité à survivre et à se reproduire. Si vous mourez avant de vous reproduire, votre aptitude est nulle. Si vous avez 12 petits-enfants, votre forme physique sera plus élevée que celle d'une personne ayant 2 petits-enfants.
Dans les AG, l'aptitude est similaire, mais un peu différente. Une fonction d'aptitude évalue dans quelle mesure une solution résout le problème posé. Les solutions ayant des scores de fitness plus élevés sont plus susceptibles d'être sélectionnées pour la reproduction, ce qui garantit que les meilleures solutions se propagent au fil des générations.
Les algorithmes génétiques s'inspirent de l'évolution. Par conséquent, les composants d'un AG ont des noms et des fonctions similaires à ceux de leurs homologues biologiques. Chacun de ces composants est généralement codé comme sa propre fonction.
La population d'un algorithme génétique est un ensemble de solutions candidates, souvent appelées individus. Chaque individu est représenté par un chromosome, qui peut être codé sous forme de chaînes binaires, tableauxou d'autres structures de données.
Par exemple, chaque chromosome peut représenter un ensemble de valeurs d'entrée pour une fonction que nous devons optimiser. Ou encore, chaque chromosome pourrait représenter un itinéraire de camion pour les chauffeurs-livreurs.
La fonction d'aptitude évalue la capacité de chaque individu à résoudre le problème qui nous intéresse. Il attribue une valeur d'aptitude à chaque individu, les valeurs les plus élevées correspondant aux meilleures solutions. La fonction d'aptitude guide l'algorithme vers de meilleures solutions.
Par exemple, dans notre exemple d'optimisation d'une fonction mathématique, la fonction d'aptitude peut renvoyer la valeur de la fonction pour les entrées données. Pour notre exemple d'itinéraires de camions, la fonction d'aptitude pourrait renvoyer la vitesse d'achèvement de la livraison.
La fonction de sélection choisit les individus de la population à reproduire en fonction de leur aptitude. Les individus ayant une meilleure aptitude physique sont plus susceptibles d'être choisis pour la reproduction. Cela imite la sélection naturelle, où les individus les mieux adaptés ont plus de chances de survivre et de se reproduire.
Il existe plusieurs méthodes de sélection. Les méthodes de sélection les plus courantes sont la sélection par la roulette, la sélection par le tournoi et la sélection par le rang.
La sélection par la roulette consiste à sélectionner des individus sur la base d'une probabilité proportionnelle à leur aptitude, un peu comme si l'on faisait tourner une roulette.
Dans la sélection par tournoi, un sous-ensemble d'individus est choisi au hasard et l'individu le plus adapté de ce sous-ensemble est sélectionné.
La sélection basée sur le rang classe les individus en fonction de leur aptitude. Les probabilités de sélection sont ensuite attribuées sur la base de ces classements plutôt que sur la base des valeurs brutes d'aptitude.
Chaque méthode a ses propres avantages et doit être choisie en fonction des exigences spécifiques du problème posé.
Le croisement combine les informations de deux individus pour créer une descendance. L'objectif est d'hériter des caractéristiques bénéfiques des deux parents. Les techniques de croisement les plus courantes sont le croisement en un point, le croisement en plusieurs points, le croisement uniforme et le croisement mixte.
Le croisement en un point consiste à choisir un point aléatoire et à échanger le matériel génétique de deux parents en ce point pour créer deux descendants. Le croisement multipoint utilise plusieurs points pour échanger des segments entre les parents, ce qui permet des combinaisons génétiques plus complexes.
Le croisement uniforme décide de manière aléatoire quel parent apportera chaque gène, ce qui permet d'obtenir un niveau élevé de diversité génétique. Le croisement mixte génère une progéniture en mélangeant les gènes des parents à l'aide d'un facteur de mélange aléatoire. Le choix de la technique à utiliser doit être basé sur la complexité du problème et le niveau de diversité souhaité dans la descendance.
La mutation introduit des changements aléatoires dans le matériel génétique de la progéniture. Cela permet de maintenir la diversité de la population et d'explorer de nouveaux domaines de l'espace de solution. Les mutations peuvent être aussi simples que le basculement d'un bit dans une chaîne binaire ou impliquer des changements plus complexes en fonction du schéma d'encodage.
Un algorithme génétique passe par une série d'étapes qui imitent les processus évolutifs naturels afin de trouver des solutions optimales. Ces étapes permettent à la population d'évoluer au fil des générations, améliorant ainsi la qualité des solutions. Voici une ligne directrice générale sur le déroulement d'un algorithme génétique :
Tout d'abord, nous générons une population initiale d'individus aléatoires. Cette étape crée un ensemble diversifié de solutions potentielles pour lancer l'algorithme.
Ensuite, nous devons calculer l'aptitude de chaque individu de la population. Nous utilisons ici la fonction d'aptitude pour évaluer la qualité de chaque solution.
En utilisant les critères de sélection, nous sélectionnons les individus pour la reproduction en fonction de leur aptitude. Cette étape permet de déterminer quelles personnes seront les parents.
Crossover vient ensuite. En combinant le matériel génétique des parents sélectionnés, nous appliquons des techniques de croisement pour générer de nouvelles solutions ou descendants.
Pour maintenir la diversité dans notre population, nous devons introduire des mutations aléatoires dans la descendance.
Nous remplaçons ensuite une partie ou la totalité de l'ancienne population par la nouvelle progéniture, en déterminant les individus qui passent à la génération suivante.
Les étapes 2 à 6 précédentes sont répétées en boucle pendant un nombre déterminé de générations ou jusqu'à ce qu'une condition d'arrêt soit remplie. Cette boucle permet à la population d'évoluer au fil du temps, avec l'espoir d'aboutir à une bonne solution.
Maintenant que nous avons une bonne idée de ce que sont les algorithmes génétiques et de leur fonctionnement général, construisons notre propre algorithme génétique pour résoudre un problème d'optimisation simple.
L'équation y=ax2+bx+c, lorsqu'elle est représentée graphiquement, crée une parabole. Nous utiliserons un algorithme génétique pour trouver la combinaison de valeurs pour a, b et c qui donne la parabole la plus plate. Voici un aperçu de ce que nous allons réaliser :
Au début de notre fonction, nous importerons les bibliothèques nécessaires. Nous utiliserons "random" pour générer des valeurs aléatoires pour notre population de départ. Numpy est généralement utile pour effectuer des calculs, à mon avis.
Et je crois fermement qu'il faut toujours faire des tracés pour s'assurer que votre code fait bien ce que vous pensez qu'il fait. Nous allons donc importer "matplotlib.pyplot" pour créer des graphiques.
J'aime aussi imprimer les résultats importants de chaque génération (en supposant un nombre relativement faible de générations) pour mieux comprendre ce qui s'est passé pendant la simulation. Nous allons donc importer "PrettyTable" pour cela.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTableEnsuite, nous devons définir la fonction d'aptitude qui évaluera l'aptitude de chaque solution. Dans ce cas, nous voulons trouver la forme en U la plus plate. J'ai donc calculé la valeur y au sommet et aux points x=-1 et x=1.
J'ai ensuite calculé la courbure du graphique comme étant la différence de valeur dey en ces trois points. Comme nous voulons obtenir la courbe la plus plate, j'ai annulé la courbure pour terminer la fonction d'aptitude.
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curvinessNous utiliserons la bibliothèque "random" pour générer une population de solutions aléatoires. Chaque individu de cette population est un ensemble de valeurs pour a, b et c.
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return populationLa fonction de sélection détermine quels individus se reproduisent pour créer la population suivante. Dans cet exemple, nous utiliserons un processus de sélection par tournoi, dans lequel un sous-ensemble aléatoire d'individus de la population sera pris, et les individus ayant la meilleure aptitude dans ce sous-ensemble seront sélectionnés pour la reproduction.
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selectedEnsuite, nous allons écrire une fonction rapide pour utiliser le croisement afin de créer de nouvelles solutions basées sur des solutions existantes.
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2Nous avons également besoin d'une fonction de mutation pour introduire le hasard dans les générations suivantes. Ceci est important pour s'assurer qu'il y a suffisamment de diversité dans chaque génération pour faire une sélection.
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)Ensuite, nous devons créer la boucle principale qui rassemblera tous ces éléments pour exécuter notre algorithme. Étant donné que nous devons également tracer nos résultats, j'ajouterai le code de traçage dans cette section, ainsi que le code nécessaire à la création de notre tableau final.
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)Enfin, nous devons définir les paramètres de notre algorithme et l'exécuter.
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Dans cet exemple, nous avons fixé un nombre spécifique de générations pour l'exécution de notre algorithme. Cependant, nous aurions pu mettre en place une condition de terminaison qui aurait arrêté le programme lorsque nous avons atteint une valeur d'aptitude cible. Cela pourrait ressembler à ceci :
def termination_condition(fitnesses, target_fitness):
return max(fitnesses) >= target_fitnessVoici le code complet.
import random
import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable
# Define the fitness function (objective is to create the flattest U-shape)
def fitness_function(params):
a, b, c = params
if a <= 0:
return -float('inf') # Penalize downward facing u-shapes heavily
vertex_x = -b / (2 * a) #x value at vertex
vertex_y = a * (vertex_x ** 2) + b * vertex_x + c #y value at vertex
y_left = a * (-1) ** 2 + b * (-1) + c #y-coordinate at x = -1
y_right = a * (1) ** 2 + b * (1) + c #y-coordinate at x = 1
curviness = abs(y_left - vertex_y) + abs(y_right - vertex_y)
return -curviness # Negate to minimize curviness
# Create the initial population
def create_initial_population(size, lower_bound, upper_bound):
population = []
for _ in range(size):
individual = (random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound),
random.uniform(lower_bound, upper_bound))
population.append(individual)
return population
# Selection function using tournament selection
def selection(population, fitnesses, tournament_size=3):
selected = []
for _ in range(len(population)):
tournament = random.sample(list(zip(population, fitnesses)), tournament_size)
winner = max(tournament, key=lambda x: x[1])[0]
selected.append(winner)
return selected
# Crossover function
def crossover(parent1, parent2):
alpha = random.random()
child1 = tuple(alpha * p1 + (1 - alpha) * p2 for p1, p2 in zip(parent1, parent2))
child2 = tuple(alpha * p2 + (1 - alpha) * p1 for p1, p2 in zip(parent1, parent2))
return child1, child2
# Mutation function
def mutation(individual, mutation_rate, lower_bound, upper_bound):
individual = list(individual)
for i in range(len(individual)):
if random.random() < mutation_rate:
mutation_amount = random.uniform(-1, 1)
individual[i] += mutation_amount
# Ensure the individual stays within bounds
individual[i] = max(min(individual[i], upper_bound), lower_bound)
return tuple(individual)
# Main genetic algorithm function
def genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate):
population = create_initial_population(population_size, lower_bound, upper_bound)
# Prepare for plotting
fig, axs = plt.subplots(3, 1, figsize=(12, 18)) # 3 rows, 1 column for subplots
best_performers = []
all_populations = []
# Prepare for table
table = PrettyTable()
table.field_names = ["Generation", "a", "b", "c", "Fitness"]
for generation in range(generations):
fitnesses = [fitness_function(ind) for ind in population]
# Store the best performer of the current generation
best_individual = max(population, key=fitness_function)
best_fitness = fitness_function(best_individual)
best_performers.append((best_individual, best_fitness))
all_populations.append(population[:])
table.add_row([generation + 1, best_individual[0], best_individual[1], best_individual[2], best_fitness])
population = selection(population, fitnesses)
next_population = []
for i in range(0, len(population), 2):
parent1 = population[i]
parent2 = population[i + 1]
child1, child2 = crossover(parent1, parent2)
next_population.append(mutation(child1, mutation_rate, lower_bound, upper_bound))
next_population.append(mutation(child2, mutation_rate, lower_bound, upper_bound))
# Replace the old population with the new one, preserving the best individual
next_population[0] = best_individual
population = next_population
# Print the table
print(table)
# Plot the population of one generation (last generation)
final_population = all_populations[-1]
final_fitnesses = [fitness_function(ind) for ind in final_population]
axs[0].scatter(range(len(final_population)), [ind[0] for ind in final_population], color='blue', label='a')
axs[0].scatter([final_population.index(best_individual)], [best_individual[0]], color='cyan', s=100, label='Best Individual a')
axs[0].set_ylabel('a', color='blue')
axs[0].legend(loc='upper left')
axs[1].scatter(range(len(final_population)), [ind[1] for ind in final_population], color='green', label='b')
axs[1].scatter([final_population.index(best_individual)], [best_individual[1]], color='magenta', s=100, label='Best Individual b')
axs[1].set_ylabel('b', color='green')
axs[1].legend(loc='upper left')
axs[2].scatter(range(len(final_population)), [ind[2] for ind in final_population], color='red', label='c')
axs[2].scatter([final_population.index(best_individual)], [best_individual[2]], color='yellow', s=100, label='Best Individual c')
axs[2].set_ylabel('c', color='red')
axs[2].set_xlabel('Individual Index')
axs[2].legend(loc='upper left')
axs[0].set_title(f'Final Generation ({generations}) Population Solutions')
# Plot the values of a, b, and c over generations
generations_list = range(1, len(best_performers) + 1)
a_values = [ind[0][0] for ind in best_performers]
b_values = [ind[0][1] for ind in best_performers]
c_values = [ind[0][2] for ind in best_performers]
fig, ax = plt.subplots()
ax.plot(generations_list, a_values, label='a', color='blue')
ax.plot(generations_list, b_values, label='b', color='green')
ax.plot(generations_list, c_values, label='c', color='red')
ax.set_xlabel('Generation')
ax.set_ylabel('Parameter Values')
ax.set_title('Parameter Values Over Generations')
ax.legend()
# Plot the fitness values over generations
best_fitness_values = [fit[1] for fit in best_performers]
min_fitness_values = [min([fitness_function(ind) for ind in population]) for population in all_populations]
max_fitness_values = [max([fitness_function(ind) for ind in population]) for population in all_populations]
fig, ax = plt.subplots()
ax.plot(generations_list, best_fitness_values, label='Best Fitness', color='black')
ax.fill_between(generations_list, min_fitness_values, max_fitness_values, color='gray', alpha=0.5, label='Fitness Range')
ax.set_xlabel('Generation')
ax.set_ylabel('Fitness')
ax.set_title('Fitness Over Generations')
ax.legend()
# Plot the quadratic function for each generation
fig, ax = plt.subplots()
colors = plt.cm.viridis(np.linspace(0, 1, generations))
for i, (best_ind, best_fit) in enumerate(best_performers):
color = colors[i]
a, b, c = best_ind
x_range = np.linspace(lower_bound, upper_bound, 400)
y_values = a * (x_range ** 2) + b * x_range + c
ax.plot(x_range, y_values, color=color)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Quadratic Function')
# Create a subplot for the colorbar
cax = fig.add_axes([0.92, 0.2, 0.02, 0.6]) # [left, bottom, width, height]
norm = plt.cm.colors.Normalize(vmin=0, vmax=generations)
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, cax=cax, orientation='vertical', label='Generation')
plt.show()
return max(population, key=fitness_function)
# Parameters for the genetic algorithm
population_size = 100
lower_bound = -50
upper_bound = 50
generations = 20
mutation_rate = 1
# Run the genetic algorithm
best_solution = genetic_algorithm(population_size, lower_bound, upper_bound, generations, mutation_rate)
print(f"Best solution found: a = {best_solution[0]}, b = {best_solution[1]}, c = {best_solution[2]}")Utilisons nos résultats pour voir comment notre fonction s'est comportée.
Tout d'abord, nous pouvons voir dans notre tableau que nous avons effectué 20 générations et que la condition physique semble passer d'une condition physique relativement négative à une condition physique moins négative à chaque génération. Excellent !
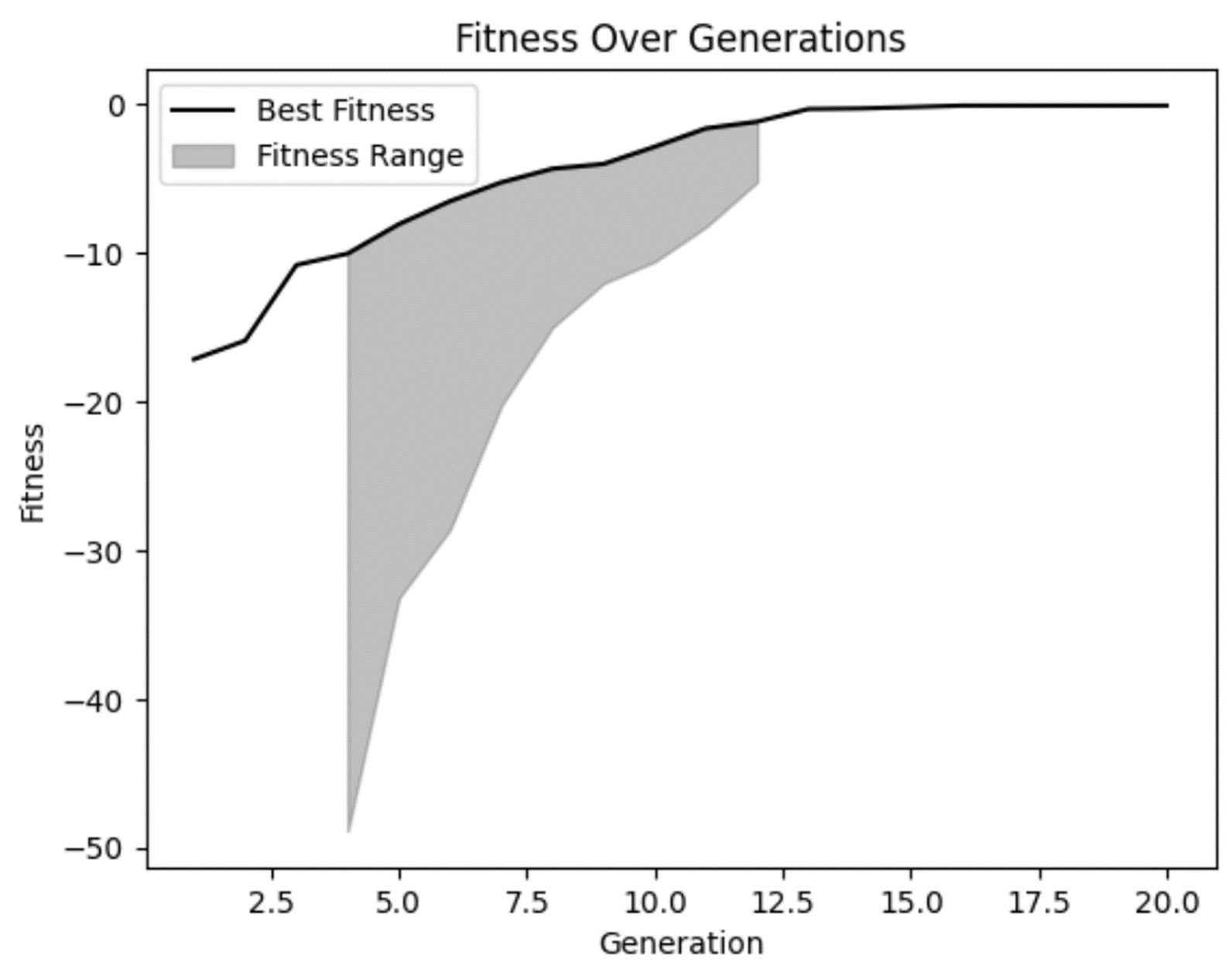
Notre graphique d'aptitude nous permet de confirmer nos soupçons : l'aptitude s'est améliorée au fil du temps et semble s'être quelque peu stabilisée dans les générations ultérieures. Mais nous pouvons également constater que, dans certaines des premières générations, il y avait de très mauvaises solutions que notre modèle a rejetées à juste titre.
Nous pouvons également constater que, sur plusieurs générations, il n'y avait pas beaucoup de diversité dans l'éventail des aptitudes. Ce n'est pas nécessairement une mauvaise chose, mais il faut s'en méfier. Dans certains cas, il peut s'agir d'un indicateur de convergence prématurée, un problème qui survient lorsqu'il n'y a pas assez de diversité dans votre population.
Ensuite, traçons nos équations de chaque génération pour voir si nous avons vraiment aplani les choses.
Nous pouvons constater que nos solutions de première génération sont très incurvées, ce qui est logique. Cette équation produit un graphique en forme de U. Mais nous pouvons également constater que les générations suivantes sont devenues de plus en plus plates. C'est exactement ce que nous recherchions !
Il convient de noter que nous ne cherchons explicitement qu'à l'intérieur de nos limites de -50 - 50. Si l'on agrandissait ce graphique, on verrait que même ces lignes apparemment plates sont toujours des formes en U, mais avec des bases plus larges.
Cet exemple souligne l'importance d'être prudent avec nos hypothèses dans les analyses afin de s'assurer qu'elles soutiennent nos prédictions. Notre modèle a fait exactement ce que nous voulions qu'il fasse, mais seulement dans les limites que nous lui avons données. Si nous voulions trouver une combinaison de variables qui créerait une forme plate plus éloignée, nous devrions réexécuter le modèle avec des limites plus larges.
Nous pouvons représenter graphiquement chacune des variables pour voir dans quelle mesure elles ont changé au fil des générations. Nous pouvons constater que dans cette simulation, c a connu des variations importantes au début, tandis que a et b ont connu des variations beaucoup moins importantes. Ce graphique sera différent à chaque fois que nous effectuerons cette simulation, même si nous ne modifions aucun paramètre, car notre population de départ est aléatoire.
Le dernier graphique que je souhaite examiner est un instantané de l'ensemble de la population en une seule génération : la dernière génération. Étant donné que chaque individu de la population possède trois paramètres, j'ai décidé de les séparer en trois sous-graphes au lieu de m'embarrasser de graphes tridimensionnels.
Ce que je veux vraiment voir dans ces graphiques, c'est s'il y a une bonne diversité au sein de cette génération. Sans une bonne dose de diversité, nous pourrions nous retrouver dans une situation où les seules solutions disponibles sont celles qui présentent de faibles valeurs d'aptitude, ce qui entraînerait une convergence prématurée. Mais il semble que ce graphique présente une bonne diversité, et je suis donc satisfait de ce résultat.
Les algorithmes génétiques peuvent être utilisés dans une grande variété de situations. Mais il y a quelques considérations à garder à l'esprit.
Comme pour tout modèle, les performances d'un algorithme génétique dépendent de divers paramètres, notamment la taille de la population, le taux de croisement, le taux de mutation et les paramètres limites. La modification de ces paramètres changera les performances de votre modèle.
En règle générale, une population plus importante vous permettra de trouver plus rapidement la solution optimale, car il y a plus d'options parmi lesquelles choisir. Cependant, l'augmentation de la taille des populations nécessite plus de temps et de ressources pour fonctionner.
Un taux de croisement plus élevé peut conduire à une convergence plus rapide en combinant plus fréquemment les caractéristiques bénéfiques de différents individus. Toutefois, un taux de croisement trop élevé peut perturber la structure de la population et entraîner une convergence prématurée.
Un taux de mutation plus élevé permet de maintenir la diversité génétique, ce qui empêche l'algorithme de rester bloqué à un optimum local. Toutefois, si le taux de mutation est trop élevé, il peut perturber le processus de convergence en introduisant trop d'aléa, ce qui rend difficile l'affinement des solutions par l'algorithme.
Les paramètres de délimitation définissent la plage dans laquelle l'algorithme recherche des solutions. Il est important de les adapter au problème particulier de votre entreprise. Une zone de délimitation trop étroite peut ne pas permettre de trouver des solutions optimales à votre problème. Une zone de délimitation trop large nécessitera plus de temps et de ressources. Mais il y a aussi d'autres considérations.
Par exemple, dans notre exemple codé ci-dessus, cette équation n'a théoriquement aucune limite. Mais en pratique, nous ne pouvons pas demander à l'ordinateur de trouver l'arc le plus plat dans un graphe infiniment grand. Des limites sont donc nécessaires. Mais la modification de ces limites modifiera également la réponse optimale. À mon avis, il est impératif, quel que soit le modèle, d'établir des limites appropriées à votre cas d'utilisation spécifique.
Il peut y avoir d'autres paramètres importants à régler dans votre modèle particulier. Expérimentez avec différentes valeurs pour trouver les meilleurs paramètres pour votre problème. Pour en savoir plus sur l'optimisation des AG, consultez le site Informed Methods : Algorithmes génétiques.
Le codage est une étape importante dans la mise en place d'un algorithme génétique. Il s'agit de convertir les solutions potentielles dans un format que l'algorithme peut traiter. Par exemple, imaginons que nous concevions un algorithme génétique pour optimiser les itinéraires de livraison de nos camions. Comment transformer une liste de lieux de livraison en un chromosome à intégrer dans un AG ? Le codage transforme cette liste en une séquence que l'algorithme peut manipuler, par exemple une liste ordonnée de lieux représentant un itinéraire de livraison possible.
Un codage approprié permet à l'algorithme génétique d'explorer efficacement l'espace de solution et de combiner ou de faire muter les solutions de manière significative. Sans elle, l'algorithme ne serait pas en mesure de traiter des données complexes. Les données telles que les lieux de livraison, les problèmes de programmation ou les interactions avec le service clientèle ne sont accessibles aux ordinateurs que par le biais de l'encodage.
Il existe plusieurs schémas d'encodage. Vous pouvez en savoir plus pour décider ce qui convient le mieux à votre situation dans Travailler avec des données catégorielles en Python ou Comment convertir des chaînes de caractères en octets en Python.
La convergence prématurée est un problème qui survient lorsque la population devient trop similaire. L'algorithme peut ainsi rester bloqué à un optimum local au lieu de trouver l'optimum global. Essentiellement, s'il n'y a pas assez de diversité dans la population, les solutions deviennent "consanguines" et vous n'obtenez pas la meilleure solution.
Vous pouvez essayer quelques techniques pour éviter une convergence prématurée. Un taux de mutation plus élevé peut introduire davantage de diversité dans la population, ce qui permet d'explorer de nouvelles zones de l'espace de solution. Vous pouvez également essayer de commencer avec une population initiale plus diversifiée afin de garantir une large exploration de l'espace de solution dès le début.
Si vous êtes toujours confronté à une convergence prématurée, vous pouvez essayer d'ajuster les paramètres tels que le taux de mutation et le taux de croisement de manière dynamique en fonction de la progression de l'algorithme. Vous pouvez également utiliser plusieurs populations (imaginez des îles) qui échangent occasionnellement des individus pour maintenir la diversité.
Pour en savoir plus sur la convergence prématurée et d'autres erreurs de l'apprentissage automatique, consultez la rubrique Contrôler les concepts de l'apprentissage automatique dans le cours de suivi des concepts de l'apprentissage automatique.
D'autre part, des croisements et des mutations importants ou une sélection aléatoire peuvent empêcher la reproduction de bonnes solutions. C'est là que l'élitisme peut intervenir. L'élitisme est une technique selon laquelle les meilleurs individus sont directement transmis à la génération suivante afin de préserver les bonnes solutions. Cela permet de s'assurer que les meilleures solutions ne sont pas perdues au cours du processus d'évolution.
Cependant, soyez prudent si vous utilisez l'élitisme. Si l'élitisme est utilisé sans une diversité de population suffisamment élevée, vous risquez d'obtenir une convergence prématurée. Si votre problème requiert des techniques d'élitisme, veillez à les associer à des fonctions de croisement et de mutation suffisamment puissantes et à une population de grande taille. Cette approche permet de maintenir un équilibre sain entre l'exploitation des solutions connues et l'exploration de nouvelles possibilités.
Les algorithmes génétiques sont un exemple fantastique de science des données s'inspirant du monde naturel. Ils offrent une méthode puissante pour résoudre des problèmes d'optimisation complexes en imitant le processus de sélection naturelle.
Si vous vous intéressez à d'autres modèles inspirés de la biologie, découvrez les réseaux neuronaux et d'autres techniques d'apprentissage profond dans la rubrique Introduction à l'apprentissage profond en Python. Vous pouvez également être intéressé par le cours de DataCamp intitulé Cours sur les concepts de l'IA générative et L'éthique de l'IA.
Si vous avez envie de réaliser un projet avec des données biologiques, consultez le site Analyse de données génomiques en R ou Analyse d'images biomédicales en Python.
Apprenez l'IA avec ces cours !
Cours
Cours
Cours
Tutoriel
Laiba Siddiqui
Tutoriel
Satyabrata Pal
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
Aditya Sharma
Tutoriel
DataCamp Team
