Python'da Zaman Serileri için Makine Öğrenmesi
45.4K learners
Sınıflandırma teknikleri, makine öğrenmesi ve veri madenciliği uygulamalarının vazgeçilmez bir parçasıdır. Veri bilimi problemlerinin yaklaşık %70'i sınıflandırma problemleridir. Çok sayıda sınıflandırma yöntemi vardır; ancak lojistik regresyon yaygın olup ikili sınıflandırma problemini çözmek için kullanışlı bir regresyon yöntemidir. Sınıflandırmanın bir diğer kategorisi de hedef değişkende birden fazla sınıfın bulunduğu durumları ele alan Multinomial (çok terimli) sınıflandırmadır. Örneğin IRIS veri seti, çok sınıflı sınıflandırmanın çok bilinen bir örneğidir. Diğer örnekler; makale/blog/doküman kategorilerinin sınıflandırılmasıdır.
Lojistik regresyon, spam tespiti gibi çeşitli sınıflandırma problemlerinde kullanılabilir. Diğer bazı örnekler: diyabet tahmini; belirli bir müşterinin belirli bir ürünü satın alıp almayacağı; bir müşterinin aboneliği sonlandırıp sonlandırmayacağı (churn); bir kullanıcının belirli bir reklam bağlantısına tıklayıp tıklamayacağı ve daha birçok örnek.
Lojistik Regresyon, iki sınıflı sınıflandırma için en basit ve en yaygın kullanılan Makine Öğrenmesi algoritmalarından biridir. Uygulaması kolaydır ve herhangi bir ikili sınıflandırma problemi için temel bir başlangıç noktası olarak kullanılabilir. Temel kavramları derin öğrenmede de yapıtaşıdır. Lojistik regresyon, bir bağımlı ikili değişken ile bağımsız değişkenler arasındaki ilişkiyi tanımlar ve tahmin eder.
Bu eğitimdeki tüm örnek kodları kolayca kendiniz çalıştırmak için, Python'un önceden yüklü olduğu ve tüm kod örneklerini içeren ücretsiz bir DataLab çalışma kitabı oluşturabilirsiniz. Lojistik regresyon üzerinde daha fazla pratik için, çok sayıda gerçek dünya örneği içeren R ile Kredi Riski Modellemesi kursumuzdaki alıştırmalara göz atın.
Lojistik regresyon, ikili sınıfları tahmin etmek için kullanılan istatistiksel bir yöntemdir. Çıktı ya da hedef değişken doğası gereği dişikomdur. Dişikom, yalnızca iki olası sınıf olduğu anlamına gelir. Örneğin kanser tespiti problemlerinde kullanılabilir. Bir olayın gerçekleşme olasılığını hesaplar.
Hedef değişkenin kategorik olduğu, doğrusal regresyonun özel bir durumudur. Bağımlı değişken olarak olasılık oranlarının logaritmasını kullanır. Lojistik Regresyon, bir logit fonksiyonundan yararlanarak ikili bir olayın gerçekleşme olasılığını tahmin eder.
Doğrusal Regresyon Denklemi:
![]()
Burada y bağımlı değişkendir; x1, x2 ... ve Xn ise açıklayıcı değişkenlerdir.
Sigmoid Fonksiyonu:
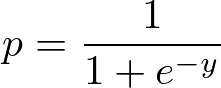
Doğrusal regresyona Sigmoid fonksiyonunu uygulama:
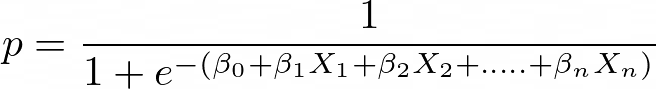
Lojistik Regresyonun Özellikleri:
Doğrusal regresyon sürekli bir çıktı üretirken, lojistik regresyon ayrık bir çıktı sağlar. Sürekli çıktıya örnek olarak konut fiyatı ve hisse senedi fiyatı verilebilir. Ayrık çıktıya örnekler ise bir hastada kanser olup olmadığının tahmini ve bir müşterinin aboneliğini sonlandırıp sonlandırmayacağının tahminidir. Lojistik regresyon, en çok olabilirlik tahmini (MLE) yaklaşımıyla kestirilirken, doğrusal regresyon tipik olarak sıradan en küçük kareler (OLS) ile kestirilir; bu da model hatalarının normal dağıldığı durumda MLE'nin özel bir hâli olarak görülebilir.
MLE bir "olabilirlik" eniyileme yöntemiyken, OLS uzaklığı en aza indiren bir yaklaşım yöntemidir. Olasılık fonksiyonunu en büyüklemek, gözlemlenen veriyi üretmesi en olası parametreleri belirler. İstatistiksel bakış açısından MLE, belirli bir model için parametre değerlerini belirlerken ortalama ve varyansı parametre olarak ele alır. Bu parametre kümesi, normal dağılımdaki verileri tahmin etmek için kullanılabilir.
Sıradan En Küçük Kareler kestirimleri, kareler toplamı en küçük olan (en küçük kare hatası) bir regresyon doğrusunun verilen veri noktalarına uydurulmasıyla hesaplanır. Her ikisi de doğrusal regresyon modelinin parametrelerini kestirmek için kullanılır. MLE, ortak bir olasılık kütle fonksiyonu varsayar; OLS ise uzaklığı en aza indirmek için stokastik bir varsayım gerektirmez.
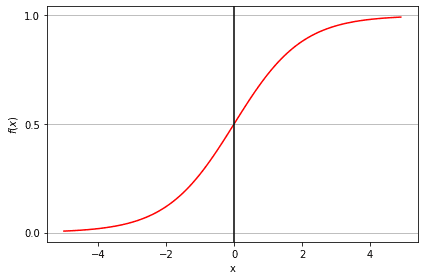
Sigmoid fonksiyonu, lojistik fonksiyon olarak da adlandırılır, herhangi bir gerçek sayı değerini 0 ile 1 arasında bir değere eşleyen ‘S’ şeklinde bir eğri verir. Eğri pozitif sonsuza giderse tahmin edilen y, 1 olur; negatif sonsuza giderse tahmin edilen y, 0 olur. Sigmoid fonksiyonunun çıktısı 0,5'ten büyükse sonucu 1 ya da EVET; 0,5'ten küçükse 0 ya da HAYIR olarak sınıflandırabiliriz. Örneğin çıktı 0,75 ise, bir hastanın kansere yakalanma olasılığının %75 olduğu söylenebilir.

Lojistik Regresyon türleri:
Hadi, lojistik regresyon sınıflandırıcısı kullanarak diyabet tahmin modeli kuralım.
Önce pandas'ın read CSV fonksiyonunu kullanarak gerekli Pima Indian Diyabet veri setini yükleyelim. Veriyi şu bağlantıdan indirebilirsiniz: https://www.kaggle.com/uciml/pima-indians-diabetes-database veya DataCamp'ten bir veri seti seçebilirsiniz: https://www.datacamp.com/datalab/datasets. Kullanıma hazır veri seti, modeli DataLab'de, DataCamp'in buluttaki ücretsiz Jupyter defterinde eğitme seçeneği sunar.
Sütunları basitleştirmek için pandas read_csv() fonksiyonuna col_names sağlayacağız.
#import pandas
import pandas as pd
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("pima-indians-diabetes.csv", header=None, names=col_names)pima.head()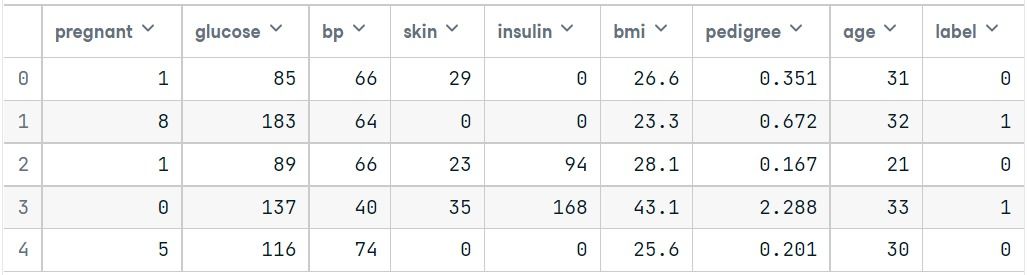
Burada, verilen sütunları iki tür değişkene ayırmanız gerekir: bağımlı (ya da hedef değişken) ve bağımsız değişkenler (ya da özellik değişkenleri).
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variableModel performansını anlamak için veri setini eğitim ve test olarak ikiye bölmek iyi bir stratejidir.
train_test_split() fonksiyonunu kullanarak veri setini bölelim. 3 parametre geçirmeniz gerekir: features, target ve test_set boyutu. Ek olarak, kayıtları rastgele seçmek için random_state kullanabilirsiniz.
# split X and y into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=16)Burada veri seti 75:25 oranında iki parçaya ayrılmıştır. Yani verinin %75'i model eğitimi için, %25'i ise model testi için kullanılacaktır.
Önce LogisticRegression modülünü içe aktarın ve yeniden üretilebilirlik için random_state ile LogisticRegression() fonksiyonunu kullanarak bir lojistik regresyon sınıflandırıcı nesnesi oluşturun.
Ardından, fit() ile modelinizi eğitim kümesine uydurun ve test kümesi üzerinde predict() ile tahmin yapın.
# import the class
from sklearn.linear_model import LogisticRegression
# instantiate the model (using the default parameters)
logreg = LogisticRegression(random_state=16)
# fit the model with data
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)Karmaşıklık matrisi, bir sınıflandırma modelinin performansını değerlendirmek için kullanılan bir tablodur. Bir algoritmanın performansını görselleştirmek için de kullanılabilir. Karmaşıklık matrisinin temel unsuru, sınıf bazında toplanan doğru ve yanlış tahmin sayılarıdır.
# import the metrics class
from sklearn import metrics
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
cnf_matrixarray([[115, 8],
[ 30, 39]])Burada karmaşıklık matrisini bir dizi nesnesi biçiminde görebilirsiniz. Bu matrisin boyutu 2x2'dir çünkü bu model ikili sınıflandırmadır. İki sınıfınız vardır: 0 ve 1. Diyagonal değerler doğru tahminleri, diyagonal olmayanlar ise yanlış tahminleri temsil eder. Çıktıda 115 ve 39 doğru tahminler, 30 ve 8 ise yanlış tahminlerdir.
Hadi, modelin sonuçlarını matplotlib ve seaborn kullanarak bir karmaşıklık matrisi şeklinde görselleştirelim.
Burada karmaşıklık matrisi bir Isı Haritası ile görselleştirilecektir.
# import required modules
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
class_names=[0,1] # name of classes
fig, ax = plt.subplots()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
# create heatmap
sns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu" ,fmt='g')
ax.xaxis.set_label_position("top")
plt.tight_layout()
plt.title('Confusion matrix', y=1.1)
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
Text(0.5,257.44,'Predicted label');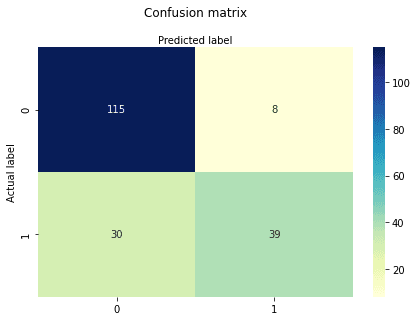
Modeli doğruluk, kesinlik ve duyarlılık için classification_report kullanarak değerlendirelim.
from sklearn.metrics import classification_report
target_names = ['without diabetes', 'with diabetes']
print(classification_report(y_test, y_pred, target_names=target_names)) precision recall f1-score support
without diabetes 0.79 0.93 0.86 123
with diabetes 0.83 0.57 0.67 69
accuracy 0.80 192
macro avg 0.81 0.75 0.77 192
weighted avg 0.81 0.80 0.79 192Burada, %80 sınıflandırma oranı elde ettiniz; bu, iyi bir doğruluk olarak kabul edilir.
Kesinlik (Precision): Kesinlik, modelinizin ne kadar isabetli olduğu ile ilgilidir. Başka bir deyişle, bir model tahmin yaptığında bunun ne sıklıkla doğru olduğudur. Sizin örneğinizde, lojistik regresyon modeliniz bir hastanın diyabetten muzdarip olacağını tahmin ettiğinde, bu hastalar zamanın %73'ünde doğruydu.
Duyarlılık (Recall): Test kümesinde diyabeti olan hastalar varsa, lojistik regresyon modeliniz bunları zamanın %57'sinde tanımlayabiliyor.
Alıcı İşletim Özelliği (ROC) eğrisi, gerçek pozitif oranına karşı yalancı pozitif oranının grafiğidir. Duyarlılık ile özgüllük arasındaki ödünleşimi gösterir.
y_pred_proba = logreg.predict_proba(X_test)[::,1]
fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)
auc = metrics.roc_auc_score(y_test, y_pred_proba)
plt.plot(fpr,tpr,label="data 1, auc="+str(auc))
plt.legend(loc=4)
plt.show()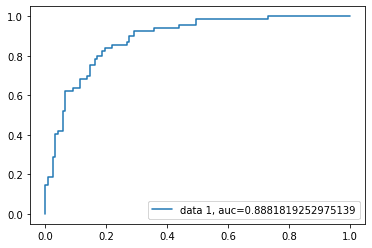
Bu durumda AUC skoru 0,88'dir. AUC skoru 1, mükemmel bir sınıflandırıcıyı; 0,5 ise değersiz bir sınıflandırıcıyı temsil eder.
Kaynak kodu DataLab'de mevcuttur: Python'da Lojistik Regresyonu Anlamak.
Verimli ve yalın doğası sayesinde yüksek hesaplama gücü gerektirmez, uygulaması kolaydır, yorumlanması rahattır ve veri analistleri ile bilim insanları tarafından yaygın biçimde kullanılır. Ayrıca özelliklerin ölçeklenmesini gerektirmez. Lojistik regresyon gözlemler için olasılık skoru sağlar.
Lojistik regresyon çok sayıda kategorik özellik/değişkeni iyi yönetemez. Aşırı öğrenmeye (overfitting) yatkındır. Ayrıca doğrusal olmayan problemleri çözemez; bu nedenle doğrusal olmayan özelliklerin dönüştürülmesini gerektirir. Lojistik regresyon, hedef değişkenle ilişkisiz olan veya birbirine çok benzer/yüksek korelasyonlu bağımsız değişkenlerle iyi performans göstermez.
Bu eğitimde, lojistik regresyon hakkında pek çok ayrıntıyı ele aldınız. Lojistik regresyonun ne olduğunu, ilgili modellerin nasıl kurulacağını, sonuçların nasıl görselleştirileceğini ve bazı kuramsal arka plan bilgilerini öğrendiniz. Ayrıca sigmoid fonksiyonu, en çok olabilirlik, karmaşıklık matrisi, ROC eğrisi gibi temel kavramları da kapsadınız.
Umarız artık kendi veri setlerinizi analiz etmek için Lojistik Regresyon tekniğinden yararlanabilirsiniz. Bu eğitimi okuduğunuz için teşekkürler!
Lojistik Regresyon hakkında daha fazla bilgi edinmek isterseniz, DataCamp'in scikit-learn ile Makine Öğrenmesi kursunu alın. Ayrıca Python ile Makine Öğrenimi Bilimcisi kariyer yoluna kaydolarak bir makine öğrenmesi mühendisi olma yolculuğunuza başlayabilirsiniz.
Python Regresyon Kursları
Kurs
Kurs