In today’s fast-paced digital landscape, with the rise of Large Language Models (LLMs), conversational applications have gained immense popularity. Chatbots have transformed the way we interact with applications, websites, and even customer service channels in our daily lives.
The ability to build your own chatbot has emerged as a game-changer, empowering businesses and individuals to create personalized, efficient, and engaging conversational interfaces tailored to their specific needs.
This article aims to break down how to build a chatbot in Python leveraging the power of LLMs. We will explore how to create our own chatbot using ChatGPT and how to further optimize it using the popular LangChain framework.
If you're new to ChatGPT and LangChain, check out our Introduction to Large Language Models with GPT & LangChain AI code-along below:
This article covers all the crucial aspects of the development of an optimized chatbot that uses ChatGPT as a model underneath. We will be using a Jupyter Notebook with both openai and langchain libraries installed. You can follow along in this DataLab workbook.
In the following sections, we will explore how to use the OpenAI API to do basic API calls to ChatGPT as the building blocks of our conversation. Additionally, we will implement context awareness for our chatbot using basic Python structures. Finally, we will optimize both the chatbot implementation and the conversation history using LangChain and explore its memory features.
Basic ChatGPT API Calls
We are going to use ChatGPT as the model behind our chatbot. For that reason, our first hands-on task will consist of writing a simple yet complete API call to ChatGPT, so that we can establish a first interaction.
The following Python function embeds our desired API call to ChatGPT using only the openai library.
import os
import openai
openai_api_key = os.environ["OPENAI_API_KEY"]
def chatgpt_call(prompt, model="gpt-3.5-turbo"):
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message["content"]
Note that in this case, we are using the gpt-3.5-turbo model since it is the most capable GPT-3.5 model and it is optimized for chat, being also one of the cheapest models. More information about the different models available can be found in the OpenAI documentation.
Do you need help getting your OpenAI API keys? Then the training Getting Started with the OpenAI API and ChatGPT is for you.
Let’s analyze our implementation step by step!
The function chatgpt_call() is a wrapper around the original OpenAI function call ChatCompletion.create that creates a chat completion request.
Given the desired prompt, the function reports the corresponding ChatGPT completion. For a successful completion call, only the ID of the model to use (model) and the desired prompt (prompt) must be provided.
The actual completion returned by ChatGPT contains metadata along with the response itself. Nevertheless, the completion itself is always returned in the response.choices[0].message[“content”] field. More information about the full completion content can be found in the OpenAI documentation.
Given this implementation, we can simply prompt ChatGPT in a single line:
prompt = "My name is Andrea"
response = chatgpt_call(prompt)
print(response)
# Output: Nice to meet you, Andrea! How can I assist you today?
The call as a standalone interaction
Do you notice any catch in the implementation above?
To give you a hint, let’s do a follow-up interaction:
prompt = "Do you remember my name?"
response = chatgpt_call(prompt)
print(response)
# Output: I'm sorry, as an AI language model, I don't have the ability to remember specific information about individual users.
Right, as we can observe, each API call is a standalone interaction. This means that the model has no memory of the previous input prompts or completions already given. Each time we call the chatgpt_call() function, we start a brand new conversation.
That is definitely an issue when trying to build a chatbot since it is impossible to have a conversation with our model if it has no memory of what we have been discussing so far. For that reason, our next step would be to make the model aware of our previous interactions.
Context-awareness
Context-awareness enables chatbots to understand and respond appropriately based on an ongoing conversation.
By building up a context, future interactions can be personalized based on past ones, maintaining continuity in the conversation and avoiding repetitions. Moreover, with context-aware chatbots, the user can proactively ask clarifying questions or provide suggestions to rectify misunderstandings.
Overall, context-awareness enhances the naturalness, effectiveness, and user experience of chatbots. From now on, we will refer to the collection of previous interactions as conversation history or memory.
The original OpenAI API for ChatGPT already provides a way to send our conversation history to the model along with each new prompt. In addition, the LangChain framework also provides a way to manage ChatGPT’s memory more effectively and in a cost-optimized way.
Understanding System, Assistant, and User Messages
ChatGPT’s conversation history structure
At this point, we can use the method chatgpt_call() straight away by just providing the desired prompt. If we have a closer look at the implementation, the input prompt is formatted as part of the messages list. This list is actually intended to keep track of the conversation history, and that is why it has to be formatted in a very particular way.
Let’s have a closer look!
So far, we have formatted the messages list in chatgpt_call() as follows:
messages = [{"role": "user", "content": prompt}]
The messages list stores the conversation history as a collection of dictionaries. Each dictionary within the list represents a message in the conversation by using two key-value pairs.
- The key
rolewith the valueuserindicates that the message has been sent by the user. - The key
contentwith the valuepromptcontains the actual user prompt.
This is a very simple example that contains only one interaction. Although the key content will always store either the user prompt or the chatbot’s completion, the key role is much more versatile.
System, Assistant, and User Roles
The key role indicates the owner of the message in content. When using ChatGPT, we can have up to three roles:
- User. As we have already discussed, the
userrole corresponds to the actual user that interacts with the chatbot. - Assistant. The
assistantrole corresponds to the chatbot. - System. The
systemrole serves to provide instructions, guidance, and context to the chatbot. System messages help guide user interactions, set chatbot behavior, offer contextual information, and handle specific interactions within the conversation. System messages can be seen as high-level instructions for the chatbot, transparent to the user.
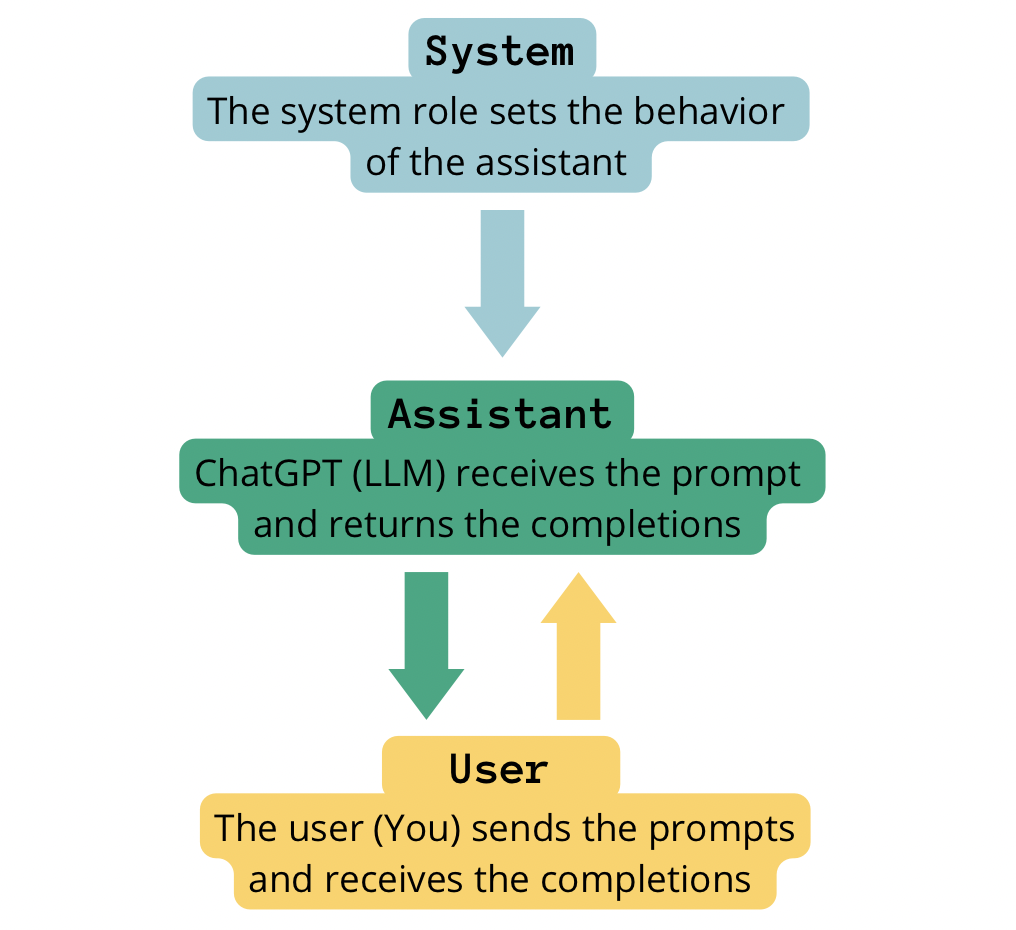
Self-made image. Interaction of the different roles in the conversation chain when building a chatbot with chatGPT.
Building a Conversation History
We can proceed to build our conversation history making use of the three user, assistant, and system roles in our messages list.
Given our test interactions, a properly formatted conversation history making use of the three aforementioned roles could look as follows:
messages = [
{'role':'system', 'content':'You are friendly chatbot.'},
{'role':'user', 'content':'Hi, my name is Andrea'},
{'role':'assistant', 'content': "Nice to meet you, Andrea! How can I assist you today?"},
{'role':'user', 'content':'Do you remember my name?'} ]
We can slightly modify our call_chatgpt() function to include the conversation history as an input parameter:
def call_chatgpt_with_memory(messages, model="gpt-3.5-turbo"):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
)
return response.choices[0].message["content"]
Let’s try this new implementation!
messages = [
{'role':'system', 'content':'You are friendly chatbot.'},
{'role':'user', 'content':'Hi, my name is Andrea'},
{'role':'assistant', 'content': "Nice to meet you, Andrea! How can I assist you today?"},
{'role':'user', 'content':'Do you remember my name?'} ]
response = call_chatgpt_with_memory(messages)
print(response)
# Output: Yes, your name is Andrea.
Nice! We have managed to keep the model aware of our past interactions so that we can actually have a conversation with the model. Nevertheless, we need to find a way to automatically update our messages list.
Automatic conversation history
We could achieve the automatic collection of messages by elaborating a bit further on our API call function:
def chatgpt_conversation(prompt):
context.append({'role':'user', 'content':f"{prompt}"})
response = call_chatgpt_with_memory(context)
context.append({'role':'assistant',
'content':f"{response}"})
return response
Let’s try now!
chatgpt_conversation("Hello, my name is Andrea")
# Output: 'Nice to meet you, Andrea! How can I assist you today?'
And a follow-up interaction:
chatgpt_conversation("Do you remember my name?")
# Output: 'Yes, your name is Andrea.'
Now the conversation history is automatically updated. Finally, just note that one can observe the conversation history — and its structure — at any time just by printing the messages list.
print(messages)
# Output:
[{'role': 'user', 'content': 'Hello, my name is Andrea'},
{'role': 'assistant', 'content': 'Nice to meet you, Andrea! How can I assist you today?'},
{'role': 'user', 'content': 'Do you remember my name?'},
{'role': 'assistant', 'content': 'Yes, your name is Andrea.'}]
The LangChain Framework
Up to this point, we will agree that our implementation leads to a useful chatbot, but it may not be its most optimized version.
Continuously feeding each and every previous prompt and completion messages can quickly lead to a huge collection of tokens, and ChatGPT would need to process them all before returning the latest completion.
So far, we have used .append operations for bundling together the past interactions so that the chatbot has some kind of memory. Nevertheless, the memory management could be done in a more effective way by using dedicated packages such as LangChain.
LangChain is a framework for developing applications powered by language models. Being a chatbot one of the most popular applications nowadays, LangChain provides a cleaner implementation for building the chatbot conversation history, and other alternatives to handle it more efficiently.
For more information on the LangChain framework itself, I really recommend the introductory article Introduction to LangChain for Data Engineering & Data Applications.
Simple conversation history with LangChain
In this section, we will explore how to use the LangChain Framework to build a chatbot instead.
The langchain library serves as a replacement for the openai library used above, since the module langchain.llms already allows you to interact with ChatGPT in two simple lines of code:
# OpenAI key from environment
from langchain.llms import OpenAI
llm = OpenAI()Once the llm model has been loaded, let’s import the memory object that will store our conversation history. For storing each past interaction with the chatbot, LangChain provides the so-called ConversationBufferMemory:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
Now it is finally time to import the so-called ConversationChain, as a wrapper that will make use of the llm and the memory to feed the user prompt to ChatGPT and return its completions:
from langchain.chains import ConversationChain
conversation = ConversationChain(
llm=llm,
memory=memory
)
Finally, to submit a user prompt to ChatGPT, we can use the .predict method as follows:
conversation.predict(input="Hello, my name is Andrea")
# Output: "Hi Andrea, I'm an AI created to help you with whatever you may need. What can I do for you today?"
Let’s set verbose=True to observe the information that the model considers to provide a completion. Let’s try it in a follow-up interaction:
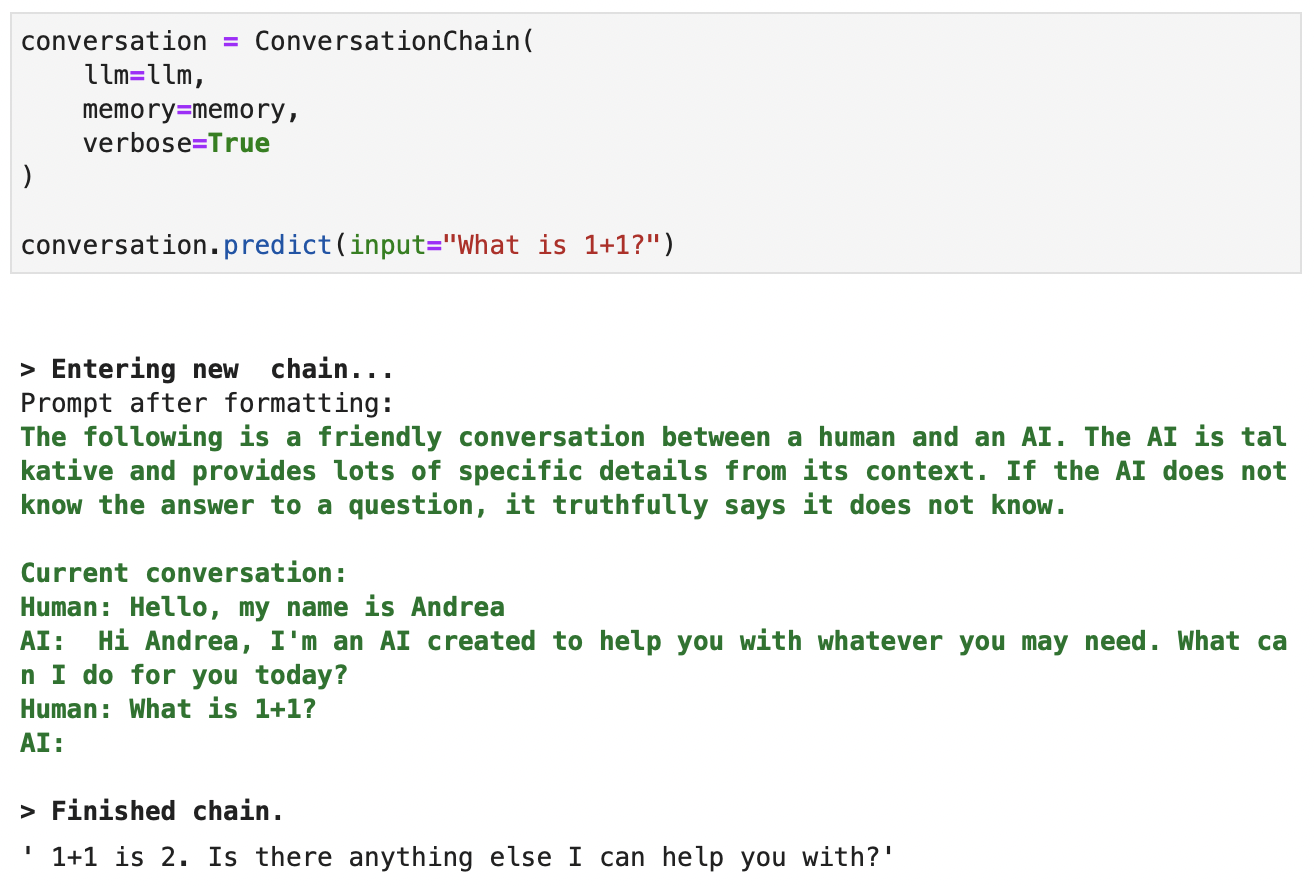
Screenshot of the context available to ChatGPT when creating a completion. Verbose output in green.
Finally, let’s check that it perfectly remembers previous interactions:
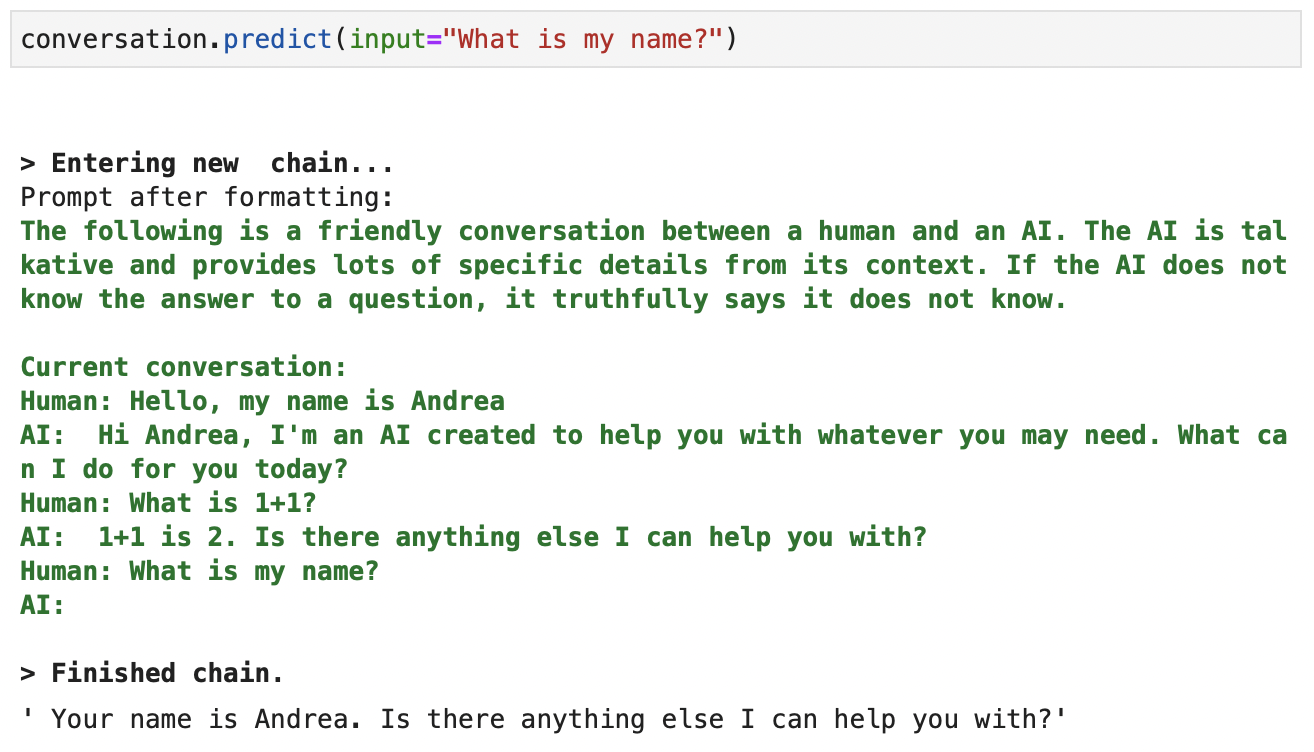
Screenshot of the context available to ChatGPT when creating a completion. Verbose output in green.
Filling up the conversation history
We can feed additional context to the chatbot using memory.save_context() method. This way, we can make our chatbot aware of any desired content without the necessity of providing this information in a conversation. In LangChain, the keywords for this purpose are input and output. For example,
memory.save_context({"input": "Hi"},
{"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"},
{"output": "Cool"})
In addition, we can also consult the memory content any time by running print(memory.buffer) or memory.load_memory_variables({}).
LangChain Memory Types
LangChain implements different types of memories for ChatGPT. The ConversationBufferMemory used above keeps track of every single interaction with ChatGPT. Nevertheless, we have already discussed that prompting ChatGPT with the entire conversation history can quickly escalate to a huge number of tokens to process at each new interaction.
Bear in mind that aside from the fact that ChatGPT has a token limit per interaction, its usage cost also depends on the number of tokens. Processing all the conversation history in each new interaction will likely be expensive over time.
To avoid the continuous processing of the conversation history, LangChain implements other optimized ways to manage ChatGPT’s memory. We will explore one of the most advanced types in the next section.
Advanced conversation history with LangChain
An advanced way to manage the memory avoiding storing each past interaction consists of storing a summary of the interactions instead.
This type of memory is my favorite one since it can really lead to an optimized memory management, without sacrificing any past interaction.
Let’s go for it!
# OpenAI key from environment
from langchain.llms import OpenAI
llm = OpenAI()
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
Just note that this type of memory uses the defined llm to generate the summary of the previous interactions.
In addition, this memory can store complete interactions up to a maximum number of tokens (max_token_limit). Above this limit, it incorporates the information of those messages in the summary.
To test it, let’s create an interaction with a large number of tokens. Considering the following schedule:
schedule = "There is a meeting at 8am with your product team. \
You will need your powerpoint presentation prepared. \
9am-12pm have time to work on your LangChain \
project which will go quickly because Langchain is such a powerful tool. \
At Noon, lunch at the italian resturant with a customer who is driving \
from over an hour away to meet you to understand the latest in AI. \
Be sure to bring your laptop to show the latest LLM demo."
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
memory.save_context({"input": "Hello"}, {"output": "What's up"})
memory.save_context({"input": "Not much, just hanging"}, {"output": "Cool"})
memory.save_context({"input": "What is on the schedule today?"}, {"output": f"{schedule}"})
Now, we just need to declare a new conversation chain given the llm and the memory as in the previous examples.
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
We can use the .predict to prompt ChatGPT:
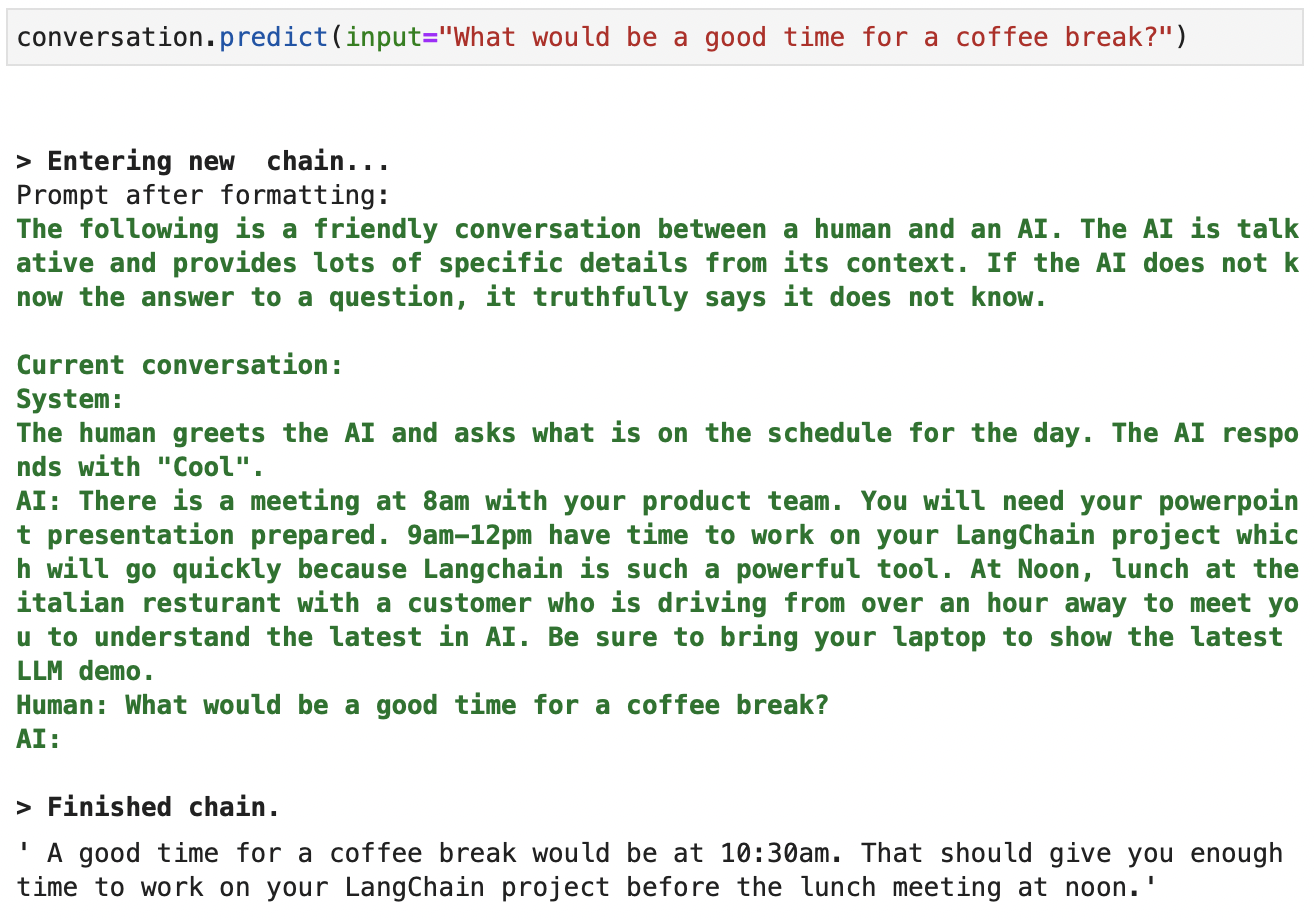
Screenshot of the context available to ChatGPT when creating a completion. Verbose output in green.
As we can observe, the chatbot keeps a summary of the original conversation history, reducing the number of tokens processed by ChatGPT in each follow-up interaction.
That’s it! Now we can continue talking to our optimized chatbot for hours!
Set verbose=False, to get a more pleasant Q&A experience in your notebook.
Conclusion
In this article, we have seen how to build a context-aware chatbot using the well-known ChatGPT model.
We have seen how building our own context-aware chatbot can lead to continuous interactions. This iterative approach fosters a constant feedback loop, allowing you to keep user needs and preferences along the conversation.
We have seen two main approaches to managing the chatbot conversation history. Firstly, by using the original ChatGPT API leading to a functional native chatbot. Secondly, by using the dedicated LangChain framework and an optimized memory type implementation.
Now the floor is yours! It is time to use the building blocks presented in this article to customize a chatbot tailored to your specific use case!
If you are interested in building other applications using both LangChain and ChatGPT, the webinar Building AI Applications with LangChain and GPT is for you. Looking to get up to speed with NLP? Then check out the modules on Natural Language Processing in Python instead!






