Course
Introduction to Python
4 hr
6.9M
The field of Data Science has progressed like nothing before. It incorporates so many different domains like Statistics, Linear Algebra, Machine Learning, Databases into its account and merges them in the most meaningful way possible. But, in its core, what makes this domain one of the craziest ones? - The powerful statistical algorithms
One such very primitive statistical algorithm is Linear Regression. Although it is very old, it is never too old to be neglected for a budding data scientist like you. Understanding the principle behind the working of linear regression is very important as to reason the evolution of a whole class of statistical algorithms called Generalized Linear Models. Moreover, it will also help you understand other aspects of a typical statistical/machine learning algorithm for example - cost functions, coefficients, optimization, etc.
As the title of this tutorial suggests, you will cover Linear Regression in details in this tutorial. Before diving deep into the theories behind Linear Regression let's have a clear view of the term regression.
Regression belongs to the class of Supervised Learning tasks where the datasets that are used for predictive/statistical modeling contain continuous labels. But, let's define a regression problem more mathematically.
Let's consider the following image below:  Source: Andrew Ng's lecture notes
Source: Andrew Ng's lecture notes
So, in the above image, X is the set of values that correspond to the living areas of various houses (also considered as the space of input values) and y is the price of the respective houses but note that these values are predicted by h. h is the function that maps the X values to y (often called as predictor). For historical reasons, this h is referred to as a hypothesis function. Keep in mind that, this dataset has only featured, i.e., the living areas of various houses and consider this to be a toy dataset for the sake of understanding.
Note that, the predicted values here are continuous in nature. So, your ultimate goal is, given a training set, to learn a function $h : \mathcal{X} \rightarrow \mathcal{Y}$ so that h(x) is a "good" predictor for the corresponding value of y. Also, keep in mind that the domain of values that both X and Y accept are all real numbers and you can define it like this: $\mathcal{X} = \mathcal{Y} = \mathbb{IR}$ where, $\mathbb{IR}$ is the set of all real numbers.
A pair (x(i), y(i)) is called a training example. You can define the training set as {(x(i), y(i)) ; i = 1,...,m} (in case the training set contains m instances and there is only one feature x in the dataset).
A bit of mathematics there for you so that you don't go wrong even in the simplest of things. So, according to Han, Kamber, and Pei-
"In general, these methods are used to predict the value of a response (dependent) variable from one or more predictor (independent) variables, where the variables are numeric." - Data Mining: Concepts and Techniques (3rd edn.)
As simple as that!
So, in the course of understanding a typical regression problem you also saw how to define a hypothesis for it as well. Brilliant going. You have set the mood just perfect! Now, you will straight dive into the mechanics of Linear Regression.
Before going into its details, won't it be good to take a look when it was discovered? Well, that goes way-way back to 18th Century. The mighty Carl Friedrich Gauss first proposed the most trivial form of statistical regression, but there are many arguments on this. Let's not get into those. But if you are interested to see the arguments that took place for this between Gauss and Adrien-Marie Legendre, this is the link to check out.
Linear regression is perhaps one of the most well known and well-understood algorithms in statistics and machine learning. Linear regression was developed in the field of statistics and is studied as a model for understanding the relationship between input and output numerical variables, but with the course of time, it has become an integral part of modern machine learning toolbox.
Let's have a toy dataset for it. You will use the same house price prediction dataset to investigate this but this time with two features. The task remains the same i.e., predicting the house price.
 Source: Andrew Ng's lecture notes
Source: Andrew Ng's lecture notes
As mentioned earlier, now the x’s are two-dimensional which means your dataset contains two features. For instance, x1(i) is the living area of the i-th house in the training set, and x2(i) is its number of bedrooms.
To perform regression, you must decide the way you are going to represent h. As an initial choice, let’s say you decide to approximate y as a linear function of x:
Here, the θi’s are the parameters (also called weights) parameterizing the space of linear functions mapping from $\mathcal{X}$ to $\mathcal{Y}$. In a simpler sense, these parameters are used for accurately mapping $\mathcal{X}$ to $\mathcal{Y}$. But to keep things simple for your understanding, you will drop the θ subscript in hθ(x), and write it simply as h(x). To simplify your notation even further, you will also introduce the convention of letting x0 = 1 (this is the intercept term), so that

where on the right-hand side above you are considering θ and x both as vectors, and here n is the number of input instances (not counting x0).
But the main question that gets raised at this point is how do you pick or learn the parameters θ? You cannot change your input instances as to predict the prices. You have only these θ parameters to tune/adjust.
One prominent method seems to be to make h(x) close to y, at least for the training examples you have. To understand this more formally, let's try defining a function that determines, for each value of the θ’s, how close the h(x(i))’s are to the corresponding y(i) ’s. The function should look like the following:

To understand the reason behind taking the squared value instead of the absolute value, consider this squared-term as an advantage for the future operations to be performed for training the regression model. But if you want to dig deeper, help yourself.
You just saw one of the most important formulas in the world of Data Science/Machine Learning/Statistics. It is called as cost function.
This is an essential derivation because not only it gives birth to the next evolution of the linear regression (Ordinary Least Squares) but also formulates the foundations of a whole class of linear modeling algorithms (remember you came across a term called Generalized Linear Models).
It is important to note that, linear regression can often be divided into two basic forms:
These things are very straightforward but can often cause confusion.
You have already laid your foundations of linear regression. Now you will study more about the ways of estimating the parameters you saw in the above section. This estimation of parameters is essentially known as the training of linear regression. Now, there are many methods to train a linear regression model Ordinary Least Squares (OLS) being the most popular among them. So, it is good to refer a linear regression model trained using OLS as Ordinary Least Squares Linear Regression or just Least Squares Regression.
Note that the parameters here in this context are also called model coefficients.
Learning/training a linear regression model essentially means estimating the values of the coefficients/parameters used in the representation with the data you have.
In this section, you will take a brief look at some techniques to prepare a linear regression model.
You left the previous section with a notion to choose θ so as to minimize J(θ). To do so, let’s use a search algorithm that starts with some "initial guess" for θ, and that iteratively changes θ to make J(θ) smaller, until hopefully, you converge to a value of θ that minimizes J(θ). Specifically, let’s consider the gradient descent algorithm, which starts with some initial θ, and repeatedly performs the update:
 Source: Andrew Ng's lecture notes
Source: Andrew Ng's lecture notes
(This update is simultaneously performed for all values of j = 0, . . . , n.) Here, α is called the learning rate. This is a very natural algorithm that repeatedly takes a step in the direction of steepest decrease of J. This term α effectively controls how steep your algorithm would move to the decrease of J. It can be pictorially expressed as the following:
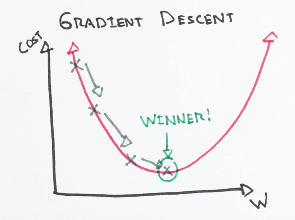 Source: ml-cheatsheet
Source: ml-cheatsheet
Intuitively speaking, the above formula denotes the small change that happens in J w.r.t the θj parameter and how it affects the initial value of θj. But look carefully, you have a partial derivative here to deal with. The whole derivation process is out of the scope of this tutorial.
Just note that for a single training example, this gives the update rule:
 Source: ml-cheatsheet
Source: ml-cheatsheet
The rule is called the LMS update rule (LMS stands for “least mean squares”) and is also known as the Widrow-Hoff learning rule.
Let's summarize a few things in the context of OLS.
"The Ordinary Least Squares procedure seeks to minimize the sum of the squared residuals. This means that given a regression line through the data we calculate the distance from each data point to the regression line, square it, and sum all of the squared errors together. This is the quantity that ordinary least squares seeks to minimize." - Jason Brownlee
In the previous training rule, you already got the notion of how gradient descent can be incorporated in this context. Essentially, gradient descent is a process of optimizing the values of the coefficients by iteratively minimizing the error of the model on your training data.
More briefly speaking, it works by starting with random values for each coefficient. The sum of the squared errors is calculated for each pair of input and output values. A learning rate is used as a scale factor, and the coefficients are updated in the direction towards minimizing the error. The process is repeated until a minimum sum squared error is achieved or no further improvement is possible.
The term α (learning rate) is very important here since it determines the size of the improvement step to take on each iteration of the procedure.
Now there are commonly two variants of gradient descent:
That is all for gradient descent for this tutorial. Now, you take a look at another way of optimizing a linear regression model, i.e. Regularization.
DataCamp already has a good introductory article on Regularization. You might want to check that out before proceeding with this one.
Generally, regularization methods work by penalizing the coefficients of features having extremely large values and thereby try to reduce the error. It not only results in an enhanced error rate but also, it reduces the model complexity. This is particularly very useful when you are dealing with a dataset that has a large number of features, and your baseline model is not able to distinguish between the importance of the features (not all features in a dataset are equally important, right?).
There are two variants of regularization procedures for linear regression are:
Lasso Regression: adds a penalty term which is equivalent to the absolute value of the magnitude of the coefficients (also called L1 regularization). The penalty terms look like: 
where,
Ridge Regression: adds a penalty term which is equivalent to the square of the magnitude of coefficients (also called L2 regularization). The penalty terms look like: 
Is it not? You already saw how gracefully linear regression introduces some of the most critical concepts of Machine Learning such as cost functions, optimization, variable relationships and what not? All these things are vital even if you are constructing a neural network. The applicability may differ in some places, but the overall concepts remain precisely the same. So, without understanding these fundamental things, you will never be able to reason why your neural net is not performing well.
Moreover, a simple concept of deriving the relationships among variables gave birth to so many concepts and most importantly it created a whole new family of algorithms - Generalized Linear Models. So for aspiring Data Science/Machine Learning/Artificial Intelligence practitioner, this algorithm is something which cannot be neglected. You already have understood that by now!
No, you will implement a simple linear regression in Python for yourself now. It should be fun!
For this case study first, you will use the Statsmodel library for Python. It is a very popular library which provides classes and functions for the estimation of many different statistical models, as well as for conducting statistical tests, and statistical data exploration. For the data, you will use the famous Boston House dataset. The mighty scikit-learn comes with this dataset, so you don't need to download it separately.
Let's start the case study by importing the statsmodels library and your dataset:
import statsmodels.api as sm
from sklearn import datasets
data = datasets.load_boston()
Scikit-learn provides a handy description of the dataset, and it can be easily viewed by:
print (data.DESCR)
Boston House Prices dataset
===========================
Notes
------
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive
:Median Value (attribute 14) is usually the target
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
http://archive.ics.uci.edu/ml/datasets/Housing
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
**References**
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan, R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
- many more! (see http://archive.ics.uci.edu/ml/datasets/Housing)
Now, before applying linear regression, you will have to prepare the data and segregate the features and the label of the dataset. MEDV (median home value) is the label in this case. You can access the features of the dataset using feature_names attribute.
A bit of pandas knowledge will come in handy here. This cheat sheet is a must-see if you are looking for ways to refresh basic pandas concepts.
# Pandas and NumPy import
import numpy as np
import pandas as pd
# Set the features
df = pd.DataFrame(data.data, columns=data.feature_names)
# Set the target
target = pd.DataFrame(data.target, columns=["MEDV"])
At this point, you need to consider a few important things about linear regression before applying it to the data. You could have studied this earlier in this tutorial, but studying these factors at this particular point of time will help you get the real feel.
Let's do some hands-on now. To keep things simple you will just take RM — the average number of rooms feature for now. Note that Statsmodels does not add a constant term (recall the factor θ0) by default. Let’s see it first without the constant term in your regression model:
X = df["RM"]
y = target["MEDV"]
# Fit and make the predictions by the model
model = sm.OLS(y, X).fit()
predictions = model.predict(X)
# Print out the statistics
model.summary()
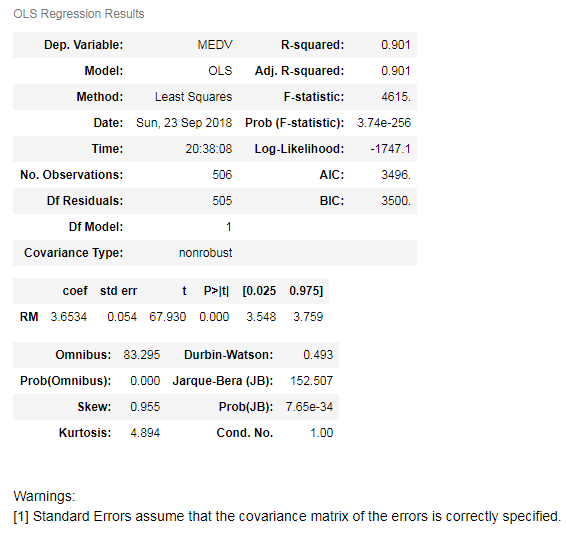
What is this output! It is way too big to understand when you are seeing it for the first time. Let's go through the most critical points step by step:
OLS method to train your linear regression model. RM variable increases by 1, the predicted value of MEDV increases by 3.634. These are the most important points you should take care of for the time being (and you can ignore the warning as well).
A constant term can easily be added to the linear regression model. You can do it by X = sm.add_constant(X) (X is the name of the dataframe containing the input (independent variables).
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
predictions = model.predict(X)
model.summary()
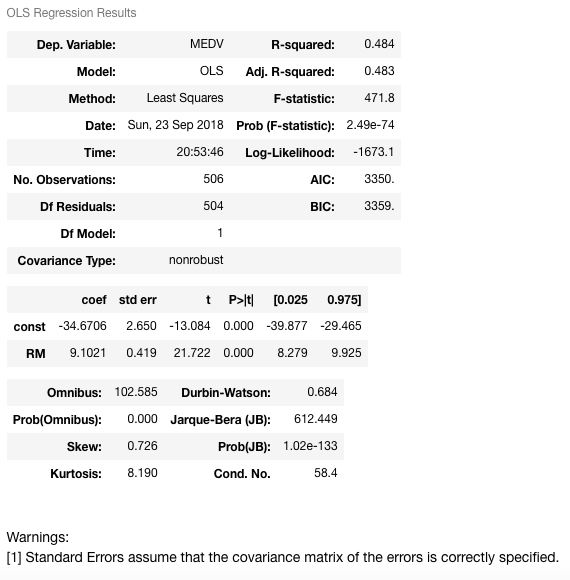
It can be clearly seen that the addition of the constant term has a direct effect on the coefficient term. Without the constant term, your model was passing through the origin, but now you have a y-intercept at -34.67. Now the slope of the RM predictor is also changed from 3.634 to 9.1021 (coef of RM).
Now you will fit a regression model with more than one variable — you will add LSTAT (percentage of lower status of the population) along with the RM variable. The model training (fitting) procedure remains the exact same as previous:
X = df[["RM", "LSTAT"]]
y = target["MEDV"]
model = sm.OLS(y, X).fit()
predictions = model.predict(X)
model.summary()
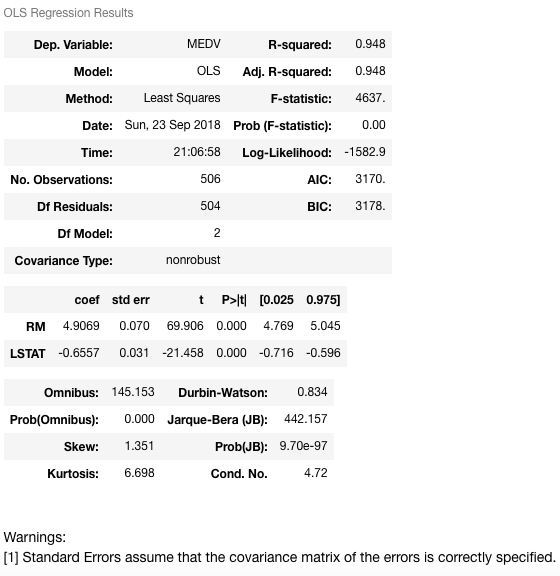
Let's interpret this one now:
This model has a much higher R-squared value — 0.948, which essentially means that this model captures 94.8% of the variance in the dependent variable. Now, let's try to figure out the relationship between the two variables RM and LSTAT and median house value. As RM increases by 1, MEDV will increase by 4.9069, and when LSTAT increases by 1, MEDV will decrease by 0.6557. This indicates that RM and LSTAT are statistically significant in predicting (or estimating) the median house value.
You can interpret this relationship in plain English as well:
Makes more sense now! Isn't it?
This was the example of both single and multiple linear regression in Statsmodels. Your homework will be to investigate and interpret the results with the further features.
Next, let's see how linear regression can be implemented using your very own scikit-learn. You already have the dataset imported, but you will have to import the linear_model class.
from sklearn import linear_model
X = df
y = target["MEDV"]
lm = linear_model.LinearRegression()
model = lm.fit(X,y)
The model training is completed. This sklearn implementation also uses OLS. Let's make some predictions of MEDV values for the first five samples.
predictions = lm.predict(X)
print(predictions[0:5])
[30.00821269 25.0298606 30.5702317 28.60814055 27.94288232]
If you want to know some more details (such as the R-squared, coefficients, etc.) of your model, you can easily do so.
lm.score(X,y)
0.7406077428649427
lm.coef_
array([-1.07170557e-01, 4.63952195e-02, 2.08602395e-02, 2.68856140e+00,
-1.77957587e+01, 3.80475246e+00, 7.51061703e-04, -1.47575880e+00,
3.05655038e-01, -1.23293463e-02, -9.53463555e-01, 9.39251272e-03,
-5.25466633e-01])
Beautiful! You have made it to the end. Covering one of the simplest and the most fundamental algorithms was not that easy, but you did it pretty well. You not only got familiarized with simple linear regression but also studied many fundamental aspects, terms, factors of machine learning. You did an in-depth case study in Python as well.
This tutorial can also be treated as a motivation for you to implement Linear Regression from scratch. Following are the brief steps if anyone wants to do it for real:
Following are some references that were used in order to prepare this tutorial:
If you would like to learn more about linear classifiers, take DataCamp's Linear Classifiers in Python course.
Check out our Normal Equation for Linear Regression Tutorial.
Python courses
Course
Course
Course
Tutorial
Kurtis Pykes
Tutorial
Avinash Navlani
Tutorial
Eladio Montero Porras
Tutorial
Hadrien Jean
Tutorial
DataCamp Team
code-along
George Boorman

