
Course
Data Manipulation in SQL
4 hr
324.1K
Choosing to focus on the NOT IN operator stems from its utility in data exclusion scenarios. Whether you're cleaning data, preparing reports, or conducting complex analyses, understanding how to effectively exclude specific data points is invaluable. This operator offers a straightforward syntax but comes with nuances that can affect performance and accuracy.
Our decision to explore NOT IN in depth is to provide a comprehensive understanding that equips you with the knowledge to use it effectively in your SQL queries.
The NOT IN operator is used within a WHERE clause to exclude rows where a specified column's value matches any in a given list of values. Its basic syntax is as follows:
SELECT column_names
FROM table_name
WHERE column_name NOT IN (value1, value2, ...);This syntax highlights the operator's role in filtering data—a critical step in data analysis and database management.
Consider a database containing a table of customer information. If you wish to select customers who are not from specific cities, NOT IN becomes an invaluable tool, allowing you to exclude those cities from your result set easily.
Let's say we have a table named Customers with columns CustomerID, CustomerName, and City. To find customers who are not located in 'New York' or 'Los Angeles', the query would be:
|
CustomerlD |
CustomerName |
City |
|
1 |
John Doe |
New York |
|
2 |
Jane Smith |
Los Angeles |
|
3 |
Emily Jones |
Chicago |
|
4 |
Chris Brown |
Miami |
|
5 |
Alex Johnson |
San Francisco |
|
6 |
Jessica White |
New York |
Customers Table
SELECT CustomerName, City
FROM Customers
WHERE City NOT IN ('New York', 'Los Angeles');|
CustomerName |
City |
|
Emily Jones |
Chicago |
|
Chris Brown |
Miami |
|
Alex Johnson |
San Francisco |
NOT IN can also work with subqueries. For example, to find products that have not been ordered:
|
ProductID |
ProductName |
|
1 |
Apple |
|
2 |
Banana |
|
3 |
Orange |
|
4 |
Pear |
|
5 |
Grape |
Table Products
|
OrderID |
ProductID |
|
101 |
2 |
|
102 |
4 |
|
103 |
2 |
|
104 |
3 |
Order Table
SELECT ProductName
FROM Products
WHERE ProductID NOT IN (
SELECT ProductID
FROM Orders
);
|
ProductName |
|
Apple |
|
Grape |
A common issue with NOT IN arises when the list of values contains NULL. Because NULL represents an unknown value, any comparison with NULL using NOT IN will not return any rows, even if there are rows that should logically be excluded from the list.
To circumvent this, ensure that the list of values does not contain NULL or use an alternative approach such as NOT EXISTS.
Example:
Suppose we have a table Orders with a column CustomerID, some of which are NULL to represent guest orders. If you run a query to find orders not made by certain customers, including NULL in the list would cause no results to be returned.
|
OrderID |
CustomerID |
|
101 |
3 |
|
102 |
4 |
|
103 |
2 |
|
104 |
|
|
106 |
1 |
Orders Table
-- Assume we want to exclude CustomerID 1, 2, and unknown (NULL) customers
SELECT OrderID
FROM Orders
WHERE CustomerID NOT IN (1, 2, NULL);This query would return no rows, which is likely not the intended outcome.
Solution: To ensure accurate results, avoid including NULL in the list for NOT IN. Alternatively, use a combination of NOT IN for known values and IS NOT NULL for handling NULLs effectively.
SELECT OrderID
FROM Orders
WHERE CustomerID NOT IN (1, 2) AND CustomerID IS NOT NULL;|
OrderID |
|
101 |
|
102 |
For large datasets or subqueries, NOT IN can be less efficient than alternatives like NOT EXISTS or LEFT JOIN /IS NULL. The inefficiency stems from how NOT IN compares each row in the table to each value in the list, which can lead to slow performance on large datasets.
NOT EXISTS is often recommended over NOT IN when dealing with subqueries that might return NULL values. It is generally more efficient because it stops as soon as it finds a match.
Example:
To find products that have not been ordered, using NOT EXISTS:
SELECT ProductName
FROM Products p
WHERE NOT EXISTS (
SELECT 1
FROM Orders o
WHERE o.ProductID = p.ProductID
);
|
ProductName |
|
Apple |
|
Grape |
This query checks for the non-existence of a product in the orders table, which can be more efficient than comparing against a potentially large list of IDs with NOT IN.
Another efficient alternative for excluding rows is to use a LEFT JOIN combined with a WHERE ... IS NULL clause. This method is particularly effective for large datasets.
Example:
To achieve the same goal of finding products that have not been ordered:
SELECT p.ProductName
FROM Products p
LEFT JOIN Orders o ON p.ProductID = o.ProductID
WHERE o.ProductID IS NULL;|
ProductName |
|
Apple |
|
Grape |
This method leverages the LEFT JOIN to include all products and any matching orders, then filters out those products that have orders using WHERE o.ProductID IS NULL, effectively excluding them.
NULL values: Ensure the list used in NOT IN does not contain NULL values to avoid unexpected results.NOT EXISTS might offer better performance.NOT IN clause are indexed, if possible, to improve query performance.In data analysis, the "Not IN" SQL command is commonly used to retrieve specific data. In this section, we will work with a bookstore database that keeps track of its inventory (books available in the store) and sales (books sold). Our goal is to identify which books have never been sold.
We have two tables:
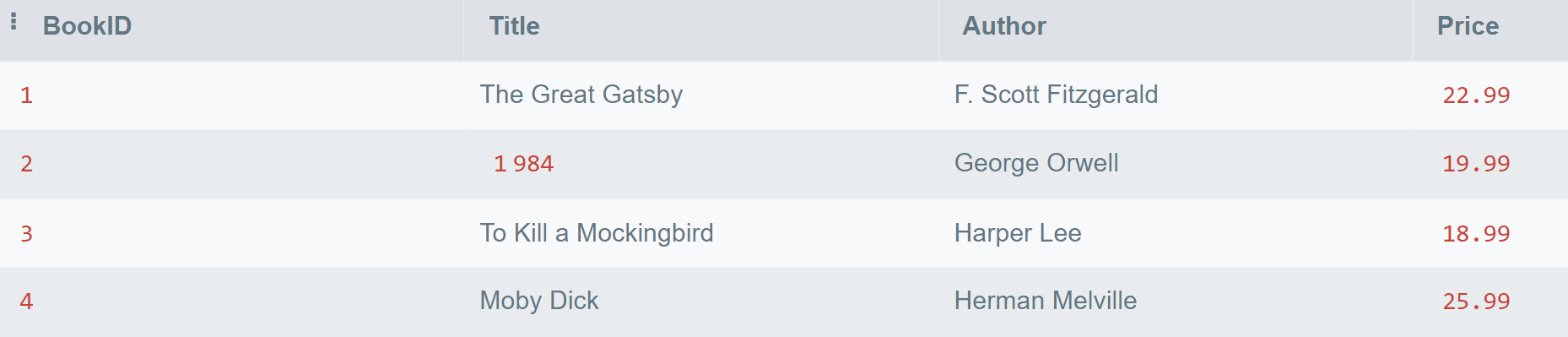
Inventory Table

Sales Table
Now, we want to find out which books have never been sold.
SELECT Title, Author
FROM Inventory
WHERE BookID NOT IN (
SELECT BookID
FROM Sales
);

Next, we want to identify books in our inventory that have not been sold in the last month, assuming today is February 7, 2024. This involves checking the SaleDate in the Sales table against our current date.
SELECT Title, Author
FROM Inventory
WHERE BookID NOT IN (
SELECT BookID
FROM Sales
WHERE SaleDate >= date('now', '-1 month')
);

The NOT IN operator is a versatile tool in SQL for excluding specific values from your query results. By understanding its syntax, practical applications, and potential pitfalls, you can effectively use this operator in your data manipulation tasks.
Remember to consider NULL values and dataset size to optimize your queries' performance and accuracy. As you become more familiar with NOT IN, you'll find it an invaluable addition to your SQL toolkit, enabling more precise and efficient data analysis and management.
You can learn more about NOT IN and NOT EXISTS in our Improving Query Performance in SQL Server course and explore SQL operators and much more in our SQL Basics Cheat Sheet and SQL Fundamentals skill track.
Start Your SQL Learning Journey Today!
Course
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Oluseye Jeremiah
Tutorial
Sayak Paul