
Tracks
Kỹ sư Trợ lý Trí tuệ Nhân tạo (AI) cho Lập trình viên
26 giờ
Khi script Python của bạn kiên nhẫn chờ phản hồi API, truy vấn cơ sở dữ liệu, hoặc thao tác tệp hoàn tất, khoảng thời gian đó thường bị lãng phí. Với lập trình async trong Python, mã của bạn có thể xử lý nhiều tác vụ cùng lúc. Vì vậy, khi một thao tác đang chờ, các thao tác khác vẫn tiếp tục, biến thời gian rỗi thành công việc hữu ích và thường rút ngắn thời gian chờ từ vài phút xuống chỉ còn vài giây.
Trong hướng dẫn này, tôi sẽ dạy bạn những điều cốt lõi về lập trình bất đồng bộ trong Python thông qua các mini-project. Bạn sẽ thấy coroutine, vòng lặp sự kiện và async I/O có thể giúp mã của bạn phản hồi nhanh hơn nhiều như thế nào.
Nếu bạn muốn học cách xây dựng web API bất đồng bộ, hãy xem khóa học về FastAPI.
Trong Python đồng bộ truyền thống, mã của bạn thực thi từng dòng một. Ví dụ, khi bạn gọi một API, chương trình của bạn dừng lại và chờ phản hồi. Nếu mất hai giây, toàn bộ chương trình ngồi chờ hai giây. Lập trình bất đồng bộ cho phép mã của bạn khởi tạo một lệnh gọi API rồi tiếp tục làm việc khác.
Khi phản hồi đến, mã của bạn tiếp tục từ chỗ tạm dừng. Thay vì chờ từng thao tác hoàn tất, bạn có thể chạy nhiều thao tác cùng lúc. Điều này đặc biệt quan trọng khi mã của bạn phải chờ các hệ thống bên ngoài như cơ sở dữ liệu, API hoặc hệ thống tệp phản hồi.
Để làm được điều đó, hệ thống async của Python dùng một vài khái niệm cốt lõi:
Coroutine: Hàm được định nghĩa với async def thay vì def. Chúng có thể tạm dừng và tiếp tục thực thi, rất phù hợp cho các thao tác phải chờ đợi.
await: Từ khóa này bảo Python: "tạm dừng coroutine này cho đến khi thao tác hoàn tất, nhưng trong lúc đó hãy cho phép mã khác chạy".
Vòng lặp sự kiện (event loop): Động cơ quản lý tất cả coroutine của bạn, quyết định chạy cái nào và khi nào chuyển đổi giữa chúng.
Task: Coroutine được bọc để chạy đồng thời. Bạn tạo chúng với asyncio.create_task() để chạy nhiều thao tác cùng lúc.
Để tránh hiểu nhầm về những gì async có thể (và không thể) làm, hãy ghi nhớ:
Async hoạt động tốt nhất với công việc I/O-bound như yêu cầu HTTP, truy vấn cơ sở dữ liệu và thao tác tệp, nơi mã của bạn chờ hệ thống bên ngoài.
Async không giúp ích cho công việc CPU-bound như tính toán phức tạp hoặc xử lý dữ liệu, nơi mã của bạn bận tính toán thay vì chờ đợi.
Cách tốt nhất để thấm nhuần các khái niệm này là viết mã async thực sự. Ở phần tiếp theo, bạn sẽ tạo hàm async đầu tiên và thấy rõ coroutine và vòng lặp sự kiện phối hợp với nhau như thế nào.
Trước khi viết mã async, hãy xem một hàm đồng bộ thông thường chờ trước khi làm gì đó:
import time
def greet_after_delay():
print("Starting...")
time.sleep(2) # Blocks for 2 seconds
print("Hello!")
greet_after_delay()Starting...
Hello!Hàm này hoạt động, nhưng time.sleep(2) chặn toàn bộ chương trình. Không có gì khác có thể chạy trong hai giây đó.
Dưới đây là phiên bản async:
import asyncio
async def greet_after_delay():
print("Starting...")
await asyncio.sleep(2) # Pauses, but doesn't block
print("Hello!")
asyncio.run(greet_after_delay())Starting...
Hello!Kết quả trông giống hệt nhau, nhưng bên trong thì khác. Ba thay đổi đã biến nó thành async:
async def thay vì def để khai báo coroutine.
await asyncio.sleep(2) thay vì time.sleep(2) để tạm dừng mà không chặn.
asyncio.run() khởi động vòng lặp sự kiện và chạy coroutine.
Lưu ý rằng asyncio.sleep() tự nó là một hàm async, đó là lý do cần await. Đây là quy tắc then chốt: mọi hàm async phải được gọi kèm await. Dù là hàm dựng sẵn như asyncio.sleep() hay do bạn viết, quên await đồng nghĩa nó sẽ không thực sự chạy.
Lúc này, phiên bản async chưa có vẻ nhanh hơn. Vì chúng ta chỉ có một tác vụ. Lợi ích thực sự xuất hiện khi bạn chạy nhiều coroutine cùng lúc, điều mà chúng ta sẽ đề cập ở phần tiếp theo.
Một điều quan trọng khác: bạn không thể gọi trực tiếp một hàm async như hàm thường. Hãy thử nhé:
result = greet_after_delay()
print(result)
print(type(result))<coroutine object greet_after_delay at 0x...>
<class 'coroutine'>Gọi greet_after_delay() trả về một đối tượng coroutine, không phải kết quả. Hàm chưa thực sự chạy. Bạn cần asyncio.run() hoặc await để thực thi nó bên trong một hàm khác.
Vòng lặp sự kiện là động cơ đứng sau lập trình async. Nó quản lý coroutine của bạn và quyết định chạy cái gì, khi nào. Dưới đây là các bước khi bạn chạy hàm async greet_after_delay():
asyncio.run() tạo một vòng lặp sự kiện.
Vòng lặp sự kiện khởi chạy greet_after_delay().
In "Starting...".
Đến await asyncio.sleep(2) → coroutine tạm dừng.
Vòng lặp sự kiện kiểm tra: "Có tác vụ nào khác để chạy không?" (chưa có lúc này).
Sau 2 giây, sleep hoàn tất.
Vòng lặp sự kiện tiếp tục greet_after_delay().
In "Hello!".
Hàm kết thúc → vòng lặp sự kiện thoát.
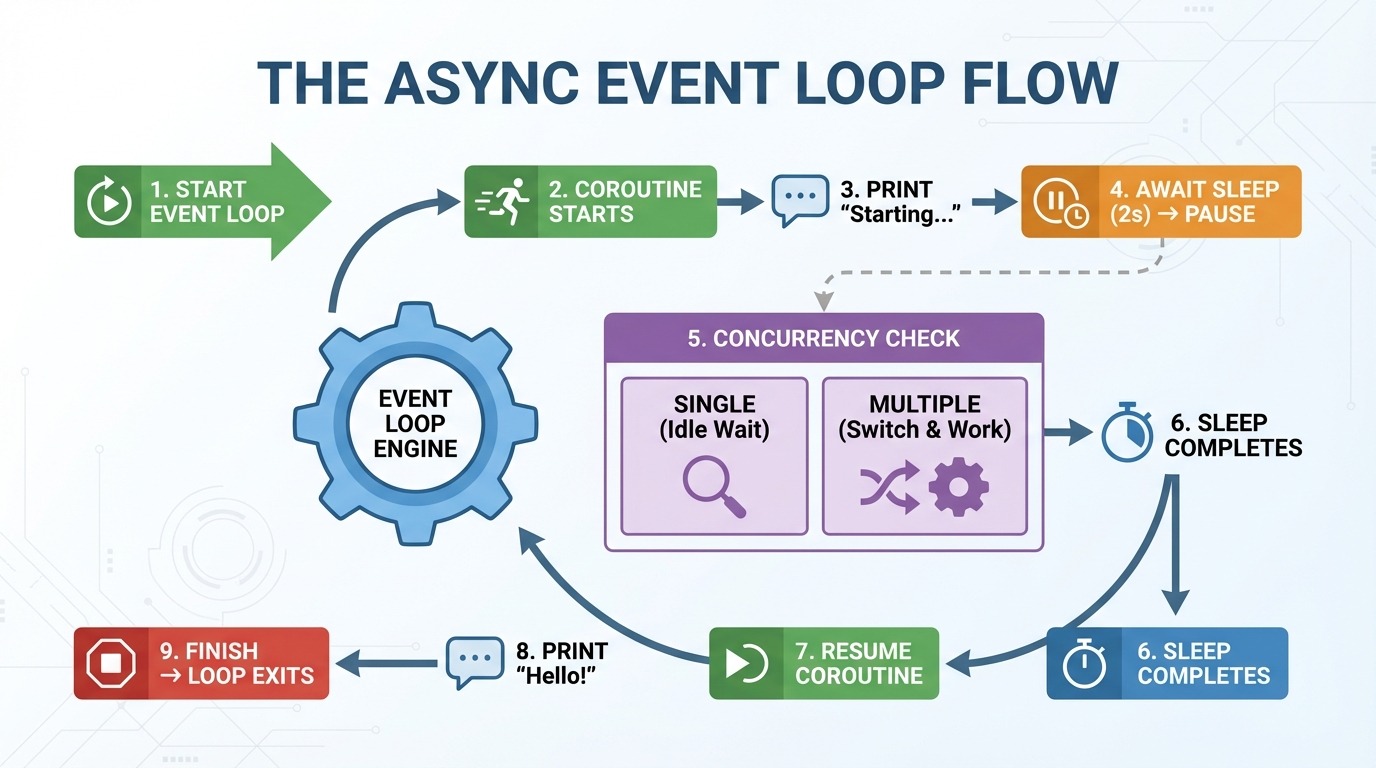
Bước 5 là nơi async trở nên thú vị. Với một coroutine, không còn việc gì khác để làm. Nhưng khi bạn có nhiều coroutine, vòng lặp sự kiện sẽ chuyển sang công việc khác trong khi một coroutine chờ. Thay vì ngồi yên trong hai giây sleep, nó có thể chạy mã khác.
Hãy nghĩ về vòng lặp sự kiện như người điều phối giao thông. Nó không làm từng chiếc xe nhanh hơn. Nó giữ dòng xe di chuyển bằng cách cho xe khác đi khi một xe đang dừng.
Một lỗi người mới hay gặp là quên await khi gọi một coroutine bên trong hàm async khác:
import asyncio
async def get_message():
await asyncio.sleep(1)
return "Hello!"
async def main():
message = get_message() # Missing await!
print(message)
asyncio.run(main())<coroutine object get_message at 0x...>
RuntimeWarning: coroutine 'get_message' was never awaitedKhông có await, bạn nhận đối tượng coroutine thay vì giá trị trả về. Python cũng cảnh báo rằng coroutine chưa từng được await.
Cách sửa rất đơn giản:
async def main():
message = await get_message() # Added await
print(message)
asyncio.run(main())Hello!Khi bạn thấy RuntimeWarning về coroutine chưa được await, hãy kiểm tra rằng bạn đã dùng await cho mọi lần gọi hàm async.
Ở phần trước, chúng ta đã chuyển một hàm đồng bộ sang async. Nhưng nó không nhanh hơn. Vì chúng ta chỉ chạy một coroutine. Sức mạnh thực sự của async xuất hiện khi bạn chạy nhiều coroutine cùng lúc.
Bạn có thể nghĩ gọi nhiều hàm async sẽ tự động chạy đồng thời. Nhưng xem điều gì xảy ra khi chúng ta gọi greet_after_delay() ba lần:
import asyncio
import time
async def greet_after_delay(name):
print(f"Starting {name}...")
await asyncio.sleep(2)
print(f"Hello, {name}!")
async def main():
start = time.perf_counter()
await greet_after_delay("Alice")
await greet_after_delay("Bob")
await greet_after_delay("Charlie")
elapsed = time.perf_counter() - start
print(f"Total time: {elapsed:.2f} seconds")
asyncio.run(main())Starting Alice...
Hello, Alice!
Starting Bob...
Hello, Bob!
Starting Charlie...
Hello, Charlie!
Total time: 6.01 secondsSáu giây cho ba tác vụ mỗi tác vụ hai giây. Mỗi await chờ coroutine của nó hoàn tất trước khi chuyển sang dòng tiếp theo. Mã là async nhưng chạy tuần tự.
Để chạy các coroutine cùng lúc, dùng asyncio.gather(). Nó nhận nhiều coroutine và chạy đồng thời:
async def main():
start = time.perf_counter()
await asyncio.gather(
greet_after_delay("Alice"),
greet_after_delay("Bob"),
greet_after_delay("Charlie"),
)
elapsed = time.perf_counter() - start
print(f"Total time: {elapsed:.2f} seconds")
asyncio.run(main())Starting Alice...
Starting Bob...
Starting Charlie...
Hello, Alice!
Hello, Bob!
Hello, Charlie!
Total time: 2.00 secondsHai giây thay vì sáu. Cả ba coroutine bắt đầu ngay lập tức, sleep đồng thời và kết thúc cùng nhau. Chỉ một thay đổi đã tăng tốc gấp 3 lần.
Lưu ý thứ tự kết quả: cả ba thông điệp "Starting..." in ra trước bất kỳ thông điệp "Hello..." nào. Điều này cho thấy tất cả coroutine chạy trong cùng một khoảng hai giây, thay vì chờ nhau.
asyncio.gather() trả về danh sách kết quả theo đúng thứ tự bạn truyền coroutine vào. Nếu coroutine trả về giá trị, bạn có thể nhận chúng:
async def fetch_number(n):
await asyncio.sleep(1)
return n * 10
async def main():
results = await asyncio.gather(
fetch_number(1),
fetch_number(2),
fetch_number(3),
)
print(results)
asyncio.run(main())[10, 20, 30]Kết quả trả về theo thứ tự [10, 20, 30], khớp với thứ tự coroutine truyền vào gather().
Đến giờ, chúng ta dùng asyncio.sleep() để mô phỏng độ trễ. Giờ hãy thực hiện các yêu cầu HTTP thật. Bạn có thể nghĩ đến thư viện requests, nhưng nó không phù hợp ở đây. requests là đồng bộ và chặn vòng lặp sự kiện, làm mất ý nghĩa của async.
Thay vào đó, dùng aiohttp, một HTTP client async được xây dựng cho mục đích này.
Cách fetch một URL với aiohttp:
import aiohttp
import asyncio
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
html = await fetch("https://example.com")
print(f"Fetched {len(html)} characters")
asyncio.run(main())Fetched 513 charactersLưu ý hai khối async with lồng nhau. Mỗi khối quản lý một tài nguyên khác nhau, và hiểu vai trò của chúng là chìa khóa để dùng aiohttp đúng cách.
Dưới đây là các bước khi bạn gửi yêu cầu với aiohttp:
aiohttp.ClientSession() tạo một pool kết nối (ban đầu rỗng).
session.get(url) kiểm tra pool: "Có kết nối mở nào tới host này (máy chủ website) không?"
Nếu chưa có, tạo một kết nối TCP mới (giao thức cơ bản để truyền dữ liệu qua internet) và một bắt tay SSL (thiết lập mã hóa cho HTTPS).
Gửi yêu cầu HTTP và chờ header phản hồi.
Đối tượng phản hồi giữ kết nối.
await response.text() đọc phần thân dữ liệu từ mạng.
Thoát khỏi async with bên trong: Kết nối được trả về pool (vẫn mở!).
Yêu cầu tiếp theo tới cùng host sẽ tái sử dụng kết nối trong pool (bỏ qua bước 3).
Thoát khỏi async with bên ngoài: Tất cả kết nối trong pool được đóng.
Bước 7 và 8 là mấu chốt. Pool kết nối giữ kết nối sống giữa các yêu cầu. Khi bạn gửi yêu cầu khác tới cùng host, nó bỏ qua hoàn toàn bắt tay TCP và SSL.
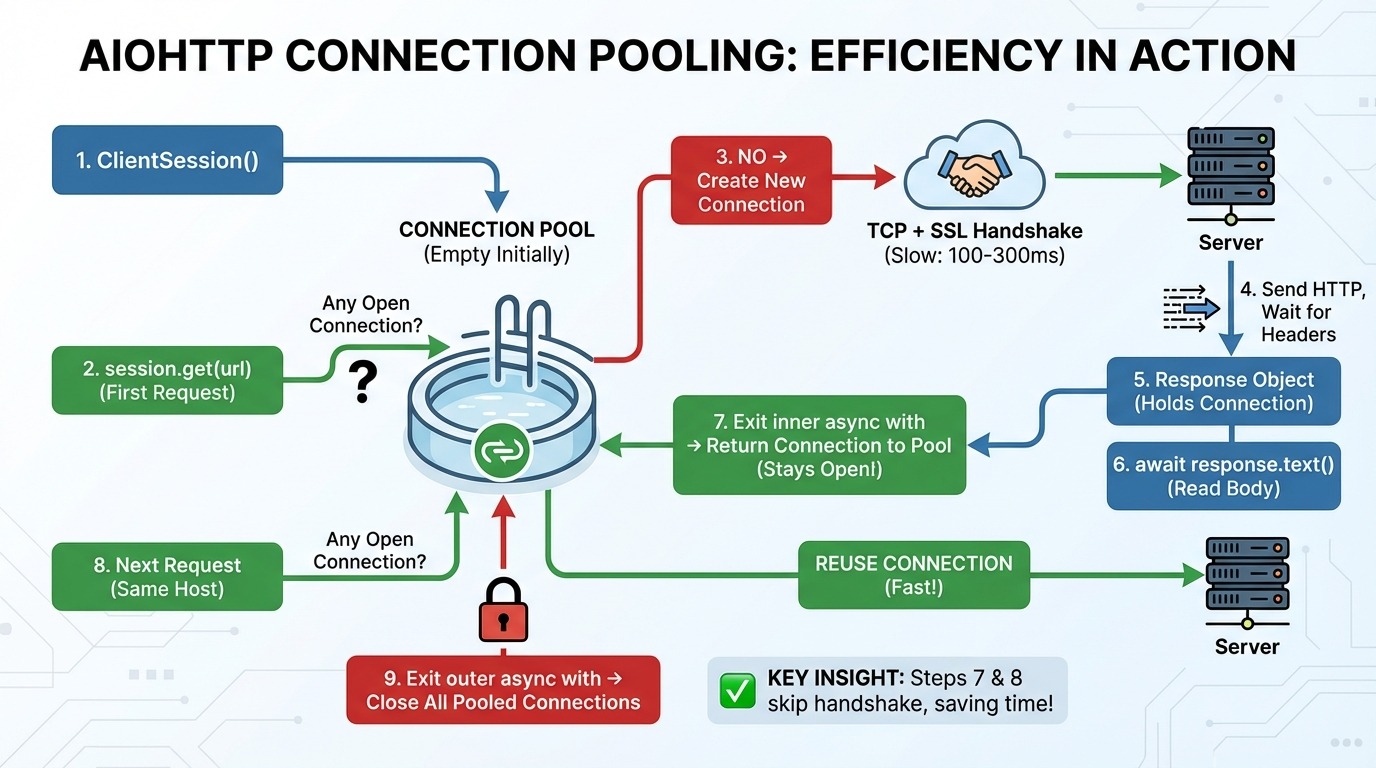
Điều này quan trọng vì thiết lập kết nối mới là chậm. Bắt tay TCP mất một lần khứ hồi tới máy chủ. Bắt tay SSL mất thêm hai lần nữa. Tùy độ trễ, đó là 100–300ms trước khi bạn gửi byte dữ liệu đầu tiên.
Giờ bạn có thể thấy vì sao tạo session mới cho mỗi yêu cầu là vấn đề:
# Wrong: new session for each request
async def fetch_bad(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 10
results = await asyncio.gather(*[fetch_bad(url) for url in urls])Mỗi lần gọi fetch_bad() tạo một session mới với pool rỗng. Mỗi yêu cầu phải trả toàn bộ chi phí bắt tay, dù tất cả đều đến cùng một host.
Cách sửa là tạo một session và truyền nó vào hàm fetch của bạn:
# Right: reuse a single session
async def fetch_good(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 10
async with aiohttp.ClientSession() as session:
results = await asyncio.gather(*[fetch_good(session, url) for url in urls])Với một session dùng chung, yêu cầu đầu tiên thiết lập kết nối, và chín yêu cầu còn lại tái sử dụng nó. Một lần bắt tay thay vì mười.
Hãy áp dụng với API Hacker News. API này rất phù hợp để minh họa hành vi bất đồng bộ vì việc lấy bài viết cần nhiều yêu cầu. Nếu bạn mới làm việc với REST API trong Python, hãy xem Python APIs: A Guide to Building and Using APIs để nắm các khái niệm nền tảng.
Cấu trúc API Hacker News:
https://hacker-news.firebaseio.com/v0/topstories.json trả về danh sách ID bài viết (chỉ là các con số)
https://hacker-news.firebaseio.com/v0/item/{id}.json trả về chi tiết cho một bài viết
Để lấy 10 bài, bạn cần 11 yêu cầu: một để lấy danh sách ID, sau đó mỗi bài một yêu cầu. Đây chính là nơi lập trình async tỏa sáng.
Đầu tiên, hãy xem API trả về gì khi thử lấy bài đầu tiên:
import aiohttp
import asyncio
HN_API = "https://hacker-news.firebaseio.com/v0"
async def main():
async with aiohttp.ClientSession() as session:
# Get top story IDs
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
print(f"Found {len(story_ids)} stories")
print(f"First 5 IDs: {story_ids[:5]}")
# Fetch first story details
first_id = story_ids[0]
async with session.get(f"{HN_API}/item/{first_id}.json") as response:
story = await response.json()
print(f"\nStory structure:")
for key, value in story.items():
print(f" {key}: {repr(value)[:50]}")
asyncio.run(main())Found 500 stories
First 5 IDs: [46051449, 46055298, 46021577, 46053566, 45984864]
Story structure:
by: 'mikeayles'
descendants: 22
id: 46051449
kids: [46054027, 46053889, 46053275, 46053515, 46053002,
score: 217
text: 'I got DOOM running in KiCad by rendering it with
time: 1764108815
title: 'Show HN: KiDoom – Running DOOM on PCB Traces'
type: 'story'
url: 'https://www.mikeayles.com/#kidoom'API trả về 500 ID bài viết, và mỗi bài có các trường như title, url, score, và by (tác giả).
Giờ hãy lấy 10 bài theo cách tuần tự:
import aiohttp
import asyncio
import time
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
start = time.perf_counter()
stories = []
for story_id in story_ids[:10]:
story = await fetch_story(session, story_id)
stories.append(story)
elapsed = time.perf_counter() - start
print(f"Sequential: Fetched {len(stories)} stories in {elapsed:.2f} seconds")
asyncio.run(main())Sequential: Fetched 10 stories in 2.41 secondsGiờ hãy lấy cùng những bài đó theo cách đồng thời:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
start = time.perf_counter()
tasks = [fetch_story(session, story_id) for story_id in story_ids[:10]]
stories = await asyncio.gather(*tasks)
elapsed = time.perf_counter() - start
print(f"Concurrent: Fetched {len(stories)} stories in {elapsed:.2f} seconds")
print("\nTop 3 stories:")
for story in stories[:3]:
print(f" - {story.get('title', 'No title')}")
asyncio.run(main())Concurrent: Fetched 10 stories in 0.69 seconds
Top 3 stories:
- Show HN: KiDoom – Running DOOM on PCB Traces
- AWS is 10x slower than a dedicated server for the same price [video]
- Surprisingly, Emacs on Android is pretty goodPhiên bản đồng thời nhanh hơn 3,5 lần. Thay vì chờ từng yêu cầu hoàn tất rồi mới bắt đầu yêu cầu kế tiếp, cả 10 yêu cầu chạy cùng lúc. Đây là nơi lập trình async phát huy hiệu quả với I/O mạng thực tế.
Khi lấy dữ liệu đồng thời, nhiều điều có thể xảy ra. Bạn có thể làm quá tải máy chủ với quá nhiều yêu cầu. Một số yêu cầu có thể treo mãi. Số khác có thể thất bại ngay. Và khi lỗi xảy ra, bạn cần chiến lược khắc phục.
Phần này sẽ đi qua từng mối quan ngại theo thứ tự xảy ra: kiểm soát số lượng yêu cầu gửi đi, đặt giới hạn thời gian, xử lý lỗi và thử lại khi hợp lý. Nếu bạn cần ôn lại các nền tảng xử lý ngoại lệ trong Python, xem Exception & Error Handling in Python. Chúng ta sẽ dùng thiết lập cơ bản này xuyên suốt:
import aiohttp
import asyncio
import time
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()Ở phần trước, chúng ta bắn 10 yêu cầu cùng lúc. Ổn thôi. Nhưng chuyện gì xảy ra khi bạn cần lấy 500 bài? Hoặc thu thập 10.000 trang?
Hầu hết API đều áp dụng giới hạn. Họ có thể cho phép 10 yêu cầu mỗi giây, hoặc 100 kết nối đồng thời. Vượt quá, bạn sẽ bị chặn, giảm tốc, hoặc cấm. Ngay cả khi API không áp dụng giới hạn, bắn hàng nghìn yêu cầu cùng lúc có thể làm quá tải chính hệ thống của bạn hoặc máy chủ.
Bạn cần cách kiểm soát số yêu cầu "đang bay" tại mọi thời điểm. Đó là nhiệm vụ của semaphore.
Semaphore hoạt động như hệ thống cấp phép. Hãy tưởng tượng bạn có ba giấy phép. Mọi tác vụ muốn gửi yêu cầu phải xin giấy phép trước. Khi xong, nó trả lại giấy phép để yêu cầu mới dùng. Nếu không còn giấy phép, tác vụ sẽ chờ cho đến khi có cái được trả lại.
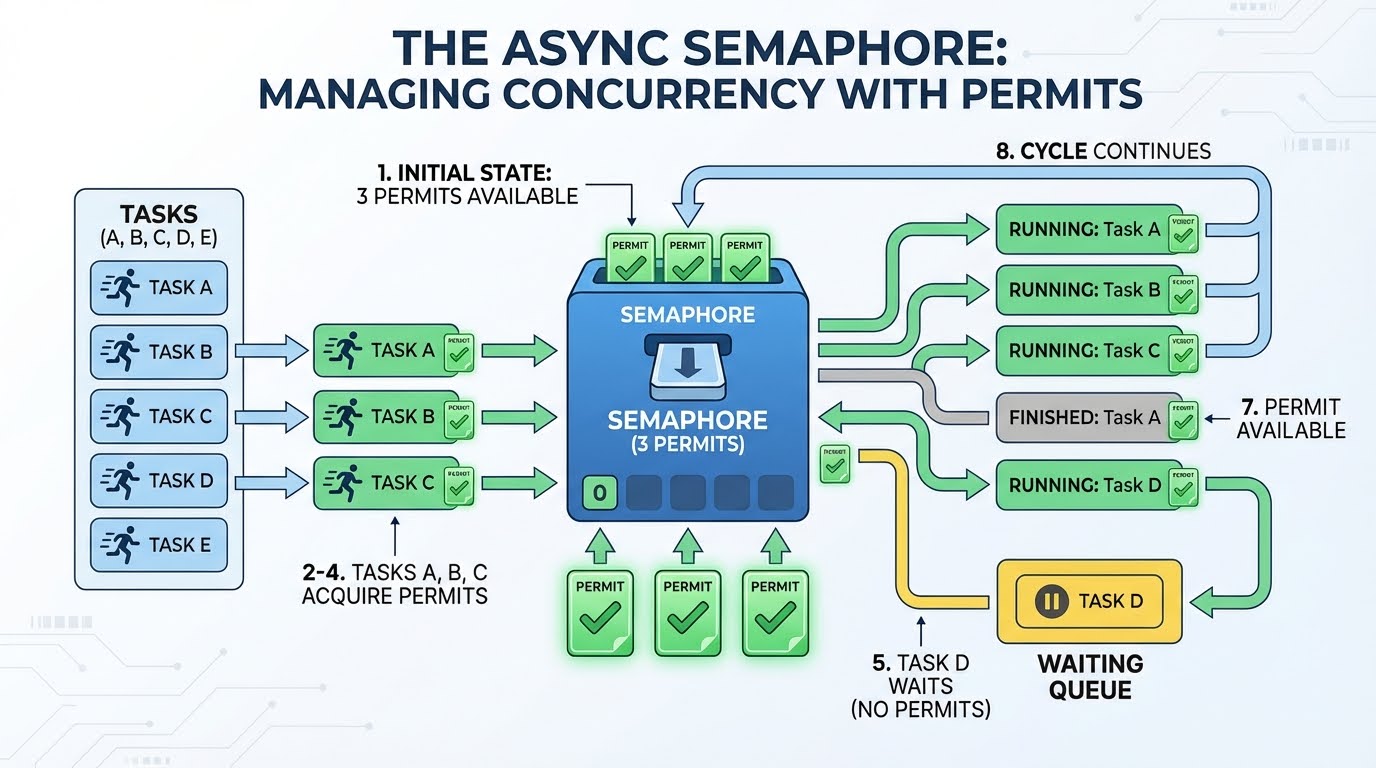
Kịch bản với 3 giấy phép và từ 4 tác vụ trở lên:
Có ba giấy phép sẵn có.
Tác vụ A lấy một giấy phép (còn 2), bắt đầu yêu cầu.
Tác vụ B lấy một giấy phép (còn 1), bắt đầu yêu cầu.
Tác vụ C lấy một giấy phép (còn 0), bắt đầu yêu cầu.
Tác vụ D muốn giấy phép, nhưng không còn — nó chờ.
Tác vụ A xong, trả giấy phép (còn 1).
Tác vụ D lấy giấy phép đó và bắt đầu yêu cầu.
Tiếp tục như vậy cho đến khi mọi tác vụ hoàn tất.
Việc chờ ở bước 5 rất hiệu quả. Tác vụ không quay vòng kiểm tra "đã có giấy phép trống chưa?". Nó tạm dừng và cho phép mã khác chạy. Vòng lặp sự kiện chỉ đánh thức nó khi có giấy phép.
Giờ hãy xem mã. Trong asyncio, bạn tạo semaphore với asyncio.Semaphore(n), trong đó n là số giấy phép. Để dùng, bọc mã trong async with semaphore:. Điều này sẽ lấy giấy phép khi vào khối và tự động trả khi thoát:
async def fetch_story_limited(session, story_id, semaphore):
async with semaphore: # Acquire permit (or wait if none available)
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
# Permit automatically released hereSo sánh việc lấy 30 bài có và không có semaphore:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = (await response.json())[:30]
# Without rate limiting: all 30 at once
start = time.perf_counter()
await asyncio.gather(*[fetch_story(session, sid) for sid in story_ids])
print(f"No limit: {time.perf_counter() - start:.2f}s (30 concurrent)")
# With Semaphore(5): max 5 at a time
semaphore = asyncio.Semaphore(5)
start = time.perf_counter()
await asyncio.gather(*[fetch_story_limited(session, sid, semaphore) for sid in story_ids])
print(f"Semaphore(5): {time.perf_counter() - start:.2f}s (5 concurrent)")
asyncio.run(main())No limit: 0.62s (30 concurrent)
Semaphore(5): 1.50s (5 concurrent)Bản dùng semaphore chậm hơn vì xử lý theo lô năm yêu cầu một lần. Nhưng đó là sự đánh đổi: bạn hy sinh tốc độ để có hành vi ổn định, thân thiện với máy chủ.
Lưu ý: semaphore giới hạn số yêu cầu đồng thời, không phải số yêu cầu theo đơn vị thời gian. Semaphore(10) nghĩa là "tối đa 10 yêu cầu đang bay cùng lúc", không phải "10 yêu cầu mỗi giây". Nếu bạn cần giới hạn nghiêm ngặt theo thời gian (ví dụ chính xác 10 yêu cầu/giây), bạn có thể kết hợp semaphore với độ trễ giữa các lô, hoặc dùng thư viện như aiolimiter.
Ngay cả khi đã kiểm soát đồng thời, các yêu cầu riêng lẻ vẫn có thể treo. Máy chủ có thể chấp nhận kết nối nhưng không bao giờ phản hồi. Không có timeout, chương trình của bạn sẽ chờ vô hạn.
Hàm asyncio.wait_for() bọc mọi coroutine với một hạn chót. Bạn truyền coroutine và timeout tính bằng giây. Nếu thao tác không hoàn thành kịp, nó phát sinh asyncio.TimeoutError:
async def slow_operation():
print("Starting slow operation...")
await asyncio.sleep(5)
return "Done"
async def main():
try:
result = await asyncio.wait_for(slow_operation(), timeout=2.0)
print(f"Success: {result}")
except asyncio.TimeoutError:
print("Operation timed out after 2 seconds")
asyncio.run(main())Starting slow operation...
Operation timed out after 2 secondsKhi timeout hết hạn, wait_for() hủy coroutine. Bạn có thể bắt TimeoutError và quyết định làm gì: bỏ qua yêu cầu, trả giá trị mặc định, hoặc thử lại.
Với các yêu cầu đồng thời, hãy bọc từng yêu cầu riêng. Dưới đây là một helper trả về dict lỗi thay vì ném lỗi:
async def fetch_story_with_timeout(session, story_id, timeout=5.0):
try:
coro = fetch_story(session, story_id)
return await asyncio.wait_for(coro, timeout=timeout)
except asyncio.TimeoutError:
return {"error": f"Story {story_id} timed out"}Khi một coroutine bị hủy (do timeout hoặc lý do khác), Python phát sinh asyncio.CancelledError bên trong nó. Nếu coroutine của bạn giữ tài nguyên như file handle hoặc kết nối, dùng try/finally để đảm bảo việc dọn dẹp diễn ra ngay cả khi bị hủy:
async def fetch_with_cleanup(session, url):
print("Starting fetch...")
try:
async with session.get(url) as response:
return await response.text()
finally:
print("Cleanup complete") # Runs even on cancellationTimeout xử lý các yêu cầu chậm. Nhưng một số yêu cầu thất bại ngay với lỗi. Hãy xem điều gì xảy ra khi một yêu cầu trong nhóm bị lỗi.
Trước hết, ta cần phiên bản fetch_story() ném ngoại lệ với ID không hợp lệ:
async def fetch_story_strict(session, story_id):
story = await fetch_story(session, story_id)
if story is None:
raise ValueError(f"Story not found: {story_id}")
return storyGiờ hãy lấy bốn bài hợp lệ cộng thêm một ID không hợp lệ:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
ids_to_fetch = story_ids[:4] + [99999999999] # 4 valid + 1 invalid
try:
stories = await asyncio.gather(
*[fetch_story_strict(session, sid) for sid in ids_to_fetch]
)
print(f"Got {len(stories)} stories")
except ValueError as e:
print(f"ERROR: {e}")
asyncio.run(main())ERROR: Story not found: 99999999999Chỉ một ID không hợp lệ khiến ta mất cả bốn kết quả thành công. Mặc định, gather() dùng hành vi fail-fast: một ngoại lệ sẽ hủy mọi thứ và ném lỗi ra ngoài.
Để giữ các kết quả một phần, thêm return_exceptions=True. Điều này thay đổi hành vi của gather(): thay vì ném ngoại lệ, nó trả chúng như các phần tử trong danh sách kết quả cùng với các giá trị thành công:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
ids_to_fetch = story_ids[:4] + [99999999999]
results = await asyncio.gather(
*[fetch_story_strict(session, sid) for sid in ids_to_fetch],
return_exceptions=True # Don't raise, return exceptions in list
)
# Separate successes from failures using isinstance()
stories = [r for r in results if not isinstance(r, Exception)]
errors = [r for r in results if isinstance(r, Exception)]
print(f"Got {len(stories)} stories, {len(errors)} failed")
asyncio.run(main())Got 4 stories, 1 failedPhép kiểm isinstance(result, Exception) cho phép bạn tách kết quả thành công khỏi lỗi. Sau đó bạn có thể xử lý phần thành công và ghi log hoặc thử lại phần thất bại.
Một số lỗi chỉ mang tính tạm thời. Máy chủ có thể quá tải trong chốc lát, hoặc sự cố mạng làm rơi kết nối. Trong các trường hợp này, thử lại là hợp lý.
Nhưng thử lại ngay có thể làm mọi thứ tệ hơn. Nếu máy chủ đang gặp khó, dồn dập thử lại chỉ khiến vấn đề trầm trọng. Backoff lũy tiến giải quyết bằng cách chờ lâu hơn giữa mỗi lần thử.
Mẫu này dùng 2 ** attempt để tính thời gian chờ: lần 0 chờ một giây (2⁰), lần 1 chờ hai giây (2¹), lần 2 chờ bốn giây (2²), v.v. Điều này cho máy chủ ngày càng nhiều thời gian để hồi phục:
async def fetch_with_retry(session, story_id, max_retries=3):
for attempt in range(max_retries):
try:
story = await fetch_story(session, story_id)
if story is None:
raise ValueError(f"Story {story_id} not found")
return story
except (aiohttp.ClientError, ValueError): # Catch specific exceptions
if attempt == max_retries - 1:
print(f"Story {story_id}: Failed after {max_retries} attempts")
return None
backoff = 2 ** attempt # 1s, 2s, 4s...
print(f"Story {story_id}: Attempt {attempt + 1} failed, retrying in {backoff}s...")
await asyncio.sleep(backoff)Lưu ý chúng ta bắt các ngoại lệ cụ thể (aiohttp.ClientError, ValueError) thay vì except trần. Điều này đảm bảo chỉ thử lại với các lỗi có thể tạm thời. Một KeyError do mã sai không nên kích hoạt thử lại.
Hãy kiểm thử với danh sách ID gồm cả hợp lệ lẫn không hợp lệ:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
test_ids = [story_ids[0], 99999999999, story_ids[1], 88888888888, story_ids[2]]
results = await asyncio.gather(*[fetch_with_retry(session, sid) for sid in test_ids])
successful = [r for r in results if r is not None]
print(f"\nSuccessful: {len(successful)}, Failed: {len(test_ids) - len(successful)}")
asyncio.run(main())Story 99999999999: Attempt 1 failed, retrying in 1s...
Story 88888888888: Attempt 1 failed, retrying in 1s...
Story 99999999999: Attempt 2 failed, retrying in 2s...
Story 88888888888: Attempt 2 failed, retrying in 2s...
Story 99999999999: Failed after 3 attempts
Story 88888888888: Failed after 3 attempts
Successful: 3, Failed: 2Trong môi trường production, bạn cũng nên thêm jitter (thêm các độ trễ ngẫu nhiên nhỏ) để tránh nhiều yêu cầu thất bại cùng thử lại đúng một thời điểm. Ngoài ra, bạn chỉ nên thử lại lỗi tạm thời (sự cố mạng phía máy chủ, như 503) và bỏ ngay với lỗi vĩnh viễn (ví dụ 404 hoặc 401).
Chúng ta đã lấy các bài Hacker News với giới hạn tốc độ, timeout và xử lý lỗi phù hợp. Giờ hãy lưu chúng vào cơ sở dữ liệu.
Dùng thư viện cơ sở dữ liệu đồng bộ như sqlite3 sẽ chặn vòng lặp sự kiện trong lúc truy vấn, làm mất ý nghĩa của lập trình bất đồng bộ. Trong khi mã của bạn chờ cơ sở dữ liệu, không coroutine nào khác có thể chạy. Với ứng dụng async, bạn cần thư viện cơ sở dữ liệu async.
aiosqlite bọc sqlite3 tích hợp sẵn của Python bằng giao diện async. Nó chạy thao tác cơ sở dữ liệu trong thread pool để không chặn vòng lặp sự kiện. SQLite không cần thiết lập máy chủ — chỉ là một tệp — nên bạn có thể chạy mã này ngay. Nếu bạn mới làm việc với cơ sở dữ liệu trong Python, khóa học Introduction to Databases in Python bao quát nền tảng đồng bộ mà aiosqlite kế thừa.
Mẫu sử dụng sẽ quen thuộc. Cũng như aiohttp.ClientSession, bạn dùng async with để quản lý kết nối:
import aiosqlite
async def init_db(db_path):
async with aiosqlite.connect(db_path) as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS stories (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
score INTEGER,
fetched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
await db.commit()
asyncio.run(init_db("stories.db"))Các hàm chính:
aiosqlite.connect(path) mở (hoặc tạo) tệp cơ sở dữ liệu.
await db.execute(sql) chạy một câu lệnh SQL.
await db.commit() lưu thay đổi xuống đĩa.
Đây là hàm lưu một bài viết:
async def save_story(db, story):
await db.execute(
"INSERT OR REPLACE INTO stories (id, title, url, score) VALUES (?, ?, ?, ?)",
(story["id"], story.get("title", ""), story.get("url", ""), story.get("score", 0))
)Các placeholder ? ngăn SQL injection — đừng dùng f-string để chèn giá trị vào SQL. INSERT OR REPLACE cập nhật bài viết đã có nếu chúng ta lấy lại chúng.
Giờ hãy kết hợp mọi thứ trong hướng dẫn thành một pipeline hoàn chỉnh. Chúng ta sẽ lấy 20 bài Hacker News với giới hạn tốc độ và lưu vào cơ sở dữ liệu:
import aiohttp
import aiosqlite
import asyncio
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
async def fetch_story_limited(session, story_id, semaphore):
async with semaphore:
story = await fetch_story(session, story_id)
if story:
return story
return None
async def save_story(db, story):
await db.execute(
"INSERT OR REPLACE INTO stories (id, title, url, score) VALUES (?, ?, ?, ?)",
(story["id"], story.get("title", ""), story.get("url", ""), story.get("score", 0))
)
async def main():
# Initialize database
async with aiosqlite.connect("hn_stories.db") as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS stories (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
score INTEGER,
fetched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
# Fetch stories
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
semaphore = asyncio.Semaphore(5)
tasks = [fetch_story_limited(session, sid, semaphore) for sid in story_ids[:20]]
stories = await asyncio.gather(*tasks)
# Save to database
for story in stories:
if story:
await save_story(db, story)
await db.commit()
# Query and display
cursor = await db.execute("SELECT id, title, score FROM stories ORDER BY score DESC LIMIT 5")
rows = await cursor.fetchall()
print(f"Saved {len([s for s in stories if s])} stories. Top 5 by score:")
for row in rows:
print(f" [{row[2]}] {row[1][:50]}")
asyncio.run(main())Saved 20 stories. Top 5 by score:
[671] Google Antigravity exfiltrates data via indirect p
[453] Trillions spent and big software projects are stil
[319] Ilya Sutskever: We're moving from the age of scali
[311] Show HN: We built an open source, zero webhooks pa
[306] FLUX.2: Frontier Visual IntelligencePipeline này dùng các mẫu ở mọi phần: ClientSession để pooling kết nối, Semaphore(5) để giới hạn tốc độ, gather() để lấy dữ liệu đồng thời, và giờ là aiosqlite để lưu trữ async. Mỗi thành phần xử lý phần việc của mình mà không chặn phần khác.
Mỗi lần bạn chạy quy trình này, bạn sẽ nhận được các bài nổi bật trong ngày.
Hướng dẫn này đưa bạn từ cú pháp async/await cơ bản đến một pipeline dữ liệu hoàn chỉnh. Bạn đã học cách coroutine tạm dừng và tiếp tục, cách vòng lặp sự kiện quản lý tác vụ đồng thời, và cách asyncio.gather() chạy nhiều thao tác cùng lúc. Bạn đã thêm các yêu cầu HTTP thực với aiohttp, kiểm soát đồng thời bằng semaphore, xử lý lỗi với timeout và retry, và lưu kết quả vào cơ sở dữ liệu với aiosqlite.
Hãy dùng async khi mã của bạn chờ các hệ thống bên ngoài: HTTP API, cơ sở dữ liệu, I/O tệp hoặc socket mạng. Với công việc nặng CPU như xử lý dữ liệu hay tính toán, async sẽ không giúp — hãy xem multiprocessing hoặc concurrent.futures. Để đi xa hơn, bạn có thể đọc tài liệu asyncio và cân nhắc FastAPI để xây dựng web API async.
Nếu bạn muốn phát triển thêm từ nền tảng này và học cách thiết kế ứng dụng thông minh, hãy xem lộ trình nghề nghiệp Associate AI Engineer for Developers.
Khóa học Python
Tracks
Courses
Courses