When working with machine learning, it's easy to try them all out without understanding what each model does, and when to use them. In this cheat sheet, you'll find a handy guide describing the most widely used machine learning models, their advantages, disadvantages, and some key use-cases.
Get started on your way to becoming a machine learnng expert by starting our Machine Learning Scientist with Python track today.
Have this cheat sheet at your fingertips
Download PDFSupervised Learning
Supervised learning models are models that map inputs to outputs, and attempt to extrapolate patterns learned in past data on unseen data. Supervised learning models can be either regression models, where we try to predict a continuous variable, like stock prices—or classification models, where we try to predict a binary or multi-class variable, like whether a customer will churn or not. In the section below, we'll explain two popular types of supervised learning models: linear models, and tree-based models.
Become an ML Scientist
Linear Models
In a nutshell, linear models create a best-fit line to predict unseen data. Linear models imply that outputs are a linear combination of features. In this section, we'll specify commonly used linear models in machine learning, their advantages, and disadvantages.
| Algorithm | Description | Applications | Advantages | Disadvantages |
| Linear Regression | A simple algorithm that models a linear relationship between inputs and a continuous numerical output variable |
|
|
|
| Logistic Regression | A simple algorithm that models a linear relationship between inputs and a categorical output (1 or 0) |
|
|
|
| Ridge Regression | Part of the regression family — it penalizes features that have low predictive outcomes by shrinking their coefficients closer to zero. Can be used for classification or regression |
|
|
|
| Lasso Regression | Part of the regression family — it penalizes features that have low predictive outcomes by shrinking their coefficients to zero. Can be used for classification or regression |
|
|
|
Tree-based models
In a nutshell, tree-based models use a series of "if-then" rules to predict from decision trees. In this section, we'll specify commonly used linear models in machine learning, their advantages, and disadvantages.
| Algorithm | Description | Applications | Advantages | Disadvantages |
| Decision Tree | Decision Tree models make decision rules on the features to produce predictions. It can be used for classification or regression |
|
|
|
| Random Forests | An ensemble learning method that combines the output of multiple decision trees |
|
|
|
| Gradient Boosting Regression | Gradient Boosting Regression employs boosting to make predictive models from an ensemble of weak predictive learners |
|
|
|
| XGBoost | Gradient Boosting algorithm that is efficient & flexible. Can be used for both classification and regression tasks |
|
|
|
| LightGBM Regressor | A gradient boosting framework that is designed to be more efficient than other implementations |
|
|
|
Unsupervised Learning
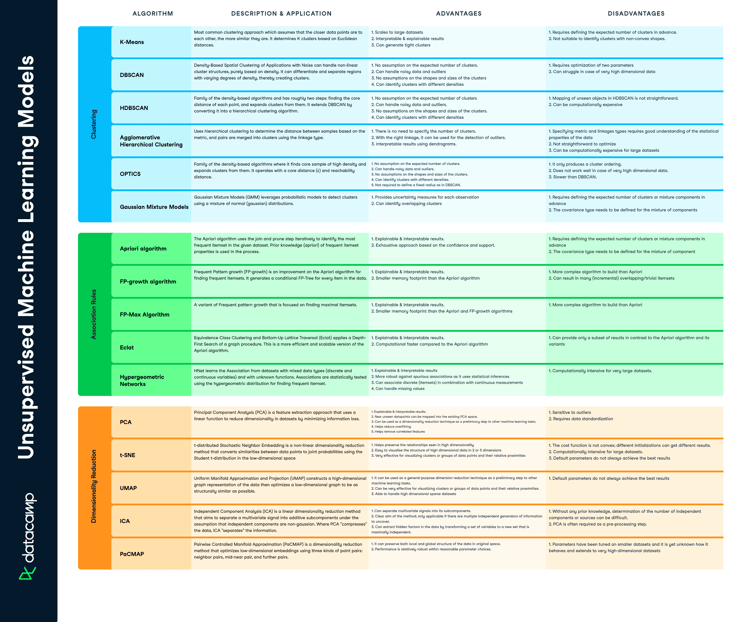
Unsupervised learning is about discovering general patterns in data. The most popular example is clustering or segmenting customers and users. This type of segmentation is generalizable and can be applied broadly, such as to documents, companies, and genes. Unsupervised learning consists of clustering models, that learn how to group similar data points together, or association algorithms, that group different data points based on pre-defined rules.
Clustering models
| Algorithm | Description | Applications | Advantages | Disadvantages |
| K-Means | K-Means is the most widely used clustering approach—it determines K clusters based on euclidean distances |
|
|
|
| Hierarchical Clustering | A "bottom-up" approach where each data point is treated as its own cluster—and then the closest two clusters are merged together iteratively |
|
|
|
| Gaussian Mixture Models | A probabilistic model for modeling normally distributed clusters within a dataset |
|
|
|
Association
| Algorithm | Description | Applications | Advantages | Disadvantages |
| Apriori Algorithm | Rule based approach that identifies the most frequent itemset in a given dataset where prior knowledge of frequent itemset properties is used |
|
|
|