
Kurs
Einführung in Python
4 Std.
6.9M
Python bietet mehrere numerische Datentypen, um verschiedene Arten von numerischen Werten zu verarbeiten.
Ganze Zahlen, positiv oder negativ, ohne eine Bruchkomponente.
Dies sind grundlegende numerische Werte, die Zählungen oder diskrete Messungen darstellen.
Im Gegensatz zu Fließkommazahlen sind Ganzzahlen exakt und erfordern keine Annäherungen, was sie ideal für Szenarien macht, in denen es auf Genauigkeit ankommt, wie z. B. beim Indizieren oder Zählen von Elementen.
age = 25Zahlen mit Dezimalpunkten oder in Exponentialform.
Diese Werte werden häufig in Szenarien mit gebrochener Genauigkeit verwendet, z. B. bei Finanzberechnungen, wissenschaftlichen Messungen und der Grafikprogrammierung.
Fließkommazahlen können auch extrem große oder kleine Werte in Exponentialschreibweise darstellen, was sie vielseitig für verschiedene numerische Anwendungen einsetzbar macht.
price = 19.99Zahlen mit einem realen und einem imaginären Teil. Komplexe Zahlen sind in Bereichen wie Elektrotechnik, Physik und Signalverarbeitung nützlich, wo Operationen mit imaginären Zahlen üblich sind.
Python stellt komplexe Zahlen als a + bj dar, wobei a der Realteil und b der Imaginärteil ist. Diese integrierte Unterstützung vereinfacht Berechnungen, die sonst externe Bibliotheken oder eigene Implementierungen in anderen Sprachen erfordern würden.
z = 2 + 3jNeben Zahlen bietet Python auch Sequenz-Datentypen, die geordnete Sammlungen von Elementen speichern.
Geordnete Folgen von Zeichen, die in einfachen oder doppelten Anführungszeichen eingeschlossen sind. Strings sind einer der vielseitigsten Datentypen in Python, mit dem du textbasierte Daten speichern und manipulieren kannst.
Sie werden häufig für Aufgaben wie das Verarbeiten von Benutzereingaben, das Erstellen von Nachrichten oder die Verarbeitung großer Textdatensätze verwendet.
Python bietet eine Vielzahl von eingebauten Methoden, wie .lower(), .upper(), .replace() und .split(), die die Arbeit mit Zeichenketten sehr effizient machen.
greeting = "Welcome to Python!"Listen sind geordnete, veränderbare Sammlungen von Elementen, die Elemente verschiedener Datentypen enthalten können.
Diese Flexibilität macht Listen zu einem der am häufigsten verwendeten Datentypen in Python, der sich für Aufgaben von der einfachen Speicherung bis zur komplexen Datenmanipulation eignet.
Listen ermöglichen eine dynamische Größenänderung und unterstützen verschiedene Operationen wie das Aufteilen, Anhängen und Entfernen von Elementen, was sie zu einer idealen Struktur für Szenarien macht, die geordnete und veränderbare Daten erfordern.
fruits = ["apple", "banana", "cherry"]Geordnete, unveränderliche Sammlungen von Gegenständen. Tupel werden oft verwendet, um feste Datensammlungen zu speichern, bei denen die Unveränderlichkeit wichtig ist, z. B. geografische Koordinaten, RGB-Farbcodes oder Datenbankeinträge.
Im Gegensatz zu Listen können Tupel nach ihrer Erstellung nicht mehr verändert werden, was sie in Szenarien, in denen die Datenintegrität entscheidend ist, schneller und sicherer macht.
dimensions = (1920, 1080)Während Sequenzen geordnete Sammlungen von Elementen speichern, gibt es in Python auch Mapping-Datentypen, die Schlüssel mit Werten verknüpfen. Die am häufigsten verwendete Zuordnungsart ist das Wörterbuch.
Sammlungen von Schlüssel-Wert-Paaren, bei denen die Schlüssel eindeutig und unveränderlich sind.
Wörterbücher sind sehr vielseitig und ermöglichen es dir, Daten effizient mit aussagekräftigen Schlüsseln zu organisieren und abzurufen, anstatt sich auf numerische Indizes zu verlassen. Das macht sie besonders nützlich für die Darstellung strukturierter Daten, wie JSON-Objekte oder Konfigurationseinstellungen.
Python-Wörterbücher unterstützen auch verschiedene Operationen wie das Hinzufügen, Aktualisieren oder Löschen von Schlüssel-Wert-Paaren, was sie zu einem unverzichtbaren Werkzeug in vielen Programmierszenarien macht.
person = {"name": "Alice", "age": 30}Neben Sequenzen und Mappings gibt es in Python auch Set-Datentypen, die Sammlungen eindeutiger Elemente ohne eine bestimmte Reihenfolge speichern.
Ungeordnete Sammlungen von eindeutigen Elementen. Gruppen sind besonders nützlich, wenn du sicherstellen musst, dass deine Daten keine Duplikate enthalten, z. B. bei Zugehörigkeitstests oder beim Entfernen doppelter Einträge aus einer Liste.
Sie unterstützen mathematische Operationen wie Vereinigung, Schnittmenge und Differenz, was sie zu leistungsstarken Werkzeugen für die Lösung von Problemen mit Datensätzen macht.
unique_numbers = {1, 2, 3, 4, 5}Eine unveränderliche Version einer Menge, was bedeutet, dass ihre Elemente, sobald sie erstellt wurden, nicht mehr verändert werden können.
Gefrorene Sets sind in Szenarien nützlich, in denen du eine hashfähige Sammlung eindeutiger Elemente brauchst, z. B. wenn du ein Set als Schlüssel in einem Wörterbuch verwendest oder die Integrität von Daten sicherstellen willst, die sich nicht ändern sollen.
Sie haben alle Eigenschaften regulärer Mengen, wie z. B. die Unterstützung mathematischer Operationen wie Vereinigung und Schnittmenge, aber mit dem zusätzlichen Vorteil der Unveränderlichkeit.
immutable_set = frozenset([1, 2, 3])Mehr darüber erfährst du in dem ausgezeichneten Tutorial zu Python Sets and Sets Theory.
In vielen Programmierszenarien brauchen wir eine Möglichkeit, um Wahrheitswerte darzustellen. Python bietet den Datentyp Boolean, der bei der Entscheidungsfindung und dem Kontrollfluss eine Rolle spielt.
Logische Werte, entweder True oder False. Diese Werte werden oft in Entscheidungsprozessen verwendet, z. B. in bedingten Anweisungen und Schleifen.
Boolesche Werte sind grundlegend für den Kontrollfluss in der Programmierung. Sie ermöglichen es dir, Code zu schreiben, der dynamisch auf Bedingungen reagiert.
In Python können boolesche Werte auch durch Vergleiche (z. B. 5 > 3 ergibt True ) oder logische Operationen (z. B. True and False ergibt False ) entstehen.
is_active = TrueZusätzlich zu den numerischen, Sequenz-, Mapping-, Set- und booleschen Typen gibt es in Python einen speziellen Datentyp, der das Fehlen eines Wertes darstellt.
Stellt das Fehlen eines Wertes oder einen Nullwert dar.
Der Typ None wird oft verwendet, um einen Platzhalter, nicht initialisierte Variablen oder den Standardrückgabewert von Funktionen zu bezeichnen, die nicht explizit etwas zurückgeben .
Sie ist vor allem dann nützlich, wenn eine Operation möglicherweise kein Ergebnis liefert oder wenn eine Variable ohne Anfangswert definiert werden muss.
result = NoneNeben den grundlegenden eingebauten Typen bietet Python auch erweiterte Datentypen für speziellere Anwendungsfälle. Schauen wir uns die häufigsten Arten an.
Byte-Objekte sind speziell für den Umgang mit Binärdaten wie Dateien, Multimedia und Netzwerkpaketen konzipiert. Diese Datentypen sind besonders nützlich, wenn du mit nicht-textuellen Daten arbeitest.
Der Typ bytes ist unveränderlich und eignet sich daher für Nur-Lese-Operationen, während bytearray eine veränderbare Alternative für Szenarien bietet, in denen Änderungen erforderlich sind. Der Typ memory view ermöglicht den Zugriff auf den internen Datenpuffer eines Objekts, ohne ihn zu kopieren, was die Leistung in speicherintensiven Anwendungen verbessert.
data = b"hello" # Immutable bytes object
mutable_data = bytearray(b"hello") # Mutable bytearray object
view = memoryview(mutable_data) # Memoryview of the bytearrayNumPy-Arrays sind hocheffiziente, mehrdimensionale Arrays, die für numerische Berechnungen entwickelt wurden.
Im Gegensatz zu Python-Listen bieten NumPy-Arrays eine bessere Leistung und sind für mathematische Operationen geeignet. Sie sind ein Eckpfeiler des wissenschaftlichen Rechnens und unterstützen Aufgaben wie lineare Algebra, Fourier-Transformationen und statistische Analysen.
Sie unterstützen das Broadcasting, das Operationen auf Arrays verschiedener Formen ermöglicht, was ihre Vielseitigkeit weiter erhöht.
import numpy as np
# Creating a 1D array
data = np.array([1, 2, 3, 4])
# Creating a 2D array
data_2d = np.array([[1, 2], [3, 4]])
# Performing element-wise operations
squared = data ** 2Wenn du mehr über NumPy erfahren möchtest, melde dich für diesen kostenlosen Einführungskurs in NumPy an.
Pandas DataFrames sind tabellarische Datenstrukturen, die leistungsstarke Werkzeuge für die Datenbearbeitung und -analyse bieten. Mit beschrifteten Zeilen und Spalten machen sie den Umgang mit strukturierten Daten intuitiv und effizient.
DataFrames sind ein wesentlicher Bestandteil von Data-Science-Workflows und ermöglichen Aufgaben wie das Filtern, Gruppieren, Zusammenführen und Aggregieren großer Datensätze. Außerdem lassen sie sich nahtlos in andere Bibliotheken integrieren, was Pandas für die moderne Datenanalyse unverzichtbar macht.
import pandas as pd
# Creating a simple DataFrame
data = pd.DataFrame({"Name": ["Alice", "Bob"], "Age": [25, 30]})
# Filtering rows based on a condition
adults = data[data["Age"] > 18]
# Adding a new column
data["IsAdult"] = data["Age"] > 18
# show data
data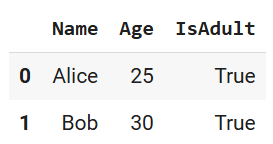
Pandas DataFrame im Notizbuch angezeigt
Sieh dir den Pandas-Spickzettel an, der Codebeispiele enthält und eine Kurzreferenz für die Datenverarbeitung mit Pandas ist.
Wenn du mehr über fortgeschrittene Datenbearbeitung mit Pandas DataFrames erfahren möchtest, melde dich für den kostenlosen Kurs Datenbearbeitung mit Pandas an.
Unter Typkonvertierung versteht man den Prozess der Umwandlung eines Wertes von einem Datentyp in einen anderen. In der Programmierung ist dies oft notwendig, um sicherzustellen, dass die Operationen korrekt ausgeführt und die Daten in der gewünschten Weise manipuliert werden können.
Python ist bei der Typumwandlung sehr flexibel und bietet sowohl automatische (implizite) als auch manuelle (explizite) Methoden.
Python wandelt in Ausdrücken automatisch einen Datentyp in einen anderen um, wenn ein kleinerer oder weniger präziser Datentyp mit einem größeren oder präziseren Typ kombiniert wird.
Wenn du z.B. eine int mit einer float kombinierst, erhältst du eine float, die sicherstellt, dass bei den Berechnungen keine Präzision verloren geht.
result = 5 + 3.5
print(result)
>>> 8.5 # This is a floatMit der expliziten Typkonvertierung oder dem Typ-Casting kannst du einen Wert manuell von einem Datentyp in einen anderen umwandeln, indem du integrierte Funktionen wie int(), float(), str() und andere verwendest.
Dies ist in Szenarien nützlich, in denen keine implizite Konvertierung stattfindet oder wenn du mit Datentypen wie Strings arbeitest, die für numerische Operationen explizit konvertiert werden müssen.
num = int("10") # Converts string to integer
price = float("19.99") # Converts string to float
text = str(123) # Converts integer to stringDie Datentypen von Python zu verstehen ist nur der erste Schritt - sie effektiv zu nutzen ist der Schlüssel zum Schreiben von sauberem, effizientem und wartbarem Code. Hier sind einige bewährte Methoden, die du bei der Arbeit mit Datentypen beachten solltest.
Wähle Typen, die zu deiner Aufgabe passen. Verwende zum Beispiel set, wenn du eindeutige Elemente pflegen musst, list für geordnete Datensammlungen und tuple für unveränderliche Sequenzen .
Eine bewusste Auswahl der Datentypen sorgt dafür, dass dein Code effizient und leichter zu lesen und zu warten ist.
Wenn du sicherstellst, dass die Eingabedaten den erwarteten Typ haben, kannst du Laufzeitfehler vermeiden und die Zuverlässigkeit des Codes verbessern.
Pythons Funktion isinstance() ist eine einfache Möglichkeit, Typen zu überprüfen. Diese Praxis ist besonders wichtig bei Anwendungen, in denen Eingaben dynamisch empfangen werden, z. B. von Benutzerformularen oder APIs.
if not isinstance(age, int):
raise ValueError("Age must be an integer")Python-Bibliotheken wie NumPy und pandas sind für fortgeschrittene Datenmanipulationen und Berechnungen unverzichtbar.
Wie wir gesehen haben, bietet NumPy schnelle, mehrdimensionale Arrays für numerische Operationen, während Pandas strukturierte Daten effizient verarbeiten und transformieren kann. Der Einsatz dieser Bibliotheken kann die Komplexität deines Codes erheblich reduzieren und seine Leistung verbessern.
Das Verständnis der Python-Datentypen ist der erste Schritt zu einer effizienten Programmierung und Datenbearbeitung. Die Datentypen bilden die Grundlage für die Vielseitigkeit von Python und ermöglichen es dir, verschiedene Arten von Daten mit Präzision und Leichtigkeit zu verarbeiten.
Wenn du die Grundlagen der in Python eingebauten Typen lernst und fortgeschrittene Bibliotheken wie NumPy und pandas kennenlernst, bist du auf dem besten Weg, ein professioneller Python-Benutzer zu werden und reale Probleme in den Bereichen Data Science, Datenanalyse, Finanzanalyse, künstliche Intelligenz und mehr zu lösen!
Wenn du dein Wissen vertiefen möchtest, solltest du dir den Kurs Einführung in Python für Entwickler ansehen, in dem die wichtigsten Python-Konzepte praxisnah vermittelt werden. Wenn du einen strukturierten Lernpfad suchst, der deine Python-Kenntnisse von Grund auf aufbaut, solltest du den Kurs Python Data Fundamentals in Betracht ziehen.
Lerne mehr über Python mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
