Data Science wird als der "sexieste Job des 21. Jahrhunderts" bezeichnet, und das ist nicht nur eine übertriebene Behauptung. Das US Bureau of Labor Statistics prognostiziert, dass die Zahl der Stellen für Datenwissenschaftler/innen zwischen 2021 und 2031 um 36 % steigen wird, was die wachsende Bedeutung dieses Bereichs deutlich macht.
Aber was genau ist Data Science, und warum ist sie im heutigen digitalen Zeitalter so wichtig? Dieser umfassende Artikel führt dich durch die Welt der Datenwissenschaft. Vom Lebenszyklus der Datenwissenschaft über ihre Anwendungen in verschiedenen Branchen bis hin zu den Fähigkeiten, die man braucht, um in der Datenwissenschaft Fuß zu fassen, werden wir einen tiefen Einblick geben, warum und wie die Datenwissenschaft zu einer der dynamischsten Branchen unserer Zeit geworden ist.
Was ist Data Science?
Data Science ist ein interdisziplinärer Bereich, der wissenschaftliche Methoden, Prozesse, Algorithmen und Systeme nutzt, um Wissen und Erkenntnisse aus strukturierten und unstrukturierten Daten zu gewinnen. Einfacher ausgedrückt, geht es bei der Datenwissenschaft um das Sammeln, Verarbeiten und Analysieren von Daten, um Erkenntnisse für viele Zwecke zu gewinnen.
Der Lebenszyklus der Datenwissenschaft
Der Data-Science-Lebenszyklus bezieht sich auf die verschiedenen Phasen, die ein Data-Science-Projekt im Allgemeinen durchläuft, von der anfänglichen Konzeption über die Datenerfassung bis hin zur Kommunikation der Ergebnisse und Erkenntnisse.
Obwohl jedes Data Science-Projekt einzigartig ist - abhängig von der Problemstellung, der Branche, in der es angewendet wird, und den beteiligten Daten - folgen die meisten Projekte einem ähnlichen Lebenszyklus.
Dieser Lebenszyklus bietet einen strukturierten Ansatz für den Umgang mit komplexen Daten, um genaue Schlussfolgerungen zu ziehen und datengestützte Entscheidungen zu treffen.
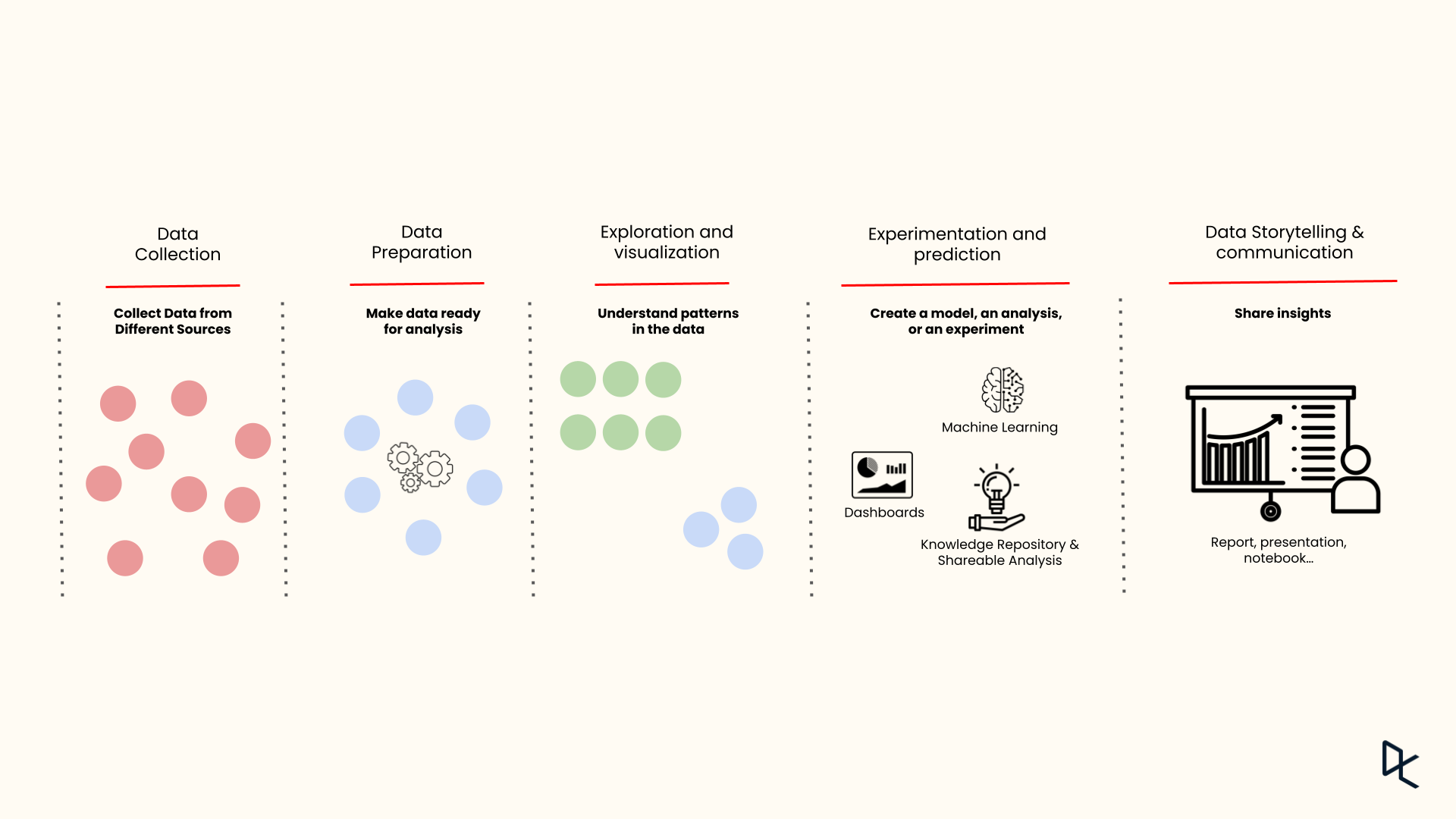
Der Lebenszyklus der Datenwissenschaft
Hier sind die fünf Hauptphasen, die den Lebenszyklus der Datenwissenschaft strukturieren:
Datenerhebung und -speicherung
In dieser ersten Phase werden Daten aus verschiedenen Quellen gesammelt, z. B. aus Datenbanken, Excel-Dateien, Textdateien, APIs, Web Scraping oder sogar Echtzeit-Datenströmen. Die Art und der Umfang der gesammelten Daten hängen weitgehend von dem Problem ab, das du angehen willst.
Sobald die Daten gesammelt sind, werden sie in einem geeigneten Format gespeichert und können weiterverarbeitet werden. Es ist wichtig, die Daten sicher und effizient zu speichern, damit sie schnell abgerufen und verarbeitet werden können.
Datenaufbereitung
Die Datenaufbereitung wird oft als die zeitaufwändigste Phase angesehen und umfasst die Reinigung und Umwandlung der Rohdaten in ein für die Analyse geeignetes Format. In dieser Phase werden fehlende oder inkonsistente Daten behandelt, Duplikate entfernt, Normalisierungen vorgenommen und Datentypen umgewandelt. Das Ziel ist es, einen sauberen, qualitativ hochwertigen Datensatz zu erstellen, der genaue und zuverlässige Analyseergebnisse liefern kann.
Erkundung und Visualisierung
In dieser Phase untersuchen Datenwissenschaftler/innen die aufbereiteten Daten, um ihre Muster, Merkmale und möglichen Anomalien zu verstehen. Techniken wie die statistische Analyse und Datenvisualisierung fassen die wichtigsten Merkmale der Daten zusammen, oft mit visuellen Methoden.
Visualisierungswerkzeuge wie Diagramme und Grafiken machen die Daten verständlicher und ermöglichen es den Beteiligten, die Datentrends und -muster besser zu verstehen.
Experimentieren und Vorhersagen
Datenwissenschaftler/innen nutzen Algorithmen des maschinellen Lernens und statistische Modelle, um Muster zu erkennen, Vorhersagen zu treffen oder Erkenntnisse zu gewinnen. Das Ziel ist es, aus den Daten etwas Bedeutendes abzuleiten, das mit den Projektzielen übereinstimmt, sei es die Vorhersage zukünftiger Ergebnisse, die Klassifizierung von Daten oder die Aufdeckung verborgener Muster.
Data Storytelling und Kommunikation
In der letzten Phase geht es darum, die aus der Datenanalyse gewonnenen Ergebnisse zu interpretieren und zu kommunizieren. Es reicht nicht aus, Erkenntnisse zu haben, du musst sie auch effektiv kommunizieren, mit einer klaren, prägnanten Sprache und überzeugenden Bildern. Ziel ist es, diese Erkenntnisse nicht-technischen Interessengruppen so zu vermitteln, dass sie die Entscheidungsfindung beeinflussen oder strategische Initiativen vorantreiben.
Das Verständnis und die Umsetzung dieses Lebenszyklus ermöglichen einen systematischeren und erfolgreicheren Ansatz für Data Science-Projekte. Jetzt wollen wir uns ansehen, warum Data Science so wichtig ist.
Warum ist Data Science wichtig?
Data Science hat sich zu einem revolutionären Bereich entwickelt, der entscheidend dazu beiträgt, Erkenntnisse aus Daten zu gewinnen und Unternehmen zu verändern. Es ist nicht übertrieben zu sagen, dass die Datenwissenschaft das Rückgrat der modernen Industrie ist. Aber warum hat sie so viel an Bedeutung gewonnen?
- Datenvolumen. Erstens hat der Aufstieg der digitalen Technologien zu einer Explosion von Daten geführt. Jede Online-Transaktion, jede Interaktion in den sozialen Medien und jeder digitale Prozess erzeugt Daten. Diese Daten sind jedoch nur dann wertvoll, wenn wir aussagekräftige Erkenntnisse aus ihnen gewinnen können. Und genau da kommt die Datenwissenschaft ins Spiel.
- Wertschöpfung. Zweitens geht es bei Data Science nicht nur um die Analyse von Daten, sondern auch darum, diese Daten zu interpretieren und zu nutzen, um fundierte Geschäftsentscheidungen zu treffen, zukünftige Trends vorherzusagen, das Kundenverhalten zu verstehen und die betriebliche Effizienz zu steigern. Diese Fähigkeit, Entscheidungen auf der Grundlage von Daten zu treffen, macht Data Science für Unternehmen so wichtig.
- Karriereoptionen. Und schließlich bietet der Bereich der Datenwissenschaft lukrative Karrieremöglichkeiten. Aufgrund der steigenden Nachfrage nach Fachkräften, die mit Daten arbeiten können, gehören Jobs in der Datenwissenschaft zu den bestbezahlten in der Branche. Laut Glassdoor liegt das Durchschnittsgehalt eines Datenwissenschaftlers in den USA bei 137.984 Dollar, was ihn zu einer lohnenden Berufswahl macht.
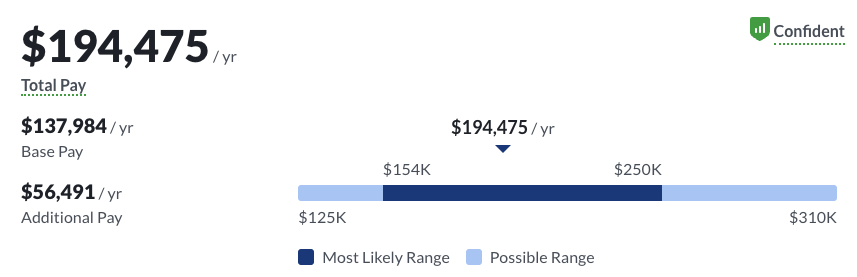
Durchschnittliches Gehalt eines Datenwissenschaftlers in den USA
Wofür wird Data Science eingesetzt?
Data Science wird für eine Vielzahl von Anwendungen genutzt, von der Vorhersage des Kundenverhaltens bis zur Optimierung von Geschäftsprozessen. Der Bereich der Datenwissenschaft ist breit gefächert und umfasst verschiedene Arten der Analytik.
- Deskriptive Analytik. Analysiert vergangene Daten, um den aktuellen Stand zu verstehen und Trends zu erkennen. Ein Einzelhandelsgeschäft könnte damit zum Beispiel den Umsatz des letzten Quartals analysieren oder die meistverkauften Produkte ermitteln.
- Diagnostische Analytik. Untersucht Daten, um zu verstehen, warum bestimmte Ereignisse eingetreten sind, und identifiziert Muster und Anomalien. Wenn die Umsätze eines Unternehmens zurückgehen, würde es feststellen, ob schlechte Produktqualität, verstärkter Wettbewerb oder andere Faktoren die Ursache dafür sind.
- Prädiktive Analytik. Nutzt statistische Modelle zur Vorhersage zukünftiger Ergebnisse auf der Grundlage von Daten aus der Vergangenheit und wird häufig in den Bereichen Finanzen, Gesundheitswesen und Marketing eingesetzt. Ein Kreditkartenunternehmen kann sie einsetzen, um das Ausfallrisiko seiner Kunden vorherzusagen.
- Prädiktive Analytik. Schlägt Maßnahmen vor, die auf den Ergebnissen anderer Analysemethoden basieren, um zukünftige Probleme zu mildern oder vielversprechende Trends zu nutzen. Zum Beispiel eine Navigations-App, die die schnellste Route basierend auf den aktuellen Verkehrsbedingungen empfiehlt.
Die zunehmende Verfeinerung von deskriptiven über diagnostische bis hin zu prädiktiven und präskriptiven Analysen kann Unternehmen wertvolle Erkenntnisse für die Entscheidungsfindung und strategische Planung liefern. Du kannst mehr über die vier Arten von Analysen in einem separaten Artikel lesen.
Was sind die Vorteile von Data Science?
Data Science kann für jedes Unternehmen, das seine Daten effektiv nutzt, einen Mehrwert schaffen. Von Statistiken bis hin zu Vorhersagen können effektive datengesteuerte Verfahren ein Unternehmen auf die Überholspur zum Erfolg bringen. Hier sind einige Möglichkeiten, wie die Datenwissenschaft eingesetzt wird:
Geschäftsprozesse optimieren
Data Science kann die Abläufe eines Unternehmens in verschiedenen Abteilungen erheblich verbessern, von der Logistik über die Lieferkette bis hin zum Personalwesen und darüber hinaus. Es kann bei der Ressourcenzuweisung, Leistungsbewertung und Prozessautomatisierung helfen. Ein Logistikunternehmen kann zum Beispiel Data Science nutzen, um Routen zu optimieren, Lieferzeiten zu verkürzen, Treibstoffkosten zu sparen und die Kundenzufriedenheit zu verbessern.
Neue Erkenntnisse gewinnen
Data Science kann verborgene Muster und Einsichten aufdecken, die auf den ersten Blick vielleicht nicht sichtbar sind. Diese Erkenntnisse können Unternehmen einen Wettbewerbsvorteil verschaffen und ihnen helfen, ihr Geschäft besser zu verstehen. Ein Unternehmen kann zum Beispiel Kundendaten nutzen, um Trends und Vorlieben zu erkennen und seine Produkte oder Dienstleistungen entsprechend anzupassen.
Innovative Produkte und Lösungen schaffen
Unternehmen können Data Science nutzen, um innovativ zu sein und neue Produkte oder Dienstleistungen zu entwickeln, die auf den Bedürfnissen und Vorlieben der Kunden basieren. Außerdem können Unternehmen so Markttrends vorhersagen und der Konkurrenz einen Schritt voraus sein. Streaming-Dienste wie Netflix nutzen zum Beispiel Data Science, um die Vorlieben der Zuschauer zu verstehen und personalisierte Empfehlungen zu erstellen, die das Nutzererlebnis verbessern.
Welche Branchen nutzen Data Science?
Die Auswirkungen der Datenwissenschaft erstrecken sich über alle Branchen und verändern die Art und Weise, wie Unternehmen arbeiten und Entscheidungen treffen, grundlegend. Obwohl jede Branche von der Einführung von Data Science profitieren kann, ist sie in datenreichen Branchen besonders einflussreich.
Wir wollen uns genauer ansehen, wie die Datenwissenschaft diese Schlüsselindustrien revolutioniert:
Datenwissenschaftliche Anwendungen im Finanzwesen
Der Finanzsektor hat sich die Möglichkeiten der Datenwissenschaft schnell zunutze gemacht. Von der Betrugserkennung und dem algorithmischen Handel bis hin zum Portfoliomanagement und der Risikobewertung hat die Datenwissenschaft komplexe Finanzoperationen effizienter und präziser gemacht. Kreditkartenunternehmen nutzen zum Beispiel datenwissenschaftliche Verfahren, um betrügerische Transaktionen zu erkennen und zu verhindern und so jährlich Milliarden von Dollar zu sparen.
Erfahre mehr über die Finanzgrundlagen in Python und wie du mit unserem Skill Track datengesteuerte Finanzentscheidungen treffen kannst.
Datenwissenschaftliche Anwendungen im Gesundheitswesen
Das Gesundheitswesen ist eine weitere Branche, in der die Datenwissenschaft einen großen Einfluss hat. Die Anwendungen reichen von der Vorhersage von Krankheitsausbrüchen und der Verbesserung der Qualität der Patientenversorgung bis hin zur Verbesserung des Krankenhausmanagements und der Arzneimittelentwicklung. Vorhersagemodelle helfen Ärzten, Krankheiten frühzeitig zu diagnostizieren, und die Behandlungspläne können an die spezifischen Bedürfnisse des Patienten angepasst werden, was zu besseren Behandlungsergebnissen führt.
Mehr darüber, wie Data Science das Gesundheitswesen verändert, erfährst du in einer Episode des DataFramed Podcasts.
Datenwissenschaftliche Anwendungen im Marketing
Das Marketing ist ein Bereich, der sich durch das Aufkommen der Datenwissenschaft stark verändert hat. Die Anwendungen in dieser Branche sind vielfältig und reichen von Kundensegmentierung und gezielter Werbung bis hin zu Umsatzprognosen und Stimmungsanalysen. Data Science ermöglicht es Marketingfachleuten, das Verhalten der Verbraucherinnen und Verbraucher in einem noch nie dagewesenen Detail zu verstehen und so effektivere Kampagnen zu entwickeln. Predictive Analytics können Unternehmen auch dabei helfen, potenzielle Markttrends zu erkennen, und ihnen so einen Wettbewerbsvorteil verschaffen. Personalisierungsalgorithmen können Produktempfehlungen auf einzelne Kunden zuschneiden und so den Umsatz und die Kundenzufriedenheit steigern.
Wir haben einen separaten Blog-Beitrag über fünf Möglichkeiten, Data Science im Marketing einzusetzen, in dem wir einige der in der Branche verwendeten Methoden vorstellen. Du kannst auch mehr in unserem Marketing Analytics with Python Skill Track lernen.
Datenwissenschaftliche Anwendungen in der Technik
Technologieunternehmen sind vielleicht die größten Nutznießer der Datenwissenschaft. Von der Unterstützung von Empfehlungsmaschinen bis hin zur Verbesserung der Bild- und Spracherkennung - Data Science findet in vielen Bereichen Anwendung. Ride-Hailing-Plattformen zum Beispiel setzen auf Data Science, um Fahrer/innen mit Ride-Hailern zu verbinden und das Angebot an Fahrer/innen je nach Tageszeit zu optimieren.
Wie unterscheidet sich die Datenwissenschaft von anderen datenbezogenen Bereichen?
Data Science überschneidet sich zwar mit vielen anderen Bereichen, die ebenfalls mit Daten arbeiten, hat aber eine einzigartige Mischung aus Prinzipien, Werkzeugen und Techniken, um aufschlussreiche Muster aus Daten zu extrahieren.
Die Unterscheidung zwischen Data Science und diesen verwandten Bereichen kann zu einem besseren Verständnis der Landschaft führen und dabei helfen, den richtigen Karriereweg einzuschlagen. Lass uns diese Unterschiede entmystifizieren.
Datenwissenschaft vs. Datenanalytik
Data Science und Data Analytics spielen beide eine wichtige Rolle bei der Gewinnung von Werten aus Daten, aber sie haben unterschiedliche Schwerpunkte. Data Science ist ein übergreifender Bereich, der Methoden wie maschinelles Lernen und prädiktive Analytik einsetzt, um Erkenntnisse aus Daten zu gewinnen. Im Gegensatz dazu konzentriert sich die Datenanalyse auf die Verarbeitung und statistische Analyse vorhandener Datensätze, um bestimmte Fragen zu beantworten.
Datenwissenschaft vs. Geschäftsanalytik
Business Analytics befasst sich zwar auch mit der Datenanalyse, konzentriert sich aber mehr auf die Nutzung von Daten für strategische Geschäftsentscheidungen. Sie ist in der Regel weniger technisch und mehr geschäftsorientiert als Data Science. Data Science kann zwar Geschäftsstrategien beeinflussen, taucht aber oft tiefer in die technischen Aspekte ein, wie Programmierung und maschinelles Lernen.
Data Science vs. Data Engineering
Data Engineering konzentriert sich auf den Aufbau und die Pflege der Infrastruktur für die Datenerfassung, -speicherung und -verarbeitung und stellt sicher, dass die Daten sauber und zugänglich sind. Data Science hingegen analysiert diese Daten mit Hilfe von statistischen und maschinellen Lernmodellen, um wertvolle Erkenntnisse zu gewinnen, die Geschäftsentscheidungen beeinflussen. Im Wesentlichen erstellen Data Engineers die "Straßen" der Daten, während Data Scientists auf ihnen "fahren", um aussagekräftige Erkenntnisse zu gewinnen. Beide Rollen sind in einer datengesteuerten Organisation wichtig.
Datenwissenschaft vs. maschinelles Lernen
Maschinelles Lernen ist ein Teilbereich der Datenwissenschaft, der sich auf die Entwicklung und Implementierung von Algorithmen konzentriert, die es Maschinen ermöglichen, aus Daten zu lernen und auf dieser Grundlage Entscheidungen zu treffen. Data Science ist jedoch breiter angelegt und umfasst viele Techniken, darunter auch maschinelles Lernen, um aussagekräftige Informationen aus Daten zu gewinnen.
Datenwissenschaft vs. Statistik
Die Statistik, eine mathematische Disziplin, die sich mit der Sammlung, Analyse, Interpretation und Organisation von Daten beschäftigt, ist ein wichtiger Bestandteil der Datenwissenschaft. Die Datenwissenschaft integriert jedoch Statistik mit anderen Methoden, um Erkenntnisse aus Daten zu gewinnen, was sie zu einem eher multidisziplinären Bereich macht.
|
Industrie |
Focus |
Technischer Schwerpunkt |
|
Datenwissenschaft |
Wertsteigerung durch Daten auf den 4 Ebenen der Analytik |
Programmierung, ML, Statistik |
|
Datenanalyse |
Statistische Analysen zu bestehenden Datensätzen durchführen |
Statistische Analyse |
|
Business Analytics |
Nutze Daten für strategische Geschäftsentscheidungen |
Geschäftsstrategien, Datenanalyse |
|
Datentechnik |
Dateninfrastruktur aufbauen und pflegen |
Datenerhebung, -speicherung, -verarbeitung |
|
Maschinelles Lernen |
Algorithmen für maschinelles Lernen erstellen und implementieren |
Algorithmenentwicklung, Modellimplementierung |
|
Statistik |
Datenerhebung, -analyse, -auswertung und -organisation |
Statistische Analyse, mathematische Grundlagen |
Nachdem wir diese Unterscheidungen verstanden haben, können wir uns nun den Schlüsselkonzepten widmen, die jeder Datenwissenschaftler beherrschen muss.
Wichtige Konzepte der Datenwissenschaft
Ein erfolgreicher Datenwissenschaftler braucht nicht nur technische Fähigkeiten, sondern auch ein Verständnis der Kernkonzepte, die die Grundlage des Fachgebiets bilden. Hier sind einige wichtige Begriffe, die du verstehen solltest:
Statistik und Wahrscheinlichkeit
Sie sind das Fundament der Datenwissenschaft. Statistik wird verwendet, um aus Daten aussagekräftige Erkenntnisse zu gewinnen, während die Wahrscheinlichkeitsrechnung es uns ermöglicht, auf der Grundlage der verfügbaren Daten Vorhersagen über zukünftige Ereignisse zu treffen. Das Verständnis von Verteilungen, statistischen Tests und Wahrscheinlichkeitstheorien ist für jeden Datenwissenschaftler unerlässlich.
Ressourcen für den Anfang
- Kurs Einführung in die Statistik
- Grundlagen der Statistik mit Python Skill Track
- Spickzettel für deskriptive Statistik
Programmierung
Programmieren ist das Werkzeug, mit dem Datenwissenschaftler/innen mit Daten arbeiten können. Sprachen wie Python und R sind aufgrund ihrer Benutzerfreundlichkeit und ihrer leistungsstarken Datenverarbeitungsbibliotheken besonders beliebt. Die Vertrautheit mit diesen Sprachen ermöglicht es einem Datenwissenschaftler, Daten effektiv zu bereinigen, zu verarbeiten und zu analysieren.
Ressourcen für den Anfang
- Python Programmierung Skill Track
- Berufsbild Python-Programmierer/in
- R Programmierung Skill Track
- R Programmierer Karriere Track
- Wie man im Jahr 2023 Programmierer/in wird: Eine Schritt-für-Schritt-Anleitung
Datenvisualisierung
Datenvisualisierung ist die Kunst, komplexe Daten in einem visuellen und leicht verständlichen Format darzustellen. Sie hilft dabei, Ergebnisse zu kommunizieren und macht es einfacher, komplexe Datensätze zu verstehen. Tools wie Tableau, Matplotlib und Seaborn werden in diesem Bereich häufig eingesetzt.
Ressourcen für den Anfang
- Kurs zum Verständnis der Datenvisualisierung
- Datenvisualisierung mit Python Skill Track
- Datenvisualisierung mit R Skill Track
- Spickzettel zur Datenvisualisierung
Maschinelles Lernen
Beim maschinellen Lernen, einem Teilbereich der künstlichen Intelligenz, wird ein Modell auf Daten trainiert, um Vorhersagen oder Entscheidungen zu treffen, ohne explizit programmiert zu werden. Sie ist das Herzstück vieler moderner Data Science-Anwendungen, von Empfehlungssystemen bis hin zu Predictive Analytics.
Ressourcen für den Anfang
- Kurs "Maschinelles Lernen verstehen
- Grundlagen des maschinellen Lernens mit Python Skill Track
- Machine Learning Scientist mit Python Karriere Track
- Was ist maschinelles Lernen?
Datentechnik
Die Datentechnik befasst sich mit dem Entwurf und der Konstruktion von Systemen zur Erfassung, Speicherung und Verarbeitung von Daten. Sie bildet die Grundlage, auf der Datenanalysen und maschinelle Lernmodelle aufgebaut werden.
Ressourcen für den Anfang
- Kurs "Datentechnik für jedermann
- Kurs Einführung in die Datentechnik
- Was ist Data Engineering?
- Wie man im Jahr 2023 Dateningenieur/in wird: 5 Schritte zum beruflichen Erfolg
- Aufbau von Data Engineering Pipelines in Python Kurs
Wichtige Tools für die Datenwissenschaft
Data Scientists brauchen eine Reihe von Werkzeugen, um ihre Aufgaben effektiv zu erledigen. Diese Tools können von Programmiersprachen bis hin zu Software für die Datenvisualisierung reichen. Hier sind einige wichtige Tools für die Datenwissenschaft.
Programmiersprachen
Im Bereich der Datenwissenschaft sind Programmiersprachen das Handwerkszeug. Sie bieten einen Rahmen, um einen Computer anzuweisen, bestimmte Aufgaben auszuführen, z. B. Datenmanipulation, statistische Analysen und maschinelles Lernen. Hier sind einige wichtige Sprachen, die jeder Datenwissenschaftler beherrschen sollte:
- Python. Sie ist bekannt für ihre Einfachheit und leistungsstarke Bibliotheken wie Pandas und NumPy.
- R. Ideal für statistische Analysen und Visualisierungen.
- Julia. Anerkannt für seine hohe Leistung und Geschwindigkeit, ideal für numerische und wissenschaftliche Berechnungen.
Ressourcen für den Anfang
- Python Grundlagen Skill Track
- Kurs Einführung in die R-Programmierung
- Einführung in den Julia-Kurs
- Python vs. R für Data Science: Was solltest du lernen?
- Python Spickzettel für Anfänger
Business Intelligence Tools
Business Intelligence (BI)-Tools sind Softwareanwendungen, mit denen die Rohdaten eines Unternehmens analysiert werden können. Sie helfen bei der Visualisierung, Berichterstattung und Weitergabe von Dateneinblicken und ermöglichen es Unternehmen, datengestützte Entscheidungen zu treffen. Hier sind einige wichtige BI-Tools für Data Science:
- Tableau. Zur Erstellung interaktiver Datenvisualisierungen.
- Power BI. Microsofts Suite von Business-Analytics-Tools.
- QlikView. Kombiniert ETL, Datenspeicherung und Visualisierung.
Ressourcen für den Anfang
- Tableau Grundlagen Skill Track
- Einführung in Power BI Kurs
- Power BI vs. Tableau: Was solltest du 2023 wählen?
- Power BI Spickzettel
- Tableau Spickzettel
Bibliotheken für maschinelles Lernen
Bibliotheken für maschinelles Lernen sind eine Sammlung von vorgefertigtem Code, mit dem Datenwissenschaftler Zeit sparen können. Sie bieten vorgefertigte Algorithmen und Lernroutinen, die in Programme integriert werden können. Hier sind einige wichtige Bibliotheken, die Aufgaben des maschinellen Lernens vereinfachen:
- Scikit-learn. Bietet verschiedene Algorithmen für Klassifizierung, Regression, Clustering, etc.
- TensorFlow. Entwickelt von Google für den Aufbau neuronaler Netzwerke.
- PyTorch. Bekannt für seinen dynamischen Berechnungsgraphen.
Ressourcen für den Anfang
- Grundlagen des maschinellen Lernens mit Python
- Was ist maschinelles Lernen? Blog Post
- Einführung in maschinelles Lernen in Python Tutorial
- Maschinelles Lernen mit scikit-learn Kurs
- Einführung in TensorFlow in Python Kurs
Datenbank-Management-Systeme
Datenbankmanagementsysteme (DBMS) sind Softwareanwendungen, die mit dem Benutzer, anderen Anwendungen und der Datenbank interagieren, um Daten zu erfassen und zu analysieren. Ein DBMS ermöglicht eine systematische Art und Weise, Daten zu erstellen, abzurufen, zu aktualisieren und zu verwalten. Hier sind einige beliebte DBMS, die in der Datenwissenschaft verwendet werden:
- MySQL. Ein relationales Open-Source-Datenbanksystem.
- PostgreSQL. Bietet fortschrittliche Funktionen wie die Gleichzeitigkeitskontrolle für mehrere Versionen.
- MongoDB. Eine beliebte NoSQL-Datenbank.
Ressourcen für den Anfang
- Datenbank-Design-Kurs
- Einführung in SQL Kurs
- SQL Datenbank Übersicht Tutorial
- Einsteigerhandbuch zu PostgreSQL
Top Data Science Jobs
Data Science ist ein weites Feld mit vielen spezialisierten Aufgaben, von denen jede ihre eigenen Verantwortlichkeiten, Qualifikationsanforderungen und Gehaltsvorstellungen hat. Hier sind einige der begehrtesten Berufsbezeichnungen im Bereich der Datenwissenschaft:
Datenanalytiker/in
Datenanalysten spielen eine entscheidende Rolle bei der Interpretation der Daten eines Unternehmens. Sie verfügen über Fachkenntnisse in mathematischer und statistischer Analyse, die es ihnen ermöglichen, komplexe Datensätze in verwertbare Erkenntnisse umzuwandeln, die Geschäftsentscheidungen vorantreiben. Mithilfe von Datenvisualisierungstools kommunizieren sie ihre Ergebnisse sowohl an technische als auch an nicht-technische Interessengruppen.
Datenanalysten tauchen in die Daten ein und erstellen Berichte und Visualisierungen, um verborgene Einblicke zu erhalten. Auch wenn sie nicht unbedingt an der Entwicklung fortschrittlicher Algorithmen beteiligt sind, nutzen sie eine Reihe von Tools, um Daten sinnvoll zu nutzen. Ihre Aufgaben können auch SQL-Abfragen, Datenbereinigung und Datenmanagement umfassen. Mehr darüber, wie man Datenanalyst/in wird, erfährst du in einem anderen Artikel.
Schlüsselqualifikationen:
- Beherrschung von SQL, Python oder R
- Ausgeprägtes Verständnis der statistischen Analyse
- Die Fähigkeit, überzeugende Datenvisualisierungen und Berichte zu erstellen
- Beherrschung der Datenbereinigung und -verwaltung
- Effektive Kommunikationsfähigkeiten
Unverzichtbare Werkzeuge:
- SQL für Datenbankabfragen
- Programmiersprachen wie Python oder R zur Datenmanipulation
- Datenvisualisierungstools wie Tableau oder PowerBI
- Tabellenkalkulationsprogramme wie MS Excel oder Google Sheets
- Statistische Software wie SPSS oder SAS
Datenwissenschaftler/in
Data Scientists erforschen die Daten eines Unternehmens, um aussagekräftige Erkenntnisse zu gewinnen und zu vermitteln. Sie verfügen über ein tiefes Verständnis von maschinellen Lernabläufen und deren Anwendung auf reale Geschäftsanwendungen. Data Scientists arbeiten hauptsächlich mit Codierungstools, führen gründliche Analysen durch und arbeiten häufig mit Big-Data-Tools.
Data Scientists sind so etwas wie Detektive im Bereich der Daten. Sie sind dafür verantwortlich, reichhaltige Datenquellen ausfindig zu machen und zu interpretieren, große Datensätze zu verwalten und durch das Zusammenführen von Datenpunkten Trends zu erkennen. Mit Hilfe von analytischen, statistischen und programmiertechnischen Fähigkeiten sammeln, analysieren und interpretieren sie umfangreiche Datensätze. Diese Erkenntnisse treiben die Entwicklung von datengesteuerten Lösungen für komplexe Geschäftsprobleme voran. Dabei werden oft Algorithmen für maschinelles Lernen entwickelt, um neue Erkenntnisse zu gewinnen, Prozesse zu automatisieren oder den Kunden einen höheren Mehrwert zu bieten.
In unserem ausführlichen Leitfaden " Wie werde ich Data Scientist?" findest du einige der wichtigsten Schritte, die du für den Einstieg in diese Rolle unternehmen musst.
Schlüsselqualifikationen:
- Gute Kenntnisse in Python, R und SQL
- Verständnis von Machine Learning und KI-Konzepten
- Kenntnisse in statistischer Analyse, quantitativer Analytik und Prognosemodellierung
- Die Fähigkeit, Daten effektiv zu visualisieren und zu berichten
- Ausgezeichnete Kommunikations- und Präsentationsfähigkeiten
Unverzichtbare Werkzeuge:
- Datenanalyse-Tools wie Pandas und NumPy
- Bibliotheken für maschinelles Lernen wie Scikit-learn
- Datenvisualisierungstools wie Matplotlib und Tableau
- Big Data-Frameworks wie Airflow und Spark
- Kommandozeilen-Tools wie Git und Bash
Dateningenieur
Data Engineers sind die Architekten der Datenwissenschaft. Sie entwerfen, bauen und verwalten eine Dateninfrastruktur, die es Data Scientists ermöglicht, Daten effizient zu analysieren. Data Engineers konzentrieren sich auf die Sammlung, Speicherung und Verarbeitung von Daten und bauen Datenpipelines auf, die den Analyseprozess rationalisieren.
Dateningenieure befassen sich oft mit der Entwicklung von Algorithmen zur Informationsgewinnung und erstellen Datenbanksysteme. Sie sorgen für optimale Leistung, indem sie die Datenarchitektur, Datenbanken und Verarbeitungssysteme verwalten. Diese Aufgabe erfordert ein umfassendes Verständnis von Programmiersprachen und Erfahrung mit relationalen und nicht-relationalen Datenbanken. Mehr darüber, wie du Dateningenieur/in wirst, erfährst du in einem anderen Beitrag.
Schlüsselqualifikationen:
- Kenntnisse in SQL und Datenbankdesign
- Beherrschung von Programmiersprachen wie Python oder Java
- Kenntnisse von Big-Data-Technologien wie Hadoop oder Spark
- Vertrautheit mit den Prinzipien der Datenmodellierung und des Data Warehousing
- Starke Problemlösungs- und Kommunikationsfähigkeiten
Werkzeuge:
- SQL für die Datenbankverwaltung
- Programmiersprachen für den Aufbau von Datenpipelines (z. B. Python, Java)
- Big Data-Plattformen wie Hadoop und Spark
- ETL-Tools (Extract, Transform, Load) wie Informatica oder Talend
- NoSQL-Datenbanken wie MongoDB oder Cassandra
Ingenieur für maschinelles Lernen
Machine Learning Engineers sind die Architekten der KI-Welt. Sie entwickeln und implementieren maschinelle Lernsysteme, die Unternehmensdaten nutzen, um Vorhersagen zu treffen. Zu ihren Aufgaben gehört es auch, Herausforderungen wie die Vorhersage der Kundenabwanderung und die Schätzung des Lebenszeitwerts zu bewältigen und Modelle für den Einsatz im Unternehmen zu entwickeln. Machine Learning Engineers arbeiten hauptsächlich mit kodierungsbasierten Tools.
Wie du Ingenieur für maschinelles Lernen wirst, erfährst du in einem separaten Artikel.
Schlüsselqualifikationen:
- Tiefes Verständnis von Python, Java und Scala
- Vertrautheit mit Frameworks für maschinelles Lernen wie Scikit-learn, Keras oder PyTorch
- Verständnis von Datenstrukturen, Datenmodellierung und Softwarearchitektur
- Fortgeschrittene mathematische Fähigkeiten, die lineare Algebra, Kalkül und Statistik umfassen
- Starke Teamarbeit und außergewöhnliche Problemlösungsfähigkeiten
Werkzeuge:
- Bibliotheken und Algorithmen für maschinelles Lernen (z. B. Scikit-learn, TensorFlow)
- Data Science Bibliotheken wie Pandas und NumPy
- Cloud-Plattformen wie AWS oder Google Cloud Platform
- Versionskontrollsysteme wie Git
|
Rolle |
Zuständigkeiten |
Schlüsselqualifikationen |
Unverzichtbare Werkzeuge |
|
Datenanalyst |
Erkenntnisse aus Daten für die Lösung von Geschäftsproblemen extrahieren und berichten |
SQL, Python, or R |
SQL, Python oder R, Datenvisualisierungstools (z. B. Tableau, PowerBI), Statistiksoftware (z. B. SPSS, SAS), Tabellenkalkulationstools |
|
Datenwissenschaftler/in |
Gewinnung aussagekräftiger Erkenntnisse, Entwicklung datengesteuerter Lösungen mit maschinellem Lernen, Kommunikation der Ergebnisse |
Python, R, SQL, Maschinelles Lernen und KI-Konzepte, statistische Analyse, Datenvisualisierung, Kommunikations- und Präsentationsfähigkeiten |
Pandas, NumPy, Scikit-learn, Matplotlib, Tableau, Airflow, Spark, Git, Bash |
|
Dateningenieur |
Entwerfen, Aufbauen und Verwalten der Dateninfrastruktur, Erstellen von Datenpipelines, Sicherstellen einer optimalen Leistung |
SQL, Python, Java, Datenbankdesign, Big Data Technologien, Datenmodellierung, Problemlösung, Kommunikationsfähigkeit |
SQL, Python, Java, Hadoop, Spark, ETL-Tools, NoSQL-Datenbanken |
|
Ingenieur für maschinelles Lernen |
Systeme für maschinelles Lernen entwerfen und einsetzen, komplexe Probleme mit ML lösen, mit Teams zusammenarbeiten |
Python, Java, Scala, Frameworks für maschinelles Lernen, Datenstrukturen, Softwarearchitektur, Mathematik, Teamarbeit, Problemlösungsfähigkeiten |
Scikit-learn, TensorFlow, Pandas, NumPy, Cloud-Plattformen (z. B. AWS, Google Cloud Platform), Versionskontrollsysteme (z. B. Git) |
Wie du mit Data Science anfängst
Data Science ist ein interdisziplinäres Fachgebiet. Um damit anzufangen, musst du dir eine Mischung aus Mathematik, Statistik, Informatik und domänenspezifischem Wissen aneignen. Schauen wir uns einen möglichen Fahrplan an, um deine Reise in die Datenwissenschaft zu beginnen.
Data Science ist ein faszinierender Bereich, in dem Neugierde auf Technologie trifft. Der erste Schritt mag einschüchternd erscheinen, aber denk daran, dass es nicht darum geht, alle Algorithmen zu kennen, sondern die richtigen Fragen zu stellen und zu lernen, sinnvolle Erkenntnisse aus den Daten zu entschlüsseln. Tauche einfach ein, fange an zu erkunden und der Rest wird folgen.
Richie Cotton, Data Evangelist at DataCamp
Was ist der Unterschied zwischen Datenwissenschaft, Datenanalyse und maschinellem Lernen?
Ist Datenwissenschaft schwer?
Ist Datenwissenschaft ein guter Beruf?
Warum Data Science studieren?
Warum ist Datenwissenschaft ein wachsendes Berufsfeld?
Wie kann ich mich auf ein Vorstellungsgespräch als Datenwissenschaftler/in vorbereiten?
Wie kann ich meine Fähigkeiten in der Datenanalyse bei Arbeitgebern beweisen?
Themen