
Kurs
MLOps-Konzepte
2 Std.
42.7K
Der Einsatz von großen Sprachmodellen (LLMs) wird immer schwieriger, da diese Modelle High-End-GPU-Maschinen mit viel VRAM benötigen. Ingenieure müssen auch MLOps-Tools beherrschen, um Aufgaben wie das Bereitstellen, Verteilen, Testen und Überwachen der Modelle zu erledigen. Außerdem müssen sie Zugangsbeschränkungen einführen und die Sicherheit aufrechterhalten, um sich vor Cyber-Bedrohungen und Prompt-Injection-Angriffen zu schützen. Das Leben eines LLMOps-Ingenieurs kann hart sein - aber keine Sorge, wir haben für dich gesorgt!
In diesem Tutorial werden wir eine einfachere und effizientere Lösung für den Einsatz von LLMs, wie Llama 3.3 70B, in der Cloud erkunden. Mit nur ein paar Zeilen Python-Code und ein paar Terminal-Befehlen ist dein Modell einsatzbereit. BentoCloud rationalisiert und verwaltet alles und macht den Einsatzprozess einfach und sicher.

Wenn du Anfänger bist, empfehle ich dirden Kurs Einführung in LLMs in Python, um die Grundlagen großer Sprachmodelle zu verstehen.
Das neue Meta Llama 3.3 ist ein nur auf Text (70B) abgestimmtes mehrsprachiges Large Language Model (LLM), das im Vergleich zu Llama 3.1 (70B) und Llama 3.2 (90B) eine verbesserte Leistung bietet. In einigen Fällen hat es sogar das größere Llama 3.1 (405B) übertroffen. Dieses Modell ist rein textbasiert und für mehrsprachige Dialoganwendungen optimiert.
Llama 3.3 ist ein autoregressives Sprachmodell, das auf einer optimierten Transformer-Architektur aufbaut. Es wurde mit Hilfe von überwachter Feinabstimmung (SFT) und Verstärkungslernen mit menschlichem Feedback (RLHF) feinabgestimmt, um den menschlichen Präferenzen für Hilfsbereitschaft und Sicherheit besser zu entsprechen.
Mehr über Llama 3.3 erfährst du auf . Was ist Meta's Llama 3.3 70B? Funktionsweise, Anwendungsfälle und mehr blog post.
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

In diesem Projekt werden wir BentoML für den Aufbau des KI-Dienstes, vLLM für die Bereitstellung von Modellen mit hohem Durchsatz und BentoCloud für eine robuste Infrastruktur und Bereitstellung verwenden. Außerdem werden wir die AWQ-Version des Modells einsetzen, um die Leistung zu optimieren.
Kurz gesagt, vLLM in Kombination mit AWQ ist eine tödliche Kombination für die Erstellung von LLM-Anwendungen, die superschnell sind und mehrere Anfragen gleichzeitig bearbeiten können.
AWQ (Activation-aware Weight Quantization) ist eine innovative Quantisierungstechnik, die entwickelt wurde, um den Einsatz von großen Sprachmodellen zu verbessern. Dies wird erreicht, indem die Speichernutzung deutlich reduziert und die Geschwindigkeit der Schlussfolgerungen verbessert wird, während gleichzeitig eine hohe Genauigkeit beibehalten wird.
Lies das Forschungspapier, um mehr über die AWQ-Technologie zu erfahren und darüber, wie sie die Modellinferenz optimiert und gleichzeitig die Genauigkeit beibehält.
vLLM (Virtual Large Language Model) ist eine Open-Source-Bibliothek, die speziell dafür entwickelt wurde, die Inferenz und die Bedienung von großen Sprachmodellen zu optimieren. Es löst kritische Herausforderungen wie Durchsatz und Speichereffizienz, indem es fortschrittliche Techniken wie PagedAttention einführt, die eine effiziente Verwaltung des Key-Value-Speichers sicherstellen.
Mehr über das Python-Paket vLLM erfährst du unter vLLM: Einrichten von vLLM lokal und in der Google Cloud für CPU tutorial.
BentoML ist ein Open-Source-Framework für maschinelles Lernen, das als Rückgrat der LLM-Einsatzpipeline dient. Es vereinfacht das Paketieren, Bereitstellen und Verwalten von Machine Learning-Modellen, einschließlich LLMs, in der Produktion.
In der Anleitung "Wie man LLMs mit BentoML einsetzt " erfährst du mehr über das BentoML-Ökosystem und wie man kleinere LLM-Modelle einsetzt.
BentoCloud ist eine serverlose Plattform, die auf BentoML aufbaut und die Bereitstellung und Verwaltung von Machine-Learning-Modellen vereinfachen soll. Es bietet eine robuste Infrastruktur, die für KI-Inferenz optimiert ist und sich daher besonders gut für LLMs eignet.
Mit BentoCloud können Nutzer skalierbare und effiziente KI-Lösungen in Cloud-Umgebungen einsetzen, ohne sich um das Infrastrukturmanagement kümmern zu müssen.
Lass uns jetzt mit dem Projekt weitermachen. Wir werden die folgenden Komponenten erstellen:
app.py Datei zur Definition der Model Serving API mit vLLM und FastAPI.requirements.txt Datei, um die notwendigen Python-Pakete für die Installation in der Cloud-Umgebung anzugeben.bentofile.yaml Datei, um die Infrastruktur zu konfigurieren, Docker-Images zu erstellen und die Einsatzumgebung einzurichten.Wir beginnen mit der Installation des BentoML Python-Pakets mit dem Befehl pip:
pip install bentomlIn der Python-Anwendungsdatei richten wir den Modell-Endpunkt wie folgt ein:
bentoml, fastapi, und vllm.Füge den untenstehenden Code in dein app.py ein:
# Standard library imports
import uuid
from argparse import Namespace
from typing import AsyncGenerator, Optional
# Third-party imports
import bentoml
import fastapi
from annotated_types import Ge, Le
from typing_extensions import Annotated
# Initialize FastAPI application
openai_api_app = fastapi.FastAPI()
# Constants
MAX_MODEL_LEN = 8192
MAX_TOKENS = 1024
SYSTEM_PROMPT = """You are a helpful and respectful assistant. Provide safe, unbiased, and accurate answers.
If a question is unclear or you don't know the answer, explain why instead of guessing."""
MODEL_ID = "casperhansen/llama-3.3-70b-instruct-awq"
# Define OpenAI-compatible API endpoints
OPENAI_ENDPOINTS = [
["/chat/completions", "create_chat_completion", ["POST"]],
["/completions", "create_completion", ["POST"]],
["/models", "show_available_models", ["GET"]],
]
@bentoml.mount_asgi_app(openai_api_app, path="/v1")
@bentoml.service(
name="llama3.3-70b-instruct-awq",
traffic={
"timeout": 1200,
"concurrency": 256,
},
resources={
"gpu": 1,
"gpu_type": "nvidia-a100-80gb",
},
)
class BentoVLLM:
def __init__(self) -> None:
"""Initialize the BentoVLLM service with VLLM engine and tokenizer."""
import vllm.entrypoints.openai.api_server as vllm_api_server
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
# Configure VLLM engine arguments
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_MODEL_LEN,
enable_prefix_caching=True,
)
# Initialize engine and tokenizer
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
# Register API endpoints
for route, endpoint_name, methods in OPENAI_ENDPOINTS:
endpoint_func = getattr(vllm_api_server, endpoint_name)
openai_api_app.add_api_route(
path=route,
endpoint=endpoint_func,
methods=methods,
)
# Configure model arguments
model_config = self.engine.engine.get_model_config()
args = Namespace(
model=MODEL_ID,
disable_log_requests=True,
max_log_len=1000,
response_role="assistant",
served_model_name=None,
chat_template=None,
lora_modules=None,
prompt_adapters=None,
request_logger=None,
disable_log_stats=True,
return_tokens_as_token_ids=False,
enable_tool_call_parser=True,
enable_auto_tool_choice=True,
tool_call_parser="llama3_json",
enable_prompt_tokens_details=False,
)
# Initialize application state
vllm_api_server.init_app_state(
self.engine, model_config, openai_api_app.state, args
)
@bentoml.api
async def generate(
self,
prompt: str = "Describe the process of photosynthesis in simple terms",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
"""
Generate text based on the input prompt using the VLLM engine.
Args:
prompt: The user's input prompt
system_prompt: Optional system prompt to guide the model's behavior
max_tokens: Maximum number of tokens to generate
Returns:
AsyncGenerator yielding generated text chunks
"""
from vllm import SamplingParams
# Configure sampling parameters
SAMPLING_PARAM = SamplingParams(
max_tokens=max_tokens,
skip_special_tokens=True,
)
# Use default system prompt if none provided
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
# Prepare messages for chat
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
# Apply chat template
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# Generate response stream
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
# Stream the generated text
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Erstelle eine requirements.txt Datei und füge alle notwendigen Python-Pakete ein, um die KI-Anwendung zu erstellen. Gib die genauen Versionen der einzelnen Pakete an, um die Stabilität und Reproduzierbarkeit des Projekts zu gewährleisten.
So sollte die requirements.txt aussehen:
accelerate==1.2.0
autoawq==0.2.7.post3
bentoml>=1.3.15
fastapi==0.115.6
openai==1.57.0
vllm==0.6.4.post1; sys_platform == "linux"Die bentofile.yaml Datei ist die Konfigurationsdatei, die zum Definieren und Erstellen des BentoML-Dienstes verwendet wird. Es umfasst die folgenden Komponenten:
app.py) und den Dienstklassennamen (BentoVLLM) verknüpft.requirements.txt.Füge den folgenden Inhalt zu deiner bentofile.yaml Datei hinzu:
service: 'app:BentoVLLM'
labels:
owner: Abid
team: DataCamp
stage: dev
include:
- '*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"Jetzt kommt der magische Teil: BentoCloud macht alles für uns, und wir müssen nur einen Befehl eingeben. Aber vorher müssen wir uns bei BentoCloud anmelden, indem wir den folgenden Befehl in das Terminal eingeben.
bentoml cloud login
Das CLI-Tool stellt dir ein paar Fragen und leitet dich dann auf die BentoCloud-Website weiter, um ein Konto zu erstellen und den API-Schlüssel zu generieren.
Sobald du das getan hast, wird der API-Schlüssel automatisch auf deine CLI-Tools angewendet.
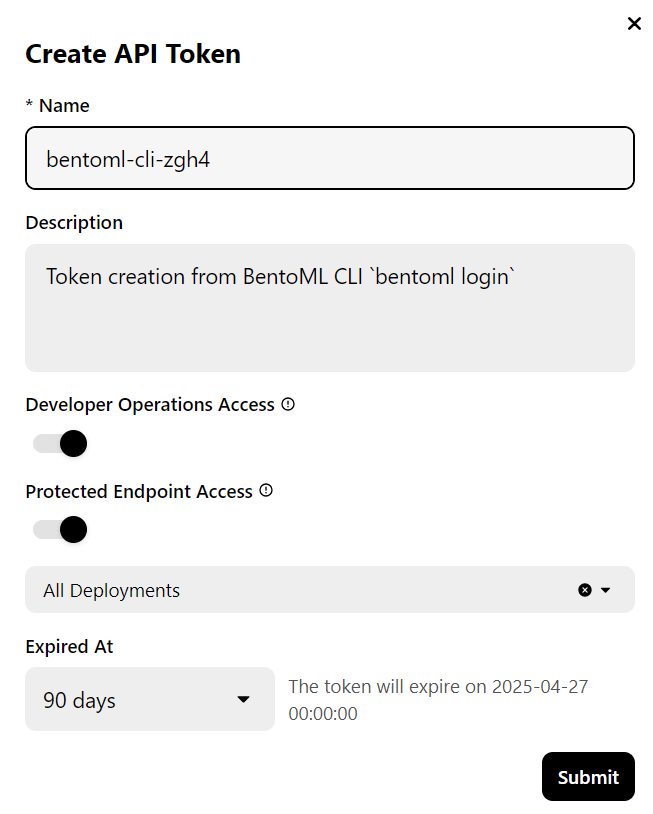
Hinweis: Für den Einsatz der Vollversion des 70B-Modells werden 80 GB GPU-Speicher benötigt. Obwohl BentoCloud 10 USD an kostenlosem Guthaben zur Verfügung stellt, musst du den Pro-Tarif abonnieren, um Zugang zu den A100-GPUs mit 80 GB VRAM zu erhalten.
Um dich anzumelden, gehst du auf die Registerkarte "Abrechnung", indem du oben rechts auf dein Profilbild klickst und deine Kreditkartendaten eingibst.
Keine Sorge, wenn du beim Einsatz vorsichtig bist, kostet es dich nicht mehr als 6 USD. Achte aber darauf, dass du den Einsatz beendest, wenn du mit dem Experimentieren fertig bist!
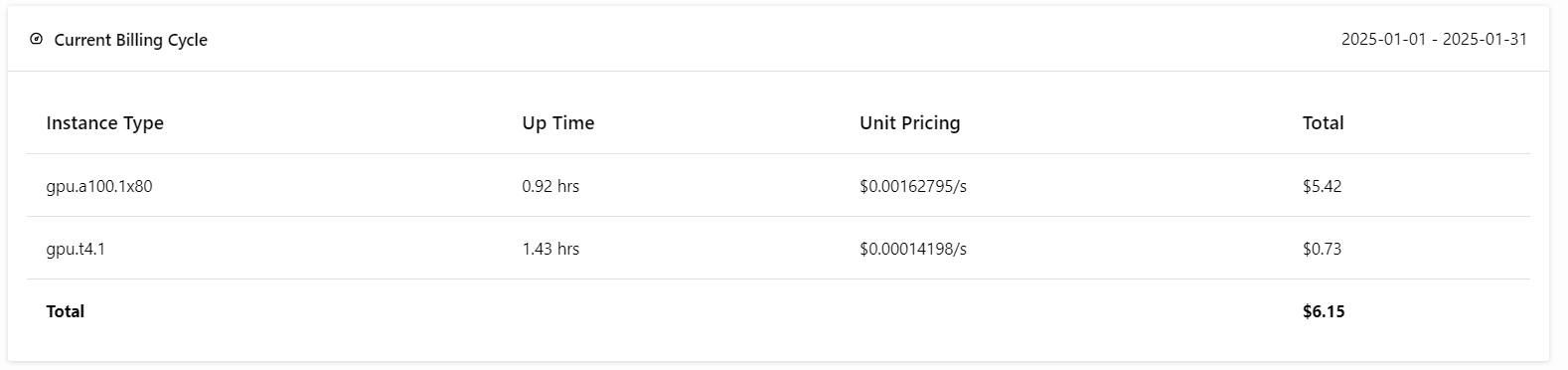
Jetzt kommt der beste Teil: Wir werden die BentoML-Anwendung mit dem folgenden Befehl in der Cloud bereitstellen und die Zugriffsberechtigung aktivieren. Das bedeutet, dass nur Benutzer mit dem BentoML-API-Schlüssel auf diesen API-Server zugreifen können.
bentoml deploy . --access-authorization trueEs dauert ein paar Sekunden, bis alle Dateien, Konfigurationen und anderen notwendigen Komponenten gesendet sind, danach erledigt BentoCloud den Rest.

Um deine laufenden Einsätze zu sehen, gehe zu deinem BentoCloud Dashboard und klicke auf die Registerkarte "Einsätze". Das folgende Bild zeigt zum Beispiel die Anwendung im Prozess "Bilderstellung":
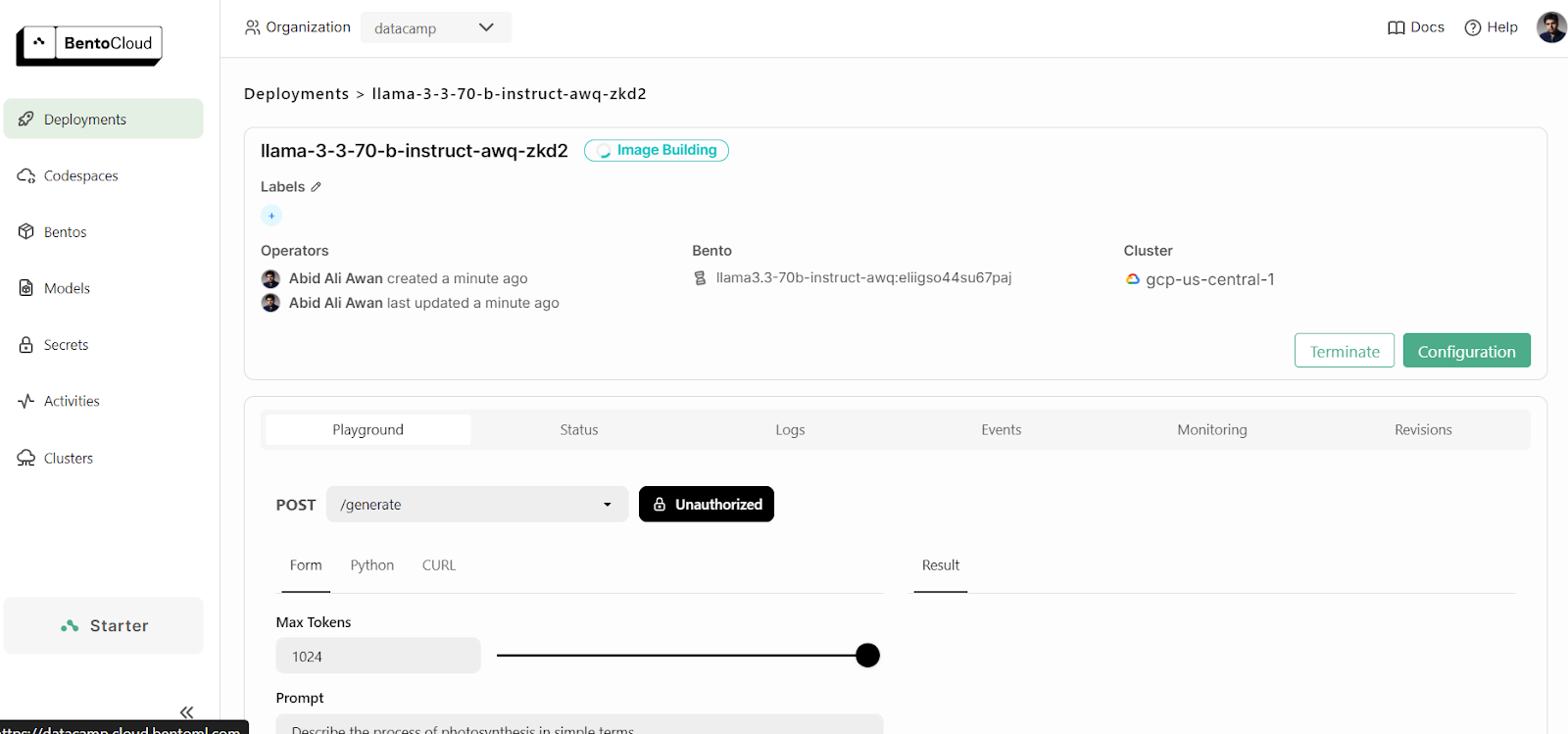
Nach ein paar weiteren Minuten, in denen wir das Image erstellen, die Infrastruktur einrichten und das Modell bereitstellen, ist unsere Anwendung einsatzbereit!
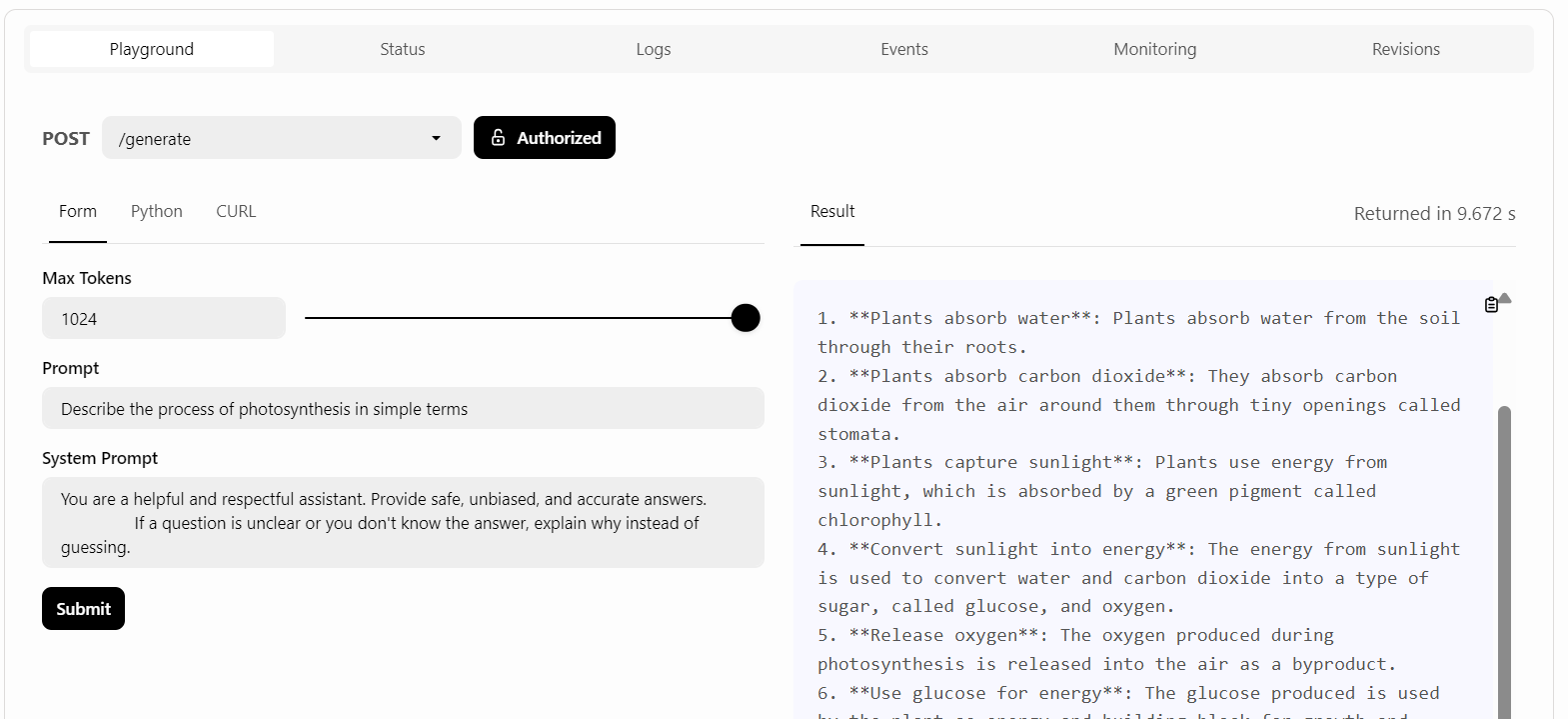
BentoCloud bietet eine Playground UI, mit der du dein Modell auf dem Dashboard testen kannst, ähnlich wie bei der OpenAI-Plattform. Da unser Dienst eingeschränkt ist, müssen wir einen API-Schlüssel angeben, um auf das Modell im Playground zuzugreifen, wie unten gezeigt:
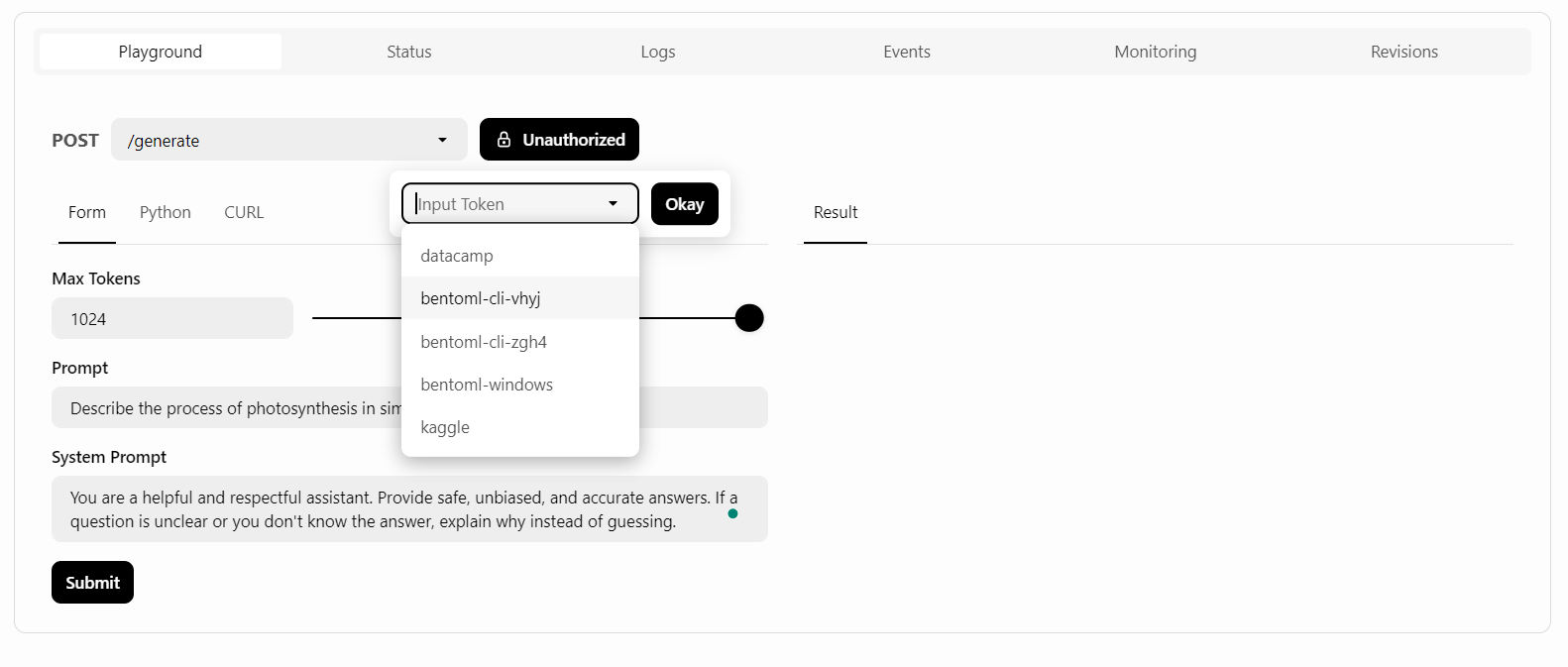
Danach schreiben wir die Eingabeaufforderung und klicken auf die Schaltfläche "Absenden".
Die Antwortgenerierung war schnell und präzise:
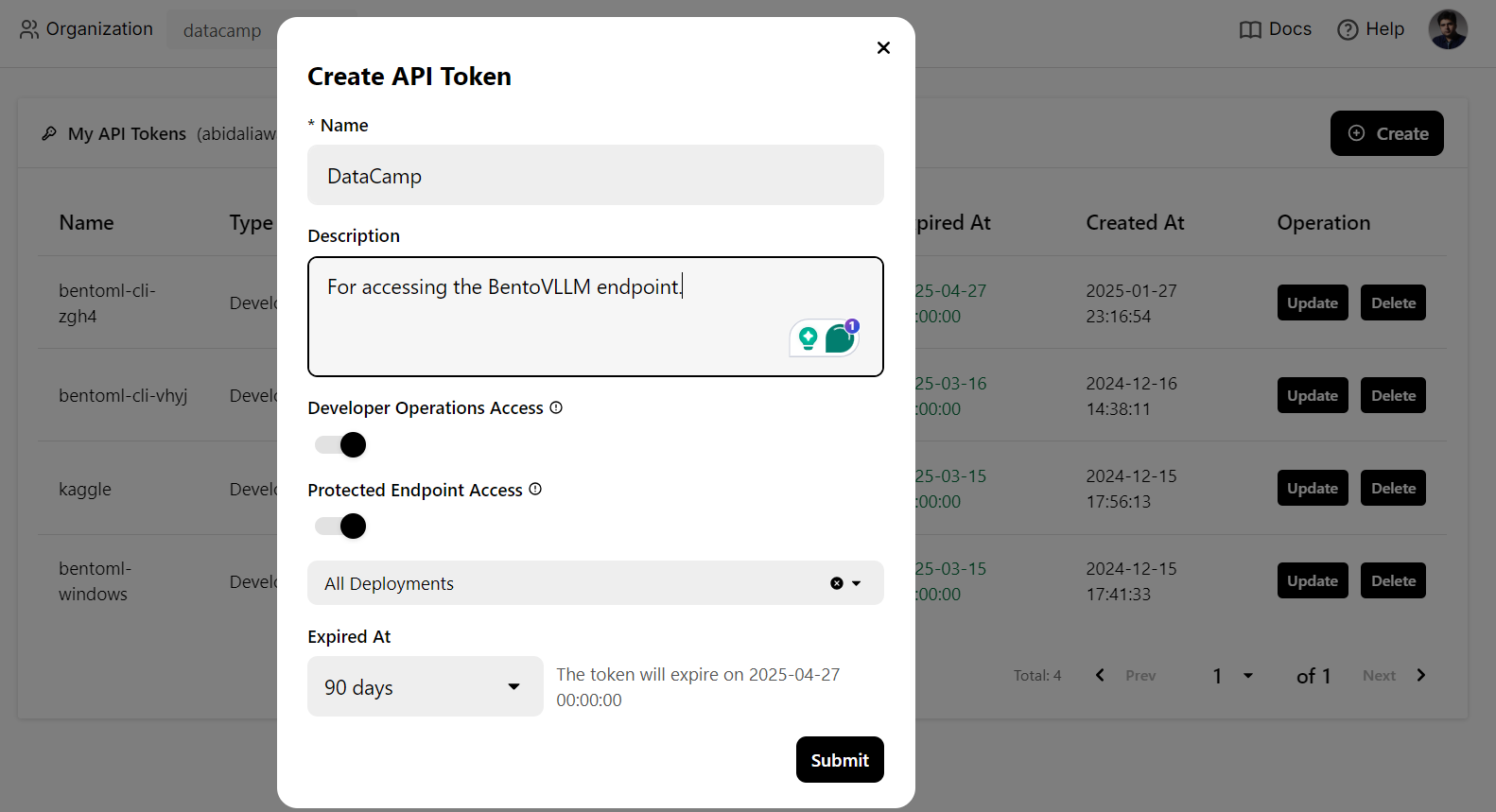
Wir werden einen CURL-Befehl im Terminal verwenden, um lokal auf den LLM-Dienst zuzugreifen. Aber vorher müssen wir einen neuen API-Schlüssel generieren, um diesen Dienst auf jedem System nutzen zu können:
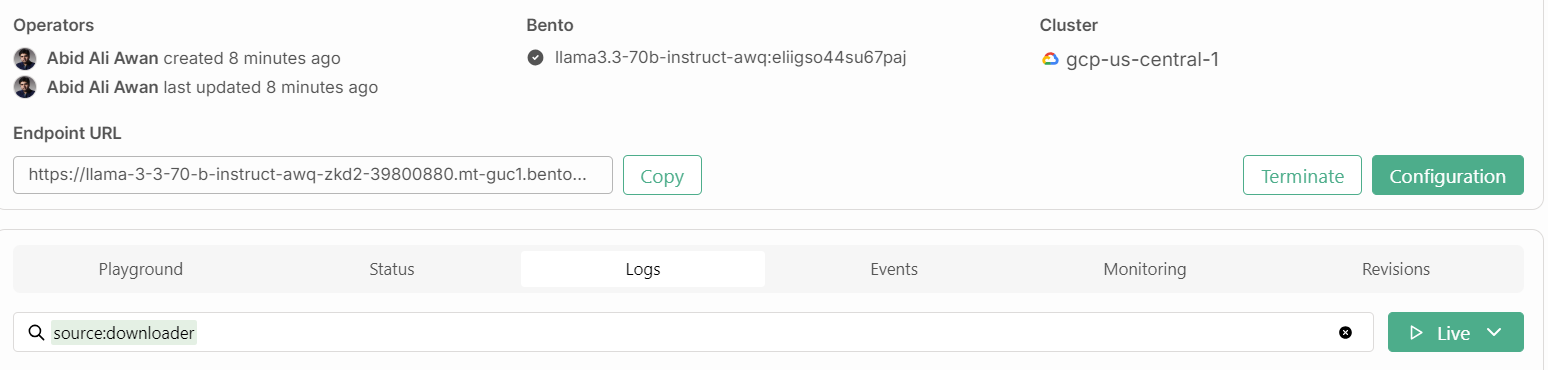
Außerdem brauchen wir die Endpunkt-URL, die wir von der Registerkarte "Einsätze" kopieren können:
Sobald du den API-Schlüssel und die Endpunkt-URL hast, kannst du mit dem folgenden CURL-Befehl eine Antwort erzeugen.
Der Befehl enthält die Endpunkt-URL, den API-Schlüssel, das Argument max_tokens und die prompt:
curl -s -X POST \
'https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/generate' \
-H "Authorization: Bearer $(echo $BENTO_CLOUD_API_KEY)" \
-H 'Content-Type: application/json' \
-d '{
"max_tokens": 1024,
"prompt": "Describe the process of photosynthesis in simple terms"
}'Die Antwort ist genau, und es hat ein paar Sendungen gedauert, um sie zu erstellen.

Der BentoML-Endpunkt ist mit dem OpenAI Python-Client kompatibel. Du musst deinen Code nicht wesentlich ändern, um dieses Open-Source-Modell in deine Anwendung zu integrieren.
Alles, was du tun musst, ist, die Basis-URL zu ändern, den API-Schlüssel anzugeben und den Modellnamen zu spezifizieren:
import os
from openai import OpenAI
BENTOML_API_KEY = os.getenv("BENTO_CLOUD_API_KEY") #
if BENTOML_API_KEY is None:
raise ValueError("BENTOML_API_KEY environment variable is not set.")
client = OpenAI(
base_url="https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/v1",
api_key=BENTOML_API_KEY,
)
chat_completion = client.chat.completions.create(
model="casperhansen/llama-3.3-70b-instruct-awq",
messages=[
{"role": "user", "content": "What is a black hole and how does it work?"}
],
stream=True,
stop=["<|eot_id|>", "<|end_of_text|>"],
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")
Bitte schau dir das GitHub-Repository kingabzpro/Deploying-Llama-3.3-70B an, das die Anwendungsdatei, Konfigurationen und Inferenzcodes enthält.
Mit BentCloud kannst du die Leistung des Modells, die Latenzzeit, die Hardwarenutzung, den Durchsatz des Modells und andere wichtige Kennzahlen überwachen, ohne Protokollierungs- oder Überwachungstools einzurichten.
Gehe zu deinen Verteilungen und klicke auf den Reiter "Überwachung".
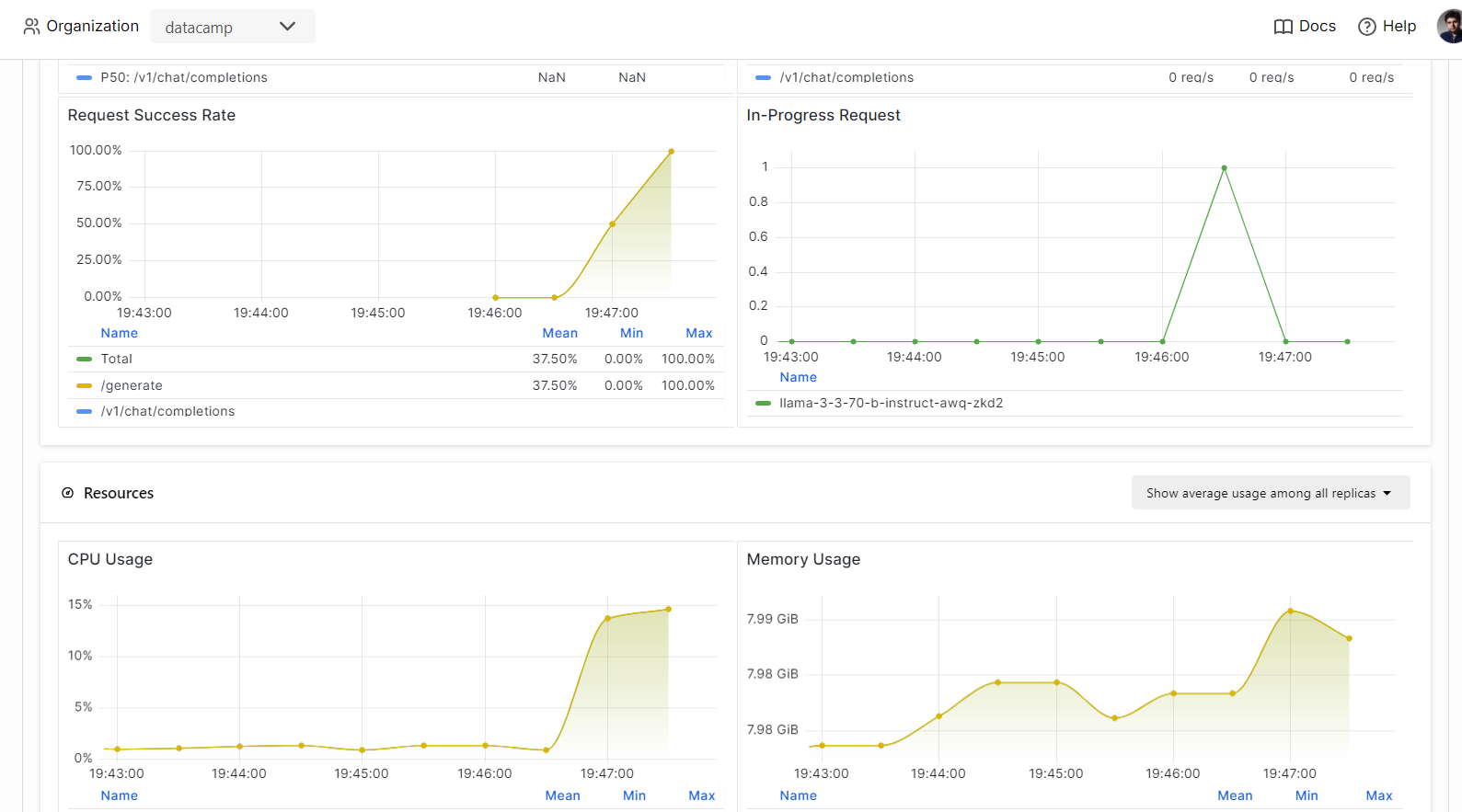
Scrolle nach unten, um die dienst-, ressourcen- und LLM-bezogenen Metriken in intuitiven, übersichtlichen Diagrammen zu sehen.
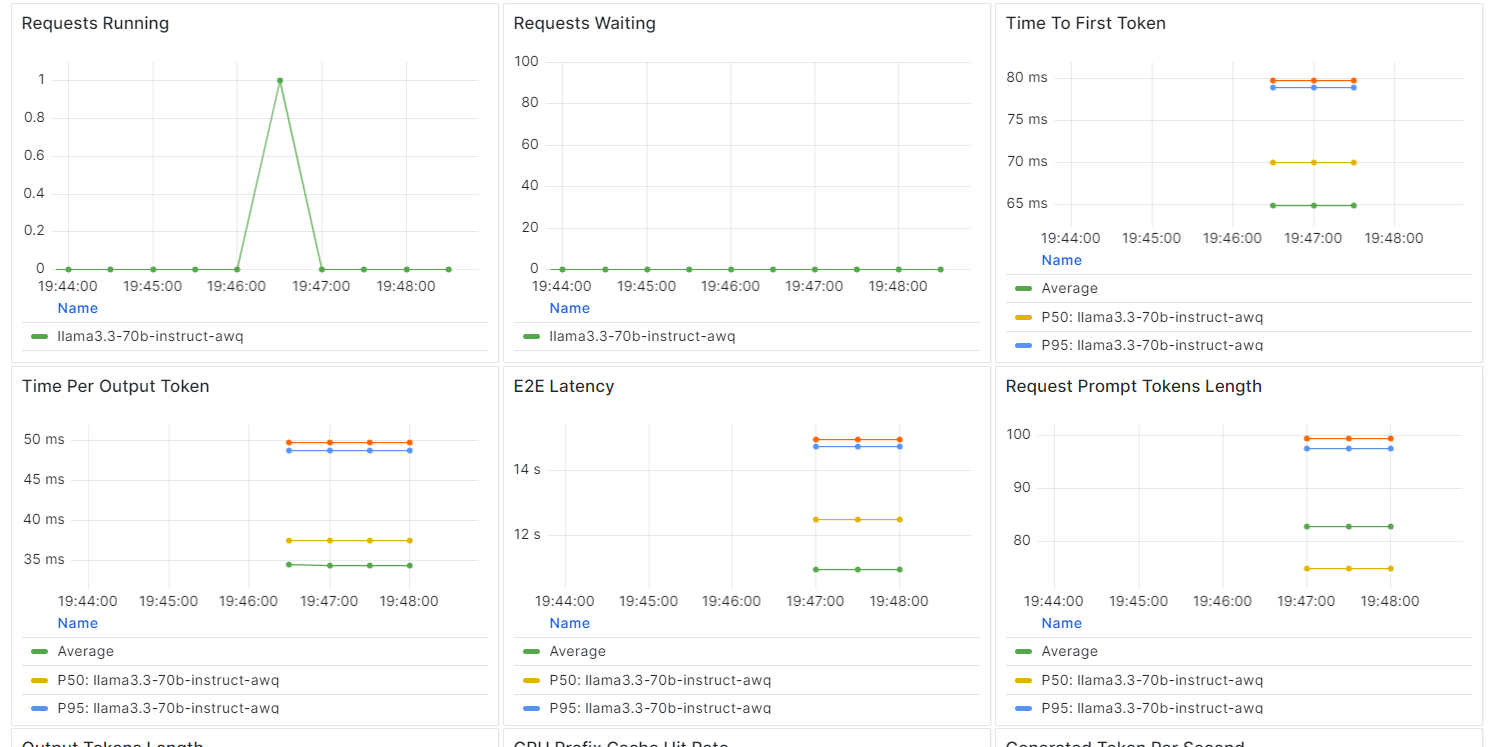
Mit dem BentoML-Ökosystem ist die Entwicklung und der Einsatz eines LLM-Endpunkts bemerkenswert einfach geworden.
Wenn du nur ein paar Zeilen Code schreibst, um deine API zu erstellen, eine "bentofile" einrichtest und das Modell bereitstellst, kannst du dein Modell in wenigen Minuten zum Laufen bringen. Nach dem Einsatz kann der Endpunkt über CURL-Befehle, die Python-Anforderungsbibliothek, den BentoML-Client oder den OpenAI-Client erreicht werden.
Das Ergebnis ist ein hocheffizientes System mit niedriger Latenz und hohem Durchsatz, das mehrere Anfragen gleichzeitig bearbeiten kann. BentoCloud bietet außerdem eine automatische Skalierung, die auf deiner Konfiguration basiert und sicherstellt, dass das System ein hohes Verkehrsaufkommen bewältigen kann, indem es je nach Bedarf nach oben oder unten skaliert wird.
Für eine detailliertere Anleitung zum Einsatz von LLMs mit BentoML empfehle ich dir die Seite How to Deploy LLMs with BentoML: Eine Schritt-für-Schritt-Anleitung.
Erfahre mehr über KI und LLMs mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
