
Cours
Concepts MLOps
2 h
42.6K
Le déploiement de grands modèles de langage (LLM) devient de plus en plus difficile, car ces modèles nécessitent des machines GPU haut de gamme dotées d'une VRAM importante. Les ingénieurs doivent également maîtriser les outils MLOps pour gérer des tâches telles que la mise à disposition, le déploiement, le test et le contrôle des modèles. En outre, ils doivent mettre en œuvre des restrictions d'accès et maintenir la sécurité pour se protéger contre les cybermenaces et les attaques par injection. La vie d'un ingénieur LLMOps peut être difficile, mais ne vous inquiétez pas, nous vous couvrons !
Dans ce tutoriel, nous allons explorer une solution plus simple et plus efficace pour déployer des LLM, tels que Llama 3.3 70B, sur le cloud. Avec seulement quelques lignes de code Python et quelques commandes de terminal, votre modèle sera opérationnel. BentoCloud rationalise et gère tout, rendant le processus de déploiement simple et sûr.

Si vous êtes débutant, je vous recommande de suivrele cours Introduction aux LLM en Python pour comprendre les bases des grands modèles de langage.
Le nouveau Meta Llama 3.3 est un modèle multilingue à grande échelle (LLM) adapté aux instructions pour le texte seul (70B) qui offre des performances améliorées par rapport à Llama 3.1 (70B) et Llama 3.2 (90B). Dans certains cas, il a même surpassé le Llama 3.1 (405B), plus grand. Ce modèle est textuel et optimisé pour les cas d'utilisation du dialogue multilingue.
Llama 3.3 est un modèle de langage auto-régressif construit sur une architecture de transformateur optimisée. Il a été affiné à l'aide d'un réglage fin supervisé (SFT) et d'un apprentissage par renforcement avec retour d'information humain (RLHF) afin de mieux s'aligner sur les préférences humaines en matière de serviabilité et de sécurité.
Pour en savoir plus sur Llama 3.3, consultez le site Qu'est-ce que Llama 3.3 70B de Meta ? Comment ça marche, les cas d'utilisation et plus encore blog post.
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Dans ce projet, nous utiliserons BentoML pour construire le service d'IA, vLLM pour le service de modèles à haut débit, et BentoCloud pour une infrastructure et un déploiement robustes. En outre, nous déploierons la version AWQ du modèle afin d'en optimiser les performances.
En bref, vLLM combiné à AWQ crée une combinaison mortelle pour la construction d'applications LLM super rapides et capables de traiter plusieurs requêtes simultanément.
AWQ (Activation-aware Weight Quantization) est une technique de quantification innovante conçue pour améliorer le déploiement de modèles linguistiques de grande taille. Il y parvient en réduisant considérablement l'utilisation de la mémoire et en améliorant la vitesse d'inférence, tout en conservant une grande précision.
Lisez l'article de recherche pour en savoir plus sur la technologie AWQ et sur la façon dont elle optimise l'inférence des modèles tout en maintenant la précision.
vLLM (Virtual Large Language Model) est une bibliothèque open-source spécialement conçue pour optimiser l'inférence et l'utilisation de modèles linguistiques de grande taille. Il relève des défis cruciaux tels que le débit et l'efficacité de la mémoire en introduisant des techniques avancées telles que PagedAttention, qui garantit une gestion efficace de la mémoire clé-valeur de l'attention.
Pour en savoir plus sur le paquetage Python vLLM, consultez le site vLLM : Tutoriel sur la configuration de vLLM en local et sur Google Cloud pour le CPU.
BentoML est un cadre de service de modèle d'apprentissage automatique open-source qui sert d'épine dorsale au pipeline de déploiement LLM. Il simplifie le processus de conditionnement, de déploiement et de gestion des modèles d'apprentissage automatique, y compris les LLM, en production.
Suivez le tutoriel Comment déployer des LLM avec BentoML pour en savoir plus sur l'écosystème BentoML et sur la manière de déployer de petits modèles LLM.
BentoCloud est une plateforme sans serveur construite au-dessus de BentoML qui est conçue pour rationaliser le déploiement et la gestion des modèles d'apprentissage automatique. Il offre une infrastructure robuste optimisée pour l'inférence de l'IA, ce qui le rend particulièrement adapté aux LLM.
Avec BentoCloud, les utilisateurs peuvent déployer des solutions d'IA évolutives et efficaces dans des environnements cloud sans se soucier de la gestion de l'infrastructure.
Passons maintenant à la suite du projet. Nous allons créer les composants suivants :
app.py pour définir l'API de service de modèle avec vLLM et FastAPI.requirements.txt pour spécifier les paquets Python nécessaires à l'installation dans l'environnement cloud.bentofile.yaml pour configurer l'infrastructure, construire des images Docker et mettre en place l'environnement de déploiement.Nous allons commencer par installer le paquetage Python de BentoML à l'aide de la commande pip:
pip install bentomlDans le fichier d'application Python, nous allons configurer le point de terminaison du modèle en procédant comme suit :
bentoml, fastapi, et vllm.Ajoutez le code ci-dessous à votre site app.py:
# Standard library imports
import uuid
from argparse import Namespace
from typing import AsyncGenerator, Optional
# Third-party imports
import bentoml
import fastapi
from annotated_types import Ge, Le
from typing_extensions import Annotated
# Initialize FastAPI application
openai_api_app = fastapi.FastAPI()
# Constants
MAX_MODEL_LEN = 8192
MAX_TOKENS = 1024
SYSTEM_PROMPT = """You are a helpful and respectful assistant. Provide safe, unbiased, and accurate answers.
If a question is unclear or you don't know the answer, explain why instead of guessing."""
MODEL_ID = "casperhansen/llama-3.3-70b-instruct-awq"
# Define OpenAI-compatible API endpoints
OPENAI_ENDPOINTS = [
["/chat/completions", "create_chat_completion", ["POST"]],
["/completions", "create_completion", ["POST"]],
["/models", "show_available_models", ["GET"]],
]
@bentoml.mount_asgi_app(openai_api_app, path="/v1")
@bentoml.service(
name="llama3.3-70b-instruct-awq",
traffic={
"timeout": 1200,
"concurrency": 256,
},
resources={
"gpu": 1,
"gpu_type": "nvidia-a100-80gb",
},
)
class BentoVLLM:
def __init__(self) -> None:
"""Initialize the BentoVLLM service with VLLM engine and tokenizer."""
import vllm.entrypoints.openai.api_server as vllm_api_server
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
# Configure VLLM engine arguments
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_MODEL_LEN,
enable_prefix_caching=True,
)
# Initialize engine and tokenizer
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
# Register API endpoints
for route, endpoint_name, methods in OPENAI_ENDPOINTS:
endpoint_func = getattr(vllm_api_server, endpoint_name)
openai_api_app.add_api_route(
path=route,
endpoint=endpoint_func,
methods=methods,
)
# Configure model arguments
model_config = self.engine.engine.get_model_config()
args = Namespace(
model=MODEL_ID,
disable_log_requests=True,
max_log_len=1000,
response_role="assistant",
served_model_name=None,
chat_template=None,
lora_modules=None,
prompt_adapters=None,
request_logger=None,
disable_log_stats=True,
return_tokens_as_token_ids=False,
enable_tool_call_parser=True,
enable_auto_tool_choice=True,
tool_call_parser="llama3_json",
enable_prompt_tokens_details=False,
)
# Initialize application state
vllm_api_server.init_app_state(
self.engine, model_config, openai_api_app.state, args
)
@bentoml.api
async def generate(
self,
prompt: str = "Describe the process of photosynthesis in simple terms",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
"""
Generate text based on the input prompt using the VLLM engine.
Args:
prompt: The user's input prompt
system_prompt: Optional system prompt to guide the model's behavior
max_tokens: Maximum number of tokens to generate
Returns:
AsyncGenerator yielding generated text chunks
"""
from vllm import SamplingParams
# Configure sampling parameters
SAMPLING_PARAM = SamplingParams(
max_tokens=max_tokens,
skip_special_tokens=True,
)
# Use default system prompt if none provided
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
# Prepare messages for chat
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
# Apply chat template
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# Generate response stream
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
# Stream the generated text
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Créez un fichier requirements.txt et incluez tous les paquets Python nécessaires pour construire l'application AI. Précisez les versions exactes de chaque paquetage afin de maintenir la stabilité et la reproductibilité du projet.
Voici à quoi devrait ressembler le site requirements.txt:
accelerate==1.2.0
autoawq==0.2.7.post3
bentoml>=1.3.15
fastapi==0.115.6
openai==1.57.0
vllm==0.6.4.post1; sys_platform == "linux"Le fichier bentofile.yaml est le fichier de configuration utilisé pour définir et construire le service BentoML. Il comprend les éléments suivants :
app.py) et le nom de la classe de service (BentoVLLM).requirements.txt.Ajoutez le contenu suivant à votre fichier bentofile.yaml:
service: 'app:BentoVLLM'
labels:
owner: Abid
team: DataCamp
stage: dev
include:
- '*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"C'est maintenant que la magie opère : BentoCloud fera tout pour nous, et nous n'aurons qu'à taper une seule commande. Mais avant cela, nous devons nous connecter à BentoCloud en tapant la commande suivante dans le terminal.
bentoml cloud login
L'outil CLI vous posera quelques questions et vous redirigera ensuite vers le site Web de BentoCloud pour créer un compte et générer la clé API.
Une fois que vous avez fait cela, la clé API sera automatiquement appliquée à vos outils CLI.
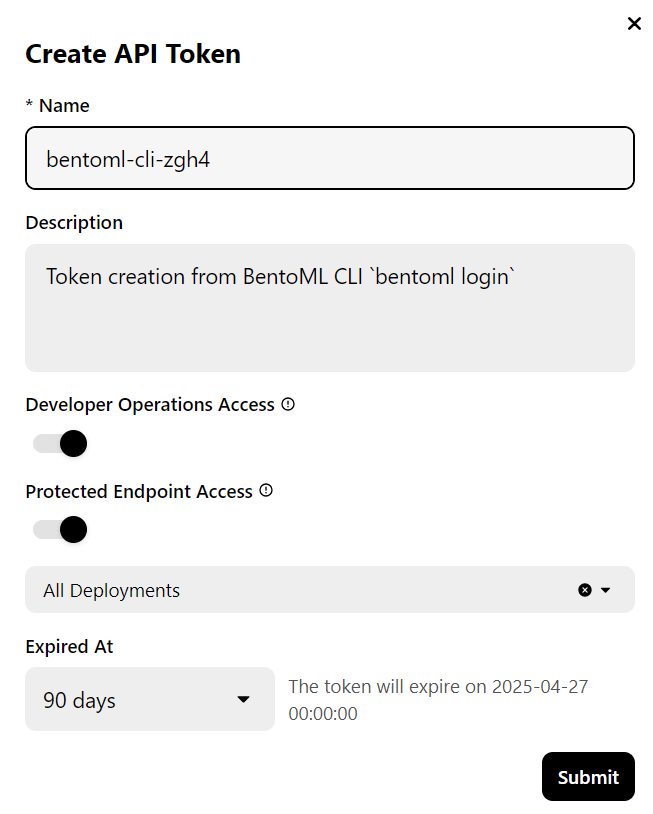
Note : Le déploiement de la version complète du modèle 70B nécessite 80 Go de mémoire GPU. Bien que BentoCloud fournisse 10 USD de crédits gratuits, vous devrez souscrire au plan pro pour accéder aux GPU A100 avec 80 Go de VRAM.
Pour vous abonner, rendez-vous dans l'onglet "Facturation" en cliquant sur votre photo de profil dans le coin supérieur droit et ajoutez les détails de votre carte de crédit.
Ne vous inquiétez pas ; si vous faites attention aux déploiements, cela ne vous coûtera pas plus de 6 USD. Mais veillez à mettre fin au déploiement lorsque vous avez terminé vos expériences !
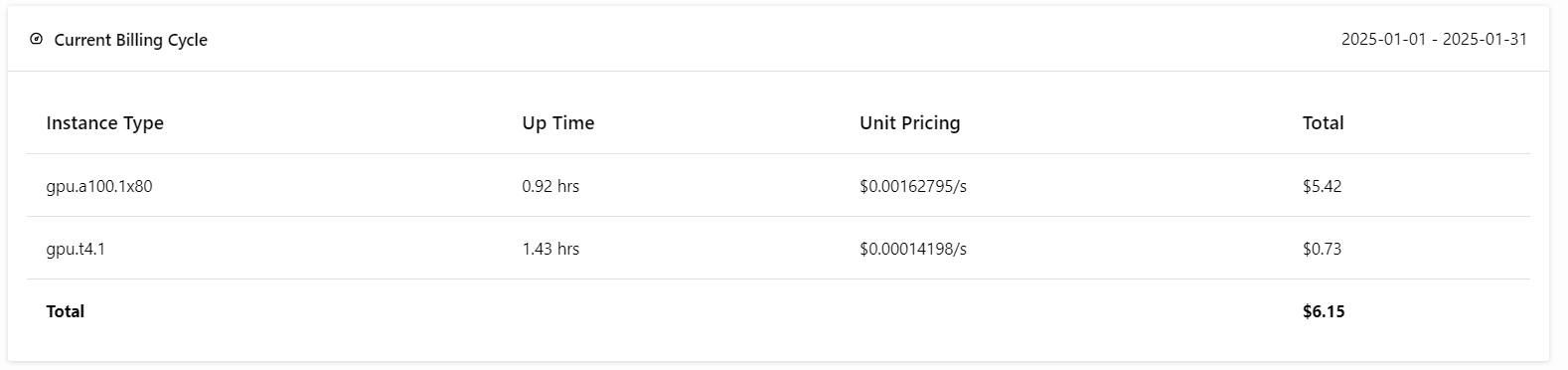
Vient maintenant la meilleure partie : nous allons déployer l'application BentoML sur le cloud à l'aide de la commande suivante et activer l'autorisation d'accès. Cela signifie que seuls les utilisateurs possédant la clé API de BentoML peuvent accéder à ce serveur API.
bentoml deploy . --access-authorization trueIl faudra quelques secondes pour que tous les fichiers, configurations et autres composants nécessaires soient envoyés, après quoi BentoCloud s'occupera du reste.

Pour visualiser les déploiements en cours, accédez à votre tableau de bord BentoCloud et cliquez sur l'onglet "Déploiements". Par exemple, l'image ci-dessous montre l'application dans le processus de "construction d'images" :
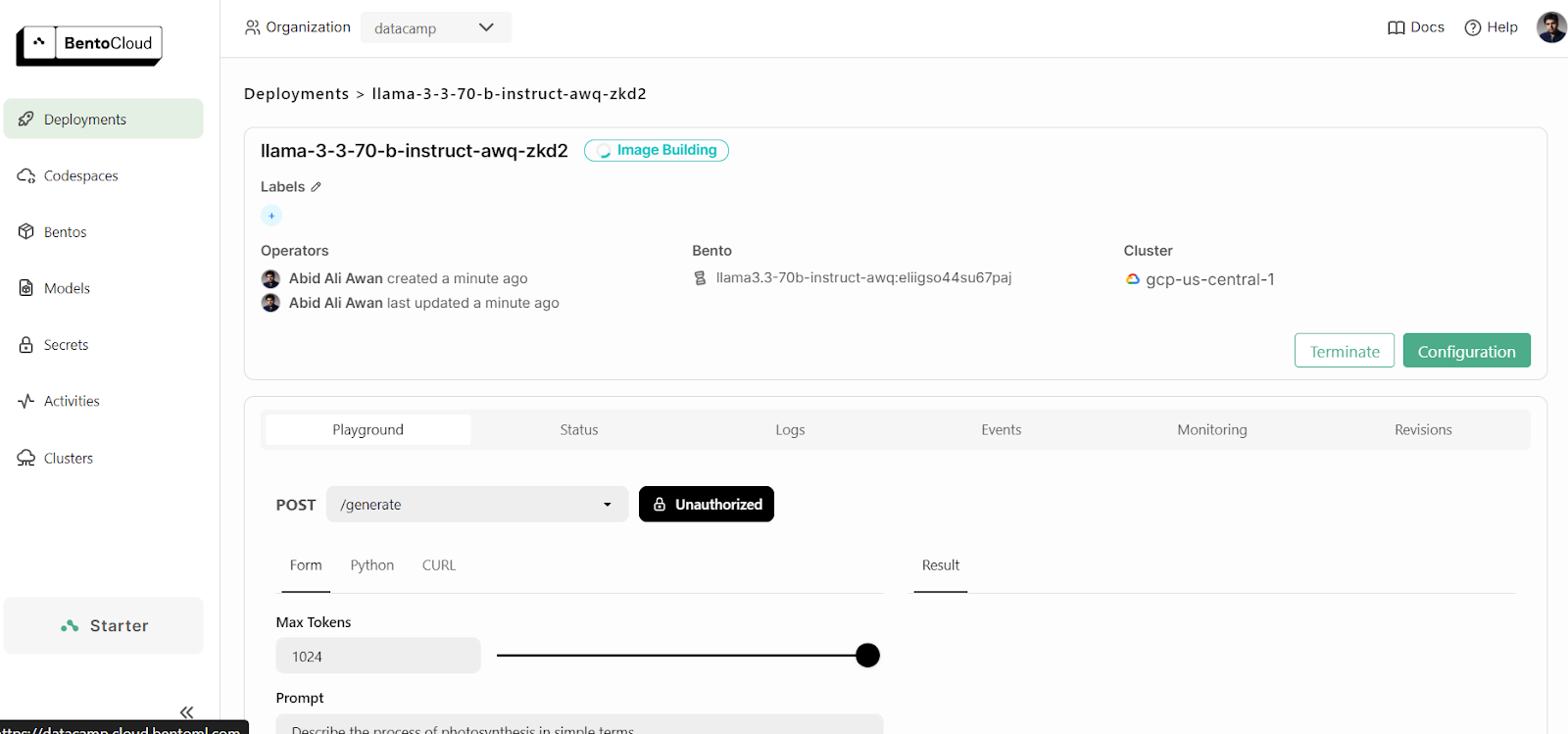
Après quelques minutes de construction de l'image, de mise en place de l'infrastructure et de déploiement du modèle, notre application est prête à être utilisée !
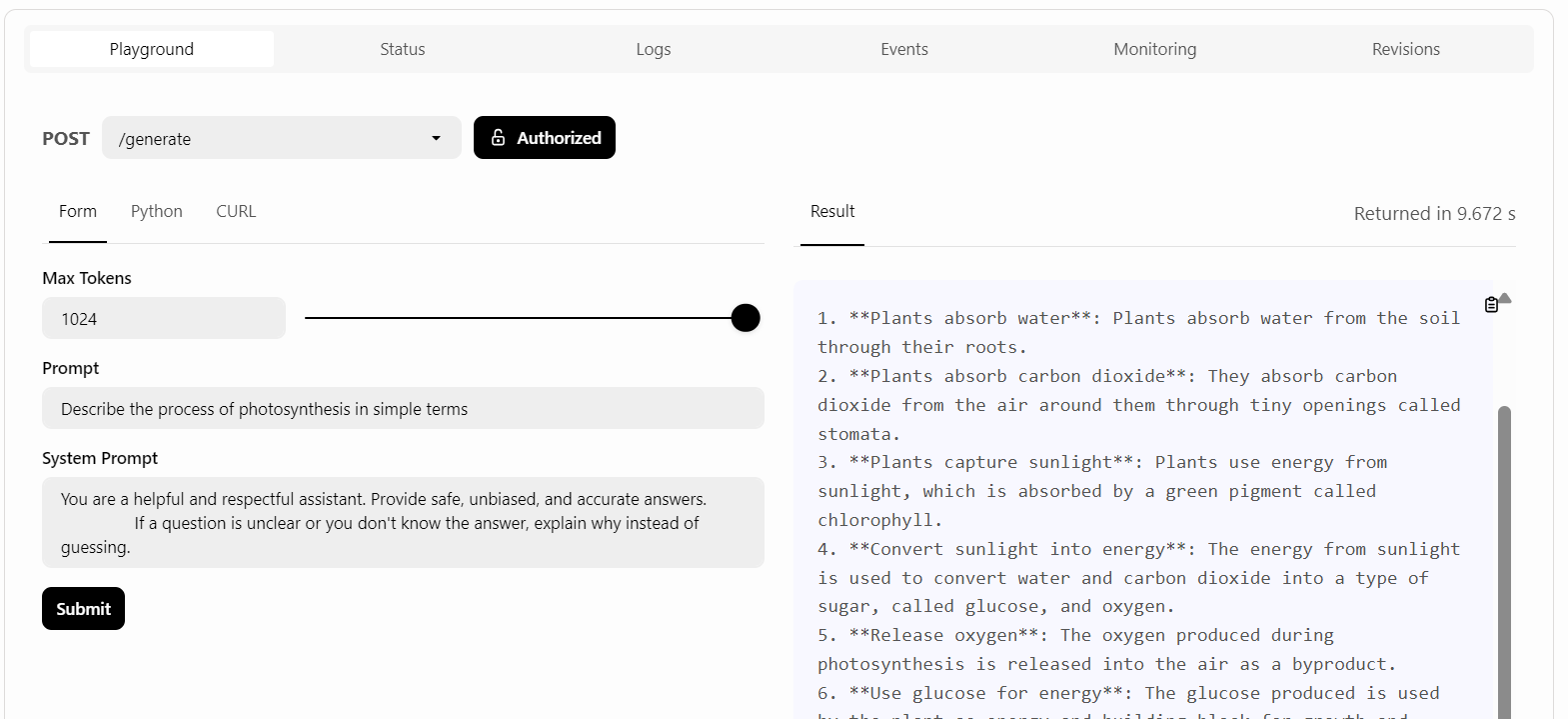
BentoCloud propose une interface utilisateur Playground pour tester votre modèle sur le tableau de bord, à l'instar de la plateforme OpenAI. Comme notre service est restreint, nous devrons fournir une clé API pour accéder au modèle dans le terrain de jeu, comme indiqué ci-dessous :
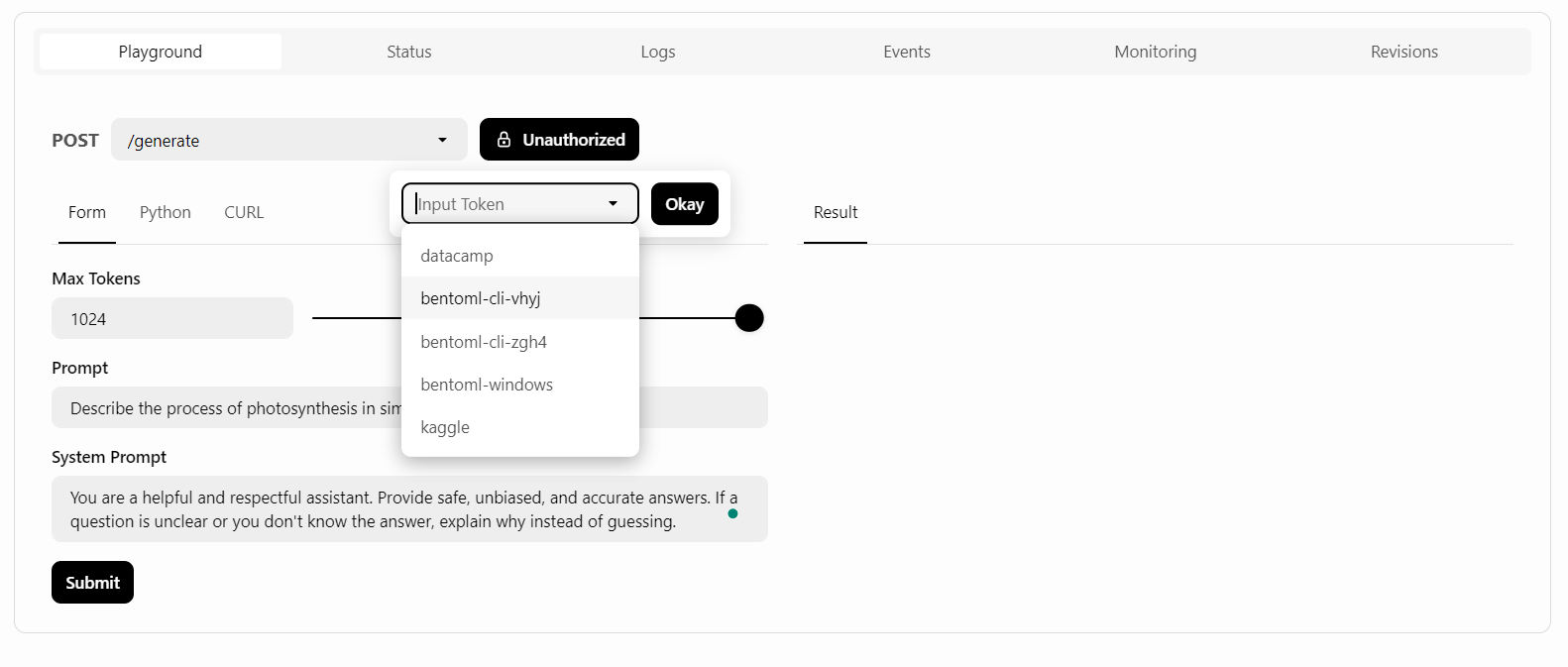
Ensuite, nous rédigerons l'invite et cliquerons sur le bouton "Soumettre".
La réponse a été rapide et précise :
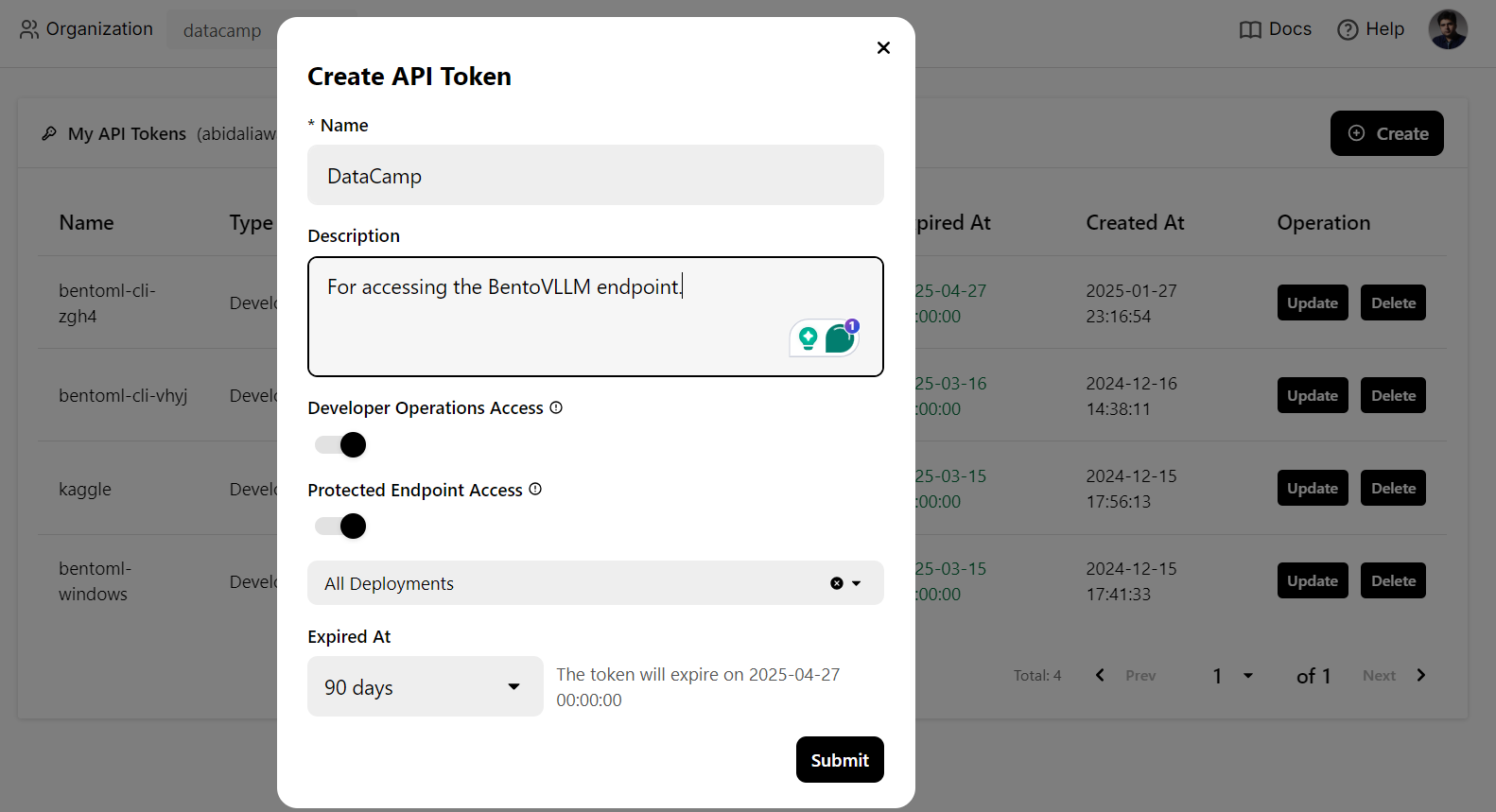
Nous utiliserons une commande CURL dans le terminal pour accéder au service LLM localement. Mais avant cela, nous devons générer une nouvelle clé API pour utiliser ce service sur n'importe quel système :
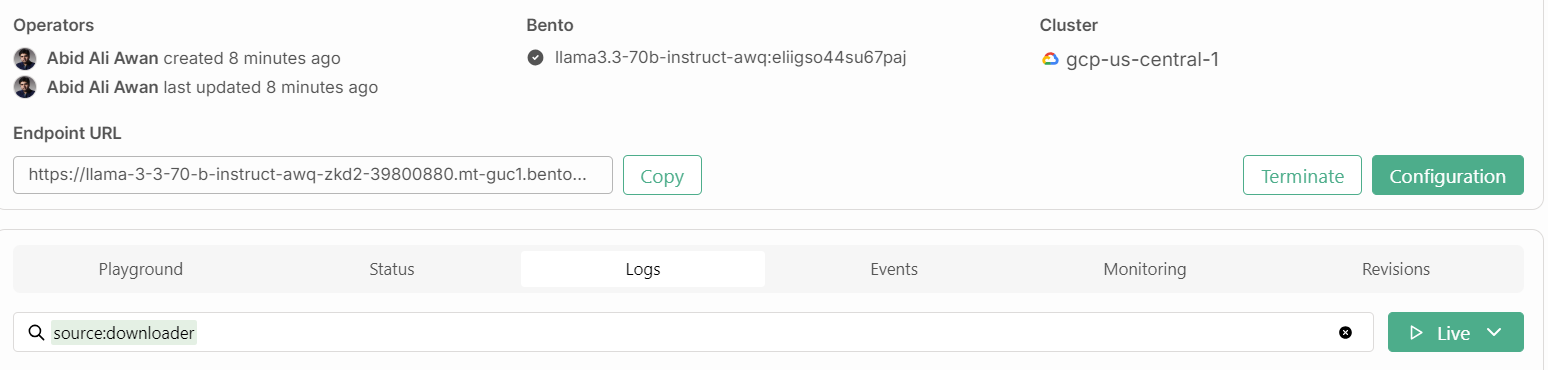
Nous aurons également besoin de l'URL du point de terminaison que nous pouvons copier à partir de l'onglet "Déploiements" :
Une fois que vous disposez de la clé API et de l'URL du point final, vous pouvez générer une réponse à l'aide de la commande CURL suivante.
La commande comprend l'URL du point final, la clé API, l'argument max_tokens et l'argument prompt:
curl -s -X POST \
'https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/generate' \
-H "Authorization: Bearer $(echo $BENTO_CLOUD_API_KEY)" \
-H 'Content-Type: application/json' \
-d '{
"max_tokens": 1024,
"prompt": "Describe the process of photosynthesis in simple terms"
}'La réponse est précise, et il a fallu quelques envois pour la générer.

Le point de terminaison BentoML est compatible avec le client OpenAI Python. Vous n'avez pas besoin de modifier votre code de manière significative pour intégrer ce modèle open-source dans votre application.
Il vous suffit de modifier l'URL de base, de fournir la clé API et de spécifier le nom du modèle :
import os
from openai import OpenAI
BENTOML_API_KEY = os.getenv("BENTO_CLOUD_API_KEY") #
if BENTOML_API_KEY is None:
raise ValueError("BENTOML_API_KEY environment variable is not set.")
client = OpenAI(
base_url="https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/v1",
api_key=BENTOML_API_KEY,
)
chat_completion = client.chat.completions.create(
model="casperhansen/llama-3.3-70b-instruct-awq",
messages=[
{"role": "user", "content": "What is a black hole and how does it work?"}
],
stream=True,
stop=["<|eot_id|>", "<|end_of_text|>"],
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")
Veuillez consulter le dépôt GitHub kingabzpro/Deploying-Llama-3.3-70B, qui contient le fichier d'application, les configurations et les codes d'inférence.
Sur BentCloud, vous pouvez surveiller les performances du modèle, la latence, l'utilisation du matériel, le débit du modèle et d'autres mesures critiques sans avoir à configurer d'outils de journalisation ou de surveillance.
Allez dans vos déploiements et cliquez sur l'onglet "Monitoring".
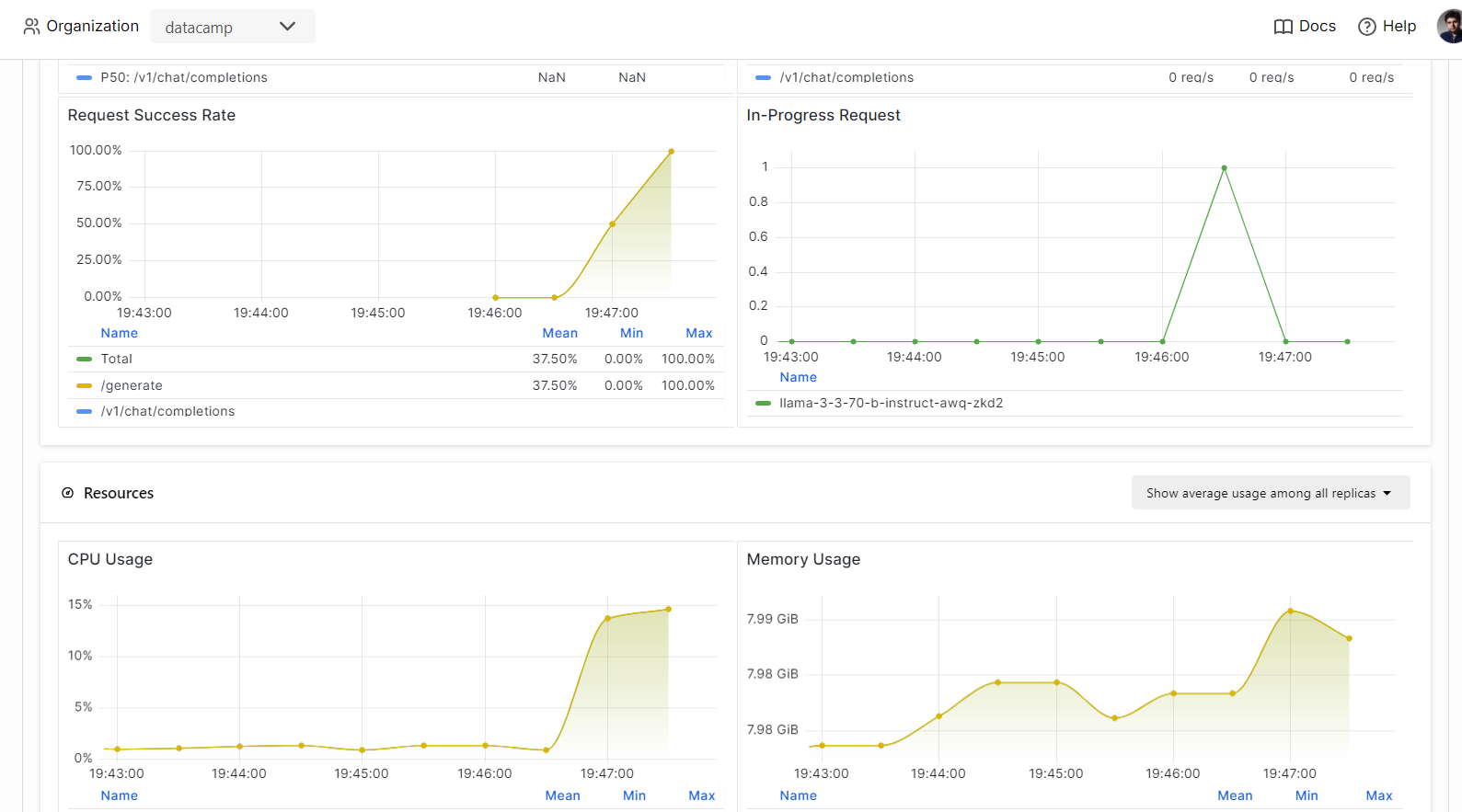
Faites défiler vers le bas pour voir les mesures relatives aux services, aux ressources et au LLM dans des graphiques intuitifs et directs.
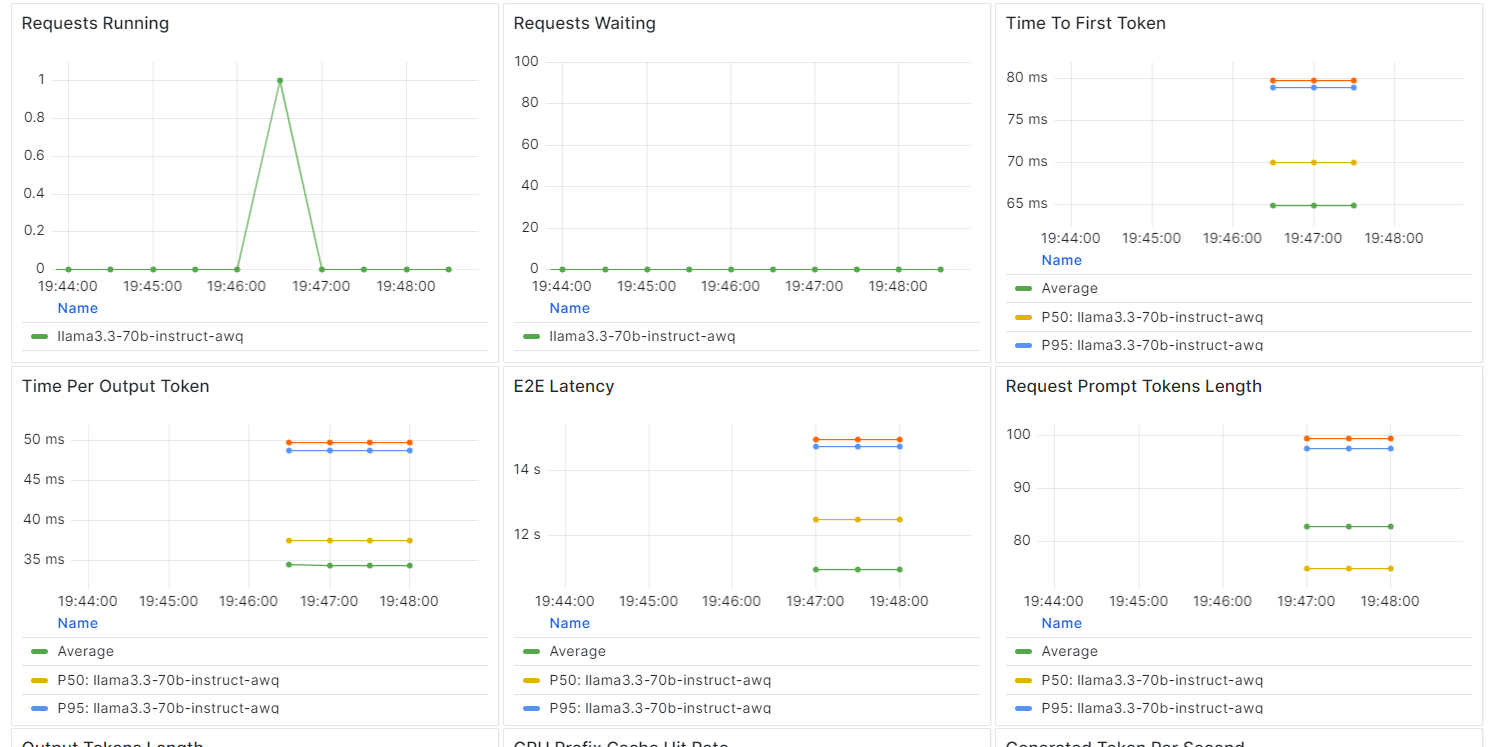
La construction et le déploiement d'un point final LLM sont devenus remarquablement simples grâce à l'écosystème BentoML.
En écrivant seulement quelques lignes de code pour créer votre API, en configurant un "bentofile" et en déployant le modèle, vous pouvez avoir votre modèle opérationnel en quelques minutes. Une fois déployé, le point de terminaison est accessible via des commandes CURL, la bibliothèque de requêtes Python, le client BentoML ou le client OpenAI.
Le résultat est un système très efficace, à faible latence et à haut débit, capable de traiter plusieurs demandes simultanément. BentoCloud offre également une mise à l'échelle automatique basée sur votre configuration, garantissant que le système peut gérer des volumes de trafic élevés en augmentant ou en réduisant l'échelle en fonction des besoins.
Pour un guide plus approfondi sur le déploiement des LLM avec BentoML, je vous recommande de suivre le site How to Deploy LLMs with BentoML (Comment déployer des LLM avec BentoML) : Un guide étape par étape.
Apprenez-en plus sur l'IA et les LLM grâce à ces cours !
Cours
Cours
Cours