
Course
MLOps Concepts
2 hr
42.7K
Deploying large language models (LLMs) is becoming increasingly challenging as these models require high-end GPU machines with significant VRAM. Engineers must also master MLOps tools to handle tasks such as serving, deploying, testing, and monitoring the models. On top of that, they need to implement access restrictions and maintain security to protect against cyber threats and prompt injection attacks. Life as an LLMOps engineer can be tough—but don’t worry; we’ve got you covered!
In this tutorial, we will explore a simpler and more efficient solution for deploying LLMs, such as Llama 3.3 70B, on the cloud. With just a few lines of Python code and some terminal commands, your model will be up and running. BentoCloud streamlines and manages everything, making the deployment process straightforward and secure.

If you’re a beginner, I recommend taking the Introduction to LLMs in Python course to understand the basics of large language models.
The new Meta Llama 3.3 is a text-only (70B) instruction-tuned multilingual large language model (LLM) that offers improved performance compared to Llama 3.1 (70B) and Llama 3.2 (90B). In some cases, it has even outperformed the larger Llama 3.1 (405B). This model is text-only and optimized for multilingual dialogue use cases.
Llama 3.3 is an auto-regressive language model built on an optimized transformer architecture. It has been fine-tuned using supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to better align with human preferences for helpfulness and safety.
Learn more about Llama 3.3 by reading the What Is Meta's Llama 3.3 70B? How It Works, Use Cases & More blog post.
Learn how to work with LLMs in Python right in your browser

In this project, we will use BentoML to build the AI service, vLLM for high-throughput model serving, and BentoCloud for robust infrastructure and deployment. Additionally, we will deploy the AWQ version of the model to optimize performance.
In short, vLLM combined with AWQ creates a deadly combination for building LLM applications that are super fast and capable of handling multiple requests simultaneously.
AWQ (Activation-aware Weight Quantization) is an innovative quantization technique designed to enhance the deployment of large language models. It achieves this by significantly reducing memory usage and improving inference speed, all while maintaining high accuracy.
Read the research paper to learn about AWQ technology and how it optimizes model inference while maintaining accuracy.
vLLM (Virtual Large Language Model) is an open-source library specifically designed to optimize the inference and serving of large language models. It addresses critical challenges such as throughput and memory efficiency by introducing advanced techniques like PagedAttention, which ensures efficient attention key-value memory management.
Learn more about the vLLM Python package by following the vLLM: Setting Up vLLM Locally and on Google Cloud for CPU tutorial.
BentoML is an open-source machine learning model serving framework that serves as the backbone of the LLM deployment pipeline. It simplifies the process of packaging, deploying, and managing machine learning models, including LLMs, in production.
Follow the How to Deploy LLMs with BentoML tutorial to learn about the BentoML ecosystem and how to deploy smaller LLM models.
BentoCloud is a serverless platform built on top of BentoML that is designed to streamline the deployment and management of machine learning models. It offers a robust infrastructure optimized for AI inference, making it particularly well-suited for serving LLMs.
With BentoCloud, users can deploy scalable and efficient AI solutions in cloud environments without worrying about infrastructure management.
Let’s now move forward with the project. We will create the following components:
app.py file to define the model serving API with vLLM and FastAPI.requirements.txt file to specify the necessary Python packages for installation in the cloud environment.bentofile.yaml file to configure the infrastructure, build Docker images, and set up the deployment environment.We will start by installing the BentoML Python package using the pip command:
pip install bentomlIn the Python application file, we will set up the model endpoint by doing the following:
bentoml, fastapi, and vllm.Add the code below to your app.py:
# Standard library imports
import uuid
from argparse import Namespace
from typing import AsyncGenerator, Optional
# Third-party imports
import bentoml
import fastapi
from annotated_types import Ge, Le
from typing_extensions import Annotated
# Initialize FastAPI application
openai_api_app = fastapi.FastAPI()
# Constants
MAX_MODEL_LEN = 8192
MAX_TOKENS = 1024
SYSTEM_PROMPT = """You are a helpful and respectful assistant. Provide safe, unbiased, and accurate answers.
If a question is unclear or you don't know the answer, explain why instead of guessing."""
MODEL_ID = "casperhansen/llama-3.3-70b-instruct-awq"
# Define OpenAI-compatible API endpoints
OPENAI_ENDPOINTS = [
["/chat/completions", "create_chat_completion", ["POST"]],
["/completions", "create_completion", ["POST"]],
["/models", "show_available_models", ["GET"]],
]
@bentoml.mount_asgi_app(openai_api_app, path="/v1")
@bentoml.service(
name="llama3.3-70b-instruct-awq",
traffic={
"timeout": 1200,
"concurrency": 256,
},
resources={
"gpu": 1,
"gpu_type": "nvidia-a100-80gb",
},
)
class BentoVLLM:
def __init__(self) -> None:
"""Initialize the BentoVLLM service with VLLM engine and tokenizer."""
import vllm.entrypoints.openai.api_server as vllm_api_server
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
# Configure VLLM engine arguments
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_MODEL_LEN,
enable_prefix_caching=True,
)
# Initialize engine and tokenizer
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
# Register API endpoints
for route, endpoint_name, methods in OPENAI_ENDPOINTS:
endpoint_func = getattr(vllm_api_server, endpoint_name)
openai_api_app.add_api_route(
path=route,
endpoint=endpoint_func,
methods=methods,
)
# Configure model arguments
model_config = self.engine.engine.get_model_config()
args = Namespace(
model=MODEL_ID,
disable_log_requests=True,
max_log_len=1000,
response_role="assistant",
served_model_name=None,
chat_template=None,
lora_modules=None,
prompt_adapters=None,
request_logger=None,
disable_log_stats=True,
return_tokens_as_token_ids=False,
enable_tool_call_parser=True,
enable_auto_tool_choice=True,
tool_call_parser="llama3_json",
enable_prompt_tokens_details=False,
)
# Initialize application state
vllm_api_server.init_app_state(
self.engine, model_config, openai_api_app.state, args
)
@bentoml.api
async def generate(
self,
prompt: str = "Describe the process of photosynthesis in simple terms",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
"""
Generate text based on the input prompt using the VLLM engine.
Args:
prompt: The user's input prompt
system_prompt: Optional system prompt to guide the model's behavior
max_tokens: Maximum number of tokens to generate
Returns:
AsyncGenerator yielding generated text chunks
"""
from vllm import SamplingParams
# Configure sampling parameters
SAMPLING_PARAM = SamplingParams(
max_tokens=max_tokens,
skip_special_tokens=True,
)
# Use default system prompt if none provided
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
# Prepare messages for chat
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
# Apply chat template
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# Generate response stream
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
# Stream the generated text
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Create a requirements.txt file and include all the necessary Python packages to build the AI application. Specify the exact versions of each package to maintain the project's stability and reproducibility.
Here’s how the requirements.txt should look:
accelerate==1.2.0
autoawq==0.2.7.post3
bentoml>=1.3.15
fastapi==0.115.6
openai==1.57.0
vllm==0.6.4.post1; sys_platform == "linux"The bentofile.yaml file is the configuration file used to define and build the BentoML service. It includes the following components:
app.py) and the service class name (BentoVLLM).requirements.txt file.Add the following contents to your bentofile.yaml file:
service: 'app:BentoVLLM'
labels:
owner: Abid
team: DataCamp
stage: dev
include:
- '*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"Now comes the magical part: BentoCloud will do everything for us, and we just have to type one command. But before that, we have to log in to BentoCloud by typing the following command in the terminal.
bentoml cloud login
The CLI tool will ask you a few questions and then redirect you to the BentoCloud website to create an account and generate the API key.
Once you have done that, it will automatically apply the API key to your CLI tools.
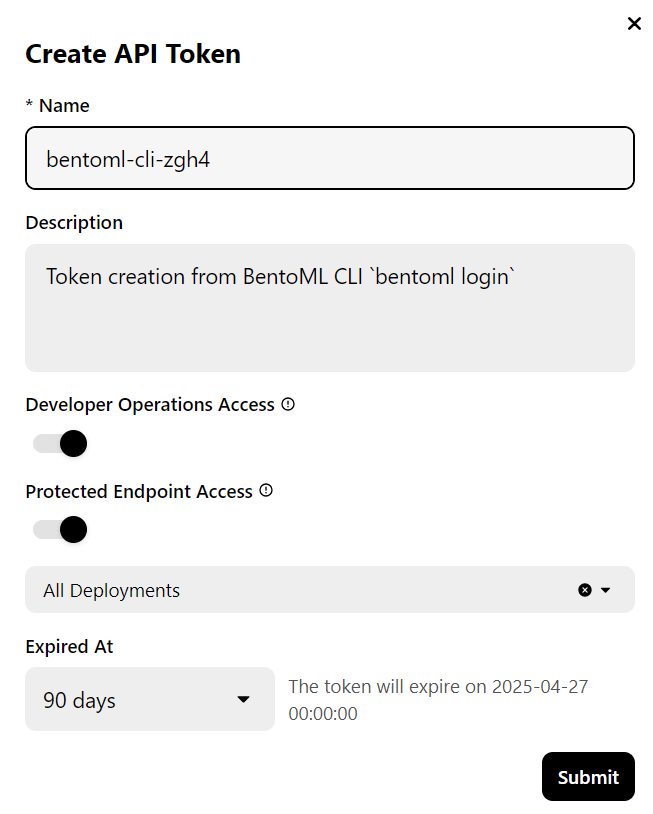
Note: Deploying the full version of the 70B model requires 80GB of GPU memory. Although BentoCloud provides 10 USD in free credits, you will need to subscribe to the pro plan to access the A100 GPUs with 80GB of VRAM.
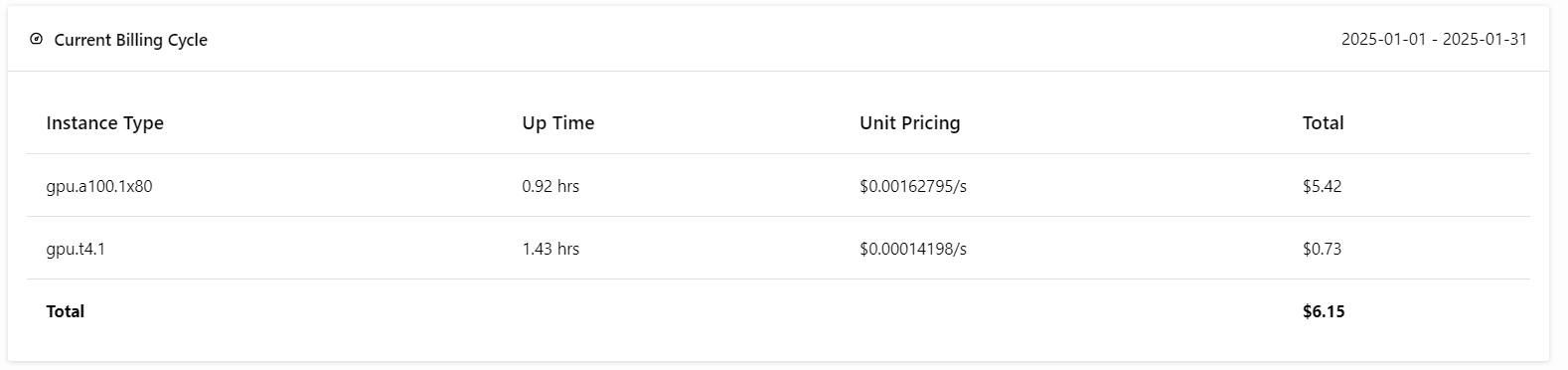
To subscribe, go to the “Billing” tab by clicking on your profile picture in the top right corner and adding your credit card details.
Don't worry; if you are careful about deployments, it won't cost you more than $6 USD. But make sure to terminate the deployment when you are finished experimenting!
Now comes the best part: we will deploy the BentoML application to the cloud using the following command and enable access authorization. This means that only users with the BentoML API key can access this API server.
bentoml deploy . --access-authorization trueIt will take a few seconds for all the files, configurations, and other necessary components to be sent, after which BentoCloud will manage the rest.

To view your current running deployments, go to your BentoCloud dashboard and click the “Deployments” tab. For example, the below image shows the application in the “Image Building” process:
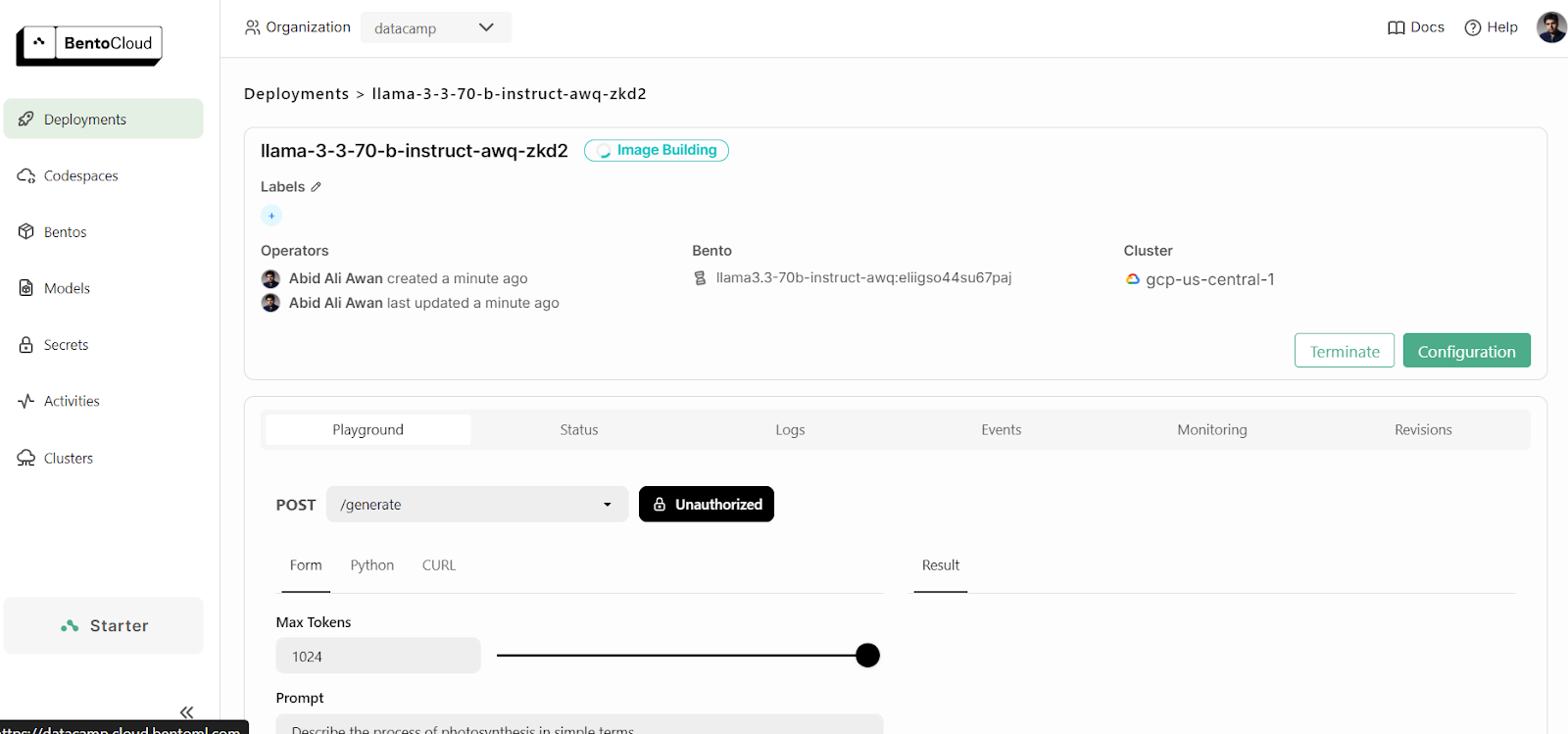
After a few more minutes of building the image, setting up the infrastructure, and deploying the model, our application is ready to be used!
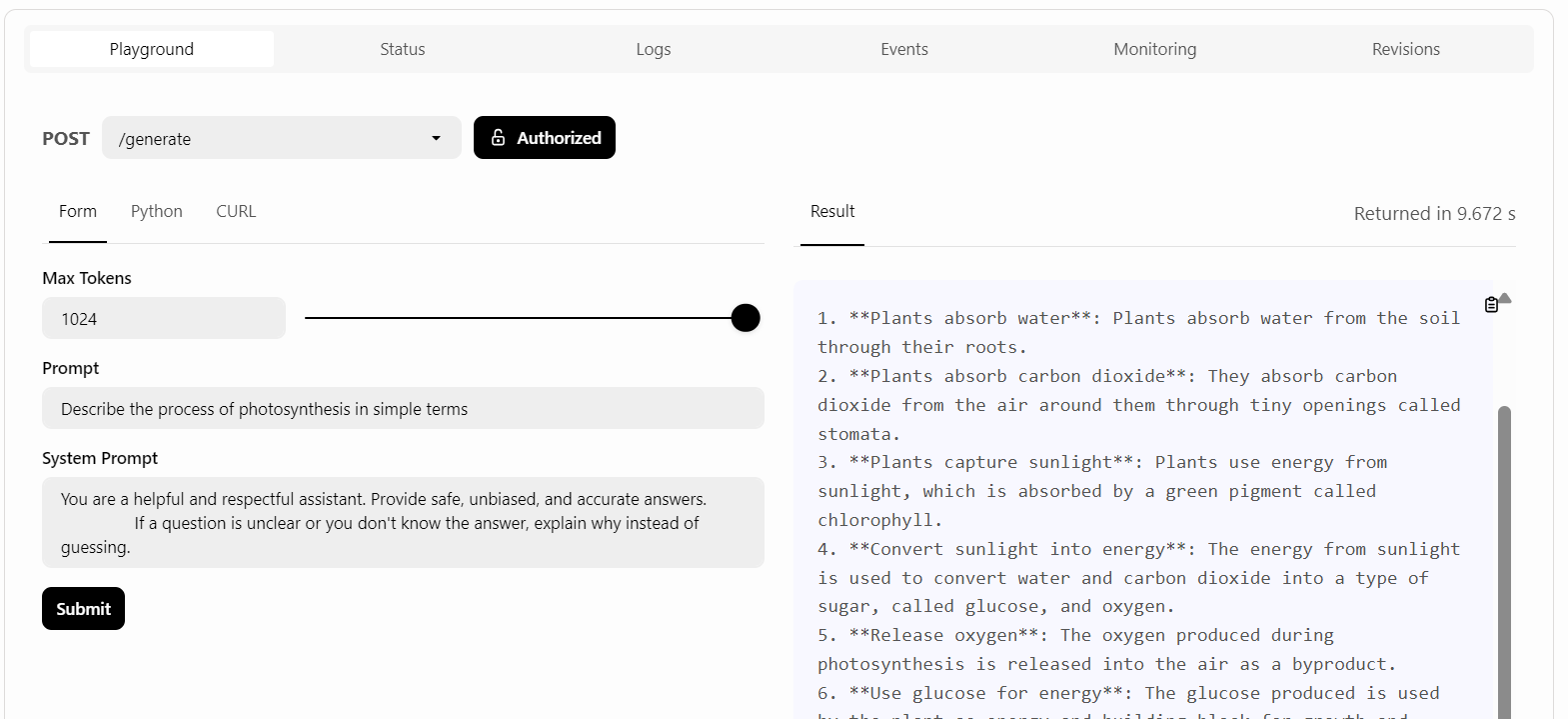
BentoCloud provides a Playground UI to test your model on the dashboard, similar to the OpenAI platform. Since our service is restricted, we will need to provide an API key to access the model in the Playground, as shown below:
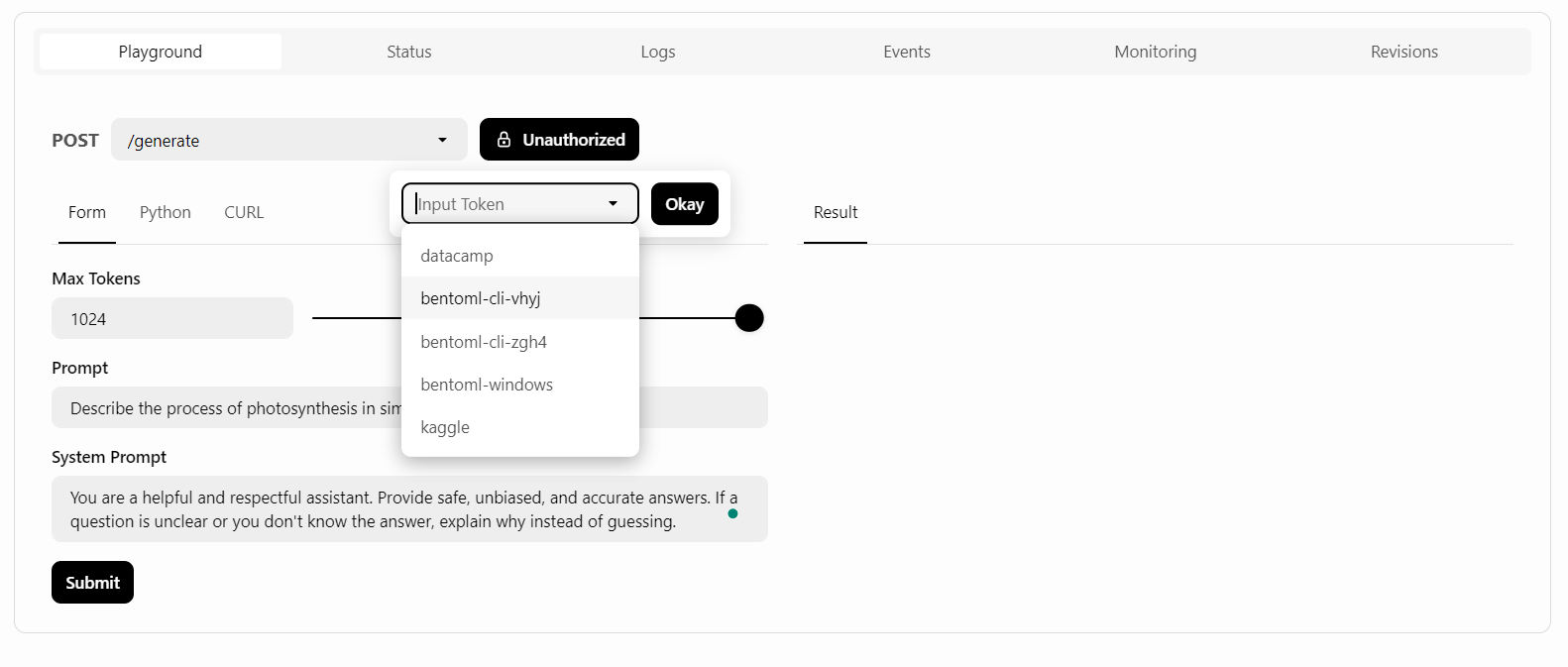
After that, we will write the prompt and click the “Submit” button.
The response generation was quick and accurate:
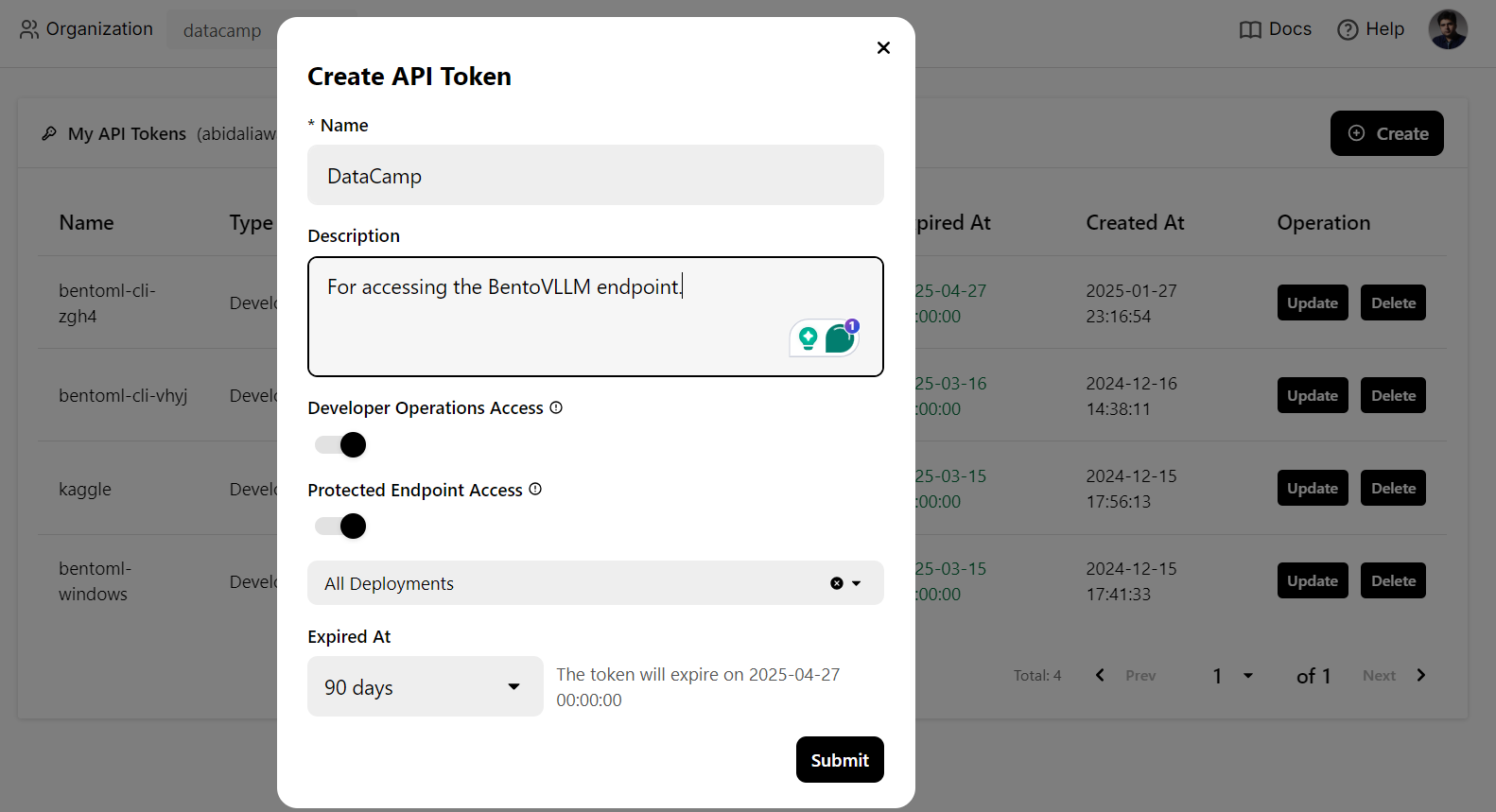
We will use a CURL command in the terminal to access the LLM service locally. But before that, we need to generate a new API key to use this service on any system:
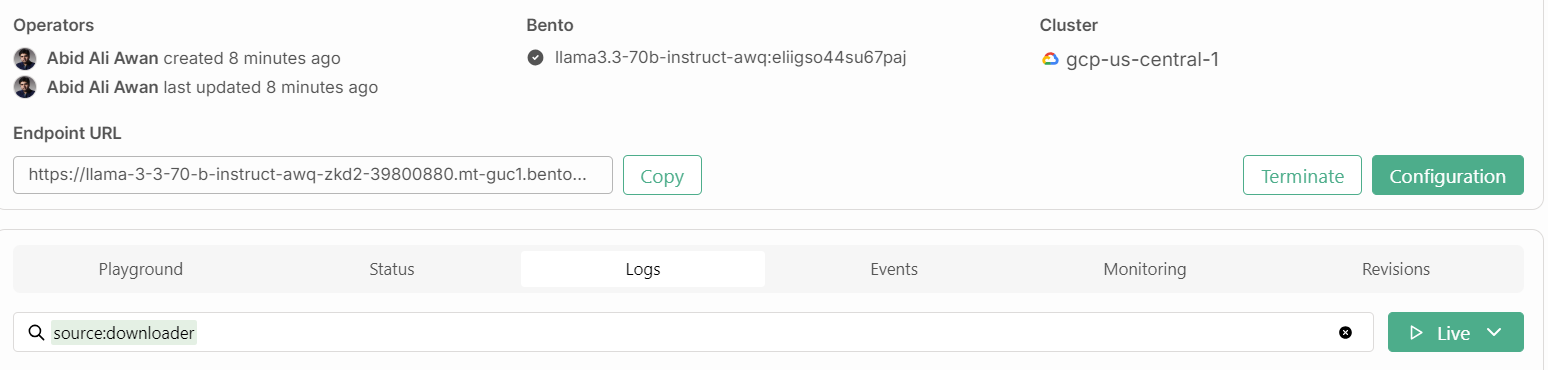
Also, we will need the endpoint URL that we can copy from the “Deployments” tab:
Once you have the API key and endpoint URL, you can generate a response using the following CURL command.
The command includes the endpoint URL, API key, max_tokens argument, and the prompt:
curl -s -X POST \
'https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/generate' \
-H "Authorization: Bearer $(echo $BENTO_CLOUD_API_KEY)" \
-H 'Content-Type: application/json' \
-d '{
"max_tokens": 1024,
"prompt": "Describe the process of photosynthesis in simple terms"
}'The response is accurate, and it took a couple of sending to generate it.

The BentoML endpoint is compatible with the OpenAI Python client. You don’t have to modify your code significantly to integrate this open-source model into your application.
All you need to do is change the base URL, provide the API key, and specify the model name:
import os
from openai import OpenAI
BENTOML_API_KEY = os.getenv("BENTO_CLOUD_API_KEY") #
if BENTOML_API_KEY is None:
raise ValueError("BENTOML_API_KEY environment variable is not set.")
client = OpenAI(
base_url="https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/v1",
api_key=BENTOML_API_KEY,
)
chat_completion = client.chat.completions.create(
model="casperhansen/llama-3.3-70b-instruct-awq",
messages=[
{"role": "user", "content": "What is a black hole and how does it work?"}
],
stream=True,
stop=["<|eot_id|>", "<|end_of_text|>"],
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")
Please check out the kingabzpro/Deploying-Llama-3.3-70B GitHub repository, which contains the application file, configurations, and inference codes.
On BentCloud, you can monitor model performance, latency, hardware usage, model throughput, and other critical metrics without setting up logging or monitoring tools.
Go to your deployments and click on the “Monitoring” tab.
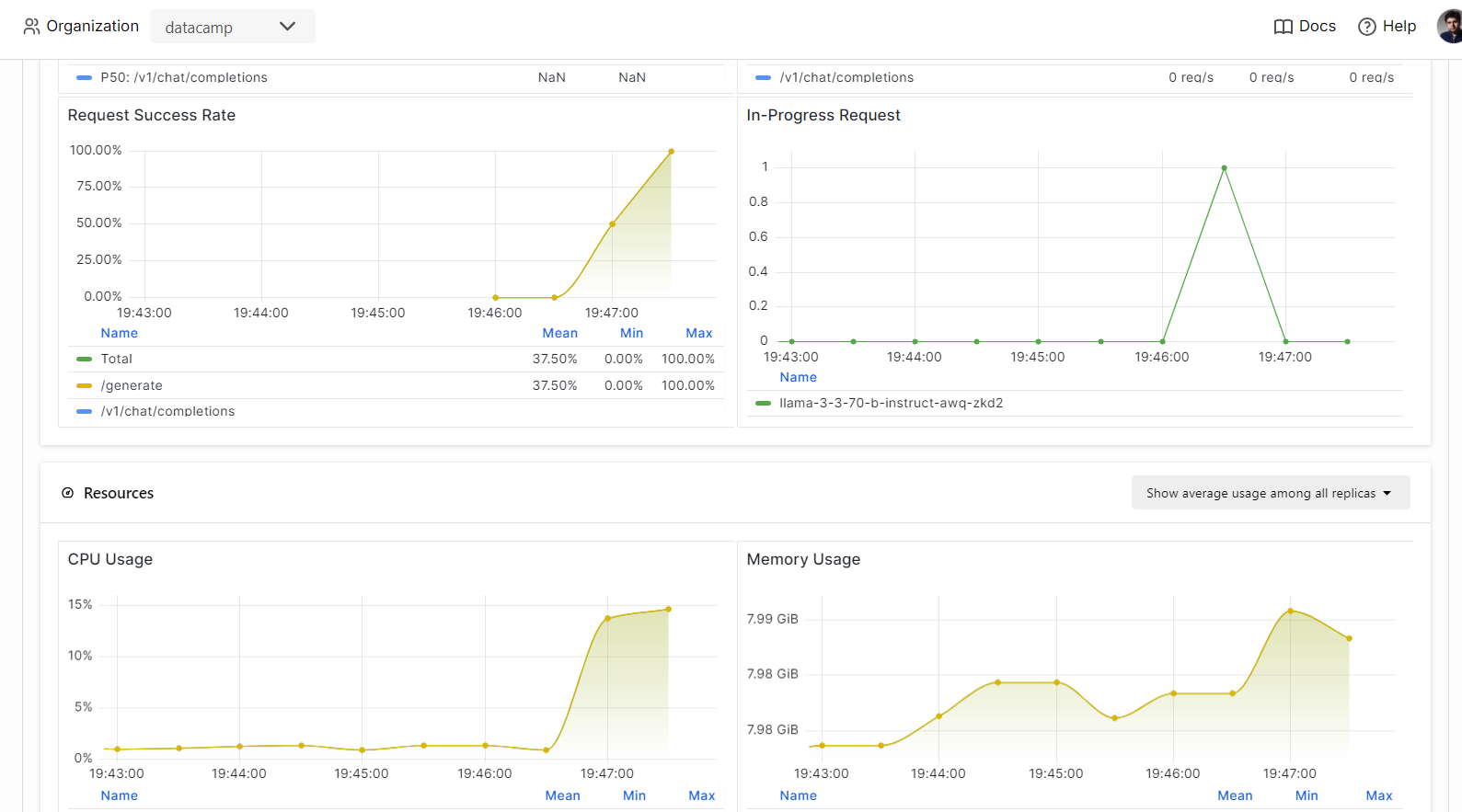
Scroll down to see the service, resource, and LLM-related metrics in intuitive, straightforward graphs.
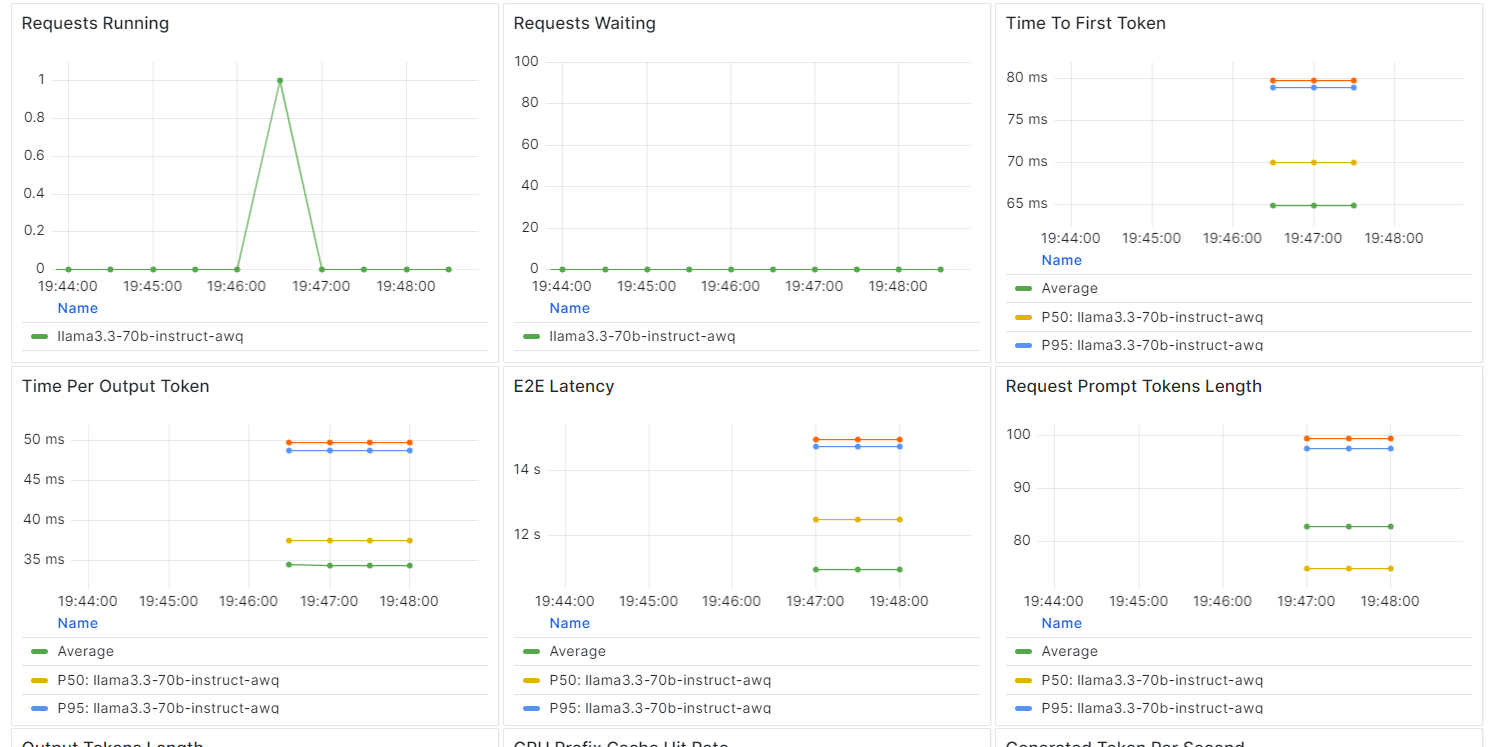
Building and deploying an LLM endpoint has become remarkably straightforward with the BentoML ecosystem.
By writing just a few lines of code to create your API, setting up a “bentofile”, and deploying the model, you can have your model up and running in minutes. Once deployed, the endpoint can be accessed via CURL commands, the Python requests library, the BentoML client, or the OpenAI client.
The result is a highly efficient, low-latency system with high throughput capable of handling multiple requests simultaneously. BentoCloud also offers auto-scaling based on your configuration, ensuring the system can handle high traffic volumes by scaling up or down as needed.
For a more in-depth guide on deploying LLMs with BentoML, I recommend following the How to Deploy LLMs with BentoML: A Step-by-Step Guide.
Learn more about AI and LLMs with these courses!
Course
Course
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan

