
Curso
Conceptos de MLOps
2 h
42.6K
El despliegue de grandes modelos lingüísticos (LLM) es cada vez más difícil, ya que estos modelos requieren máquinas GPU de gama alta con una importante VRAM. Los ingenieros también deben dominar las herramientas MLOps para gestionar tareas como servir, desplegar, probar y supervisar los modelos. Además, tienen que aplicar restricciones de acceso y mantener la seguridad para protegerse contra las ciberamenazas y los ataques de inyección rápida. La vida como ingeniero de LLMOps puede ser dura, pero no te preocupes, ¡te tenemos cubierto!
En este tutorial, exploraremos una solución más sencilla y eficaz para desplegar LLMs, como Llama 3.3 70B, en la nube. Con sólo unas pocas líneas de código Python y algunos comandos de terminal, tu modelo estará listo y funcionando. BentoCloud agiliza y gestiona todo, haciendo que el proceso de despliegue sea sencillo y seguro.

Si eres principiante, te recomiendo que sigasel curso Introducción a los LLM en Python para comprender los fundamentos de los grandes modelos lingüísticos.
El nuevo Meta Llama 3.3 es un modelo multilingüe de gran lenguaje (LLM) ajustado a instrucciones de sólo texto (70B) que ofrece un rendimiento mejorado en comparación con Llama 3.1 (70B) y Llama 3.2 (90B). En algunos casos, incluso ha superado a la mayor Llama 3.1 (405B). Este modelo es sólo de texto y está optimizado para casos de uso de diálogo multilingüe.
Llama 3.3 es un modelo de lenguaje autorregresivo construido sobre una arquitectura de transformadores optimizada. Se ha ajustado utilizando el ajuste fino supervisado (SFT) y el aprendizaje por refuerzo con retroalimentación humana (RLHF) para alinearse mejor con las preferencias humanas de utilidad y seguridad.
Obtén más información sobre Llama 3.3 leyendo ¿Qué es Llama 3.3 70B de Meta? Cómo funciona, casos de uso y más entrada de blog.
Aprende a trabajar con LLMs en Python directamente en tu navegador

En este proyecto, utilizaremos BentoML para construir el servicio de IA, vLLM para servir modelos de alto rendimiento, y BentoCloud para una infraestructura y despliegue robustos. Además, desplegaremos la versión AWQ del modelo para optimizar el rendimiento.
En resumen, vLLM combinado con AWQ crea una combinación mortal para construir aplicaciones LLM que sean superrápidas y capaces de gestionar múltiples peticiones simultáneamente.
AWQ (Activation-aware Weight Quantization) es una innovadora técnica de cuantificación diseñada para mejorar el despliegue de grandes modelos lingüísticos. Lo consigue reduciendo significativamente el uso de memoria y mejorando la velocidad de inferencia, todo ello manteniendo una gran precisión.
Lee el artículo de investigación para conocer la tecnología AWQ y cómo optimiza la inferencia de modelos manteniendo la precisión.
vLLM (Virtual Large Language Model) es una biblioteca de código abierto diseñada específicamente para optimizar la inferencia y el servicio de grandes modelos lingüísticos. Aborda retos críticos como el rendimiento y la eficiencia de la memoria introduciendo técnicas avanzadas como PagedAttention, que garantiza una gestión eficiente de la memoria clave-valor de atención.
Obtén más información sobre el paquete vLLM Python en vLLM: Configurar vLLM localmente y en Google Cloud para CPU tutorial.
BentoML es un marco de servidor de modelos de aprendizaje automático de código abierto que sirve de columna vertebral del conducto de despliegue de LLM. Simplifica el proceso de empaquetado, despliegue y gestión de modelos de aprendizaje automático, incluidos los LLM, en producción.
Sigue el tutorial Cómo desplegar LLM con BentoML para conocer el ecosistema BentoML y cómo desplegar modelos LLM más pequeños.
BentoCloud es una plataforma sin servidor construida sobre BentoML y diseñada para agilizar el despliegue y la gestión de modelos de aprendizaje automático. Ofrece una sólida infraestructura optimizada para la inferencia de IA, lo que la hace especialmente adecuada para servir a los LLM.
Con BentoCloud, los usuarios pueden desplegar soluciones de IA escalables y eficientes en entornos de nube sin preocuparse de la gestión de la infraestructura.
Sigamos adelante con el proyecto. Crearemos los siguientes componentes:
app.py para definir la API de servicio del modelo con vLLM y FastAPI.requirements.txt para especificar los paquetes de Python necesarios para la instalación en el entorno de la nube.bentofile.yaml para configurar la infraestructura, crear imágenes Docker y configurar el entorno de despliegue.Empezaremos instalando el paquete BentoML Python mediante el comando pip:
pip install bentomlEn el archivo de la aplicación Python, configuraremos el punto final del modelo haciendo lo siguiente:
bentoml, fastapi, y vllm.Añade el código siguiente a tu app.py:
# Standard library imports
import uuid
from argparse import Namespace
from typing import AsyncGenerator, Optional
# Third-party imports
import bentoml
import fastapi
from annotated_types import Ge, Le
from typing_extensions import Annotated
# Initialize FastAPI application
openai_api_app = fastapi.FastAPI()
# Constants
MAX_MODEL_LEN = 8192
MAX_TOKENS = 1024
SYSTEM_PROMPT = """You are a helpful and respectful assistant. Provide safe, unbiased, and accurate answers.
If a question is unclear or you don't know the answer, explain why instead of guessing."""
MODEL_ID = "casperhansen/llama-3.3-70b-instruct-awq"
# Define OpenAI-compatible API endpoints
OPENAI_ENDPOINTS = [
["/chat/completions", "create_chat_completion", ["POST"]],
["/completions", "create_completion", ["POST"]],
["/models", "show_available_models", ["GET"]],
]
@bentoml.mount_asgi_app(openai_api_app, path="/v1")
@bentoml.service(
name="llama3.3-70b-instruct-awq",
traffic={
"timeout": 1200,
"concurrency": 256,
},
resources={
"gpu": 1,
"gpu_type": "nvidia-a100-80gb",
},
)
class BentoVLLM:
def __init__(self) -> None:
"""Initialize the BentoVLLM service with VLLM engine and tokenizer."""
import vllm.entrypoints.openai.api_server as vllm_api_server
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
# Configure VLLM engine arguments
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_MODEL_LEN,
enable_prefix_caching=True,
)
# Initialize engine and tokenizer
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
# Register API endpoints
for route, endpoint_name, methods in OPENAI_ENDPOINTS:
endpoint_func = getattr(vllm_api_server, endpoint_name)
openai_api_app.add_api_route(
path=route,
endpoint=endpoint_func,
methods=methods,
)
# Configure model arguments
model_config = self.engine.engine.get_model_config()
args = Namespace(
model=MODEL_ID,
disable_log_requests=True,
max_log_len=1000,
response_role="assistant",
served_model_name=None,
chat_template=None,
lora_modules=None,
prompt_adapters=None,
request_logger=None,
disable_log_stats=True,
return_tokens_as_token_ids=False,
enable_tool_call_parser=True,
enable_auto_tool_choice=True,
tool_call_parser="llama3_json",
enable_prompt_tokens_details=False,
)
# Initialize application state
vllm_api_server.init_app_state(
self.engine, model_config, openai_api_app.state, args
)
@bentoml.api
async def generate(
self,
prompt: str = "Describe the process of photosynthesis in simple terms",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
"""
Generate text based on the input prompt using the VLLM engine.
Args:
prompt: The user's input prompt
system_prompt: Optional system prompt to guide the model's behavior
max_tokens: Maximum number of tokens to generate
Returns:
AsyncGenerator yielding generated text chunks
"""
from vllm import SamplingParams
# Configure sampling parameters
SAMPLING_PARAM = SamplingParams(
max_tokens=max_tokens,
skip_special_tokens=True,
)
# Use default system prompt if none provided
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
# Prepare messages for chat
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
# Apply chat template
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# Generate response stream
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
# Stream the generated text
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Crea un archivo requirements.txt e incluye todos los paquetes Python necesarios para construir la aplicación de IA. Especifica las versiones exactas de cada paquete para mantener la estabilidad y reproducibilidad del proyecto.
Este es el aspecto que debe tener requirements.txt:
accelerate==1.2.0
autoawq==0.2.7.post3
bentoml>=1.3.15
fastapi==0.115.6
openai==1.57.0
vllm==0.6.4.post1; sys_platform == "linux"El archivo bentofile.yaml es el archivo de configuración utilizado para definir y construir el servicio BentoML. Incluye los siguientes componentes:
app.py) y el nombre de la clase del servicio (BentoVLLM).requirements.txt.Añade el siguiente contenido a tu archivo bentofile.yaml:
service: 'app:BentoVLLM'
labels:
owner: Abid
team: DataCamp
stage: dev
include:
- '*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"Ahora viene la parte mágica: BentoCloud lo hará todo por nosotros, y sólo tendremos que teclear un comando. Pero antes, tenemos que iniciar sesión en BentoCloud escribiendo el siguiente comando en el terminal.
bentoml cloud login
La herramienta CLI te hará algunas preguntas y luego te redirigirá al sitio web de BentoCloud para crear una cuenta y generar la clave API.
Una vez hecho esto, se aplicará automáticamente la clave API a tus herramientas CLI.
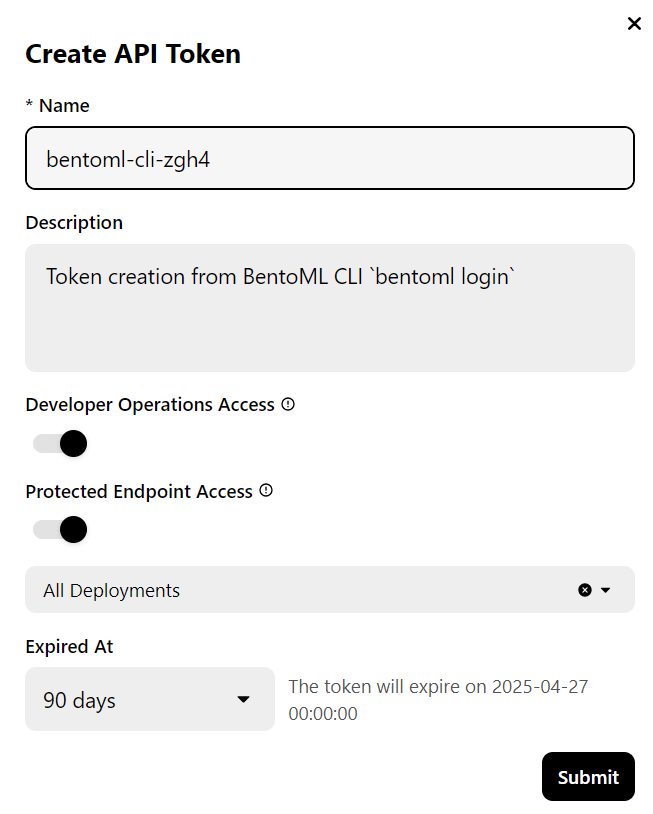
Nota: Desplegar la versión completa del modelo 70B requiere 80 GB de memoria GPU. Aunque BentoCloud proporciona 10 USD en créditos gratuitos, tendrás que suscribirte al plan pro para acceder a las GPU A100 con 80 GB de VRAM.
Para suscribirte, ve a la pestaña "Facturación" haciendo clic en tu foto de perfil en la esquina superior derecha y añade los datos de tu tarjeta de crédito.
No te preocupes; si tienes cuidado con los despliegues, no te costará más de 6 USD. ¡Pero asegúrate de finalizar el despliegue cuando hayas terminado de experimentar!
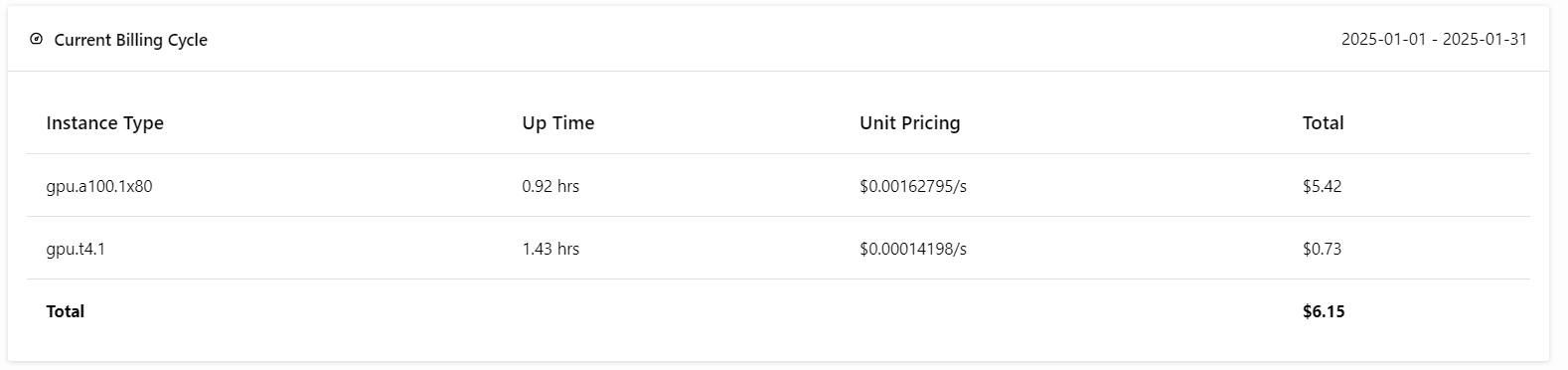
Ahora viene la mejor parte: desplegaremos la aplicación BentoML en la nube utilizando el siguiente comando y habilitaremos la autorización de acceso. Esto significa que sólo los usuarios con la clave API BentoML pueden acceder a este servidor API.
bentoml deploy . --access-authorization trueEl envío de todos los archivos, configuraciones y demás componentes necesarios tardará unos segundos, tras los cuales BentoCloud gestionará el resto.

Para ver tus despliegues en ejecución, ve a tu panel de control de BentoCloud y haz clic en la pestaña "Despliegues". Por ejemplo, la imagen siguiente muestra la aplicación en el proceso de "Construcción de imágenes":
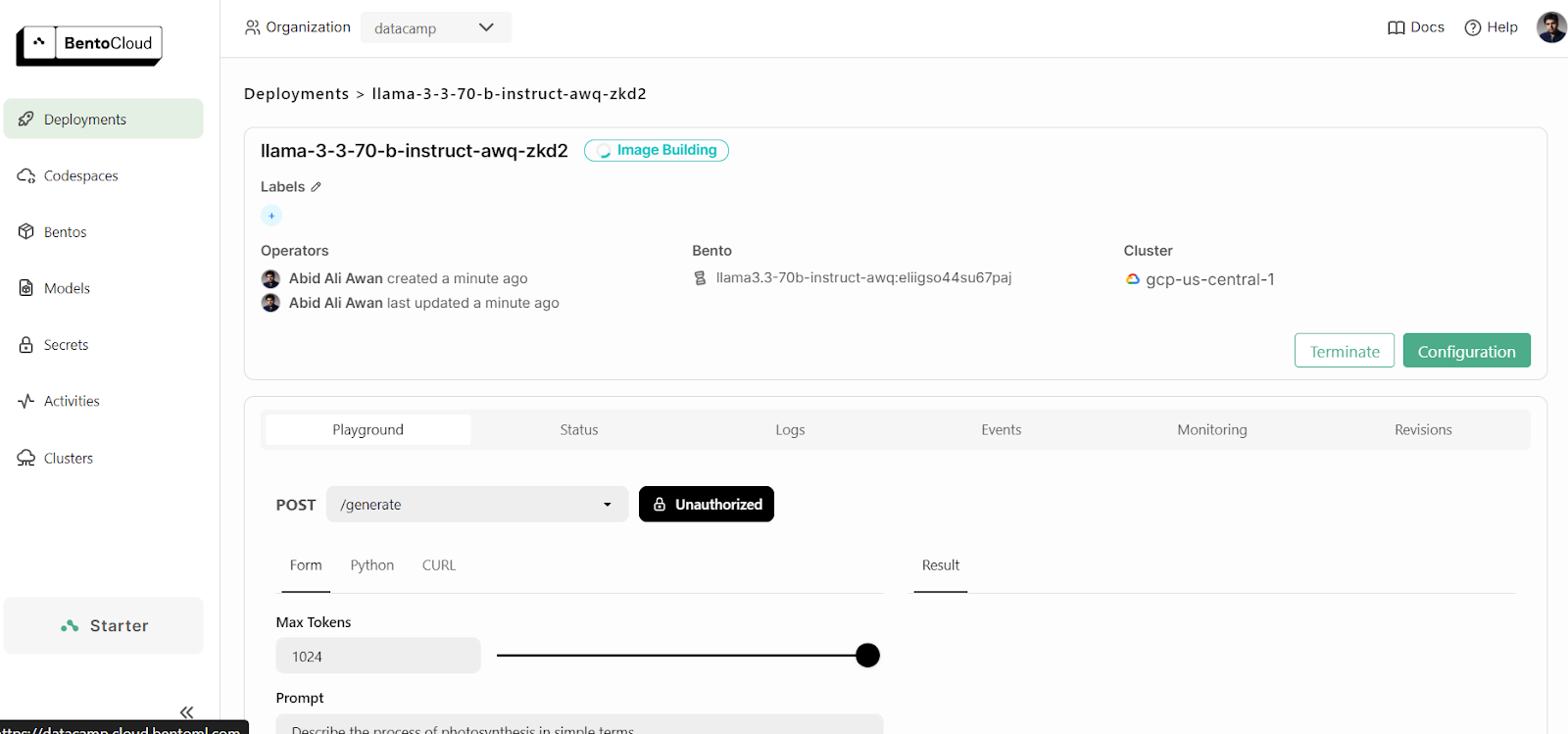
Tras unos minutos más de construir la imagen, configurar la infraestructura y desplegar el modelo, ¡nuestra aplicación está lista para ser utilizada!
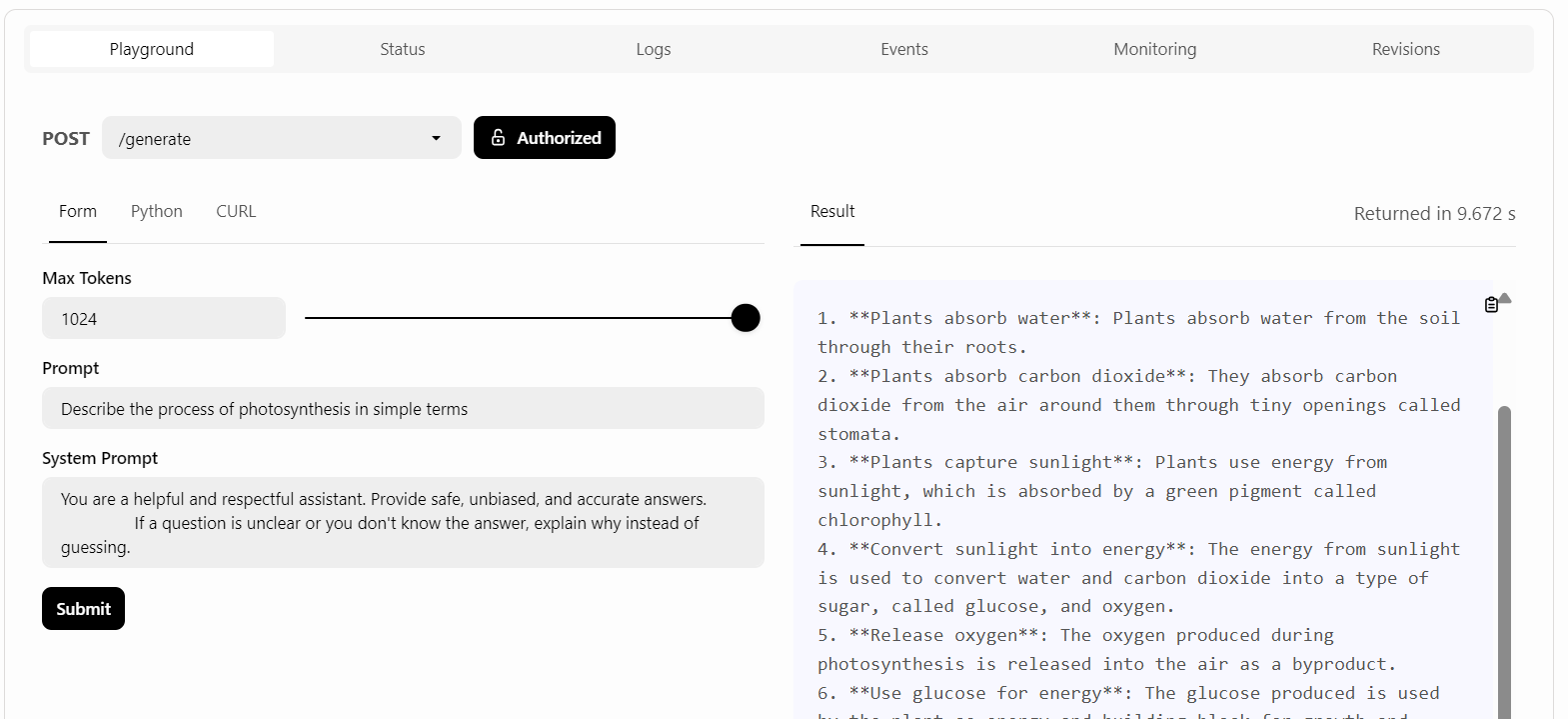
BentoCloud proporciona una interfaz de usuario Playground para probar tu modelo en el tablero, similar a la plataforma OpenAI. Como nuestro servicio está restringido, tendremos que proporcionar una clave API para acceder al modelo en el Playground, como se muestra a continuación:
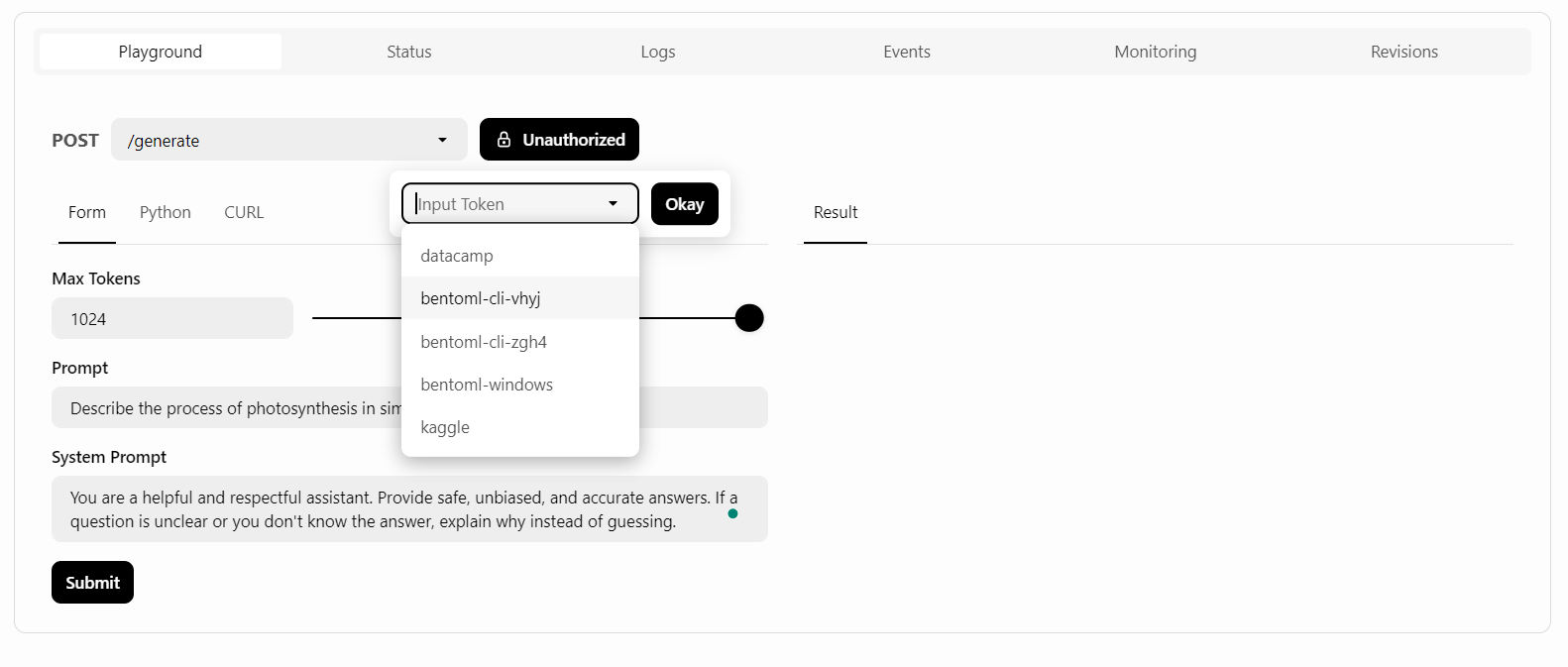
Después, escribiremos el aviso y haremos clic en el botón "Enviar".
La generación de respuestas fue rápida y precisa:
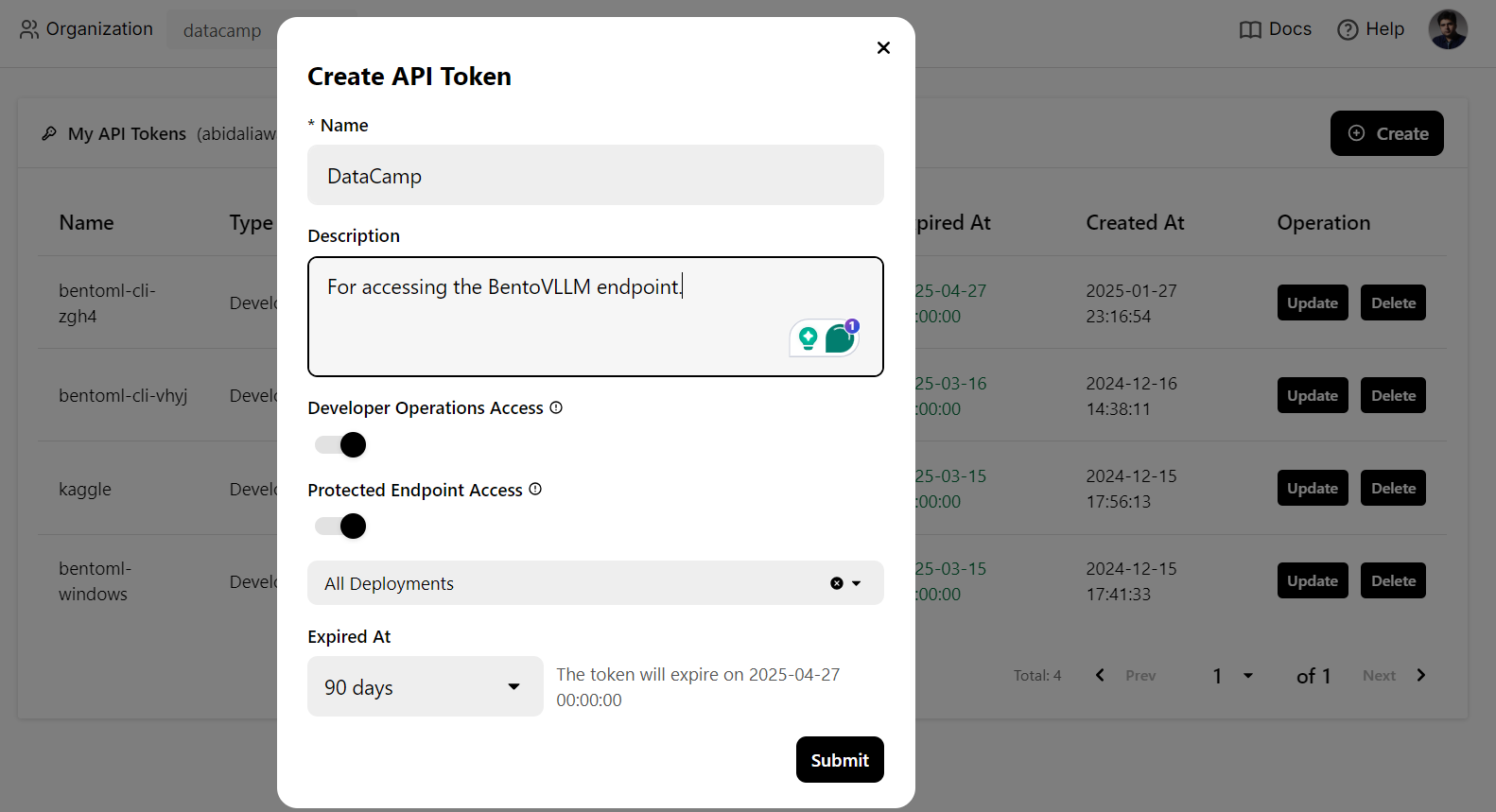
Utilizaremos un comando CURL en el terminal para acceder localmente al servicio LLM. Pero antes, necesitamos generar una nueva clave API para utilizar este servicio en cualquier sistema:
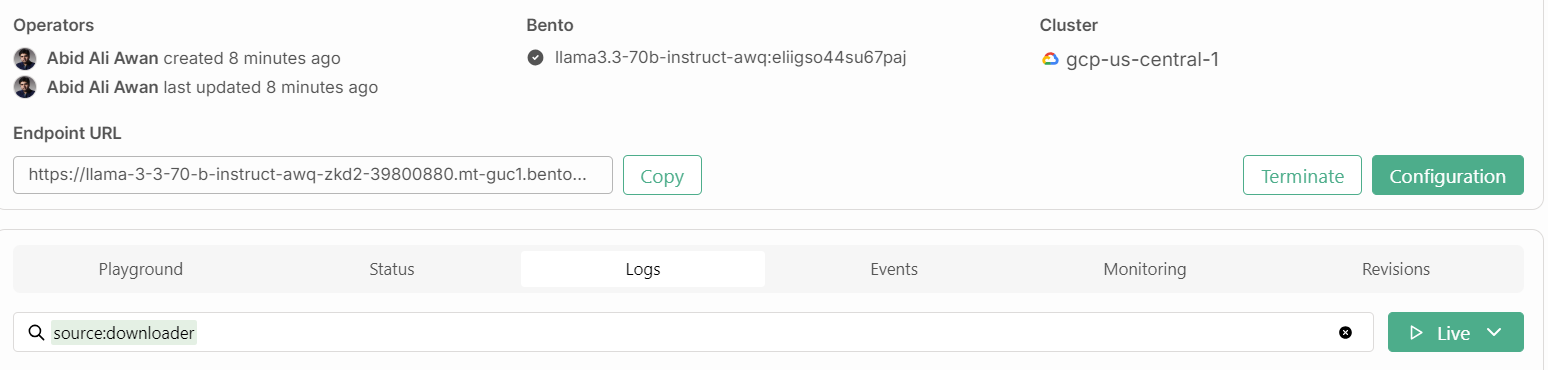
Además, necesitaremos la URL del punto final que podemos copiar de la pestaña "Despliegues":
Una vez que tengas la clave API y la URL del punto final, puedes generar una respuesta utilizando el siguiente comando CURL.
El comando incluye la URL del punto final, la clave API, el argumento max_tokens y la dirección prompt:
curl -s -X POST \
'https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/generate' \
-H "Authorization: Bearer $(echo $BENTO_CLOUD_API_KEY)" \
-H 'Content-Type: application/json' \
-d '{
"max_tokens": 1024,
"prompt": "Describe the process of photosynthesis in simple terms"
}'La respuesta es precisa, y se tardó un par de envíos en generarla.

El punto final BentoML es compatible con el cliente OpenAI Python. No tienes que modificar tu código de forma significativa para integrar este modelo de código abierto en tu aplicación.
Todo lo que tienes que hacer es cambiar la URL base, proporcionar la clave API y especificar el nombre del modelo:
import os
from openai import OpenAI
BENTOML_API_KEY = os.getenv("BENTO_CLOUD_API_KEY") #
if BENTOML_API_KEY is None:
raise ValueError("BENTOML_API_KEY environment variable is not set.")
client = OpenAI(
base_url="https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/v1",
api_key=BENTOML_API_KEY,
)
chat_completion = client.chat.completions.create(
model="casperhansen/llama-3.3-70b-instruct-awq",
messages=[
{"role": "user", "content": "What is a black hole and how does it work?"}
],
stream=True,
stop=["<|eot_id|>", "<|end_of_text|>"],
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")
Consulta el repositorio GitHub kingabzpro/Deploying-Llama-3.3-70B, que contiene el archivo de la aplicación, las configuraciones y los códigos de inferencia.
En BentCloud, puedes supervisar el rendimiento del modelo, la latencia, el uso de hardware, el rendimiento del modelo y otras métricas críticas sin necesidad de configurar herramientas de registro o supervisión.
Ve a tus despliegues y haz clic en la pestaña "Monitorización".
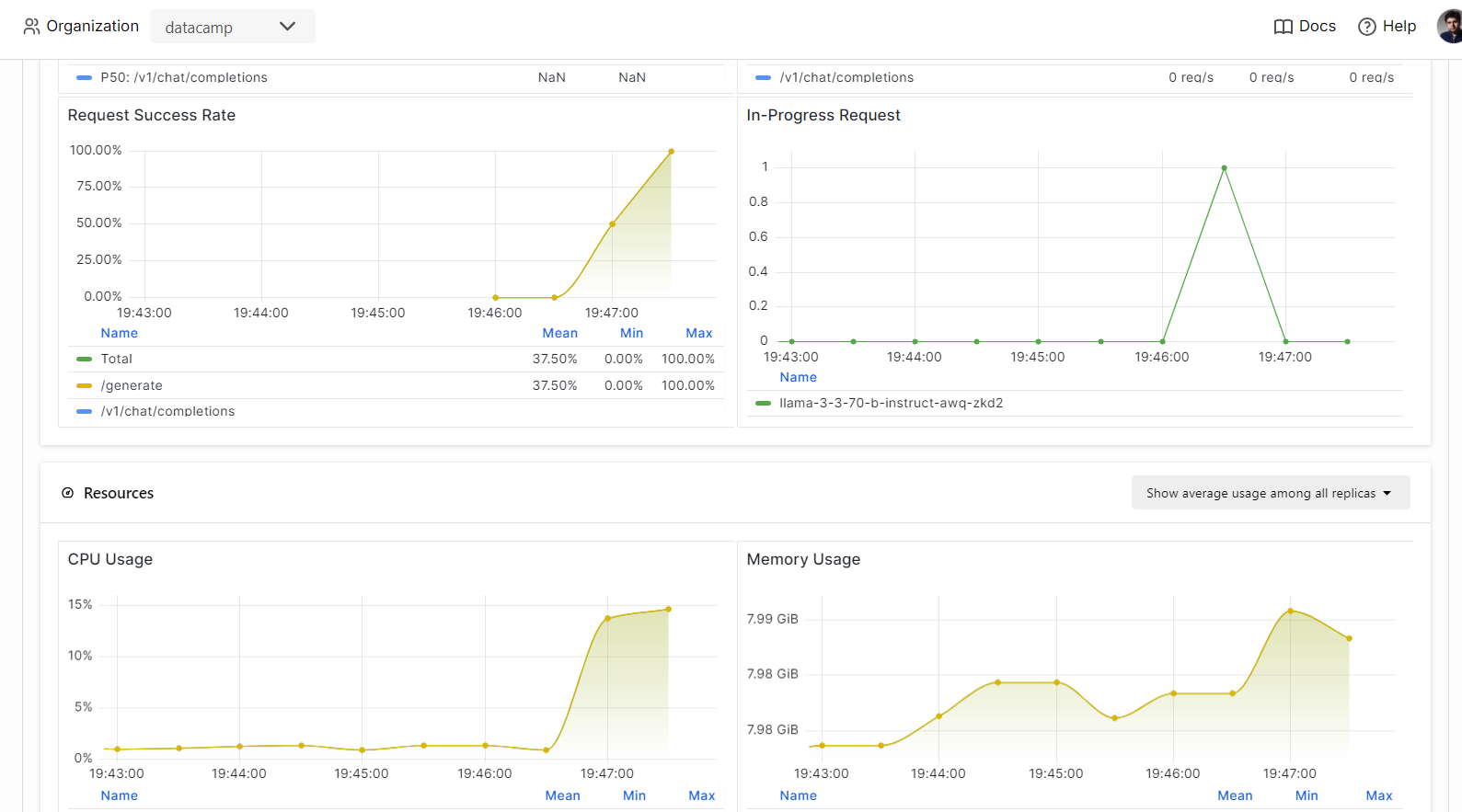
Desplázate hacia abajo para ver las métricas relacionadas con servicios, recursos y LLM en gráficos intuitivos y sencillos.
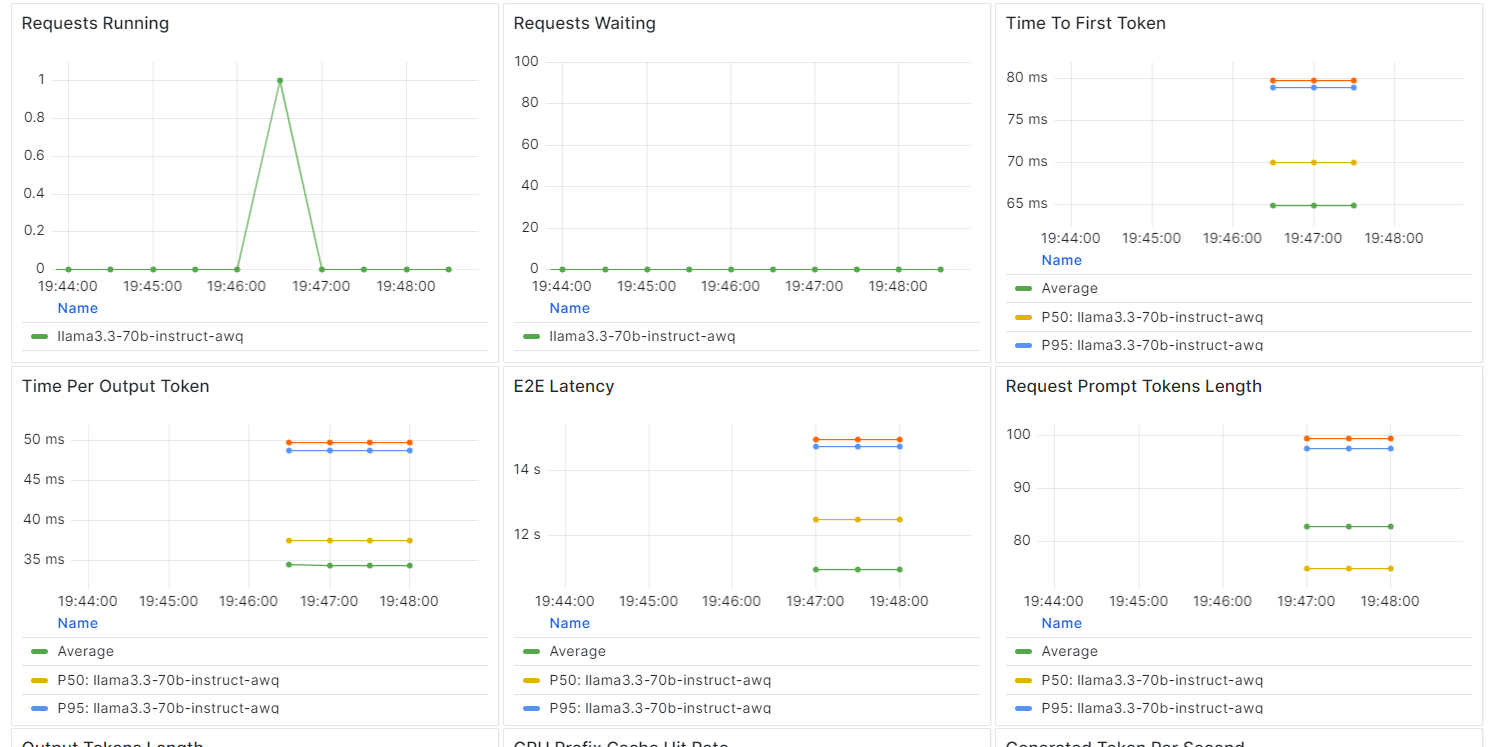
Construir y desplegar un punto final LLM se ha convertido en algo notablemente sencillo con el ecosistema BentoML.
Con sólo escribir unas pocas líneas de código para crear tu API, configurar un "bentofile" y desplegar el modelo, puedes tener tu modelo funcionando en cuestión de minutos. Una vez desplegado, se puede acceder al punto final mediante comandos CURL, la biblioteca de peticiones Python, el cliente BentoML o el cliente OpenAI.
El resultado es un sistema muy eficiente, de baja latencia y alto rendimiento, capaz de gestionar múltiples peticiones simultáneamente. BentoCloud también ofrece autoescalado en función de tu configuración, lo que garantiza que el sistema pueda gestionar grandes volúmenes de tráfico aumentando o reduciendo la escala según sea necesario.
Para una guía más detallada sobre el despliegue de LLMs con BentoML, te recomiendo que sigas Cómo desplegar LLMs con BentoML: Guía paso a paso.
¡Aprende más sobre IA y LLMs con estos cursos!
Curso
Curso
Curso
blog
Joleen Bothma
12 min
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan

