
Curso
Conceitos de MLOps
2 h
42.6K
A implementação de modelos de linguagem grandes (LLMs) está se tornando cada vez mais desafiadora, pois esses modelos exigem máquinas de GPU de ponta com VRAM significativa. Os engenheiros também precisam dominar as ferramentas de MLOps para lidar com tarefas como servir, implantar, testar e monitorar os modelos. Além disso, eles precisam implementar restrições de acesso e manter a segurança para se proteger contra ameaças cibernéticas e ataques de injeção imediata. A vida de um engenheiro de LLMOps pode ser difícil - mas não se preocupe, nós ajudamos você!
Neste tutorial, exploraremos uma solução mais simples e eficiente para a implementação de LLMs, como o Llama 3.3 70B, na nuvem. Com apenas algumas linhas de código Python e alguns comandos de terminal, seu modelo estará pronto e funcionando. O BentoCloud simplifica e gerencia tudo, tornando o processo de implantação simples e seguro.

Se você for iniciante, recomendo que façao curso Introduction to LLMs in Python para entender os fundamentos dos modelos de linguagem grandes.
O novo Meta Llama 3.3 é um modelo multilíngue de linguagem grande (LLM) somente de texto (70B) ajustado por instruções que oferece desempenho aprimorado em comparação com o Llama 3.1 (70B) e o Llama 3.2 (90B). Em alguns casos, ele superou até mesmo o Llama 3.1 (405B), que é maior. Esse modelo é somente de texto e otimizado para casos de uso de diálogo multilíngue.
O Llama 3.3 é um modelo de linguagem auto-regressivo criado em uma arquitetura de transformador otimizada. Ele foi ajustado usando o ajuste fino supervisionado (SFT) e o aprendizado por reforço com feedback humano (RLHF) para se alinhar melhor com as preferências humanas de ajuda e segurança.
Saiba mais sobre o Llama 3.3 lendo o site O que é o Llama 3.3 70B da Meta? Como funciona, casos de uso e muito mais blog post.
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

Neste projeto, usaremos o BentoML para criar o serviço de IA, o vLLM para servir modelos de alto rendimento e o BentoCloud para infraestrutura e implementação robustas. Além disso, implantaremos a versão AWQ do modelo para otimizar o desempenho.
Resumindo, o vLLM combinado com o AWQ cria uma combinação mortal para a criação de aplicativos LLM que são super rápidos e capazes de lidar com várias solicitações simultaneamente.
AWQ (Activation-aware Weight Quantization) é uma técnica inovadora de quantização projetada para aprimorar a implantação de modelos de linguagem grandes. Você consegue isso reduzindo significativamente o uso da memória e melhorando a velocidade de inferência, tudo isso mantendo a alta precisão.
Leia o artigo de pesquisa para saber mais sobre a tecnologia AWQ e como ela otimiza a inferência de modelos, mantendo a precisão.
O vLLM (Virtual Large Language Model) é uma biblioteca de código aberto projetada especificamente para otimizar a inferência e a veiculação de modelos de linguagem grandes. Ele aborda desafios críticos, como rendimento e eficiência de memória, introduzindo técnicas avançadas como o PagedAttention, que garante o gerenciamento eficiente da memória de valor-chave de atenção.
Saiba mais sobre o pacote Python vLLM seguindo o endereço vLLM: Configuração do vLLM localmente e no Google Cloud para CPU tutorial.
O BentoML é uma estrutura de serviço de modelo de aprendizado de máquina de código aberto que funciona como a espinha dorsal do pipeline de implementação do LLM. Ele simplifica o processo de empacotamento, implantação e gerenciamento de modelos de aprendizado de máquina, incluindo LLMs, na produção.
Siga o tutorial Como implantar LLMs com o BentoML para saber mais sobre o ecossistema do BentoML e como implantar modelos LLM menores.
O BentoCloud é uma plataforma sem servidor construída sobre o BentoML, projetada para simplificar a implantação e o gerenciamento de modelos de aprendizado de máquina. Ele oferece uma infraestrutura robusta otimizada para inferência de IA, o que o torna particularmente adequado para atender a LLMs.
Com o BentoCloud, os usuários podem implementar soluções de IA escaláveis e eficientes em ambientes de nuvem sem se preocupar com o gerenciamento da infraestrutura.
Agora, vamos dar continuidade ao projeto. Criaremos os seguintes componentes:
app.py para definir o modelo que serve a API com vLLM e FastAPI.requirements.txt para especificar os pacotes Python necessários para a instalação no ambiente de nuvem.bentofile.yaml para configurar a infraestrutura, criar imagens do Docker e configurar o ambiente de implantação.Começaremos instalando o pacote BentoML Python usando o comando pip:
pip install bentomlNo arquivo do aplicativo Python, configuraremos o endpoint do modelo fazendo o seguinte:
bentoml, fastapi e vllm.Adicione o código abaixo em seu site app.py:
# Standard library imports
import uuid
from argparse import Namespace
from typing import AsyncGenerator, Optional
# Third-party imports
import bentoml
import fastapi
from annotated_types import Ge, Le
from typing_extensions import Annotated
# Initialize FastAPI application
openai_api_app = fastapi.FastAPI()
# Constants
MAX_MODEL_LEN = 8192
MAX_TOKENS = 1024
SYSTEM_PROMPT = """You are a helpful and respectful assistant. Provide safe, unbiased, and accurate answers.
If a question is unclear or you don't know the answer, explain why instead of guessing."""
MODEL_ID = "casperhansen/llama-3.3-70b-instruct-awq"
# Define OpenAI-compatible API endpoints
OPENAI_ENDPOINTS = [
["/chat/completions", "create_chat_completion", ["POST"]],
["/completions", "create_completion", ["POST"]],
["/models", "show_available_models", ["GET"]],
]
@bentoml.mount_asgi_app(openai_api_app, path="/v1")
@bentoml.service(
name="llama3.3-70b-instruct-awq",
traffic={
"timeout": 1200,
"concurrency": 256,
},
resources={
"gpu": 1,
"gpu_type": "nvidia-a100-80gb",
},
)
class BentoVLLM:
def __init__(self) -> None:
"""Initialize the BentoVLLM service with VLLM engine and tokenizer."""
import vllm.entrypoints.openai.api_server as vllm_api_server
from transformers import AutoTokenizer
from vllm import AsyncEngineArgs, AsyncLLMEngine
# Configure VLLM engine arguments
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_MODEL_LEN,
enable_prefix_caching=True,
)
# Initialize engine and tokenizer
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
# Register API endpoints
for route, endpoint_name, methods in OPENAI_ENDPOINTS:
endpoint_func = getattr(vllm_api_server, endpoint_name)
openai_api_app.add_api_route(
path=route,
endpoint=endpoint_func,
methods=methods,
)
# Configure model arguments
model_config = self.engine.engine.get_model_config()
args = Namespace(
model=MODEL_ID,
disable_log_requests=True,
max_log_len=1000,
response_role="assistant",
served_model_name=None,
chat_template=None,
lora_modules=None,
prompt_adapters=None,
request_logger=None,
disable_log_stats=True,
return_tokens_as_token_ids=False,
enable_tool_call_parser=True,
enable_auto_tool_choice=True,
tool_call_parser="llama3_json",
enable_prompt_tokens_details=False,
)
# Initialize application state
vllm_api_server.init_app_state(
self.engine, model_config, openai_api_app.state, args
)
@bentoml.api
async def generate(
self,
prompt: str = "Describe the process of photosynthesis in simple terms",
system_prompt: Optional[str] = SYSTEM_PROMPT,
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
"""
Generate text based on the input prompt using the VLLM engine.
Args:
prompt: The user's input prompt
system_prompt: Optional system prompt to guide the model's behavior
max_tokens: Maximum number of tokens to generate
Returns:
AsyncGenerator yielding generated text chunks
"""
from vllm import SamplingParams
# Configure sampling parameters
SAMPLING_PARAM = SamplingParams(
max_tokens=max_tokens,
skip_special_tokens=True,
)
# Use default system prompt if none provided
if system_prompt is None:
system_prompt = SYSTEM_PROMPT
# Prepare messages for chat
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
# Apply chat template
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# Generate response stream
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
# Stream the generated text
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)Crie um arquivo requirements.txt e inclua todos os pacotes Python necessários para criar o aplicativo de IA. Especifique as versões exatas de cada pacote para manter a estabilidade e a reprodutibilidade do projeto.
Veja como deve ser o site requirements.txt:
accelerate==1.2.0
autoawq==0.2.7.post3
bentoml>=1.3.15
fastapi==0.115.6
openai==1.57.0
vllm==0.6.4.post1; sys_platform == "linux"O arquivo bentofile.yaml é o arquivo de configuração usado para definir e criar o serviço BentoML. Ele inclui os seguintes componentes:
app.py) e o nome da classe do serviço (BentoVLLM).requirements.txt.Adicione o seguinte conteúdo ao seu arquivo bentofile.yaml:
service: 'app:BentoVLLM'
labels:
owner: Abid
team: DataCamp
stage: dev
include:
- '*.py'
python:
requirements_txt: './requirements.txt'
lock_packages: false
docker:
python_version: "3.11"Agora vem a parte mágica: O BentoCloud fará tudo por nós, e você só precisa digitar um comando. Mas antes disso, temos que fazer o login no BentoCloud digitando o seguinte comando no terminal.
bentoml cloud login
A ferramenta CLI fará algumas perguntas e, em seguida, redirecionará você para o site do BentoCloud para criar uma conta e gerar a chave da API.
Depois que você fizer isso, ele aplicará automaticamente a chave de API às suas ferramentas de CLI.
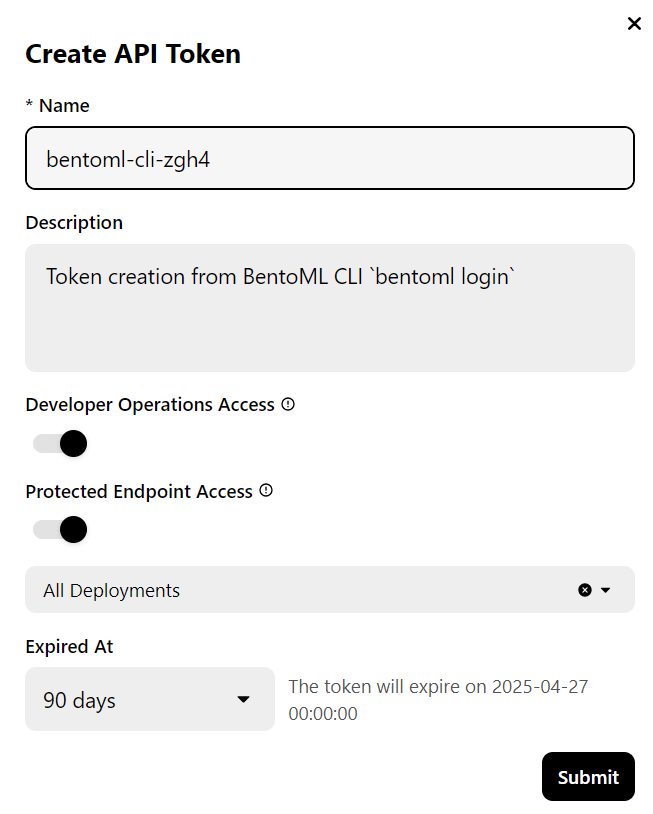
Observação: A implementação da versão completa do modelo 70B requer 80 GB de memória da GPU. Embora o BentoCloud forneça 10 dólares em créditos gratuitos, você precisará assinar o plano pro para acessar as GPUs A100 com 80 GB de VRAM.
Para assinar, acesse a guia "Billing" (Cobrança) clicando na foto do seu perfil no canto superior direito e adicionando os detalhes do seu cartão de crédito.
Não se preocupe; se você for cuidadoso com as implementações, isso não custará mais do que US$ 6. Mas certifique-se de encerrar a implantação quando você terminar de fazer experiências!
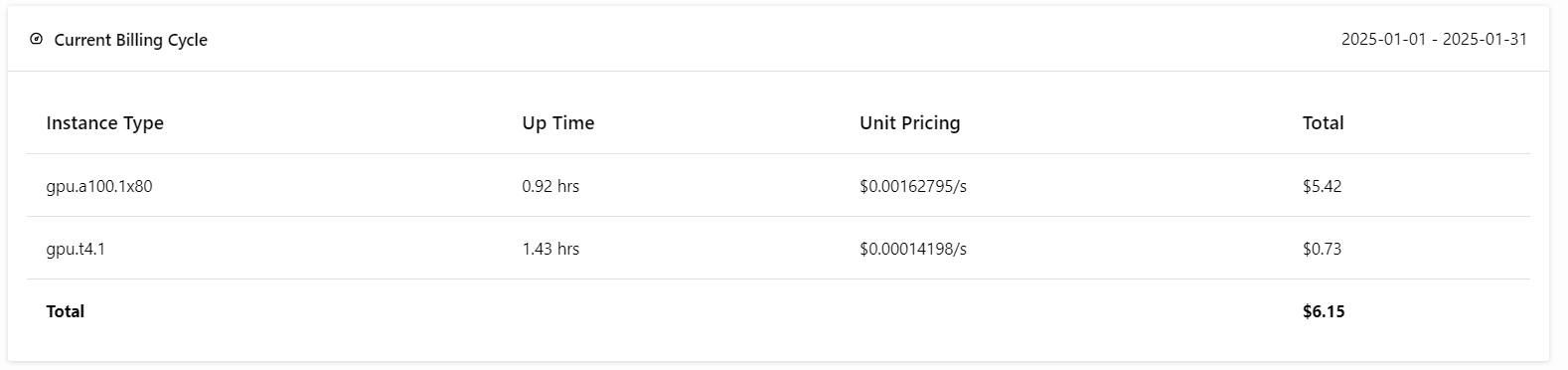
Agora vem a melhor parte: implantaremos o aplicativo BentoML na nuvem usando o seguinte comando e habilitaremos a autorização de acesso. Isso significa que apenas usuários com a chave BentoML API podem acessar esse servidor API.
bentoml deploy . --access-authorization trueVocê levará alguns segundos para que todos os arquivos, configurações e outros componentes necessários sejam enviados e, em seguida, o BentoCloud cuidará do resto.

Para visualizar as implantações atuais em execução, acesse o painel do BentoCloud e clique na guia "Deployments". Por exemplo, a imagem abaixo mostra o aplicativo no processo "Image Building":
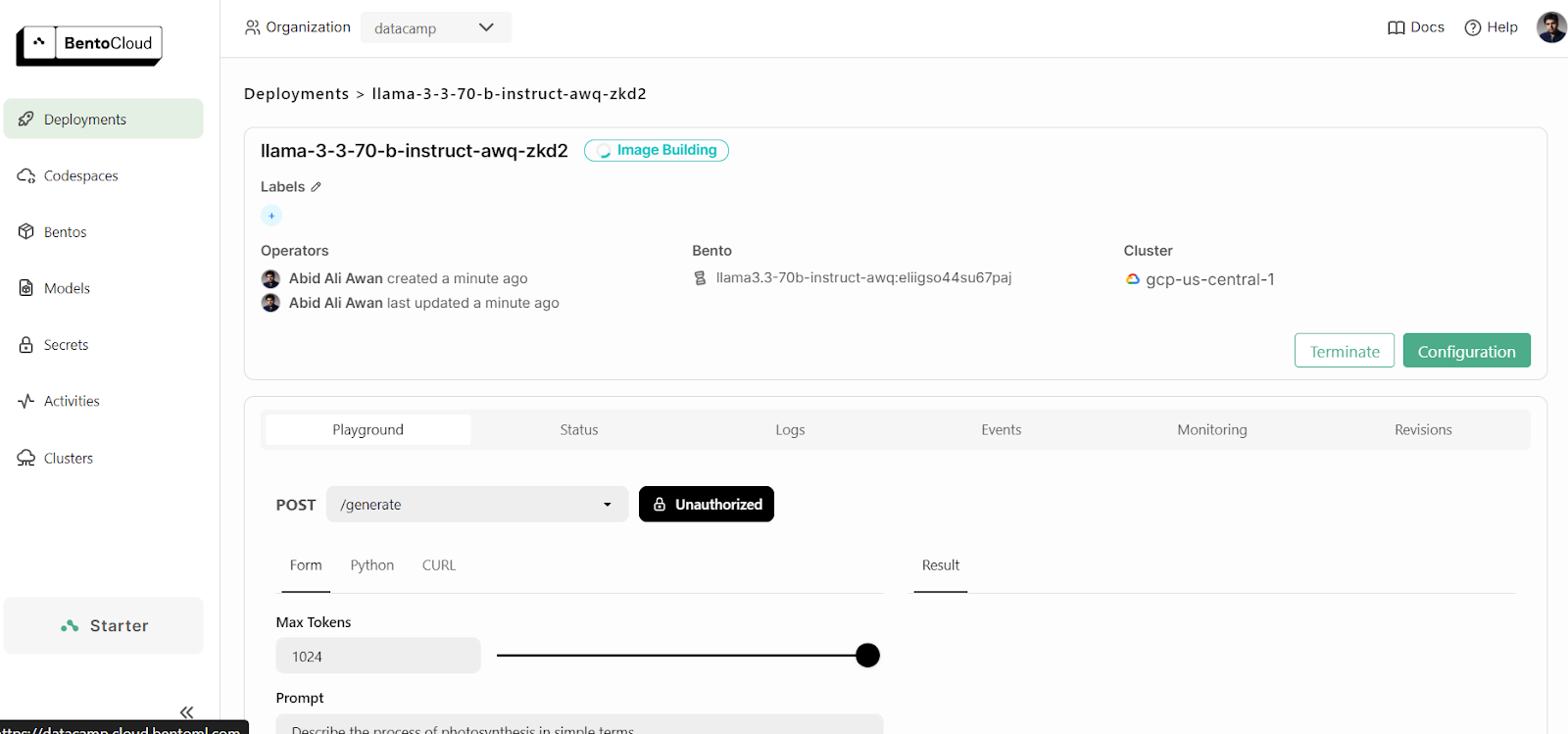
Depois de mais alguns minutos criando a imagem, configurando a infraestrutura e implantando o modelo, nosso aplicativo está pronto para ser usado!
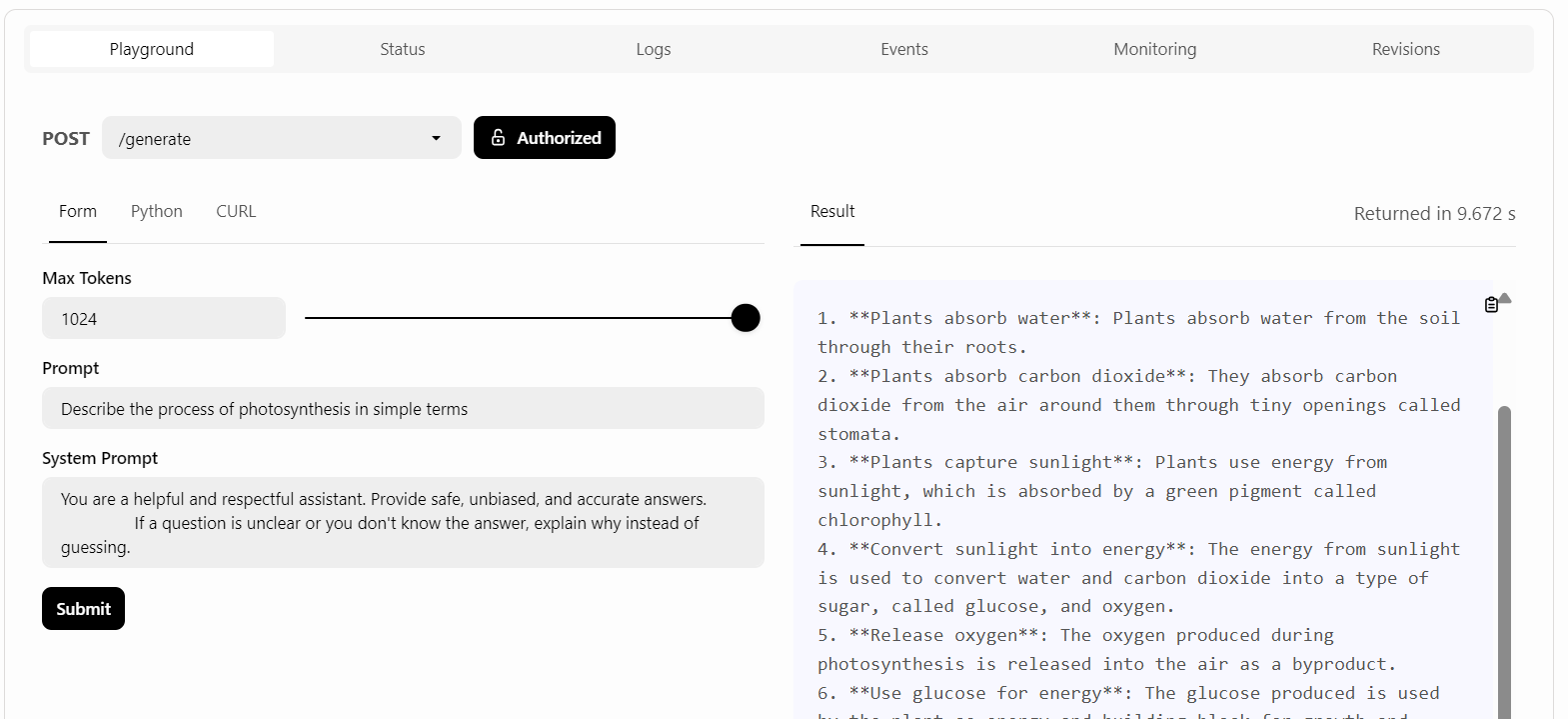
O BentoCloud oferece uma interface de usuário Playground para você testar seu modelo no painel, semelhante à plataforma OpenAI. Como nosso serviço é restrito, precisaremos fornecer uma chave de API para acessar o modelo no Playground, conforme mostrado abaixo:
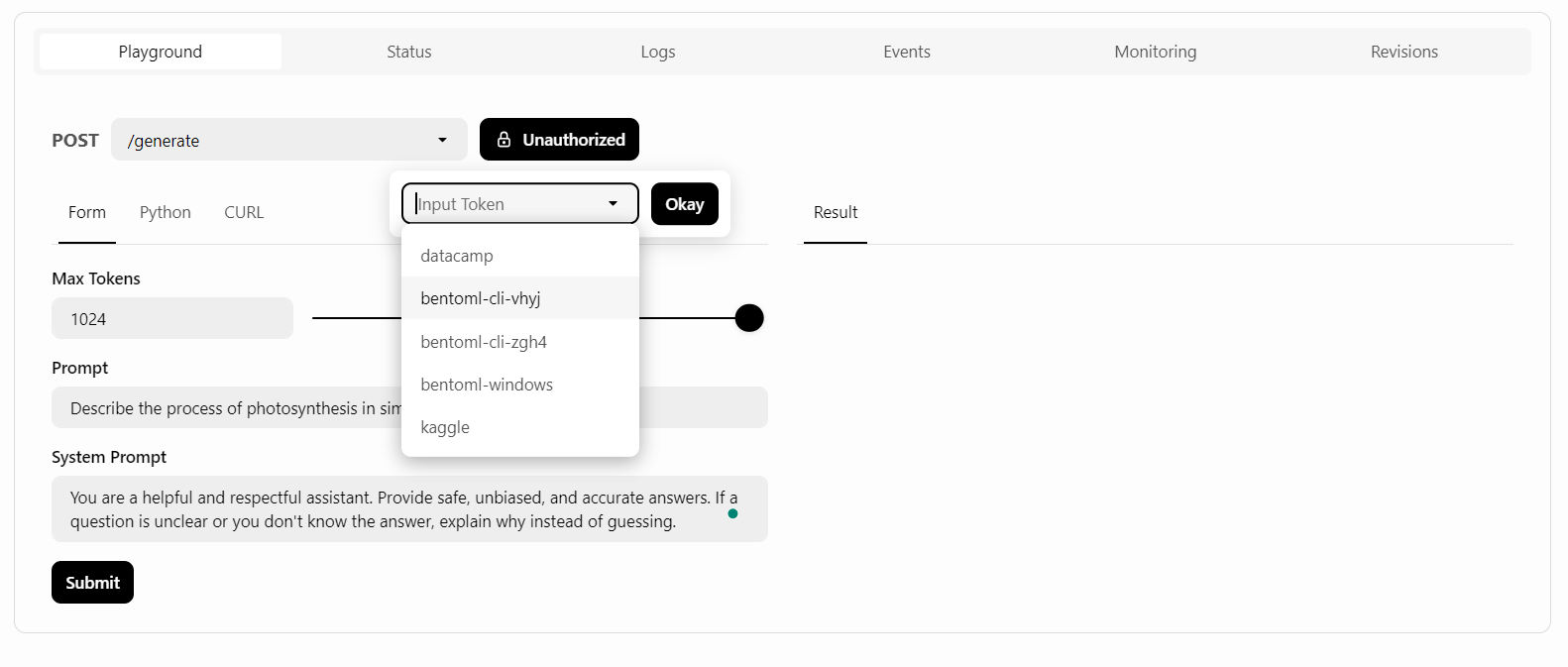
Depois disso, escreveremos o prompt e clicaremos no botão "Submit" (Enviar).
A geração de respostas foi rápida e precisa:
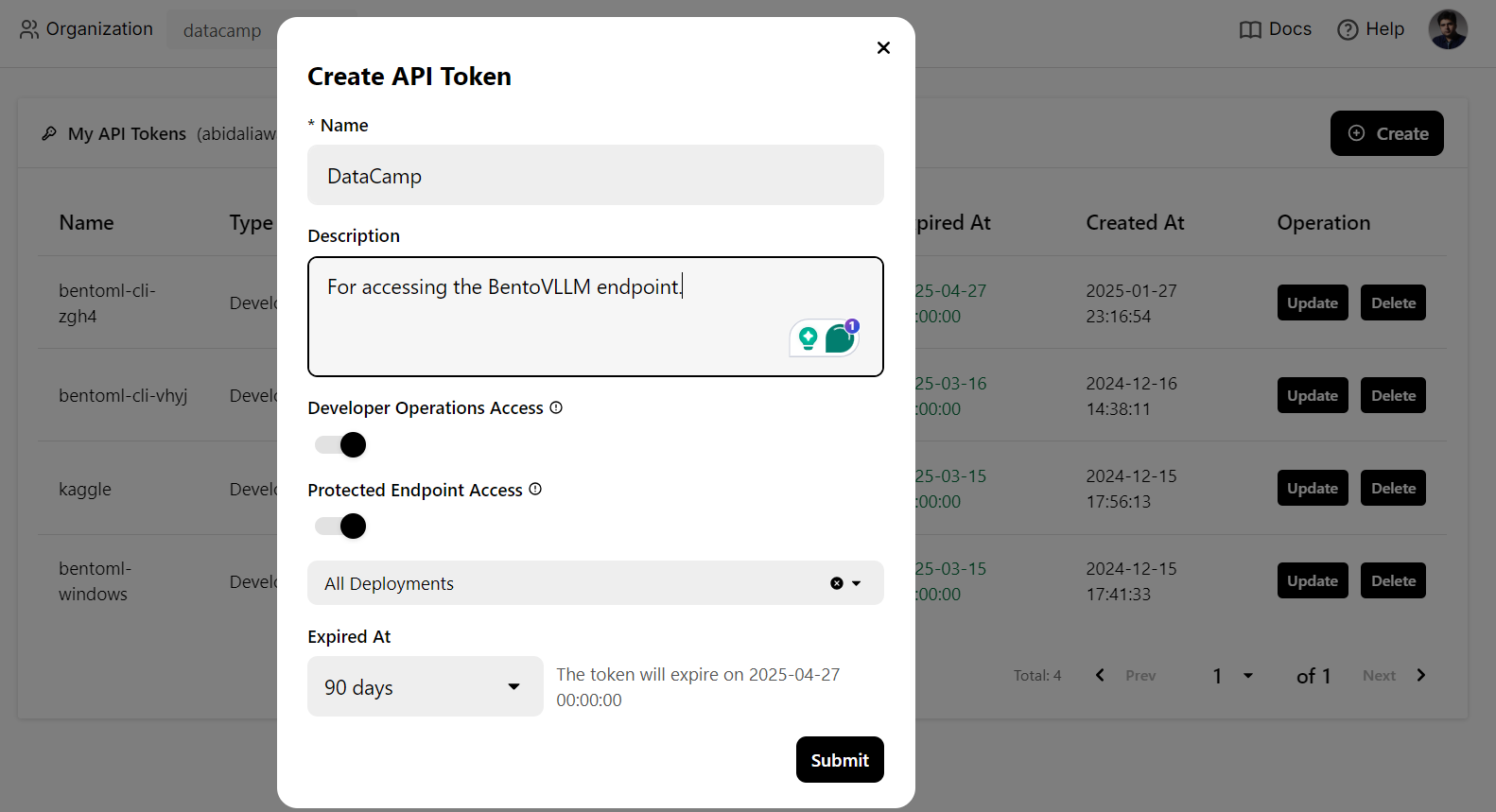
Usaremos um comando CURL no terminal para acessar o serviço LLM localmente. Mas, antes disso, precisamos gerar uma nova chave de API para usar esse serviço em qualquer sistema:
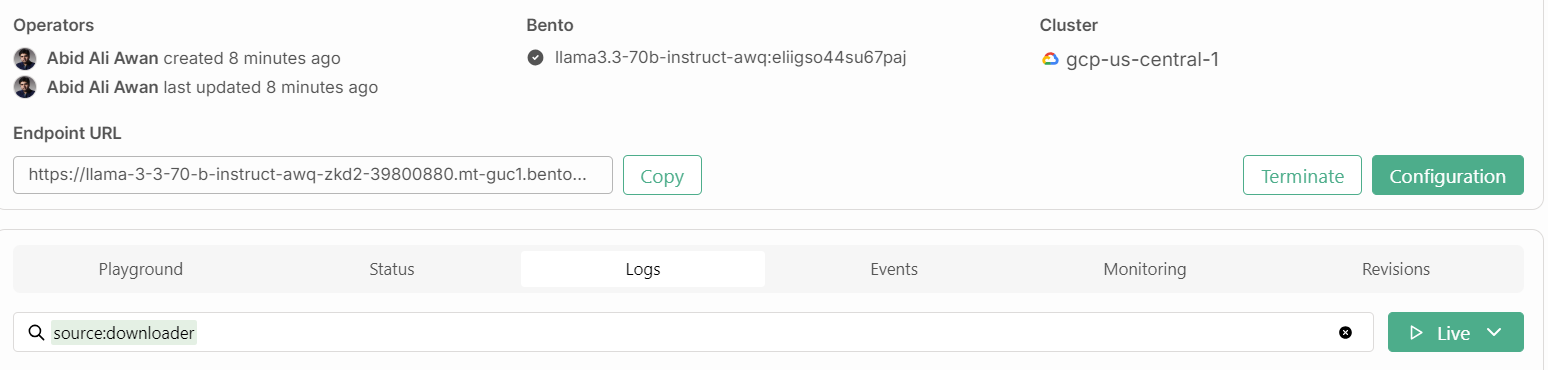
Além disso, precisaremos do URL do endpoint que podemos copiar da guia "Deployments" (Implantações):
Depois de obter a chave da API e o URL do ponto de extremidade, você pode gerar uma resposta usando o seguinte comando CURL.
O comando inclui o URL do ponto de extremidade, a chave da API, o argumento max_tokens e o argumento prompt:
curl -s -X POST \
'https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/generate' \
-H "Authorization: Bearer $(echo $BENTO_CLOUD_API_KEY)" \
-H 'Content-Type: application/json' \
-d '{
"max_tokens": 1024,
"prompt": "Describe the process of photosynthesis in simple terms"
}'A resposta é precisa, e você precisou de alguns envios para gerá-la.

O endpoint do BentoML é compatível com o cliente OpenAI Python. Você não precisa modificar significativamente seu código para integrar esse modelo de código aberto ao seu aplicativo.
Tudo o que você precisa fazer é alterar o URL de base, fornecer a chave da API e especificar o nome do modelo:
import os
from openai import OpenAI
BENTOML_API_KEY = os.getenv("BENTO_CLOUD_API_KEY") #
if BENTOML_API_KEY is None:
raise ValueError("BENTOML_API_KEY environment variable is not set.")
client = OpenAI(
base_url="https://llama-3-3-70-b-instruct-awq-zkd2-39800880.mt-guc1.bentoml.ai/v1",
api_key=BENTOML_API_KEY,
)
chat_completion = client.chat.completions.create(
model="casperhansen/llama-3.3-70b-instruct-awq",
messages=[
{"role": "user", "content": "What is a black hole and how does it work?"}
],
stream=True,
stop=["<|eot_id|>", "<|end_of_text|>"],
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")
Consulte o repositório kingabzpro/Deploying-Llama-3.3-70B do GitHub, que contém o arquivo do aplicativo, as configurações e os códigos de inferência.
No BentCloud, você pode monitorar o desempenho do modelo, a latência, o uso do hardware, a taxa de transferência do modelo e outras métricas críticas sem configurar ferramentas de registro ou monitoramento.
Vá para suas implantações e clique na guia "Monitoring" (Monitoramento).
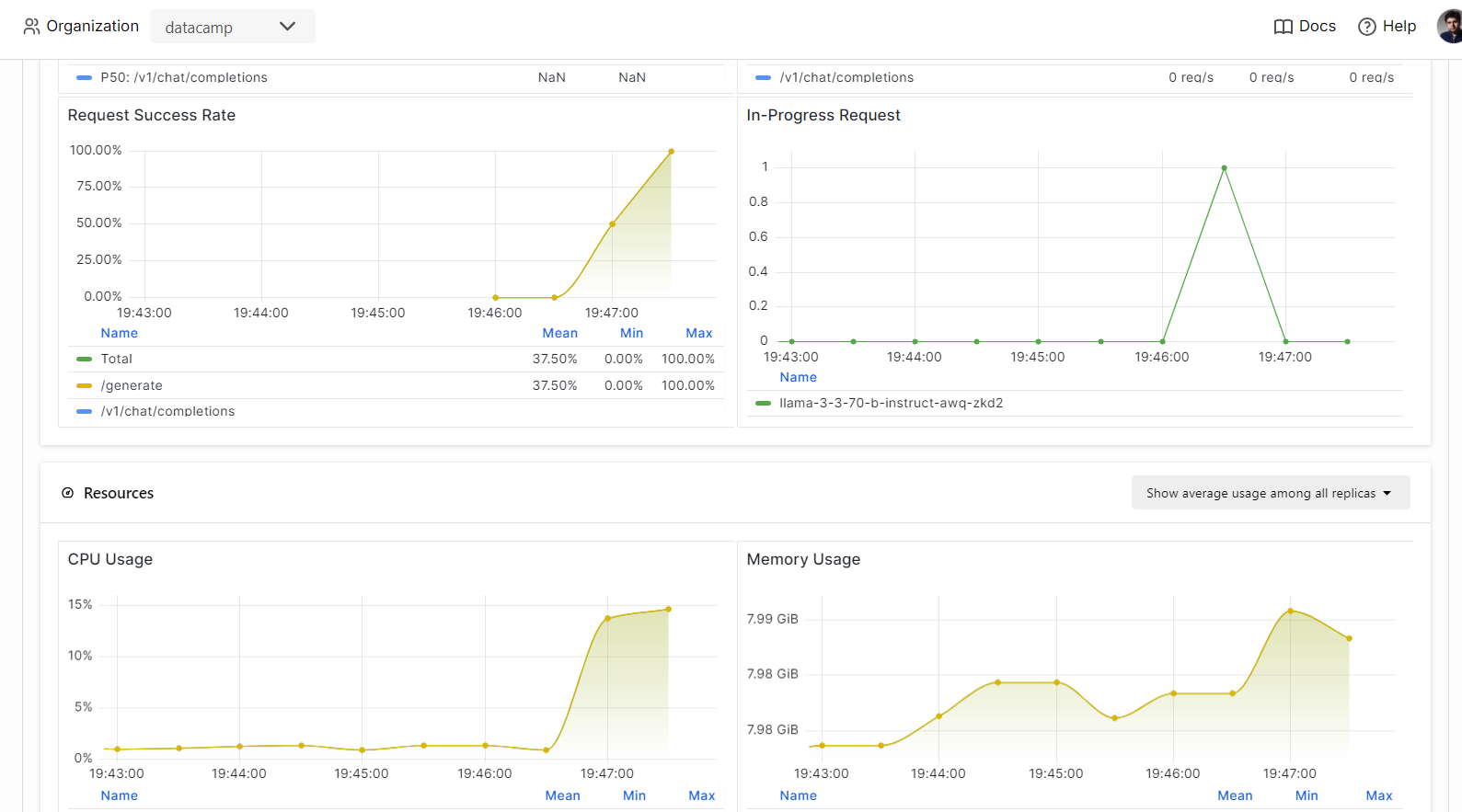
Role para baixo para ver as métricas relacionadas a serviços, recursos e LLM em gráficos intuitivos e diretos.
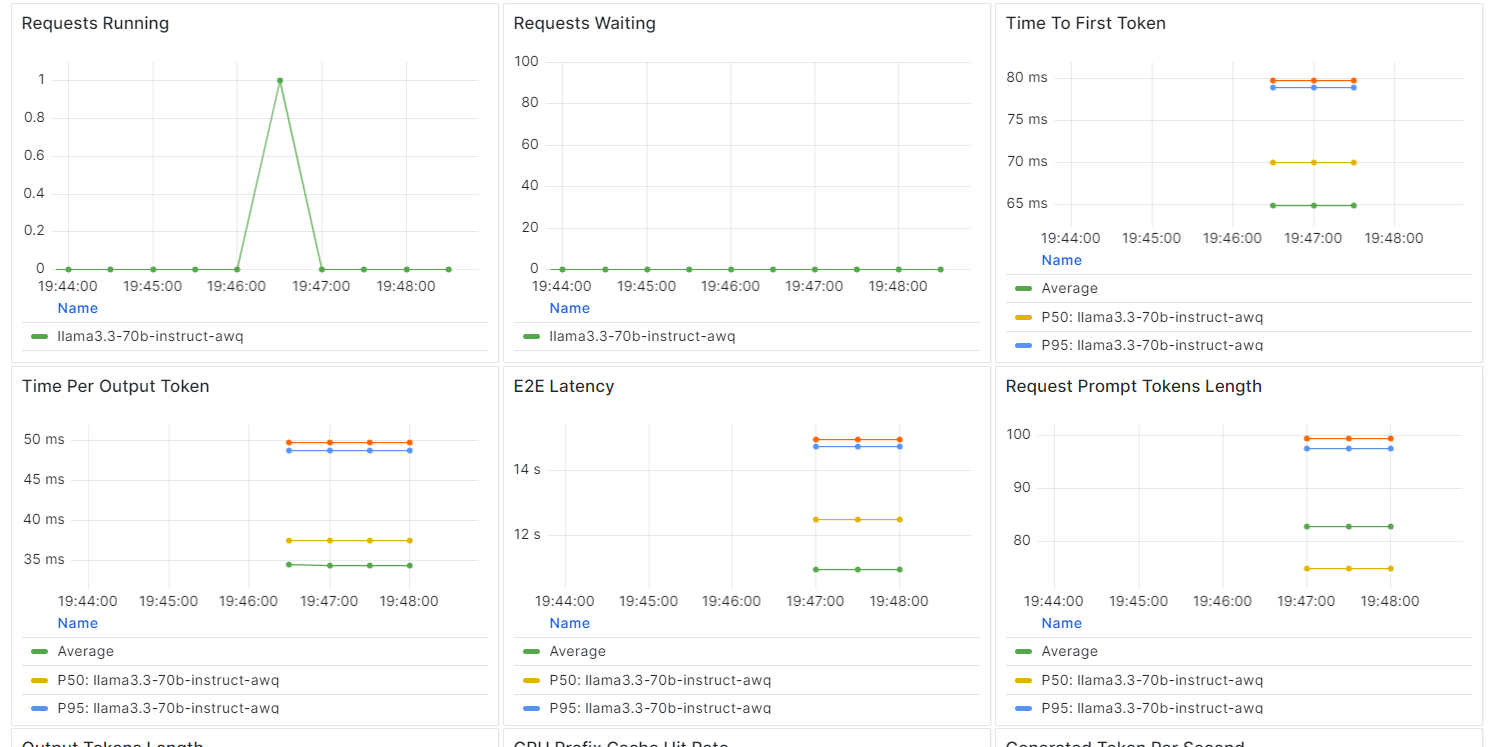
A criação e a implementação de um endpoint LLM tornaram-se extremamente simples com o ecossistema BentoML.
Ao escrever apenas algumas linhas de código para criar sua API, configurar um "bentofile" e implantar o modelo, você pode ter seu modelo em funcionamento em minutos. Depois de implantado, o endpoint pode ser acessado por meio de comandos CURL, da biblioteca de solicitações Python, do cliente BentoML ou do cliente OpenAI.
O resultado é um sistema altamente eficiente, de baixa latência e com alta taxa de transferência, capaz de lidar com várias solicitações simultaneamente. O BentoCloud também oferece escalonamento automático com base em sua configuração, garantindo que o sistema possa lidar com altos volumes de tráfego, aumentando ou diminuindo conforme necessário.
Para obter um guia mais detalhado sobre a implementação de LLMs com o BentoML, recomendo que você siga o site How to Deploy LLMs with BentoML: Um guia passo a passo.
Saiba mais sobre IA e LLMs com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
8 min
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer

