
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Googles neue Open-Source-Modellfamilie, Gemma 3, erfreut sich aufgrund ihrer beeindruckenden Leistung, die mit einigen der neuesten proprietären Modelle vergleichbar ist, schnell wachsender Beliebtheit. Gemma 3 bietet multimodale Funktionen, verbesserte Argumentationsfähigkeiten und unterstützt über 140 Sprachen.
In diesem Tutorial werden wir die Möglichkeiten von Gemma 3 erkunden und lernen, wie wir es anhand eines Datensatzes für die Beantwortung von Finanzfragen feinabstimmen können. Dieser Feinabstimmungsprozess wird die Genauigkeit des Modells beim Verstehen komplexer Finanzfragen erheblich verbessern und es in die Lage versetzen, präzise, kontextbezogene Antworten zu geben.
Bist du neu in der Feinabstimmung von LLMs? Keine Sorge, wir haben alles für dich! Folge unserem leicht verständlichen Tutorial, Fine-Tuning LLMs: Ein Leitfaden mit Beispielen, um zu lernen, wie die Feinabstimmung funktioniert .
Du kannst auch den Kurs Einführung in LLMs in Python besuchen, um mehr darüber zu erfahren, wie LLMs funktionieren, wie man sie fein abstimmt und wie man ihre Leistung bewertet.

Bild vom Autor
Die Gemma-Familie offener Modelle ist ein bedeutender Fortschritt, um modernste KI-Technologie für alle zugänglich zu machen. Die Gemma 3 basiert auf der Forschung und Technologie der Gemini 2.0 Modelle und bietet modernste Leistung bei geringem Gewicht und Effizienz.
Mit Größen von 1 Milliarde bis 27 Milliarden Parametern bietet Gemma 3 Flexibilität bei den Hardware- und Leistungsanforderungen und macht es einfacher denn je, fortschrittliche KI in reale Anwendungen zu integrieren.
Gemma 3 setzt neue Maßstäbe für die Leistung in seiner Klasse und übertrifft Konkurrenten wie das Llama3-405B, DeepSeek-V3und o3-mini in den menschlichen Präferenzbewertungen auf dem LMArena Leaderboard. Sein leichtes Design geht keine Kompromisse bei der Leistung ein und ermöglicht es Entwicklern, branchenführende Ergebnisse zu erzielen und gleichzeitig effizient zu arbeiten.
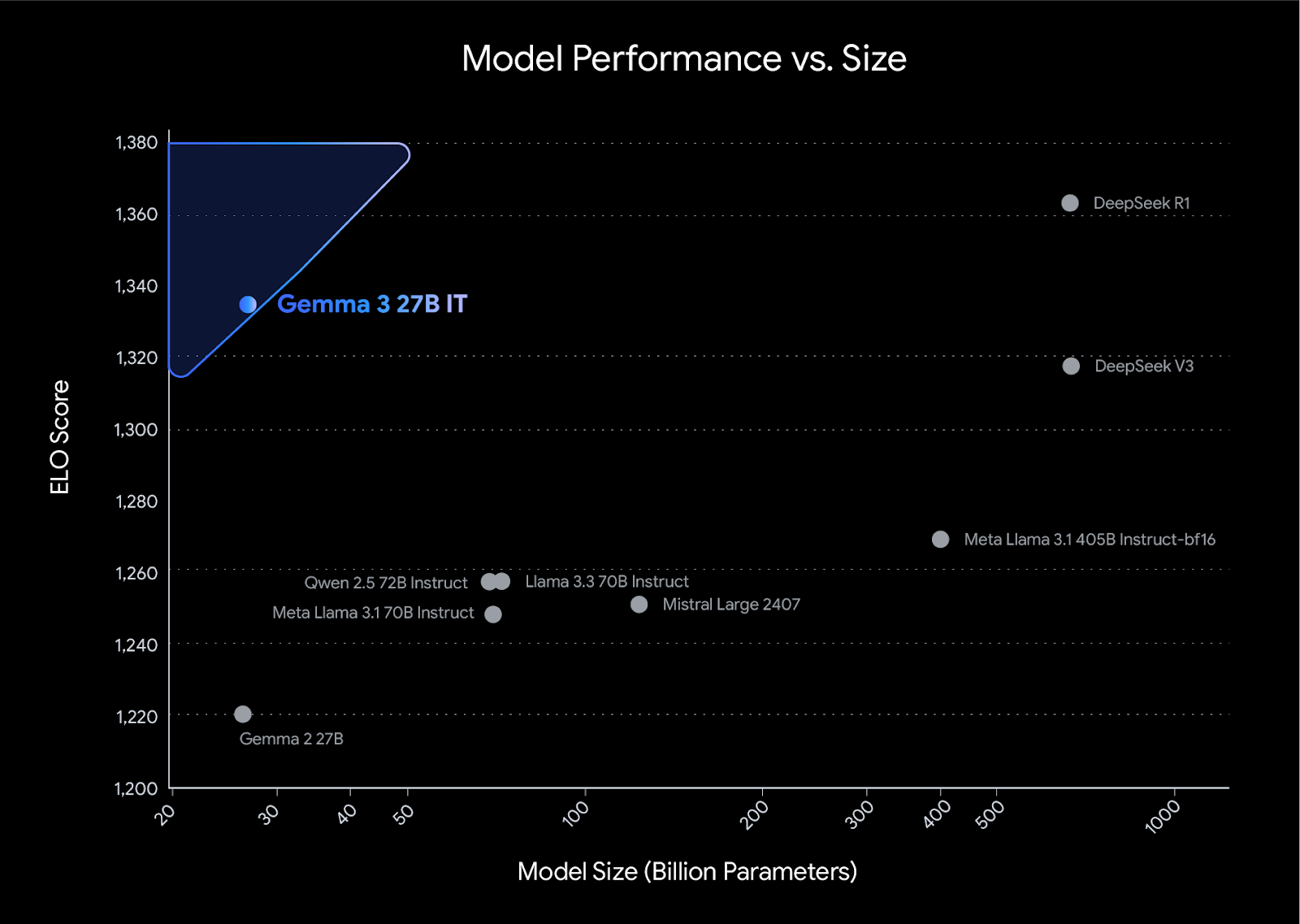
Quelle: Wir stellen vor: Gemma 3
In diesem Projekt werden wir Gemma 3 von Kaggle laden und die Daten von Hugging Face abrufen. Dann werden wir die Bibliotheken Transformers und TRL verwenden, um unser Modell zu verfeinern. Zum Vergleich werden wir die Antwort vor und nach der Feinabstimmung erstellen.
Wenn du lernen möchtest, wie du die Unsloth-Bibliothek zur Feinabstimmung deines Modells auf Reasoning-Daten verwendest, schau dir die Feinabstimmung DeepSeek R1 (Reasoning-Modell) Anleitung.
Installiere alle erforderlichen Python-Bibliotheken und stelle sicher, dass du die transformer Bibliothek.
%%capture
!pip install -U datasets
!pip install -U accelerate
!pip install -U peft
!pip install -U trl
!pip install -U bitsandbytes
!pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3Melde dich mit deinem API-Schlüssel beim Hugging Face-Client an. Der API-Schlüssel ist sicher in den Kaggle-Geheimnissen gespeichert, und wir werden ihn extrahieren und auf den Hugging Face-Client anwenden.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Füge das Gemma 3 4B IT-Modell zum Kaggle-Notizbuch hinzu, indem du auf die Schaltfläche "+ Eingabe hinzufügen" klickst, ähnlich wie du den Datensatz hinzufügst.
Lade das Modell und den Tokenizer mit Hilfe der transformers Bibliothek. Stelle sicher, dass das Modell auf device_map="auto" eingestellt ist, um ein Dual-GPU-Setup effektiv zu nutzen.
from transformers import AutoTokenizer, Gemma3ForConditionalGeneration
import torch
GEMMA_PATH = "/kaggle/input/gemma-3/transformers/gemma-3-4b-it/1"
model = Gemma3ForConditionalGeneration.from_pretrained(
GEMMA_PATH, device_map="auto",attn_implementation='eager'
).eval()
tokenizer = AutoTokenizer.from_pretrained(GEMMA_PATH)Bevor wir den Datensatz laden, erstellen wir den Stil für die Trainingsaufforderung und stellen drei Platzhalter bereit, die wir mit den Spalten des Datensatzes füllen werden. Dieser Souffleur-Stil wird uns helfen, einen argumentativen Text zu erstellen.
train_prompt_style="""
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Question:
{}
### Response:
<think>
{}
</think>
{}
"""Als Nächstes erstellen wir die Formatierungsfunktion, die die Spalten aus dem Datensatz verwendet und sie auf den Trainings-Prompt-Stil anwendet, um die Spalte "Text" zu erstellen. Achte darauf, dass du das EOS-Token am Ende der Antwort hinzufügst.
def formatting_prompts_func(examples):
inputs = examples["Open-ended Verifiable Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Wir laden nun die TheFinAI/Fino1_Reasoning_Path_FinQA Datensatz, der auf FinQA basiert und mit GPT-4o generierten Argumentationspfaden für die Beantwortung strukturierter Finanzfragen erweitert wurde. Danach wenden wir die Formatierungsfunktion auf den Datensatz an und erstellen die neue Textspalte, die durch den Prompt-Stil geformt wird.
from datasets import load_dataset
dataset = load_dataset("TheFinAI/Fino1_Reasoning_Path_FinQA", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]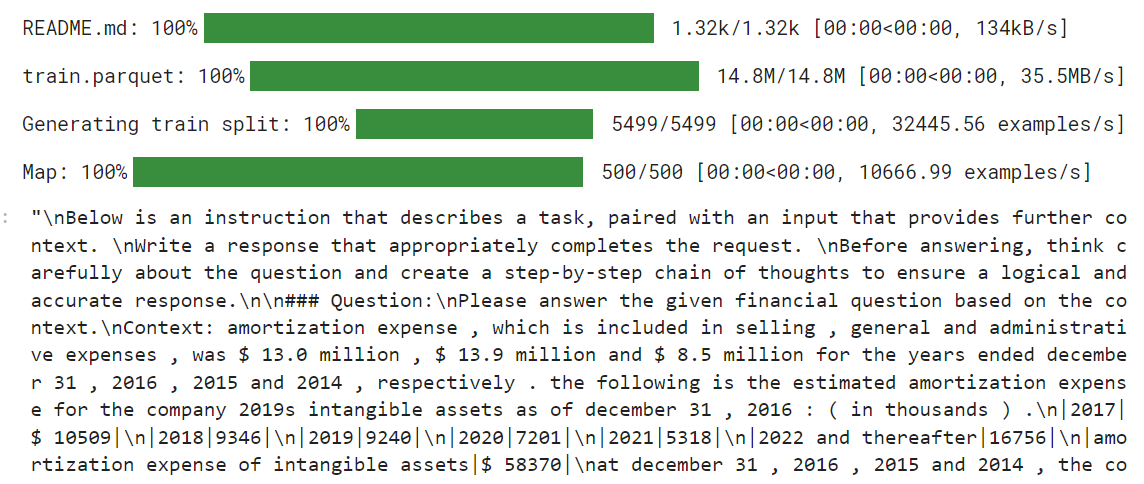
Der neue STF-Trainer akzeptiert die Tokenizer nicht, also müssen wir unsere Datensammlung mit dem Tokenizer erstellen und sie dem Trainer später zur Verfügung stellen.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # we're doing causal LM, not masked LM
)Bevor wir mit der Feinabstimmung des Modells beginnen, testen wir unser ursprüngliches Modell, um zu sehen, wie gut es bei der Generierung von Antworten ist. Wir erstellen den Prompt-Stil mit zwei statt drei Platzhaltern.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Question:
{}
### Response:
<think>
{}
"""Dann wenden wir den Prompt-Stil auf die Frage an, wandeln sie in Tokens um und geben sie an das Modell weiter. Danach erzeugen wir die Antwort und wandeln die Token wieder in Text um.
question = dataset[0]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Die Antwort ist kurz und alles andere als präzise.
<think>
The question asks for the portion of the estimated amortization expense that will be recognized in 2017.
The provided table shows the estimated amortization expense for intangible assets for the years 2017, 2018, 2019, 2020, 2021, and 2022 and thereafter.
The amortization expense for 2017 is $10,509.
</think>
$10,509Hier ist die Antwort aus dem Datensatz. Die Antwort sollte ein Verhältnis sein, nicht der Betrag.
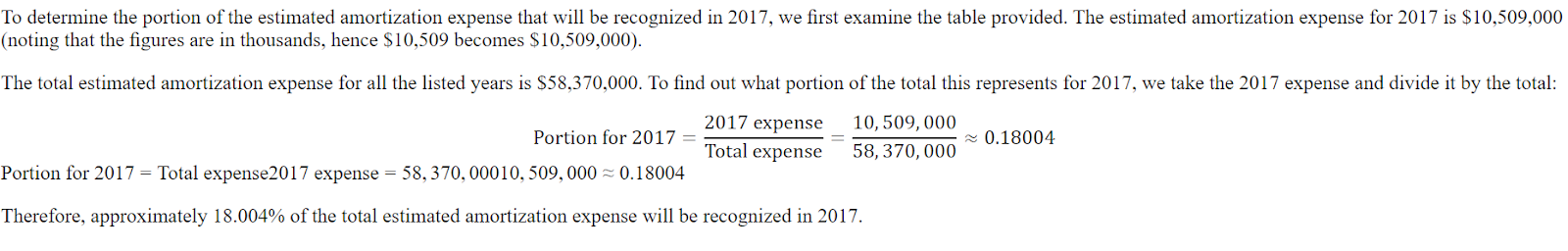
Sogar ChatGPT hat sich geirrt, und wir mussten es bitten, den Fehler zu korrigieren. Danach hat sie verstanden, dass sie einen Fehler gemacht hat und ihn korrigiert.

Wir werden nun den Datensatz, das Modell, die Datenerfassung, die Trainingsargumente und die LoRA-Konfiguration an den SFTTrainer übergeben.
from trl import SFTTrainer
from transformers import TrainingArguments
from peft import LoraConfig
# LoRA Configuration
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Lösche den CUDA-Zwischenspeicher, bevor du den Straining-Prozess startest.
torch.cuda.empty_cache()
trainer_stats = trainer.train()Es dauerte fast 1 Stunde und 20 Minuten, um eine Epoche abzuschließen. Wie wir sehen können, hat sich der Verlust allmählich verringert.
Testen wir unser ausgefeiltes Modell, indem wir eine Beispielfrage stellen, wie wir es zuvor getan haben.
question = dataset[0]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Der Argumentationsteil ist jetzt detailliert und korrekt. Die Antwort ist auch richtig.
<think>
Alright, let's figure out what portion of the estimated amortization expense will be recognized in 2017. First, I need to see what the total estimated amortization expense is for the years 2017 through 2022. Looking at the numbers, it's $58,370.
Now, I need to find out how much of that is specifically for 2017. The table shows that the estimated amortization expense for 2017 is $10,509.
So, to find out what portion of the total expense is for 2017, I'll divide the 2017 expense by the total expense. That's $10,509 divided by $58,370.
Let's do the math: $10,509 divided by $58,370 gives me approximately 0.1805.
Now, to express this as a percentage, I'll multiply by 100. So, 0.1805 times 100 gives me 18.05%.
Therefore, about 18.05% of the estimated amortization expense for the years 2017 through 2022 will be recognized in 2017.
</think>
About 18.05% of the estimated amortization expense for the years 2017 through 2022 will be recognized in 2017.Lass uns eine andere Frage stellen.
question = dataset[10]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Wie wir sehen können, haben wir das Modell erfolgreich auf den neuen Datensatz abgestimmt. Sie ist jetzt genau und folgt der Argumentation und dem Antwortstil.
<think>
Alright, let's figure out the total purchase price of Impella Cardiosystems. First, we know the purchase price was $45.1 million, but there's a contingent payment of $5.6 million that could be earned. So, we need to see if we can figure out how much of that $5.6 million is actually likely to be paid.
Now, the question mentions that the contingent payment is triggered by FDA approvals. Since we're dealing with a medical device, getting FDA clearance is pretty important. Let's assume that the FDA approval for the Impella 2.5 is a good sign that the contingent payments will be made.
Okay, so if we assume all the contingent payments are earned, we just need to add the $5.6 million to the original $45.1 million. Let's do the math: $45.1 million plus $5.6 million equals $50.7 million.
Hmm, let's double-check our work. We're adding $45.1 million to $5.6 million, which gives us $50.7 million. Yep, that seems right.
So, if we assume all the contingent payments are earned, the total purchase price of Impella Cardiosystems would be $50.7 million.
</think>
The total purchase price of Impella Cardiosystems, assuming all contingent consideration is earned, would be $50.7 million.Die Feinabstimmung eines Modells erfordert Fachwissen, Geld und Zeit. In manchen Fällen brauchst du vielleicht einfach eine bessere RAG-Pipeline, um deine Bedürfnisse zu erfüllen. Bitte lies den Leitfaden RAG vs. Fine-Tuning: Ein umfassendes Tutorial mit praktischen Beispielen um deine Anforderungen zu verstehen.
Zuerst werden wir das Modell und den Tokenizer lokal speichern.
new_model_online = "kingabzpro/Gemma-3-4B-Fin-QA-Reasoning"
new_model_local = "Gemma-3-4B-Fin-QA-Reasoning"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local)Dann schieben wir das Modell zum Hugging Face Hub.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online savingBei diesem Prozess wird zunächst das Modell-Repository erstellt und dann alle Modell-, Tokenizer- und Konfigurationsfelder auf den Remote-Server übertragen.
Quelle: kingabzpro/Gemma-3-4B-Fin-QA-Reasoning - Hugging Face
Wenn du Probleme hast, den obigen Code auszuführen, haben wir ein Kaggle-Notizbuch erstellt, das jeder klonen und selbst ausführen kann, um den Prozess besser zu verstehen.
Die Feinabstimmung des Gemma 3 Modells bringt einige Herausforderungen mit sich: Du könntest auf Hardware-Probleme, Bibliotheksprobleme, Probleme mit der Speicherfragmentierung und mehr stoßen. Dieser Leitfaden zeigt dir, wie du ein beliebiges Modell in ein Argumentationsmodell umwandeln kannst, um zukünftige Probleme mit Software und Hardware zu vermeiden.
In diesem Tutorial haben wir uns mit den Funktionen des Gemma 3-Modells beschäftigt und wie wir es mit den kostenlosen GPU-Ressourcen, die auf Kaggle zur Verfügung stehen, ganz einfach auf den Reasoning-Datensatz abstimmen können.
Nimm die Feinabstimmung mit Llama 3 Kurs, um Feinabstimmungsaufgaben mit TorchTune zu lösen und effiziente Feinabstimmungstechniken wie Quantisierung zu lernen.
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
