Kurs
Text Mining mit Bag-of-Words in R
4 Std.
44.3K
Die Textklassifizierung ist eine häufige NLP-Aufgabe, die zur Lösung von Geschäftsproblemen in verschiedenen Bereichen eingesetzt wird. Das Ziel der Textklassifizierung ist es, eine Klasse von ungesehenen Textdokumenten zu kategorisieren oder vorherzusagen, oft mit Hilfe von überwachtem maschinellem Lernen.
Ähnlich wie ein Klassifizierungsalgorithmus, der auf einem Tabellendatensatz trainiert wurde, um eine Klasse vorherzusagen, nutzt auch die Textklassifizierung überwachtes maschinelles Lernen. Der Hauptunterschied zwischen den beiden ist die Tatsache, dass bei der Textklassifizierung Text beteiligt ist.
Du kannst auch eine Textklassifizierung ohne überwachtes maschinelles Lernen durchführen. Anstelle von Algorithmen kann auch ein manuelles, regelbasiertes System entwickelt werden, das die Aufgabe der Textklassifizierung übernimmt. Im nächsten Abschnitt werden wir die Vor- und Nachteile von regelbasierten und maschinenlernbasierten Textklassifizierungssystemen vergleichen.
Wenn du mehr über überwachtes maschinelles Lernen erfahren möchtest, schau dir unseren separaten Artikel an.
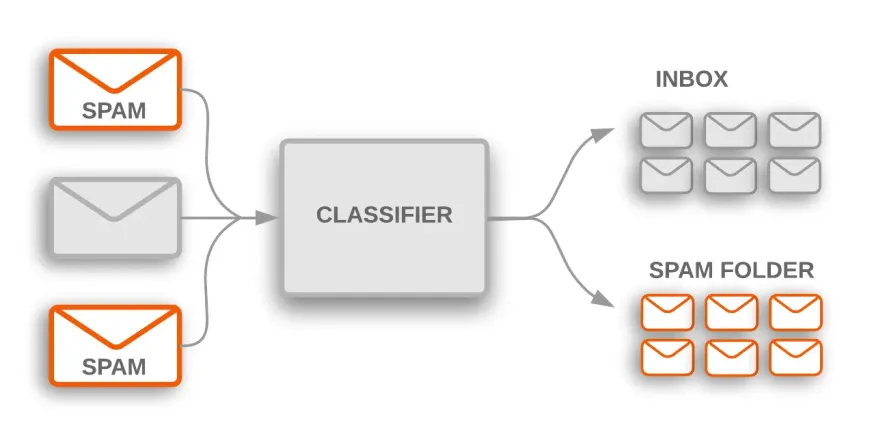
Es gibt viele praktische Anwendungsfälle für Textklassifizierung in vielen Branchen. Ein Spamfilter ist zum Beispiel eine gängige Anwendung, die Textklassifizierungen verwendet, um E-Mails in Spam- und Nicht-Spam-Kategorien zu sortieren.
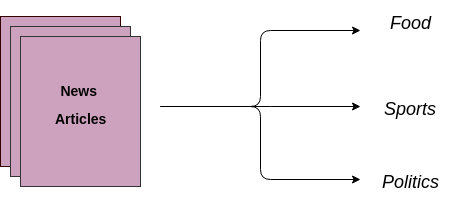
Ein weiterer Anwendungsfall ist die automatische Zuordnung von Textdokumenten zu vorgegebenen Kategorien. Ein überwachtes maschinelles Lernmodell wird auf gelabelten Daten trainiert, die sowohl den Rohtext als auch das Ziel enthalten. Sobald ein Modell trainiert ist, wird es in der Produktion verwendet, um eine Kategorie (Label) für die neuen und ungesehenen Daten (Artikel/Blogs, die in der Zukunft geschrieben werden) zu erhalten.
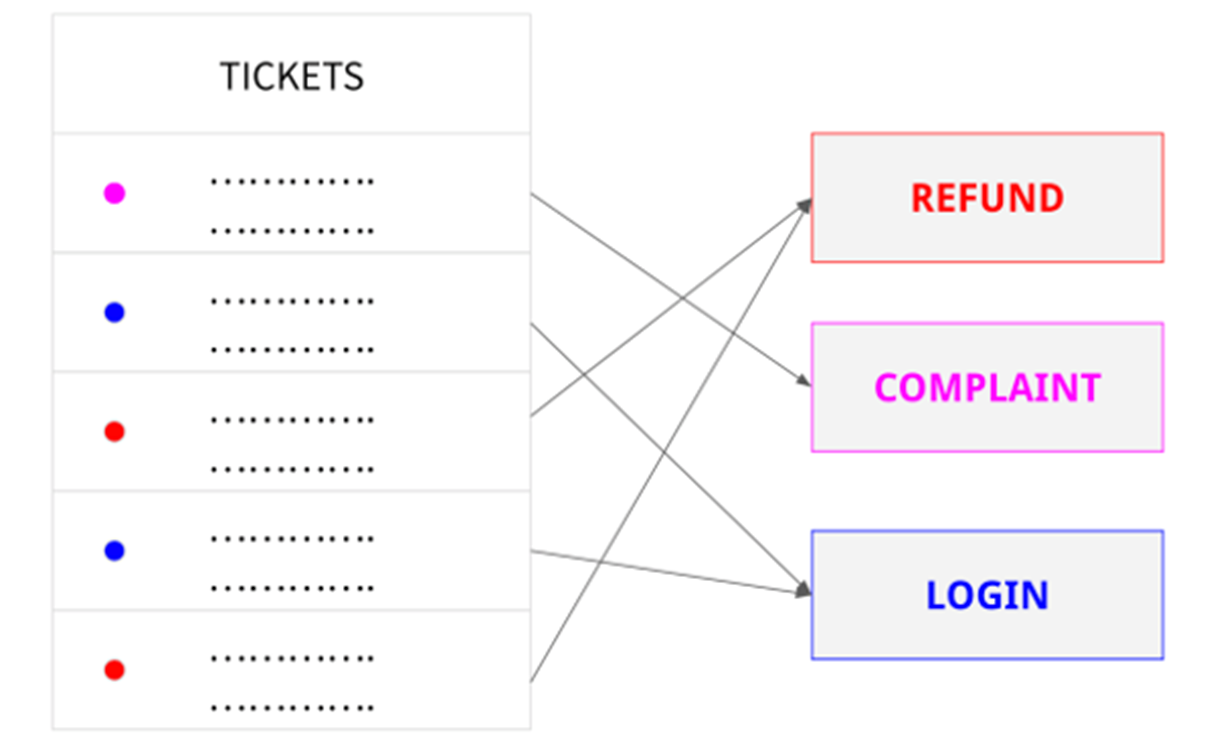
Ein Unternehmen könnte die Textklassifizierung nutzen, um Kundenanfragen automatisch nach Themen zu kategorisieren oder um Anfragen zu priorisieren und an die richtige Abteilung weiterzuleiten.
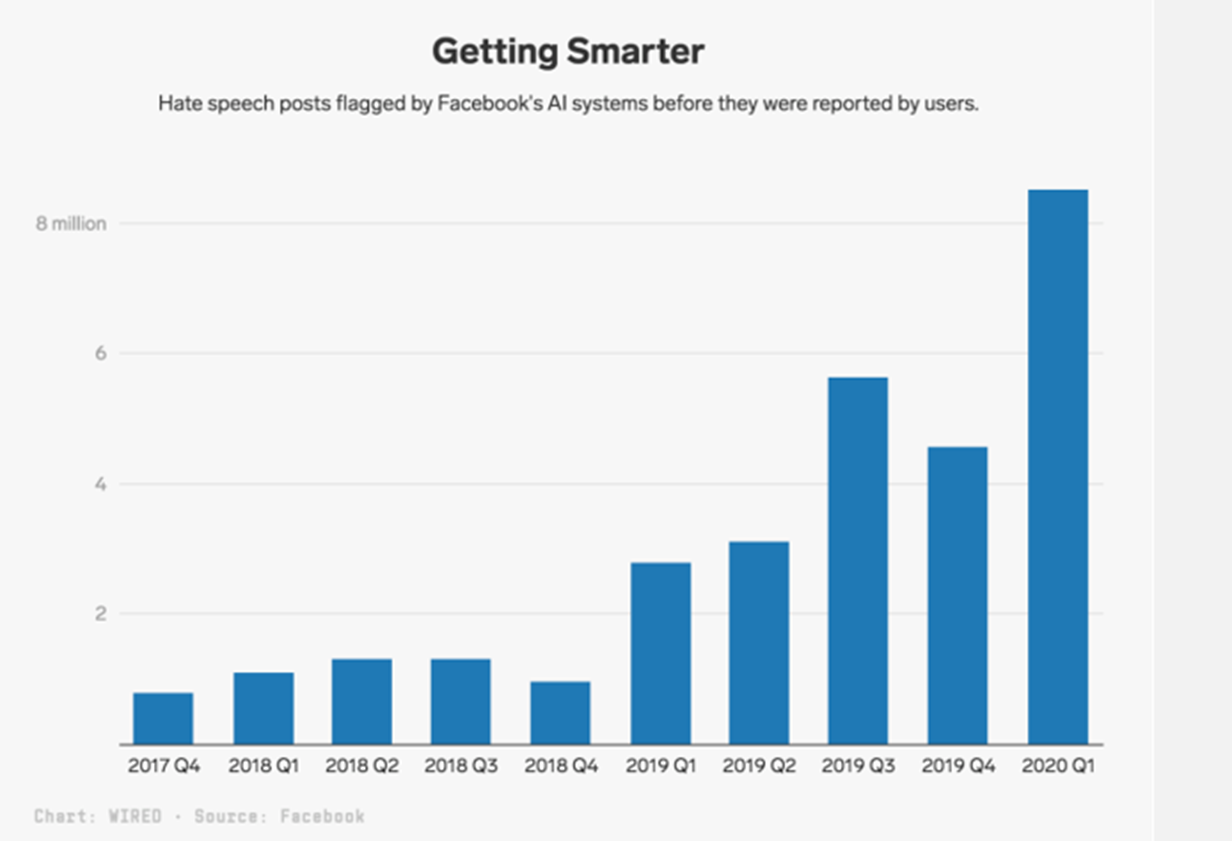
Mit über 1,7 Milliarden täglich aktiven Nutzerinnen und Nutzern gibt es auf Facebook zwangsläufig Inhalte, die gegen die Regeln verstoßen. Hassreden gehören zu diesen unerwünschten Inhalten.
Facebook geht dieses Problem an, indem es eine manuelle Überprüfung von Beiträgen verlangt, die ein KI-Textklassifikator als Hassrede identifiziert hat. Beiträge, die von der KI markiert wurden, werden auf die gleiche Weise untersucht wie Beiträge, die von den Nutzern gemeldet wurden. Allein in den ersten drei Monaten des Jahres 2020 hat die Plattform 9,6 Millionen Inhalte entfernt, die als Hassrede eingestuft worden waren.
Es gibt hauptsächlich zwei Arten von Textklassifikationssystemen: regelbasierte und auf maschinellem Lernen basierende Textklassifikation.
Regelbasierte Verfahren verwenden eine Reihe von manuell erstellten Sprachregeln, um Text in Kategorien oder Gruppen zu kategorisieren. Diese Regeln sagen dem System, dass es den Text anhand des Inhalts in eine bestimmte Kategorie einordnen soll, indem es semantisch relevante Textelemente verwendet. Jede Regel besteht aus einem Antezedens oder Muster und einer projizierten Kategorie.
Stell dir zum Beispiel vor, du hast eine Menge neuer Artikel und dein Ziel ist es, diese den relevanten Kategorien wie Sport, Politik, Wirtschaft usw. zuzuordnen.
Bei einem regelbasierten Klassifizierungssystem überprüfst du eine Reihe von Dokumenten, um linguistische Regeln wie diese aufzustellen:
Regelbasierte Systeme können mit der Zeit verfeinert werden und sind für Menschen verständlich. Diese Strategie hat jedoch auch einige Nachteile.
Diese Systeme erfordern zunächst einmal fundierte Fachkenntnisse auf dem Gebiet. Sie nehmen viel Zeit in Anspruch, denn die Erstellung von Regeln für ein kompliziertes System kann schwierig sein und erfordert häufig umfangreiche Studien und Tests.
Da das Hinzufügen neuer Regeln die Ergebnisse der bereits bestehenden Regeln verändern kann, sind regelbasierte Systeme auch schwer zu warten und lassen sich nicht effektiv skalieren.
Die auf maschinellem Lernen basierende Textklassifizierung ist ein überwachtes maschinelles Lernproblem. Es lernt die Zuordnung von Eingabedaten (Rohtext) zu den Bezeichnungen (auch Zielvariablen genannt). Dies ist ähnlich wie bei der Klassifizierung von Nicht-Text-Problemen, bei denen wir einen überwachten Klassifizierungsalgorithmus auf einem Tabellendatensatz trainieren, um eine Klasse vorherzusagen.
Wie jedes andere überwachte maschinelle Lernen besteht auch das maschinelle Lernen zur Textklassifizierung aus zwei Phasen: Training und Vorhersage.
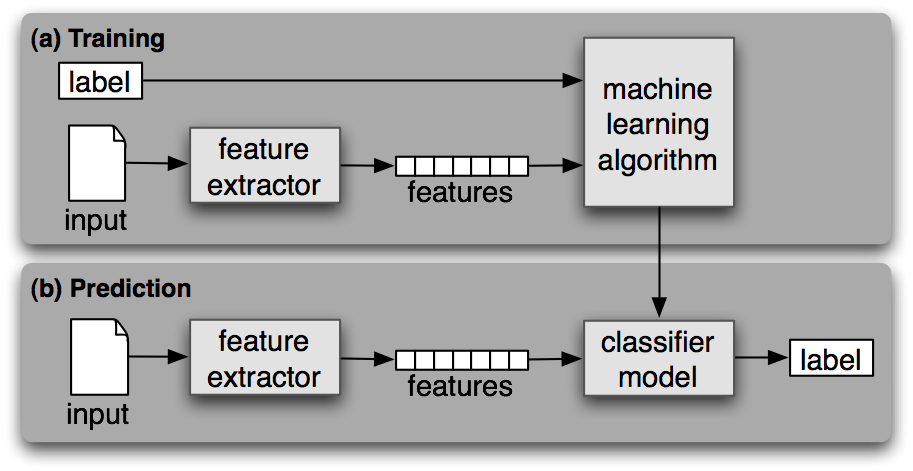
In der Trainingsphase wird ein überwachter Algorithmus für maschinelles Lernen auf den beschrifteten Eingabedatensatz trainiert. Am Ende dieses Prozesses erhalten wir ein trainiertes Modell, das wir verwenden können, um Vorhersagen (Labels) für neue und ungesehene Daten zu erhalten.
Sobald ein maschinelles Lernmodell trainiert ist, kann es verwendet werden, um Kennzeichnungen für neue und ungesehene Daten vorherzusagen. Dies geschieht in der Regel, indem das beste Modell aus einer früheren Phase als API auf dem Server bereitgestellt wird.
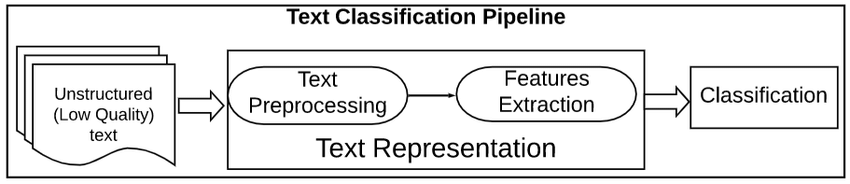
Die Vorverarbeitung von Textdaten ist ein wichtiger Schritt in jeder Aufgabe der natürlichen Sprachverarbeitung. Es hilft bei der Reinigung und Vorbereitung der Textdaten für die weitere Verarbeitung oder Analyse.
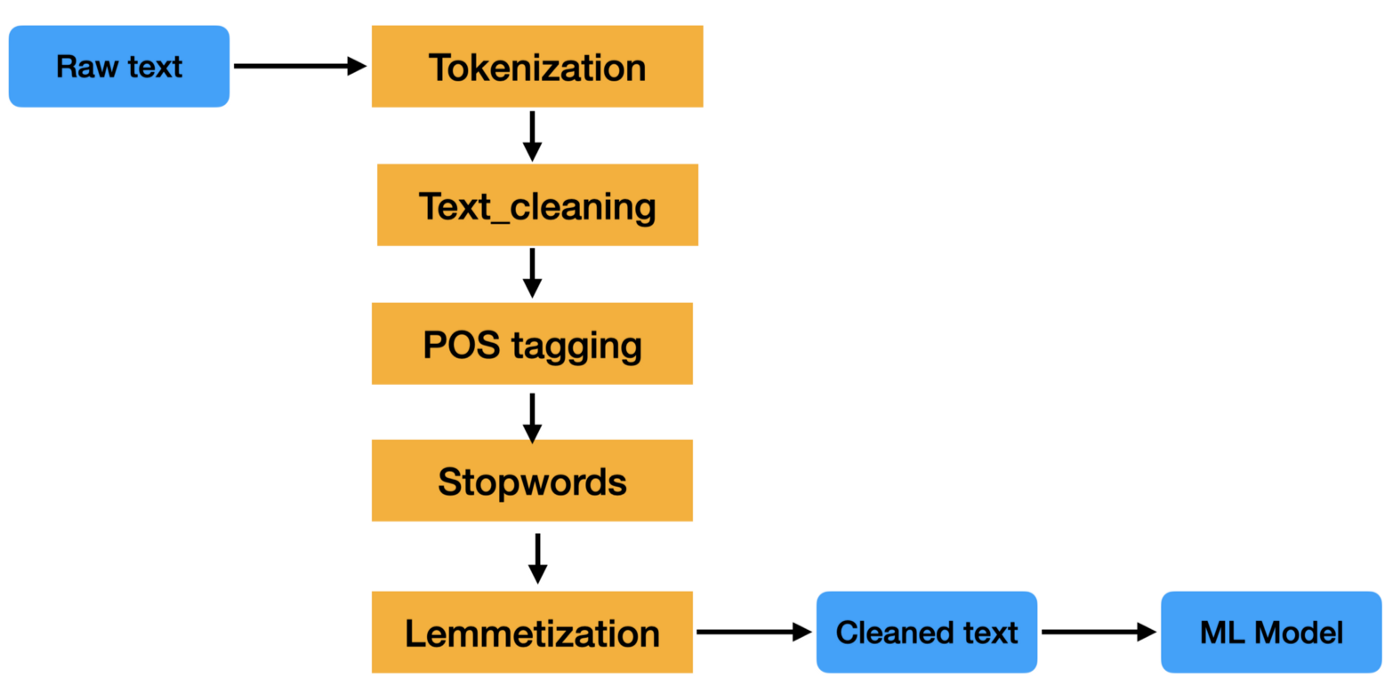
Eine Textvorverarbeitungspipeline ist eine Reihe von Verarbeitungsschritten, die auf rohe Textdaten angewendet werden, um sie für die Verwendung in der Verarbeitung natürlicher Sprache vorzubereiten.
Die Schritte in einer Textvorverarbeitungspipeline können variieren, aber sie umfassen in der Regel Aufgaben wie Tokenisierung, Stoppwortentfernung, Stemming und Lemmatisierung. Diese Schritte helfen dabei, den Umfang der Textdaten zu reduzieren und die Genauigkeit von NLP-Aufgaben wie Textklassifizierung und Informationsextraktion zu verbessern.
Textdaten sind schwer zu verarbeiten, weil sie unstrukturiert sind und oft viel Rauschen enthalten. Dieser Lärm kann in Form von Rechtschreibfehlern, grammatikalischen Fehlern und nicht standardmäßiger Formatierung auftreten. Eine Pipeline zur Textvorverarbeitung soll dieses Rauschen beseitigen, damit die Textdaten leichter analysiert werden können.
Willst du mehr darüber erfahren? Schau dir unseren Lernpfad zum Thema Text Mining mit R an.
Die beiden gebräuchlichsten Methoden zur Extraktion von Merkmalen aus Text oder, anders ausgedrückt, zur Umwandlung von Textdaten (Strings) in numerische Merkmale, damit ein maschinelles Lernmodell trainiert werden kann, sind: Bag of Words (auch bekannt als CountVectorizer) und Tf-IDF.
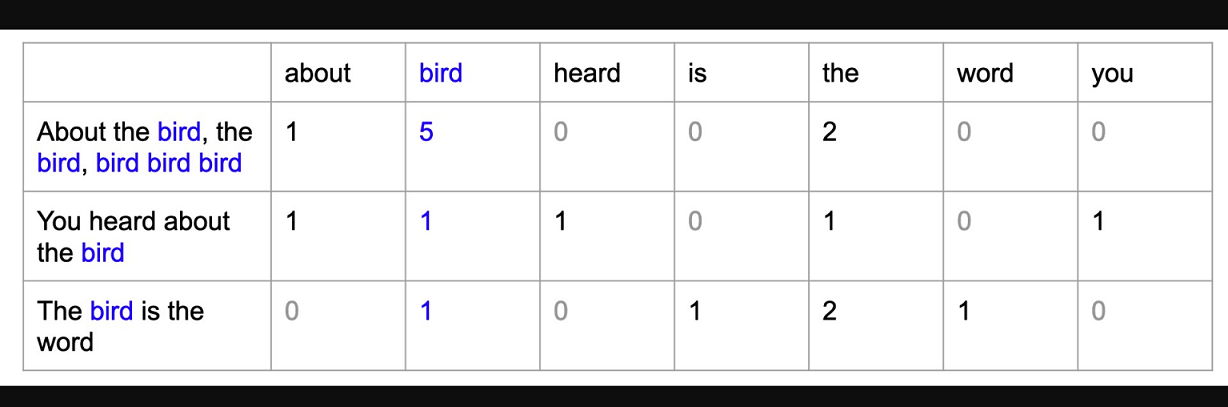
Ein Bag of Words (BoW)-Modell ist eine einfache Möglichkeit, Textdaten als numerische Merkmale darzustellen. Dabei wird ein Vokabular bekannter Wörter aus dem Korpus erstellt und dann für jedes Dokument ein Vektor erstellt, der die Häufigkeit des Auftretens jedes Worts enthält.
TF-IDF steht für Term Frequency-Inverse Document Frequency und ist eine weitere Möglichkeit, Text als numerische Merkmale darzustellen. Das Bag of Words (BoW)-Modell hat einige Schwächen, die Tf-IDF ausgleicht. Wir werden in diesem Artikel nicht näher darauf eingehen, aber wenn du dieses Konzept näher kennenlernen möchtest, schau dir unseren Kurs Einführung in die natürliche Sprachverarbeitung in Python an.
Das TF-IDF-Modell unterscheidet sich vom Bag of Words-Modell dadurch, dass es sowohl die Häufigkeit der Wörter im Dokument als auch die inverse Dokumenthäufigkeit berücksichtigt. Das bedeutet, dass das TF-IDF-Modell mit größerer Wahrscheinlichkeit die wichtigen Wörter in einem Dokument identifiziert als das Bag-of-Words-Modell.
Beginne damit, den Datensatz direkt von diesem GitHub-Link zu importieren. Die SMS-Spam-Sammlung ist ein Datensatz, der 5.574 SMS-Nachrichten in englischer Sprache mit der Bezeichnung Spam oder Ham (nicht Spam) enthält. Unser Ziel ist es, ein maschinelles Lernmodell zu trainieren, das aus dem SMS-Text und dem Label lernt und in der Lage ist, die Klasse der SMS-Nachrichten vorherzusagen.
# reading data
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv', encoding='latin-1')
data.head()
Nachdem du den Datensatz gelesen hast, bemerkst du, dass es ein paar zusätzliche Spalten gibt, die wir nicht brauchen. Wir brauchen nur die ersten beiden Spalten. Lass uns die restlichen Spalten löschen und die ersten beiden Spalten umbenennen.
# drop unnecessary columns and rename cols
data.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)
data.columns = ['label', 'text']
data.head()
Führen wir ein paar grundlegende EDA-Maßnahmen durch, um zu sehen, ob es fehlende Werte im Datensatz gibt und wie hoch der Zielsaldo ist.
# check missing values
data.isna().sum()
# check data shape
data.shape>>> (5572, 2)# check target balance
data['label'].value_counts(normalize = True).plot.bar()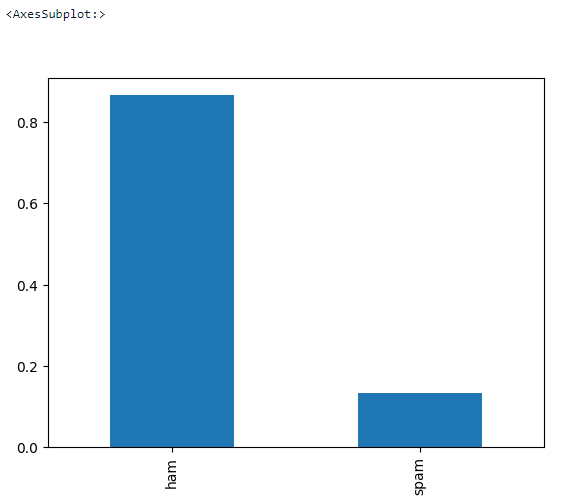
Hier findet die Textbereinigung statt. Es ist eine Schleife, die alle 5.572 Dokumente durchläuft und Folgendes tut:
# text preprocessing
# download nltk
import nltk
nltk.download('all')
# create a list text
text = list(data['text'])
# preprocessing loop
import re
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
corpus = []
for i in range(len(text)):
r = re.sub('[^a-zA-Z]', ' ', text[i])
r = r.lower()
r = r.split()
r = [word for word in r if word not in stopwords.words('english')]
r = [lemmatizer.lemmatize(word) for word in r]
r = ' '.join(r)
corpus.append(r)
#assign corpus to data['text']
data['text'] = corpus
data.head()
Wir teilen den Datensatz vor der Merkmalsextraktion in Training und Test auf.
# Create Feature and Label sets
X = data['text']
y = data['label']
# train test split (66% train - 33% test)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=123)
print('Training Data :', X_train.shape)
print('Testing Data : ', X_test.shape)>>> Training Data : (3733,)
>>> Testing Data : (1839,)Hier verwenden wir das Bag of Words-Modell (CountVectorizer), um den bereinigten Text in numerische Merkmale umzuwandeln. Dies wird für das Training des maschinellen Lernmodells benötigt.
# Train Bag of Words model
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X_train_cv = cv.fit_transform(X_train)
X_train_cv.shape>>> (3733, 7020)In diesem Teil trainieren wir ein logistisches Regressionsmodell und werten die Konfusionsmatrix des trainierten Modells aus.
# Training Logistic Regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train_cv, y_train)
# transform X_test using CV
X_test_cv = cv.transform(X_test)
# generate predictions
predictions = lr.predict(X_test_cv)
predictions>>> array(['ham', 'spam', 'ham', ..., 'ham', 'ham', 'spam'], dtype=object)# confusion matrix
import pandas as pd
from sklearn import metrics
df = pd.DataFrame(metrics.confusion_matrix(y_test,predictions), index=['ham','spam'], columns=['ham','spam'])
df
Weitere Informationen findest du in der DataLab-Arbeitsmappe.
NLP ist nach wie vor ein aktiver Bereich der Forschung und Entwicklung, in dem viele Universitäten und Unternehmen an der Entwicklung neuer Algorithmen und Anwendungen arbeiten. NLP ist ein interdisziplinäres Fachgebiet, in dem Forscherinnen und Forscher aus verschiedenen Bereichen kommen, darunter Informatik, Linguistik, Psychologie und Kognitionswissenschaften.
Die Textklassifizierung ist eine leistungsstarke und weit verbreitete Aufgabe im NLP, mit der eine Klasse von ungesehenen Textdokumenten automatisch kategorisiert oder vorhergesagt werden kann, oft mit Hilfe von überwachtem maschinellem Lernen.
Sie ist nicht immer genau, aber wenn sie richtig eingesetzt wird, kann sie einen großen Mehrwert für deine Analysen bieten. Es gibt viele verschiedene Wege und Algorithmen, um einen Textklassifikator zu erstellen, und es gibt keinen einzigen Ansatz, der am besten ist. Es ist wichtig, zu experimentieren und herauszufinden, was für deine Daten und deine Zwecke am besten funktioniert.
Top Kurse
Kurs
Kurs
Kurs