Cours
Text mining avec sac de mots en R
4 h
44.3K
La classification des textes est une tâche NLP courante utilisée pour résoudre des problèmes commerciaux dans différents domaines. L'objectif de la classification des textes est de catégoriser ou de prédire une classe de documents textuels inédits, souvent avec l'aide de l'apprentissage automatique supervisé.
À l'instar d'un algorithme de classification qui a été entraîné sur un ensemble de données tabulaires pour prédire une classe, la classification des textes fait également appel à l'apprentissage automatique supervisé. Le fait que le texte soit impliqué dans la classification des textes est la principale distinction entre les deux.
Vous pouvez également effectuer une classification de texte sans recourir à l'apprentissage automatique supervisé. Au lieu d'algorithmes, un système manuel basé sur des règles peut être conçu pour effectuer la tâche de classification des textes. Nous comparerons et examinerons les avantages et les inconvénients des systèmes de classification de textes basés sur des règles et sur l'apprentissage automatique dans la section suivante.
Si vous souhaitez en savoir plus sur l'apprentissage automatique supervisé, consultez notre article séparé.
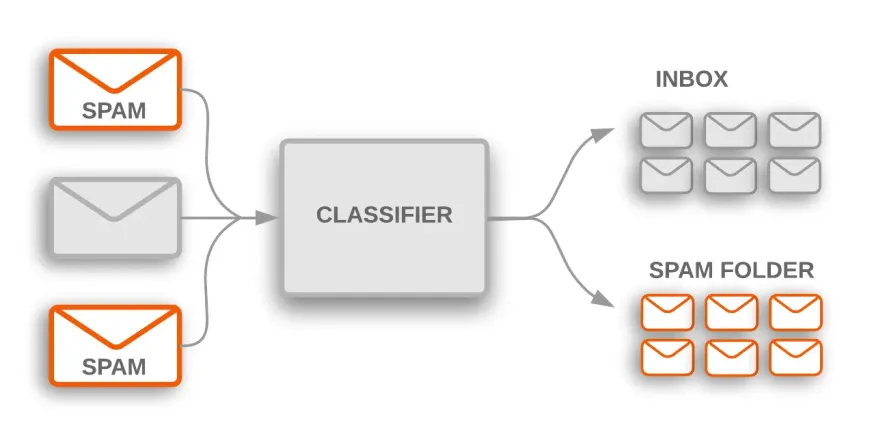
Il existe de nombreux cas d'utilisation pratique pour la classification des textes dans de nombreux secteurs. Par exemple, un filtre anti-spam est une application courante qui utilise la classification des textes pour classer les courriels dans des catégories de spam et de non-spam.
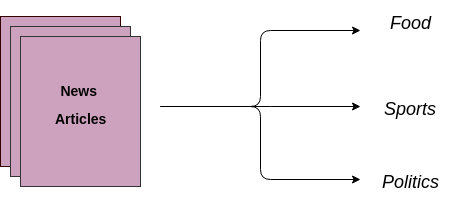
Un autre cas d'utilisation consiste à classer automatiquement des documents textuels dans des catégories prédéterminées. Un modèle d'apprentissage automatique supervisé est formé sur des données étiquetées, qui comprennent à la fois le texte brut et la cible. Une fois le modèle formé, il est utilisé en production pour obtenir une catégorie (étiquette) sur les données nouvelles et inédites (articles/blogs écrits dans le futur).
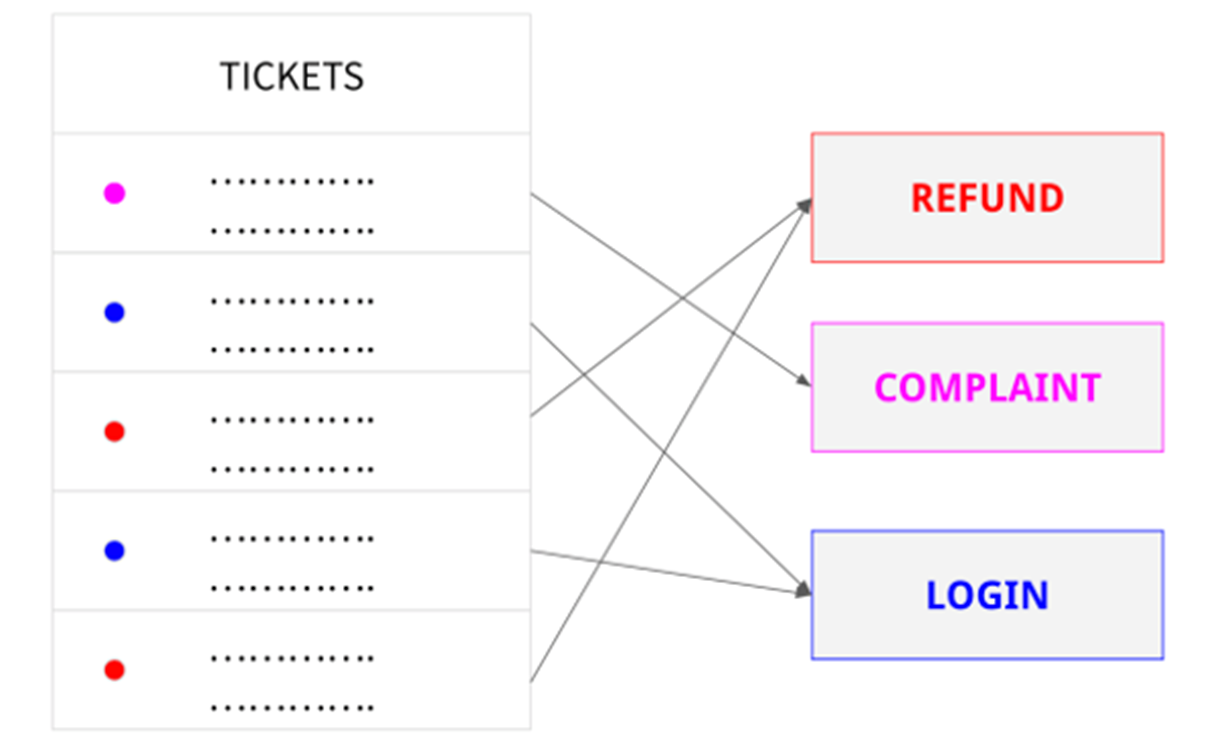
Une entreprise peut utiliser la classification de texte pour classer automatiquement les demandes d'assistance à la clientèle par sujet ou pour hiérarchiser et acheminer les demandes vers le service approprié.
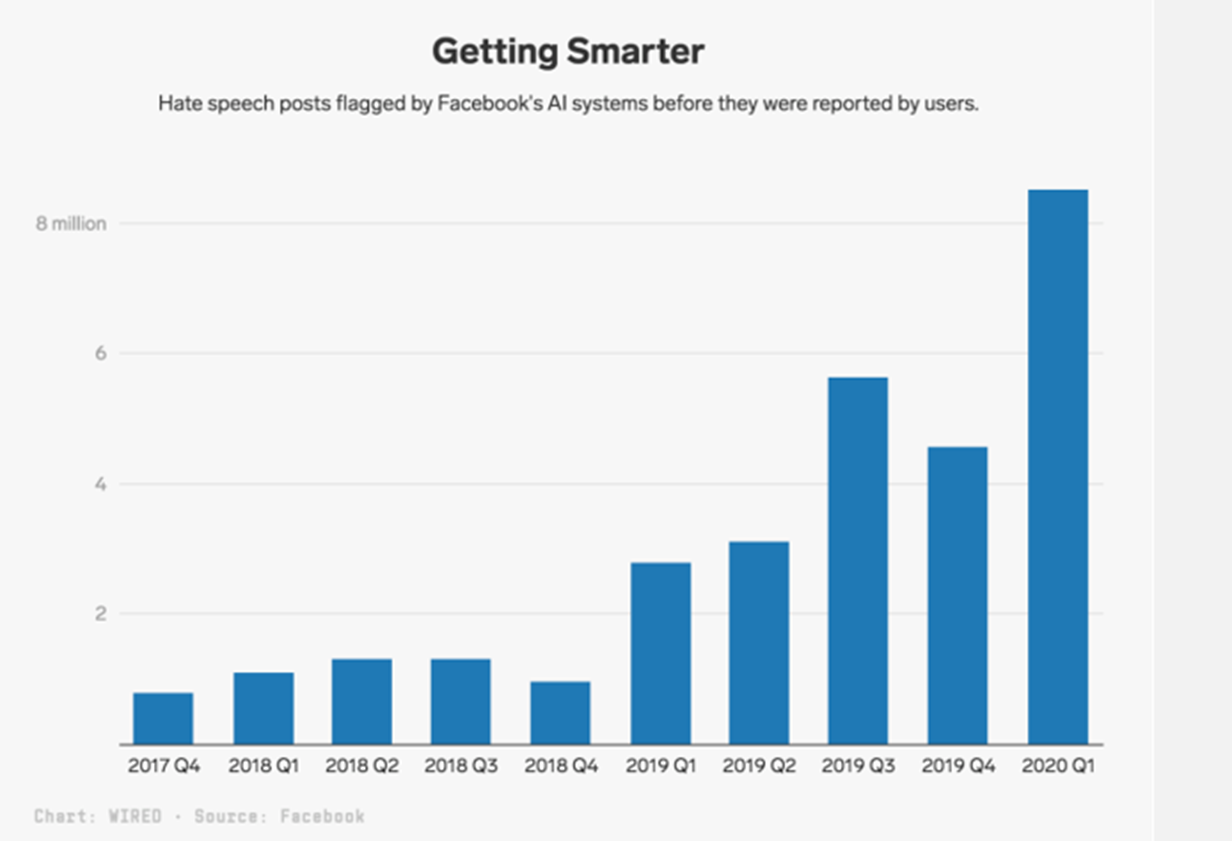
Avec plus de 1,7 milliard d'utilisateurs actifs quotidiens, Facebook est inévitablement confronté à des contenus créés sur le site qui sont contraires aux règles. Les propos haineux font partie de ces contenus indésirables.
Facebook s'attaque à ce problème en demandant un examen manuel des publications qu'un classificateur de texte IA a identifiées comme étant des discours haineux. Les messages signalés par l'IA sont examinés de la même manière que les messages signalés par les utilisateurs. En fait, au cours des trois premiers mois de 2020, la plateforme a supprimé 9,6 millions de contenus classés comme discours de haine.
Il existe principalement deux types de systèmes de classification des textes : la classification basée sur des règles et la classification basée sur l'apprentissage automatique.
Les techniques basées sur des règles utilisent un ensemble de règles linguistiques élaborées manuellement pour classer le texte dans des catégories ou des groupes. Ces règles indiquent au système de classer un texte dans une catégorie particulière sur la base de son contenu en utilisant des éléments textuels sémantiquement pertinents. Chaque règle se compose d'un antécédent ou d'un modèle et d'une catégorie projetée.
Par exemple, imaginez que vous avez des tonnes de nouveaux articles et que votre objectif est de les classer dans des catégories pertinentes telles que Sports, Politique, Économie, etc.
Avec un système de classification basé sur des règles, vous procéderez à un examen humain de quelques documents afin d'élaborer des règles linguistiques telles que celle-ci :
Les systèmes basés sur des règles peuvent être affinés au fil du temps et sont compréhensibles pour les humains. Cette stratégie présente toutefois certains inconvénients.
Ces systèmes exigent tout d'abord une expertise approfondie dans le domaine. Elles prennent beaucoup de temps car l'élaboration de règles pour un système complexe peut être difficile et nécessite souvent des études et des tests approfondis.
Étant donné que l'ajout de nouvelles règles peut modifier les résultats des règles préexistantes, les systèmes fondés sur des règles sont également difficiles à maintenir et ne s'adaptent pas efficacement.
La classification de textes basée sur l'apprentissage automatique est un problème d'apprentissage automatique supervisé. Il apprend la correspondance entre les données d'entrée (texte brut) et les étiquettes (également connues sous le nom de variables cibles). Ceci est similaire aux problèmes de classification non textuelle où nous entraînons un algorithme de classification supervisée sur un ensemble de données tabulaires pour prédire une classe, à l'exception du fait que dans la classification textuelle, les données d'entrée sont des textes bruts au lieu de caractéristiques numériques.
Comme tout autre apprentissage automatique supervisé, l'apprentissage automatique de la classification des textes comporte deux phases : l'apprentissage et la prédiction.
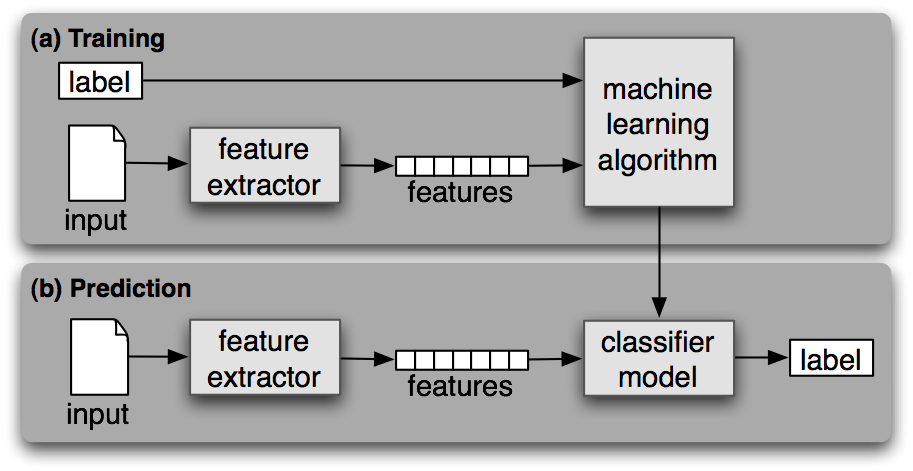
Un algorithme d'apprentissage automatique supervisé est formé sur l'ensemble de données étiquetées pendant la phase de formation. À la fin de ce processus, nous obtenons un modèle entraîné que nous pouvons utiliser pour obtenir des prédictions (étiquettes) sur des données nouvelles et inédites.
Une fois qu'un modèle d'apprentissage automatique est formé, il peut être utilisé pour prédire des étiquettes sur des données nouvelles et inédites. Cela se fait généralement en déployant le meilleur modèle d'une phase antérieure en tant qu'API sur le serveur.
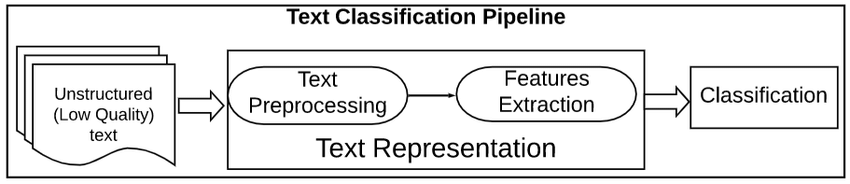
Le prétraitement des données textuelles est une étape importante dans toute tâche de traitement du langage naturel. Il permet de nettoyer et de préparer les données textuelles en vue d'un traitement ou d'une analyse ultérieurs.
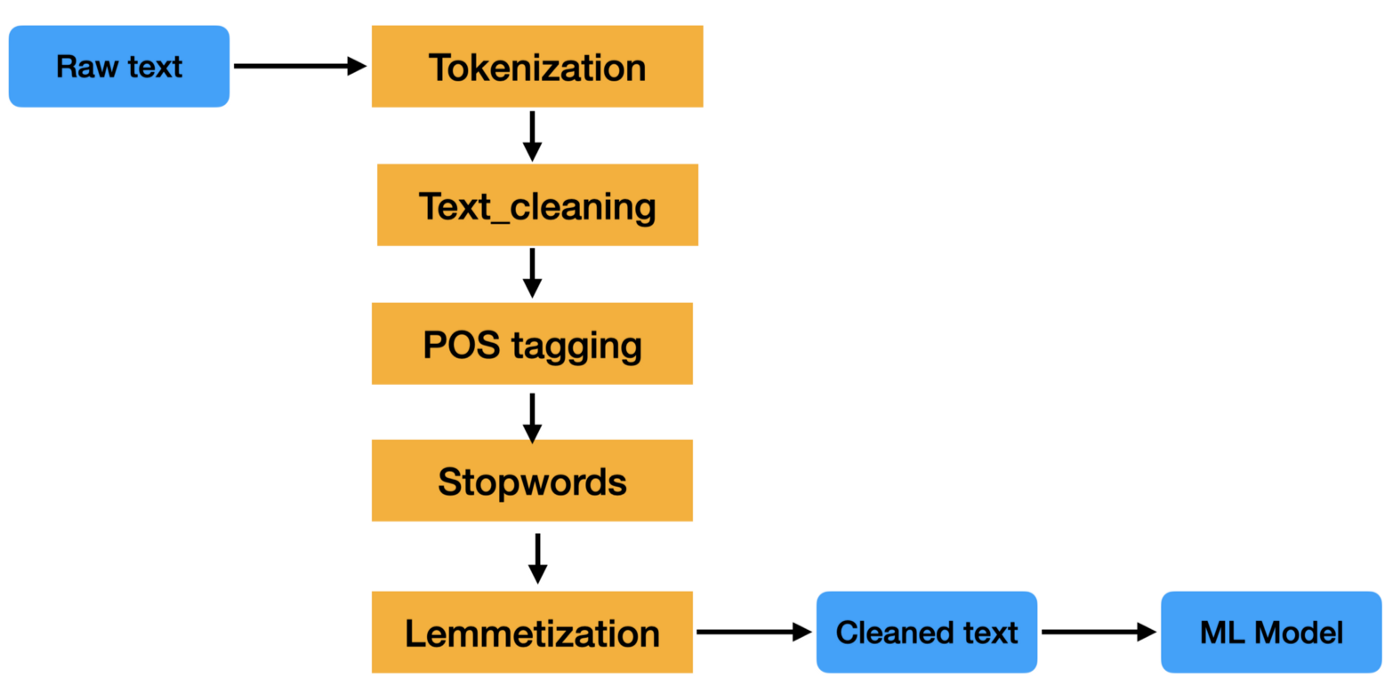
Un pipeline de prétraitement de texte est une série d'étapes de traitement appliquées aux données textuelles brutes afin de les préparer à être utilisées dans des tâches de traitement du langage naturel.
Les étapes d'un pipeline de prétraitement de texte peuvent varier, mais elles comprennent généralement des tâches telles que la tokenisation, la suppression des mots vides, le stemming et la lemmatisation. Ces étapes permettent de réduire la taille des données textuelles et d'améliorer la précision des tâches NLP telles que la classification des textes et l'extraction d'informations.
Les données textuelles sont difficiles à traiter car elles ne sont pas structurées et contiennent souvent beaucoup de bruit. Ce bruit peut prendre la forme de fautes d'orthographe, d'erreurs grammaticales et de formatage non standard. Un pipeline de prétraitement de texte vise à nettoyer ce bruit afin que les données textuelles puissent être analysées plus facilement.
Vous voulez en savoir plus ? Consultez notre parcours Text Mining avec R.
Les deux méthodes les plus courantes pour extraire des caractéristiques d'un texte ou, en d'autres termes, pour convertir des données textuelles (chaînes) en caractéristiques numériques permettant d'entraîner un modèle d'apprentissage automatique sont les suivantes : Bag of Words (alias CountVectorizer) et Tf-IDF.
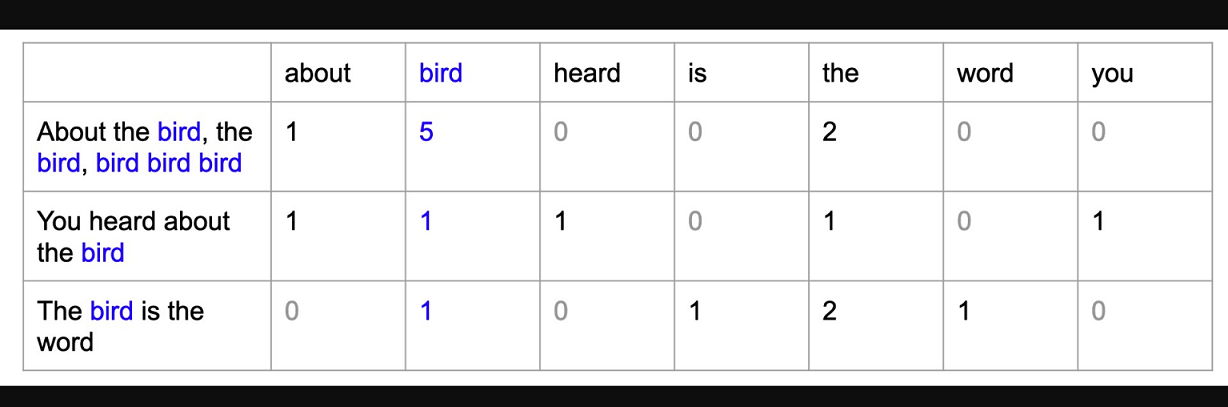
Un modèle de sac de mots (BoW) est un moyen simple de représenter des données textuelles sous forme de caractéristiques numériques. Il s'agit de créer un vocabulaire de mots connus dans le corpus, puis de créer un vecteur pour chaque document qui contient le nombre de fois où chaque mot apparaît.
TF-IDF est l'abréviation de term frequency-inverse document frequency (fréquence des termes - fréquence inverse des documents) et constitue une autre façon de représenter le texte sous forme de caractéristiques numériques. Le modèle du sac de mots (BoW) présente certaines lacunes que le modèle Tf-IDF permet de surmonter. Nous n'entrerons pas dans les détails à ce sujet dans cet article, mais si vous souhaitez approfondir ce concept, consultez notre cours Introduction au traitement du langage naturel en Python.
Le modèle TF-IDF diffère du modèle de sac de mots en ce qu'il prend en compte la fréquence des mots dans le document, ainsi que la fréquence inverse du document. Cela signifie que le modèle TF-IDF est plus à même d'identifier les mots importants d'un document que le modèle du sac de mots.
Commencez par importer le jeu de données directement depuis ce lien GitHub. La collection SMS Spam est un ensemble de données contenant 5 574 messages SMS en anglais accompagnés de l'étiquette Spam ou Ham (pas de spam). Notre objectif est de former un modèle d'apprentissage automatique qui, à partir du texte du SMS et de l'étiquette, sera capable de prédire la classe des messages SMS.
# reading data
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv', encoding='latin-1')
data.head()
Après avoir lu l'ensemble de données, vous remarquerez qu'il y a quelques colonnes supplémentaires dont nous n'avons pas besoin. Nous n'avons besoin que des deux premières colonnes. Supprimons les colonnes restantes et renommons les deux premières colonnes.
# drop unnecessary columns and rename cols
data.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)
data.columns = ['label', 'text']
data.head()
Faisons un peu d'AED de base pour voir s'il y a des valeurs manquantes dans l'ensemble de données et quel est l'équilibre cible.
# check missing values
data.isna().sum()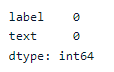
# check data shape
data.shape>>> (5572, 2)# check target balance
data['label'].value_counts(normalize = True).plot.bar()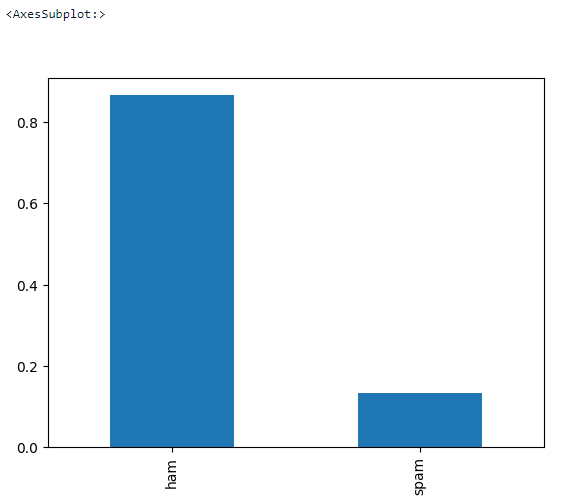
C'est ici que s'effectue le nettoyage du texte. Il s'agit d'une boucle qui parcourt les 5 572 documents et effectue les opérations suivantes :
# text preprocessing
# download nltk
import nltk
nltk.download('all')
# create a list text
text = list(data['text'])
# preprocessing loop
import re
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
corpus = []
for i in range(len(text)):
r = re.sub('[^a-zA-Z]', ' ', text[i])
r = r.lower()
r = r.split()
r = [word for word in r if word not in stopwords.words('english')]
r = [lemmatizer.lemmatize(word) for word in r]
r = ' '.join(r)
corpus.append(r)
#assign corpus to data['text']
data['text'] = corpus
data.head()
Divisons l'ensemble de données en deux parties, formation et test, avant de procéder à l'extraction des caractéristiques.
# Create Feature and Label sets
X = data['text']
y = data['label']
# train test split (66% train - 33% test)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=123)
print('Training Data :', X_train.shape)
print('Testing Data : ', X_test.shape)>>> Training Data : (3733,)
>>> Testing Data : (1839,)Ici, nous utilisons le modèle de sac de mots (CountVectorizer) pour convertir le texte nettoyé en caractéristiques numériques. Cette information est nécessaire pour former le modèle d'apprentissage automatique.
# Train Bag of Words model
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X_train_cv = cv.fit_transform(X_train)
X_train_cv.shape>>> (3733, 7020)Dans cette partie, nous formons un modèle de régression logistique et évaluons la matrice de confusion du modèle formé.
# Training Logistic Regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train_cv, y_train)
# transform X_test using CV
X_test_cv = cv.transform(X_test)
# generate predictions
predictions = lr.predict(X_test_cv)
predictions>>> array(['ham', 'spam', 'ham', ..., 'ham', 'ham', 'spam'], dtype=object)# confusion matrix
import pandas as pd
from sklearn import metrics
df = pd.DataFrame(metrics.confusion_matrix(y_test,predictions), index=['ham','spam'], columns=['ham','spam'])
df
Consultez le cahier d'exercices DataLab complet pour plus de détails.
Le NLP est toujours un domaine actif de recherche et de développement, avec de nombreuses universités et entreprises travaillant au développement de nouveaux algorithmes et de nouvelles applications. La PNL est un domaine interdisciplinaire, dont les chercheurs proviennent de divers horizons, notamment l'informatique, la linguistique, la psychologie et les sciences cognitives.
La classification de textes est une tâche puissante et largement utilisée dans le domaine du NLP qui peut être utilisée pour catégoriser ou prédire automatiquement une classe de documents textuels non vus, souvent avec l'aide de l'apprentissage automatique supervisé.
Il n'est pas toujours précis, mais lorsqu'il est utilisé correctement, il peut apporter une grande valeur ajoutée à vos analyses. Il existe de nombreuses façons et de nombreux algorithmes pour mettre en place un classificateur de texte, et aucune approche unique n'est la meilleure. Il est important d'expérimenter et de trouver ce qui fonctionne le mieux pour vos données et vos objectifs.
Cours supérieurs
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min