Introdução
Pipelines, implantação e MLOps são alguns conceitos muito importantes para os cientistas de dados atualmente. Criar um modelo no Notebook não é suficiente. A implantação de pipelines e o gerenciamento de processos de ponta a ponta com as práticas recomendadas de MLOps é um foco crescente para muitas empresas. Este tutorial aborda vários conceitos importantes, como pipeline, CI/DI, API, contêiner, Docker e Kubernetes. Você também aprenderá sobre estruturas e bibliotecas de MLOps em Python. Por fim, o tutorial mostra a implementação de ponta a ponta da conteinerização de um aplicativo da Web de ML baseado em Flask e sua implantação na nuvem do Microsoft Azure.
Conceitos-chave
MLOps
MLOps significa Machine Learning Operations (operações de aprendizado de máquina). O foco do MLOps é simplificar o processo de implantação de modelos de aprendizado de máquina na produção e, em seguida, mantê-los e monitorá-los. O MLOps é uma função colaborativa, geralmente composta por cientistas de dados, engenheiros de ML e engenheiros de DevOps. A palavra MLOps é um composto de dois campos diferentes, ou seja, aprendizado de máquina e DevOps da engenharia de software.
Os MLOps podem abranger tudo, desde o pipeline de dados até a produção do modelo de aprendizado de máquina. Em alguns lugares, você verá que a implementação de MLOps é apenas para a implantação do modelo de aprendizado de máquina, mas também encontrará empresas com implementação de MLOps em muitas áreas diferentes do desenvolvimento do ciclo de vida de ML, incluindo análise exploratória de dados (EDA), pré-processamento de dados, treinamento de modelos etc.
Embora o MLOps tenha começado como um conjunto de práticas recomendadas, ele está evoluindo lentamente para uma abordagem independente do gerenciamento do ciclo de vida do ML. O MLOps se aplica a todo o ciclo de vida, desde a integração com a geração de modelos (ciclo de vida de desenvolvimento de software e integração contínua/entrega contínua), orquestração e implantação até a integridade, o diagnóstico, a governança e as métricas de negócios.
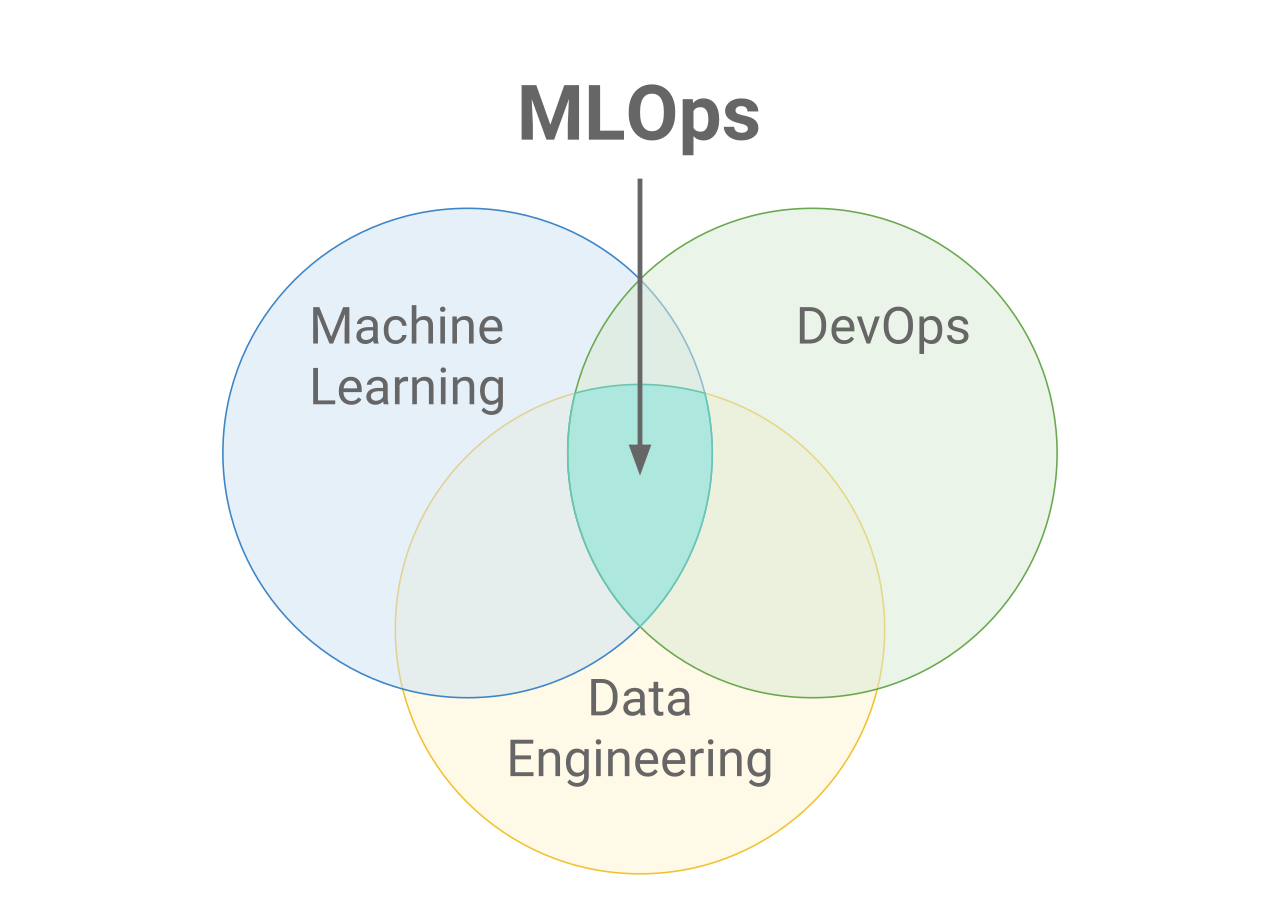
Por que MLOps?
Há muitos objetivos que as empresas querem alcançar com os MLOps. Alguns dos mais comuns são:
- Automação
- Escalabilidade
- Reprodutibilidade
- Monitoramento
- Governança
MLOps vs. DevOps
DevOps é uma abordagem iterativa para enviar aplicativos de software para produção. O MLOps utiliza os mesmos princípios para levar os modelos de aprendizado de máquina à produção. Seja Devops ou MLOps, o objetivo final é aumentar a qualidade e o controle dos aplicativos de software/modelos de ML.
CI/CD: integração contínua, entrega contínua e implantação contínua.
A CI/CD é uma prática derivada do DevOps e refere-se a um processo contínuo de reconhecimento de problemas, reavaliação e atualização automática dos modelos de aprendizado de máquina. Os principais conceitos atribuídos à CI/CD são integração contínua, entrega contínua e implantação contínua. Ele automatiza o pipeline de aprendizado de máquina (criação, teste e implantação) e reduz bastante a necessidade de os cientistas de dados intervirem manualmente no processo, tornando-o eficiente, rápido e menos propenso a erros humanos.
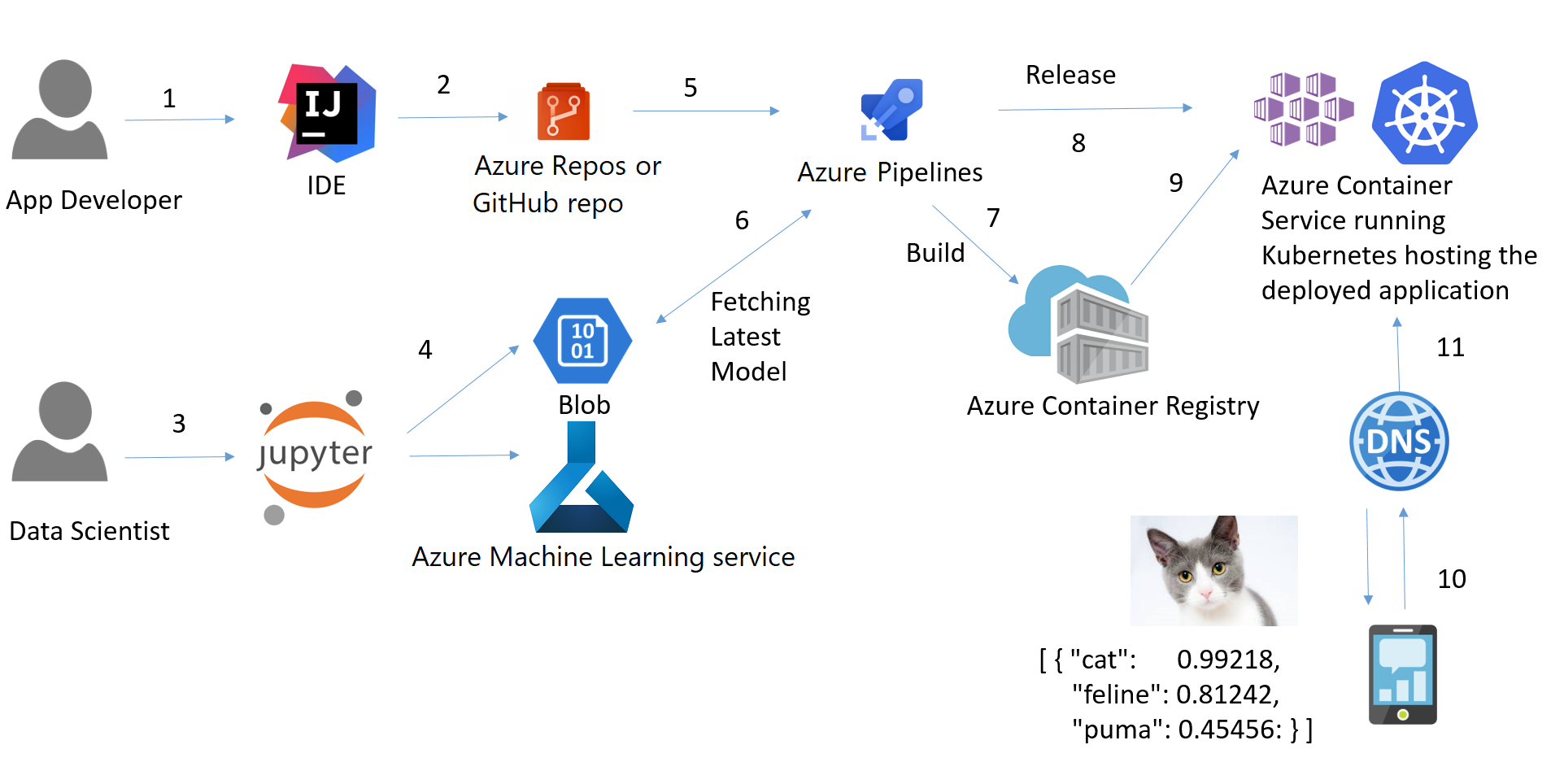
Tubulação
Um pipeline de aprendizado de máquina é uma maneira de controlar e automatizar o fluxo de trabalho necessário para produzir um modelo de aprendizado de máquina. Os pipelines de aprendizado de máquina consistem em várias etapas sequenciais que fazem tudo, desde a extração e o pré-processamento de dados até o treinamento e a implantação do modelo.
Os pipelines de aprendizado de máquina são iterativos, pois cada etapa é repetida para melhorar continuamente a precisão do modelo e atingir o objetivo final.
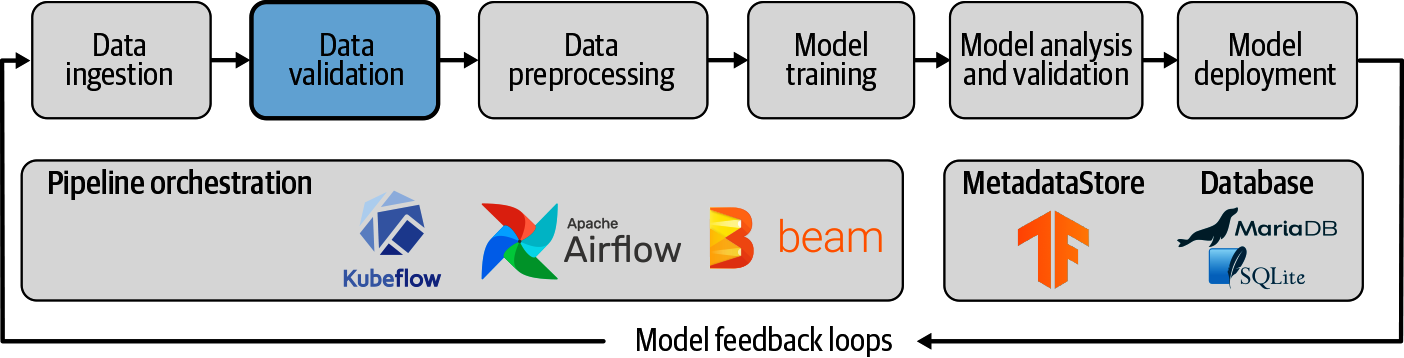
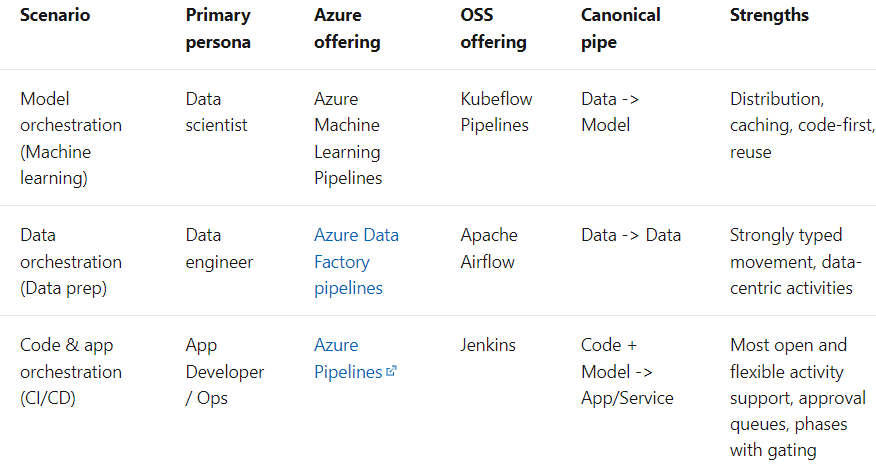
O termo Pipeline é usado geralmente para descrever a sequência independente de etapas que são organizadas em conjunto para realizar uma tarefa. Essa tarefa pode ser de aprendizado de máquina ou não. Os pipelines de aprendizado de máquina são muito comuns, mas esse não é o único tipo de pipeline que existe. Os pipelines de orquestração de dados são outro exemplo. De acordo com os documentos da Microsoft, há três cenários:
Implantação
A implantação de modelos de aprendizado de máquina (ou pipelines) é o processo de disponibilização de modelos na produção, onde aplicativos da Web, software empresarial (ERPs) e APIs podem consumir o modelo treinado fornecendo novos pontos de dados e obter as previsões.
Em resumo, a implantação do aprendizado de máquina é o método pelo qual você integra um modelo de aprendizado de máquina em um ambiente de produção existente para tomar decisões práticas de negócios com base em dados. É o último estágio do ciclo de vida do aprendizado de máquina.
Normalmente, o termo Implementação de modelo de aprendizado de máquina é usado para descrever a implementação de todo o pipeline de aprendizado de máquina, no qual o próprio modelo é apenas um componente do pipeline.
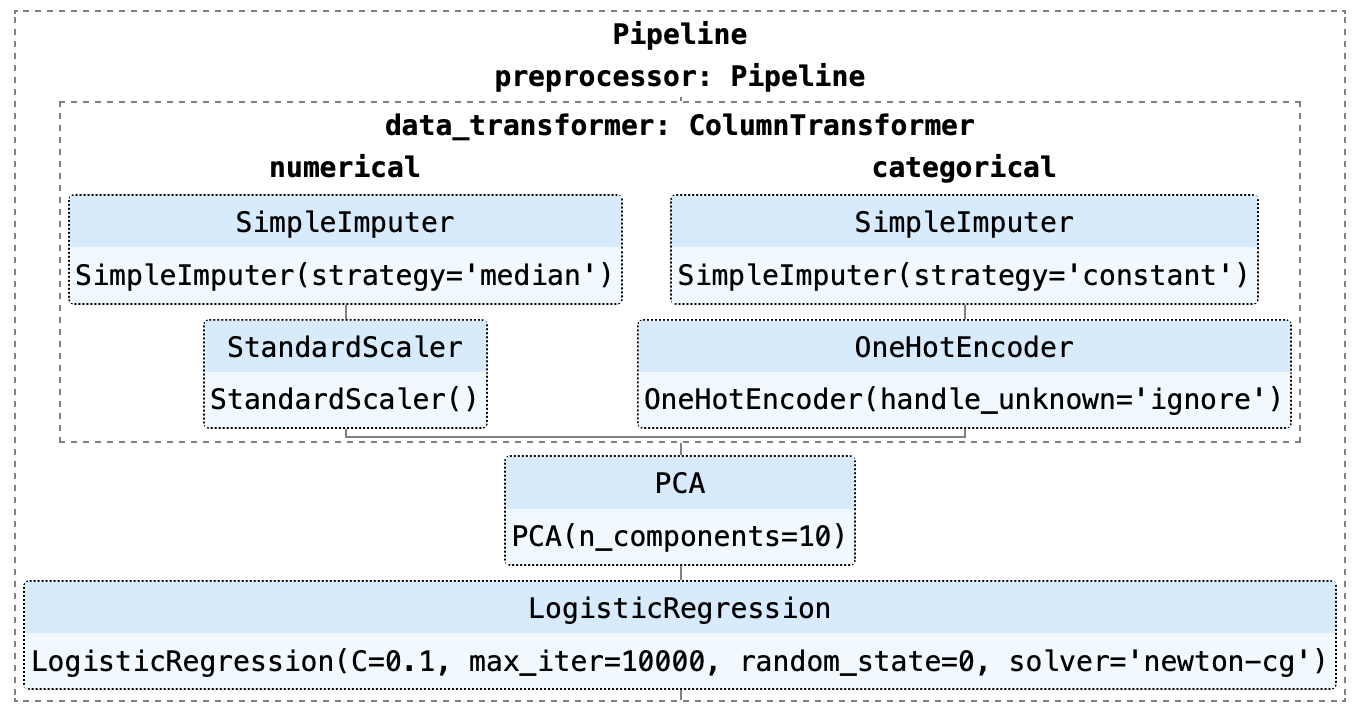
Como você pode ver no exemplo acima, esse pipeline consiste em um modelo de regressão logística. Há várias etapas no pipeline que precisam ser executadas antes do início do treinamento, como a imputação de valores ausentes, a codificação One-Hot, o dimensionamento e a análise de componentes principais (PCA).
Interface de programação de aplicativos (API)
Interface de programação de aplicativos (API) é um intermediário de software que permite que dois aplicativos conversem entre si. Em palavras simples, uma API é um contrato entre dois aplicativos que diz que, se o software do usuário fornecer uma entrada em um formato predefinido, a API fornecerá o resultado ao usuário. Em outras palavras, a API é um ponto de extremidade onde você hospeda os modelos treinados de aprendizado de máquina (pipelines) para uso. Na prática, é mais ou menos assim:
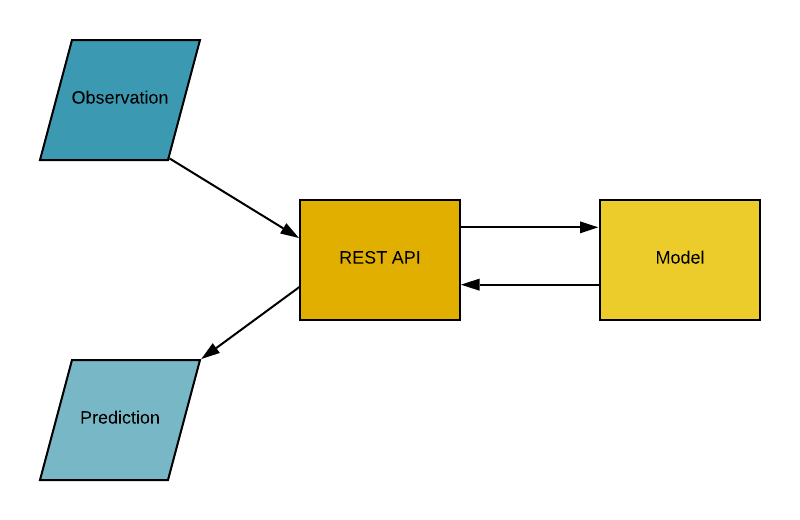
Contêineres
Você já teve o problema de seu código python (ou qualquer outro código) funcionar bem em seu computador, mas quando seu amigo tenta executar exatamente o mesmo código, ele não funciona? Se o seu amigo estiver repetindo exatamente as mesmas etapas, ele deverá obter os mesmos resultados, certo? A resposta simples para isso é que o ambiente Python de seu amigo é diferente do seu.
O que um ambiente inclui?
Python (ou qualquer outra linguagem que você tenha usado) e todas as bibliotecas e dependências usadas para criar esse aplicativo.
Se, de alguma forma, pudermos criar um ambiente que possa ser transferido para outras máquinas (por exemplo, o computador do seu amigo ou um provedor de serviços em nuvem, como Microsoft Azure, AWS ou GCP), poderemos reproduzir os resultados em qualquer lugar. Um contêiner é um tipo de software que empacota um aplicativo e todas as suas dependências para que o aplicativo possa ser executado de forma confiável de um ambiente de computação para outro.
A maneira mais intuitiva de entender os contêineres na ciência de dados é pensar nos contêineres de uma embarcação ou de um navio. O objetivo é isolar o conteúdo de um contêiner dos outros para que eles não se misturem. É exatamente para isso que os contêineres são usados na ciência de dados.
Agora que entendemos a metáfora por trás dos contêineres, vamos analisar as opções alternativas para criar um ambiente isolado para o nosso aplicativo. Uma alternativa simples é ter uma máquina separada para cada um de seus aplicativos.
O uso de uma máquina separada é simples, mas não supera os benefícios do uso de contêineres, pois manter várias máquinas para cada aplicativo é caro, um pesadelo para manter e difícil de dimensionar. Em resumo, isso não é prático em muitos cenários da vida real.
Outra alternativa para criar um ambiente isolado é usar máquinas virtuais. Mais uma vez, os contêineres são preferíveis aqui porque exigem menos recursos, são muito portáteis e mais rápidos para serem ativados.
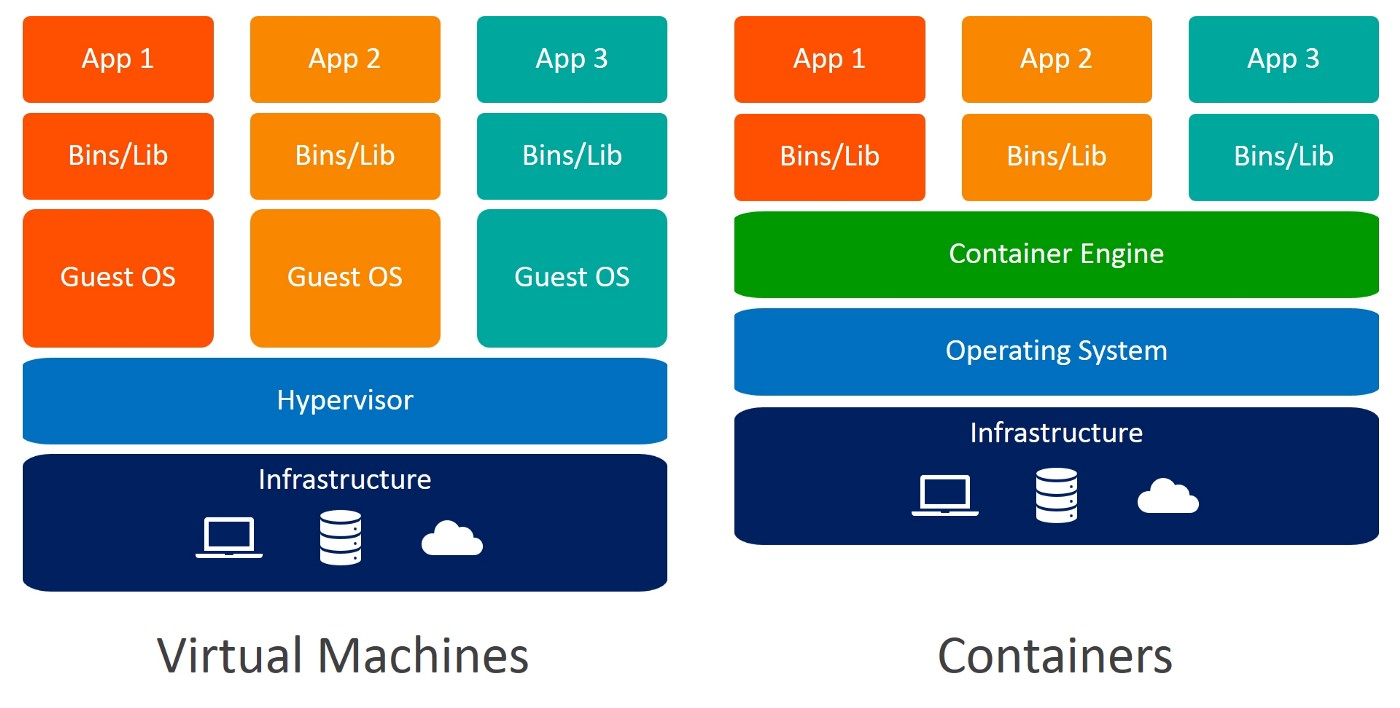
Você consegue identificar as diferenças entre máquinas virtuais e contêineres? Ao usar contêineres, você não precisa de sistemas operacionais convidados. Imagine 10 aplicativos em execução em uma máquina virtual. Isso exigiria 10 sistemas operacionais convidados, em comparação com nenhum exigido quando você usa contêineres.
Docker
A Docker é uma empresa que fornece software (também chamado de Docker) que permite aos usuários criar, executar e gerenciar contêineres. Embora os contêineres do Docker sejam os mais comuns, outras alternativas menos famosas, como o LXD e o LXC, também oferecem soluções de contêineres.
O Docker é uma ferramenta projetada para facilitar a criação, a implantação e a execução de aplicativos usando contêineres. Os contêineres são usados para empacotar um aplicativo com todos os seus componentes necessários, como bibliotecas e outras dependências, e enviá-los como um único pacote.
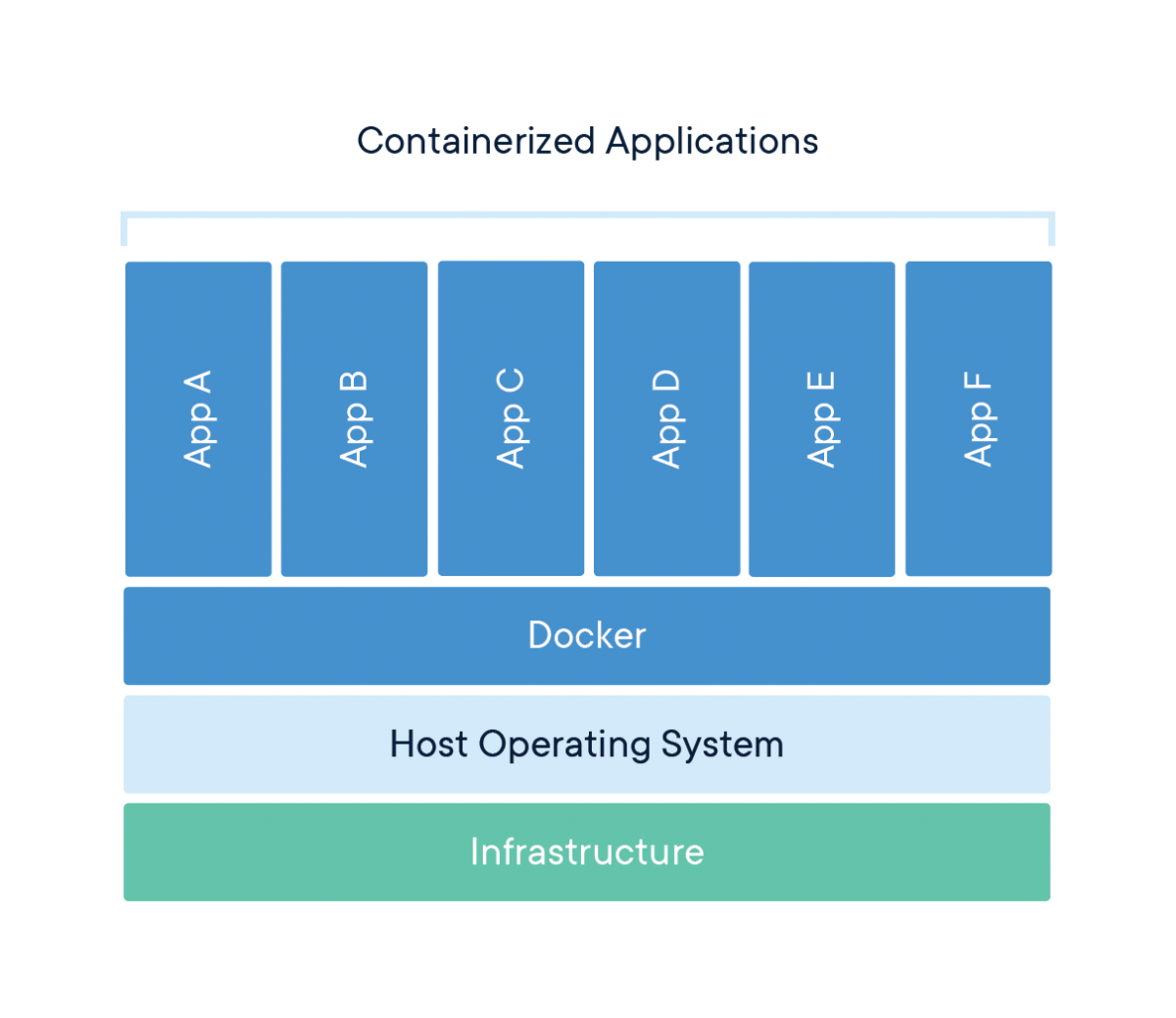
Quebrando o hype
No final das contas, o Docker é apenas um arquivo com algumas linhas de instruções que são salvas na pasta do seu projeto com o nome "Dockerfile".
Outra maneira de pensar nos arquivos do Docker é que eles são como receitas que você inventou em sua própria cozinha. Quando você compartilha essas receitas com outra pessoa e ela segue exatamente as mesmas instruções, ela é capaz de produzir o mesmo prato. Da mesma forma, você pode compartilhar seus arquivos Docker com outras pessoas, que podem criar imagens e executar contêineres com base nesse arquivo Docker específico.
Kubernetes
Desenvolvido pelo Google em 2014, o Kubernetes é um sistema avançado e de código aberto para gerenciar aplicativos em contêineres. Em palavras simples, o Kubernetes é um sistema para executar e coordenar aplicativos em contêineres em um cluster de máquinas. É uma plataforma projetada para gerenciar completamente o ciclo de vida dos aplicativos em contêineres.
Recursos
- Balanceamento de carga: Distribui automaticamente a carga entre os contêineres.
- Dimensionamento: Aumente ou diminua a escala automaticamente, adicionando ou removendo contêineres quando a demanda mudar, como nos horários de pico e durante os fins de semana e feriados.
- Armazenamento: Mantém o armazenamento consistente com várias instâncias de um aplicativo.
Por que você precisa do Kubernetes se já tem o Docker?
Imagine um cenário em que você precisa executar vários contêineres do Docker, em várias máquinas, para dar suporte a um aplicativo de ML de nível empresarial com cargas de trabalho variadas, dia e noite. Por mais simples que isso possa parecer, é muito trabalhoso fazer isso manualmente.
Você precisa iniciar os contêineres certos no momento certo, descobrir como eles podem conversar entre si, lidar com considerações de armazenamento e lidar com contêineres ou hardware com falha. Esse é o problema que o Kubernetes está resolvendo, permitindo que um grande número de contêineres trabalhe em harmonia e reduzindo a carga operacional.
O Google Kubernetes Engine é uma implementação do Kubernetes de código aberto do Google no Google Cloud Platform. Outras alternativas populares ao GKE são o Amazon ECS e o Microsoft Azure Kubernetes Service.
Uma rápida recapitulação dos termos:
- Um contêiner é um tipo de software que empacota um aplicativo e todas as suas dependências para que o aplicativo seja executado de forma confiável de um ambiente de computação para outro.
- O Docker é um software usado para criar e gerenciar contêineres.
- O Kubernetes é um sistema de código aberto para gerenciar aplicativos em contêineres em um ambiente em cluster.
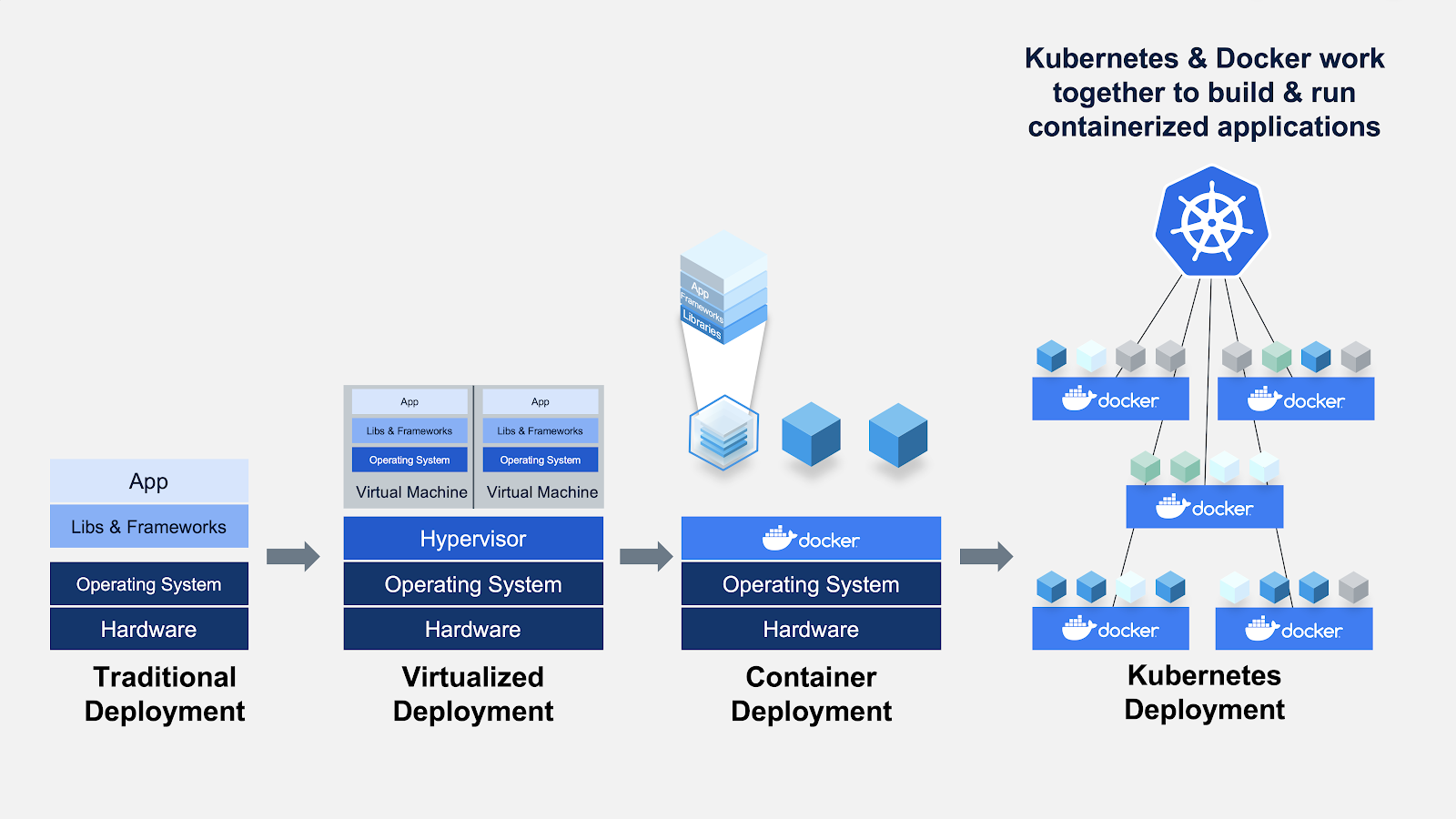
Estruturas e bibliotecas de MLOps em Python
MLflow
O MLflow é uma plataforma de código aberto para gerenciar o ciclo de vida do ML, incluindo experimentação, reprodutibilidade, implantação e um registro de modelo central. Atualmente, o MLflow oferece rastreamento do MLflow, projetos do MLflow, modelos do MLflow e registro de modelos.
Metaflow
O Metaflow é uma biblioteca Python de fácil utilização que ajuda cientistas e engenheiros a criar e gerenciar projetos reais de ciência de dados. O Metaflow foi originalmente desenvolvido na Netflix para aumentar a produtividade dos cientistas de dados que trabalham em uma ampla variedade de projetos, desde a estatística clássica até o aprendizado profundo de última geração. O Metaflow fornece uma API unificada para a pilha de infraestrutura necessária para executar projetos de ciência de dados, do protótipo à produção.
Kubeflow
O Kubeflow é uma plataforma de aprendizado de máquina de código aberto, projetada para permitir que os pipelines de aprendizado de máquina orquestrem fluxos de trabalho complicados em execução no Kubernetes. O Kubeflow foi baseado no método interno do Google para implantar modelos do TensorFlow, chamado TensorFlow Extended.
Kedro
O Kedro é uma estrutura Python de código aberto para a criação de código de ciência de dados reproduzível, sustentável e modular. Ele empresta conceitos das práticas recomendadas de engenharia de software e os aplica ao código de aprendizado de máquina; os conceitos aplicados incluem modularidade, separação de preocupações e controle de versão.
FastAPI
FastAPI é uma estrutura da Web para o desenvolvimento de APIs RESTful em Python. O FastAPI é baseado em Pydantic e em dicas de tipo para validar, serializar e desserializar dados e gerar automaticamente documentos OpenAPI.
ZenML
O ZenML é uma estrutura MLOps extensível e de código aberto para criar pipelines de aprendizado de máquina prontos para produção. Criado para cientistas de dados, ele tem uma sintaxe simples e flexível, é independente de nuvem e de ferramentas e tem interfaces/abstrações que atendem aos fluxos de trabalho de ML.
Exemplo: Desenvolvimento, implantação e MLOps de pipeline de ponta a ponta
Configuração de problemas
Uma seguradora deseja aprimorar sua previsão de fluxo de caixa, prevendo melhor as cobranças dos pacientes, usando métricas demográficas e de risco básico de saúde do paciente no momento da hospitalização.
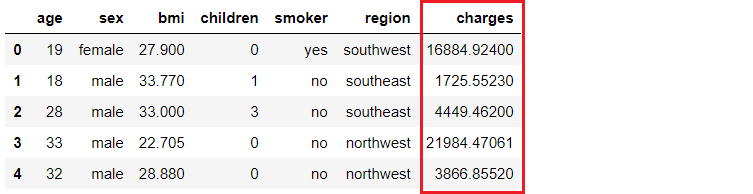
Nosso objetivo é criar e implantar um aplicativo da Web no qual as informações demográficas e de saúde de um paciente são inseridas em um formulário baseado na Web, que gera um valor de cobrança previsto. Para isso, faremos o seguinte:
- Treinar e desenvolver um pipeline de aprendizado de máquina para implantação (modelo de regressão linear simples).
- Crie um aplicativo da Web usando a estrutura do Flask. Ele usará o pipeline de ML treinado para gerar previsões sobre novos pontos de dados em tempo real (o código de front-end não é o foco deste tutorial).
- Crie uma imagem e um contêiner do Docker.
- Publique o contêiner no Registro de Contêineres do Azure (ACR).
- Implemente o aplicativo Web no contêiner publicando-o no ACR. Uma vez implantado, ele se tornará disponível publicamente e poderá ser acessado por meio de um URL da Web.
Pipeline de aprendizado de máquina
Usarei o PyCaret em Python para treinar e desenvolver um pipeline de aprendizado de máquina que será usado como parte de nosso aplicativo da Web. Você pode usar qualquer estrutura que desejar, pois as etapas subsequentes não dependem disso.
# load dataset
from pycaret.datasets import get_data
insurance = get_data('insurance')
# init environment
from pycaret.regression import *
r1 = setup(insurance, target = 'charges', session_id = 123,
normalize = True,
polynomial_features = True, trigonometry_features = True,
feature_interaction=True,
bin_numeric_features= ['age', 'bmi'])
# train a model
lr = create_model('lr')
# save pipeline/model
save_model(lr, model_name = 'c:/username/pycaret-deployment-azure/deployment_28042020')
Quando você salva um modelo no PyCaret, todo o pipeline de transformação é criado, com base na configuração definida na função de configuração. Todas as interdependências são orquestradas automaticamente. Veja o pipeline e o modelo armazenados na variável "deployment_28042020":

Aplicativo Web de front-end
Este tutorial não está focado na criação de um aplicativo Flask. Ela é discutida aqui apenas para fins de completude. Agora que nosso pipeline de aprendizado de máquina está pronto, precisamos de um aplicativo da Web que possa ler nosso pipeline treinado para prever novos pontos de dados. Há duas partes desse aplicativo:
- Front-end (projetado usando HTML)
- Back-end (desenvolvido com o Flask)
Esta é a aparência do front-end:
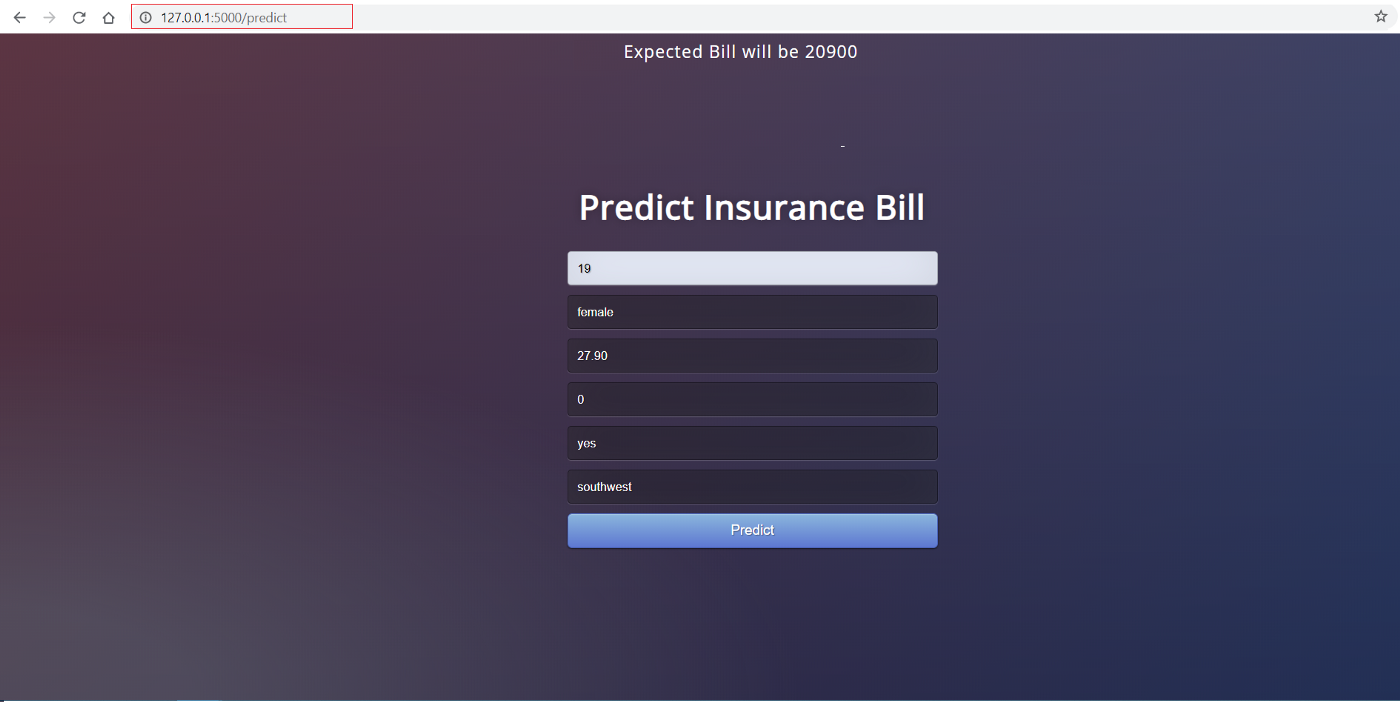
O front-end desse aplicativo é um HTML realmente simples com alguns estilos de CSS. Se você quiser conferir o código, consulte este repositório. Agora que temos um aplicativo da Web totalmente funcional, podemos iniciar o processo de conteinerização do aplicativo usando o Docker.
Back-end do aplicativo
O back-end do aplicativo é um arquivo Python chamado app.py. Ele foi criado usando a estrutura do Flask.
from flask import Flask,request, url_for, redirect, render_template, jsonify
from pycaret.regression import *
import pandas as pd
import pickle
import numpy as np
app = Flask(__name__)
model = load_model('deployment_28042020')
cols = ['age', 'sex', 'bmi', 'children', 'smoker', 'region']
@app.route('/')
def home():
return render_template("home.html")
@app.route('/predict',methods=['POST'])
def predict():
int_features = [x for x in request.form.values()]
final = np.array(int_features)
data_unseen = pd.DataFrame([final], columns = cols)
prediction = predict_model(model, data=data_unseen, round = 0)
prediction = int(prediction.Label[0])
return render_template('home.html',pred='Expected Bill will be {}'.format(prediction))
@app.route('/predict_api',methods=['POST'])
def predict_api():
data = request.get_json(force=True)
data_unseen = pd.DataFrame([data])
prediction = predict_model(model, data=data_unseen)
output = prediction.Label[0]
return jsonify(output)
if __name__ == '__main__':
app.run(debug=True)
Contêiner do Docker
Se estiver usando o Windows, você terá que instalar o Docker para Windows. Se você estiver usando o Ubuntu, o Docker vem por padrão e não é necessário fazer nenhuma instalação.
A primeira etapa para colocar seu aplicativo em contêineres é escrever um Dockerfile na mesma pasta/diretório em que o aplicativo reside. Um Dockerfile é apenas um arquivo com um conjunto de instruções. O Dockerfile para esse projeto tem a seguinte aparência:
FROM python:3.7
RUN pip install virtualenv
ENV VIRTUAL_ENV=/venv
RUN virtualenv venv -p python3
ENV PATH="VIRTUAL_ENV/bin:$PATH"
WORKDIR /app
ADD . /app
# install dependencies
RUN pip install -r requirements.txt
# expose port
EXPOSE 5000
# run application
CMD ["python", "app.py"]
O Dockerfile diferencia maiúsculas de minúsculas e deve estar na pasta do projeto com os outros arquivos do projeto. Um Dockerfile não tem extensão e pode ser criado usando qualquer editor. Usamos o Visual Studio Code para criá-lo. Você pode usar o Visual Studio Code para criar o código.
Implementação na nuvem
Depois de configurar o Dockerfile corretamente, escreveremos alguns comandos para criar uma imagem do Docker a partir desse arquivo, mas, primeiro, precisamos de um serviço para hospedar essa imagem. Neste exemplo, usaremos o Microsoft Azure para hospedar nosso aplicativo.
Registro de contêineres do Azure
Se você não tem uma conta do Microsoft Azure ou nunca a usou antes, pode se inscrever gratuitamente. Quando você se inscreve pela primeira vez, recebe um crédito gratuito durante os primeiros 30 dias. Você pode utilizar esse crédito para criar e implantar um aplicativo Web no Azure. Depois que você se inscrever, siga estas etapas:
- Faça login em https://portal.azure.com
- Clique em Criar um recurso
- Procure o Container Registry e clique em Create
- Selecione Subscription, Resource group e Registry name (no nosso caso: pycaret.azurecr.io é o nome do nosso registro)
Depois que um registro é criado, a primeira etapa é criar uma imagem do Docker usando a linha de comando. Navegue até a pasta do projeto e execute o seguinte código:
docker build -t pycaret.azurecr.io/pycaret-insurance:latest .
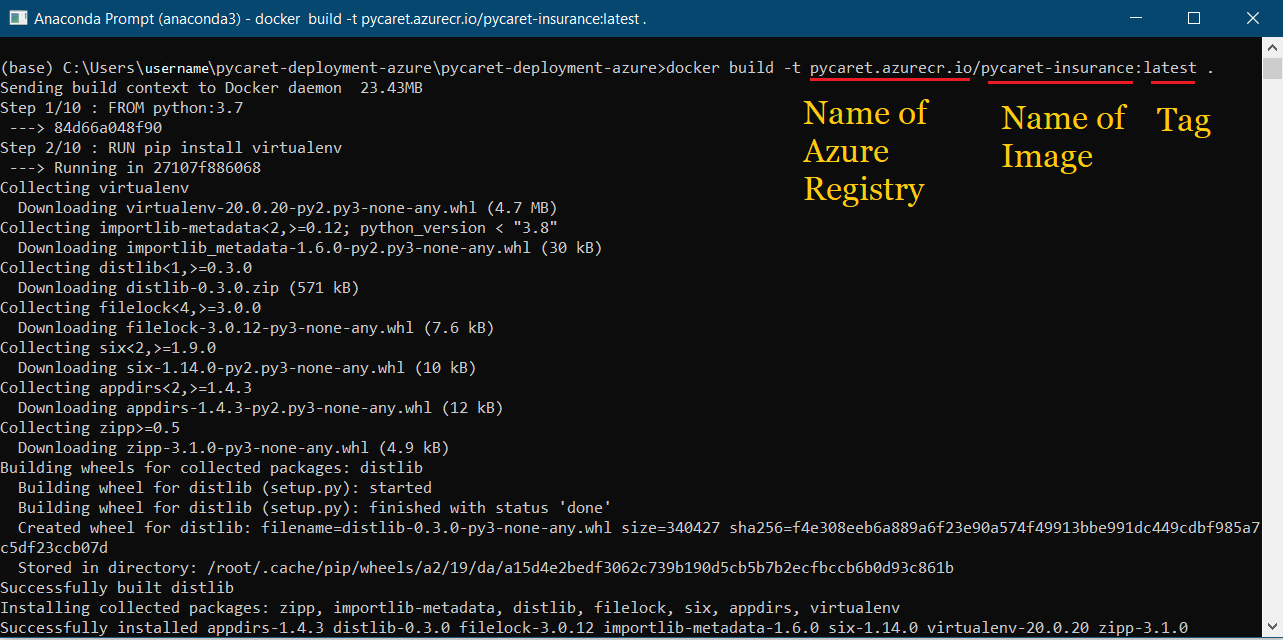
- pycaret.azurecr.io é o nome do registro que você obtém quando cria um recurso no portal do Azure
- pycaret-insurance é o nome da imagem e the latest é a tag; pode ser qualquer coisa que você queira
Execute o contêiner a partir da imagem do Docker
Agora que a imagem foi criada, executaremos um contêiner localmente e testaremos o aplicativo antes de enviá-lo para o Azure Container Registry. Para executar o contêiner localmente, execute o seguinte código:
docker run -d -p 5000:5000 pycaret.azurecr.io/pycaret-insurance
Você pode ver o aplicativo em ação acessando localhost:5000 em seu navegador de Internet. Isso deve abrir um aplicativo da Web.
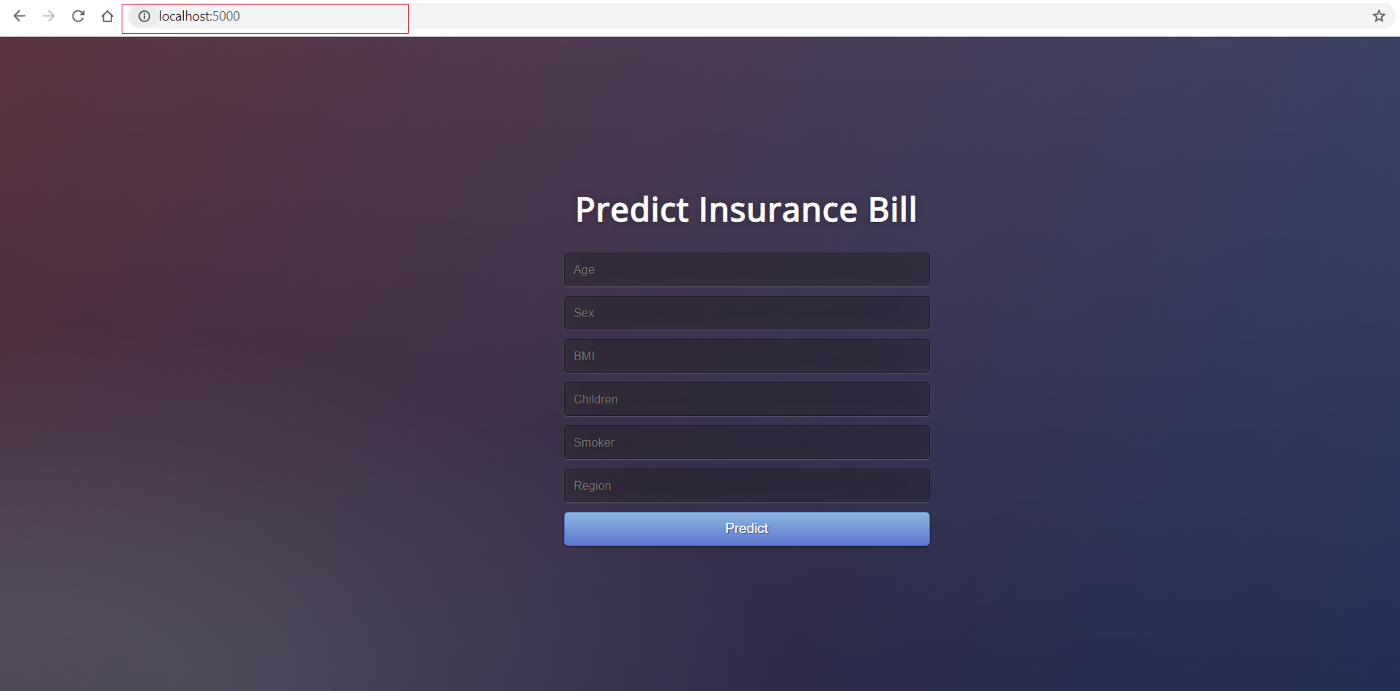
Se você puder ver isso, significa que o aplicativo já está em funcionamento no computador local e agora é só uma questão de transferi-lo para a nuvem. Para a implantação no Azure, leia mais:
Autenticar credenciais do Azure
Uma etapa final antes que você possa carregar o contêiner no ACR é autenticar as credenciais do Azure no seu computador local. Para isso, execute o código a seguir na linha de comando:
docker login pycaret.azurecr.io
Você será solicitado a fornecer um nome de usuário e uma senha. O nome de usuário é o nome do seu registro (neste exemplo, o nome de usuário é "pycaret"). Você pode encontrar sua senha nas chaves de acesso do recurso Azure Container Registry que você criou.
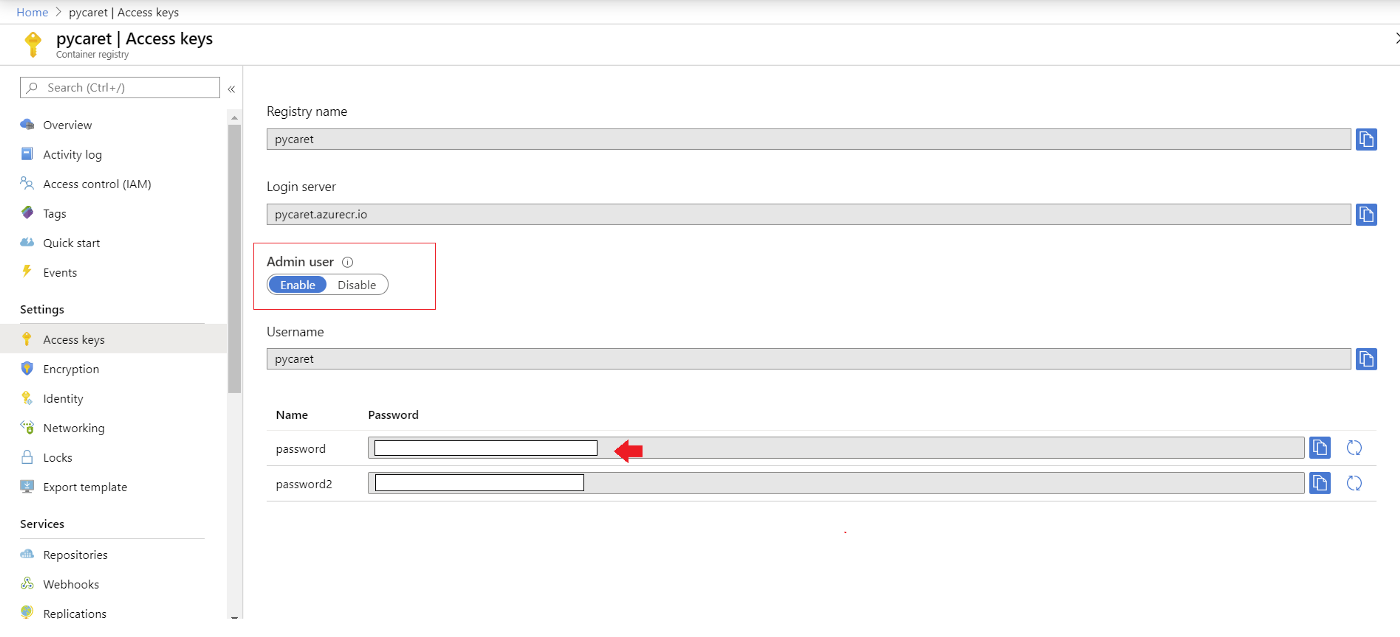
Empurre o contêiner para o Registro de Contêiner do Azure
Agora que você se autenticou no ACR, pode enviar o contêiner que criou para o ACR executando o seguinte código:
docker push pycaret.azurecr.io/pycaret-insurance:latest
Dependendo do tamanho do contêiner, o comando push pode levar algum tempo para transferir o contêiner para a nuvem.
Aplicativo da Web
Para criar um aplicativo Web no Azure, siga estas etapas:
- Faça login no portal do Azure
- Clique em criar um recurso
- Procure o aplicativo da Web e clique em criar
- Vincule sua imagem ACR ao seu aplicativo
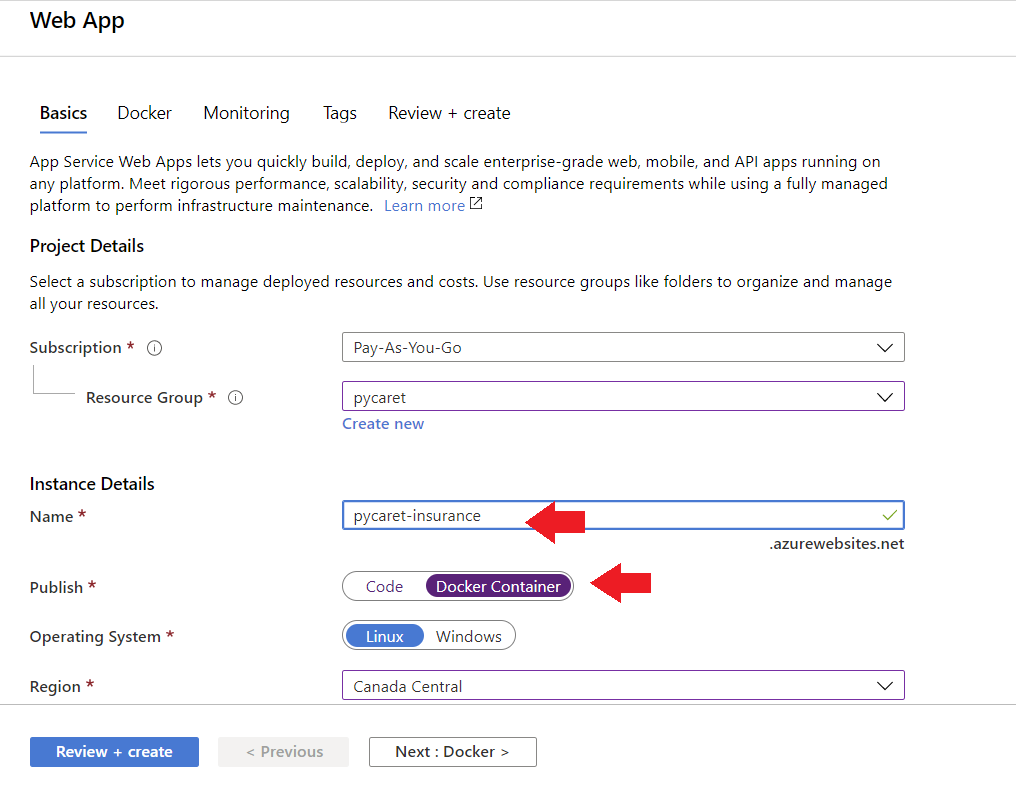
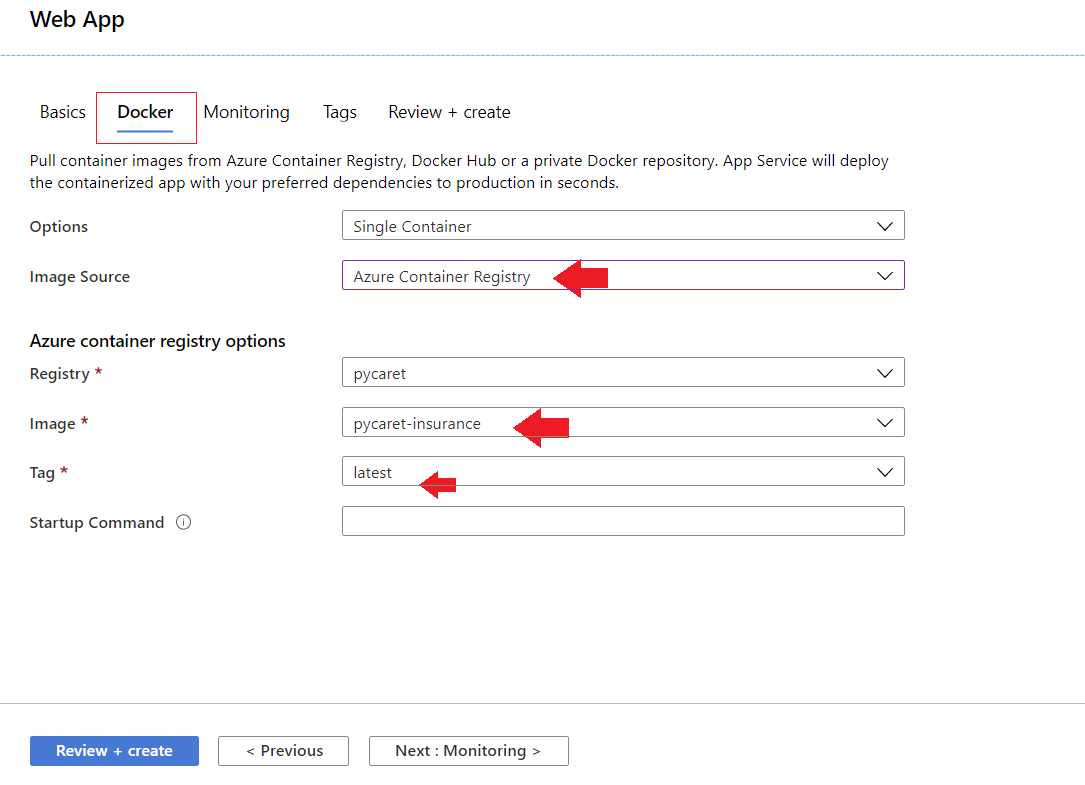
Agora, o aplicativo está em funcionamento no Azure Web Services.

Conclusão
Os MLOps ajudam a garantir que os modelos implantados sejam bem mantidos, tenham o desempenho esperado e não tenham efeitos adversos nos negócios. Essa função é fundamental para proteger a empresa contra riscos decorrentes de modelos que se desviam com o tempo, ou que são implantados, mas não são mantidos ou monitorados.
Os MLOps estão no topo da classificação de empregos emergentes do LinkedIn, com um crescimento registrado de 9,8 vezes em cinco anos.
Você pode conferir o novo MLOps Fundamentals Skill Track no DataCamp, que abrange o ciclo de vida completo de um aplicativo de aprendizado de máquina, desde a coleta de requisitos de negócios até os estágios de design, desenvolvimento, implantação, operação e manutenção. A Datacamp também tem um curso incrível de Compreensão da engenharia de dados. Inscreva-se hoje mesmo para descobrir como os engenheiros de dados estabelecem as bases que tornam a ciência de dados possível, sem necessidade de codificação.
