Lernpfad
Überwachtes Machine Learning in Python
25 Std.
Die für unsere Vorhersage verwendeten Daten stammen von FiveThirtyEightdas Umfragedaten von verschiedenen Meinungsforschern sammelt. Die Daten sind verfügbar über ihre GitHub für alle Wahlzyklen seit 1968 verfügbar.
Wir werden ihr Umfragemodell verwenden, das den durchschnittlichen Prozentsatz der Umfragen für jeden Kandidaten in jedem Bundesstaat für (fast) jedes Datum in den acht Monaten vor der Wahl ermittelt.
Wir beginnen mit dem Import von 2024-, 2020- und historischen Wahldaten aus CSV-Dateien. Die Daten für 2024 werden nur nach Umfragen aus dem aktuellen Zyklus gefiltert, und die historischen Daten bis 2016 werden mit den Daten für 2020 verknüpft. In den beiden daraus resultierenden DataFrames polls_24 und polls_until_20 werden die Datumsspalten in das Format datetime umgewandelt, um die Konsistenz zu gewährleisten, und relevante Spalten wie Zyklus, Bundesland, Kandidatennamen und Wahlprognosen werden beibehalten.
import pandas as pd
# Reading CSV files
polls_24 = pd.read_csv('presidential_general_averages.csv')
polls_20 = pd.read_csv('presidential_poll_averages_2020.csv')
polls_until_16 = pd.read_csv('pres_pollaverages_1968-2016.csv')
# Filtering and concatenating DataFrames
polls_24 = polls_24[polls_24['cycle'] == 2024]
polls_until_20 = pd.concat([polls_20, polls_until_16], ignore_index=True)
# Making sure dates are in datetime format
polls_24['date'] = pd.to_datetime(polls_24['date'], format='%Y-%m-%d')
polls_until_20['modeldate'] = pd.to_datetime(polls_until_20['modeldate'])
# Keeping only the columns of interest
polls_until_20 = polls_until_20[['cycle', 'state', 'modeldate', 'candidate_name', 'pct_estimate', 'pct_trend_adjusted']]Für die tatsächlichen Wahlergebnisse nach Bundesstaaten habe ich die Daten direkt von der Federal Election Commission der USA. Der Einfachheit halber habe ich sie vorher in einer CSV-Datei zusammengefasst.
Eine Beobachtung stellt die Kombination aus Wahlzyklus, Bundesland und Partei dar, jeweils ergänzt um den Namen des jeweiligen Kandidaten und natürlich den prozentualen Stimmenanteil, den dieser Kandidat erreicht hat.
# Importing result data
results_until_20 = pd.read_csv('results.csv', sep=';')
results_until_20 = results_until_20[['cycle', 'state', 'party', 'candidate', 'vote_share']]Um sicherzustellen, dass wir mit relevanten und hochwertigen Daten arbeiten, habe ich zwei wichtige Einschränkungen vorgenommen:
swing_states, blue_states und red_states entsprechend und erstellen Teilmengen der Daten für die Swing States.# Implementing cycle restriction
start_cycle = 2000
polls_until_20 = polls_until_20[polls_until_20['cycle'] >= start_cycle]
# Defining state lists
swing_states = [
'Pennsylvania', 'Wisconsin', 'Michigan', 'Georgia',
'North Carolina', 'Arizona', 'Nevada'
]
blue_states = [
'District of Columbia', 'Vermont', 'Massachusetts', 'Maryland',
'Hawaii', 'California', 'ME-1', 'Connecticut', 'Washington',
'Delaware', 'Rhode Island', 'New York', 'Illinois', 'New Jersey',
'Oregon', 'Colorado', 'Maine', 'New Mexico', 'Virginia',
'New Hampshire', 'NE-2', 'Minnesota'
]
red_states = [
'Wyoming', 'West Virginia', 'Oklahoma', 'North Dakota',
'Idaho', 'South Dakota', 'Arkansas', 'Kentucky', 'NE-3',
'Alabama', 'Tennessee', 'Utah', 'Louisiana', 'Nebraska',
'Mississippi', 'Montana', 'NE-1', 'Indiana', 'Kansas',
'Missouri', 'South Carolina', 'Alaska', 'Ohio', 'Iowa',
'Texas', 'ME-2', 'Florida'
]
# Defining swing state subset of the poll data
swing_until_20 = polls_until_20[polls_until_20['state'].isin(swing_states)]
swing_24 = polls_24[polls_24['state'].isin(swing_states)]Um einen Überblick über unsere Daten zu erhalten, führen wir eine explorative Datenanalyse (EDA). Zunächst verwenden wir eine Kombination aus den Methoden .isnull() und .sum(), um zu sehen, welche Spalten jeder DataFrame enthält und wo Daten fehlen könnten.
# Checking for missing values in swing_24 and swing_until_20
print(swing_24.isnull().sum())
print(swing_until_20.isnull().sum())candidate 0
date 0
pct_trend_adjusted 4394
state 0
cycle 0
party 0
pct_estimate 0
hi 0
lo 0
dtype: int64
cycle 0
state 0
modeldate 0
candidate_name 0
pct_estimate 0
pct_trend_adjusted 0
dtype: int64Wie wir sehen können, unterscheiden sich die Spaltennamen zwischen den beiden DataFrames, und die Spalte party scheint in swing_until_20 zu fehlen. Außerdem scheinen zwei verschiedene Arten von Prozentsätzen gemessen worden zu sein: ein geschätzter Prozentsatz und ein zusätzlich trendbereinigter Prozentsatz. Allerdings scheint der trendbereinigte Prozentsatz für die Daten von 2024 nicht verfügbar zu sein. Wir werden das später untersuchen.
Als Nächstes prüfen wir die unterschiedlichen Werte unserer kategorialen Variablen:
print('2024 data:')
print(swing_24['date'].min()) # earliest polling date
print(swing_24['date'].max()) # latest polling date
print(swing_24['state'].unique().tolist()) # distinct states
print(swing_24['party'].unique().tolist()) # distinct parties
print(swing_24['candidate'].unique().tolist()) # distinct candidates
print('Historical data:')
print(swing_until_20['modeldate'].min())
print(swing_until_20['modeldate'].max())
print(swing_until_20['state'].unique().tolist())
print(swing_until_20['candidate_name'].unique().tolist())2024 data:
2024-03-01 00:00:00
2024-10-29 00:00:00
['Arizona', 'Georgia', 'Michigan', 'Nevada', 'North Carolina', 'Pennsylvania', 'Wisconsin']
['REP', 'DEM', 'IND']
['Trump', 'Harris', 'Kennedy', 'Biden']
Historical data:
2000-03-02 00:00:00
2020-11-03 00:00:00
['Wisconsin', 'Pennsylvania', 'North Carolina', 'Nevada', 'Michigan', 'Georgia', 'Arizona']
['Joseph R. Biden Jr.', 'Donald Trump', 'Convention Bounce for Joseph R. Biden Jr.', 'Convention Bounce for Donald Trump', 'Hillary Rodham Clinton', 'Gary Johnson', 'Barack Obama', 'Mitt Romney', 'John McCain', 'George W. Bush', 'John Kerry', 'Al Gore', 'Ralph Nader']Während die Daten für Staaten und Daten gut aussehen, gibt es bei den kandidatenbezogenen Spalten einige Dinge zu beachten. Die historischen Daten (genauer gesagt die des Zyklus 2020) beinhalten nicht nur die Prozentsätze der beiden Kandidaten, sondern auch Convention Bounces, d.h. Zuwächse in der Unterstützung nach der Durchführung ihres nationalen Kongresses. Außerdem scheinen die Vornamen in swing_24 zu fehlen.
Für unsere Untersuchung der verschiedenen Arten von Prozenten ist es entscheidend, die Konventionssprungbeobachtungen sofort zu entfernen:
# Only keep rows where candidate_name does not start with 'Convention Bounce'
swing_until_20 = swing_until_20[~swing_until_20['candidate_name'].str.startswith('Convention Bounce')]Um Konsistenz zu gewährleisten, muss die Art des Prozentsatzes für alle Trainings- und Testdaten gleich sein. Wie wir herausgefunden haben, enthalten nur die Daten bis zum Wahlzyklus 2020 sowohl geschätzte als auch trendbereinigte Prozentsätze, während es für 2024 nur die geschätzten gibt. Damit bleiben uns zwei Möglichkeiten, die da wären:
Die Art und Weise, wie der trendbereinigte Prozentsatz für die historischen Daten berechnet wurde, ist unklar. Deshalb müssen wir das Verhältnis zwischen den geschätzten und den trendbereinigten Prozentsätzen untersuchen, bevor wir mit der Datenbereinigung fortfahren, denn die Wahl der Datenbasis ist entscheidend für unsere Vorhersagen. Zunächst untersuchen wir die Korrelation und die durchschnittliche Differenz in den historischen Daten.
# Checking the correlation between the percentages
adj_corr_swing = swing_until_20['pct_estimate'].corr(swing_until_20['pct_trend_adjusted'])
print('Correlation between estimated and trend-adjusted percentage in swing states: ' + str(adj_corr_swing))
# Calculate the mean difference between pct_estimate and pct_trend_adjusted, grouping by date, state, and party
mean_diff = (swing_until_20['pct_estimate'] - swing_until_20['pct_trend_adjusted']).mean()
print('Mean difference between estimated and trend-adjusted percentage in swing states: ' + str(mean_diff))Correlation between estimated and trend-adjusted percentage in swing states: 0.9953626583357665
Mean difference between estimated and trend-adjusted percentage in swing states: 0.24980898513865013Wir können sehen, dass die Korrelation zwischen beiden extrem hoch ist (99,5%), wie zu erwarten war. Der durchschnittliche Unterschied von etwa 0,25 Prozentpunkten sieht auf den ersten Blick gering aus, kann aber bei sehr engen Rennen wie in Nevada oder Michigan einen Unterschied machen.
Da alle Wahlmännerstimmen in jedem Staat an den Gewinner gehen, ist die Reihenfolge der Kandidaten wichtiger als jeder genaue Prozentsatz. Was wir vermeiden wollen, ist eine Diskrepanz kurz vor dem Wahltermin. Daher können wir uns die Anzahl der Beobachtungen ansehen, in denen sich der Spitzenkandidat zwischen den beiden Prozentsätzen im letzten Wahlzyklus 2020 und dem letzten Datum eines solchen Ereignisses unterschied.
# Finding out how often pct_estimate and pct_trend_adjusted saw different candidates in the lead in the 2020 race
swing_20 = swing_until_20[swing_until_20['cycle'] == 2020]
# Create a new column to indicate if the ranking is different between pct_estimate and pct_trend_adjusted
swing_20['rank_estimate'] = swing_20.groupby(['state', 'modeldate'])['pct_estimate'].rank(ascending=False)
swing_20['rank_trend_adjusted'] = swing_20.groupby(['state', 'modeldate'])['pct_trend_adjusted'].rank(ascending=False)
# Rows where the rankings are different in swing states
different_rankings_swing = swing_20[swing_20['rank_estimate'] != swing_20['rank_trend_adjusted']]
print('Number of observations with differing leader: ' + str(different_rankings_swing.shape[0] / 2))
print('Last occurrence: ' + str(different_rankings_swing['modeldate'].max()))Number of observations with differing leader: 34.0
Last occurrence: 2020-06-24 00:00:00Offenbar unterschied sich der Vorsprung nur in 34 Fällen, also im Durchschnitt etwa 5 Tage pro Swing State. Da das letzte Vorkommnis Ende Juni ist, scheinen alle Fälle in der frühen Phase des Wahlkampfs zu liegen.
In Anbetracht dessen ist es unwahrscheinlich, dass die seltenen Fälle von Führungswechseln die Gesamtgenauigkeit des Modells beeinträchtigen, vor allem, weil wir einen großen Datensatz über mehrere Zyklen hinweg haben. Deshalb habe ich mich für die erste Option entschieden und nur den geschätzten Prozentsatz über alle Wahlzyklen hinweg verwendet. Dies gewährleistet Datenkonsistenzwas beim maschinellen Lernen wichtig ist, um zu verhindern, dass das Modell durch unterschiedliche Datenverarbeitungsmethoden Verzerrungen erlernt.
Um eine Spalte für die politische Partei hinzuzufügen, erhalten wir zunächst eine Liste mit allen Kandidaten im historischen Datensatz. Dann erstellen wir ein Wörterbuch mit den Kandidaten als Schlüssel und der jeweiligen Partei als entsprechendem Wert -ChatGPT ist dafür hervorragend geeignet, um Zeit bei der Recherche zu sparen! Schließlich kombinieren wir beides in einem DataFrame und fügen es auf swing_until_20 zusammen.
# Get unique candidate names
candidate_names = swing_until_20['candidate_name'].unique().tolist()
# Create a dictionary of candidates and their political party
party_map = {
'Joseph R. Biden Jr.': 'DEM',
'Donald Trump': 'REP',
'Hillary Rodham Clinton': 'DEM',
'Gary Johnson': 'LIB',
'Barack Obama': 'DEM',
'Mitt Romney': 'REP',
'John McCain': 'REP',
'Ralph Nader': 'IND',
'George W. Bush': 'REP',
'John Kerry': 'DEM',
'Al Gore': 'DEM'
}
# Create a DataFrame with candidates and their respective parties
candidate_df = pd.DataFrame(candidate_names, columns=['candidate_name'])
candidate_df['party'] = candidate_df['candidate_name'].map(party_map)
# Merge the candidate_df with swing_until_20 on 'candidate' column
swing_until_20 = swing_until_20.merge(candidate_df[['candidate_name', 'party']], on='candidate_name', how='left')Nachdem wir nun die Parteispalte zu unserem swing_until_20 DataFrame hinzugefügt haben, können wir die historischen Wahlergebnisse in einer neuen Spalte namens vote_share zusammenführen. Da die CSV-Datei von vote_share in einem anderen Format war, müssen wir sie an das gleiche Format anpassen, das in der Spalte pct_estimate verwendet wird.
# Merging results_until_20 to swing_until_20
swing_until_20 = pd.merge(swing_until_20, results_until_20, how='left', left_on=['cycle', 'state', 'party', 'candidate_name'], right_on=['cycle', 'state', 'party', 'candidate'])
swing_until_20['vote_share'] = swing_until_20['vote_share'].str.replace(',', '.')
swing_until_20['vote_share'] = pd.to_numeric(swing_until_20['vote_share'])Schließlich benennen wir die Spalte modeldate in date um, entfernen alle unnötigen Spalten und passen das Format candidate in den 2024-Daten so an, dass es auch Vornamen enthält.
# Renaming columns in swing_until_20
swing_until_20.rename(columns={'modeldate': 'date'}, inplace=True)
# Keeping only relevant columns
swing_24 = swing_24[['cycle', 'date', 'state', 'party', 'candidate', 'pct_estimate']]
swing_until_20 = swing_until_20[['cycle', 'date', 'state', 'party', 'candidate', 'pct_estimate', 'vote_share']]
# Update candidate names in swing_24 dataframe
swing_24['candidate'] = swing_24['candidate'].replace({
'Trump': 'Donald Trump',
'Biden': 'Joseph R. Biden Jr.',
'Harris': 'Kamala Harris',
'Kennedy': 'Robert F. Kennedy'})Verschaffen wir uns einen Überblick über den bisherigen Verlauf des Wahlkampfes 2024. Wir verwenden seaborn und matplotlib, um ein Liniendiagramm zu erstellen, das den durchschnittlichen Verlauf der Wahlbeteiligung in allen ausgewählten Swing States zeigt. Die roten, blauen und schwarzen Linien zeigen die Wahlbeteiligung der Republikaner, Demokraten und unabhängigen Kandidaten. Vertikale Linien markieren wichtige Ereignisse während der Kampagne.
import matplotlib.pyplot as plt
import seaborn as sns
# Ensure the date column is in datetime format
swing_24['date'] = pd.to_datetime(swing_24['date'])
# Group by date and party, then average the pct_estimate
swing_24_grouped = swing_24.groupby(['date', 'party'])['pct_estimate'].mean().reset_index()
# Create the line chart
plt.figure(figsize=(14, 8))
sns.lineplot(data=swing_24_grouped, x='date', y='pct_estimate', hue='party', marker='o',
palette={'REP': 'red', 'DEM': 'blue', 'IND': 'black'})
# Add vertical lines for significant events
plt.axvline(pd.to_datetime('2024-07-13'), color='red', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-08-05'), color='blue', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-07-23'), color='blue', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-09-05'), color='black', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-10-01'), color='black', linestyle='--', alpha=0.25)
# Add text annotations for significant events
plt.text(pd.to_datetime('2024-07-13'), plt.ylim()[1] * 0.6, 'Trump Assassination Attempt', color='red', ha='right')
plt.text(pd.to_datetime('2024-07-23'), plt.ylim()[1] * 0.5, 'First Harris Rally', color='blue', ha='right')
plt.text(pd.to_datetime('2024-08-05'), plt.ylim()[1] * 0.4, 'Official Nomination of Harris', color='blue', ha='right')
plt.text(pd.to_datetime('2024-09-05'), plt.ylim()[1] * 0.3, 'Presidential Debate', color='black', ha='right')
plt.text(pd.to_datetime('2024-10-01'), plt.ylim()[1] * 0.2, 'Vice Presidential Debate', color='black', ha='right')
# Add horizontal gridlines at values divisible by 5
plt.yticks(range(0, 51, 5))
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Limit the y-axis range to 50
plt.ylim(0, 50)
# Adjust the legend
plt.legend(title='Party')
# Set titles and labels
plt.title('Average Polling Percentage per Party Over Time in Swing States')
plt.xlabel('Date')
plt.ylabel('Average Polling Percentage')
plt.show()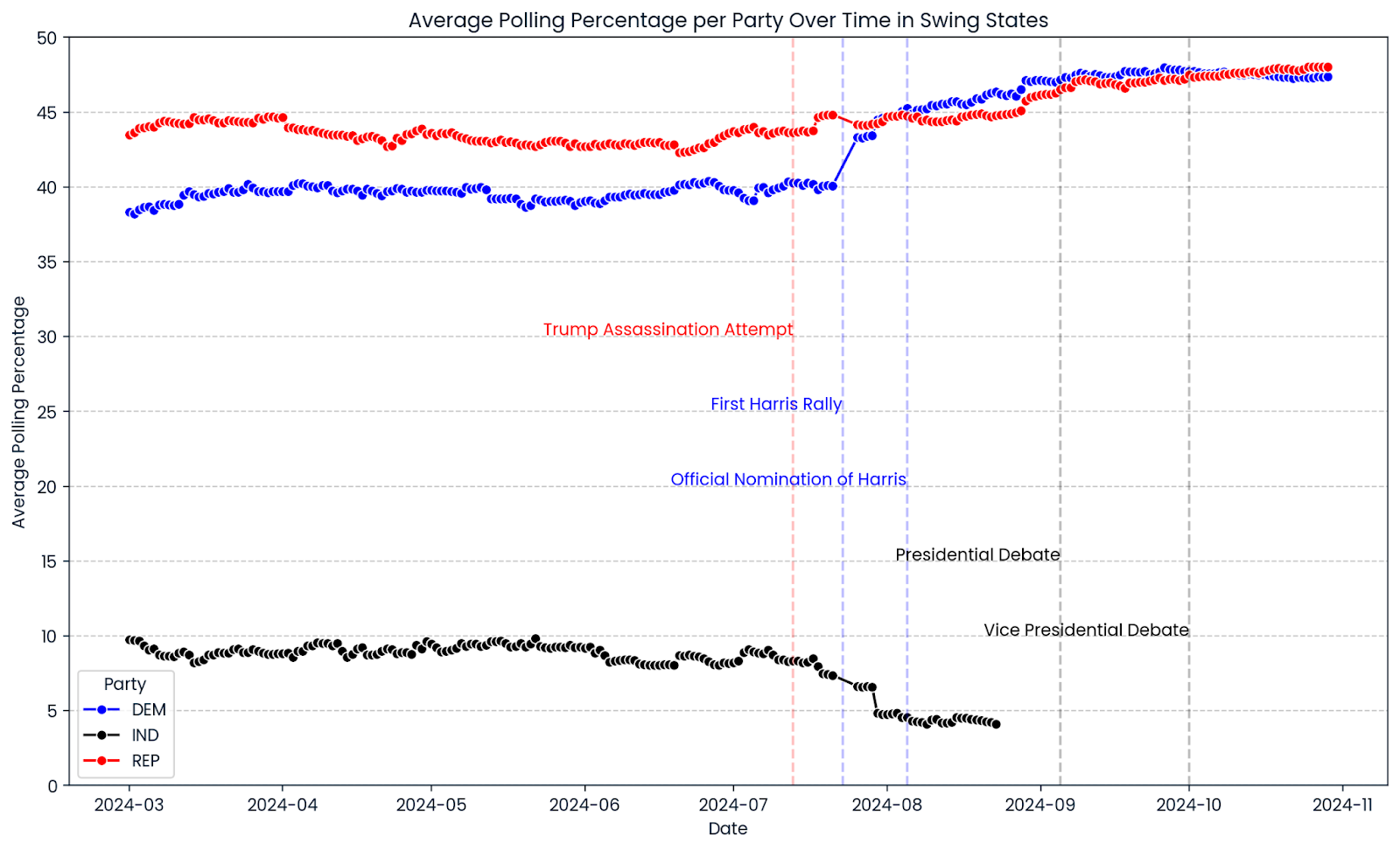
Ein erster Blick auf den Verlauf der Umfragen für 2024 zeigt, dass es in den Swing States sehr eng zugeht. Die Zustimmungsrate zu Donald Trump war während des gesamten Wahlkampfs relativ konstant, mit einem leichten Aufwärtstrend in letzter Zeit. Nachdem Kamala Harris am 5. August 2024 offiziell als Präsidentschaftskandidatin nominiert wurde, stieg der Prozentsatz der Demokratischen Partei weiter an und übertraf die Umfragewerte des ehemaligen Kandidaten und Präsidenten der Vereinigten Staaten, Joe Biden, deutlich. So oder so zeigen die Diagramme ein Bild von vielen Rennen, die viel zu knapp sind, um sie zu entscheiden.
In diesem Abschnitt stellen wir sicher, dass unsere Daten sauber und bereit für unsere maschinellen Lernmodelle sind, indem wir uns auf den Umgang mit fehlenden Werten und das Verständnis der Verteilungen unserer Schlüsselvariablen konzentrieren.
Es gibt noch ein paar Dinge zu überprüfen, ob die Daten in der richtigen Struktur vorliegen, damit die Modelle darauf trainiert werden können. Zunächst untersuchen wir, ob in beiden Datensätzen Spalten mit fehlenden Werten vorhanden sind.
# Calculate the number of missing values in each column of swing_until_20
missing_values_until_20 = swing_until_20.isnull().sum()
missing_values_24 = swing_24.isnull().sum()
# Filter out columns that have no missing values
missing_values_until_20 = missing_values_until_20[missing_values_until_20 > 0]
missing_values_24 = missing_values_24[missing_values_24 > 0]
# Display the columns with at least 1 missing value and their respective counts for both dataframes
print(missing_values_until_20, missing_values_24)momentum 84 dtype: int64
momentum 21 dtype: int64Das Kandidatenmomentum ist die einzige Spalte mit fehlenden Werten. Das macht Sinn, da sie als tägliche Differenz zwischen den Umfragewerten für jeden Kandidaten berechnet wird. Wir würden also erwarten, dass ihre erste Beobachtung ohne die Momentum-Spalte ist. Wir können die fehlenden Werte einfach entfernen.
# Dropping missing values
swing_24 = swing_24.dropna()
swing_until_20 = swing_until_20.dropna()Ein Blick auf die Verteilungen der numerischen Spalten gibt uns Aufschluss darüber, ob wir einige versteckte Ausreißer haben oder ob die Daten insgesamt plausibel sind.
Außerdem können wir die Umfragewerte für den Wahlzyklus 2024 mit dem Durchschnitt der vorherigen Zyklen vergleichen. Wir können einige der Merkmale wie pct_opponent und rolling_avg_7d weglassen, da sie im Wesentlichen aus der Spalte pct_estimate resultieren und im Grunde die gleiche Verteilung aufweisen.
# Getting description of distributions in both DataFrames
swing_until_20[['pct_estimate', 'lead', 'pct_3rd_party', 'momentum', 'vote_share']].describe()
print(swing_24[['pct_estimate', 'lead', 'pct_3rd_party','momentum']].describe())|
pct_estimate |
Blei |
pct_3rd_party |
momentum |
vote_share |
|
|
zählen |
20504 |
20504 |
20504 |
20504 |
20504 |
|
mittlere |
44.73 |
0.00 |
1.25 |
0.00 |
48.85 |
|
min |
32.65 |
-18.01 |
0.00 |
-8.45 |
40.96 |
|
25% |
42.07 |
-4.94 |
0.00 |
-0.01 |
46.17 |
|
50% |
44.99 |
0.00 |
0.00 |
0.00 |
48.67 |
|
75% |
47.43 |
4.94 |
0.00 |
0.01 |
50.77 |
|
max |
56.47 |
18.01 |
12.67 |
8.45 |
57.97 |
|
std |
3.89 |
6.58 |
2.66 |
0.47 |
3.59 |
|
pct_estimate |
Blei |
pct_3rd_party |
momentum |
|
|
zählen |
3228 |
3228 |
3228 |
3228 |
|
mittlere |
43.53 |
0.00 |
5.87 |
0.00 |
|
min |
35.39 |
-8.77 |
0.00 |
-6.28 |
|
25% |
41.06 |
-2.07 |
0.00 |
-0.12 |
|
50% |
43.76 |
0.00 |
8.01 |
0.00 |
|
75% |
46.56 |
2.07 |
8.91 |
0.12 |
|
max |
48.89 |
8.77 |
12.17 |
6.28 |
|
std |
3.22 |
3.63 |
4.05 |
0.45 |
Die Verteilungen der Merkmale in den Datensätzen von swing_until_20 und swing_24 erscheinen plausibel und stimmen mit den Erwartungen für Wahldaten in Swing States überein.
Die Werte von pct_estimate liegen zwischen etwa 33% und 56% in der Vergangenheit und 35% bis 49% im Jahr 2024, was für umkämpfte Wahlen, bei denen keiner der Kandidaten überwältigend dominiert, angemessen ist. Die vote_share im historischen Datensatz hat einen Mittelwert von 48,85%, was plausibel ist, wenn man bedenkt, dass die Wahlbeteiligung in den Swing States oft nahe bei 50-50 liegt.
Wie zu erwarten, zentrieren sich die Variablen lead und momentum in beiden Datensätzen um einen Mittelwert von 0, was darauf hindeutet, dass sich Vorsprung, Rückstand, Gewinne und Verluste zwischen den Kandidaten im Laufe der Zeit ausgleichen. Die Variable lead scheint fast perfekt normalverteilt zu sein, während die Variable momentum zumindest symmetrisch ist, aber die meisten Werte näher am Mittelwert liegen.
Die historische pct_estimate folgt einer ziemlich normalen Verteilung mit einer leichten Schräglage nach links, da der Mittelwert zumindest sehr nahe am Median liegt und die Streuung typische Werte innerhalb einer angemessenen Bandbreite erfasst.
Bei den Daten für 2024 liegen die Prozentwerte der Umfragen näher am Mittelwert. Die Variable lead hat im Jahr 2024 eine geringere Standardabweichung (3,63) als die historischen Daten (6,58), und die Bandbreite ihrer Werte ist sogar weniger als die Hälfte der historischen Werte. Dies sind alles Indikatoren dafür, dass die Abstände zwischen den Kandidatinnen und Kandidaten im Jahr 2024 enger sind, was auf noch engere Rennen hindeutet.
In den meisten Zyklen gab es keinen Kandidaten von Drittanbietern, der nennenswerte Unterstützung erhielt, wie wir aus der Tatsache ersehen können, dass über 75% der Beobachtungen einen pct_3rd_party Wert von 0 haben, wobei der Durchschnitt bei 1,25% liegt. Die hohen Zahlen im Jahr 2024 (Median von 8,01%) spiegeln die starke Unterstützung wider, die der unabhängige Kandidat Robert F. Kennedy bis zum Ende seiner Kampagne im August 2024 hatte.
Unsere Vorhersagestrategie wird der Tatsache Rechnung tragen, dass Umfragen keine endgültigen Wahlergebnisse sind, sondern lediglich Indikatoren für die öffentliche Stimmung zu bestimmten Zeitpunkten. Daher werden wir es vermeiden, uns auf einfache Zeitreihenvorhersagen zu verlassen, die Umfragedaten als direkte Vorhersagen von Ergebnissen behandeln. Stattdessen verwenden wir einen regressionsbasierten Ansatz, der den Wahlausgang für jede einzelne Wahlbeobachtung vorhersagt, anstatt eine Zeitleiste von Umfragedaten zu prognostizieren.
Da jeder Staat seine eigene politische Landschaft hat, werden wir für jeden Swing State ein eigenes Modell erstellen. Um Datenverluste zu vermeiden und den Lauf der Zeit zu berücksichtigen, stellen wir sicher, dass unsere Modelle nur mit ungesehenen Daten getestet werden - insbesondere mit Wahlzyklen, die nach denen liegen, auf denen die Modelle trainiert wurden. Dieser Ansatz hilft uns, die Fähigkeit der Modelle zu bewerten, auf zukünftige Wahlen zu verallgemeinern.
Bei der Bewertung der Prognosemodelle für den Stimmenanteil bei Wahlen habe ich zwei Bewertungskriterien gewählt. Da der Gewinner in jedem Bundesland "alles gewinnt", ist die Anzahl der richtig vorhergesagten Gewinner über die Testzyklen hinweg die wichtigste Kennzahl, die es zu berücksichtigen gilt.
Der mittlere absolute Fehler (Mean Absolute Error, MAE) ist das zweite Bewertungskriterium. Sie misst die durchschnittliche Größe der Fehler zwischen vorhergesagten und tatsächlichen Werten in denselben Einheiten wie die Zielvariable - in diesem Fall Prozentpunkte des Stimmenanteils. Das macht sie sehr interpretierbar und direkt relevant für unseren Kontext, da sie uns im Durchschnitt sagt, um wie viele Prozentpunkte unsere Vorhersagen von den tatsächlichen Ergebnissen abweichen.
Schließlich trainieren wir das beste Modell für jeden Staat auf allen Wahlzyklen bis 2020 und wenden es an, um die Wahlergebnisse für 2024 vorherzusagen. Wir verwenden eine zeitbasierte Gewichtung mit einer exponentiellen Abklingfunktion, um die einzelnen Vorhersagen in einen einzigen Vorhersagewert pro Bundesland umzuwandeln und den jüngsten Umfragen mehr Bedeutung zu verleihen.
Als erstes importieren wir die Pakete, die wir später brauchen werden. Dazu gehören alle Modelle, die wir bewerten werden, NumPy, sowie das mean_absolute_error.
# Importing models
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression, Ridge, ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.svm import SVR
import catboost
import xgboost as xgb
# Importing other necessary libraries
from sklearn.metrics import mean_absolute_error
import numpy as npLass uns einen Arbeitsablauf erstellen, um die Basismodelle zu trainieren und zu bewerten! Wir gehen den Prozess Schritt für Schritt durch und wenden ihn dann auf jeden Staat für jeden Prüfzyklus an, beginnend mit 2004.
Um unsere Modelle auf die besonderen Merkmale jedes Bundeslandes zuzuschneiden, filtern wir den Datensatz zunächst so, dass nur die für das untersuchte Land relevanten Daten enthalten sind. So wird sichergestellt, dass das Modell die bundeslandspezifischen Wahlmuster und Wahldaten erfasst.
# Filter data for the state you're analyzing
data_state = swing_until_20[swing_until_20['state'] == state].copy()Dann legen wir eine Gewichtungsfunktion fest, um Umfragen, die näher am Wahltermin durchgeführt werden, mehr Bedeutung beizumessen. Diese exponentielle Abklingfunktion verringert das Gewicht der Umfragen, je weiter sie von der Wahl entfernt sind, was die Relevanz der jüngsten Umfragedaten unterstreicht.
# Define the weight function (using a typical starting k value)
def compute_weight(days_until_election, k):
return np.exp(-k * days_until_election)
# Add weights to the data
data_state['weight'] = compute_weight(data_state['days_until_election'], k=0.1)Als Nächstes unterteilen wir die Daten in Trainings- und Testgruppen, die auf den Wahlzyklen basieren. So stellen wir sicher, dass wir mit vergangenen Wahlen trainieren und mit zukünftigen testen, um Datenverluste zu vermeiden. Auf die Definition von train_cycles und test_cycle kommen wir später zu sprechen, wenn wir uns durch die Wahlzyklen winden. Wir legen auch die Merkmale fest, die für die Vorhersage verwendet werden, und extrahieren die Zielvariable, nämlich den tatsächlichen Stimmenanteil.
# Split data into training and testing sets based on election cycles
train_data = data_state[data_state['cycle'].isin(train_cycles)]
test_data = data_state[data_state['cycle'] == test_cycle]
# Define features and target variable
features = ['pct_estimate', 'pct_opponent', 'pct_3rd_party', 'lead', 'rolling_avg_7d',
'days_until_election', 'momentum_candidate', 'momentum_opponent', 'momentum',
'is_incumbent_president', 'is_incumbent_vice_president', 'is_incumbent_party',
'candidate_Donald Trump',
'party_DEM', 'party_REP']
X_train = train_data[features]
y_train = train_data['vote_share']
X_test = test_data[features]
y_test = test_data['vote_share']Wir definieren eine Reihe von maschinellen Lernmodellen, die wir bewerten, darunter lineare Regression, Ensemble-Methoden, Support-Vektor-Maschinen und neuronale Netze. Diese Vielfalt ermöglicht es uns, verschiedene Algorithmen zu vergleichen und das leistungsstärkste Modell für jeden Staat auszuwählen.
# Models to evaluate
models = {
'LinearRegression': LinearRegression(),
'XGBoost': xgb.XGBRegressor(objective='reg:absoluteerror', n_estimators=100, random_state=42),
'CatBoost': catboost.CatBoostRegressor(loss_function='MAE', iterations=100, random_seed=42, verbose=0),
'RandomForest': RandomForestRegressor(n_estimators=100, random_state=42),
'SVR': SVR(kernel='rbf', C=1.0, epsilon=0.1),
'KNeighbors': KNeighborsRegressor(n_neighbors=5),
'MLPRegressor': MLPRegressor(hidden_layer_sizes=(100,), max_iter=500, random_state=42),
'ElasticNet': ElasticNet(alpha=1.0, l1_ratio=0.5, random_state=42),
}Im Anschluss daran werden wir das Wörterbuch models durchgehen. Für jedes Modell trainieren wir es mit dem Trainingsdatensatz für den aktuellen Zustand und machen dann Vorhersagen für den Testdatensatz. Dieser Vorgang wird für jedes Modell wiederholt, um ihre Leistung vergleichend zu bewerten.
for model_name, model in models.items():
# Train the model
model.fit(X_train, y_train)
# Predict on test data
test_data[f'predicted_{model_name}'] = model.predict(X_test)In der Modellschleife fassen wir die einzelnen Vorhersagen für jede Partei mit Hilfe einer Lambda-Funktion und den zuvor berechneten Gewichten zusammen. Daraus ergibt sich ein einzelner vorhergesagter Stimmenanteil pro Partei, den wir dann mit dem tatsächlichen Stimmenanteil vergleichen, um die Genauigkeit des Modells zu bewerten.
# Aggregate predictions using weights
aggregated_predictions = test_data.groupby('party').apply(
lambda df: np.average(df[f'predicted_{model_name}'], weights=df['weight'])
).reset_index(name='aggregated_prediction')
# Get actual vote shares for comparison
actual_vote_shares = test_data.groupby('party')['vote_share'].mean().reset_index()
comparison = pd.merge(aggregated_predictions, actual_vote_shares, on='party')
comparison.rename(columns={'vote_share': 'actual_vote_share'}, inplace=True)Um die Modellschleife zu beenden, berechnen wir den mittleren absoluten Fehler (MAE) zwischen den aggregierten Vorhersagen und den tatsächlichen Stimmanteilen, um die Leistung des Modells zu quantifizieren. Wir stellen auch fest, ob das Modell die siegreiche Partei im Staat richtig vorhergesagt hat und speichern diese Ergebnisse für eine spätere Analyse.
# Calculate Mean Absolute Error
mae = mean_absolute_error(comparison['actual_vote_share'], comparison['aggregated_prediction'])
# Check if the predicted winner matches the actual winner
predicted_winner = comparison.loc[comparison['aggregated_prediction'].idxmax(), 'party']
actual_winner = comparison.loc[comparison['actual_vote_share'].idxmax(), 'party']
correct_winner = int(predicted_winner == actual_winner)
# Store the results
results_list.append({
'state': state,
'model_name': model_name,
'test_cycle': test_cycle,
'MAE': mae,
'correct_winner': correct_winner
})Dieser gesamte Prozess wird in zwei Schleifen abgewickelt: Die äußere Schleife durchläuft jeden Wahlzyklus (mit Ausnahme des ersten, da es keine vorherigen Daten zum Trainieren gibt), und die innere Schleife durchläuft jeden Swing State. Auf diese Weise stellen wir sicher, dass die Modelle für jeden Staat und jeden Wahlzyklus entsprechend trainiert und getestet werden, wobei die chronologische Reihenfolge der Wahlen eingehalten wird, um Datenverluste zu vermeiden.
Das Vorwort zum obigen Code sieht wie folgt aus:
# Initialize a list to store results
results_list = []
# Define the election cycles
cycles = [2000, 2004, 2008, 2012, 2016, 2020]
for i in range(1, len(cycles)): # The loop starts at index 1, so with the 2nd cycle (2004)
test_cycle = cycles[i]
train_cycles = cycles[:i] # train_cycles = all cycles before the test_cycle
for state in swing_states:
# Filter data for the state you're analyzing, etc. …Mit dieser Strategie können wir mehrere Modelle für verschiedene Staaten und Wahlzyklen auswerten und schließlich das beste Modell für jeden Staat auf der Grundlage der Vorhersagegenauigkeit und der Fähigkeit, den Wahlsieger korrekt vorherzusagen, auswählen.
Nachdem wir verschiedene Machine-Learning-Modelle für verschiedene Staaten und Wahlzyklen trainiert und getestet haben, bewerten wir ihre Leistung, um die besten Modelle für jeden Staat zu ermitteln. Diese Auswertung konzentriert sich auf zwei Schlüsselkennzahlen: die Anzahl der Fälle, in denen jedes Modell die siegreiche Partei richtig vorhergesagt hat (correct_winner) und den durchschnittlichen mittleren absoluten Fehler (MAE) ihrer Vorhersagen.
Zunächst fassen wir alle Ergebnisse, die während der Modellevaluierungen gesammelt wurden, in einem einzigen DataFrame zusammen und aggregieren die Leistungsmetriken:
# After the loop, create a DataFrame from the results list
results_df = pd.DataFrame(results_list)
# Get the sum of correct_winner and the average MAE for every combination of state and model_name
aggregated_evaluation = results_df.groupby(['state', 'model_name']).agg({
'correct_winner': 'sum',
'MAE': 'mean'
}).reset_index()
# Display the maximum number of correct winner predictions and the minimum MAE for each state
print(aggregated_evaluation.groupby('state')['correct_winner'].max())
print(aggregated_evaluation.groupby('state')['MAE'].min())|
Staat |
Maximum correct_winner |
Minimum MAE |
|
Arizona |
5 |
1.248966 |
|
Georgia |
5 |
0.770760 |
|
Michigan |
4 |
2.685870 |
|
Nevada |
5 |
2.079582 |
|
North Carolina |
5 |
0.917522 |
|
Pennsylvania |
4 |
2.027426 |
|
Wisconsin |
4 |
2.462907 |
Das sieht gar nicht so schlecht aus! In allen Staaten gab es mindestens ein Modell, das 4 der 5 früheren Wahlen richtig vorhersagte. In 4 der Staaten (Arizona, Georgia, Nevada und North Carolina) haben wir sogar einige Modelle, die in jedem Zyklus den richtigen Gewinner vorhersagen. Die Ergebnisse für die niedrigste MAE sind jedoch teilweise verbesserungswürdig und unterscheiden sich stark zwischen den einzelnen Staaten: Sie liegen im Durchschnitt bei 1,74 Prozentpunkten und reichen von 0,77 in Georgia bis 2,69 in Michigan.
Mit diesen aggregierten Informationen wählen wir das leistungsstärkste Modell für jeden Staat aus. Wir sortieren die Modelle zuerst nach ihrer Fähigkeit, den richtigen Gewinner vorherzusagen, und erst danach nach ihrem MAE. Die ausgewählten Modelle werden im Wörterbuch best_models gespeichert.
# Sort the models for each state by correct_winner (descending) and then by MAE (ascending)
sorted_evaluation = aggregated_evaluation.sort_values(by=['state', 'correct_winner', 'MAE'], ascending=[True, False, True])
# Create a dictionary to store the best model for each state
best_models = {}
# Iterate over each state and get the top model
for state in sorted_evaluation['state'].unique():
top_model = sorted_evaluation[sorted_evaluation['state'] == state].iloc[0]
best_models[state] = top_model['model_name']
best_models{'Arizona': 'RandomForest',
'Georgia': 'ElasticNet',
'Michigan': 'LinearRegression',
'Nevada': 'KNeighbors',
'North Carolina': 'CatBoost',
'Pennsylvania': 'KNeighbors',
'Wisconsin': 'MLPRegressor'}Die Top-Modelle für die einzelnen Bundesstaaten sind sehr unterschiedlich und spiegeln die einzigartigen Wahlmuster und das Wahlverhalten in jeder Region wider. Überraschenderweise werden in Michigan sogar die besten Ergebnisse mit der linearen Regression erzielt, was darauf hindeutet, dass dort ein einfacher linearer Ansatz ausreichen könnte.
An diesem Punkt können wir die Hyperparameter abstimmen, um die Leistung der einzelnen Machine-Learning-Modelle zu optimieren. Da dies weitere methodische Fragen aufwirft und große Anpassungen am Code erfordern würde, ist es nicht im Rahmen dieses bereits recht langen Tutorials möglich. Die Ergebnisse der Basismodelle sehen schon jetzt vielversprechend genug aus, um das Wahlergebnis 2024 zu wagen und vorherzusagen.
In der letzten Phase unserer Analyse verwenden wir die besten Modelle für jeden Swing State, um den Wahlausgang 2024 vorherzusagen. Wir beginnen damit, eine leere Liste zu initialisieren, um unsere Vorhersagen zu speichern.
Für jeden Zustand und das dazugehörige beste Modell aus unseren vorherigen Bewertungen verwenden wir denselben Arbeitsablauf wie zuvor. Nur müssen wir dieses Mal nicht die Wahlzyklen durchlaufen, sondern trainieren mit allen historischen Daten von 2000 bis 2020 (swing_until_20 ).
# Initialize a list to store predictions
predictions_list = []
for state, model_name in best_models.items():
# Filter the data for the specific state
state_data_train = swing_until_20[swing_until_20['state'] == state].copy() # Data from 2000 to 2020
state_data_test = swing_24[swing_24['state'] == state].copy() # Data for 2024
# Add weights to the test data
state_data_test['weight'] = compute_weight(state_data_test['days_until_election'], k=0.1)
# Define features
features = [
'pct_estimate',
'pct_opponent',
'pct_3rd_party',
'lead',
'rolling_avg_7d',
'days_until_election',
'momentum_candidate',
'momentum_opponent',
'momentum',
'is_incumbent_president',
'is_incumbent_vice_president',
'is_incumbent_party',
'candidate_Donald Trump',
'party_DEM',
'party_REP'
]
# Split features and target variable
X_train = state_data_train[features]
y_train = state_data_train['vote_share']
X_test = state_data_test[features]
# Train the model on the 2000 to 2020 data
model.fit(X_train, y_train)
# Predict on the 2024 data
state_data_test['predicted_vote_share'] = model.predict(X_test)
# Aggregate predictions using weights
aggregated_predictions = state_data_test.groupby('party').apply(
lambda df: np.average(df['predicted_vote_share'], weights=df['weight'])
).reset_index(name='aggregated_prediction')
# Append predictions to the list
for _, pred_row in aggregated_predictions.iterrows():
predictions_list.append({
'state': state,
'party': pred_row['party'],
'predicted_vote_share': pred_row['aggregated_prediction'],
'model': model_name
})Nach der Vorhersage der Spalte vote_share, der Aggregation der Vorhersagen mit der zuvor definierten Gewichtungsfunktion und dem Anhängen der Vorhersagen an predictions_list fassen wir die endgültigen Vorhersagen in einem DataFrame zusammen. Außerdem fügen wir für jeden Staat ein Ranking hinzu und drehen die Vorhersagen nach Staat. Hier sind die Vorhersagen unserer Modelle:
# Convert predictions list to DataFrame
predictions_df = pd.DataFrame(predictions_list)
# Add a rank to predictions_df for each state based on the order of predicted_vote_share
predictions_df['rank'] = predictions_df.groupby('state')['predicted_vote_share'].rank(ascending=False)
# Create a pivot table indexed by state
predictions_pivot = predictions_df.pivot(index='state', columns='party', values='predicted_vote_share')
# Display predictions
print("\n2024 Vote Share Predictions:")
predictions_pivot2024 Vote Share Predictions:
state
DEM
REP
Arizona
49.02
50.31
Georgia
48.95
50.08
Michigan
50.34
48.64
Nevada
49.41
48.54
North Carolina
48.95
50.06
Pennsylvania
49.57
49.20
Wisconsin
49.66
49.41Die Vorhersagen bestätigen unsere Einschätzung eines sehr engen Rennens in den Swing States. Unsere Modelle sagen voraus, dass vier Staaten ihre Mehrheit für Kamala Harris (Michigan, Nevada, Pennsylvania, Wisconsin) und drei für Donald Trump (Arizona, Georgia, North Carolina) abgeben werden. Die Bundesstaaten Pennsylvania und Wisconsin werden voraussichtlich besonders eng beieinander liegen, da der Unterschied zwischen den beiden vorhergesagten Stimmenanteilen nur 0,37 bzw. 0,25 Prozentpunkte beträgt.
Wie bereits erwähnt, gehen wir davon aus, dass alle anderen Staaten für den Kandidaten stimmen, der voraussichtlich gewinnen wird, d.h. die "blauen" Staaten stimmen für Kamala Harris und die "roten" Staaten für Donald Trump. Um festzustellen, wie viele Wählerstimmen jeder Kandidat erhält, definieren wir ein Wörterbuch, das jedem Bundesstaat und Bezirk die Anzahl der Stimmen zuordnet, und fassen die Informationen in einem DataFrame namens electoral_votes_df zusammen.
# Define the number of electoral votes per state for the 2024 US-Presidential elections
electoral_votes = {
'Alabama': 9, 'Alaska': 3, 'Arizona': 11, 'Arkansas': 6, 'California': 54,
'Colorado': 10, 'Connecticut': 7, 'Delaware': 3, 'District of Columbia': 3,
'Florida': 30, 'Georgia': 16, 'Hawaii': 4, 'Idaho': 4, 'Illinois': 19,
'Indiana': 11, 'Iowa': 6, 'Kansas': 6, 'Kentucky': 8, 'Louisiana': 8,
'Maine': 2, 'Maryland': 10, 'Massachusetts': 11, 'Michigan': 15,
'Minnesota': 10, 'Mississippi': 6, 'Missouri': 10, 'Montana': 4,
'Nebraska': 2, 'Nevada': 6, 'New Hampshire': 4, 'New Jersey': 14,
'New Mexico': 5, 'New York': 28, 'North Carolina': 16, 'North Dakota': 3,
'Ohio': 17, 'Oklahoma': 7, 'Oregon': 8, 'Pennsylvania': 19,
'Rhode Island': 4, 'South Carolina': 9, 'South Dakota': 3,
'Tennessee': 11, 'Texas': 40, 'Utah': 6, 'Vermont': 3, 'Virginia': 13,
'Washington': 12, 'West Virginia': 4, 'Wisconsin': 10, 'Wyoming': 3
}
# Create a DataFrame from the dictionary
electoral_votes_df = pd.DataFrame(list(electoral_votes.items()), columns=['State', 'Electoral Votes'])
# Handle states that divide their votes into multiple districts (Maine and Nebraska)
districts = {'ME-1': 1, 'ME-2': 1, 'NE-1': 1, 'NE-2': 1, 'NE-3': 1}
# Add the districts to the DataFrame
districts_df = pd.DataFrame(list(districts.items()), columns=['State', 'Electoral Votes'])
# Combine the two DataFrames
electoral_votes_df = pd.concat([electoral_votes_df, districts_df], ignore_index=True)Als Nächstes erstellen wir zwei Listen, harris und trump, die die blauen bzw. roten Staaten sowie die Swing States enthalten, die jeder Kandidat voraussichtlich gewinnen wird. Im nächsten Schritt können wir electoral_votes_df für die Staaten in jeder Liste filtern und die Summe der Wahlstimmen berechnen, die für jeden Kandidaten erwartet werden.
# Extract states from predictions_df where party is DEM and rank is 1
additional_blue_states = predictions_df[
(predictions_df['party'] == 'DEM') & (predictions_df['rank'] == 1)
].state.tolist()
# Extract states from predictions_df where party is REP and rank is 1
additional_red_states = predictions_df[
(predictions_df['party'] == 'REP') & (predictions_df['rank'] == 1)
].state.tolist()
# Combine blue_states and additional_blue_states into a single list
harris = list(set(blue_states + additional_blue_states))
trump = list(set(red_states + additional_red_states))
# Filter the electoral votes for states in each candidate's list
harris_electoral_votes = electoral_votes_df[electoral_votes_df['state'].isin(harris)]
trump_electoral_votes = electoral_votes_df[electoral_votes_df['state'].isin(trump)]
# Sum the electoral votes
sum_harris_electoral_votes = harris_electoral_votes['electoral_votes'].sum()
sum_trump_electoral_votes = trump_electoral_votes['electoral_votes'].sum()
print(
f'According to the predictions made by the machine learning models, '
f'Kamala Harris will win {sum_harris_electoral_votes} electoral votes '
f'and Donald Trump will win {sum_trump_electoral_votes} electoral votes.'
)According to the predictions made by the machine learning models, Kamala Harris will win 276 electoral votes and Donald Trump will win 262 electoral votes.Die Vorhersage lautet, dass Kamala Harris 276 Wahlmännerstimmen und Donald Trump 262 Wahlmännerstimmen gewinnen wird. Wenn unsere Annahmen und Vorhersagen zutreffen, würde die Wahlkarte am 5. November folgendermaßen aussehen:
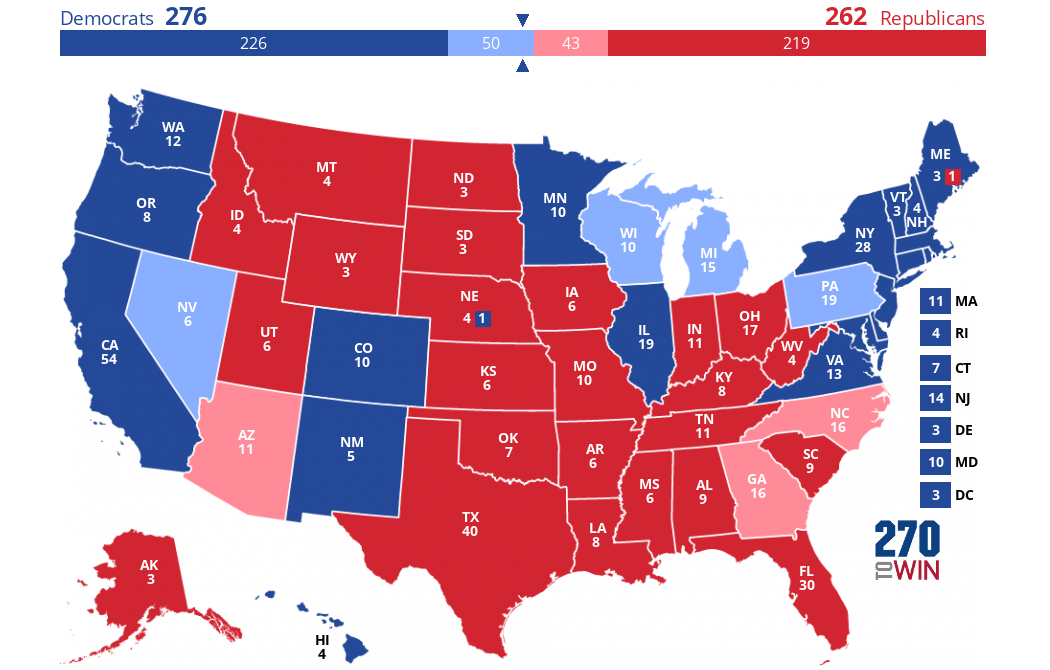
Erstellt mit diesem interaktiven Kartenersteller.
Die dunklen Farben stellen das dar, was wir als "blaue" oder "rote" Zustände angenommen haben. Die von uns vorhergesagten Swing States machen den Unterschied - sie sind in einem helleren Blau oder Rot eingefärbt.
In diesem Projekt haben wir historische Umfragedaten genutzt, um das Ergebnis der US-Präsidentschaftswahlen 2024 vorherzusagen. Wie erwartet, zeigen unsere Modelle ein enges Rennen zwischen den Spitzenkandidaten.
Es ist wichtig zu bedenken, dass unsere Analyse ausschließlich auf Umfragedaten basiert, die in der Vergangenheit manchmal ungenau waren und nicht alle Nuancen einer Wahl erfassen. Faktoren wie Wahlmethoden, Wahlbeteiligung, Wahlkampfdynamik, wirtschaftliche und demografische Umstände und unvorhergesehene Ereignisse wurden in unseren Modellen nicht berücksichtigt, können aber die tatsächlichen Ergebnisse erheblich beeinflussen.
Nichtsdestotrotz zeigt diese Untersuchung das Potenzial der prädiktiven Analytik, um komplexe Systeme wie Wahlen zu verstehen. Wenn du mehr über Predictive Analytics mit Python erfahren möchtest, empfehle ich dir diese Ressourcen:
Lerne maschinelles Lernen mit diesen Kursen!
Lernpfad
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.