Cursus
Apprentissage automatique supervisé en Python
25 h
Les données utilisées pour notre prédiction proviennent de FiveThirtyEightqui rassemble des données de sondages provenant de toutes sortes d'instituts de sondage. Les données sont disponibles sur leur site GitHub pour tous les cycles électoraux depuis 1968.
Nous utiliserons leur modèle de sondage, qui attribue le pourcentage moyen des sondages pour chaque candidat dans chaque État pour (presque) chaque date donnée au cours des huit mois précédant l'élection.
Nous commençons par importer les données des sondages 2024, 2020 et historiques à partir de fichiers CSV. Les données de 2024 sont filtrées sur les sondages du cycle actuel uniquement, et les données historiques jusqu'à 2016 sont concaténées avec les données de 2020. Dans les deux DataFrame qui en résultent, polls_24 et polls_until_20, les colonnes de date sont converties au format datetime pour garantir la cohérence, et les colonnes pertinentes telles que le cycle, l'État, le nom du candidat et les estimations de sondage sont conservées.
import pandas as pd
# Reading CSV files
polls_24 = pd.read_csv('presidential_general_averages.csv')
polls_20 = pd.read_csv('presidential_poll_averages_2020.csv')
polls_until_16 = pd.read_csv('pres_pollaverages_1968-2016.csv')
# Filtering and concatenating DataFrames
polls_24 = polls_24[polls_24['cycle'] == 2024]
polls_until_20 = pd.concat([polls_20, polls_until_16], ignore_index=True)
# Making sure dates are in datetime format
polls_24['date'] = pd.to_datetime(polls_24['date'], format='%Y-%m-%d')
polls_until_20['modeldate'] = pd.to_datetime(polls_until_20['modeldate'])
# Keeping only the columns of interest
polls_until_20 = polls_until_20[['cycle', 'state', 'modeldate', 'candidate_name', 'pct_estimate', 'pct_trend_adjusted']]Pour les résultats des votes par État, j'ai pris les données directement auprès de la Commission électorale fédérale des États-Unis. Par souci de simplicité, je les ai résumés au préalable dans un fichier CSV.
Une observation représente la combinaison du cycle électoral, de l'État et du parti, chacun complété par le nom du candidat respectif et, bien sûr, le pourcentage de voix obtenu par ce candidat.
# Importing result data
results_until_20 = pd.read_csv('results.csv', sep=';')
results_until_20 = results_until_20[['cycle', 'state', 'party', 'candidate', 'vote_share']]Pour garantir que nous travaillons avec des données pertinentes et de haute qualité, j'ai appliqué deux restrictions clés :
swing_states, blue_states et red_states en conséquence et nous créons des sous-ensembles de données pour les États en transition.# Implementing cycle restriction
start_cycle = 2000
polls_until_20 = polls_until_20[polls_until_20['cycle'] >= start_cycle]
# Defining state lists
swing_states = [
'Pennsylvania', 'Wisconsin', 'Michigan', 'Georgia',
'North Carolina', 'Arizona', 'Nevada'
]
blue_states = [
'District of Columbia', 'Vermont', 'Massachusetts', 'Maryland',
'Hawaii', 'California', 'ME-1', 'Connecticut', 'Washington',
'Delaware', 'Rhode Island', 'New York', 'Illinois', 'New Jersey',
'Oregon', 'Colorado', 'Maine', 'New Mexico', 'Virginia',
'New Hampshire', 'NE-2', 'Minnesota'
]
red_states = [
'Wyoming', 'West Virginia', 'Oklahoma', 'North Dakota',
'Idaho', 'South Dakota', 'Arkansas', 'Kentucky', 'NE-3',
'Alabama', 'Tennessee', 'Utah', 'Louisiana', 'Nebraska',
'Mississippi', 'Montana', 'NE-1', 'Indiana', 'Kansas',
'Missouri', 'South Carolina', 'Alaska', 'Ohio', 'Iowa',
'Texas', 'ME-2', 'Florida'
]
# Defining swing state subset of the poll data
swing_until_20 = polls_until_20[polls_until_20['state'].isin(swing_states)]
swing_24 = polls_24[polls_24['state'].isin(swing_states)]Pour obtenir une vue d'ensemble de nos données, nous effectuons une analyse exploratoire des données (AED). Tout d'abord, nous utilisons une combinaison des méthodes .isnull() et .sum() pour voir quelles colonnes chaque DataFrame inclut et où des données pourraient manquer.
# Checking for missing values in swing_24 and swing_until_20
print(swing_24.isnull().sum())
print(swing_until_20.isnull().sum())candidate 0
date 0
pct_trend_adjusted 4394
state 0
cycle 0
party 0
pct_estimate 0
hi 0
lo 0
dtype: int64
cycle 0
state 0
modeldate 0
candidate_name 0
pct_estimate 0
pct_trend_adjusted 0
dtype: int64Comme nous pouvons le constater, les noms des colonnes diffèrent entre les deux DataFrame, et la colonne party semble manquer dans swing_until_20. En outre, il semble qu'il y ait deux types de pourcentages mesurés : un pourcentage estimé et un pourcentage corrigé de la tendance. Toutefois, le pourcentage corrigé de la tendance ne semble pas être disponible pour les données de 2024. Nous y reviendrons plus tard.
Vérifions ensuite les valeurs distinctes de chacune de nos variables catégorielles :
print('2024 data:')
print(swing_24['date'].min()) # earliest polling date
print(swing_24['date'].max()) # latest polling date
print(swing_24['state'].unique().tolist()) # distinct states
print(swing_24['party'].unique().tolist()) # distinct parties
print(swing_24['candidate'].unique().tolist()) # distinct candidates
print('Historical data:')
print(swing_until_20['modeldate'].min())
print(swing_until_20['modeldate'].max())
print(swing_until_20['state'].unique().tolist())
print(swing_until_20['candidate_name'].unique().tolist())2024 data:
2024-03-01 00:00:00
2024-10-29 00:00:00
['Arizona', 'Georgia', 'Michigan', 'Nevada', 'North Carolina', 'Pennsylvania', 'Wisconsin']
['REP', 'DEM', 'IND']
['Trump', 'Harris', 'Kennedy', 'Biden']
Historical data:
2000-03-02 00:00:00
2020-11-03 00:00:00
['Wisconsin', 'Pennsylvania', 'North Carolina', 'Nevada', 'Michigan', 'Georgia', 'Arizona']
['Joseph R. Biden Jr.', 'Donald Trump', 'Convention Bounce for Joseph R. Biden Jr.', 'Convention Bounce for Donald Trump', 'Hillary Rodham Clinton', 'Gary Johnson', 'Barack Obama', 'Mitt Romney', 'John McCain', 'George W. Bush', 'John Kerry', 'Al Gore', 'Ralph Nader']Si les données sont satisfaisantes en ce qui concerne les États et les dates, il y a lieu de noter certaines choses dans les colonnes relatives aux candidats. Les données historiques (celles du cycle 2020 plus précisément) comprennent non seulement les pourcentages des deux candidats mais aussi les rebonds de convention, c'est-à-dire les augmentations de soutien après la tenue de leur convention nationale. En outre, les prénoms semblent manquer sur le site swing_24.
Pour notre étude des différents types de pourcentages, il est essentiel de supprimer immédiatement les observations de rebond de convention :
# Only keep rows where candidate_name does not start with 'Convention Bounce'
swing_until_20 = swing_until_20[~swing_until_20['candidate_name'].str.startswith('Convention Bounce')]Pour garantir la cohérence, le type de pourcentage doit être le même pour toutes les données de formation et de test. Comme nous l'avons découvert, seules les données jusqu'au cycle électoral de 2020 contiennent à la fois des pourcentages estimés et des pourcentages corrigés de la tendance, tandis qu'il n'y a que des pourcentages estimés pour 2024. Il nous reste donc deux options, qui sont les suivantes :
La manière dont le pourcentage corrigé de la tendance a été calculé pour les données historiques n'est pas claire. C'est pourquoi nous devons étudier la relation entre les pourcentages estimés et les pourcentages corrigés de la tendance avant de procéder au nettoyage des données, car le choix de la base de données est crucial pour nos prédictions. Tout d'abord, nous étudions la corrélation et la différence moyenne dans les données historiques.
# Checking the correlation between the percentages
adj_corr_swing = swing_until_20['pct_estimate'].corr(swing_until_20['pct_trend_adjusted'])
print('Correlation between estimated and trend-adjusted percentage in swing states: ' + str(adj_corr_swing))
# Calculate the mean difference between pct_estimate and pct_trend_adjusted, grouping by date, state, and party
mean_diff = (swing_until_20['pct_estimate'] - swing_until_20['pct_trend_adjusted']).mean()
print('Mean difference between estimated and trend-adjusted percentage in swing states: ' + str(mean_diff))Correlation between estimated and trend-adjusted percentage in swing states: 0.9953626583357665
Mean difference between estimated and trend-adjusted percentage in swing states: 0.24980898513865013Nous pouvons constater que la corrélation entre les deux est extrêmement élevée (99,5%), comme on pouvait s'y attendre. La différence moyenne d'environ 0,25 point de pourcentage semble faible à première vue, mais elle pourrait faire la différence dans des courses très serrées, comme celles attendues dans le Nevada ou le Michigan.
Étant donné que tous les votes électoraux de chaque État sont attribués au vainqueur, l'ordre des candidats est plus important qu'un pourcentage précis. Ce que nous voulons éviter, c'est une divergence à l'approche de la date des élections. Par conséquent, nous pouvons examiner le nombre d'observations dans lesquelles le candidat en tête des deux pourcentages a été différent lors du dernier cycle électoral de 2020 et la dernière date d'une telle occurrence.
# Finding out how often pct_estimate and pct_trend_adjusted saw different candidates in the lead in the 2020 race
swing_20 = swing_until_20[swing_until_20['cycle'] == 2020]
# Create a new column to indicate if the ranking is different between pct_estimate and pct_trend_adjusted
swing_20['rank_estimate'] = swing_20.groupby(['state', 'modeldate'])['pct_estimate'].rank(ascending=False)
swing_20['rank_trend_adjusted'] = swing_20.groupby(['state', 'modeldate'])['pct_trend_adjusted'].rank(ascending=False)
# Rows where the rankings are different in swing states
different_rankings_swing = swing_20[swing_20['rank_estimate'] != swing_20['rank_trend_adjusted']]
print('Number of observations with differing leader: ' + str(different_rankings_swing.shape[0] / 2))
print('Last occurrence: ' + str(different_rankings_swing['modeldate'].max()))Number of observations with differing leader: 34.0
Last occurrence: 2020-06-24 00:00:00Apparemment, l'avance n'a différé que dans 34 cas, soit environ 5 jours par État membre en moyenne. Comme la dernière occurrence se situe à la fin du mois de juin, toutes les occurrences semblent se situer dans la phase initiale de la campagne électorale.
Compte tenu de tout cela, il est peu probable que les rares cas de changement de direction influencent la précision globale du modèle, surtout si nous disposons d'un ensemble de données assez important couvrant plusieurs cycles. J'ai donc choisi la première option et n'ai utilisé que le pourcentage estimé pour tous les cycles électoraux. Cela permet de garantir cohérence des donnéesce qui est essentiel dans l'apprentissage automatique pour éviter que le modèle n'apprenne les biais introduits par les différentes méthodes de traitement des données.
Pour ajouter une colonne pour le parti politique, nous obtenons d'abord une liste de tous les candidats dans l'ensemble de données historiques. Ensuite, nous créons un dictionnaire avec les candidats comme clés et le parti respectif comme valeur correspondante.ChatGPT est idéal pour cela et vous permet de gagner du temps dans vos recherches ! Enfin, nous combinons les deux dans un DataFrame, et nous le fusionnons à swing_until_20.
# Get unique candidate names
candidate_names = swing_until_20['candidate_name'].unique().tolist()
# Create a dictionary of candidates and their political party
party_map = {
'Joseph R. Biden Jr.': 'DEM',
'Donald Trump': 'REP',
'Hillary Rodham Clinton': 'DEM',
'Gary Johnson': 'LIB',
'Barack Obama': 'DEM',
'Mitt Romney': 'REP',
'John McCain': 'REP',
'Ralph Nader': 'IND',
'George W. Bush': 'REP',
'John Kerry': 'DEM',
'Al Gore': 'DEM'
}
# Create a DataFrame with candidates and their respective parties
candidate_df = pd.DataFrame(candidate_names, columns=['candidate_name'])
candidate_df['party'] = candidate_df['candidate_name'].map(party_map)
# Merge the candidate_df with swing_until_20 on 'candidate' column
swing_until_20 = swing_until_20.merge(candidate_df[['candidate_name', 'party']], on='candidate_name', how='left')Maintenant que nous avons ajouté la colonne des partis à notre DataFrame swing_until_20, nous pouvons y fusionner les résultats historiques des élections dans une nouvelle colonne appelée vote_share. Étant donné que le fichier CSV de vote_share était dans un format différent, nous devons l'adapter au même format que celui utilisé dans la colonne pct_estimate.
# Merging results_until_20 to swing_until_20
swing_until_20 = pd.merge(swing_until_20, results_until_20, how='left', left_on=['cycle', 'state', 'party', 'candidate_name'], right_on=['cycle', 'state', 'party', 'candidate'])
swing_until_20['vote_share'] = swing_until_20['vote_share'].str.replace(',', '.')
swing_until_20['vote_share'] = pd.to_numeric(swing_until_20['vote_share'])Enfin, nous renommons la colonne modeldate en date, nous supprimons toutes les colonnes inutiles et nous adaptons le format candidate dans les données de 2024 afin d'inclure également les prénoms.
# Renaming columns in swing_until_20
swing_until_20.rename(columns={'modeldate': 'date'}, inplace=True)
# Keeping only relevant columns
swing_24 = swing_24[['cycle', 'date', 'state', 'party', 'candidate', 'pct_estimate']]
swing_until_20 = swing_until_20[['cycle', 'date', 'state', 'party', 'candidate', 'pct_estimate', 'vote_share']]
# Update candidate names in swing_24 dataframe
swing_24['candidate'] = swing_24['candidate'].replace({
'Trump': 'Donald Trump',
'Biden': 'Joseph R. Biden Jr.',
'Harris': 'Kamala Harris',
'Kennedy': 'Robert F. Kennedy'})Voyons un peu comment s'est déroulée la campagne électorale de 2024 jusqu'à présent. Nous utilisons seaborn et matplotlib pour créer un graphique linéaire montrant la progression moyenne des sondages dans tous les "swing states" sélectionnés. Les lignes rouges, bleues et noires indiquent les pourcentages de vote des républicains, des démocrates et des candidats indépendants. Les lignes verticales marquent les événements importants de la campagne.
import matplotlib.pyplot as plt
import seaborn as sns
# Ensure the date column is in datetime format
swing_24['date'] = pd.to_datetime(swing_24['date'])
# Group by date and party, then average the pct_estimate
swing_24_grouped = swing_24.groupby(['date', 'party'])['pct_estimate'].mean().reset_index()
# Create the line chart
plt.figure(figsize=(14, 8))
sns.lineplot(data=swing_24_grouped, x='date', y='pct_estimate', hue='party', marker='o',
palette={'REP': 'red', 'DEM': 'blue', 'IND': 'black'})
# Add vertical lines for significant events
plt.axvline(pd.to_datetime('2024-07-13'), color='red', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-08-05'), color='blue', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-07-23'), color='blue', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-09-05'), color='black', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-10-01'), color='black', linestyle='--', alpha=0.25)
# Add text annotations for significant events
plt.text(pd.to_datetime('2024-07-13'), plt.ylim()[1] * 0.6, 'Trump Assassination Attempt', color='red', ha='right')
plt.text(pd.to_datetime('2024-07-23'), plt.ylim()[1] * 0.5, 'First Harris Rally', color='blue', ha='right')
plt.text(pd.to_datetime('2024-08-05'), plt.ylim()[1] * 0.4, 'Official Nomination of Harris', color='blue', ha='right')
plt.text(pd.to_datetime('2024-09-05'), plt.ylim()[1] * 0.3, 'Presidential Debate', color='black', ha='right')
plt.text(pd.to_datetime('2024-10-01'), plt.ylim()[1] * 0.2, 'Vice Presidential Debate', color='black', ha='right')
# Add horizontal gridlines at values divisible by 5
plt.yticks(range(0, 51, 5))
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Limit the y-axis range to 50
plt.ylim(0, 50)
# Adjust the legend
plt.legend(title='Party')
# Set titles and labels
plt.title('Average Polling Percentage per Party Over Time in Swing States')
plt.xlabel('Date')
plt.ylabel('Average Polling Percentage')
plt.show()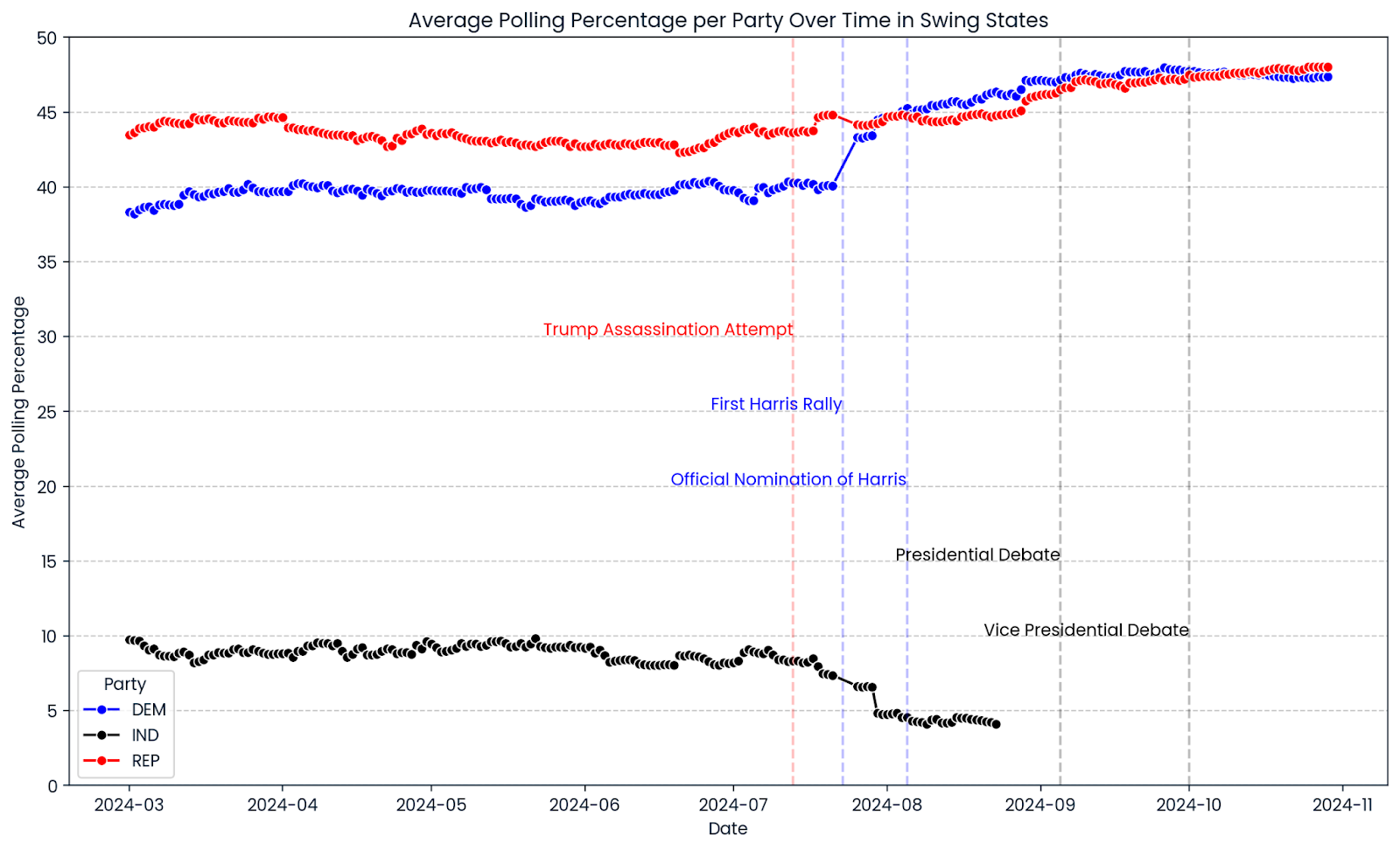
Un premier aperçu de la progression des sondages pour 2024 montre que la marge de manœuvre est très étroite dans les "swing states". Le taux d'approbation de Donald Trump est resté relativement constant tout au long de la campagne, avec une légère hausse récemment. Le pourcentage du Parti démocrate a continué à augmenter après que Kamala Harris a été officiellement désignée comme leur candidate à la présidence le 5 août 2024, dépassant de manière significative les sondages de l'ancien candidat et président des États-Unis, Joe Biden. Quoi qu'il en soit, les graphiques montrent que de nombreuses courses sont bien trop serrées pour être départagées.
Dans cette section, nous nous assurerons que nos données sont propres et prêtes pour nos modèles d'apprentissage automatique, en nous concentrant sur le traitement des valeurs manquantes et la compréhension des distributions de nos variables clés.
Il reste quelques éléments à vérifier pour s'assurer que les données sont dans la bonne structure pour l'entraînement des modèles. Tout d'abord, nous cherchons à savoir si des colonnes des deux ensembles de données ont des valeurs manquantes.
# Calculate the number of missing values in each column of swing_until_20
missing_values_until_20 = swing_until_20.isnull().sum()
missing_values_24 = swing_24.isnull().sum()
# Filter out columns that have no missing values
missing_values_until_20 = missing_values_until_20[missing_values_until_20 > 0]
missing_values_24 = missing_values_24[missing_values_24 > 0]
# Display the columns with at least 1 missing value and their respective counts for both dataframes
print(missing_values_until_20, missing_values_24)momentum 84 dtype: int64
momentum 21 dtype: int64L'élan du candidat est la seule colonne dont les valeurs sont manquantes. C'est logique puisqu'elle est calculée comme la différence quotidienne entre les valeurs des sondages pour chaque candidat, et nous nous attendons donc à ce que leur première observation soit sans la colonne "momentum". Nous pouvons simplement supprimer les valeurs manquantes.
# Dropping missing values
swing_24 = swing_24.dropna()
swing_until_20 = swing_until_20.dropna()L'examen des distributions des colonnes numériques nous permettra de savoir si nous avons des valeurs aberrantes cachées ou si les données sont plausibles dans l'ensemble.
En outre, nous pouvons comparer les sondages du cycle électoral 2024 à la moyenne des cycles précédents. Nous pouvons laisser de côté certaines caractéristiques telles que pct_opponent et rolling_avg_7d puisqu'elles résultent essentiellement de la colonne pct_estimate et qu'elles ressembleront à la même distribution.
# Getting description of distributions in both DataFrames
swing_until_20[['pct_estimate', 'lead', 'pct_3rd_party', 'momentum', 'vote_share']].describe()
print(swing_24[['pct_estimate', 'lead', 'pct_3rd_party','momentum']].describe())|
pct_estimate |
plomb |
pct_3rd_party |
élan |
vote_share |
|
|
compter |
20504 |
20504 |
20504 |
20504 |
20504 |
|
moyenne |
44.73 |
0.00 |
1.25 |
0.00 |
48.85 |
|
min |
32.65 |
-18.01 |
0.00 |
-8.45 |
40.96 |
|
25% |
42.07 |
-4.94 |
0.00 |
-0.01 |
46.17 |
|
50% |
44.99 |
0.00 |
0.00 |
0.00 |
48.67 |
|
75% |
47.43 |
4.94 |
0.00 |
0.01 |
50.77 |
|
max |
56.47 |
18.01 |
12.67 |
8.45 |
57.97 |
|
std |
3.89 |
6.58 |
2.66 |
0.47 |
3.59 |
|
pct_estimate |
plomb |
pct_3rd_party |
élan |
|
|
compter |
3228 |
3228 |
3228 |
3228 |
|
moyenne |
43.53 |
0.00 |
5.87 |
0.00 |
|
min |
35.39 |
-8.77 |
0.00 |
-6.28 |
|
25% |
41.06 |
-2.07 |
0.00 |
-0.12 |
|
50% |
43.76 |
0.00 |
8.01 |
0.00 |
|
75% |
46.56 |
2.07 |
8.91 |
0.12 |
|
max |
48.89 |
8.77 |
12.17 |
6.28 |
|
std |
3.22 |
3.63 |
4.05 |
0.45 |
Les distributions des caractéristiques dans les ensembles de données swing_until_20 et swing_24 semblent plausibles et s'alignent sur les attentes en matière de données de sondage dans les États en transition.
Les valeurs de pct_estimate varient entre environ 33 % et 56 % historiquement et entre 35 % et 49 % en 2024, ce qui est raisonnable pour des élections compétitives où aucun des deux candidats ne domine de manière écrasante. Le site vote_share dans l'ensemble de données historiques a une moyenne de 48,85 %, ce qui est plausible étant donné que les swing states ont souvent une répartition proche de 50-50.
Comme on pouvait s'y attendre, les variables lead et momentum sont centrées autour d'une moyenne de 0 dans les deux ensembles de données, ce qui indique que les avances, les retards, les gains et les pertes entre les candidats s'équilibrent au fil du temps. La variable lead semble être presque parfaitement distribuée normalement, tandis que la variable momentum est au moins symétrique, mais la plupart des valeurs sont plus proches de la moyenne.
L'historique pct_estimate suit une distribution tout à fait normale avec une légère asymétrie vers la gauche, la moyenne étant au moins très proche de la médiane, et l'écart saisit des quantités typiques de valeurs dans une fourchette raisonnable.
Dans les données de 2024, les pourcentages des sondages sont plus proches de la moyenne. La variable lead a un écart-type plus faible en 2024 (3,63) que les données historiques (6,58), et la fourchette de ses valeurs est même inférieure à la moitié de la fourchette historique. Tous ces éléments indiquent que les marges entre les candidats seront plus étroites en 2024, ce qui laisse présager des courses encore plus serrées.
Dans la plupart des cycles, aucun candidat tiers n'a recueilli de soutien significatif, comme le montre le fait que plus de 75 % des observations ont une valeur pct_3rd_party de 0, la moyenne étant de 1,25 %. Les chiffres élevés en 2024 (médiane de 8,01%) reflètent le soutien important dont a bénéficié le candidat indépendant Robert F. Kennedy jusqu'à la fin de sa campagne en août 2024.
Notre stratégie de prédiction tiendra compte du fait que les sondages ne sont pas des résultats électoraux définitifs, mais simplement des indicateurs du sentiment public à des moments précis. Par conséquent, nous éviterons de nous appuyer sur de simples prédictions de séries chronologiques qui considèrent les données des sondages comme des prévisions directes des résultats. Au lieu de cela, nous utiliserons une approche basée sur la régression qui prédit le résultat de l'élection pour chaque observation de sondage individuellement, plutôt que de prévoir une chronologie de données de sondage.
Sachant que chaque État a son propre paysage politique, nous construirons un modèle distinct pour chaque État en transition. Pour éviter les fuites de données et respecter le passage du temps, nous veillerons à ce que nos modèles ne soient testés que sur des données inédites, en l'occurrence des cycles électoraux postérieurs à ceux sur lesquels les modèles ont été entraînés. Cette approche nous permettra d'évaluer la capacité des modèles à s'appliquer avec précision aux élections futures.
J'ai choisi deux critères d'évaluation pour évaluer les modèles prédictifs des parts de voix aux élections. Étant donné que le gagnant "rafle tout" dans chaque État, le nombre de gagnants correctement prédits sur l'ensemble des cycles de test est la mesure la plus importante à prendre en compte.
L'erreur absolue moyenne (MAE) est le critère d'évaluation secondaire. Elle mesure l'ampleur moyenne des erreurs entre les valeurs prédites et les valeurs réelles dans les mêmes unités que la variable cible - dans ce cas, les points de pourcentage de la part de vote. Il est donc très facile à interpréter et s'inscrit directement dans notre contexte, puisqu'il nous indique, en moyenne, de combien de points de pourcentage nos prédictions s'écartent des résultats réels.
Enfin, nous entraînerons le meilleur modèle de chaque État sur tous les cycles électoraux jusqu'en 2020 et l'appliquerons pour prédire les résultats des élections de 2024. Nous utiliserons une pondération basée sur le temps avec une fonction de décroissance exponentielle pour transformer les prédictions individuelles en une seule valeur prédictive par État, en donnant plus d'importance aux sondages récents.
Tout d'abord, nous importons les paquets dont nous aurons besoin plus tard. Il s'agit de tous les modèles que nous allons évaluer, NumPy, ainsi que de mean_absolute_error.
# Importing models
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression, Ridge, ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.svm import SVR
import catboost
import xgboost as xgb
# Importing other necessary libraries
from sklearn.metrics import mean_absolute_error
import numpy as npCréons un flux de travail pour former et évaluer les modèles de base ! Nous allons suivre le processus étape par étape et l'appliquer à chaque État pour chaque cycle de test, en commençant par 2004.
Pour adapter nos modèles aux caractéristiques uniques de chaque État, nous commençons par filtrer l'ensemble des données afin de n'inclure que les données pertinentes pour l'État analysé. Cela permet de s'assurer que le modèle tient compte des habitudes de vote et des données de sondage propres à chaque État.
# Filter data for the state you're analyzing
data_state = swing_until_20[swing_until_20['state'] == state].copy()Nous définissons ensuite une fonction de pondération afin d'accorder plus d'importance aux sondages réalisés à une date plus proche de l'élection. Cette fonction de décroissance exponentielle diminue le poids des sondages à mesure qu'ils s'éloignent de l'élection, soulignant ainsi la pertinence des données de sondages récentes.
# Define the weight function (using a typical starting k value)
def compute_weight(days_until_election, k):
return np.exp(-k * days_until_election)
# Add weights to the data
data_state['weight'] = compute_weight(data_state['days_until_election'], k=0.1)Ensuite, nous avons divisé les données en ensembles de formation et de test en fonction des cycles électoraux, en veillant à ce que la formation porte sur les élections passées et le test sur les élections futures afin d'éviter les fuites de données. Nous reviendrons sur la définition de train_cycles et test_cycle plus tard, lorsque nous aurons bouclé la boucle des cycles électoraux. Nous définissons également les caractéristiques qui seront utilisées pour la prédiction et nous extrayons la variable cible, qui est la part de voix réelle.
# Split data into training and testing sets based on election cycles
train_data = data_state[data_state['cycle'].isin(train_cycles)]
test_data = data_state[data_state['cycle'] == test_cycle]
# Define features and target variable
features = ['pct_estimate', 'pct_opponent', 'pct_3rd_party', 'lead', 'rolling_avg_7d',
'days_until_election', 'momentum_candidate', 'momentum_opponent', 'momentum',
'is_incumbent_president', 'is_incumbent_vice_president', 'is_incumbent_party',
'candidate_Donald Trump',
'party_DEM', 'party_REP']
X_train = train_data[features]
y_train = train_data['vote_share']
X_test = test_data[features]
y_test = test_data['vote_share']Nous définissons une variété de modèles d'apprentissage automatique à évaluer, y compris la régression linéaire, les méthodes d'ensemble, les machines à vecteurs de support et les réseaux neuronaux. Cet ensemble diversifié nous permet de comparer différents algorithmes et de sélectionner le modèle le plus performant pour chaque État.
# Models to evaluate
models = {
'LinearRegression': LinearRegression(),
'XGBoost': xgb.XGBRegressor(objective='reg:absoluteerror', n_estimators=100, random_state=42),
'CatBoost': catboost.CatBoostRegressor(loss_function='MAE', iterations=100, random_seed=42, verbose=0),
'RandomForest': RandomForestRegressor(n_estimators=100, random_state=42),
'SVR': SVR(kernel='rbf', C=1.0, epsilon=0.1),
'KNeighbors': KNeighborsRegressor(n_neighbors=5),
'MLPRegressor': MLPRegressor(hidden_layer_sizes=(100,), max_iter=500, random_state=42),
'ElasticNet': ElasticNet(alpha=1.0, l1_ratio=0.5, random_state=42),
}Ensuite, nous passerons en revue le dictionnaire models. Pour chaque modèle, nous l'entraînons à l'aide de l'ensemble de données d'entraînement spécifique à l'état actuel, puis nous faisons des prédictions sur l'ensemble de données de test. Ce processus est répété pour chaque modèle afin d'évaluer leurs performances de manière comparative.
for model_name, model in models.items():
# Train the model
model.fit(X_train, y_train)
# Predict on test data
test_data[f'predicted_{model_name}'] = model.predict(X_test)Dans la boucle du modèle, nous agrégeons les prédictions individuelles pour chaque parti à l'aide d'une fonction lambda appliquant les poids calculés précédemment. Nous obtenons ainsi une seule prévision de part de voix par parti, que nous comparons ensuite à la part de voix réelle afin d'évaluer la précision du modèle.
# Aggregate predictions using weights
aggregated_predictions = test_data.groupby('party').apply(
lambda df: np.average(df[f'predicted_{model_name}'], weights=df['weight'])
).reset_index(name='aggregated_prediction')
# Get actual vote shares for comparison
actual_vote_shares = test_data.groupby('party')['vote_share'].mean().reset_index()
comparison = pd.merge(aggregated_predictions, actual_vote_shares, on='party')
comparison.rename(columns={'vote_share': 'actual_vote_share'}, inplace=True)Pour terminer la boucle du modèle, nous calculons l'erreur absolue moyenne (MAE) entre les prédictions agrégées et les votes réels afin de quantifier la performance du modèle. Nous déterminons également si le modèle a correctement prédit le parti vainqueur dans l'État et conservons ces résultats pour une analyse ultérieure.
# Calculate Mean Absolute Error
mae = mean_absolute_error(comparison['actual_vote_share'], comparison['aggregated_prediction'])
# Check if the predicted winner matches the actual winner
predicted_winner = comparison.loc[comparison['aggregated_prediction'].idxmax(), 'party']
actual_winner = comparison.loc[comparison['actual_vote_share'].idxmax(), 'party']
correct_winner = int(predicted_winner == actual_winner)
# Store the results
results_list.append({
'state': state,
'model_name': model_name,
'test_cycle': test_cycle,
'MAE': mae,
'correct_winner': correct_winner
})L'ensemble de ce processus s'inscrit dans deux boucles : la boucle extérieure itère sur chaque cycle électoral (à l'exception du premier, car il n'y a pas de données antérieures sur lesquelles s'appuyer), et la boucle intérieure itère sur chaque État en transition. Ce faisant, nous nous assurons que les modèles sont formés et testés de manière appropriée pour chaque État et chaque cycle électoral, en respectant l'ordre chronologique des élections afin d'éviter les fuites de données.
La préface du code ci-dessus ressemble à ceci :
# Initialize a list to store results
results_list = []
# Define the election cycles
cycles = [2000, 2004, 2008, 2012, 2016, 2020]
for i in range(1, len(cycles)): # The loop starts at index 1, so with the 2nd cycle (2004)
test_cycle = cycles[i]
train_cycles = cycles[:i] # train_cycles = all cycles before the test_cycle
for state in swing_states:
# Filter data for the state you're analyzing, etc. …Dans l'ensemble, cette stratégie nous permet d'évaluer plusieurs modèles dans différents États et cycles électoraux, pour finalement sélectionner le modèle le plus performant pour chaque État sur la base de la précision prédictive et de la capacité à prévoir correctement le vainqueur de l'élection.
Après avoir entraîné et testé divers modèles d'apprentissage automatique dans différents États et cycles électoraux, nous passons à l'évaluation de leurs performances afin d'identifier les meilleurs modèles pour chaque État. Cette évaluation se concentre sur deux paramètres clés : le nombre de fois où chaque modèle a correctement prédit le parti gagnant (correct_winner) et l'erreur absolue moyenne (MAE) de leurs prédictions.
Tout d'abord, nous compilons tous les résultats collectés lors des évaluations de modèles dans un seul DataFrame et agrégeons les mesures de performance :
# After the loop, create a DataFrame from the results list
results_df = pd.DataFrame(results_list)
# Get the sum of correct_winner and the average MAE for every combination of state and model_name
aggregated_evaluation = results_df.groupby(['state', 'model_name']).agg({
'correct_winner': 'sum',
'MAE': 'mean'
}).reset_index()
# Display the maximum number of correct winner predictions and the minimum MAE for each state
print(aggregated_evaluation.groupby('state')['correct_winner'].max())
print(aggregated_evaluation.groupby('state')['MAE'].min())|
state |
Maximum correct_winner |
MAE minimum |
|
Arizona |
5 |
1.248966 |
|
Géorgie |
5 |
0.770760 |
|
Michigan |
4 |
2.685870 |
|
Nevada |
5 |
2.079582 |
|
Caroline du Nord |
5 |
0.917522 |
|
Pennsylvanie |
4 |
2.027426 |
|
Wisconsin |
4 |
2.462907 |
Cela n'a pas l'air trop mal ! Dans tous les États, il y avait au moins un modèle qui prédisait correctement 4 des 5 élections précédentes. Dans quatre des États (Arizona, Géorgie, Nevada et Caroline du Nord), nous avons même obtenu des modèles prédisant le bon vainqueur pour chaque cycle. Les résultats pour le MAE le plus bas peuvent toutefois être améliorés et diffèrent considérablement entre les États, avec une moyenne de 1,74 point de pourcentage et une fourchette allant de 0,77 en Géorgie à 2,69 dans le Michigan.
Avec ces informations agrégées, nous sélectionnons le modèle le plus performant pour chaque État. Nous trions les modèles en fonction de leur capacité à prédire le bon gagnant en premier lieu et seulement ensuite en fonction de leur MAE. Les modèles choisis sont enregistrés dans le dictionnaire best_models.
# Sort the models for each state by correct_winner (descending) and then by MAE (ascending)
sorted_evaluation = aggregated_evaluation.sort_values(by=['state', 'correct_winner', 'MAE'], ascending=[True, False, True])
# Create a dictionary to store the best model for each state
best_models = {}
# Iterate over each state and get the top model
for state in sorted_evaluation['state'].unique():
top_model = sorted_evaluation[sorted_evaluation['state'] == state].iloc[0]
best_models[state] = top_model['model_name']
best_models{'Arizona': 'RandomForest',
'Georgia': 'ElasticNet',
'Michigan': 'LinearRegression',
'Nevada': 'KNeighbors',
'North Carolina': 'CatBoost',
'Pennsylvania': 'KNeighbors',
'Wisconsin': 'MLPRegressor'}Les meilleurs modèles pour chaque État varient considérablement, reflétant les habitudes de vote et les comportements électoraux propres à chaque région. Il est surprenant de constater que dans le Michigan, les meilleurs résultats sont même obtenus en utilisant la régression linéaire, ce qui indique qu'une approche linéaire plus simple peut suffire dans ce cas.
À ce stade, nous pouvons utiliser le réglage des hyperparamètres pour optimiser les performances de chaque modèle d'apprentissage automatique. Comme cela soulèverait d'autres questions méthodologiques et nécessiterait d'importants ajustements du code, cela sort du cadre de ce tutoriel déjà assez long. Les résultats des modèles de base semblent déjà suffisamment prometteurs pour oser prédire les résultats des élections de 2024.
Dans la dernière étape de notre analyse, nous utilisons les modèles les plus performants pour chaque swing state afin de prédire les résultats des élections de 2024. Nous commençons par initialiser une liste vide pour stocker nos prédictions.
Pour chaque état et son meilleur modèle correspondant à nos évaluations précédentes, nous utilisons le même flux de travail que précédemment. Seulement, cette fois-ci, nous ne devons pas passer par les cycles électoraux, mais nous entraîner sur toutes les données historiques de 2000 à 2020 (swing_until_20 ).
# Initialize a list to store predictions
predictions_list = []
for state, model_name in best_models.items():
# Filter the data for the specific state
state_data_train = swing_until_20[swing_until_20['state'] == state].copy() # Data from 2000 to 2020
state_data_test = swing_24[swing_24['state'] == state].copy() # Data for 2024
# Add weights to the test data
state_data_test['weight'] = compute_weight(state_data_test['days_until_election'], k=0.1)
# Define features
features = [
'pct_estimate',
'pct_opponent',
'pct_3rd_party',
'lead',
'rolling_avg_7d',
'days_until_election',
'momentum_candidate',
'momentum_opponent',
'momentum',
'is_incumbent_president',
'is_incumbent_vice_president',
'is_incumbent_party',
'candidate_Donald Trump',
'party_DEM',
'party_REP'
]
# Split features and target variable
X_train = state_data_train[features]
y_train = state_data_train['vote_share']
X_test = state_data_test[features]
# Train the model on the 2000 to 2020 data
model.fit(X_train, y_train)
# Predict on the 2024 data
state_data_test['predicted_vote_share'] = model.predict(X_test)
# Aggregate predictions using weights
aggregated_predictions = state_data_test.groupby('party').apply(
lambda df: np.average(df['predicted_vote_share'], weights=df['weight'])
).reset_index(name='aggregated_prediction')
# Append predictions to the list
for _, pred_row in aggregated_predictions.iterrows():
predictions_list.append({
'state': state,
'party': pred_row['party'],
'predicted_vote_share': pred_row['aggregated_prediction'],
'model': model_name
})Après avoir prédit la colonne vote_share, agrégé les prédictions à l'aide de la fonction de pondération définie précédemment et ajouté les prédictions à la colonne predictions_list, nous consolidons les prédictions finales dans un DataFrame. En outre, nous ajoutons un classement pour chaque État et faisons pivoter les prédictions par État. Voici les prédictions faites par nos modèles :
# Convert predictions list to DataFrame
predictions_df = pd.DataFrame(predictions_list)
# Add a rank to predictions_df for each state based on the order of predicted_vote_share
predictions_df['rank'] = predictions_df.groupby('state')['predicted_vote_share'].rank(ascending=False)
# Create a pivot table indexed by state
predictions_pivot = predictions_df.pivot(index='state', columns='party', values='predicted_vote_share')
# Display predictions
print("\n2024 Vote Share Predictions:")
predictions_pivot2024 Vote Share Predictions:
state
DEM
REP
Arizona
49.02
50.31
Georgia
48.95
50.08
Michigan
50.34
48.64
Nevada
49.41
48.54
North Carolina
48.95
50.06
Pennsylvania
49.57
49.20
Wisconsin
49.66
49.41Les prévisions confirment notre estimation d'une course très serrée dans les États clés. Nos modèles prévoient que quatre États donneront leur vote majoritaire à Kamala Harris (Michigan, Nevada, Pennsylvanie, Wisconsin) et trois à Donald Trump (Arizona, Géorgie, Caroline du Nord). Les États de Pennsylvanie et du Wisconsin devraient être particulièrement serrés, la différence entre les deux prévisions n'étant que de 0,37 et 0,25 points de pourcentage respectivement.
Comme indiqué précédemment, nous supposons que tous les autres États votent pour le candidat qui devrait l'emporter, c'est-à-dire que les États "bleus" votent pour Kamala Harris et les États "rouges" pour Donald Trump. Afin d'évaluer le nombre de voix électorales obtenues par chaque candidat, nous définissons un dictionnaire attribuant à chaque État et à chaque district leur nombre de voix et nous combinons les informations dans un DataFrame appelé electoral_votes_df.
# Define the number of electoral votes per state for the 2024 US-Presidential elections
electoral_votes = {
'Alabama': 9, 'Alaska': 3, 'Arizona': 11, 'Arkansas': 6, 'California': 54,
'Colorado': 10, 'Connecticut': 7, 'Delaware': 3, 'District of Columbia': 3,
'Florida': 30, 'Georgia': 16, 'Hawaii': 4, 'Idaho': 4, 'Illinois': 19,
'Indiana': 11, 'Iowa': 6, 'Kansas': 6, 'Kentucky': 8, 'Louisiana': 8,
'Maine': 2, 'Maryland': 10, 'Massachusetts': 11, 'Michigan': 15,
'Minnesota': 10, 'Mississippi': 6, 'Missouri': 10, 'Montana': 4,
'Nebraska': 2, 'Nevada': 6, 'New Hampshire': 4, 'New Jersey': 14,
'New Mexico': 5, 'New York': 28, 'North Carolina': 16, 'North Dakota': 3,
'Ohio': 17, 'Oklahoma': 7, 'Oregon': 8, 'Pennsylvania': 19,
'Rhode Island': 4, 'South Carolina': 9, 'South Dakota': 3,
'Tennessee': 11, 'Texas': 40, 'Utah': 6, 'Vermont': 3, 'Virginia': 13,
'Washington': 12, 'West Virginia': 4, 'Wisconsin': 10, 'Wyoming': 3
}
# Create a DataFrame from the dictionary
electoral_votes_df = pd.DataFrame(list(electoral_votes.items()), columns=['State', 'Electoral Votes'])
# Handle states that divide their votes into multiple districts (Maine and Nebraska)
districts = {'ME-1': 1, 'ME-2': 1, 'NE-1': 1, 'NE-2': 1, 'NE-3': 1}
# Add the districts to the DataFrame
districts_df = pd.DataFrame(list(districts.items()), columns=['State', 'Electoral Votes'])
# Combine the two DataFrames
electoral_votes_df = pd.concat([electoral_votes_df, districts_df], ignore_index=True)Ensuite, nous créons deux listes, harris et trump, qui contiennent respectivement les États bleus et les États rouges, ainsi que les États en transition qui devraient être remportés par chaque candidat. Dans l'étape suivante, nous pouvons filtrer electoral_votes_df pour les États de chaque liste et calculer la somme des votes électoraux attendus pour chaque candidat.
# Extract states from predictions_df where party is DEM and rank is 1
additional_blue_states = predictions_df[
(predictions_df['party'] == 'DEM') & (predictions_df['rank'] == 1)
].state.tolist()
# Extract states from predictions_df where party is REP and rank is 1
additional_red_states = predictions_df[
(predictions_df['party'] == 'REP') & (predictions_df['rank'] == 1)
].state.tolist()
# Combine blue_states and additional_blue_states into a single list
harris = list(set(blue_states + additional_blue_states))
trump = list(set(red_states + additional_red_states))
# Filter the electoral votes for states in each candidate's list
harris_electoral_votes = electoral_votes_df[electoral_votes_df['state'].isin(harris)]
trump_electoral_votes = electoral_votes_df[electoral_votes_df['state'].isin(trump)]
# Sum the electoral votes
sum_harris_electoral_votes = harris_electoral_votes['electoral_votes'].sum()
sum_trump_electoral_votes = trump_electoral_votes['electoral_votes'].sum()
print(
f'According to the predictions made by the machine learning models, '
f'Kamala Harris will win {sum_harris_electoral_votes} electoral votes '
f'and Donald Trump will win {sum_trump_electoral_votes} electoral votes.'
)According to the predictions made by the machine learning models, Kamala Harris will win 276 electoral votes and Donald Trump will win 262 electoral votes.La prédiction est que Kamala Harris gagnera 276 votes électoraux et Donald Trump 262 votes électoraux. Si nos hypothèses et nos prédictions se vérifient, voici à quoi ressemblerait la carte électorale le 5 novembre :
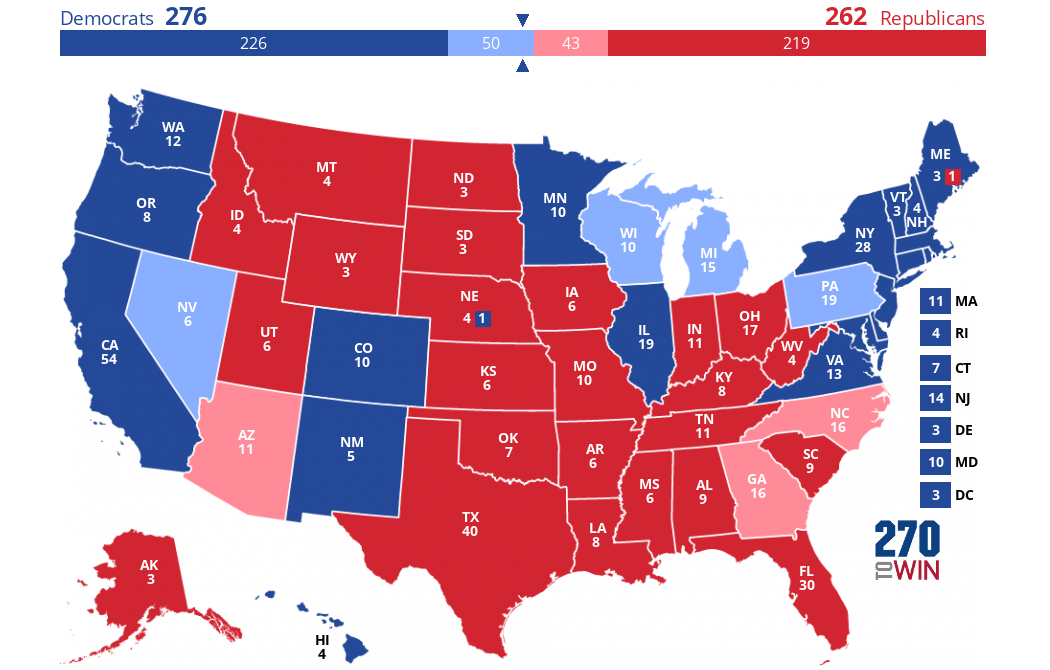
Créée à l'aide de ce créateur de cartes interactives.
Les couleurs foncées représentent ce que nous avons supposé être des états "bleus" ou "rouges". Les "swing states" que nous avons prédits font la différence : ils sont colorés en bleu ou en rouge plus clair.
Dans ce projet, nous avons utilisé les données historiques des sondages pour prédire le résultat de l'élection présidentielle américaine de 2024. Comme prévu, nos modèles indiquent une course serrée entre les principaux candidats.
Il est important de garder à l'esprit que notre analyse repose uniquement sur les données des sondages, qui se sont parfois révélées inexactes par le passé et ne permettent pas de saisir toutes les nuances d'une élection. Des facteurs tels que les méthodes de sondage, la participation des électeurs, la dynamique de la campagne, les circonstances économiques et démographiques et les événements imprévus n'ont pas été pris en compte dans nos modèles mais peuvent avoir un impact significatif sur les résultats réels.
Néanmoins, cette exploration montre le potentiel de l'analyse prédictive dans la compréhension de systèmes complexes tels que les élections. Si vous souhaitez en savoir plus sur l'analyse prédictive à l'aide de Python, je vous recommande ces ressources :
Apprenez l'apprentissage automatique avec ces cours !
Cursus
Cours
Cours