Programa
Aprendizado de máquina supervisionado em Python
25 h
Os dados usados para nossa previsão são de FiveThirtyEightque reúne dados de pesquisas de todos os tipos de pesquisadores diferentes. Os dados estão disponíveis em seu GitHub para todos os ciclos eleitorais desde 1968.
Usaremos o modelo de pesquisa deles, que atribui a porcentagem média de pesquisa para cada candidato em cada estado para (quase) cada data específica nos oito meses que antecedem a eleição.
Começamos importando dados de pesquisas eleitorais de 2024, 2020 e históricos de arquivos CSV. Os dados de 2024 são filtrados apenas nas pesquisas do ciclo atual, e os dados históricos até 2016 são concatenados com os dados de 2020. Nos dois DataFrames resultantes, polls_24 e polls_until_20, as colunas de data são convertidas em um formato datetime para garantir a consistência, e as colunas relevantes como ciclo, estado, nome do candidato e estimativas de pesquisa são mantidas.
import pandas as pd
# Reading CSV files
polls_24 = pd.read_csv('presidential_general_averages.csv')
polls_20 = pd.read_csv('presidential_poll_averages_2020.csv')
polls_until_16 = pd.read_csv('pres_pollaverages_1968-2016.csv')
# Filtering and concatenating DataFrames
polls_24 = polls_24[polls_24['cycle'] == 2024]
polls_until_20 = pd.concat([polls_20, polls_until_16], ignore_index=True)
# Making sure dates are in datetime format
polls_24['date'] = pd.to_datetime(polls_24['date'], format='%Y-%m-%d')
polls_until_20['modeldate'] = pd.to_datetime(polls_until_20['modeldate'])
# Keeping only the columns of interest
polls_until_20 = polls_until_20[['cycle', 'state', 'modeldate', 'candidate_name', 'pct_estimate', 'pct_trend_adjusted']]Para os resultados reais da votação por estado, peguei os dados diretamente da Comissão Eleitoral Federal dos EUA. Para simplificar, eu os resumi em um arquivo CSV previamente.
Uma observação representa a combinação de ciclo eleitoral, estado e partido, cada um completado com o nome do respectivo candidato e, é claro, a porcentagem de votos que esse candidato obteve.
# Importing result data
results_until_20 = pd.read_csv('results.csv', sep=';')
results_until_20 = results_until_20[['cycle', 'state', 'party', 'candidate', 'vote_share']]Para garantir que estamos trabalhando com dados relevantes e de alta qualidade, apliquei duas restrições importantes:
swing_states, blue_states e red_states de acordo com isso e criamos subconjuntos de dados para os estados indecisos.# Implementing cycle restriction
start_cycle = 2000
polls_until_20 = polls_until_20[polls_until_20['cycle'] >= start_cycle]
# Defining state lists
swing_states = [
'Pennsylvania', 'Wisconsin', 'Michigan', 'Georgia',
'North Carolina', 'Arizona', 'Nevada'
]
blue_states = [
'District of Columbia', 'Vermont', 'Massachusetts', 'Maryland',
'Hawaii', 'California', 'ME-1', 'Connecticut', 'Washington',
'Delaware', 'Rhode Island', 'New York', 'Illinois', 'New Jersey',
'Oregon', 'Colorado', 'Maine', 'New Mexico', 'Virginia',
'New Hampshire', 'NE-2', 'Minnesota'
]
red_states = [
'Wyoming', 'West Virginia', 'Oklahoma', 'North Dakota',
'Idaho', 'South Dakota', 'Arkansas', 'Kentucky', 'NE-3',
'Alabama', 'Tennessee', 'Utah', 'Louisiana', 'Nebraska',
'Mississippi', 'Montana', 'NE-1', 'Indiana', 'Kansas',
'Missouri', 'South Carolina', 'Alaska', 'Ohio', 'Iowa',
'Texas', 'ME-2', 'Florida'
]
# Defining swing state subset of the poll data
swing_until_20 = polls_until_20[polls_until_20['state'].isin(swing_states)]
swing_24 = polls_24[polls_24['state'].isin(swing_states)]Para obter uma visão geral de nossos dados, realizamos algumas análise exploratória de dados (EDA). Primeiro, usamos uma combinação dos métodos .isnull() e .sum() para ver quais colunas cada DataFrame inclui e onde os dados podem estar faltando.
# Checking for missing values in swing_24 and swing_until_20
print(swing_24.isnull().sum())
print(swing_until_20.isnull().sum())candidate 0
date 0
pct_trend_adjusted 4394
state 0
cycle 0
party 0
pct_estimate 0
hi 0
lo 0
dtype: int64
cycle 0
state 0
modeldate 0
candidate_name 0
pct_estimate 0
pct_trend_adjusted 0
dtype: int64Como podemos ver, os nomes das colunas diferem entre os dois DataFrames, e a coluna party parece estar faltando em swing_until_20. Além disso, parece haver dois tipos diferentes de porcentagens medidas: uma porcentagem estimada e uma que foi adicionalmente ajustada à tendência. No entanto, a porcentagem ajustada à tendência parece não estar disponível para os dados de 2024. Investigaremos isso mais tarde.
A seguir, vamos verificar os valores distintos de cada uma de nossas variáveis categóricas:
print('2024 data:')
print(swing_24['date'].min()) # earliest polling date
print(swing_24['date'].max()) # latest polling date
print(swing_24['state'].unique().tolist()) # distinct states
print(swing_24['party'].unique().tolist()) # distinct parties
print(swing_24['candidate'].unique().tolist()) # distinct candidates
print('Historical data:')
print(swing_until_20['modeldate'].min())
print(swing_until_20['modeldate'].max())
print(swing_until_20['state'].unique().tolist())
print(swing_until_20['candidate_name'].unique().tolist())2024 data:
2024-03-01 00:00:00
2024-10-29 00:00:00
['Arizona', 'Georgia', 'Michigan', 'Nevada', 'North Carolina', 'Pennsylvania', 'Wisconsin']
['REP', 'DEM', 'IND']
['Trump', 'Harris', 'Kennedy', 'Biden']
Historical data:
2000-03-02 00:00:00
2020-11-03 00:00:00
['Wisconsin', 'Pennsylvania', 'North Carolina', 'Nevada', 'Michigan', 'Georgia', 'Arizona']
['Joseph R. Biden Jr.', 'Donald Trump', 'Convention Bounce for Joseph R. Biden Jr.', 'Convention Bounce for Donald Trump', 'Hillary Rodham Clinton', 'Gary Johnson', 'Barack Obama', 'Mitt Romney', 'John McCain', 'George W. Bush', 'John Kerry', 'Al Gore', 'Ralph Nader']Embora os dados pareçam bons para estados e datas, há alguns aspectos a serem observados nas colunas relacionadas aos candidatos. Os dados históricos (do ciclo de 2020, mais especificamente) incluem não apenas as porcentagens dos dois candidatos, mas também os saltos da convenção, ou seja, aumentos no apoio após a realização da convenção nacional. Além disso, os nomes próprios parecem estar faltando em swing_24.
Para a nossa investigação dos diferentes tipos de porcentagens, é fundamental remover imediatamente as observações de salto da convenção:
# Only keep rows where candidate_name does not start with 'Convention Bounce'
swing_until_20 = swing_until_20[~swing_until_20['candidate_name'].str.startswith('Convention Bounce')]Para garantir a consistência, o tipo de porcentagem deve ser o mesmo para todos os dados de treinamento e teste. Como descobrimos, apenas os dados até o ciclo eleitoral de 2020 contêm porcentagens estimadas e ajustadas à tendência, enquanto há apenas as estimadas para 2024. Isso nos deixa com duas opções, que são:
A forma como a porcentagem ajustada à tendência foi calculada para os dados históricos não é clara. É por isso que temos que investigar a relação entre as porcentagens estimadas e ajustadas à tendência antes de passar para a limpeza dos dados, pois a escolha da base de dados é crucial para nossas previsões. Primeiro, investigamos a correlação e a diferença média nos dados históricos.
# Checking the correlation between the percentages
adj_corr_swing = swing_until_20['pct_estimate'].corr(swing_until_20['pct_trend_adjusted'])
print('Correlation between estimated and trend-adjusted percentage in swing states: ' + str(adj_corr_swing))
# Calculate the mean difference between pct_estimate and pct_trend_adjusted, grouping by date, state, and party
mean_diff = (swing_until_20['pct_estimate'] - swing_until_20['pct_trend_adjusted']).mean()
print('Mean difference between estimated and trend-adjusted percentage in swing states: ' + str(mean_diff))Correlation between estimated and trend-adjusted percentage in swing states: 0.9953626583357665
Mean difference between estimated and trend-adjusted percentage in swing states: 0.24980898513865013Podemos ver que a correlação entre ambos é extremamente alta (99,5%), como era de se esperar. A diferença média de cerca de 0,25 ponto percentual parece pequena em um primeiro momento, mas pode fazer a diferença em corridas muito acirradas, como as esperadas em Nevada ou Michigan.
Como todos os votos eleitorais em cada estado vão para o vencedor, a ordem entre os candidatos é mais importante do que qualquer porcentagem precisa. O que queremos evitar é uma discrepância perto da data da eleição. Portanto, podemos analisar o número de observações em que o candidato líder entre as duas porcentagens diferiu no último ciclo eleitoral de 2020 e a última data de tal ocorrência.
# Finding out how often pct_estimate and pct_trend_adjusted saw different candidates in the lead in the 2020 race
swing_20 = swing_until_20[swing_until_20['cycle'] == 2020]
# Create a new column to indicate if the ranking is different between pct_estimate and pct_trend_adjusted
swing_20['rank_estimate'] = swing_20.groupby(['state', 'modeldate'])['pct_estimate'].rank(ascending=False)
swing_20['rank_trend_adjusted'] = swing_20.groupby(['state', 'modeldate'])['pct_trend_adjusted'].rank(ascending=False)
# Rows where the rankings are different in swing states
different_rankings_swing = swing_20[swing_20['rank_estimate'] != swing_20['rank_trend_adjusted']]
print('Number of observations with differing leader: ' + str(different_rankings_swing.shape[0] / 2))
print('Last occurrence: ' + str(different_rankings_swing['modeldate'].max()))Number of observations with differing leader: 34.0
Last occurrence: 2020-06-24 00:00:00Aparentemente, a liderança diferiu apenas em 34 casos, ou seja, cerca de 5 dias por estado de oscilação, em média. Como a última ocorrência foi no final de junho, todas as instâncias parecem estar na fase inicial da campanha eleitoral.
Considerando tudo isso, é improvável que os raros casos de mudança de liderança influenciem a precisão geral do modelo, especialmente porque temos um conjunto de dados considerável que abrange vários ciclos. Portanto, escolhi a primeira opção e usei apenas a porcentagem estimada em todos os ciclos eleitorais. Isso garante consistência dos dadosque é fundamental no aprendizado de máquina para evitar que o modelo aprenda vieses introduzidos por diferentes métodos de processamento de dados.
Para adicionar uma coluna para o partido político, primeiro obtemos uma lista de todos os candidatos no conjunto de dados históricos. Em seguida, criamos um dicionário com os candidatos como chaves e o respectivo partido como valor correspondente.ChatGPT é ótimo para isso, para que você economize tempo de pesquisa! Por fim, combinamos ambos em um DataFrame e o mesclamos em swing_until_20.
# Get unique candidate names
candidate_names = swing_until_20['candidate_name'].unique().tolist()
# Create a dictionary of candidates and their political party
party_map = {
'Joseph R. Biden Jr.': 'DEM',
'Donald Trump': 'REP',
'Hillary Rodham Clinton': 'DEM',
'Gary Johnson': 'LIB',
'Barack Obama': 'DEM',
'Mitt Romney': 'REP',
'John McCain': 'REP',
'Ralph Nader': 'IND',
'George W. Bush': 'REP',
'John Kerry': 'DEM',
'Al Gore': 'DEM'
}
# Create a DataFrame with candidates and their respective parties
candidate_df = pd.DataFrame(candidate_names, columns=['candidate_name'])
candidate_df['party'] = candidate_df['candidate_name'].map(party_map)
# Merge the candidate_df with swing_until_20 on 'candidate' column
swing_until_20 = swing_until_20.merge(candidate_df[['candidate_name', 'party']], on='candidate_name', how='left')Agora que adicionamos a coluna do partido ao nosso DataFrame swing_until_20, podemos mesclar os resultados históricos das eleições a ele em uma nova coluna chamada vote_share. Como o arquivo CSV do vote_share estava em um formato diferente, precisamos ajustá-lo ao mesmo formato usado na coluna pct_estimate.
# Merging results_until_20 to swing_until_20
swing_until_20 = pd.merge(swing_until_20, results_until_20, how='left', left_on=['cycle', 'state', 'party', 'candidate_name'], right_on=['cycle', 'state', 'party', 'candidate'])
swing_until_20['vote_share'] = swing_until_20['vote_share'].str.replace(',', '.')
swing_until_20['vote_share'] = pd.to_numeric(swing_until_20['vote_share'])Por fim, renomeamos a coluna modeldate para date, removemos todas as colunas desnecessárias e ajustamos o formato candidate nos dados de 2024 para incluir também os primeiros nomes.
# Renaming columns in swing_until_20
swing_until_20.rename(columns={'modeldate': 'date'}, inplace=True)
# Keeping only relevant columns
swing_24 = swing_24[['cycle', 'date', 'state', 'party', 'candidate', 'pct_estimate']]
swing_until_20 = swing_until_20[['cycle', 'date', 'state', 'party', 'candidate', 'pct_estimate', 'vote_share']]
# Update candidate names in swing_24 dataframe
swing_24['candidate'] = swing_24['candidate'].replace({
'Trump': 'Donald Trump',
'Biden': 'Joseph R. Biden Jr.',
'Harris': 'Kamala Harris',
'Kennedy': 'Robert F. Kennedy'})Vamos dar a você uma visão geral do curso da campanha eleitoral de 2024 até o momento. Usamos os sites seaborn e matplotlib para criar um gráfico de linhas que mostra a progressão média das pesquisas em todos os estados indecisos selecionados. As linhas vermelhas, azuis e pretas mostram as porcentagens de pesquisas de candidatos republicanos, democratas e independentes. As linhas verticais marcam eventos significativos durante a campanha.
import matplotlib.pyplot as plt
import seaborn as sns
# Ensure the date column is in datetime format
swing_24['date'] = pd.to_datetime(swing_24['date'])
# Group by date and party, then average the pct_estimate
swing_24_grouped = swing_24.groupby(['date', 'party'])['pct_estimate'].mean().reset_index()
# Create the line chart
plt.figure(figsize=(14, 8))
sns.lineplot(data=swing_24_grouped, x='date', y='pct_estimate', hue='party', marker='o',
palette={'REP': 'red', 'DEM': 'blue', 'IND': 'black'})
# Add vertical lines for significant events
plt.axvline(pd.to_datetime('2024-07-13'), color='red', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-08-05'), color='blue', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-07-23'), color='blue', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-09-05'), color='black', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-10-01'), color='black', linestyle='--', alpha=0.25)
# Add text annotations for significant events
plt.text(pd.to_datetime('2024-07-13'), plt.ylim()[1] * 0.6, 'Trump Assassination Attempt', color='red', ha='right')
plt.text(pd.to_datetime('2024-07-23'), plt.ylim()[1] * 0.5, 'First Harris Rally', color='blue', ha='right')
plt.text(pd.to_datetime('2024-08-05'), plt.ylim()[1] * 0.4, 'Official Nomination of Harris', color='blue', ha='right')
plt.text(pd.to_datetime('2024-09-05'), plt.ylim()[1] * 0.3, 'Presidential Debate', color='black', ha='right')
plt.text(pd.to_datetime('2024-10-01'), plt.ylim()[1] * 0.2, 'Vice Presidential Debate', color='black', ha='right')
# Add horizontal gridlines at values divisible by 5
plt.yticks(range(0, 51, 5))
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Limit the y-axis range to 50
plt.ylim(0, 50)
# Adjust the legend
plt.legend(title='Party')
# Set titles and labels
plt.title('Average Polling Percentage per Party Over Time in Swing States')
plt.xlabel('Date')
plt.ylabel('Average Polling Percentage')
plt.show()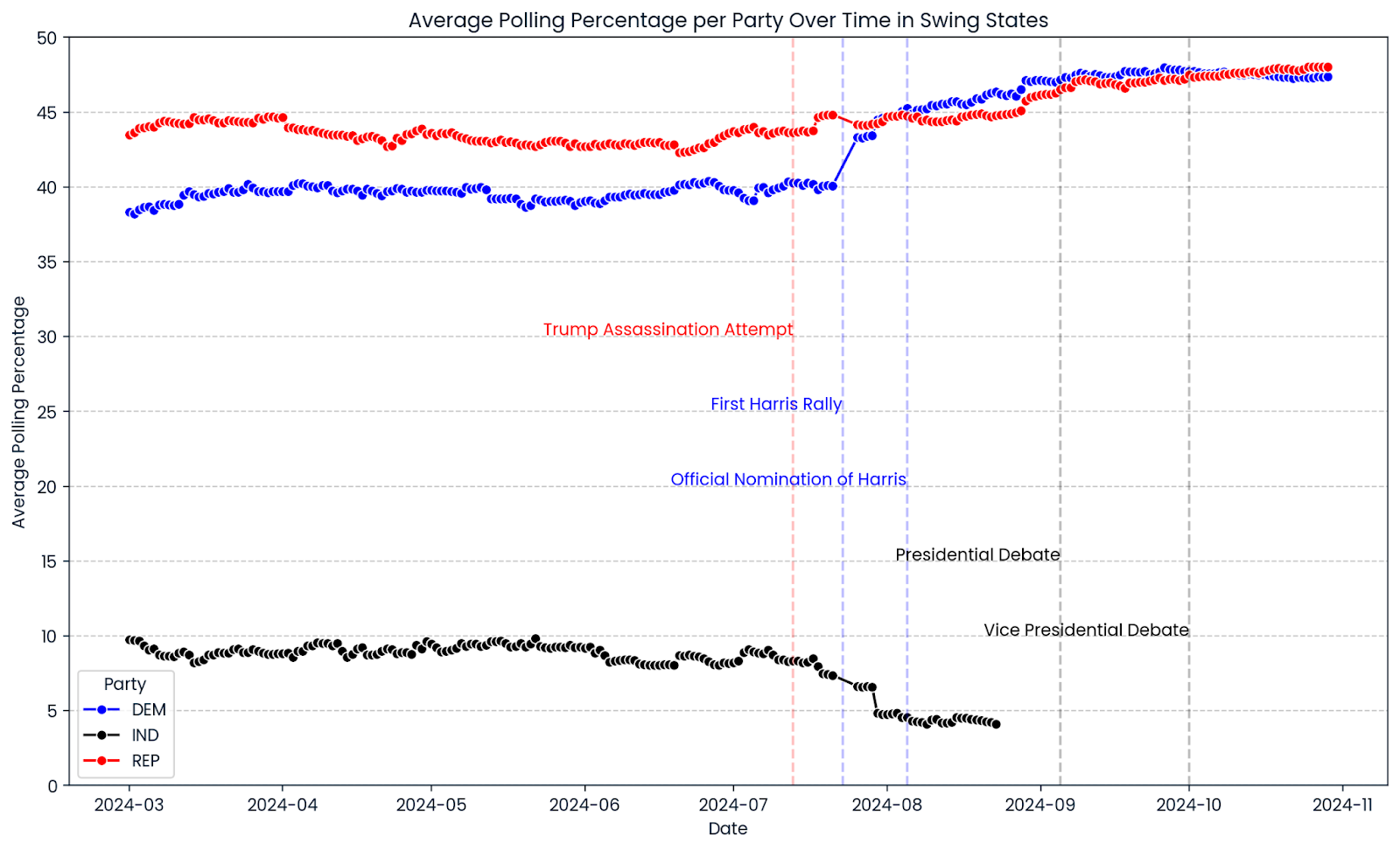
Um primeiro vislumbre da progressão das pesquisas eleitorais de 2024 mostra um estreitamento entre os estados indecisos. A taxa de aprovação de Donald Trump foi relativamente constante durante toda a campanha, com um leve aumento recente. A porcentagem do Partido Democrata continuou a subir depois que Kamala Harris foi oficialmente indicada como candidata à presidência em 5 de agosto de 2024, superando significativamente as pesquisas do ex-candidato e presidente dos Estados Unidos, Joe Biden. De qualquer forma, os gráficos mostram uma imagem de muitas corridas muito próximas para você decidir.
Nesta seção, garantiremos que nossos dados estejam limpos e prontos para nossos modelos de aprendizado de máquina, concentrando-nos em lidar com valores ausentes e entender as distribuições de nossas principais variáveis.
Você ainda precisa verificar se os dados estão na estrutura correta para que os modelos sejam treinados. Primeiro, investigamos se alguma coluna em ambos os conjuntos de dados tem valores ausentes.
# Calculate the number of missing values in each column of swing_until_20
missing_values_until_20 = swing_until_20.isnull().sum()
missing_values_24 = swing_24.isnull().sum()
# Filter out columns that have no missing values
missing_values_until_20 = missing_values_until_20[missing_values_until_20 > 0]
missing_values_24 = missing_values_24[missing_values_24 > 0]
# Display the columns with at least 1 missing value and their respective counts for both dataframes
print(missing_values_until_20, missing_values_24)momentum 84 dtype: int64
momentum 21 dtype: int64O momentum do candidato é a única coluna com valores ausentes. Isso faz sentido, pois é calculado como a diferença diária entre os valores das pesquisas para cada candidato, portanto, esperamos que sua primeira observação seja sem a coluna de momentum. Podemos simplesmente remover os valores ausentes.
# Dropping missing values
swing_24 = swing_24.dropna()
swing_until_20 = swing_until_20.dropna()Observar as distribuições das colunas numéricas nos dará uma ideia se temos alguns outliers ocultos ou se os dados são plausíveis em geral.
Além disso, podemos comparar as pesquisas do ciclo eleitoral de 2024 com a média dos ciclos anteriores. Podemos deixar de fora alguns dos recursos, como pct_opponent e rolling_avg_7d, pois eles resultam basicamente da coluna pct_estimate e se assemelharão basicamente à mesma distribuição.
# Getting description of distributions in both DataFrames
swing_until_20[['pct_estimate', 'lead', 'pct_3rd_party', 'momentum', 'vote_share']].describe()
print(swing_24[['pct_estimate', 'lead', 'pct_3rd_party','momentum']].describe())|
pct_estimate |
chumbo |
pct_3rd_party |
impulso |
vote_share |
|
|
contar |
20504 |
20504 |
20504 |
20504 |
20504 |
|
média |
44.73 |
0.00 |
1.25 |
0.00 |
48.85 |
|
min |
32.65 |
-18.01 |
0.00 |
-8.45 |
40.96 |
|
25% |
42.07 |
-4.94 |
0.00 |
-0.01 |
46.17 |
|
50% |
44.99 |
0.00 |
0.00 |
0.00 |
48.67 |
|
75% |
47.43 |
4.94 |
0.00 |
0.01 |
50.77 |
|
max |
56.47 |
18.01 |
12.67 |
8.45 |
57.97 |
|
std |
3.89 |
6.58 |
2.66 |
0.47 |
3.59 |
|
pct_estimate |
chumbo |
pct_3rd_party |
impulso |
|
|
contar |
3228 |
3228 |
3228 |
3228 |
|
média |
43.53 |
0.00 |
5.87 |
0.00 |
|
min |
35.39 |
-8.77 |
0.00 |
-6.28 |
|
25% |
41.06 |
-2.07 |
0.00 |
-0.12 |
|
50% |
43.76 |
0.00 |
8.01 |
0.00 |
|
75% |
46.56 |
2.07 |
8.91 |
0.12 |
|
max |
48.89 |
8.77 |
12.17 |
6.28 |
|
std |
3.22 |
3.63 |
4.05 |
0.45 |
As distribuições dos recursos nos conjuntos de dados swing_until_20 e swing_24 parecem plausíveis e se alinham com as expectativas de dados de pesquisas eleitorais em estados indecisos.
Os valores de pct_estimate variam entre aproximadamente 33% e 56% historicamente e 35% a 49% em 2024, o que é razoável para eleições competitivas em que nenhum candidato domina de forma esmagadora. O site vote_share no conjunto de dados históricos tem uma média de 48,85%, o que é plausível, já que os estados indecisos geralmente têm divisões próximas de 50-50.
Como era de se esperar, as variáveis lead e momentum estão centradas em uma média de 0 em ambos os conjuntos de dados, indicando que os avanços, atrasos, ganhos e perdas entre os candidatos se equilibram ao longo do tempo. A variável lead parece ter uma distribuição quase perfeitamente normal, enquanto a momentum é pelo menos simétrica, mas tem a maioria dos valores mais próximos da média.
O histórico pct_estimate segue uma distribuição bastante normal com uma leve inclinação para a esquerda, já que a média é, no mínimo, muito próxima da mediana, e o spread captura quantidades típicas de valores dentro de um intervalo razoável.
Nos dados de 2024, as porcentagens das pesquisas estão mais próximas da média. A variável lead tem um desvio padrão menor em 2024 (3,63) em comparação com os dados históricos (6,58), e o intervalo de seus valores é ainda menor do que a metade do histórico. Todos esses são indicadores de que as margens entre os candidatos serão mais estreitas em 2024, o que sugere disputas ainda mais acirradas.
Na maioria dos ciclos, não havia nenhum candidato de terceiro partido reunindo apoio significativo, como podemos ver pelo fato de que mais de 75% das observações têm um valor pct_3rd_party de 0, com a média de 1,25%. Os números altos em 2024 (mediana de 8,01%) refletem o forte apoio que o candidato independente Robert F. Kennedy teve até o final de sua campanha em agosto de 2024.
Nossa estratégia de previsão levará em conta o fato de que as pesquisas não são resultados eleitorais definitivos, mas apenas indicadores do sentimento do público em momentos específicos. Portanto, evitaremos confiar em previsões simples de séries temporais que tratam os dados de pesquisas eleitorais como previsões diretas de resultados. Em vez disso, usaremos uma abordagem baseada em regressão que prevê o resultado da eleição para cada observação de pesquisa individualmente, em vez de prever uma linha do tempo de dados de pesquisa.
Reconhecendo que cada estado tem seu próprio cenário político, criaremos um modelo separado para cada estado de oscilação. Para evitar o vazamento de dados e respeitar a passagem do tempo, garantiremos que nossos modelos sejam testados somente em dados não vistos - especificamente, ciclos eleitorais que ocorram após aqueles nos quais os modelos foram treinados. Essa abordagem nos ajudará a avaliar a capacidade de generalização dos modelos para eleições futuras com precisão.
Escolhi dois critérios de avaliação ao avaliar os modelos preditivos para as cotas de votos eleitorais. Como o vencedor "leva tudo" em cada estado, o número de vencedores previstos corretamente nos ciclos de teste é a medida mais importante a ser considerada.
O MAE (Mean Absolute Error, erro absoluto médio) é o critério de avaliação secundário. Ele mede a magnitude média dos erros entre os valores previstos e reais nas mesmas unidades da variável-alvo - nesse caso, pontos percentuais de participação nos votos. Isso o torna altamente interpretável e diretamente relevante para o nosso contexto, pois nos informa, em média, quantos pontos percentuais nossas previsões se desviam dos resultados reais.
Por fim, treinaremos o melhor modelo de cada estado em todos os ciclos eleitorais até 2020 e o aplicaremos para prever os resultados das eleições de 2024. Usaremos a ponderação baseada no tempo com uma função de decaimento exponencial para transformar as previsões individuais em um único valor preditivo por estado, dando mais importância às pesquisas recentes.
Em primeiro lugar, importamos os pacotes de que precisaremos mais tarde. Isso inclui todos os modelos que avaliaremos, NumPy, bem como o mean_absolute_error.
# Importing models
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression, Ridge, ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.svm import SVR
import catboost
import xgboost as xgb
# Importing other necessary libraries
from sklearn.metrics import mean_absolute_error
import numpy as npVamos criar um fluxo de trabalho para treinar e avaliar os modelos básicos! Analisaremos o processo passo a passo e o aplicaremos a cada estado para cada ciclo de teste, começando em 2004.
Para adaptar nossos modelos às características exclusivas de cada estado, começamos filtrando o conjunto de dados para incluir apenas os dados relevantes para o estado em análise. Isso garante que o modelo capture padrões de votação e dados de pesquisa específicos do estado.
# Filter data for the state you're analyzing
data_state = swing_until_20[swing_until_20['state'] == state].copy()Em seguida, definimos uma função de peso para atribuir mais importância às pesquisas realizadas mais perto da data da eleição. Essa função de decaimento exponencial diminui o peso das pesquisas à medida que elas se distanciam da eleição, enfatizando a relevância dos dados de pesquisas recentes.
# Define the weight function (using a typical starting k value)
def compute_weight(days_until_election, k):
return np.exp(-k * days_until_election)
# Add weights to the data
data_state['weight'] = compute_weight(data_state['days_until_election'], k=0.1)Em seguida, dividimos os dados em conjuntos de treinamento e teste com base nos ciclos eleitorais, garantindo que treinemos em eleições passadas e testemos em eleições futuras para evitar o vazamento de dados. Você verá a definição de train_cycles e test_cycle mais tarde, quando dermos a volta no ciclo eleitoral. Também definimos os recursos que serão usados para a previsão e extraímos a variável de destino, que é a participação real nos votos.
# Split data into training and testing sets based on election cycles
train_data = data_state[data_state['cycle'].isin(train_cycles)]
test_data = data_state[data_state['cycle'] == test_cycle]
# Define features and target variable
features = ['pct_estimate', 'pct_opponent', 'pct_3rd_party', 'lead', 'rolling_avg_7d',
'days_until_election', 'momentum_candidate', 'momentum_opponent', 'momentum',
'is_incumbent_president', 'is_incumbent_vice_president', 'is_incumbent_party',
'candidate_Donald Trump',
'party_DEM', 'party_REP']
X_train = train_data[features]
y_train = train_data['vote_share']
X_test = test_data[features]
y_test = test_data['vote_share']Definimos uma variedade de modelos de aprendizado de máquina para avaliar, incluindo regressão linear, métodos de conjunto, máquinas de vetor de suporte e redes neurais. Esse conjunto diversificado nos permite comparar diferentes algoritmos e selecionar o modelo com melhor desempenho para cada estado.
# Models to evaluate
models = {
'LinearRegression': LinearRegression(),
'XGBoost': xgb.XGBRegressor(objective='reg:absoluteerror', n_estimators=100, random_state=42),
'CatBoost': catboost.CatBoostRegressor(loss_function='MAE', iterations=100, random_seed=42, verbose=0),
'RandomForest': RandomForestRegressor(n_estimators=100, random_state=42),
'SVR': SVR(kernel='rbf', C=1.0, epsilon=0.1),
'KNeighbors': KNeighborsRegressor(n_neighbors=5),
'MLPRegressor': MLPRegressor(hidden_layer_sizes=(100,), max_iter=500, random_state=42),
'ElasticNet': ElasticNet(alpha=1.0, l1_ratio=0.5, random_state=42),
}A seguir, você verá o dicionário models. Para cada modelo, nós o treinamos usando o conjunto de dados de treinamento específico para o estado atual e, em seguida, fazemos previsões no conjunto de dados de teste. Esse processo é repetido para cada modelo para avaliar seu desempenho comparativamente.
for model_name, model in models.items():
# Train the model
model.fit(X_train, y_train)
# Predict on test data
test_data[f'predicted_{model_name}'] = model.predict(X_test)No loop do modelo, agregamos as previsões individuais de cada partido usando uma função lambda que aplica os pesos calculados anteriormente. Isso resulta em uma única parcela de votos prevista por partido, que depois comparamos com a parcela de votos real para avaliar a precisão do modelo.
# Aggregate predictions using weights
aggregated_predictions = test_data.groupby('party').apply(
lambda df: np.average(df[f'predicted_{model_name}'], weights=df['weight'])
).reset_index(name='aggregated_prediction')
# Get actual vote shares for comparison
actual_vote_shares = test_data.groupby('party')['vote_share'].mean().reset_index()
comparison = pd.merge(aggregated_predictions, actual_vote_shares, on='party')
comparison.rename(columns={'vote_share': 'actual_vote_share'}, inplace=True)Para finalizar o loop do modelo, calculamos o erro absoluto médio (MAE) entre as previsões agregadas e as participações reais nos votos para quantificar o desempenho do modelo. Também determinamos se o modelo previu corretamente o partido vencedor no estado e armazenamos esses resultados para análise posterior.
# Calculate Mean Absolute Error
mae = mean_absolute_error(comparison['actual_vote_share'], comparison['aggregated_prediction'])
# Check if the predicted winner matches the actual winner
predicted_winner = comparison.loc[comparison['aggregated_prediction'].idxmax(), 'party']
actual_winner = comparison.loc[comparison['actual_vote_share'].idxmax(), 'party']
correct_winner = int(predicted_winner == actual_winner)
# Store the results
results_list.append({
'state': state,
'model_name': model_name,
'test_cycle': test_cycle,
'MAE': mae,
'correct_winner': correct_winner
})Todo esse processo está envolvido em dois loops: o loop externo itera sobre cada ciclo eleitoral (excluindo o primeiro, pois não há dados anteriores para treinar) e o loop interno itera sobre cada estado de oscilação. Ao fazer isso, garantimos que os modelos sejam treinados e testados adequadamente para cada estado e ciclo eleitoral, respeitando a ordem cronológica das eleições para evitar o vazamento de dados.
O prefácio do código acima tem a seguinte aparência:
# Initialize a list to store results
results_list = []
# Define the election cycles
cycles = [2000, 2004, 2008, 2012, 2016, 2020]
for i in range(1, len(cycles)): # The loop starts at index 1, so with the 2nd cycle (2004)
test_cycle = cycles[i]
train_cycles = cycles[:i] # train_cycles = all cycles before the test_cycle
for state in swing_states:
# Filter data for the state you're analyzing, etc. …Em geral, essa estratégia nos permite avaliar vários modelos em diferentes estados e ciclos eleitorais, selecionando, por fim, o modelo de melhor desempenho para cada estado com base na precisão da previsão e na capacidade de prever corretamente o vencedor da eleição.
Depois de treinar e testar vários modelos de aprendizado de máquina em diferentes estados e ciclos eleitorais, passamos a avaliar seu desempenho para identificar os melhores modelos para cada estado. Essa avaliação se concentra em duas métricas principais: o número de vezes que cada modelo previu corretamente o partido vencedor (correct_winner) e o erro médio absoluto (MAE) de suas previsões.
Primeiro, compilamos todos os resultados coletados durante as avaliações do modelo em um único DataFrame e agregamos as métricas de desempenho:
# After the loop, create a DataFrame from the results list
results_df = pd.DataFrame(results_list)
# Get the sum of correct_winner and the average MAE for every combination of state and model_name
aggregated_evaluation = results_df.groupby(['state', 'model_name']).agg({
'correct_winner': 'sum',
'MAE': 'mean'
}).reset_index()
# Display the maximum number of correct winner predictions and the minimum MAE for each state
print(aggregated_evaluation.groupby('state')['correct_winner'].max())
print(aggregated_evaluation.groupby('state')['MAE'].min())|
estado |
Máximo de vencedor_correto |
MAE mínimo |
|
Arizona |
5 |
1.248966 |
|
Geórgia |
5 |
0.770760 |
|
Michigan |
4 |
2.685870 |
|
Nevada |
5 |
2.079582 |
|
Carolina do Norte |
5 |
0.917522 |
|
Pensilvânia |
4 |
2.027426 |
|
Wisconsin |
4 |
2.462907 |
Isso não parece tão ruim! Em todos os estados, houve pelo menos um modelo que previu corretamente 4 das 5 eleições anteriores. Em quatro dos estados (Arizona, Geórgia, Nevada e Carolina do Norte), conseguimos até mesmo alguns modelos que previram o vencedor correto em cada ciclo. No entanto, os resultados para o MAE mais baixo têm, em parte, espaço para melhorias e diferem bastante entre os estados, com uma média de 1,74 pontos percentuais e variando de 0,77 na Geórgia a 2,69 em Michigan.
Com essas informações agregadas, prosseguimos para selecionar o modelo de melhor desempenho para cada estado. Classificamos os modelos com base em sua capacidade de prever o vencedor correto primeiro e somente depois em seu MAE. Os modelos escolhidos são salvos no dicionário best_models.
# Sort the models for each state by correct_winner (descending) and then by MAE (ascending)
sorted_evaluation = aggregated_evaluation.sort_values(by=['state', 'correct_winner', 'MAE'], ascending=[True, False, True])
# Create a dictionary to store the best model for each state
best_models = {}
# Iterate over each state and get the top model
for state in sorted_evaluation['state'].unique():
top_model = sorted_evaluation[sorted_evaluation['state'] == state].iloc[0]
best_models[state] = top_model['model_name']
best_models{'Arizona': 'RandomForest',
'Georgia': 'ElasticNet',
'Michigan': 'LinearRegression',
'Nevada': 'KNeighbors',
'North Carolina': 'CatBoost',
'Pennsylvania': 'KNeighbors',
'Wisconsin': 'MLPRegressor'}Os principais modelos para cada estado variam muito, refletindo os padrões de votação e os comportamentos de pesquisa exclusivos de cada região. Surpreendentemente, em Michigan, os melhores resultados foram obtidos com o uso da regressão linear, indicando que uma abordagem linear mais simples pode ser suficiente nesse caso.
Nesse ponto, podemos usar o ajuste de hiperparâmetros para otimizar o desempenho de cada modelo de aprendizado de máquina. Como isso introduziria outras questões metodológicas e exigiria grandes ajustes no código, está fora do escopo deste tutorial, que já é bastante longo. Os resultados dos modelos básicos já parecem promissores o suficiente para você ousar e prever os resultados das eleições de 2024.
Na etapa final de nossa análise, utilizamos os modelos de melhor desempenho para cada estado decisivo para prever os resultados das eleições de 2024. Começamos inicializando uma lista vazia para armazenar nossas previsões.
Para cada estado e seu melhor modelo correspondente de nossas avaliações anteriores, usamos o mesmo fluxo de trabalho de antes. Só que, desta vez, não precisamos percorrer os ciclos eleitorais, mas treinar com todos os dados históricos de 2000 a 2020 (swing_until_20 ).
# Initialize a list to store predictions
predictions_list = []
for state, model_name in best_models.items():
# Filter the data for the specific state
state_data_train = swing_until_20[swing_until_20['state'] == state].copy() # Data from 2000 to 2020
state_data_test = swing_24[swing_24['state'] == state].copy() # Data for 2024
# Add weights to the test data
state_data_test['weight'] = compute_weight(state_data_test['days_until_election'], k=0.1)
# Define features
features = [
'pct_estimate',
'pct_opponent',
'pct_3rd_party',
'lead',
'rolling_avg_7d',
'days_until_election',
'momentum_candidate',
'momentum_opponent',
'momentum',
'is_incumbent_president',
'is_incumbent_vice_president',
'is_incumbent_party',
'candidate_Donald Trump',
'party_DEM',
'party_REP'
]
# Split features and target variable
X_train = state_data_train[features]
y_train = state_data_train['vote_share']
X_test = state_data_test[features]
# Train the model on the 2000 to 2020 data
model.fit(X_train, y_train)
# Predict on the 2024 data
state_data_test['predicted_vote_share'] = model.predict(X_test)
# Aggregate predictions using weights
aggregated_predictions = state_data_test.groupby('party').apply(
lambda df: np.average(df['predicted_vote_share'], weights=df['weight'])
).reset_index(name='aggregated_prediction')
# Append predictions to the list
for _, pred_row in aggregated_predictions.iterrows():
predictions_list.append({
'state': state,
'party': pred_row['party'],
'predicted_vote_share': pred_row['aggregated_prediction'],
'model': model_name
})Depois de prever a coluna vote_share, agregar as previsões usando a função de peso que definimos anteriormente e anexar as previsões a predictions_list, consolidamos as previsões finais em um DataFrame. Além disso, adicionamos uma classificação para cada estado e dinamizamos as previsões por estado. Aqui estão as previsões feitas por nossos modelos:
# Convert predictions list to DataFrame
predictions_df = pd.DataFrame(predictions_list)
# Add a rank to predictions_df for each state based on the order of predicted_vote_share
predictions_df['rank'] = predictions_df.groupby('state')['predicted_vote_share'].rank(ascending=False)
# Create a pivot table indexed by state
predictions_pivot = predictions_df.pivot(index='state', columns='party', values='predicted_vote_share')
# Display predictions
print("\n2024 Vote Share Predictions:")
predictions_pivot2024 Vote Share Predictions:
state
DEM
REP
Arizona
49.02
50.31
Georgia
48.95
50.08
Michigan
50.34
48.64
Nevada
49.41
48.54
North Carolina
48.95
50.06
Pennsylvania
49.57
49.20
Wisconsin
49.66
49.41As previsões confirmam nossa estimativa de uma disputa muito acirrada nos estados decisivos. Nossos modelos preveem que quatro estados darão seu voto majoritário para Kamala Harris (Michigan, Nevada, Pensilvânia, Wisconsin) e três para Donald Trump (Arizona, Geórgia, Carolina do Norte). Espera-se que os estados da Pensilvânia e Wisconsin sejam especialmente apertados, com a diferença entre as duas previsões de votos sendo de apenas 0,37 ponto percentual, respectivamente, 0,25 ponto percentual.
Conforme mencionado anteriormente, presumimos que todos os outros estados votam no candidato que se espera que vença, ou seja, os estados "azuis" votam em Kamala Harris e os estados "vermelhos" votam em Donald Trump. Para avaliar quantos votos eleitorais cada candidato recebe, definimos um dicionário que atribui a cada estado e distrito seu número de votos e combinamos as informações em um DataFrame chamado electoral_votes_df.
# Define the number of electoral votes per state for the 2024 US-Presidential elections
electoral_votes = {
'Alabama': 9, 'Alaska': 3, 'Arizona': 11, 'Arkansas': 6, 'California': 54,
'Colorado': 10, 'Connecticut': 7, 'Delaware': 3, 'District of Columbia': 3,
'Florida': 30, 'Georgia': 16, 'Hawaii': 4, 'Idaho': 4, 'Illinois': 19,
'Indiana': 11, 'Iowa': 6, 'Kansas': 6, 'Kentucky': 8, 'Louisiana': 8,
'Maine': 2, 'Maryland': 10, 'Massachusetts': 11, 'Michigan': 15,
'Minnesota': 10, 'Mississippi': 6, 'Missouri': 10, 'Montana': 4,
'Nebraska': 2, 'Nevada': 6, 'New Hampshire': 4, 'New Jersey': 14,
'New Mexico': 5, 'New York': 28, 'North Carolina': 16, 'North Dakota': 3,
'Ohio': 17, 'Oklahoma': 7, 'Oregon': 8, 'Pennsylvania': 19,
'Rhode Island': 4, 'South Carolina': 9, 'South Dakota': 3,
'Tennessee': 11, 'Texas': 40, 'Utah': 6, 'Vermont': 3, 'Virginia': 13,
'Washington': 12, 'West Virginia': 4, 'Wisconsin': 10, 'Wyoming': 3
}
# Create a DataFrame from the dictionary
electoral_votes_df = pd.DataFrame(list(electoral_votes.items()), columns=['State', 'Electoral Votes'])
# Handle states that divide their votes into multiple districts (Maine and Nebraska)
districts = {'ME-1': 1, 'ME-2': 1, 'NE-1': 1, 'NE-2': 1, 'NE-3': 1}
# Add the districts to the DataFrame
districts_df = pd.DataFrame(list(districts.items()), columns=['State', 'Electoral Votes'])
# Combine the two DataFrames
electoral_votes_df = pd.concat([electoral_votes_df, districts_df], ignore_index=True)Em seguida, criamos duas listas, harris e trump, que contêm os estados azuis e vermelhos, respectivamente, juntamente com os estados indecisos previstos para serem conquistados por cada candidato. Na próxima etapa, podemos filtrar electoral_votes_df para os estados em cada lista e calcular a soma dos votos eleitorais esperados para cada candidato.
# Extract states from predictions_df where party is DEM and rank is 1
additional_blue_states = predictions_df[
(predictions_df['party'] == 'DEM') & (predictions_df['rank'] == 1)
].state.tolist()
# Extract states from predictions_df where party is REP and rank is 1
additional_red_states = predictions_df[
(predictions_df['party'] == 'REP') & (predictions_df['rank'] == 1)
].state.tolist()
# Combine blue_states and additional_blue_states into a single list
harris = list(set(blue_states + additional_blue_states))
trump = list(set(red_states + additional_red_states))
# Filter the electoral votes for states in each candidate's list
harris_electoral_votes = electoral_votes_df[electoral_votes_df['state'].isin(harris)]
trump_electoral_votes = electoral_votes_df[electoral_votes_df['state'].isin(trump)]
# Sum the electoral votes
sum_harris_electoral_votes = harris_electoral_votes['electoral_votes'].sum()
sum_trump_electoral_votes = trump_electoral_votes['electoral_votes'].sum()
print(
f'According to the predictions made by the machine learning models, '
f'Kamala Harris will win {sum_harris_electoral_votes} electoral votes '
f'and Donald Trump will win {sum_trump_electoral_votes} electoral votes.'
)According to the predictions made by the machine learning models, Kamala Harris will win 276 electoral votes and Donald Trump will win 262 electoral votes.A previsão é de que Kamala Harris ganhe 276 votos eleitorais e Donald Trump ganhe 262 votos eleitorais. Se nossas suposições e previsões se confirmassem, o mapa eleitoral seria assim em 5 de novembro:
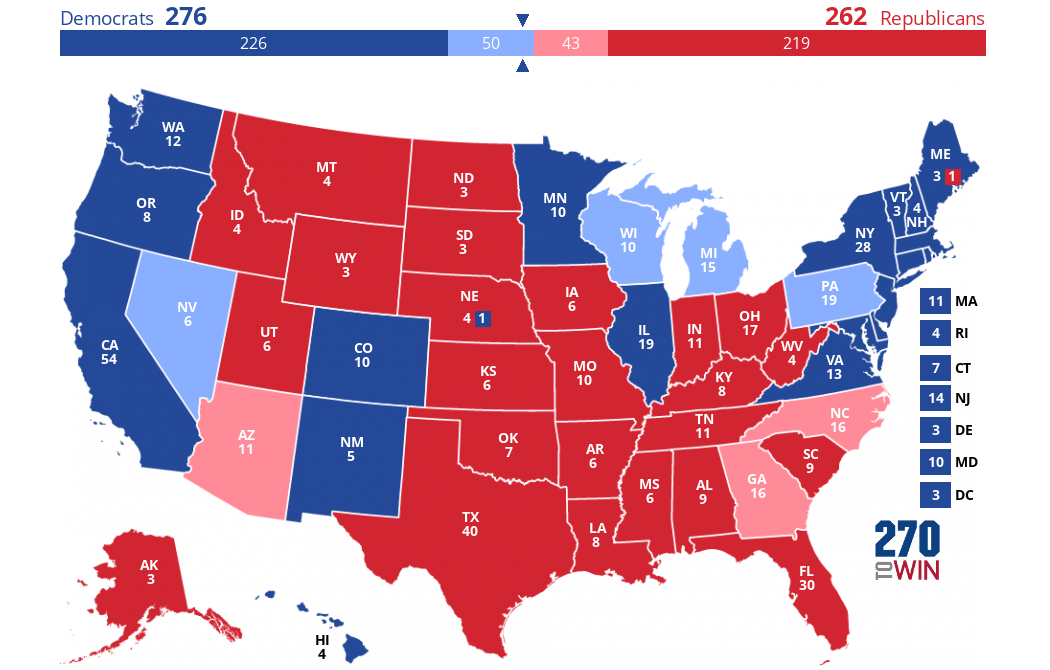
Criado usando este criador de mapas interativos.
As cores escuras representam o que presumimos ser estados "azuis" ou "vermelhos". Os estados decisivos previstos por nós fazem a diferença - eles são coloridos em um azul ou vermelho mais claro.
Neste projeto, usamos dados históricos de pesquisas de opinião para prever o resultado da eleição presidencial de 2024 nos EUA. Como esperado, nossos modelos indicam uma disputa acirrada entre os principais candidatos.
É importante ter em mente que nossa análise se baseou apenas em dados de pesquisas eleitorais, que às vezes se mostraram imprecisas no passado e não capturam todas as nuances de uma eleição. Fatores como metodologias de pesquisa, comparecimento dos eleitores, dinâmica de campanha, circunstâncias econômicas e demográficas e eventos imprevistos não foram considerados em nossos modelos, mas podem afetar significativamente os resultados reais.
No entanto, essa exploração mostra o potencial da análise preditiva na compreensão de sistemas complexos como as eleições. Se você estiver interessado em aprender mais sobre análise preditiva usando Python, recomendo estes recursos:
Aprenda aprendizado de máquina com estes cursos!
Programa
blog
DataCamp Team
6 min
Tutorial
Thushan Ganegedara
Tutorial
Moez Ali