programa
Aprendizaje automático supervisado en Python
25 h
Los datos utilizados para nuestra predicción proceden de FiveThirtyEightque recoge datos de todo tipo de encuestadores. Los datos están disponibles en GitHub para todos los ciclos electorales desde 1968.
Utilizaremos su modelo de sondeo, que asigna el porcentaje medio de sondeo para cada candidato en cada estado para (casi) cada fecha dada en los ocho meses previos a las elecciones.
Empezaremos importando los datos de las encuestas de 2024, 2020 e históricas desde archivos CSV. Los datos de 2024 se filtran sólo con las encuestas del ciclo actual, y los datos históricos hasta 2016 se concatenan con los de 2020. En los dos DataFrames resultantes, polls_24 y polls_until_20, las columnas de fecha se convierten a un formato datetime para garantizar la coherencia, y se mantienen las columnas relevantes como el ciclo, el estado, el nombre del candidato y las estimaciones de las encuestas.
import pandas as pd
# Reading CSV files
polls_24 = pd.read_csv('presidential_general_averages.csv')
polls_20 = pd.read_csv('presidential_poll_averages_2020.csv')
polls_until_16 = pd.read_csv('pres_pollaverages_1968-2016.csv')
# Filtering and concatenating DataFrames
polls_24 = polls_24[polls_24['cycle'] == 2024]
polls_until_20 = pd.concat([polls_20, polls_until_16], ignore_index=True)
# Making sure dates are in datetime format
polls_24['date'] = pd.to_datetime(polls_24['date'], format='%Y-%m-%d')
polls_until_20['modeldate'] = pd.to_datetime(polls_until_20['modeldate'])
# Keeping only the columns of interest
polls_until_20 = polls_until_20[['cycle', 'state', 'modeldate', 'candidate_name', 'pct_estimate', 'pct_trend_adjusted']]Para los resultados reales de la votación por estado, tomé los datos directamente de la Comisión Electoral Federal de EEUU. Para simplificar, los he resumido previamente en un archivo CSV.
Una observación representa la combinación de ciclo electoral, estado y partido, cada una completada con el nombre del candidato respectivo y, por supuesto, el porcentaje de votos que obtuvo dicho candidato.
# Importing result data
results_until_20 = pd.read_csv('results.csv', sep=';')
results_until_20 = results_until_20[['cycle', 'state', 'party', 'candidate', 'vote_share']]Para garantizar que trabajamos con datos relevantes y de alta calidad, he aplicado dos restricciones clave:
swing_states, blue_states y red_states en consecuencia, y creamos subconjuntos de datos para los estados indecisos.# Implementing cycle restriction
start_cycle = 2000
polls_until_20 = polls_until_20[polls_until_20['cycle'] >= start_cycle]
# Defining state lists
swing_states = [
'Pennsylvania', 'Wisconsin', 'Michigan', 'Georgia',
'North Carolina', 'Arizona', 'Nevada'
]
blue_states = [
'District of Columbia', 'Vermont', 'Massachusetts', 'Maryland',
'Hawaii', 'California', 'ME-1', 'Connecticut', 'Washington',
'Delaware', 'Rhode Island', 'New York', 'Illinois', 'New Jersey',
'Oregon', 'Colorado', 'Maine', 'New Mexico', 'Virginia',
'New Hampshire', 'NE-2', 'Minnesota'
]
red_states = [
'Wyoming', 'West Virginia', 'Oklahoma', 'North Dakota',
'Idaho', 'South Dakota', 'Arkansas', 'Kentucky', 'NE-3',
'Alabama', 'Tennessee', 'Utah', 'Louisiana', 'Nebraska',
'Mississippi', 'Montana', 'NE-1', 'Indiana', 'Kansas',
'Missouri', 'South Carolina', 'Alaska', 'Ohio', 'Iowa',
'Texas', 'ME-2', 'Florida'
]
# Defining swing state subset of the poll data
swing_until_20 = polls_until_20[polls_until_20['state'].isin(swing_states)]
swing_24 = polls_24[polls_24['state'].isin(swing_states)]Para obtener una visión general de nuestros datos, realizamos algunos análisis exploratorio de datos (AED). En primer lugar, utilizamos una combinación de los métodos .isnull() y .sum() para ver qué columnas incluye cada DataFrame y dónde pueden faltar datos.
# Checking for missing values in swing_24 and swing_until_20
print(swing_24.isnull().sum())
print(swing_until_20.isnull().sum())candidate 0
date 0
pct_trend_adjusted 4394
state 0
cycle 0
party 0
pct_estimate 0
hi 0
lo 0
dtype: int64
cycle 0
state 0
modeldate 0
candidate_name 0
pct_estimate 0
pct_trend_adjusted 0
dtype: int64Como podemos ver, los nombres de las columnas difieren entre los dos DataFrames, y la columna party parece faltar en swing_until_20. Además, parece haber dos tipos diferentes de porcentajes medidos: un porcentaje estimado y otro que además se ajustó a la tendencia. Sin embargo, el porcentaje ajustado a la tendencia parece no estar disponible para los datos de 2024. Lo investigaremos más adelante.
Comprobemos a continuación los valores distintos de cada una de nuestras variables categóricas:
print('2024 data:')
print(swing_24['date'].min()) # earliest polling date
print(swing_24['date'].max()) # latest polling date
print(swing_24['state'].unique().tolist()) # distinct states
print(swing_24['party'].unique().tolist()) # distinct parties
print(swing_24['candidate'].unique().tolist()) # distinct candidates
print('Historical data:')
print(swing_until_20['modeldate'].min())
print(swing_until_20['modeldate'].max())
print(swing_until_20['state'].unique().tolist())
print(swing_until_20['candidate_name'].unique().tolist())2024 data:
2024-03-01 00:00:00
2024-10-29 00:00:00
['Arizona', 'Georgia', 'Michigan', 'Nevada', 'North Carolina', 'Pennsylvania', 'Wisconsin']
['REP', 'DEM', 'IND']
['Trump', 'Harris', 'Kennedy', 'Biden']
Historical data:
2000-03-02 00:00:00
2020-11-03 00:00:00
['Wisconsin', 'Pennsylvania', 'North Carolina', 'Nevada', 'Michigan', 'Georgia', 'Arizona']
['Joseph R. Biden Jr.', 'Donald Trump', 'Convention Bounce for Joseph R. Biden Jr.', 'Convention Bounce for Donald Trump', 'Hillary Rodham Clinton', 'Gary Johnson', 'Barack Obama', 'Mitt Romney', 'John McCain', 'George W. Bush', 'John Kerry', 'Al Gore', 'Ralph Nader']Aunque los datos tienen buen aspecto para los estados y las fechas, hay que fijarse en algunas cosas sobre las columnas relacionadas con los candidatos. Los datos históricos (los del ciclo 2020 más concretamente) incluyen no sólo los porcentajes de los dos candidatos, sino también los rebotes de la convención, es decir, los aumentos de apoyo tras celebrar su convención nacional. Además, los nombres de pila parecen faltar en swing_24.
Para nuestra investigación de los distintos tipos de porcentajes, es crucial eliminar inmediatamente las observaciones de rebote de la convención:
# Only keep rows where candidate_name does not start with 'Convention Bounce'
swing_until_20 = swing_until_20[~swing_until_20['candidate_name'].str.startswith('Convention Bounce')]Para garantizar la coherencia, el tipo de porcentaje tiene que ser el mismo para todos los datos de entrenamiento y de prueba. Como hemos descubierto, sólo los datos hasta el ciclo electoral de 2020 contienen tanto los porcentajes estimados como los ajustados a la tendencia, mientras que sólo existen los estimados para 2024. Eso nos deja dos opciones, que son:
No está claro cómo se calculó el porcentaje ajustado a la tendencia para los datos históricos. Por eso tenemos que investigar la relación entre los porcentajes estimados y los ajustados a la tendencia antes de pasar a la limpieza de datos, ya que la elección de la base de datos es crucial para nuestras predicciones. En primer lugar, investigamos la correlación y la diferencia media en los datos históricos.
# Checking the correlation between the percentages
adj_corr_swing = swing_until_20['pct_estimate'].corr(swing_until_20['pct_trend_adjusted'])
print('Correlation between estimated and trend-adjusted percentage in swing states: ' + str(adj_corr_swing))
# Calculate the mean difference between pct_estimate and pct_trend_adjusted, grouping by date, state, and party
mean_diff = (swing_until_20['pct_estimate'] - swing_until_20['pct_trend_adjusted']).mean()
print('Mean difference between estimated and trend-adjusted percentage in swing states: ' + str(mean_diff))Correlation between estimated and trend-adjusted percentage in swing states: 0.9953626583357665
Mean difference between estimated and trend-adjusted percentage in swing states: 0.24980898513865013Podemos ver que la correlación entre ambas es extremadamente alta (99,5%), como cabía esperar. La diferencia media de unos 0,25 puntos porcentuales parece pequeña a primera vista, pero podría marcar la diferencia en contiendas muy reñidas, como las que se esperan en Nevada o Michigan.
Dado que todos los votos electorales de cada estado van al ganador, el orden entre los candidatos es más importante que cualquier porcentaje preciso. Lo que queremos evitar es una discrepancia cerca de la fecha de las elecciones. Por tanto, podemos observar el número de observaciones en las que el candidato principal entre los dos porcentajes difirió en el último ciclo electoral de 2020 y la última fecha en la que se produjo tal hecho.
# Finding out how often pct_estimate and pct_trend_adjusted saw different candidates in the lead in the 2020 race
swing_20 = swing_until_20[swing_until_20['cycle'] == 2020]
# Create a new column to indicate if the ranking is different between pct_estimate and pct_trend_adjusted
swing_20['rank_estimate'] = swing_20.groupby(['state', 'modeldate'])['pct_estimate'].rank(ascending=False)
swing_20['rank_trend_adjusted'] = swing_20.groupby(['state', 'modeldate'])['pct_trend_adjusted'].rank(ascending=False)
# Rows where the rankings are different in swing states
different_rankings_swing = swing_20[swing_20['rank_estimate'] != swing_20['rank_trend_adjusted']]
print('Number of observations with differing leader: ' + str(different_rankings_swing.shape[0] / 2))
print('Last occurrence: ' + str(different_rankings_swing['modeldate'].max()))Number of observations with differing leader: 34.0
Last occurrence: 2020-06-24 00:00:00Aparentemente, la ventaja sólo difería en 34 casos, es decir, unos 5 días por estado indeciso de media. Como el último suceso es de finales de junio, todos los casos parecen estar en la fase inicial de la campaña electoral.
Teniendo en cuenta todo esto, es poco probable que los raros casos de cambio de liderazgo influyan en la precisión general del modelo, especialmente si tenemos un conjunto de datos considerable que abarca varios ciclos. Por tanto, elegí la primera opción y sólo utilicé el porcentaje estimado a lo largo de todos los ciclos electorales. Esto garantiza coherencia de los datosque es clave en el aprendizaje automático para evitar que el modelo aprenda sesgos introducidos por distintos métodos de procesamiento de datos.
Para añadir una columna para el partido político, primero obtenemos una lista de todos los candidatos del conjunto de datos históricos. A continuación, creamos un diccionario con los candidatos como claves y el partido respectivo como valor correspondiente-.ChatGPT es ideal para ahorrar tiempo de investigación. Por último, combinamos ambos en un DataFrame, y lo fusionamos en swing_until_20.
# Get unique candidate names
candidate_names = swing_until_20['candidate_name'].unique().tolist()
# Create a dictionary of candidates and their political party
party_map = {
'Joseph R. Biden Jr.': 'DEM',
'Donald Trump': 'REP',
'Hillary Rodham Clinton': 'DEM',
'Gary Johnson': 'LIB',
'Barack Obama': 'DEM',
'Mitt Romney': 'REP',
'John McCain': 'REP',
'Ralph Nader': 'IND',
'George W. Bush': 'REP',
'John Kerry': 'DEM',
'Al Gore': 'DEM'
}
# Create a DataFrame with candidates and their respective parties
candidate_df = pd.DataFrame(candidate_names, columns=['candidate_name'])
candidate_df['party'] = candidate_df['candidate_name'].map(party_map)
# Merge the candidate_df with swing_until_20 on 'candidate' column
swing_until_20 = swing_until_20.merge(candidate_df[['candidate_name', 'party']], on='candidate_name', how='left')Ahora que hemos añadido la columna del partido a nuestro swing_until_20 DataFrame, podemos unirle los resultados electorales históricos en una nueva columna llamada vote_share. Como el archivo CSV del vote_share estaba en un formato diferente, tenemos que ajustarlo al mismo utilizado en la columna pct_estimate.
# Merging results_until_20 to swing_until_20
swing_until_20 = pd.merge(swing_until_20, results_until_20, how='left', left_on=['cycle', 'state', 'party', 'candidate_name'], right_on=['cycle', 'state', 'party', 'candidate'])
swing_until_20['vote_share'] = swing_until_20['vote_share'].str.replace(',', '.')
swing_until_20['vote_share'] = pd.to_numeric(swing_until_20['vote_share'])Por último, cambiamos el nombre de la columna modeldate a date, eliminamos todas las columnas innecesarias y ajustamos el formato candidate en los datos de 2024 para incluir también los nombres de pila.
# Renaming columns in swing_until_20
swing_until_20.rename(columns={'modeldate': 'date'}, inplace=True)
# Keeping only relevant columns
swing_24 = swing_24[['cycle', 'date', 'state', 'party', 'candidate', 'pct_estimate']]
swing_until_20 = swing_until_20[['cycle', 'date', 'state', 'party', 'candidate', 'pct_estimate', 'vote_share']]
# Update candidate names in swing_24 dataframe
swing_24['candidate'] = swing_24['candidate'].replace({
'Trump': 'Donald Trump',
'Biden': 'Joseph R. Biden Jr.',
'Harris': 'Kamala Harris',
'Kennedy': 'Robert F. Kennedy'})Hagamos un repaso de lo que ha sido hasta ahora la campaña electoral de 2024. Utilizamos seaborn y matplotlib para crear un gráfico de líneas que muestre la progresión media de las encuestas en todos los estados indecisos seleccionados. Las líneas rojas, azules y negras muestran los porcentajes en las encuestas de los candidatos republicanos, demócratas e independientes. Las líneas verticales marcan acontecimientos significativos durante la campaña.
import matplotlib.pyplot as plt
import seaborn as sns
# Ensure the date column is in datetime format
swing_24['date'] = pd.to_datetime(swing_24['date'])
# Group by date and party, then average the pct_estimate
swing_24_grouped = swing_24.groupby(['date', 'party'])['pct_estimate'].mean().reset_index()
# Create the line chart
plt.figure(figsize=(14, 8))
sns.lineplot(data=swing_24_grouped, x='date', y='pct_estimate', hue='party', marker='o',
palette={'REP': 'red', 'DEM': 'blue', 'IND': 'black'})
# Add vertical lines for significant events
plt.axvline(pd.to_datetime('2024-07-13'), color='red', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-08-05'), color='blue', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-07-23'), color='blue', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-09-05'), color='black', linestyle='--', alpha=0.25)
plt.axvline(pd.to_datetime('2024-10-01'), color='black', linestyle='--', alpha=0.25)
# Add text annotations for significant events
plt.text(pd.to_datetime('2024-07-13'), plt.ylim()[1] * 0.6, 'Trump Assassination Attempt', color='red', ha='right')
plt.text(pd.to_datetime('2024-07-23'), plt.ylim()[1] * 0.5, 'First Harris Rally', color='blue', ha='right')
plt.text(pd.to_datetime('2024-08-05'), plt.ylim()[1] * 0.4, 'Official Nomination of Harris', color='blue', ha='right')
plt.text(pd.to_datetime('2024-09-05'), plt.ylim()[1] * 0.3, 'Presidential Debate', color='black', ha='right')
plt.text(pd.to_datetime('2024-10-01'), plt.ylim()[1] * 0.2, 'Vice Presidential Debate', color='black', ha='right')
# Add horizontal gridlines at values divisible by 5
plt.yticks(range(0, 51, 5))
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Limit the y-axis range to 50
plt.ylim(0, 50)
# Adjust the legend
plt.legend(title='Party')
# Set titles and labels
plt.title('Average Polling Percentage per Party Over Time in Swing States')
plt.xlabel('Date')
plt.ylabel('Average Polling Percentage')
plt.show()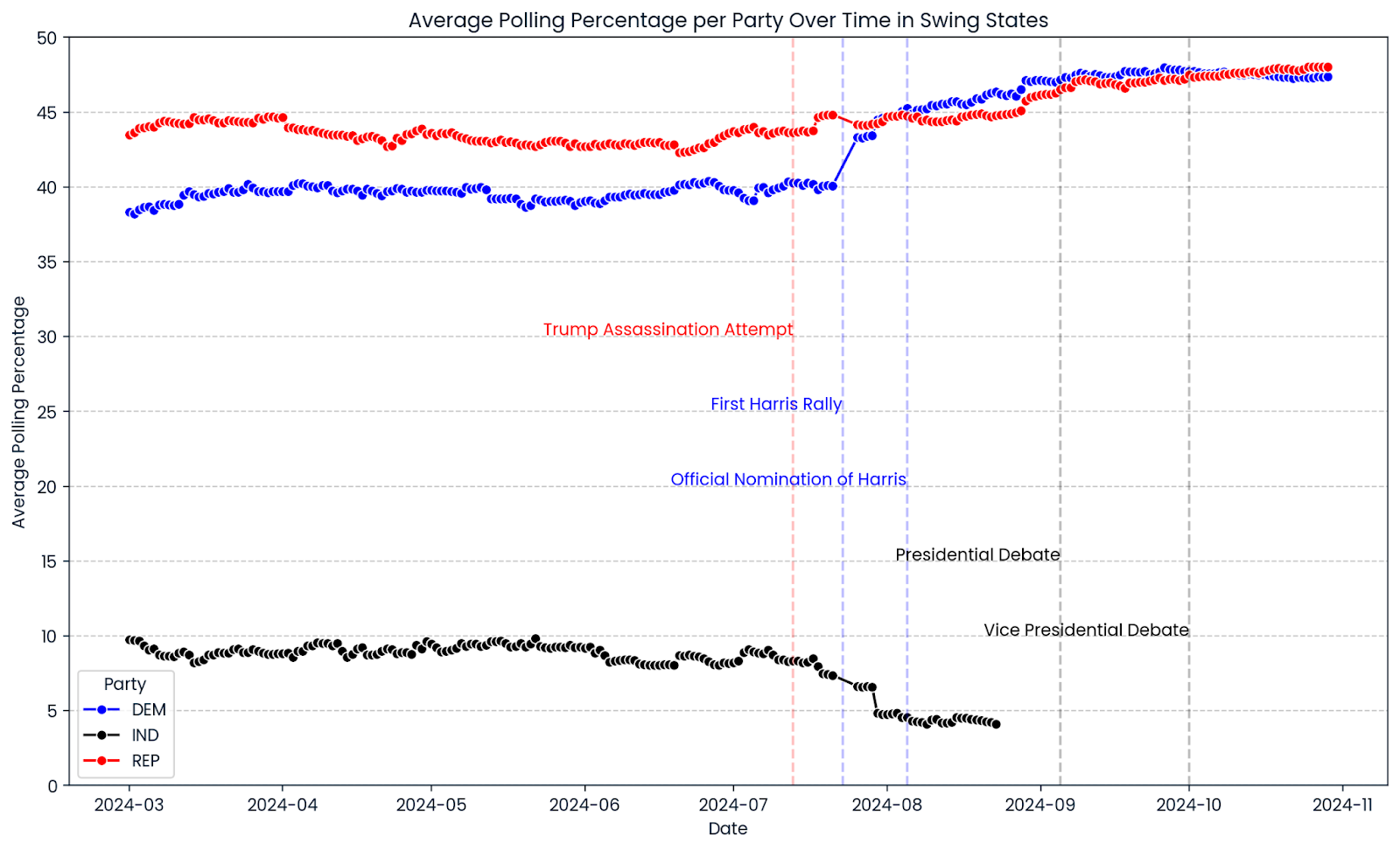
Un primer vistazo a la progresión de las encuestas de 2024 muestra un estrechamiento en los estados indecisos. El índice de aprobación de Donald Trump fue relativamente constante durante toda la campaña, con un ligero repunte reciente. El porcentaje del Partido Demócrata se mantuvo tras la nominación oficial de Kamala Harris como su candidata presidencial el 5 de agosto de 2024, superando significativamente las encuestas del ex candidato y Presidente de Estados Unidos, Joe Biden. En cualquier caso, los gráficos muestran una imagen de muchas carreras demasiado reñidas.
En esta sección, nos aseguraremos de que nuestros datos están limpios y listos para nuestros modelos de aprendizaje automático, centrándonos en el tratamiento de los valores perdidos y en la comprensión de las distribuciones de nuestras variables clave.
Quedan algunas cosas para verificar que los datos tienen la estructura adecuada para que se entrenen los modelos. En primer lugar, investigamos si alguna columna de ambos conjuntos de datos tiene valores perdidos.
# Calculate the number of missing values in each column of swing_until_20
missing_values_until_20 = swing_until_20.isnull().sum()
missing_values_24 = swing_24.isnull().sum()
# Filter out columns that have no missing values
missing_values_until_20 = missing_values_until_20[missing_values_until_20 > 0]
missing_values_24 = missing_values_24[missing_values_24 > 0]
# Display the columns with at least 1 missing value and their respective counts for both dataframes
print(missing_values_until_20, missing_values_24)momentum 84 dtype: int64
momentum 21 dtype: int64El impulso del candidato es la única columna con valores perdidos. Esto tiene sentido, ya que se calcula como la diferencia diaria entre los valores de las encuestas para cada candidato, por lo que esperaríamos que su primera observación fuera sin la columna de impulso. Podemos eliminar simplemente los valores que faltan.
# Dropping missing values
swing_24 = swing_24.dropna()
swing_until_20 = swing_until_20.dropna()Echar un vistazo a las distribuciones de las columnas numéricas nos dará una idea de si tenemos algunos valores atípicos ocultos o si los datos son plausibles en general.
Además, podemos comparar las encuestas del ciclo electoral de 2024 con la media de los ciclos anteriores. Podemos omitir algunas de las características como pct_opponent y rolling_avg_7d, ya que básicamente son el resultado de la columna pct_estimate y se parecerán básicamente a la misma distribución.
# Getting description of distributions in both DataFrames
swing_until_20[['pct_estimate', 'lead', 'pct_3rd_party', 'momentum', 'vote_share']].describe()
print(swing_24[['pct_estimate', 'lead', 'pct_3rd_party','momentum']].describe())|
pct_estimate |
plomo |
pct_3rd_party |
impulso |
vote_share |
|
|
cuenta |
20504 |
20504 |
20504 |
20504 |
20504 |
|
media |
44.73 |
0.00 |
1.25 |
0.00 |
48.85 |
|
min |
32.65 |
-18.01 |
0.00 |
-8.45 |
40.96 |
|
25% |
42.07 |
-4.94 |
0.00 |
-0.01 |
46.17 |
|
50% |
44.99 |
0.00 |
0.00 |
0.00 |
48.67 |
|
75% |
47.43 |
4.94 |
0.00 |
0.01 |
50.77 |
|
max |
56.47 |
18.01 |
12.67 |
8.45 |
57.97 |
|
std |
3.89 |
6.58 |
2.66 |
0.47 |
3.59 |
|
pct_estimate |
plomo |
pct_3rd_party |
impulso |
|
|
cuenta |
3228 |
3228 |
3228 |
3228 |
|
media |
43.53 |
0.00 |
5.87 |
0.00 |
|
min |
35.39 |
-8.77 |
0.00 |
-6.28 |
|
25% |
41.06 |
-2.07 |
0.00 |
-0.12 |
|
50% |
43.76 |
0.00 |
8.01 |
0.00 |
|
75% |
46.56 |
2.07 |
8.91 |
0.12 |
|
max |
48.89 |
8.77 |
12.17 |
6.28 |
|
std |
3.22 |
3.63 |
4.05 |
0.45 |
Las distribuciones de los rasgos en los conjuntos de datos de swing_until_20 y swing_24 parecen plausibles y se ajustan a las expectativas de los datos de las encuestas en los estados indecisos.
Los valores de pct_estimate oscilan aproximadamente entre el 33% y el 56% históricamente y entre el 35% y el 49% en 2024, lo que es razonable para unas elecciones competitivas en las que ninguno de los candidatos domina de forma abrumadora. El vote_share del conjunto de datos históricos tiene una media del 48,85%, lo que es plausible dado que los estados indecisos suelen tener divisiones cercanas al 50-50.
Como cabría esperar, las variables lead y momentum se centran en torno a una media de 0 en ambos conjuntos de datos, lo que indica que las ventajas, los inconvenientes, las ganancias y las pérdidas entre candidatos se equilibran a lo largo del tiempo. La variable lead parece tener una distribución casi perfectamente normal, mientras que la momentum es al menos simétrica, pero tiene la mayoría de los valores más próximos a la media.
El histórico pct_estimate sigue una distribución bastante normal con una ligera inclinación hacia la izquierda, ya que la media está al menos muy cerca de la mediana, y la dispersión capta cantidades típicas de valores dentro de un rango razonable.
En los datos de 2024, los porcentajes de las encuestas están más centrados en la media. La variable lead tiene una desviación típica menor en 2024 (3,63) en comparación con los datos históricos (6,58), y el rango de sus valores es incluso inferior a la mitad del histórico. Todos ellos son indicadores de que los márgenes entre los candidatos serán más estrechos en 2024, lo que sugiere unas contiendas aún más reñidas.
En la mayoría de los ciclos, no hubo ningún candidato de un tercer partido que reuniera un apoyo significativo, como podemos ver por el hecho de que más del 75% de las observaciones tienen un valor pct_3rd_party de 0, siendo la media del 1,25%. Las elevadas cifras de 2024 (mediana del 8,01%) reflejan el fuerte apoyo que tuvo el candidato independiente Robert F. Kennedy hasta el final de su campaña en agosto de 2024.
Nuestra estrategia de predicción tendrá en cuenta el hecho de que las encuestas no son resultados electorales definitivos, sino meros indicadores del sentimiento público en momentos concretos. Por tanto, evitaremos basarnos en simples predicciones de series temporales que traten los datos de las encuestas como predicciones directas de los resultados. En su lugar, utilizaremos un enfoque basado en la regresión que predice el resultado electoral para cada observación de sondeo individualmente, en lugar de predecir una línea temporal de datos de sondeo.
Reconociendo que cada estado tiene su propio panorama político, construiremos un modelo distinto para cada estado indeciso. Para evitar la fuga de datos y respetar el paso del tiempo, nos aseguraremos de que nuestros modelos sólo se prueben con datos no vistos, concretamente, ciclos electorales que ocurran después de aquellos con los que se entrenaron los modelos. Este enfoque nos ayudará a evaluar con precisión la capacidad de los modelos para generalizarse a futuras elecciones.
Elegí dos criterios de evaluación al evaluar los modelos predictivos de las cuotas de votos electorales. Dado que el ganador "se lo lleva todo" en cada estado, el número de ganadores correctamente pronosticados a lo largo de los ciclos de pruebas es la medida más importante a tener en cuenta.
El Error Absoluto Medio (EAM) es el criterio de evaluación secundario. Mide la magnitud media de los errores entre los valores previstos y los reales en las mismas unidades que la variable objetivo: en este caso, puntos porcentuales de la cuota de voto. Esto lo hace muy interpretable y directamente relevante para nuestro contexto, ya que nos dice, por término medio, cuántos puntos porcentuales se desvían nuestras predicciones de los resultados reales.
Por último, entrenaremos el mejor modelo de cada estado en todos los ciclos electorales hasta 2020 y lo aplicaremos para predecir los resultados de las elecciones de 2024. Utilizaremos una ponderación basada en el tiempo con una función de decaimiento exponencial para transformar las predicciones individuales en un único valor predictivo por estado, dando más importancia a los sondeos recientes.
En primer lugar, importamos los paquetes que necesitaremos más adelante. Esto incluye todos los modelos que evaluaremos, NumPy, así como el mean_absolute_error.
# Importing models
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression, Ridge, ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.svm import SVR
import catboost
import xgboost as xgb
# Importing other necessary libraries
from sklearn.metrics import mean_absolute_error
import numpy as np¡Vamos a crear un flujo de trabajo para entrenar y evaluar los modelos base! Recorreremos el proceso paso a paso y luego lo aplicaremos a cada estado para cada ciclo de pruebas, empezando por 2004.
Para adaptar nuestros modelos a las características únicas de cada estado, empezamos filtrando el conjunto de datos para incluir sólo los datos relevantes para el estado analizado. Esto garantiza que el modelo capte los patrones de voto específicos de cada estado y los datos de las encuestas.
# Filter data for the state you're analyzing
data_state = swing_until_20[swing_until_20['state'] == state].copy()A continuación, definimos una función de ponderación para asignar más importancia a los sondeos realizados más cerca de la fecha de las elecciones. Esta función de decaimiento exponencial disminuye el peso de las encuestas a medida que se alejan de las elecciones, destacando la relevancia de los datos de las encuestas recientes.
# Define the weight function (using a typical starting k value)
def compute_weight(days_until_election, k):
return np.exp(-k * days_until_election)
# Add weights to the data
data_state['weight'] = compute_weight(data_state['days_until_election'], k=0.1)A continuación, dividimos los datos en conjuntos de entrenamiento y de prueba en función de los ciclos electorales, asegurándonos de que entrenamos en elecciones pasadas y probamos en las futuras para evitar la fuga de datos. Llegaremos a la definición de train_cycles y test_cycle más adelante, cuando demos la vuelta al bucle a través de los ciclos electorales. También definimos las características que se utilizarán para la predicción y extraemos la variable objetivo, que es la cuota de votos real.
# Split data into training and testing sets based on election cycles
train_data = data_state[data_state['cycle'].isin(train_cycles)]
test_data = data_state[data_state['cycle'] == test_cycle]
# Define features and target variable
features = ['pct_estimate', 'pct_opponent', 'pct_3rd_party', 'lead', 'rolling_avg_7d',
'days_until_election', 'momentum_candidate', 'momentum_opponent', 'momentum',
'is_incumbent_president', 'is_incumbent_vice_president', 'is_incumbent_party',
'candidate_Donald Trump',
'party_DEM', 'party_REP']
X_train = train_data[features]
y_train = train_data['vote_share']
X_test = test_data[features]
y_test = test_data['vote_share']Definimos una variedad de modelos de aprendizaje automático para evaluar, incluida la regresión lineal, los métodos de conjunto, las máquinas de vectores de soporte y las redes neuronales. Este conjunto diverso nos permite comparar diferentes algoritmos y seleccionar el modelo de mejor rendimiento para cada estado.
# Models to evaluate
models = {
'LinearRegression': LinearRegression(),
'XGBoost': xgb.XGBRegressor(objective='reg:absoluteerror', n_estimators=100, random_state=42),
'CatBoost': catboost.CatBoostRegressor(loss_function='MAE', iterations=100, random_seed=42, verbose=0),
'RandomForest': RandomForestRegressor(n_estimators=100, random_state=42),
'SVR': SVR(kernel='rbf', C=1.0, epsilon=0.1),
'KNeighbors': KNeighborsRegressor(n_neighbors=5),
'MLPRegressor': MLPRegressor(hidden_layer_sizes=(100,), max_iter=500, random_state=42),
'ElasticNet': ElasticNet(alpha=1.0, l1_ratio=0.5, random_state=42),
}A continuación, recorreremos el diccionario models. Para cada modelo, lo entrenamos utilizando el conjunto de datos de entrenamiento específico del estado actual y luego hacemos predicciones en el conjunto de datos de prueba. Este proceso se repite con cada modelo para evaluar comparativamente su rendimiento.
for model_name, model in models.items():
# Train the model
model.fit(X_train, y_train)
# Predict on test data
test_data[f'predicted_{model_name}'] = model.predict(X_test)Dentro del bucle del modelo, agregamos las predicciones individuales de cada partido utilizando una función lambda que aplica las ponderaciones calculadas anteriormente. El resultado es un único porcentaje de votos previsto por partido, que luego comparamos con el porcentaje de votos real para evaluar la precisión del modelo.
# Aggregate predictions using weights
aggregated_predictions = test_data.groupby('party').apply(
lambda df: np.average(df[f'predicted_{model_name}'], weights=df['weight'])
).reset_index(name='aggregated_prediction')
# Get actual vote shares for comparison
actual_vote_shares = test_data.groupby('party')['vote_share'].mean().reset_index()
comparison = pd.merge(aggregated_predictions, actual_vote_shares, on='party')
comparison.rename(columns={'vote_share': 'actual_vote_share'}, inplace=True)Para finalizar el bucle del modelo, calculamos el Error Absoluto Medio (EAM) entre las predicciones agregadas y las cuotas de votos reales para cuantificar el rendimiento del modelo. También determinamos si el modelo predijo correctamente el partido ganador en el estado y almacenamos estos resultados para un análisis posterior.
# Calculate Mean Absolute Error
mae = mean_absolute_error(comparison['actual_vote_share'], comparison['aggregated_prediction'])
# Check if the predicted winner matches the actual winner
predicted_winner = comparison.loc[comparison['aggregated_prediction'].idxmax(), 'party']
actual_winner = comparison.loc[comparison['actual_vote_share'].idxmax(), 'party']
correct_winner = int(predicted_winner == actual_winner)
# Store the results
results_list.append({
'state': state,
'model_name': model_name,
'test_cycle': test_cycle,
'MAE': mae,
'correct_winner': correct_winner
})Todo este proceso está envuelto en dos bucles: el bucle exterior itera sobre cada ciclo electoral (excluyendo el primero, ya que no hay datos previos con los que entrenar), y el bucle interior itera sobre cada estado indeciso. Al hacerlo, nos aseguramos de que los modelos se entrenan y prueban adecuadamente para cada estado y ciclo electoral, respetando el orden cronológico de las elecciones para evitar la fuga de datos.
El prefacio del código anterior tiene este aspecto:
# Initialize a list to store results
results_list = []
# Define the election cycles
cycles = [2000, 2004, 2008, 2012, 2016, 2020]
for i in range(1, len(cycles)): # The loop starts at index 1, so with the 2nd cycle (2004)
test_cycle = cycles[i]
train_cycles = cycles[:i] # train_cycles = all cycles before the test_cycle
for state in swing_states:
# Filter data for the state you're analyzing, etc. …En general, esta estrategia nos permite evaluar múltiples modelos en diferentes estados y ciclos electorales, seleccionando en última instancia el modelo de mejor rendimiento para cada estado en función de la precisión predictiva y la capacidad de pronosticar correctamente el ganador de las elecciones.
Tras entrenar y probar varios modelos de aprendizaje automático en distintos estados y ciclos electorales, pasamos a evaluar su rendimiento para identificar los mejores modelos para cada estado. Esta evaluación se centra en dos métricas clave: el número de veces que cada modelo predijo correctamente el partido ganador (correct_winner) y la media del Error Absoluto Medio (MAE) de sus predicciones.
En primer lugar, recopilamos todos los resultados recogidos durante las evaluaciones del modelo en un único DataFrame y agregamos las métricas de rendimiento:
# After the loop, create a DataFrame from the results list
results_df = pd.DataFrame(results_list)
# Get the sum of correct_winner and the average MAE for every combination of state and model_name
aggregated_evaluation = results_df.groupby(['state', 'model_name']).agg({
'correct_winner': 'sum',
'MAE': 'mean'
}).reset_index()
# Display the maximum number of correct winner predictions and the minimum MAE for each state
print(aggregated_evaluation.groupby('state')['correct_winner'].max())
print(aggregated_evaluation.groupby('state')['MAE'].min())|
estado |
Ganador_correcto máximo |
MAE mínimo |
|
Arizona |
5 |
1.248966 |
|
Georgia |
5 |
0.770760 |
|
Michigan |
4 |
2.685870 |
|
Nevada |
5 |
2.079582 |
|
Carolina del Norte |
5 |
0.917522 |
|
Pennsylvania |
4 |
2.027426 |
|
Wisconsin |
4 |
2.462907 |
¡No tiene mala pinta! En todos los estados, hubo al menos un modelo que predijo correctamente 4 de las 5 elecciones anteriores. En 4 de los estados (Arizona, Georgia, Nevada y Carolina del Norte), incluso conseguimos que algunos modelos predijeran el ganador correcto en cada ciclo. Sin embargo, los resultados de la MAE más baja tienen en parte margen de mejora, y difieren bastante entre los estados, con una media de 1,74 puntos porcentuales y oscilando entre 0,77 en Georgia y 2,69 en Michigan.
Con esta información agregada, procedemos a seleccionar el modelo con mejores resultados para cada estado. Clasificamos los modelos basándonos primero en su capacidad para predecir el ganador correcto y sólo después en su MAE. Los modelos elegidos se guardan en el diccionario best_models.
# Sort the models for each state by correct_winner (descending) and then by MAE (ascending)
sorted_evaluation = aggregated_evaluation.sort_values(by=['state', 'correct_winner', 'MAE'], ascending=[True, False, True])
# Create a dictionary to store the best model for each state
best_models = {}
# Iterate over each state and get the top model
for state in sorted_evaluation['state'].unique():
top_model = sorted_evaluation[sorted_evaluation['state'] == state].iloc[0]
best_models[state] = top_model['model_name']
best_models{'Arizona': 'RandomForest',
'Georgia': 'ElasticNet',
'Michigan': 'LinearRegression',
'Nevada': 'KNeighbors',
'North Carolina': 'CatBoost',
'Pennsylvania': 'KNeighbors',
'Wisconsin': 'MLPRegressor'}Los principales modelos de cada estado varían mucho, reflejando los patrones de voto y los comportamientos electorales únicos de cada región. Sorprendentemente, en Michigan los mejores resultados se obtienen incluso utilizando la Regresión Lineal, lo que indica que allí puede bastar un enfoque lineal más sencillo.
En este punto, podríamos utilizar el ajuste de hiperparámetros para optimizar el rendimiento de cada modelo de aprendizaje automático. Dado que esto introduciría más cuestiones metodológicas y requeriría grandes ajustes en el código, queda fuera del alcance de este tutorial, ya de por sí bastante largo. Los resultados de los modelos de base ya parecen lo suficientemente prometedores como para atreverse y predecir los resultados de las elecciones de 2024.
En la fase final de nuestro análisis, utilizamos los modelos con mejores resultados para cada estado indeciso para predecir los resultados de las elecciones de 2024. Comenzamos inicializando una lista vacía para almacenar nuestras predicciones.
Para cada estado y su correspondiente mejor modelo de nuestras evaluaciones anteriores, utilizamos el mismo flujo de trabajo de antes. Sólo que esta vez, no tenemos que hacer un bucle a través de los ciclos electorales, sino que nos entrenamos con todos los datos históricos desde 2000 hasta 2020 (swing_until_20 ).
# Initialize a list to store predictions
predictions_list = []
for state, model_name in best_models.items():
# Filter the data for the specific state
state_data_train = swing_until_20[swing_until_20['state'] == state].copy() # Data from 2000 to 2020
state_data_test = swing_24[swing_24['state'] == state].copy() # Data for 2024
# Add weights to the test data
state_data_test['weight'] = compute_weight(state_data_test['days_until_election'], k=0.1)
# Define features
features = [
'pct_estimate',
'pct_opponent',
'pct_3rd_party',
'lead',
'rolling_avg_7d',
'days_until_election',
'momentum_candidate',
'momentum_opponent',
'momentum',
'is_incumbent_president',
'is_incumbent_vice_president',
'is_incumbent_party',
'candidate_Donald Trump',
'party_DEM',
'party_REP'
]
# Split features and target variable
X_train = state_data_train[features]
y_train = state_data_train['vote_share']
X_test = state_data_test[features]
# Train the model on the 2000 to 2020 data
model.fit(X_train, y_train)
# Predict on the 2024 data
state_data_test['predicted_vote_share'] = model.predict(X_test)
# Aggregate predictions using weights
aggregated_predictions = state_data_test.groupby('party').apply(
lambda df: np.average(df['predicted_vote_share'], weights=df['weight'])
).reset_index(name='aggregated_prediction')
# Append predictions to the list
for _, pred_row in aggregated_predictions.iterrows():
predictions_list.append({
'state': state,
'party': pred_row['party'],
'predicted_vote_share': pred_row['aggregated_prediction'],
'model': model_name
})Después de predecir la columna vote_share, agregar las predicciones utilizando la función de peso que definimos anteriormente, y añadir las predicciones a predictions_list, consolidamos las predicciones finales en un DataFrame. Además, añadimos una clasificación para cada estado y pivotamos las predicciones por estado. He aquí las predicciones de nuestros modelos:
# Convert predictions list to DataFrame
predictions_df = pd.DataFrame(predictions_list)
# Add a rank to predictions_df for each state based on the order of predicted_vote_share
predictions_df['rank'] = predictions_df.groupby('state')['predicted_vote_share'].rank(ascending=False)
# Create a pivot table indexed by state
predictions_pivot = predictions_df.pivot(index='state', columns='party', values='predicted_vote_share')
# Display predictions
print("\n2024 Vote Share Predictions:")
predictions_pivot2024 Vote Share Predictions:
state
DEM
REP
Arizona
49.02
50.31
Georgia
48.95
50.08
Michigan
50.34
48.64
Nevada
49.41
48.54
North Carolina
48.95
50.06
Pennsylvania
49.57
49.20
Wisconsin
49.66
49.41Las predicciones confirman nuestra estimación de una carrera muy reñida en los estados indecisos. Nuestros modelos predicen que 4 estados darán su voto mayoritario a Kamala Harris (Michigan, Nevada, Pensilvania, Wisconsin) y 3 a Donald Trump (Arizona, Georgia, Carolina del Norte). Los estados de Pensilvania y Wisconsin se prevén especialmente reñidos, ya que la diferencia entre los porcentajes de voto previstos para ambos es de sólo 0,37 y 0,25 puntos porcentuales, respectivamente.
Como ya hemos dicho, suponemos que todos los demás estados votan al candidato que se espera que gane, es decir, los estados "azules" votan a Kamala Harris, y los estados "rojos" votan a Donald Trump. Para evaluar cuántos votos electorales obtiene cada candidato, definimos un diccionario que asigna a cada estado y distrito su número de votos y combinamos la información en un DataFrame llamado electoral_votes_df.
# Define the number of electoral votes per state for the 2024 US-Presidential elections
electoral_votes = {
'Alabama': 9, 'Alaska': 3, 'Arizona': 11, 'Arkansas': 6, 'California': 54,
'Colorado': 10, 'Connecticut': 7, 'Delaware': 3, 'District of Columbia': 3,
'Florida': 30, 'Georgia': 16, 'Hawaii': 4, 'Idaho': 4, 'Illinois': 19,
'Indiana': 11, 'Iowa': 6, 'Kansas': 6, 'Kentucky': 8, 'Louisiana': 8,
'Maine': 2, 'Maryland': 10, 'Massachusetts': 11, 'Michigan': 15,
'Minnesota': 10, 'Mississippi': 6, 'Missouri': 10, 'Montana': 4,
'Nebraska': 2, 'Nevada': 6, 'New Hampshire': 4, 'New Jersey': 14,
'New Mexico': 5, 'New York': 28, 'North Carolina': 16, 'North Dakota': 3,
'Ohio': 17, 'Oklahoma': 7, 'Oregon': 8, 'Pennsylvania': 19,
'Rhode Island': 4, 'South Carolina': 9, 'South Dakota': 3,
'Tennessee': 11, 'Texas': 40, 'Utah': 6, 'Vermont': 3, 'Virginia': 13,
'Washington': 12, 'West Virginia': 4, 'Wisconsin': 10, 'Wyoming': 3
}
# Create a DataFrame from the dictionary
electoral_votes_df = pd.DataFrame(list(electoral_votes.items()), columns=['State', 'Electoral Votes'])
# Handle states that divide their votes into multiple districts (Maine and Nebraska)
districts = {'ME-1': 1, 'ME-2': 1, 'NE-1': 1, 'NE-2': 1, 'NE-3': 1}
# Add the districts to the DataFrame
districts_df = pd.DataFrame(list(districts.items()), columns=['State', 'Electoral Votes'])
# Combine the two DataFrames
electoral_votes_df = pd.concat([electoral_votes_df, districts_df], ignore_index=True)A continuación, creamos dos listas, harris y trump, que contienen los estados azules y rojos, respectivamente, junto con los estados indecisos que se prevé que gane cada candidato. En el siguiente paso, podemos filtrar electoral_votes_df para los estados de cada lista y calcular la suma de votos electorales previstos para cada candidato.
# Extract states from predictions_df where party is DEM and rank is 1
additional_blue_states = predictions_df[
(predictions_df['party'] == 'DEM') & (predictions_df['rank'] == 1)
].state.tolist()
# Extract states from predictions_df where party is REP and rank is 1
additional_red_states = predictions_df[
(predictions_df['party'] == 'REP') & (predictions_df['rank'] == 1)
].state.tolist()
# Combine blue_states and additional_blue_states into a single list
harris = list(set(blue_states + additional_blue_states))
trump = list(set(red_states + additional_red_states))
# Filter the electoral votes for states in each candidate's list
harris_electoral_votes = electoral_votes_df[electoral_votes_df['state'].isin(harris)]
trump_electoral_votes = electoral_votes_df[electoral_votes_df['state'].isin(trump)]
# Sum the electoral votes
sum_harris_electoral_votes = harris_electoral_votes['electoral_votes'].sum()
sum_trump_electoral_votes = trump_electoral_votes['electoral_votes'].sum()
print(
f'According to the predictions made by the machine learning models, '
f'Kamala Harris will win {sum_harris_electoral_votes} electoral votes '
f'and Donald Trump will win {sum_trump_electoral_votes} electoral votes.'
)According to the predictions made by the machine learning models, Kamala Harris will win 276 electoral votes and Donald Trump will win 262 electoral votes.La predicción es que Kamala Harris ganará 276 votos electorales y Donald Trump ganará 262 votos electorales. Si nuestras suposiciones y predicciones se cumplieran, éste es el aspecto que tendría el mapa electoral el 5 de noviembre:
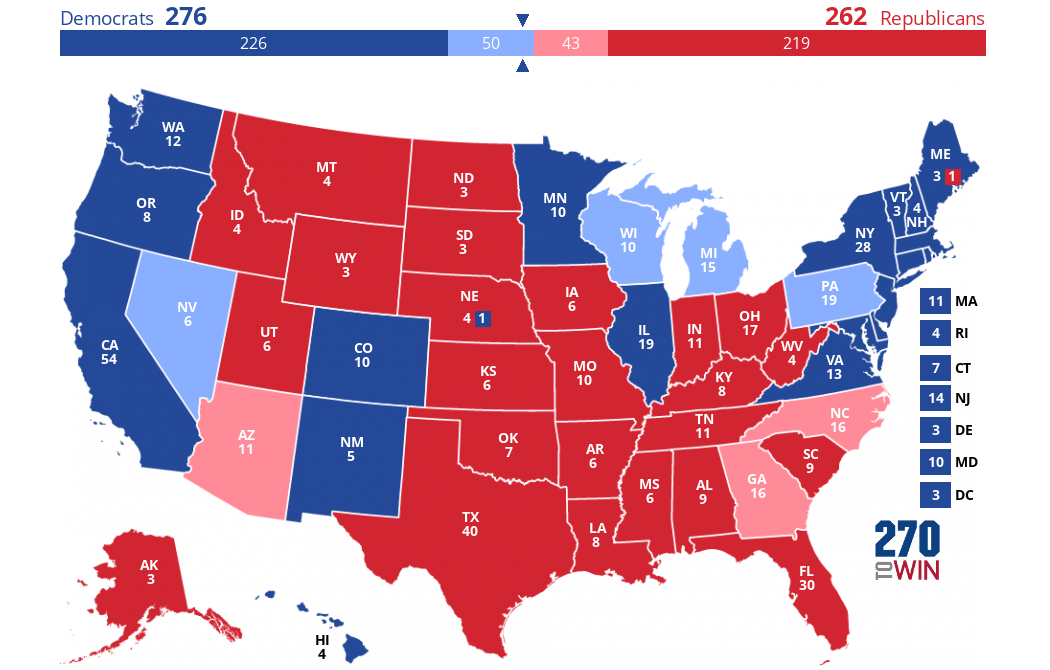
Creado con este creador de mapas interactivos.
Los colores oscuros representan lo que suponíamos que eran estados "azules" o "rojos". Los estados indecisos pronosticados por nosotros marcan la diferencia: están coloreados en azul o rojo más claro.
En este proyecto, utilizamos datos históricos de encuestas para predecir el resultado de las elecciones presidenciales estadounidenses de 2024. Como era de esperar, nuestros modelos indican una carrera reñida entre los principales candidatos.
Es importante tener en cuenta que nuestro análisis se basó únicamente en datos de encuestas, que a veces han sido inexactos en el pasado y no captan todos los matices de unas elecciones. Factores como las metodologías de sondeo, la participación electoral, la dinámica de las campañas, las circunstancias económicas y demográficas y los acontecimientos imprevistos no se tuvieron en cuenta en nuestros modelos, pero pueden influir significativamente en los resultados reales.
No obstante, esta exploración muestra el potencial del análisis predictivo para comprender sistemas complejos como las elecciones. Si te interesa aprender más sobre el análisis predictivo utilizando Python, te recomiendo estos recursos:
Aprende aprendizaje automático con estos cursos
programa
Tutorial
Moez Ali
Tutorial
Thushan Ganegedara
Tutorial
Zoumana Keita