
Curso
Entrenamiento eficiente de modelos de IA con PyTorch
4 h
1.5K
El uso de modelos lingüísticos de gran tamaño conlleva costes reales. Pagas por cada token procesado, cada ciclo de GPU utilizado y cada capa de complejidad añadida a un modelo. Aunque los precios han bajado, la factura sigue aumentando rápidamente cuando trabajas con aplicaciones grandes, comandos largos o actualizaciones frecuentes.
He visto lo rápido que esto se convierte en un problema. Los equipos asumen que los costes seguirán siendo manejables, solo para darse cuenta de que están gastando el presupuesto en modelos sobredimensionados, indicaciones ineficaces o hardware inactivo.
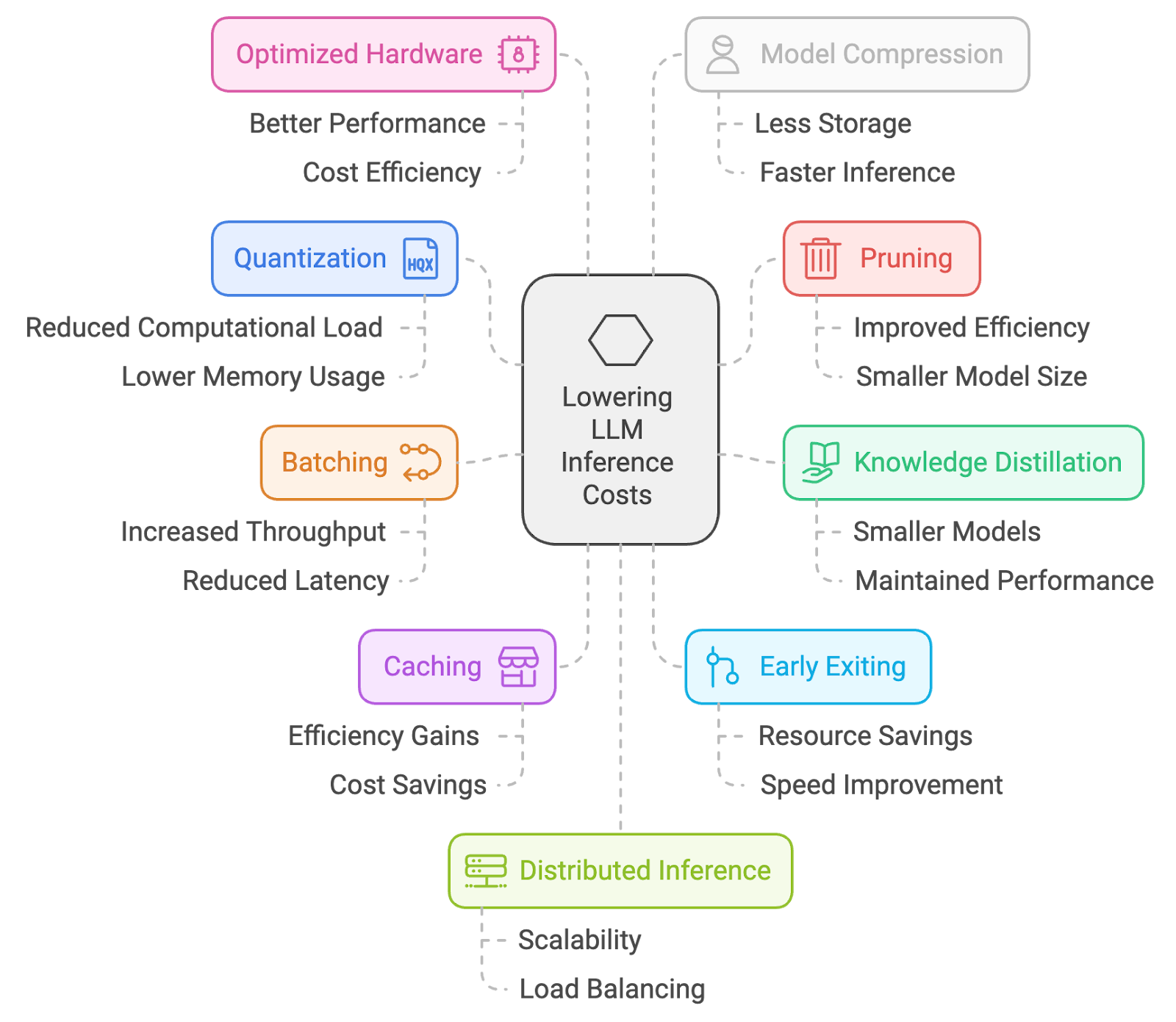
Por eso he recopilado 10 formas prácticas de reducir los costes de inferencia. Desde la cuantificación y la poda hasta el procesamiento por lotes, el almacenamiento en caché y la ingeniería de prompts, estos son los enfoques que utilizo para mantener los LLM asequibles sin sacrificar demasiado rendimiento.
La cuantificación es un proceso de reducción de la precisión de los pesos y activaciones del modelo, normalmente de números de coma flotante de 32 bits a representaciones de menos bits (por ejemplo, 16 bits o incluso 8 bits). Esto reduce el consumo de memoria y los requisitos computacionales, lo que permite una inferencia más rápida en dispositivos con recursos limitados.
Cómo se hace:
Cómo ayuda:
La principal desventaja es una posible pérdida de precisión. Aunque las técnicas modernas de cuantificación son bastante buenas, siempre existe la posibilidad de que se produzca una ligera disminución en la precisión del modelo.
La poda es una técnica que consiste en eliminar pesos menos importantes o redundantes de una red neuronal. Al eliminar las conexiones que tienen un impacto mínimo en el rendimiento del modelo, la poda reduce el tamaño y la complejidad computacional del modelo, lo que se traduce en una inferencia más rápida.
Cómo se hace:
Cómo ayuda:
Al igual que con la cuantificación, la principal desventaja es una posible pérdida de precisión. Una poda agresiva puede provocar una notable disminución del rendimiento. Es fundamental encontrar el equilibrio adecuado.
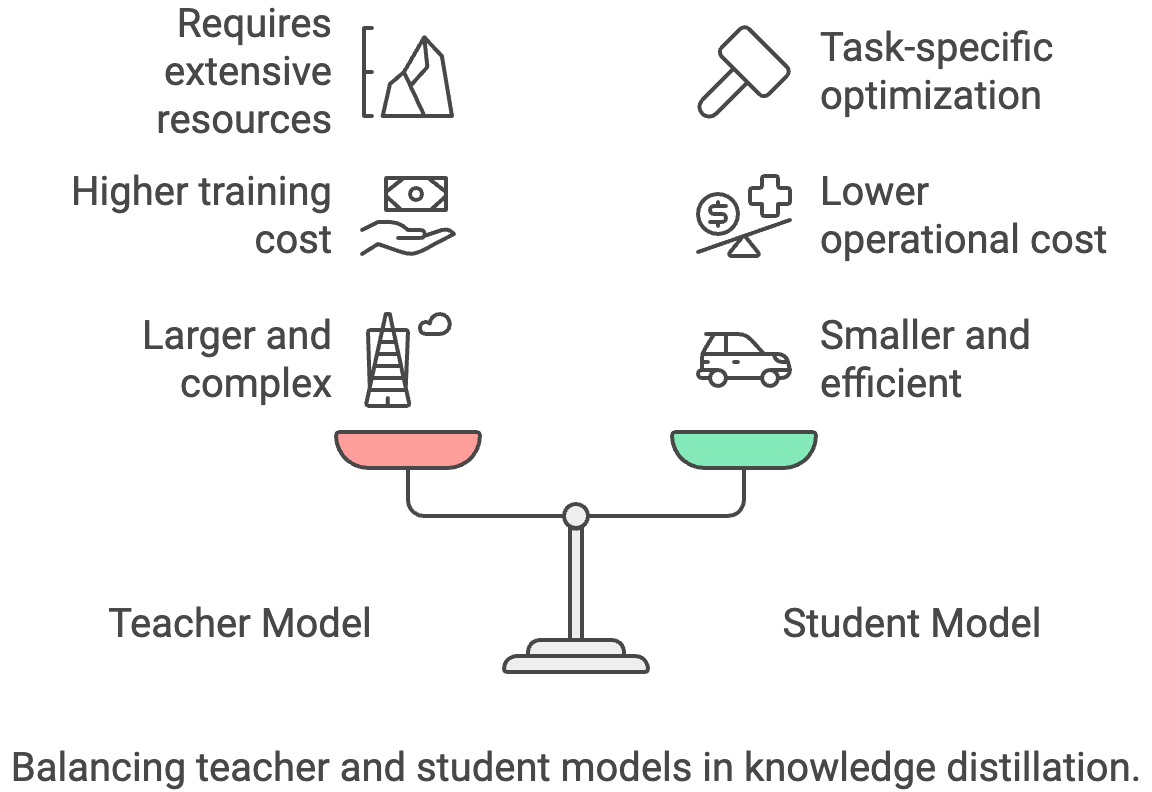
La destilación del conocimiento es un proceso de transferencia de conocimientos desde un modelo «profesor» grande y complejo a un modelo «alumno» más pequeño y eficiente. El modelo del alumno aprende a imitar el comportamiento del profesor, lo que te permite alcanzar un rendimiento comparable con un tamaño más reducido y una inferencia más rápida.
Cómo se hace:
Cómo ayuda:
La principal desventaja es que necesitas tener acceso a un modelo de enseñanza potente, cuya formación o uso puede resultar caro.
El procesamiento por lotes implica procesar varias muestras de entrada simultáneamente en un lote durante la inferencia. Esto mejora la eficiencia al utilizar las capacidades de procesamiento paralelo del hardware, lo que se traduce en una inferencia global más rápida.
Cómo se hace:
Cómo ayuda:
Sin embargo, el procesamiento por lotes puede introducir una latencia adicional para las solicitudes individuales, ya que el sistema puede esperar a acumular suficientes entradas antes de procesarlas. En aplicaciones en tiempo real o de baja latencia, este retraso adicional puede degradar la experiencia del usuario si no se ajusta cuidadosamente. El procesamiento por lotes dinámico ayuda a mitigar el problema, pero añade complejidad al sistema. También existe el riesgo de que el procesamiento por lotes sea ineficiente cuando el tráfico es desigual, lo que puede reducir el ahorro de costes previsto.
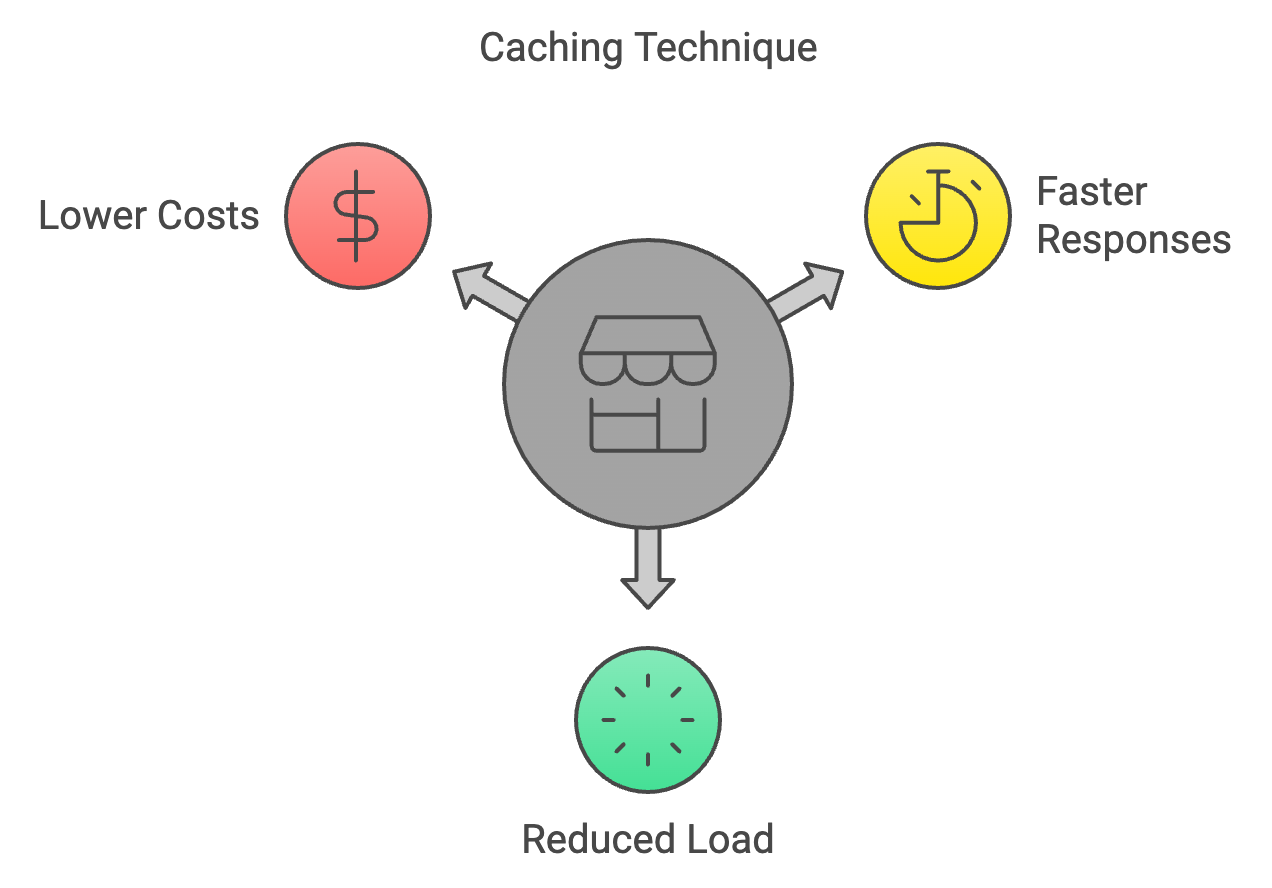
El almacenamiento en caché es una técnica que consiste en guardar los resultados de cálculos anteriores y reutilizarlos cuando se encuentran las mismas entradas de nuevo durante la inferencia. Esto evita cálculos redundantes, lo que acelera el proceso de inferencia.
Cómo se hace:
Cómo ayuda:
Sin embargo, el almacenamiento en caché solo es útil cuando las entradas se repiten o se superponen. En cargas de trabajo muy variables, las tasas de acierto pueden ser bajas y los gastos generales de mantenimiento de una caché pueden superar los beneficios. Los resultados obsoletos o desactualizados también pueden crear problemas de coherencia si los resultados almacenados en caché ya no reflejan los datos más relevantes. Además, implementar y ajustar estrategias de expulsión de caché añade complejidad técnica, especialmente en sistemas distribuidos, donde la sincronización de la caché se convierte en un reto.
La salida anticipada consiste en detener el cálculo antes de tiempo durante la inferencia si el modelo tiene suficiente confianza en su predicción. Esto ahorra recursos computacionales y acelera la inferencia en casos más sencillos en los que no es necesario realizar una pasada completa hacia adelante.
Cómo se hace:
Cómo ayuda:
La desventaja es que salir antes de tiempo puede reducir ligeramente la precisión en algunos casos, especialmente con entradas complejas.
Esta técnica implica el uso de arquitecturas de hardware y aceleradores especializados diseñados para realizar cálculos de IA de manera eficiente. Entre ellos se incluyen GPU, TPU y otros chips dedicados a la IA que ofrecen mejoras significativas en el rendimiento en comparación con las CPU de uso general para tareas de inferencia.
Cómo se hace:
Cómo ayuda:
Sin embargo, el hardware especializado suele requerir una inversión inicial considerable y puede limitarte a un ecosistema de proveedores concreto. Las GPU, TPU o aceleradores personalizados también pueden ser más difíciles de aprovisionar de manera consistente en la nube, especialmente durante los picos de demanda. Las implementaciones locales plantean retos de mantenimiento y escalabilidad, mientras que las opciones en la nube pueden conllevar mayores costes de alquiler continuos. Por último, adaptar el software para aprovechar al máximo el hardware especializado puede añadir complejidad técnica y requerir una optimización continua.
La compresión de modelos se refiere al uso de más de una técnica para reducir el tamaño y la complejidad de un modelo sin comprometer significativamente su rendimiento. Esto puede implicar la poda, la cuantificación, la destilación de conocimientos u otros métodos destinados a crear un modelo más compacto y eficiente para una inferencia más rápida.
Cómo se hace:
Cómo ayuda:
La compresión del modelo puede provocar una pérdida de precisión si las técnicas se aplican de forma demasiado agresiva o sin un ajuste cuidadoso. La combinación de métodos como la poda, la cuantificación y la destilación aumenta la complejidad del sistema y puede requerir ciclos adicionales de reentrenamiento o ajuste. Los modelos comprimidos también pueden ser menos flexibles para transferirlos a nuevas tareas, ya que las optimizaciones suelen reducir el abanico de escenarios en los que el modelo funciona bien. En algunos casos, el tiempo de ingeniería y la sobrecarga computacional dedicados a la compresión pueden contrarrestar el ahorro de costes a corto plazo.
La inferencia distribuida es un enfoque para dividir la carga de trabajo de inferencia entre varias máquinas o dispositivos. Esto permite el procesamiento paralelo de tareas de inferencia a gran escala, lo que reduce la latencia y mejora el rendimiento.
Cómo se hace:
Cómo ayuda:
La inferencia distribuida introduce una complejidad significativa en el sistema, ya que coordinar los cálculos entre múltiples máquinas requiere una sólida organización, sincronización y tolerancia a fallos. La latencia de la red y las limitaciones de ancho de banda pueden contrarrestar las mejoras de rendimiento, especialmente cuando es necesario intercambiar grandes cantidades de datos intermedios. También aumenta los costes de infraestructura, ya que hay que adquirir y mantener hardware adicional y mecanismos de equilibrio de carga. La depuración y supervisión de sistemas distribuidos puede resultar más difícil, lo que hace que la fiabilidad sea un reto en comparación con las configuraciones de un solo nodo.
La ingeniería de prompts es un proceso que consiste en elaborar cuidadosamente indicaciones de entrada para guiar a los modelos de lenguaje grandes (LLM) hacia la generación de los resultados deseados. Al formular indicaciones claras, concisas y específicas, los usuarios pueden mejorar la calidad y la capacidad de control de las respuestas del LLM, haciéndolas más relevantes y útiles para tareas específicas.
Cómo se hace:
Cómo ayuda:
La ingeniería rápida requiere experimentación e iteración continuas, lo que puede llevar mucho tiempo y resultar inconsistente en los distintos casos de uso. Las indicaciones bien elaboradas pueden no ser generalizables, lo que te obliga a rediseñarlas cuando cambian las tareas o los modelos. Las mejoras en el diseño de las preguntas también pueden ser frágiles: pequeños cambios en la redacción o actualizaciones del modelo pueden alterar los resultados de forma impredecible. Por último, depender en exceso de la ingeniería rápida sin técnicas complementarias como la gestión del contexto o el ajuste fino puede limitar la escalabilidad y el ahorro de costes a largo plazo.
La ingeniería de contexto es la práctica de diseñar sistemas que controlan la información que ve un LLM antes de generar una respuesta. En lugar de abarrotar todo en la ventana de contexto, seleccionas y organizas solo los detalles más relevantes, como el historial del usuario, los documentos recuperados o los resultados de las herramientas, para que el modelo pueda razonar de manera más eficiente.
Cómo se hace:
Cómo ayuda:
La contrapartida es que la creación de sistemas contextuales eficaces requiere un esfuerzo inicial de ingeniería. Necesitas contar con procesos de recuperación, resumen y validación, y un diseño deficiente puede provocar lagunas contextuales que perjudican el rendimiento. Pero cuando se hace bien, la ingeniería de contexto hace que las aplicaciones grandes sean más fiables y asequibles.
Reducir los costes de inferencia del LLM no es cuestión de un solo truco. Se trata de combinar enfoques que tengan sentido para tu carga de trabajo. Técnicas como la cuantificación, la poda y la destilación de conocimientos reducen el tamaño del modelo. El procesamiento por lotes, el almacenamiento en caché y la inferencia distribuida mejoran la forma en que se procesan las solicitudes. Las opciones de hardware y la compresión de modelos aumentan aún más la eficiencia, mientras que la ingeniería de contexto y de respuestas rápidas reduce el uso innecesario de tokens en el origen.
Las desventajas son reales: cada método conlleva complejidad, posible pérdida de precisión o sobrecarga de infraestructura. Pero las ganancias se acumulan. Con solo aplicar algunas de estas técnicas, podrás mantener los modelos asequibles, ampliar el uso sin que los costes se disparen y crear sistemas que sigan siendo sostenibles a medida que los modelos y las aplicaciones crecen.
¡Aprende IA con estos cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Stanislav Karzhev
12 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
